







一、基本术语:
Graph(V,E) V:顶点的有穷非空集合,E:边的有穷集合
逻辑结构:多个对多个
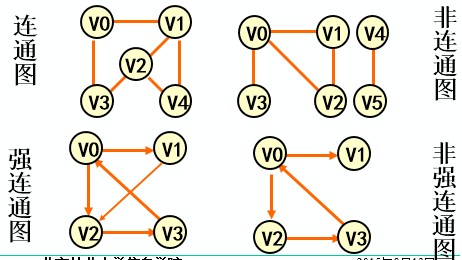
无向图:每条边都没有方向
有向图:每条边都有方向
完全图:任意两个点都有一条边相连

稀疏图:有很少边或弧的图;稠密图:多
网:边/弧带权的图
权:图中边/弧所具有的相关数,表明从一个顶点到另一个顶点的距离或耗费
邻接:有边/弧相邻的两个顶点之间的关系。存在(vi,vj),互为邻接点,存在<vi,vj>,vi邻接到vj,vj邻接于vi
关联(依附):边/弧与顶点之间的关系,存在(vi,vj)/<vi,vj>,则称该边/弧关联于vi和vj
顶点的度:与该顶点相关联的边的数目,记为TD(v)
有向图中,顶点的度=该顶点的入度+出度=ID(v)+OD(v)(入度是以V为终点的有向边条数)
路径:接续的边构成的顶点序列
路径长度:路径上边或弧的数目/权值之和
环(回路):第一个顶点和最后一个顶点相同的路径
简单路径:除路径起点和终点可以相同以外,其余顶点均不相同的路径
简单环(简单回路):除路径起点和终点相同以外,其余顶点均不相同的路径
连通图(强连通图):在G=(V,{E})中,若对任意两个顶点v,u都存在从v到u的路径,则G是连通图/强连通图------有向图称为强XX
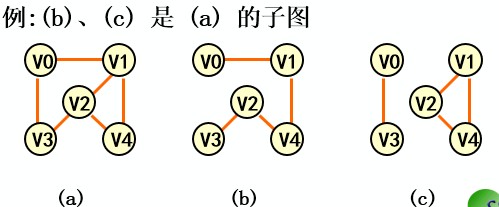
子图:G(V,E),G1(V1,E1)
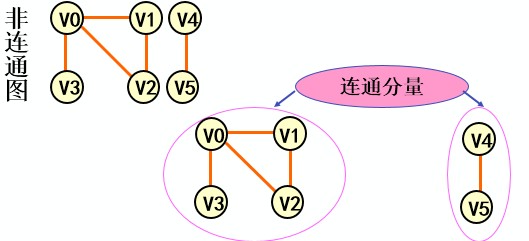
连通子图(强连通子图):
无向图G 的极大连通子图称为G的连通分量。
极大连通子图意思是:该子图是 G 连通子图,将G 的任何不在该子图中的顶点加入,子图不再连通。

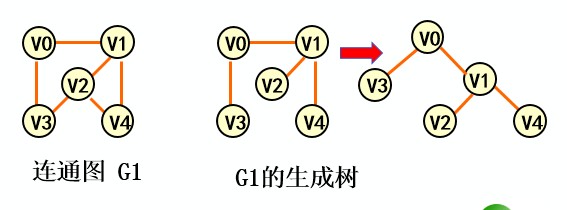
极小连通子图:该子图是G的连通子图,在该子图中删除任意一边,子图则不再连通
生成树:包含无向图G所有顶点的极小连通子图
生成森林:对非连通图,由各个连通分量的生成树的集合
二、图的存储结构:
顺序存储结构:数组表示法(邻接矩阵)
链式存储结构:多重链表(邻接表,邻接多重表,十字链表)
1.数组表示法(邻接矩阵)
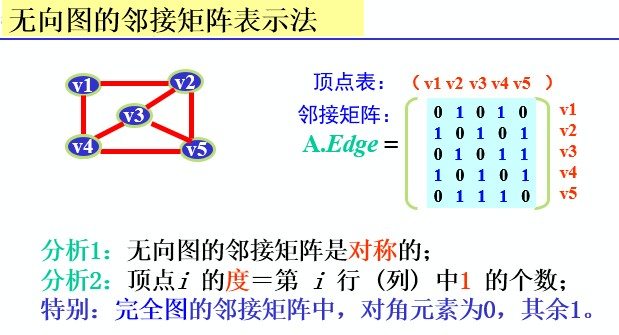

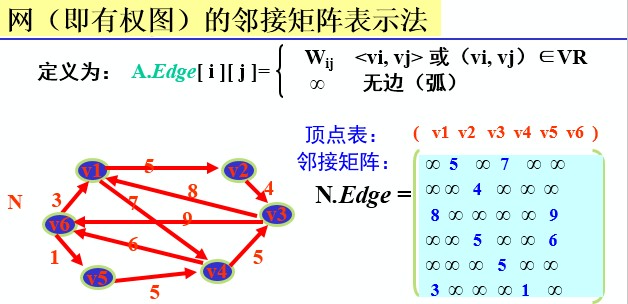
<span style="font-size:14px;">//用两个数组分别存储顶点表和邻接矩阵
#define MaxInt 32767//表示极大值 ∞
#define MVNum 100//最大定点数
typedef char VerTextType;//假设顶点的数据类型为字符型
typedef int ArcType;//边的权值类型为整数型
struct AMGraph
{
VerTextType vexs[MVNum];//顶点表
ArcType arcs[MVNum][MVNum];//邻接矩阵
int vexnum,arcnum;//图的当前点数和边数
};
</span>转载:C++ 中typedef用法总结详见
http://www.cnblogs.com/charley_yang/archive/2010/12/15/1907384.html
2.链式表示法(邻接表)
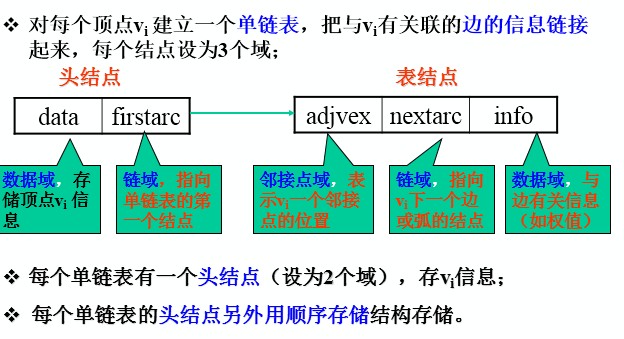

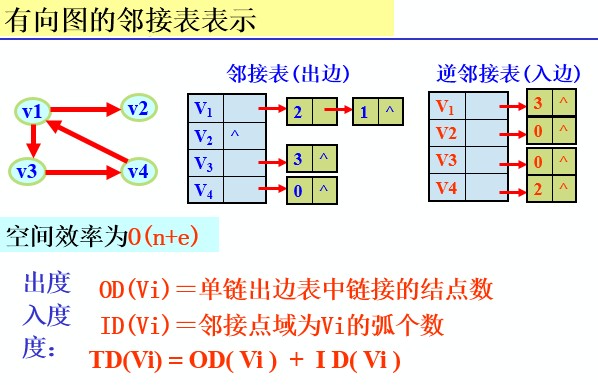
<span style="font-size:14px;">#define MVNum 100//最大顶点数
typedef char VerTextType;//假设顶点的数据类型为字符型
//邻接表的存储表达
typedef struct ArcNode//边结点
{
int adjvex;//该边所指向的顶点的位置
struct ArcNode *nextarc;//指向下一条边的指针
OtherInfo info;//和边相关的信息
}ArcNode;
typedef struct VNode
{
VerTextType data;//顶点信息
ArcNode *firststare;//指向第一条依附于该顶点的边的指针
}VNode,AdjList[MVNum];//AdjList表示邻接表类型
typedef struct
{
AdjList vertices;//邻接表
int vexnum,arcnum;//图的当前顶点数和边数
};
</span>邻接矩阵和邻接表:
1. 联系:邻接表中每个链表对应于邻接矩阵中的一行,链表中结点个数等于一行中非零元素的个数。
2. 区别:
①对于任一确定的无向图,邻接矩阵是唯一的(行列号与顶点编号一致),但邻接表不唯一(链接次序与顶点编号无关)。
②邻接矩阵的空间复杂度为O(n^2),而邻接表的空间复杂度为O(n+e)。
3. 用途:邻接矩阵多用于稠密图;而邻接表多用于稀疏图
三、图的遍历-图的基本运算
搜索引擎两种基本抓取策略-深度优先,广度优先
两种策略结合:先广后深+权重优先
1.深度优先搜索DFS(Depth_FirstSearch)
仿树的先序遍历
在访问图中某一起始顶点 v 后,由 v 出发,访问它的任一邻接顶点 w1;
再从 w1 出发,访问与 w1邻接但还未被访问过的顶点 w2;
然后再从 w2 出发,进行类似的访问,…
如此进行下去,直至到达所有的邻接顶点都被访问过的顶点 u 为止。
接着,退回一步,退到前一次刚访问过的顶点,看是否还有其它没有被访问的邻接顶点。
如果有,则访问此顶点,之后再从此顶点出发,进行与前述类似的访问;
如果没有,就再退回一步进行搜索。重复上述过程,直到连通图中所有顶点都被访问过为止。
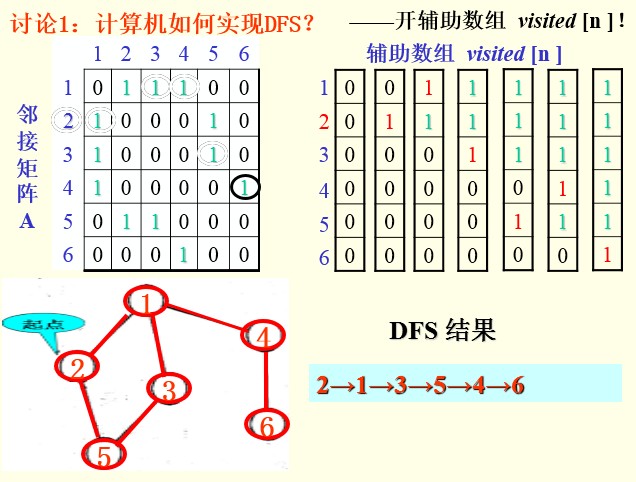
<span style="font-size:14px;">//DFS实现-可用递归
void DFS(AMGraph G,int v)//G为邻接矩阵
{
cout<<v;
visited[v]=true;//访问第v个顶点
for(int w=0;w<G.vexnum;w++)//依次检查邻接矩阵的v所在的行
{
if((G.arcs[v][w]!=0)&&(!visited[w]))
{
DFS(G,w);
}
}
}
void DFS(ALGraph G,int v)//G为邻接表类型
{
cout <<v;
visited[v]=true;
p=G.vertices[v].firststare;
while(p!=NULL)
{
w=p->adjex;//表示w是v的邻接点
if(!visited[w])
DFS(G,w);
p=p->nextarc;//p指向下一个边结点
}
}
</span>
2.广度优先搜索BFS(Breadth_FirstSearch)
仿树的层次遍历过程
分层的,不回退,非递归
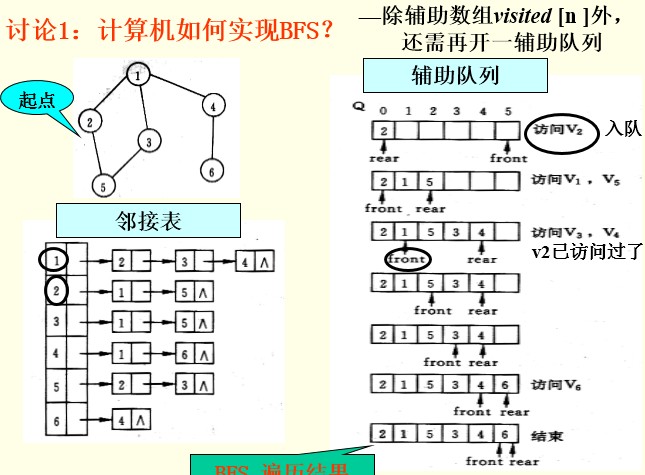
<span style="font-size:14px;">//广义遍历实现
void BFS(Graph G,int v)
{
queue<int > Q;
//访问第v个顶点
cout<<v;
visited[v]=true;
InitQueue(Q);//辅助队列Q初始化,置空
EnQueue(Q,v);//v进队列
while(!QueueEmpty(Q))//队列非空
{
DeQueue(Q,u);//出队列并置为u
for(int w=FirstAdjex(G,u);w>=0;w=NextAdjex(G,u,w))
{
if(!visited[w])//w为u尚未访问过的结点
{
cout<<w;
visited[w]=true;
EnQueue(Q,w);
}
}
}
}
</span>DSF与BFS算法效率比较
空间复杂度相同,都是O(n)(借用了堆栈和队列)
时间复杂度与存储结构(邻接矩阵或邻接表)有关,而与搜索路径无关
四、图的应用
1.最小生成树-无向图的应用
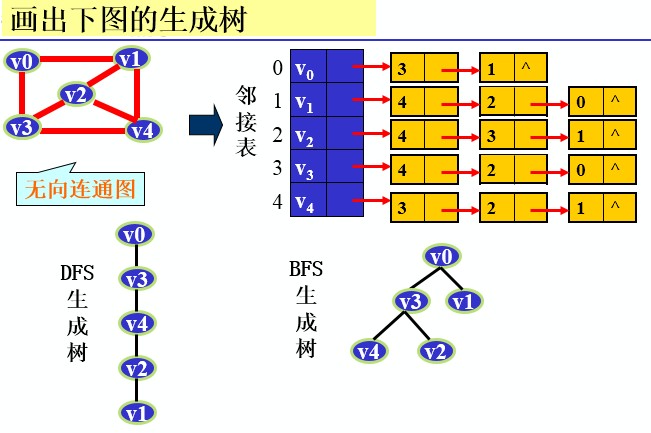
如何求?
Prim算法:归并顶点,与边数无关,适于稠密网-加点法,选择权值最小的先加上
Krustal算法:归并边,适于稀疏网—加边法,选择权值最小的先加上
贪心算法:找零钱,先找最大币值的
2.最短路径-有向图的应用
与最小生成树不同,不一定包含n个顶点
解决方法:
单源最短路径-迪杰斯特拉算法-一顶点到其他各顶点
所有顶点间的最短距离-弗洛伊德算法-任意两顶点之间
3.活动网络-有向图的应用
①AOV网(Activity On Vertices)—用顶点表示活动的网络-拓扑排序算法
② AOE网(Activity On Edges)—用边表示活动的网络-关键路径
拓扑有序序列:由AOV网中的所有顶点构成的一个线性序列,在这个序列中体现了所有顶点间的优先关系
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









