









在 MySQL 中,索引是在存储 引擎层 实现的,所以并没有统一的索引标准。
名词解释:
- 聚合型数据库:一般使用 XML 或 Json 格式来保存数据,归属于聚合型数据库。如 MongoDB
- 聚簇索引:指的是索引和数据存储放在一起的,找到了索引就可以找到数据
- 非聚簇索引:指的是索引和数据存放不再一起,索引结构的叶子节点指向数据存储所在行。
- 数据库聚合函数:count(),max(),min(),sum()
目录
一、索引的数据结构——B+Tree 和 B-Tree
MySql 采用的是 B+Tree(真正的data都存放在最底层的叶子节点上)的存储形式:
Mysql 是一种关系型数据库,区间访问是常见的一种情况,而 B-Tree并不支持区间访问,而B+Tree由于数据全部存储在叶子节点,并且通过指针串在一起,这样就很容易的进行区间遍历甚至全部遍历。
其次B+树的查询效率更加稳定,数据全部存储在叶子节点,查询时间复杂度固定为 O(log n)。
MongoDB 采用的是 B-Tree的存储形式:
MongoDB 是文档型的数据库,是一种 nosql,它使用类 Json 格式保存数据。文档型数据库和我们常见的关系型数据库不同,一般使用 XML 或 Json 格式来保存数据,归属于聚合型数据库。
MongoDB 这类 nosql 适用于 数据模型简单,性能要求高的场合。尽可能少的磁盘 IO 是提高性能的有效手段。MongoDB 是聚合型数据库,而 B-树恰好 key 和 data 域聚合在一起。最快的查询时间复杂度可以达到O(1)。
数据间的json存储方式:(类似oc2与原系统之间的数据传输报文所建立的层级关系)
//Customer { "id":1, "name":Tom, "billingAddress":[{"city":"China"}] } //Orders { "id":99, "orderItem":[ "productId"27, "price":100, "productName":book ], "shippingAddress":[{"city":"china"}], "orderPayment":[ ... ] }
二、索引的存储方式——聚簇索引 和 非聚簇索引
聚簇索引和非聚簇索引不是新的索引类型,而是一种数据存储方式。具体细节依赖于其实现方式。
- 聚簇索引 背后的数据结构是 B+Tree 或者是 B-Tree;
- 非聚合索引 背后的数据结构是 B+Tree;
三、基于mysql的聚簇索引与非聚簇索引
mysql官方对于聚簇索引的解释:
The InnoDB term for a primary key index. InnoDB table storage is organized based on the values of the primary key columns, to speed up queries and sorts involving the primary key columns. For best performance, choose the primary key columns carefully based on the most performance-critical queries. Because modifying the columns of the clustered index is an expensive operation, choose primary columns that are rarely or never updated.
聚簇索引就是在InnoDB引擎中的主键术语。
Mysql中创建的表可以选择使用不同的数据库引擎。
InnoDB使用的是聚簇索引
InnoDB中不可以自己创建聚簇索引,一般是有mysql来完成构建。
InnoDB是通过主键聚集数据:
- 有自定义的主键,通过主键来创造聚簇索引
- 如果没有自定义主键,InnoDB会选择一个非空的唯一索引来代替
- 如果没有非空的唯一索引,InnoDB会隐式的定义一个主键来作为聚簇索引。
因此,InnoDB的索引可以提供很快的主键查找性能,不过他的其他索引也会包含主键列,所以主键过大的话,也会导致其他索引过大。所以InnoDB不适合使用过大的索引。
在mysql中,聚簇索引就是按照每张表的主键来构建一个B+Tree,所以该树的叶子节点就存储了整个表的行数据,也称聚簇索引的叶子节点为数据页。因此聚簇索引具有唯一性,一张表只有一个聚簇索引。聚簇索引决定了表中数据的物理顺序。
聚簇索引的优点:
- 数据访问速度快,因为聚簇索引将索引和数据存放在一棵B+Tree上,所以比非聚簇索引访问数据要快。
- 聚簇索引使得根据主键的查询和范围查询非常快
聚簇索引的缺点:
- 插入顺序严重影响插入速度:按照主键的顺序进行插入速度最快,否则会出现 页分裂。因此对于innoDB的表一般都定义一个自增主键。
- 更新主键代价高,会导致被更新的数据行被移动
- 对于其他索引的访问,需要进行两次查询,首先索引到具体主键,然后通过聚簇索引访问数据。
非聚簇索引:
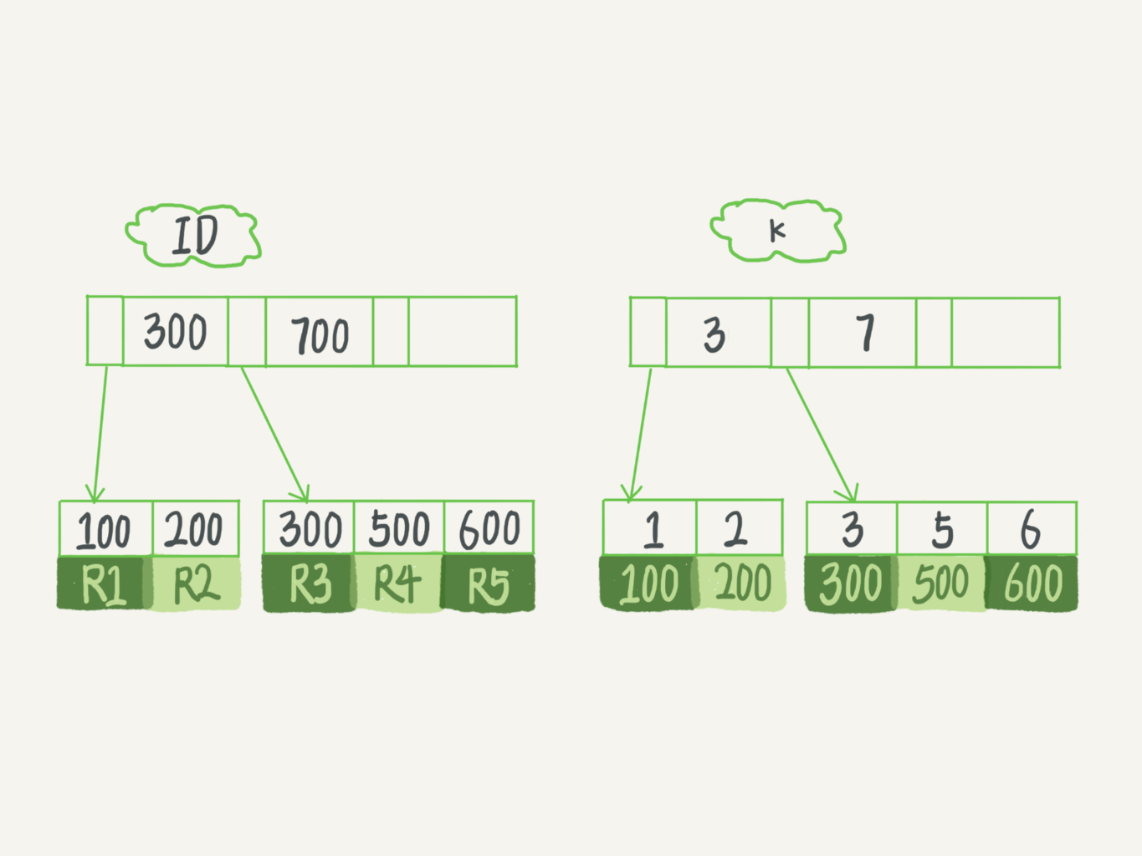
在聚簇索引之上建立的索引都称为非聚簇索引,非聚簇索引访问数据都需要二次查询。非聚簇索引的叶子节点上存放的不是数据行的具体物理位置,而是主键值。非聚簇索引的叶子节点中不仅包括主键的值,还包括相对应的数据行的聚簇索引键。在InnoDB中基于主键索引和普通索引的查询有什么区别:
如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
自增主键的优势:由于每个非主键索引的叶子节点上都是主键的值。如果用String类型做主键,那么每个二级索引的叶子节点占用约 20 个字节,而如果用整型做主键,则只要 4 个字节,如果是长整型(bigint)则是 8 个字节。显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
MyISAM使用的是非聚簇索引
MyISAM中 索引文件 和 数据文件是分开的,索引文件中保存的是数据记录的地址。该引擎下,主键索引和其他索引在存储结构上是相同的,只是主键索引要求key是唯一的,而其他索引的key可以存在重复。索引树是独立的,辅助索引无需依赖于主键索引进行数据查询。















 985
985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









