







目录
4.redis 作为缓存,mysql的数据如何与redis进行同步?(双写一致性)
redis 使用场景
- 缓存(穿透、击穿、雪崩,双写一直,持久化,数据过期,淘汰策略)
- 分布式锁(setnx,redisson)
- 计数器(incr 命令实现)
- 保存token(string)
- 消息队列(list)
- 延迟队列(zset)
其它
- 集群(主从、哨兵、集群)
- 事务
- redis 为什么这么快?
1.redis使用的场景、如果发生了缓存穿透?
我看你做的项目中,都用到了redis,你在最近的项目中哪些场景使用了redis呢?
结合项目
- 一是验证你的项目场景的真实性,二是为了作为深入发问的切入点
- 缓存 (缓存三兄弟(穿透、击穿、雪崩)、双写一致、持久化、数据过期策略、数据淘汰策略)
- 分布式锁 (setnx、redisson)
- 消息队列、延迟队列 (何种数据类型)
什么是缓存穿透?
例:
一个get请求:api/news/getById/1

缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库(导致数据库并发并不高,请求到达一定量会击垮数据库)
解决方案一:缓存空数据,如果mysql查询的数据结果为空,仍把这个空结果进行缓存(如查询key为1的null 数据,则在redis中缓存{key:1, value:null})
优点:简单
缺点:消耗内存,可能会发生数据不一致的问题
为什么会发生数据不一致问题?
比如一开始数据库中没有key=1的数据,redis缓存空数据(key:1,value:null),后面往数据库中添加key=1的数据时,用户过来查询还是查到了redis 的空数据,由此产生redis和数据库数据不一致的问题。
例:
一个get请求:api/news/getById/1
缓存预热:一些热点数据添加到缓存数据库同时,也要添加到布隆过滤器中

解决方案二:布隆过滤器
优点:没有多余key,所以内存占用较少
缺点:实现复杂,存在误判
布隆过滤器
bitmap(位图):相当于是一个以(bit)位为单位的数组,数组中每个单元只能存储二进制数0或1
布隆过滤器作用:布隆过滤器可以用于检索一个元素是否在一个集合中。
基本概念
1. bit(位,又名“比特”):bit的缩写是b,是计算机中的最小教据单位(属于二进制的范畴,其实就是0或者1)
2.Bvte(字节):Byte的缩写是B,是计算机文件大小的基本计算单位,比如一个字符就是 1Byte 如果是汉字,则是2 Byte,1B(字节)=8b(位)

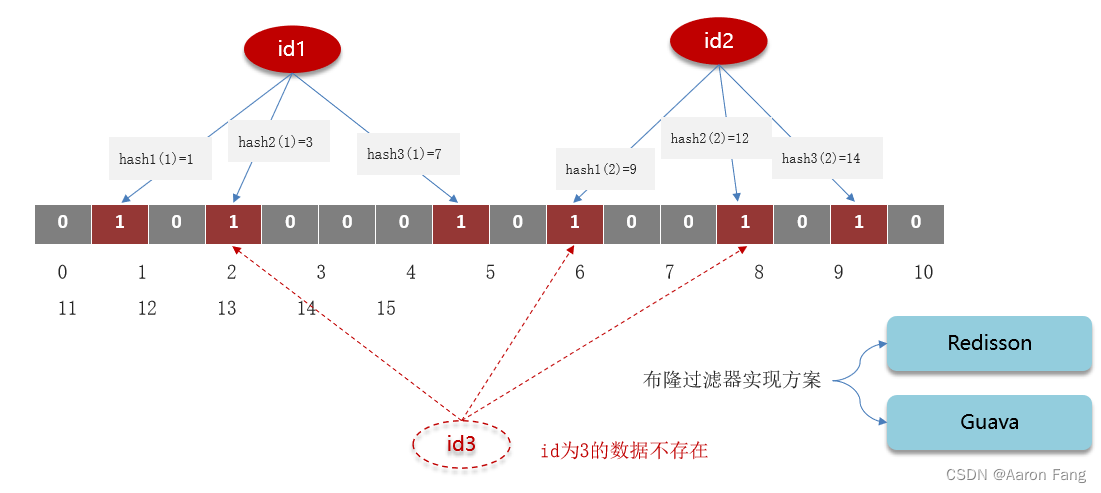
为什么存在误判?
假设id=1的数据,通过多个hash函数,获取多个hash值,假如这个值分别为1、3、7,需要把对应数组上由0改为1,假设id=2的数据按照上面方法也获取多个hash值,分别为9、12、14,也把对应的数组上的0改为1。现在查询id=3,通过多个hash函数计算,值为3、9、12,虽然数组中没有id=3的数据,但还是返回查询成功,这个就是误判。降低误判需要增大数组,增大数组的长度会增大内存的消耗,一般项目内设置5%的误判率,不至于高并发压倒数据库。
Redis的使用场景
- 根据自己简历上的业务进行回答
- 缓存 (穿透、击穿、雪崩、双写一致、持久化、数据过期、淘汰策略)
- 分布式锁(setnx、 redisson)
什么是缓存穿透,怎么解决
- 缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库
- 解决方案一:缓存空数据
- 解决方案二:布隆过滤器
面试参考回答:
面试官:什么是缓存穿透 ? 怎么解决 ?
候选人:
嗯~~,我想一下
缓存穿透是指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,可能导致 DB 挂掉。这种情况大概率是遭到了攻击。
解决方案的话,我们通常都会用布隆过滤器来解决它
面试官:好的,你能介绍一下布隆过滤器吗?
候选人:
嗯,是这样~
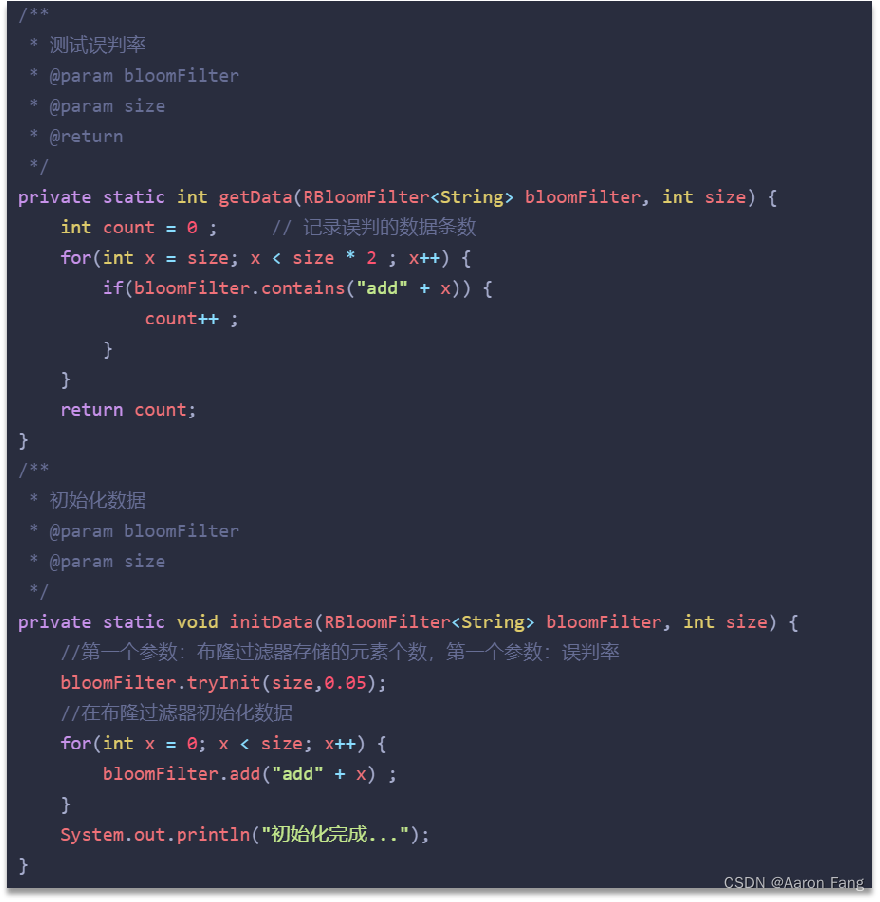
布隆过滤器主要是用于检索一个元素是否在一个集合中。我们当时使用的是redisson实现的布隆过滤器。
它的底层主要是先去初始化一个比较大数组,里面存放的二进制0或1。在一开始都是0,当一个key来了之后经过3次hash计算,模于数组长度找到数据的下标然后把数组中原来的0改为1,这样的话,三个数组的位置就能标明一个key的存在。查找的过程也是一样的。
当然是有缺点的,布隆过滤器有可能会产生一定的误判,我们一般可以设置这个误判率,大概不会超过5%,其实这个误判是必然存在的,要不就得增加数组的长度,5%以内的误判率一般的项目也能接受,不至于高并发下压倒数据库。
2.什么是缓存击穿?
缓存击穿:给某一个key设置了过期时间,当key过期的时候,恰好这时间点,这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
假如缓存重建的过程中花费50毫秒,为什么需要花费50毫秒?
有的时候存入缓存中的数据需要涉及多张表,多张表需要先分头统计后汇总结果,这样花费时间会更久

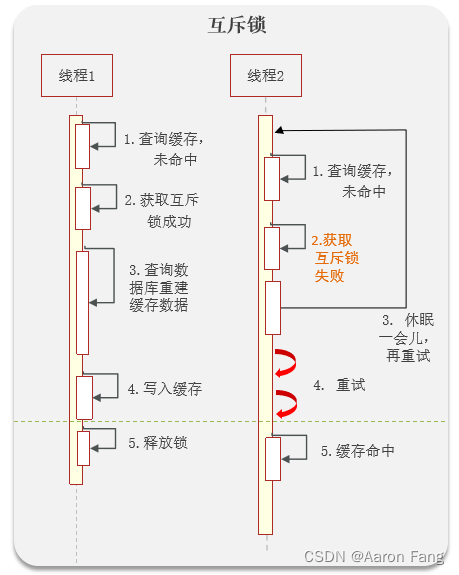
解决方案一:互斥锁
解决方案二:逻辑过期
什么是互斥锁?
缺点:只能有一个线程获取锁,其它线程只能等待,性能相对来说比较低
优点:强一致性(和钱相关的需要保持强一致)
什么是逻辑过期?
热点key不在缓存中设置过期时间,如何判断当前数据是否过期?新增数据到缓存的时候,新增一个过期的时间字段
优点:高可用、性能优(注重用户体验,互联网一般选择高可用)
缺点:不能保证数据的绝对一致


缓存击穿
- 缓存击穿:给某一个key设置了过期时间,当key过期的时候,恰好这时间点对这个key有大量的并发请求过来,这些并发的请求可能会瞬间把DB压垮
- 解决方案一:互斥锁,强一致,性能差
- 解决方案二:逻辑过期,高可用,性能优,不能保证数据绝对一致
面试参考回答:
面试官:什么是缓存击穿 ? 怎么解决 ?
候选人:
嗯!!
缓存击穿的意思是对于设置了过期时间的key,key在某个时间点过期的时候,恰好这时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把 DB 压垮。
解决方案有两种方式:
第一可以使用互斥锁:当缓存失效时,不立即去load db,先使用如 Redis 的 setnx 去设置一个互斥锁,当操作成功返回时再进行 load db的操作并回设缓存,否则重试get缓存的方法
第二种方案可以设置当前key逻辑过期,大概是思路如下:
①:在设置key的时候,设置一个过期时间字段一块存入缓存中,不给当前key设置过期时间
②:当查询的时候,从redis取出数据后判断时间是否过期
③:如果过期则开通另外一个线程进行数据同步,当前线程正常返回数据,这个数据不是最新
当然两种方案各有利弊:
如果选择数据的强一致性,建议使用分布式锁的方案,性能上可能没那么高,锁需要等,也有可能产生死锁的问题
如果选择key的逻辑删除,则优先考虑的高可用性,性能比较高,但是数据同步这块做不到强一致。
3.什么是缓存雪崩?
缓存雪崩:是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。

解决方案:
- 给不同的Key的TTL(过期时间)添加随机值(在原有过期时间上添加随机值1-5分钟),这样每个缓存的过期时间重复率会降低,很难引起集体失效
- 对redis服务宕机造成缓存雪崩,利用Redis集群提高服务的可用性(解决方案是哨兵模式、集群模式)
- 给缓存业务添加降级限流策略(ngxin或spring cloud gateway,降级可做为系统的保底策略,适用于穿透、击穿、雪崩)
- 给业务添加多级缓存(Guava或Caffeine,作为一级缓存)
缓存雪崩:是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
面试参考回答:
面试官:什么是缓存雪崩 ? 怎么解决 ?
候选人:
嗯!!
缓存雪崩意思是设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB 瞬时压力过重雪崩。与缓存击穿的区别:雪崩是很多key,击穿是某一个key缓存。
解决方案主要是可以将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
4.redis 作为缓存,mysql的数据如何与redis进行同步?(双写一致性)
一定、一定、一定要设置前提,先介绍自己的业务背景,有两种方案:
- 一致性要求高
- 允许延迟一致
双写一致性
当修改了数据库中的数据也要同时更新缓存中的数据,缓存和数据库中的数据要保持一致

读操作:缓存命中,直接返回;缓存未命中查询数据库,写入缓存
写操作:延迟双删
缺点:
- 有脏数据风险
- 代码耦合性高
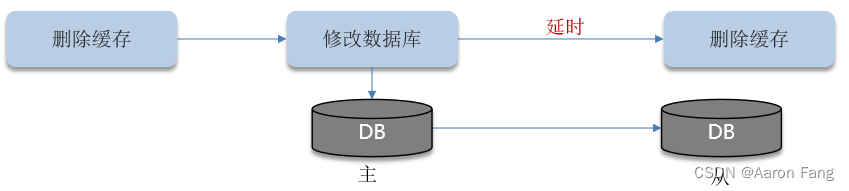
1.先删除缓存,还是先修改数据库?(都会导致脏数据的出现)
2.为什么要删除两次缓存?
3.为什么要延迟删除?
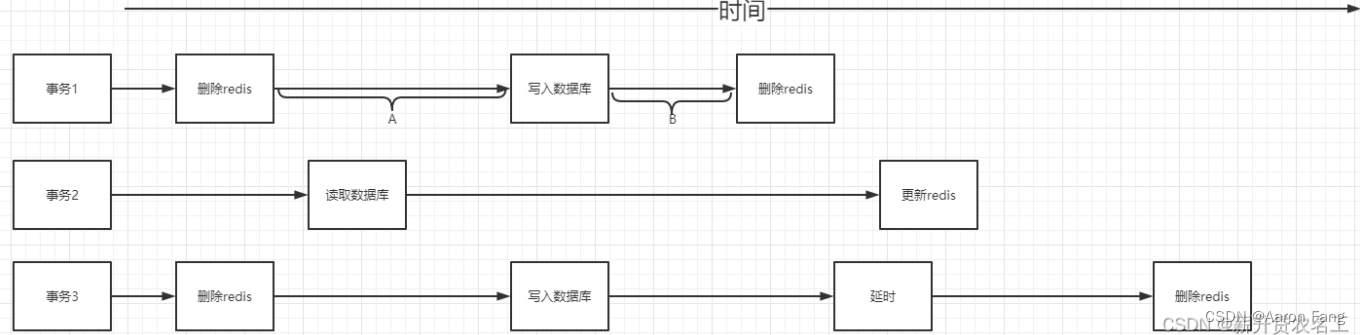
为什么要删除两次缓存?为什么要延迟双删?
1.事务1进行数据库写入,当有其他事务2在A时间段内进行查询操作时,因为这时候数据库还没写入,这时候事务2读到的是旧数据。
2.如果事务1在写入数据库后直接进行redis的删除,这时候事务2在事务1最后删除redis后更新了redis,那么这样就导致了数据不一致。以后每次读取时读到的都是脏数据直到redis过期。
延时多长时间不好控制,在延时的过程中,依然会出现脏数据。延迟双删极大的控制了脏数据的风险,也会有脏数据出现, 做不到绝地的强一致性。
先删除缓存,后操作数据库
1、如果先删除Redis缓存数据,然而还没有来得及写入MySQL,另一个线程就来读取
2、这个时候发现缓存为空,则去Mysql数据库中读取旧数据写入缓存,此时缓存中为脏数据。
3、然后数据库更新后发现Redis和Mysql出现了数据不一致的问题
先操作数据库 ,后删除缓存
1、如果先写了库,然后再删除缓存,不幸的写库的线程挂了,导致了缓存没有删除
2、这个时候就会直接读取旧缓存,最终也导致了数据不一致情况
3、因为写和读是并发的,没法保证顺序
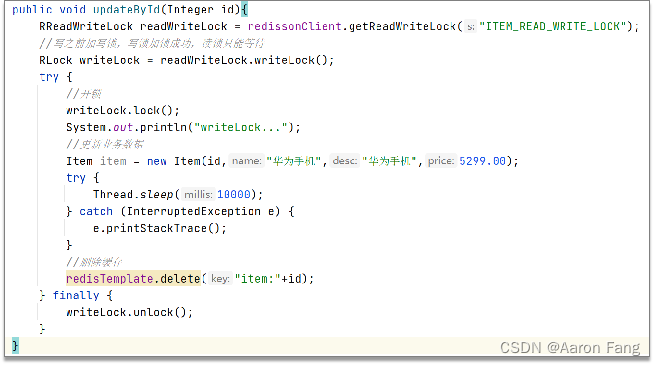
方案1:分布式锁(强一致性)
优点:强一致性
缺点:性能不高
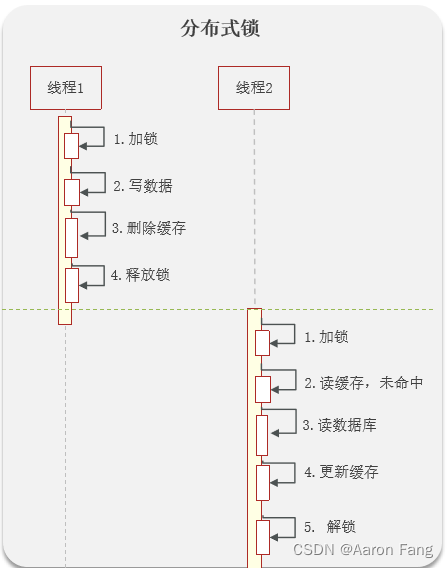
优化:
一般放入缓存中的数据都是读多写少
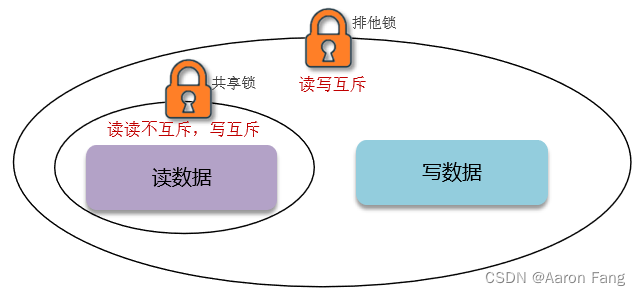
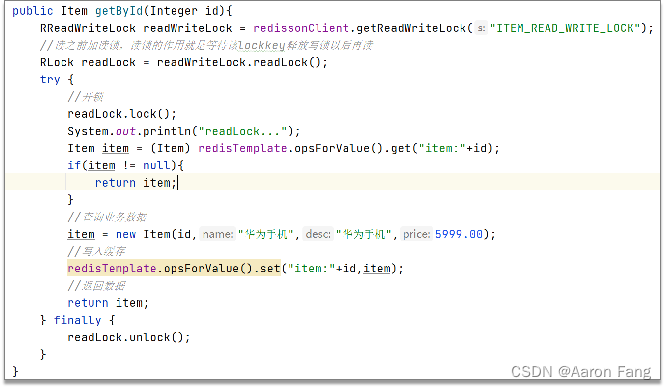
共享锁:也叫读锁readLock,加锁之后,其他线程可以共享读操作,不能写
排他锁:也叫独占锁writeLock,加锁之后,阻塞其他线程读写操作
读锁
写锁
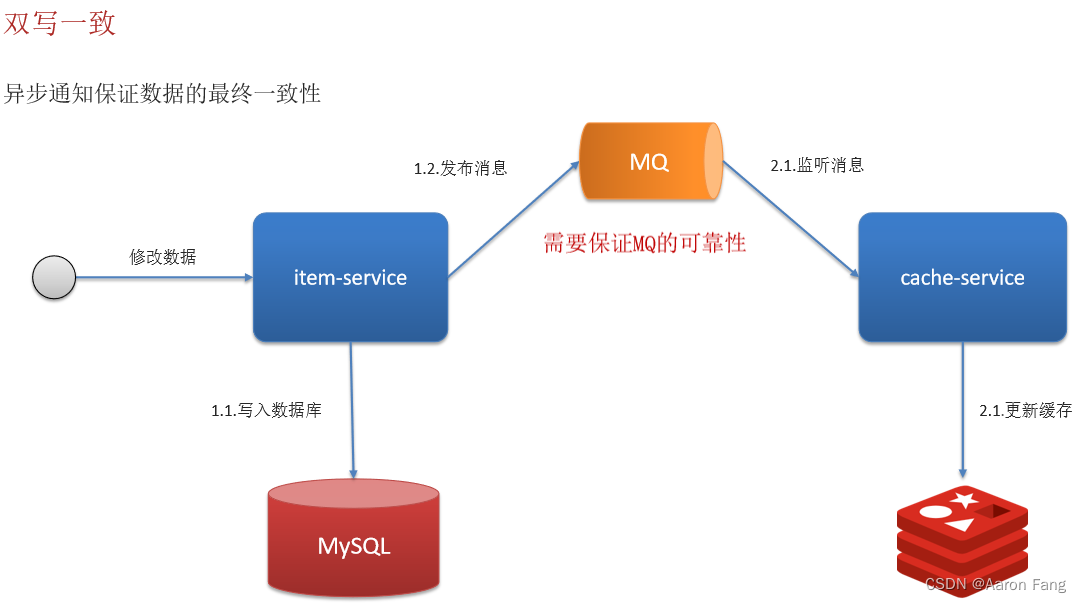
方案2:异步通知(允许短暂的不一致性)
优点:强一致
缺点:性能低
异步通知保证数据的最终一致性
基于Canal的异步通知
代码零侵入
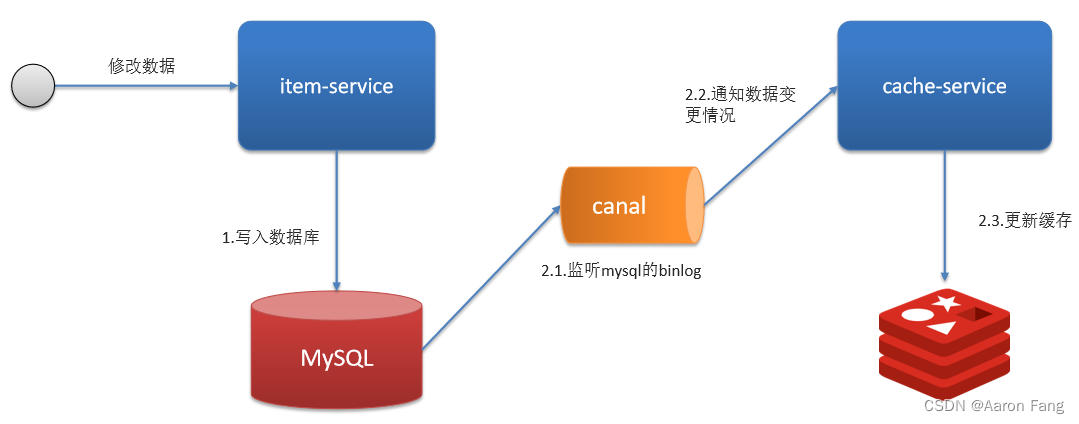
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
redis做为缓存,mysql的数据如何与redis进行同步呢?(双写一致性)
- 介绍自己简历上的业务,我们当时是把文章的热点数据存入到了缓存中,虽然是热点数据,但是实时要求性并没有那么高,所以,我们当时采用的是异步的方案同步的数据
- 我们当时是把抢券的库存存入到了缓存中,这个需要实时的进行数据同步,为了保证数据的强一致,我们当时采用的是redisson提供的读写锁来保证数据的同步
那你来介绍一下异步的方案(你来介绍一下redisson读写锁的这种方案)
- 允许延时一致的业务,采用异步通知
- 使用MQ中间中间件,更新数据之后,通知缓存更新
- 利用canal中间件,不需要修改业务代码,伪装为mysql 的一个从节点,canal通过读取binlog数据更新缓存
- 强一致性的,采用Redisson提供的读写锁
- 共享锁:读锁readLock,加锁之后,其他线程可以共享读操作
- 公排他锁:独占锁writeLock,加锁之后,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









