









1.目的
实现采样率fs=50MHz,通带为5MHz~15MHz,阻带衰减60dB的IIR带通滤波器
2.方案
采取直接型
3.详细设计
(1)确定滤波器的系数,系数和滤波器输出量化位宽
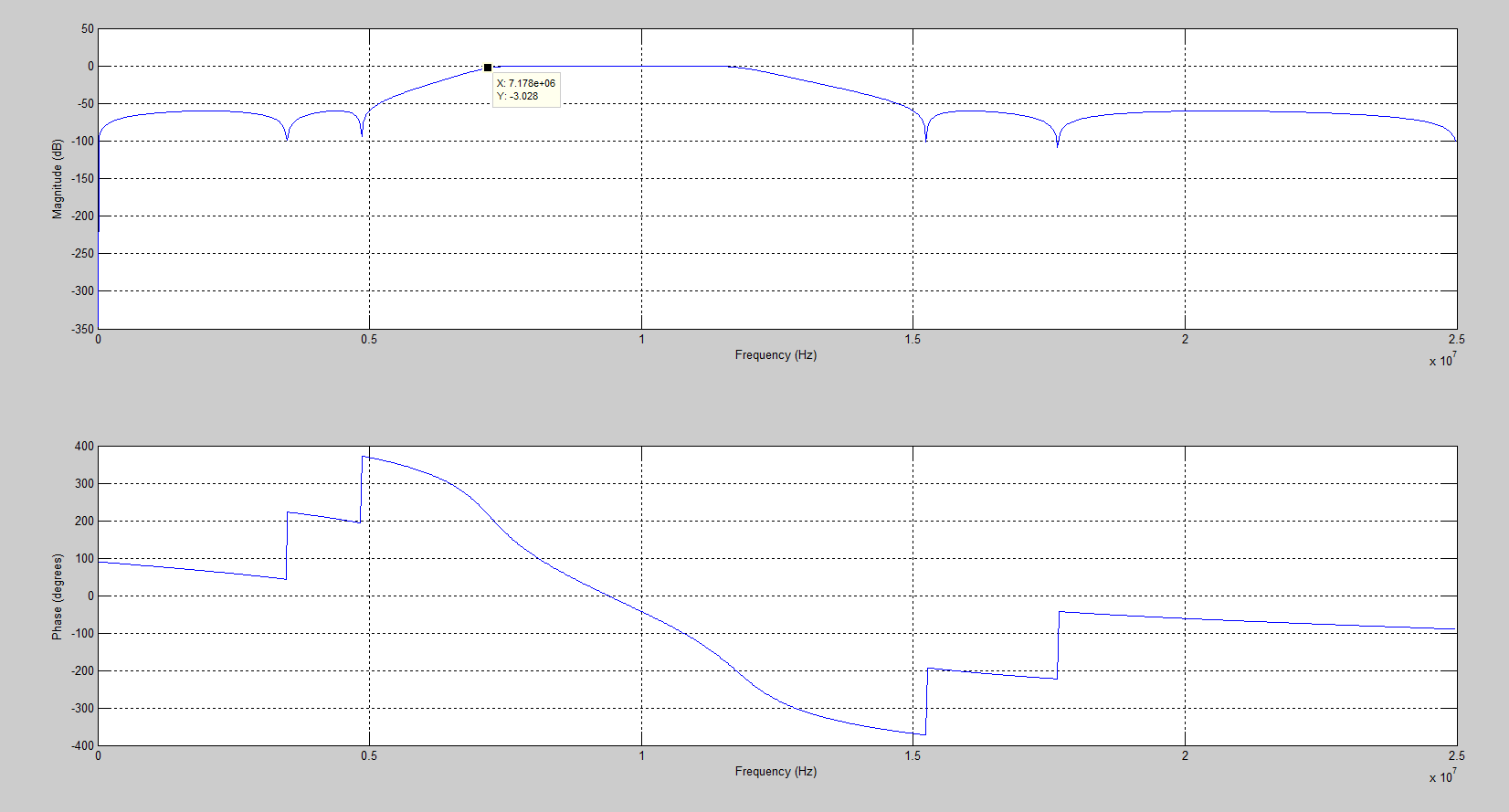
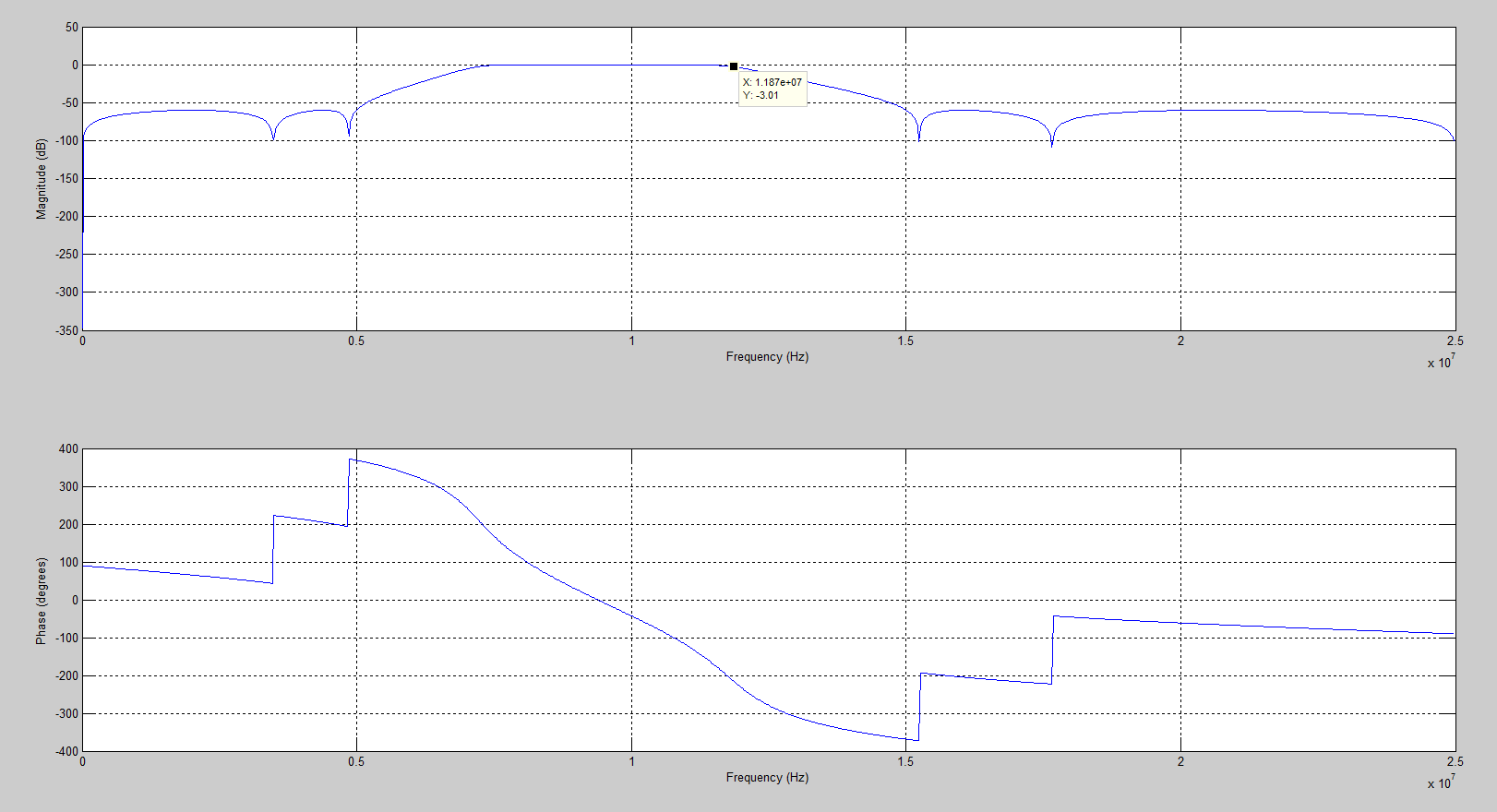
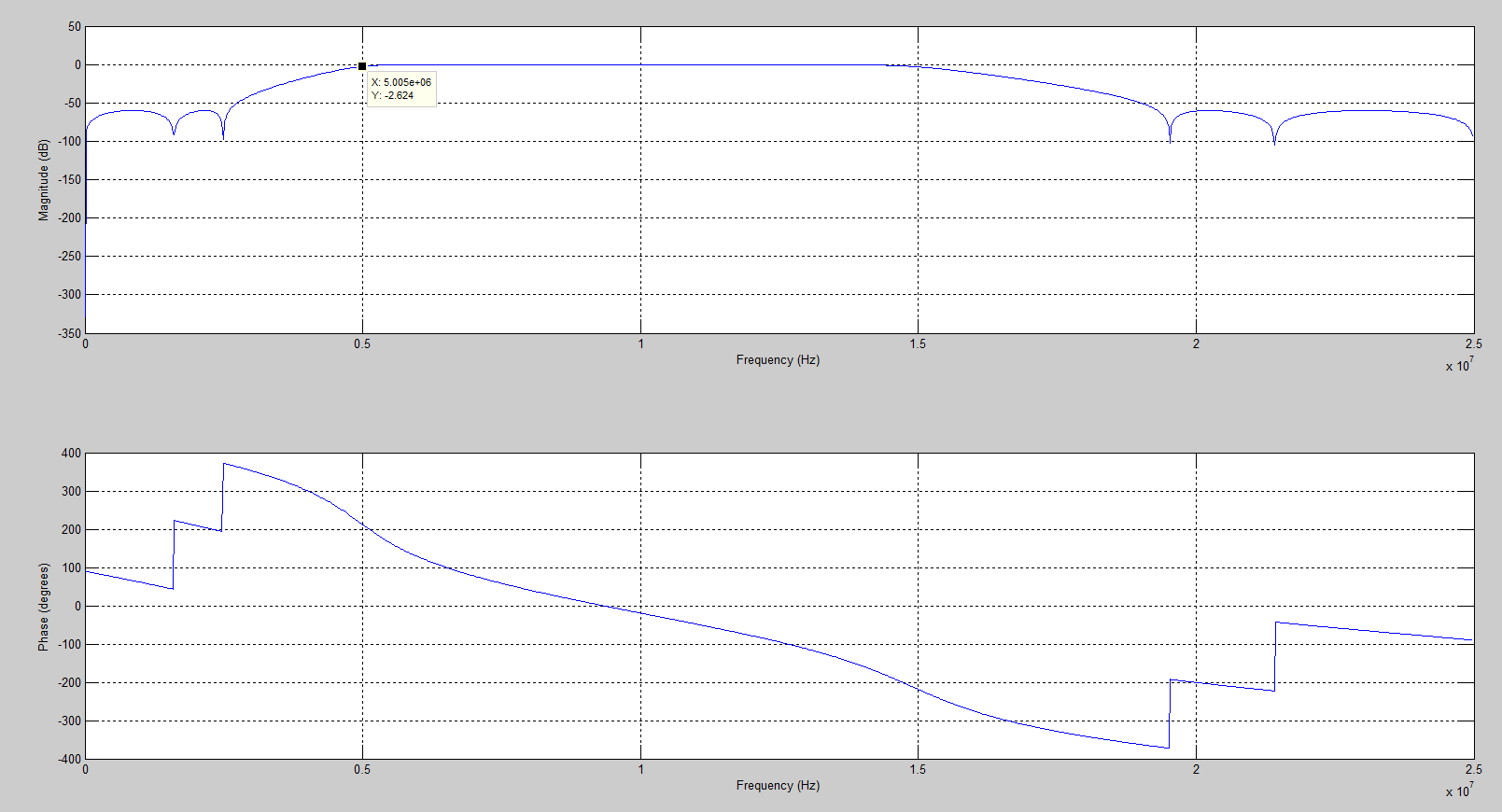
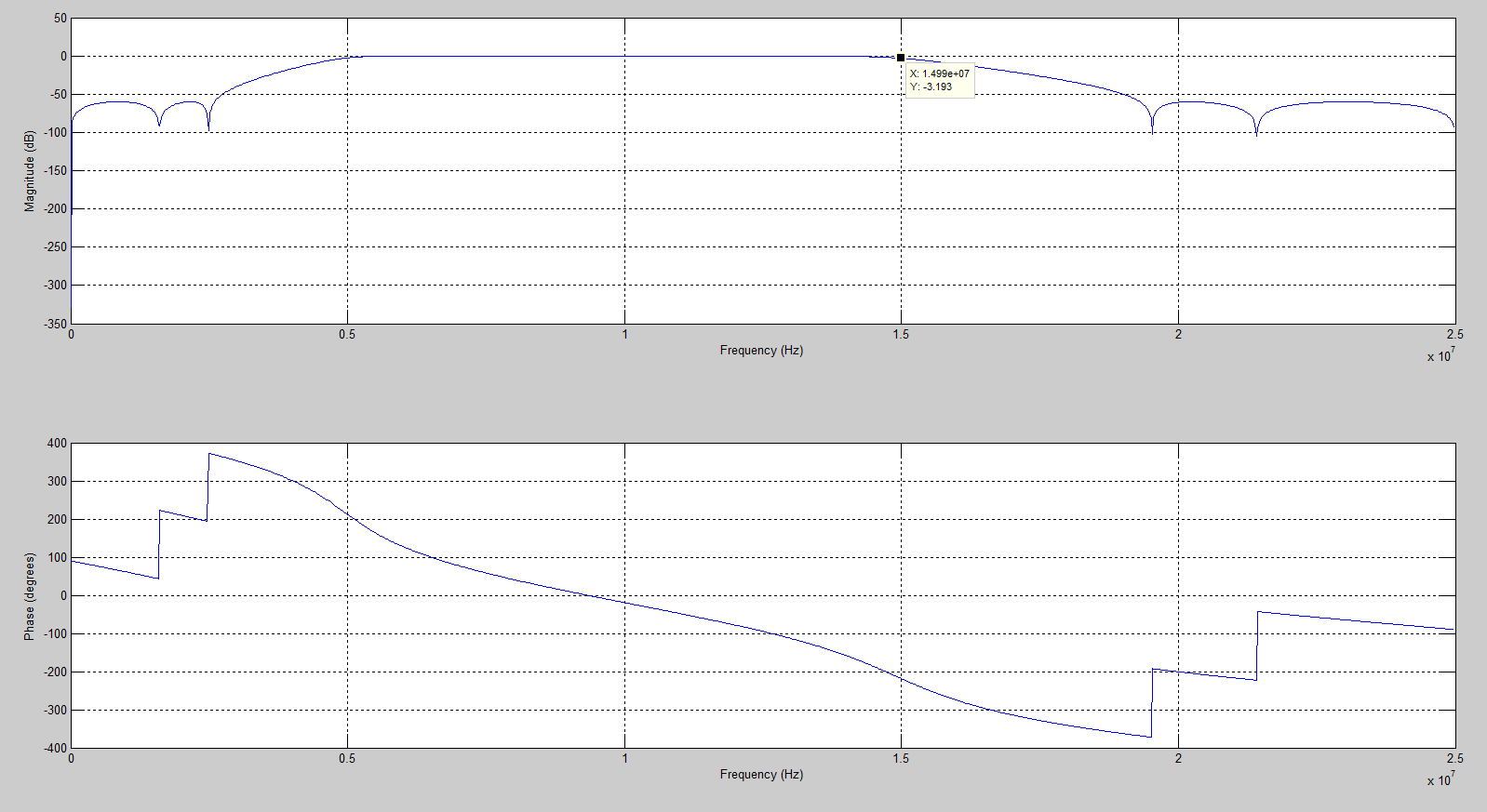
先根据要求的fs,fc1,fc2以及阻带衰减确定系数,当初如果设置截止频率f1=5MHz,f2 = 15MHz,实际的截止频率差很多,如图1。因此修改为f1 = 2.6MHz和f2 = 19.3MHz就能满足真正的通带为5MHz~15MHz,如图2满足要求后,再对系数量化。一定要确定好系数和输出数据的位宽,不满足就必须更改位宽,直到达到要求,才能进行下一步。例如:如图3,系数和输出数据的位宽都为8bits,量化后滤波器的响应与理想响应差太远,不能达到滤波要求。但如图4,系数13bits,输出数据位宽为14bit,量化后的幅频特性与理想滤波器的差不多,就能满足要求。(当然,位宽可以尽量量化大点,但相应的也更浪费资源)
(a)
(b)
图1 f1=5MHz,f2 = 15MHz滤波器的幅频特性
(a)
(b)
图2 f1=2.6MHz,f2 = 19.3MHz滤波器的幅频特性
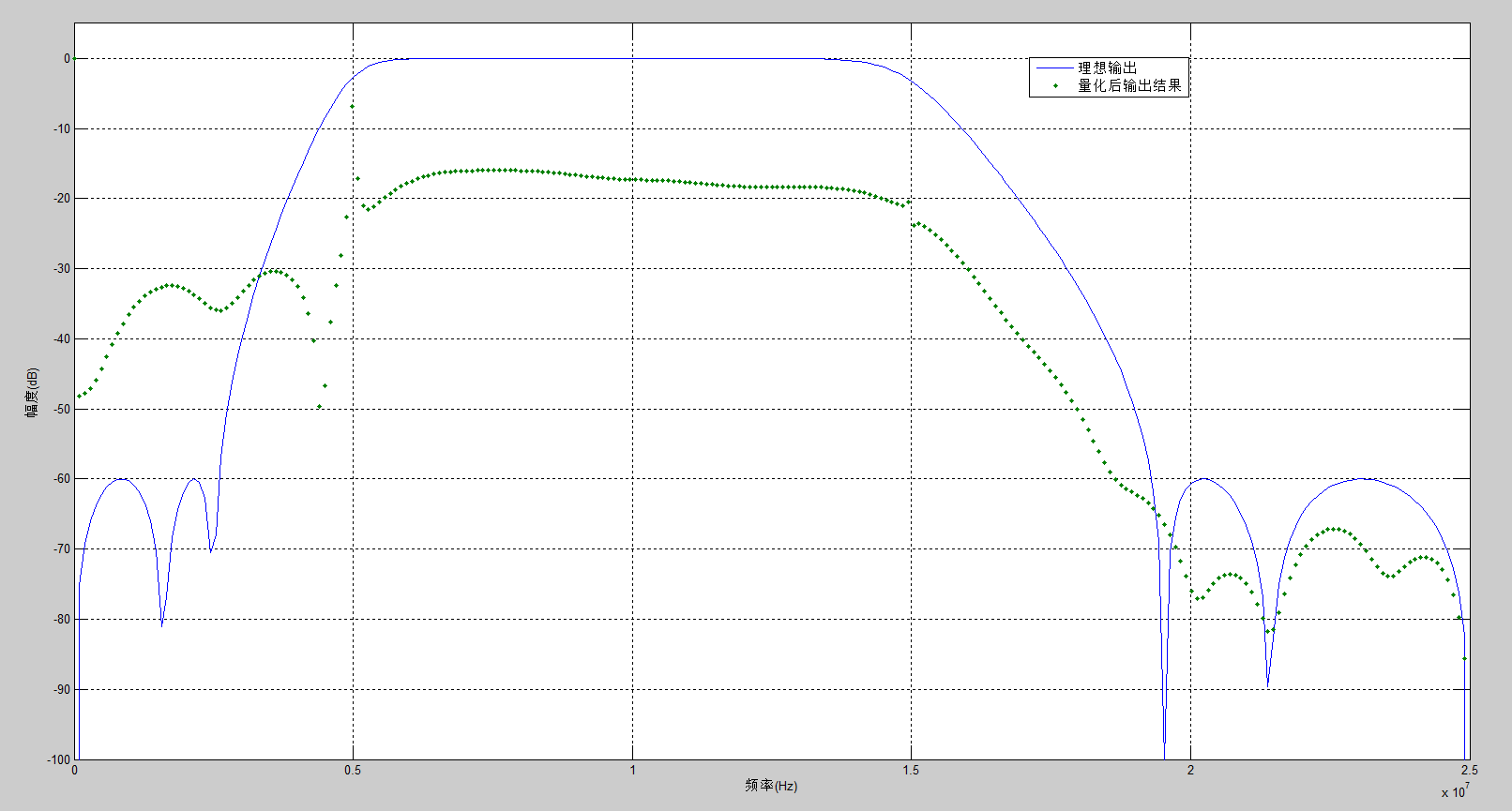
图3 量化位宽不足
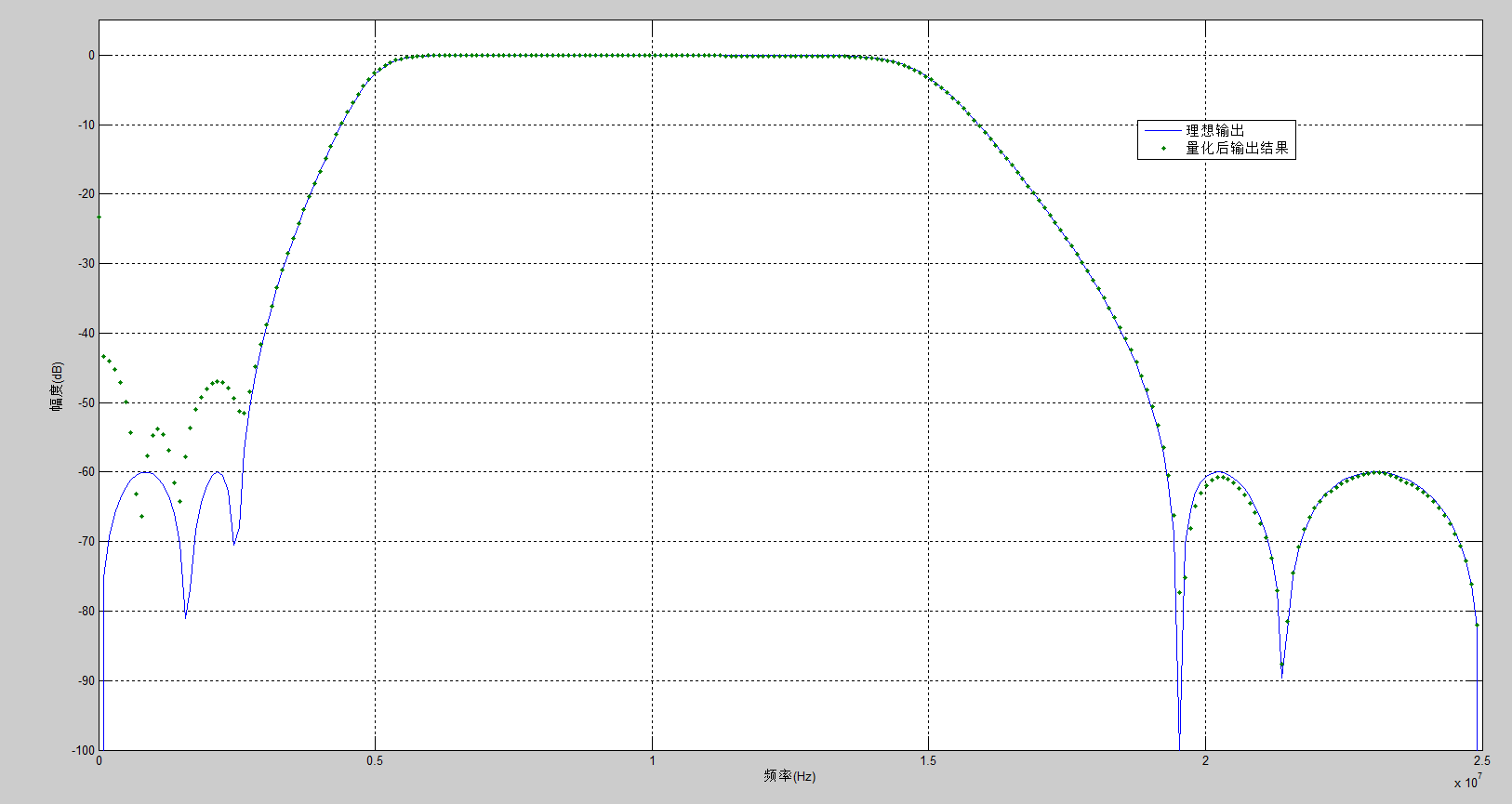
图4 量化位宽合适
文件:filter_coe.m
clc;
clear all;
fs = 50e6; %采样频率
f1 = 2.6e6;
f2 = 19.3e6;
N = 5; %5阶
Rp = 60;%阻带衰减
Wn = [2*f1/fs 2*f2/fs];%截止频率
% Qcoe=8; %滤波器系数字长
% Qout=8; %滤波器输出字长
Qcoe=13; %滤波器系数字长
Qout=14; %滤波器输出字长
delta=[1,zeros(1,511)]; %单位冲激信号作为输入信号
[b,a] = cheby2(N,Rp,Wn);
figure(1)
freqz(b,a,1024,fs);
%对滤波器系数进行量化,四舍五入截尾
%量化系数
m = max(max(abs(a)),max(abs(b)));
Qm = floor(log2(m/a(1))); %向下取整
if Qm < log2(m/a(1))
Qm = Qm + 1;
end
Qm = 2^Qm;
Qa = round(a/Qm*(2^(Qcoe-1)-1)) %四舍五入取整
Qb = round(b/Qm*(2^(Qcoe-1)-1)) %四舍五入取整
%求理想幅度响应
y=filter(b,a,delta);
%求量化后的幅度响应,QuantIIRDirectArith为自编的根据系数及输出数据量化位数计算
%IIR滤波器输出的函数
Quant = QuantIIR(Qb,Qa,delta,Qcoe,Qout);
%求滤波器输出幅频响应
Fy=20*log10(abs(fft(y))); Fy=Fy-max(Fy);
FQuant=20*log10(abs(fft(Quant))); FQuant=FQuant-max(FQuant);
%设置幅频响应的横坐标单位为Hz
x_f=[0:(fs/length(delta)):fs-1];
figure(2);
plot(x_f,Fy,’-‘,x_f,FQuant,’.’);
axis([0 fs/2 -100 5]); %只显示正频率部分的幅频响应
xlabel(‘频率(Hz)’);ylabel(‘幅度(dB)’);
legend(‘理想输出’,’量化后输出结果’);
grid on;
(2)产生激励信号用作仿真
这里产生频率分别为:80KHz,10MHz,20MHz的三个正弦波叠加,对它做14bit量化,并以二进制存入txt文件中。在modelsim仿真时,读取txt文件的数据作为设计输入。
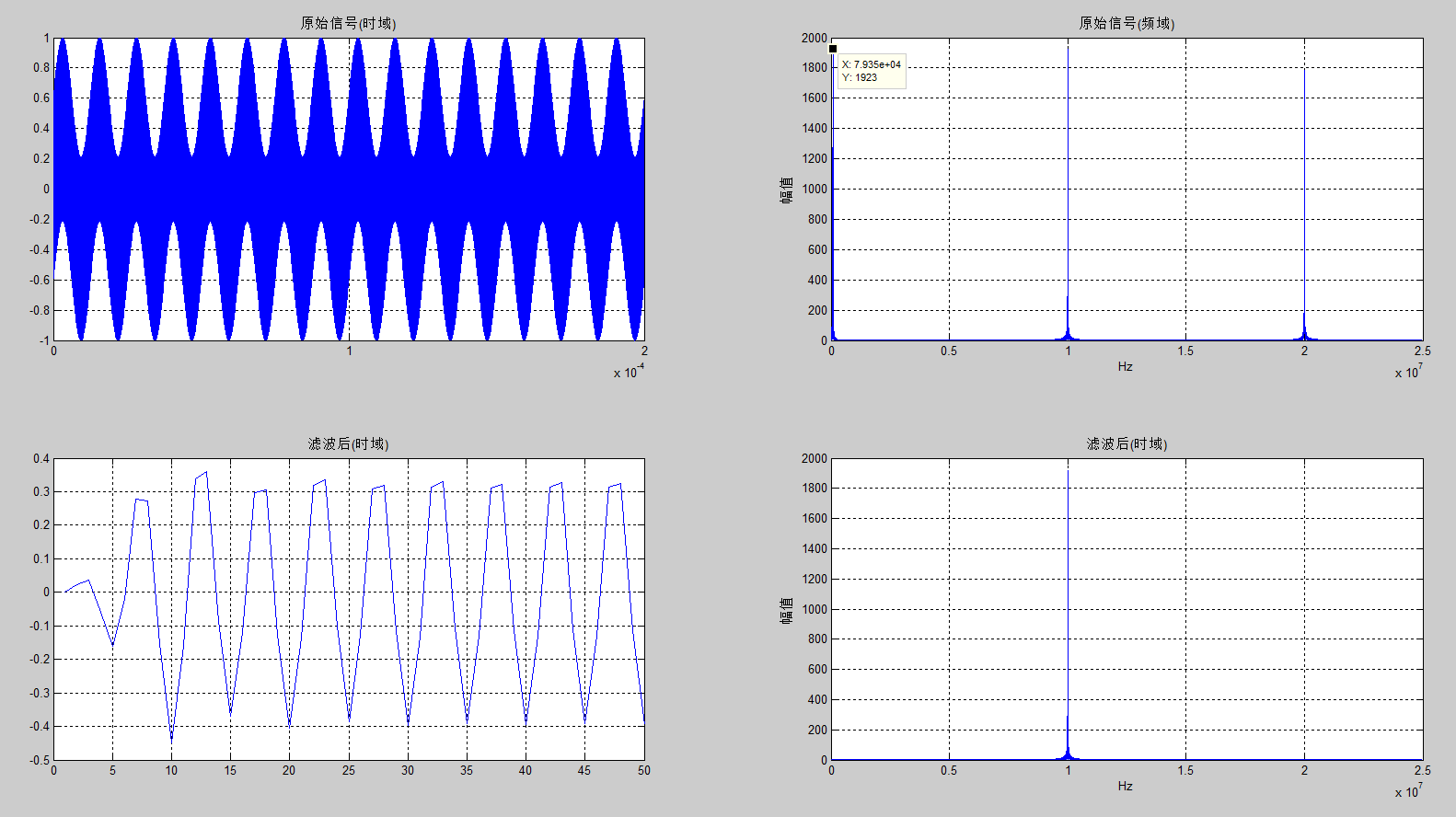
图4 激励信号
文件:test_signal_produce.m
clc;
clear all;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%变量声明区
f1 = 80e3; %80KHz
f2 = 12e6; %12MHz
f3 = 20e6; %20MHz
fs = 50e6; %采样频率50MHz
data_num = 10000; %存10000个数据
width = 8; %输入数据量化位宽
len = 2^nextpow2(data_num); %fft长度
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%数据产生区
t = (0:data_num-1)/fs;
x = sin(2*pi*f1*t) + sin(2*pi*f2*t) + sin(2*pi*f3*t);
x = x/max(abs(x)); %归一化
Q_x = round(x*(2^(width-1)-1)); %量化
fft_x = fft(x,len);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%将数据以二进制形式写入txt文件
fid = fopen(‘C:\Users\lidong\Desktop\iir_bpf\Matlab\xin.txt’,’w+’);
for i=1:length(Q_x)
x_bit = dec2bin(Q_x(i)+(Q_x(i)<0)*2^width,width);
for j=1:width
if x_bit(j) == ‘1’
tb = 1;
else
tb = 0;
end
fprintf(fid,’%d’,tb);
end
fprintf(fid,’\n’);
end
fprintf(fid,’;’);
fclose(fid);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%滤波器
fs = 50e6; %采样频率
fc1 = 2.6e6;
fc2 = 19.3e6;
N = 5; %5阶
Rp = 60;%阻带衰减
Wn = [2*fc1/fs 2*fc2/fs];%截止频率
[b,a] = cheby2(N,Rp,Wn);
f = fs*(0:len/2 - 1)/len;
filter_x = filter(b,a,x);
y = fft(filter_x,len);
subplot(2,2,1);
plot(t,x);
title(‘原始信号(时域)’);
grid on;
subplot(2,2,2);
plot(f,abs(fft_x(1:len/2)));
title(‘原始信号(频域)’);
xlabel(‘Hz’);ylabel(‘幅值’);
grid on;
subplot(2,2,3);
plot(filter_x(1:200));
title(‘滤波后(时域)’);
grid on;
subplot(2,2,4);
plot(f,abs(y(1:len/2)));
title(‘滤波后(时域)’);
xlabel(‘Hz’);ylabel(‘幅值’);
grid on;
(3)根据直接型框图编写verilog程序
文件:iir_bpf.v
/*******************************************************************************************************************************************************
模块名:iir_bpf
功能:实现通带为5-15MHz,阻带衰减为60dB的5阶IIR带通滤波器(采样频率为50MHz),采用切比雪夫II型函数设计
参数:clk为模块的时钟,50MHz;rst_n是模块的复位信号,低电平有效,异步复位;xin是模块输入,位宽14bit;yout是滤波后的输出,也是14bit。
滤波器量化后的系数(13bits量化)为:
分子b = [38 -20 -131 27 230 0 -230 -27 131 20 -38]
分母a = [1024 -2337 3127 -3241 3071 -2227 1268 -587 238 -60 9]
时间:2016.3.26
作者:冬瓜
Email:lidong10280528@163.com
*******************************************************************************************************************************************************/
module iir_bpf
(
input wire clk, //FPGA时钟50MHz
input wire rst_n, //复位信号,低电平有效
input wire [ 13:0 ] xin, // 数据输入
output reg [ 13:0 ] yout // 滤波后的数据输出
);
//
//变量声明区
reg signed[ 13:0 ] xin_r1,xin_r2,xin_r3,xin_r4,xin_r5;
reg signed[ 13:0 ] xin_r6,xin_r7,xin_r8,xin_r9,xin_r10,xin_r11;
reg signed[ 13:0 ] yin_r1,yin_r2,yin_r3,yin_r4,yin_r5;
reg signed[ 13:0 ] yin_r6,yin_r7,yin_r8,yin_r9,yin_r10,yin_r11;
wire signed[ 26:0 ] xmult_w0,xmult_w1,xmult_w2,xmult_w3,xmult_w4;
wire signed[ 26:0 ] xmult_w5,xmult_w6,xmult_w7,xmult_w8,xmult_w9,xmult_w10;
wire signed[ 26:0 ] ymult_w1,ymult_w2,ymult_w3,ymult_w4,ymult_w5;
wire signed[ 26:0 ] ymult_w6,ymult_w7,ymult_w8,ymult_w9,ymult_w10;
wire signed[ 30:0 ] feedforward;
wire signed[ 30:0 ] feedback;
wire signed[ 31:0 ] ysum;
wire signed[ 31:0 ] ydiv;
wire signed[ 13:0 ] yin;
wire signed [12:0 ] coeb[10:0]; //滤波器系数,分子b
wire signed [12:0 ] coea[10:0]; //滤波器系数,分母a
assign coea[0] = 13’d1024;
assign coea[1] = -13’d2337;
assign coea[2] = 13’d3127;
assign coea[3] = -13’d3241;
assign coea[4] = 13’d3071;
assign coea[5] = -13’d2227;
assign coea[6] = 13’d1268;
assign coea[7] = -13’d587;
assign coea[8] = 13’d238;
assign coea[9] = -13’d60;
assign coea[10] = 13’d9;
assign coeb[0] = 13’d38;
assign coeb[1] = -13’d20;
assign coeb[2] = -13’d131;
assign coeb[3] = 13’d27;
assign coeb[4] = 13’d230;
assign coeb[5] = 13’d0;
assign coeb[6] = -13’d230;
assign coeb[7] = -13’d27;
assign coeb[8] = 13’d131;
assign coeb[9] = 13’d20;
assign coeb[10] = -13’d38;
//
always @(posedge clk or negedge rst_n)
if (rst_n == 1’b0) //初始化寄存器
begin
xin_r1 <= ‘d0;
xin_r2 <= ‘d0;
xin_r3 <= ‘d0;
xin_r4 <= ‘d0;
xin_r5 <= ‘d0;
xin_r6 <= ‘d0;
xin_r7 <= ‘d0;
xin_r8 <= ‘d0;
xin_r9 <= ‘d0;
xin_r10 <= ‘d0;
xin_r11 <= ‘d0;
end
else
begin
xin_r1 <= xin;
xin_r2 <= xin_r1;
xin_r3 <= xin_r2;
xin_r4 <= xin_r3;
xin_r5 <= xin_r4;
xin_r6 <= xin_r5;
xin_r7 <= xin_r6;
xin_r8 <= xin_r7;
xin_r9 <= xin_r8;
xin_r10 <= xin_r9;
xin_r11 <= xin_r10;
end
//分子b = [38 -20 -131 27 230 0 -230 -27 131 20 -38]
mult14x13 mult14x13_instb1 (
.dataa ( xin ),
.datab ( coeb[0] ),
.result ( xmult_w0 )
);
mult14x13 mult14x13_instb2 (
.dataa ( xin_r1 ),
.datab ( coeb[1] ),
.result ( xmult_w1 )
);
mult14x13 mult14x13_instb3 (
.dataa ( xin_r2 ),
.datab ( coeb[2] ),
.result ( xmult_w2 )
);
mult14x13 mult14x13_instb4 (
.dataa ( xin_r3 ),
.datab ( coeb[3] ),
.result ( xmult_w3 )
);
mult14x13 mult14x13_instb5 (
.dataa ( xin_r4 ),
.datab ( coeb[4] ),
.result ( xmult_w4 )
);
mult14x13 mult14x13_instb6 (
.dataa ( xin_r5 ),
.datab ( coeb[5] ),
.result ( xmult_w5 )
);
mult14x13 mult14x13_instb7 (
.dataa ( xin_r6 ),
.datab ( coeb[6] ),
.result ( xmult_w6 )
);
mult14x13 mult14x13_instb8 (
.dataa ( xin_r7 ),
.datab ( coeb[7] ),
.result ( xmult_w7 )
);
mult14x13 mult14x13_instb9 (
.dataa ( xin_r8 ),
.datab ( coeb[8] ),
.result ( xmult_w8 )
);
mult14x13 mult14x13_instb10 (
.dataa ( xin_r9 ),
.datab ( coeb[9] ),
.result ( xmult_w9 )
);
mult14x13 mult14x13_instb11 (
.dataa ( xin_r10 ),
.datab ( coeb[10] ),
.result ( xmult_w10 )
);
/
//计算总的零点系数
always @(posedge clk or negedge rst_n)
if( rst_n == 1’b0)
feedforward <= ‘d0;
else
feedforward <= {{4{xmult_w0[26]}},xmult_w0} + {{4{xmult_w1[26]}},xmult_w1} + {{4{xmult_w2[26]}},xmult_w2} + {{4{xmult_w3[26]}},xmult_w3} +
{{4{xmult_w4[26]}},xmult_w4} + {{4{xmult_w5[26]}},xmult_w5} + {{4{xmult_w6[26]}},xmult_w6} + {{4{xmult_w7[26]}},xmult_w7} +
{{4{xmult_w8[26]}},xmult_w8} + {{4{xmult_w9[26]}},xmult_w9} + {{4{xmult_w10[26]}},xmult_w10};
//
always @(posedge clk or negedge rst_n)
if (rst_n == 1’b0 )
begin //初始化寄存器
yin_r1 <= ‘d0;
yin_r2 <= ‘d0;
yin_r3 <= ‘d0;
yin_r4 <= ‘d0;
yin_r5 <= ‘d0;
yin_r6 <= ‘d0;
yin_r7 <= ‘d0;
yin_r8 <= ‘d0;
yin_r9 <= ‘d0;
yin_r10 <= ‘d0;
yin_r11 <= ‘d0;
end
else
begin
yin_r1 <= yin;
yin_r2 <= yin_r1;
yin_r3 <= yin_r2;
yin_r4 <= yin_r3;
yin_r5 <= yin_r4;
yin_r6 <= yin_r5;
yin_r7 <= yin_r6;
yin_r8 <= yin_r7;
yin_r9 <= yin_r8;
yin_r10 <= yin_r9;
yin_r11 <= yin_r10;
end
//分母a = [1024 -2337 3127 -3241 3071 -2227 1268 -587 238 -60 9]
mult14x13 mult14x13_insta1 (
.dataa ( yin_r1 ),
.datab ( coea[1] ),
.result ( ymult_w1 )
);
mult14x13 mult14x13_insta2 (
.dataa ( yin_r2 ),
.datab ( coea[2] ),
.result ( ymult_w2 )
);
mult14x13 mult14x13_insta3 (
.dataa ( yin_r3 ),
.datab ( coea[3] ),
.result ( ymult_w3 )
);
mult14x13 mult14x13_insta4 (
.dataa ( yin_r4 ),
.datab ( coea[4] ),
.result ( ymult_w4 )
);
mult14x13 mult14x13_insta5 (
.dataa ( yin_r5 ),
.datab ( coea[5] ),
.result ( ymult_w5 )
);
mult14x13 mult14x13_insta6 (
.dataa ( yin_r6 ),
.datab ( coea[6] ),
.result ( ymult_w6 )
);
mult14x13 mult14x13_insta7 (
.dataa ( yin_r7 ),
.datab ( coea[7] ),
.result ( ymult_w7 )
);
mult14x13 mult14x13_insta8 (
.dataa ( yin_r8 ),
.datab ( coea[8] ),
.result ( ymult_w8 )
);
mult14x13 mult14x13_insta9 (
.dataa ( yin_r9 ),
.datab ( coea[9] ),
.result ( ymult_w9 )
);
mult14x13 mult14x13_insta10 (
.dataa ( yin_r10 ),
.datab ( coea[10] ),
.result ( ymult_w10 )
);
//计算总的极点系数
assign feedforward = {{4{xmult_w0[26]}},xmult_w0} + {{4{xmult_w1[26]}},xmult_w1} + {{4{xmult_w2[26]}},xmult_w2} + {{4{xmult_w3[26]}},xmult_w3} +
{{4{xmult_w4[26]}},xmult_w4} + {{4{xmult_w5[26]}},xmult_w5} + {{4{xmult_w6[26]}},xmult_w6} + {{4{xmult_w7[26]}},xmult_w7} +
{{4{xmult_w8[26]}},xmult_w8} + {{4{xmult_w9[26]}},xmult_w9} + {{4{xmult_w10[26]}},xmult_w10};
/
//计算最后的输出
assign ysum = {{{feedforward[30]}},feedforward} - {{feedback[30]},feedback};//31bits
assign ydiv = {{10{ysum[30]}},ysum[30:10]};
assign yin = ydiv[ 13:0 ];
//
//最后结果加一级寄存器,提高系统频率
always @(posedge clk)
yout <= ydiv[ 13:0 ];
///
endmodule
(4)Modelsim仿真
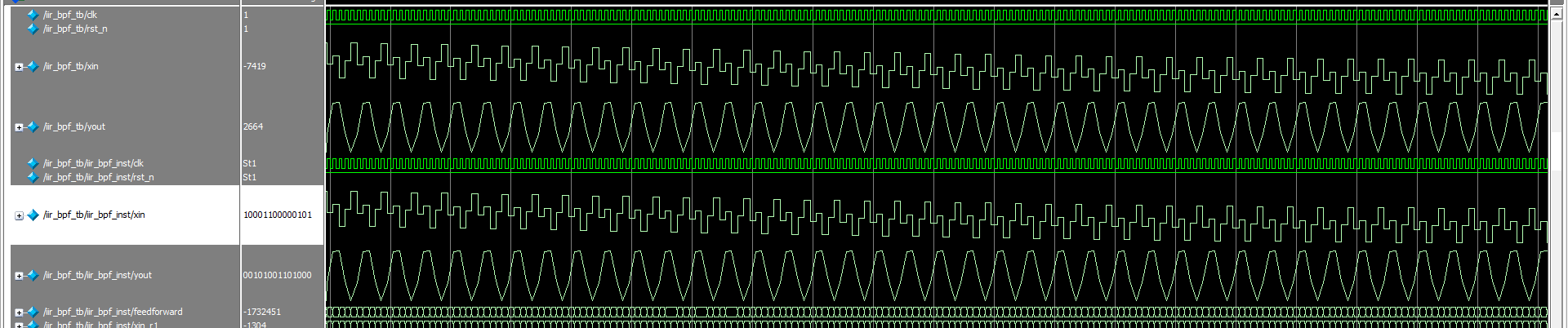
编写激励文件iir_bpf_tb.v和脚本文件run.do,并新建工程,在命令窗运行run.do文件。如图5,图6输入数据(xin)为多个正弦波叠加,经过滤波器后,输出(yout)为单一的正弦波,运行完后Modelsim会把输出数据存储在txt文件中给Matlab分析。
文件:iir_bpf_tb.v
`timescale 1 ns/1 ns
module iir_bpf_tb();
///
//变量声明区
parameter clk_period = 20; //50MHz
parameter half_clk_period = clk_period/2;
parameter data_num = 10000;
parameter time_sim = data_num*clk_period;
integer i;
integer fid;
reg clk;
reg rst_n;
reg [7:0 ] xin;
reg [7:0 ] stimulus[1:data_num];
wire clk_write;
wire signed [13:0] yout;
///
//产生时钟和复位信号
initial
begin
clk = 0;
rst_n = 0;
#400;
rst_n = 1;
#time_sim stop;
end
always #half_clk_period clk = ~clk;
///
//读取文件数据,作为滤波器输入
initial
beginreadmemb(“xin.txt”,stimulus);
i = 0;
#350;
repeat(data_num)
begin
i = i + 1;
@(posedge clk);
xin = stimulus[i];
end
end
///
//将滤波器输出数据存入文件中,给Matlab分析
initial
begin
fid =
fopen(“yout.txt”);if(!fid)begin
display(“Cannot open the file!”);
$finish;
end
end
always @(posedge clk_write)
$fdisplay(fid,”%d”,yout);
assign clk_write = rst_n & clk;
///
//例化
iir_bpf iir_bpf_inst
(
.clk (clk), //FPGA时钟50MHz
.rst_n (rst_n), //复位信号,低电平有效
.xin (xin), // 数据输入
.yout (yout) // 滤波后的数据输出
);
///
endmodule
文件:run.do
quit -sim
.main clear
vlib work
vmap work work
vlog ./iir_bpf_tb.v
vlog ./altera_lib/*.v
vlog ./../quartus_prj/ipcore_dir/mult8x16.v
vlog ./../quartus_prj/ipcore_dir/mult16x16.v
vlog ./../design/*.v
vsim -voptargs=+acc -L work work.iir_bpf_tb
add wave -divider { tb }
add wave iir_bpf_tb/*
add wave -divider { iir_bpf }
add wave iir_bpf_tb/iir_bpf_inst/*
run 50us
(5)Matlab仿真
用Matlab读取Modelsim产生的txt文件中的数据,如图7,滤波器输出数据的频谱为单一的10MHz的正弦波信号。
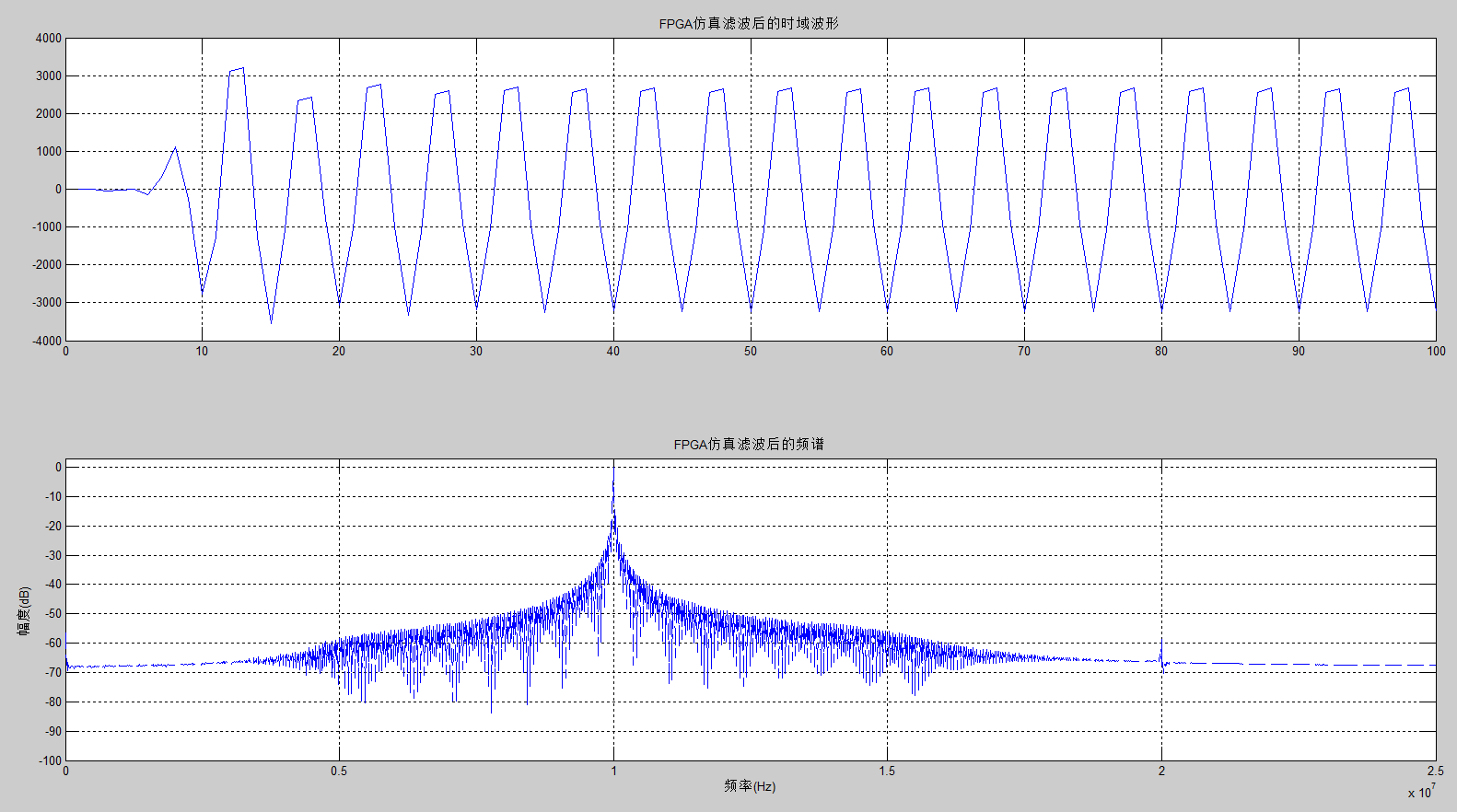
图7 Matlab仿真
文件:filter_analysis.m
clc;
clear all;
fs = 50e6;
%打开文件,并读取数据
fid_out = fopen(‘C:\Users\lidong\Desktop\iir_bpf\sim\yout.txt’,’r’);
[yout,N_out] = fscanf(fid_out,’%d’,inf);
fclose(fid_out);
%画时域波形
subplot(211);
plot(yout(1:100));
title(‘FPGA仿真滤波后的时域波形’);
grid on;
%归一化处理
NFFT2 = 2^nextpow2(N_out);
yout=yout/max(abs(yout));
Fout=20*log10(abs(fft(yout,NFFT2)));
Fout=Fout-max(Fout);
%画频域波形
subplot(212);
x_f=[0:(fs/length(Fout)):fs/2];
plot(x_f,Fout(1:length(x_f)),’–’);
axis([0 fs/2 -100 3]);
xlabel(‘频率(Hz)’);ylabel(‘幅度(dB)’);title(‘FPGA仿真滤波后的频谱’);
grid on;
4.遇到的问题及解决方案
(1)进行Modelsim仿真时,极点有关的寄存器以及输出均为未知状态x
解决方案:出现未知状态的原因是:开始输入数据的时间控制不对,必须在复位结束前把数据输入进来,例如复位时间是400ns,如果是在400ns之后数据输入就会导致这样的现象

图8 复位时间
图9 数据输入时间
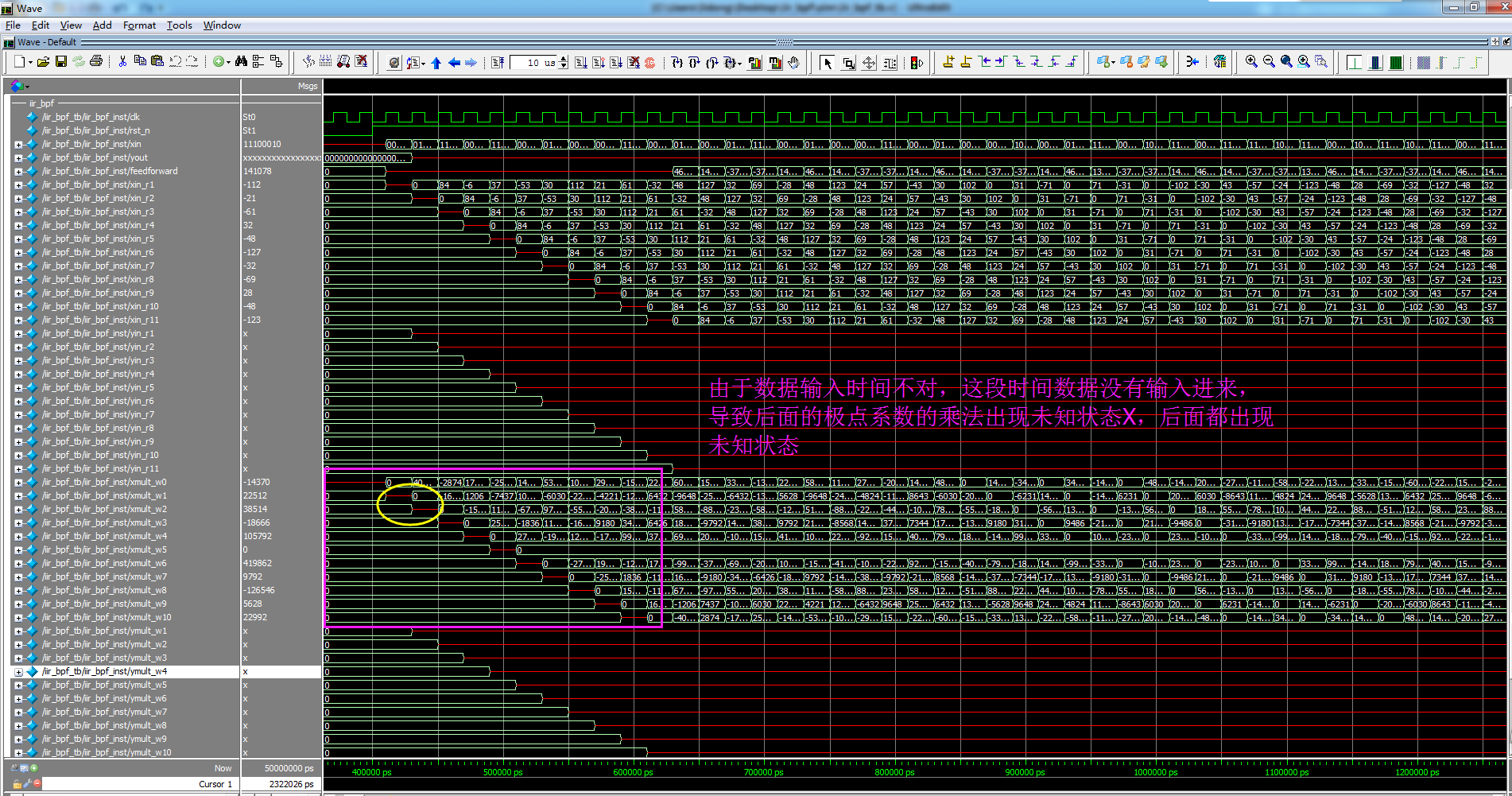
图10 出现仿真问题
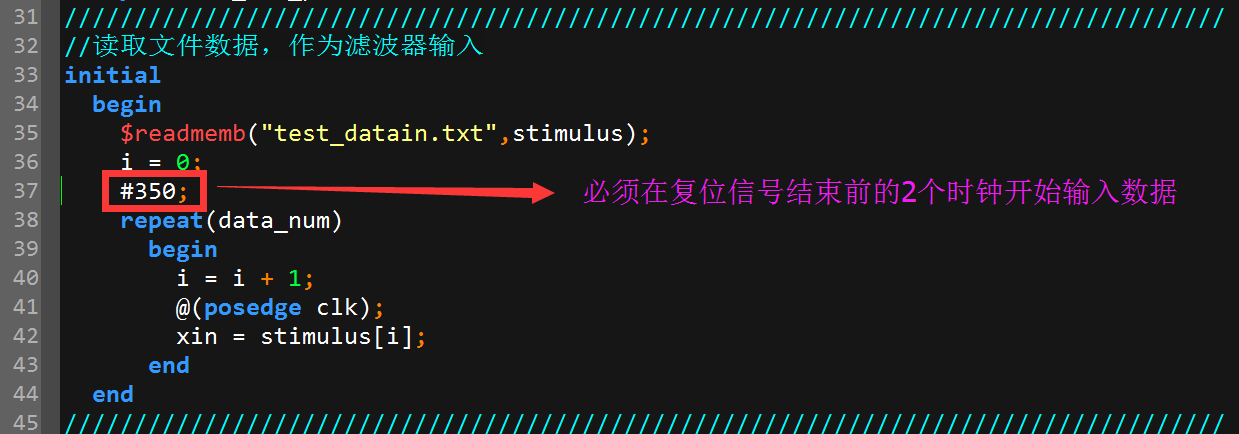
图11 修改输入数据开始时间
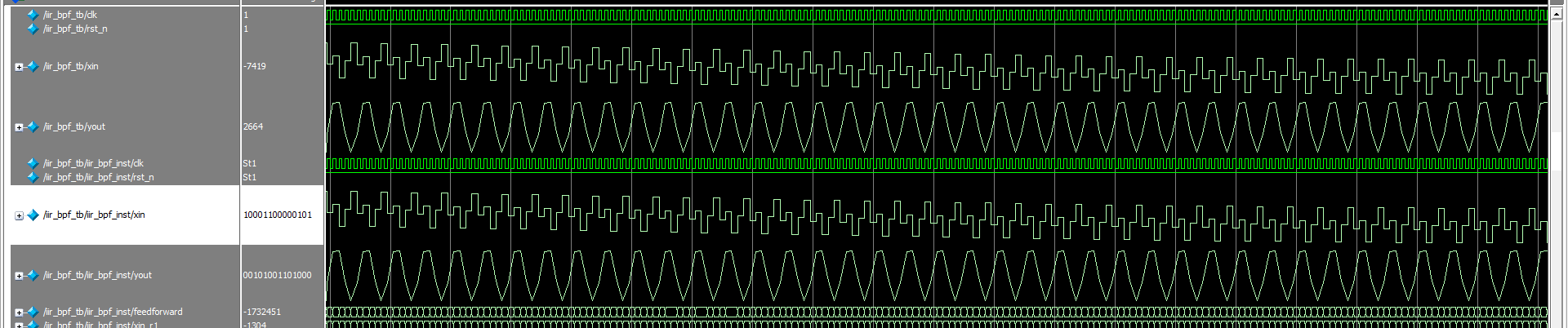
图12 正常仿真
(2)用Matlab对modelsim的输出仿真时,出现谐波和直流分量
解决方案:出现谐波的原因是:modelsim输出的数据(yout)不为signed型,可以在matlab仿真时,先检查文件中数据的时域波形,再看频域。
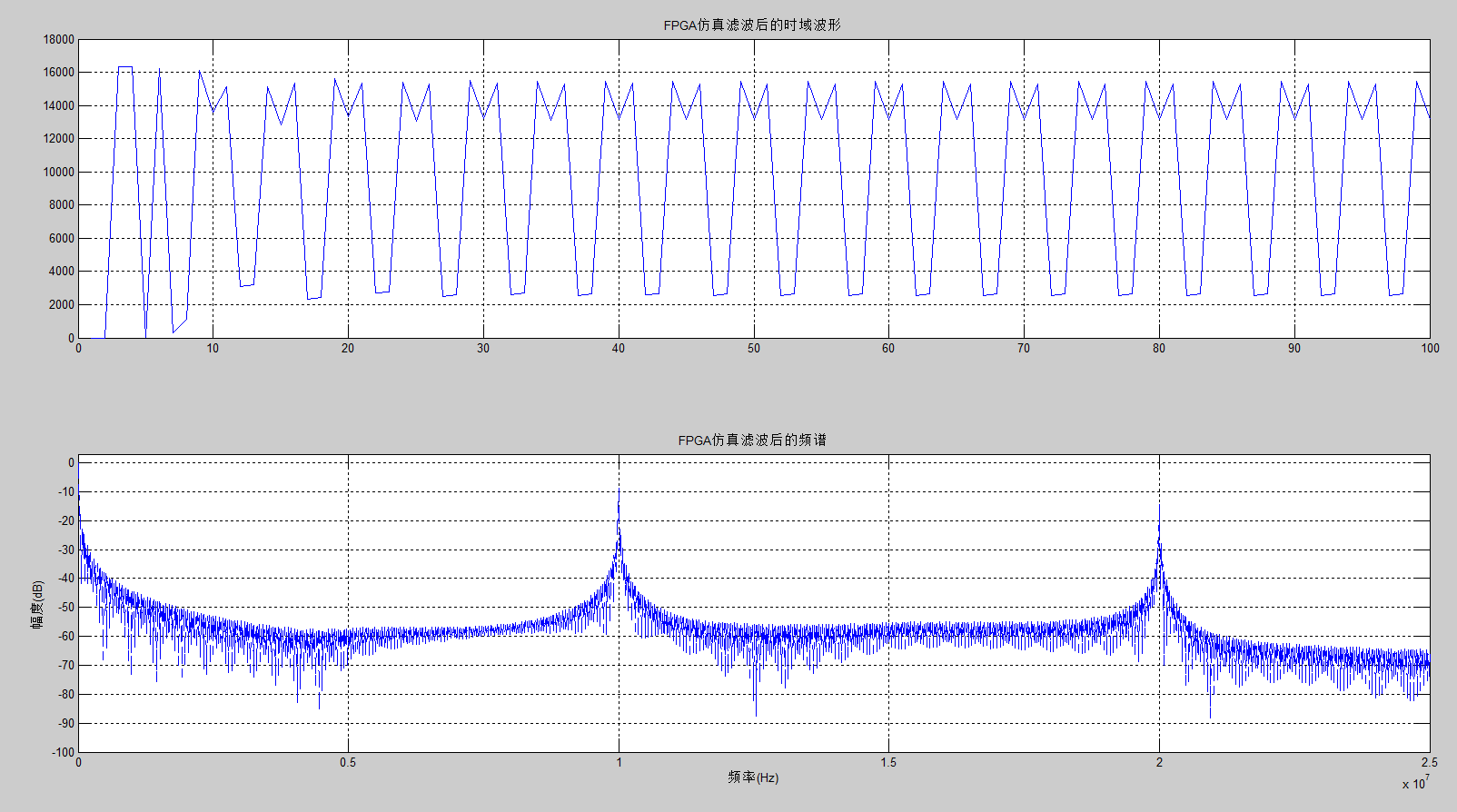
图13
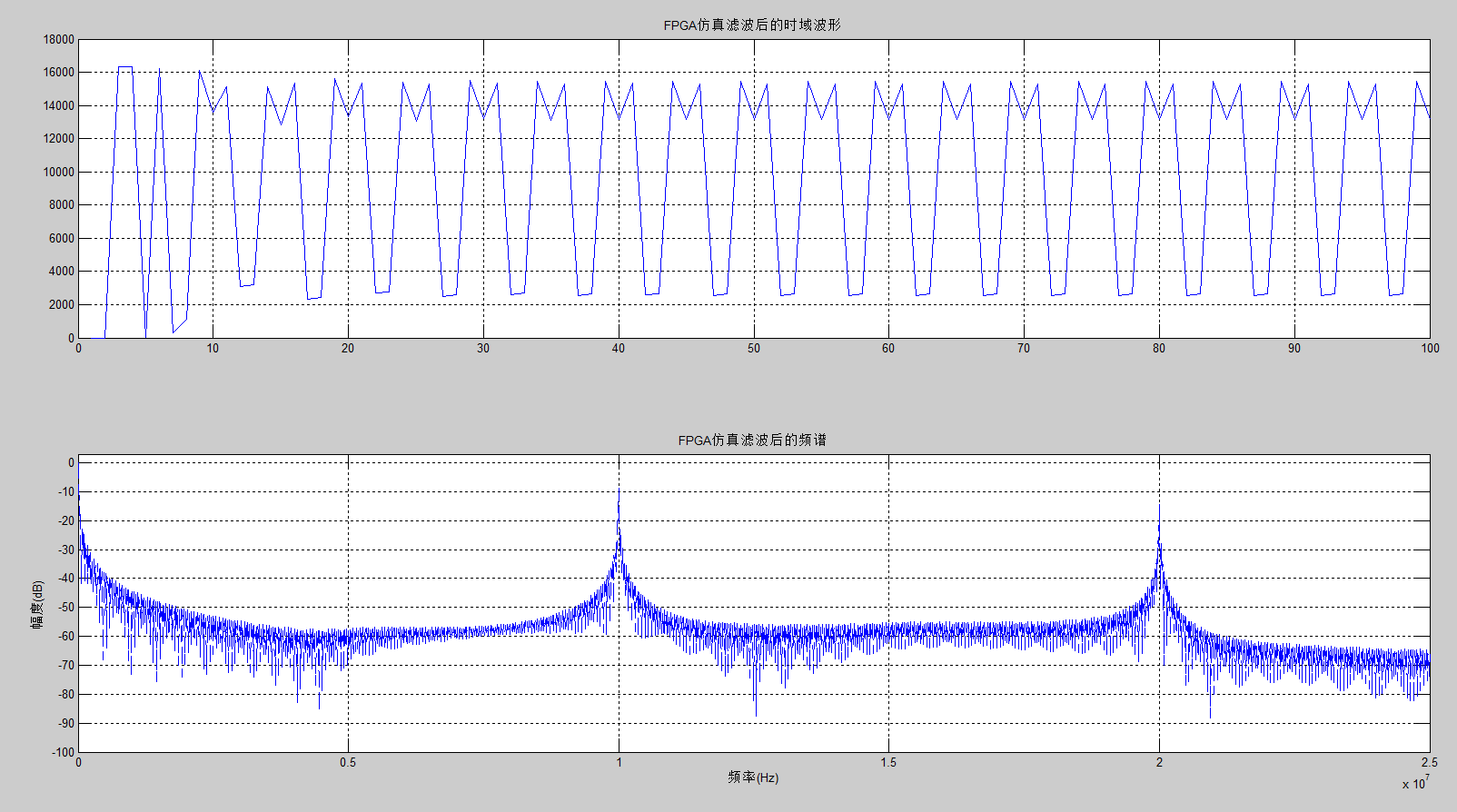
图14 Matlab仿真出错
5.系统优化
(1)在计算feedforward时,添加寄存器。对于一个FPGA时序电路来讲,决定整个电路运算速度是单个时钟周期内逻辑运算最多的环节。在上述程序中,完成一次完整的IIR滤波,需要10次常系数乘法运算,1次10输入的加减法运算和一次一位运算。显然一个时钟周期的逻辑运算量太大,因此在计算ysum之前,增加一级寄存器,相当于输入数据进行一个时钟周期的延迟,不影响滤波的结果。但在运算速度上,相当于原来1个周期的运算量采用两个时钟周期完成。
(2)乘法运算后的位宽可以优化1bit,因为位宽分别为N,M的两数据相乘,结果位宽是不超过M+N,而且只有在输入数据的最高位为1,其余位位0时,才会为(M+N)bit宽。因此用(M+N-1)bit表示输出结果时,相当于用-2^M + 1对 -2^M进行近似处理。
(3)可以用移位与加法运算代替乘法运算,例如系数为238时,如图15,但有些可能有多种移位方案,如图16,3071有两种方案,但显然方案2要优于方案1,因为方案2的加法运算级数更少。
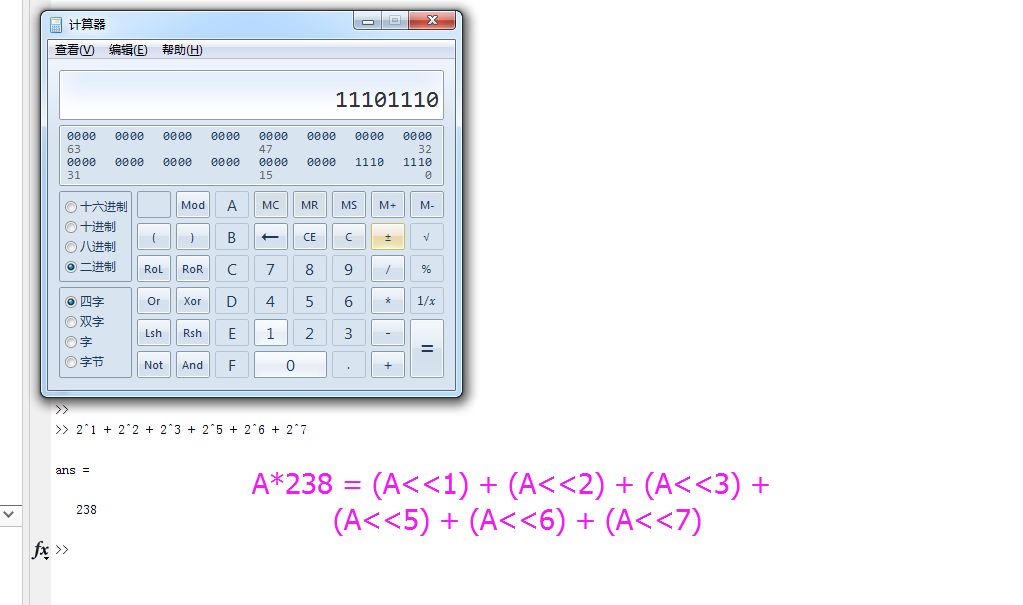
图15 乘法优化
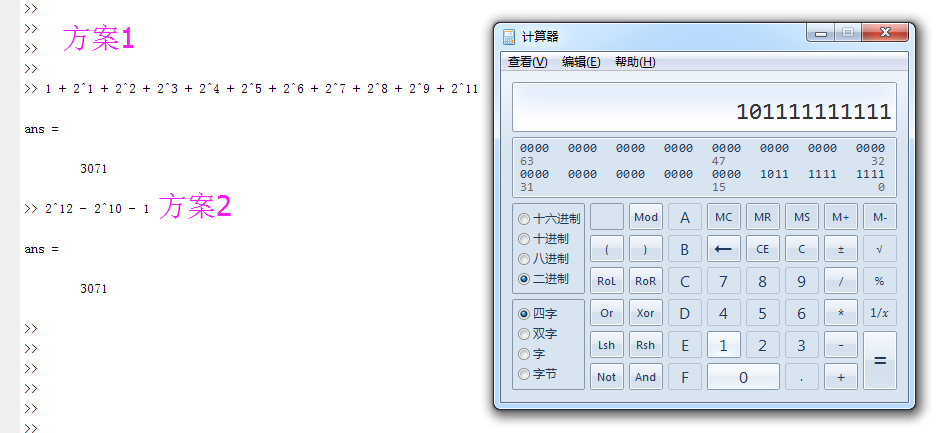
图16
技巧:通过移位和累加代替乘法限制了滤波器系数的灵活性,而且编程时比较头疼。总结一下经验(以编写yin_r4*3071为例):
先确定好几个数:assign ymult_w4 = {yin_r4,12’d0} + {yin_r4,12’d0} + {yin_r4,12’d0};
确定好前面的符号是加号还是减号:assign ymult_w4 = {yin_r4,12’d0} - {yin_r4,12’d0} - {yin_r4,12’d0};
确定拼接后面的数:assign ymult_w4 = {yin_r4,12’d0} - {yin_r4,10’d0} - {yin_r4,1’d0};
根据总位宽和输入位宽确定符号位扩展多少:assign ymult_w4 = {yin_r4,12’d0} - {{2{yin_r4[13]}},yin_r4,10’d0} - {{12{yin_r4[13]}},yin_r4};这里ymult_w* 位宽是26bit,而yin_r*是14bit,因此只需要移的位数(yin_r*右边的数)和扩展的符号位数(yin_r*左边的数)之和为26-14 = 12就行,后面计算 ymult_w5, ymult_w6。。。都是一样的。解皮带,绕大树。另外,在优化时也出现了错误,经过对比优化前后仿真图,找到了ymult_w1,ymult_w3移位算错了,从而定位到了a(1),a(3)移位移错了。


(b)优化后
图17
(4)加法的优化。在得到feedback时,需要做9次加法,如果直接用连加,则这些加法器会一级一级的级联,组合逻辑延时太长。例如assign x = a + b + c +d + e + f;可以这样优化
assign x1 = a + b;
assign x2 = c+ d;
assign x3 = e+ f;
assign x4 = x1+ x2;
assign x = x3+ x4;
优化前后分别对应图18,图19。可以看出优化前数据要经过5个加法器,优化后只过3个加法器。
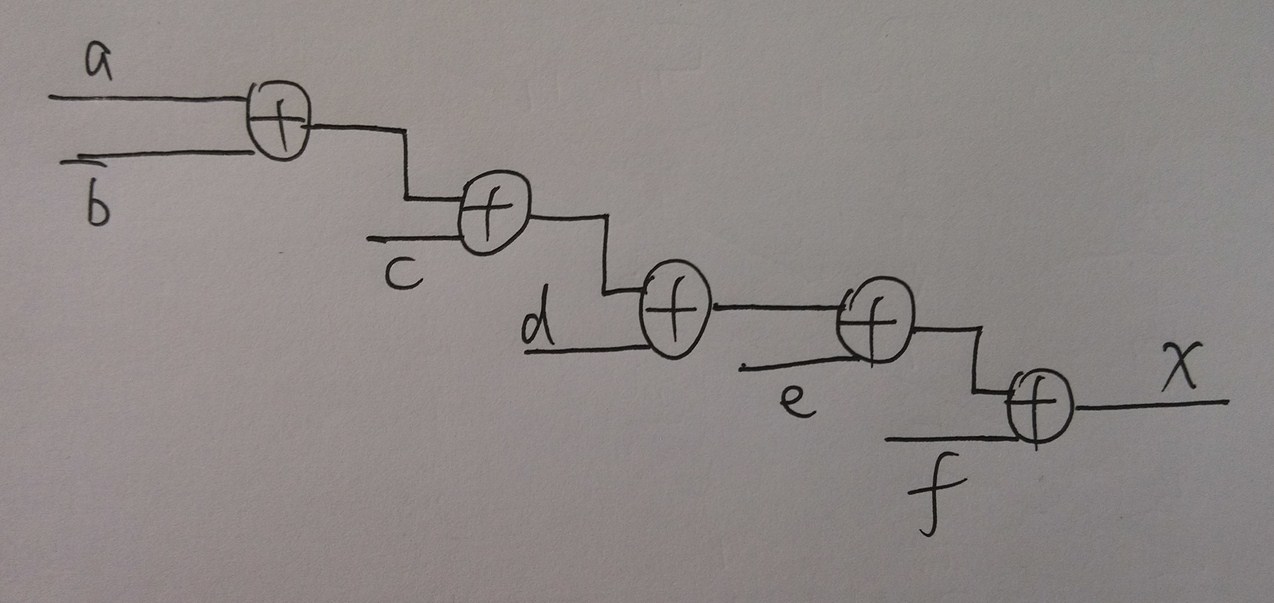
图18 优化前
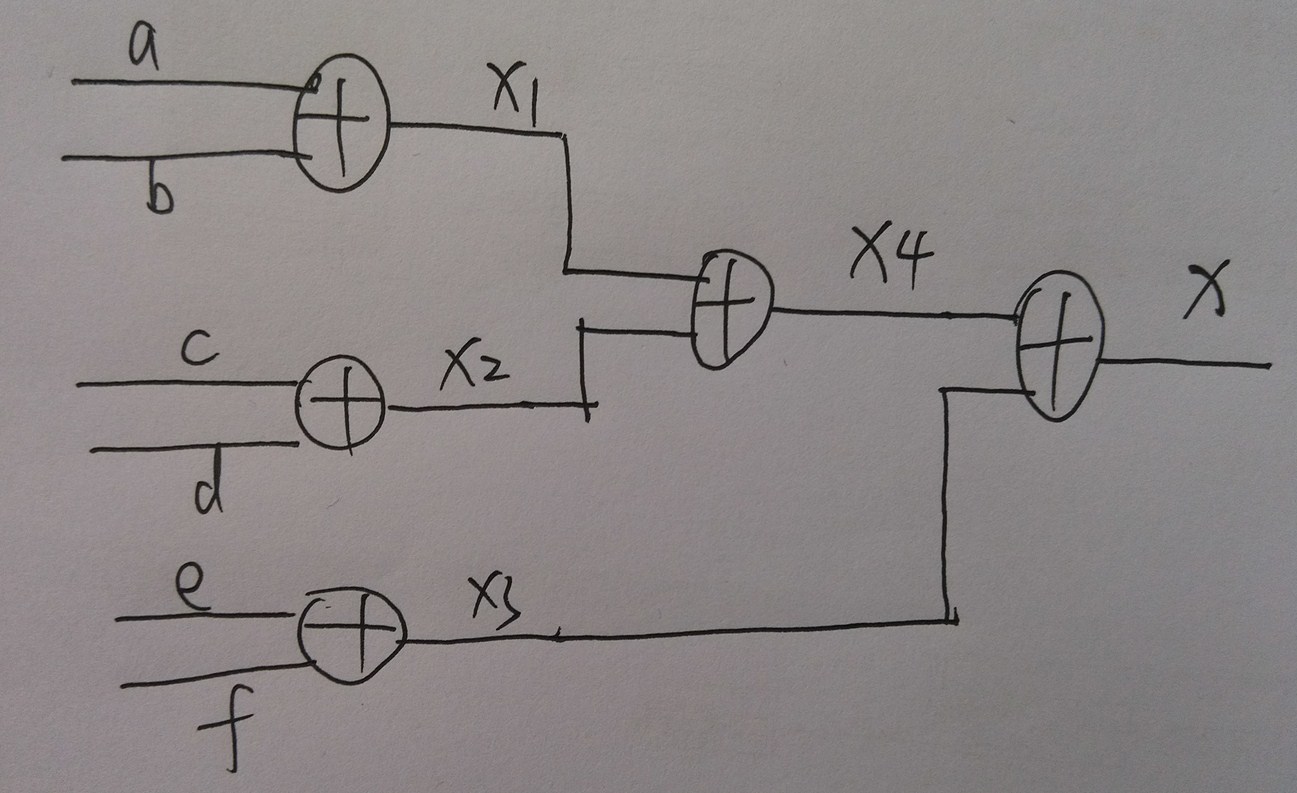
(5)由于本例采用cheby2型的IIR滤波器,分子b具有对称性,因此可以先做加/减法运算,再做乘法运算,可以节约一半乘法。例如b(1) = -b(10) = 38那么先做减法add1 = (xin_r1 - xin_r10 ),再算乘法38*add1,即可减少一次乘法。
优化前后资源对比,虽然优化后会占用多一点的逻辑资源,但优化前的乘法器用去了91%的乘法器,而优化后是0%。如图20,如图21,22,优化后功能并没有改变。
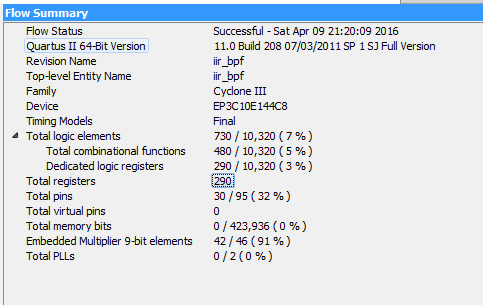
(a) 优化前
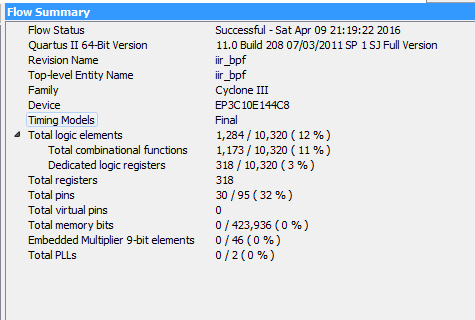
图20 优化前后资源对比

图21
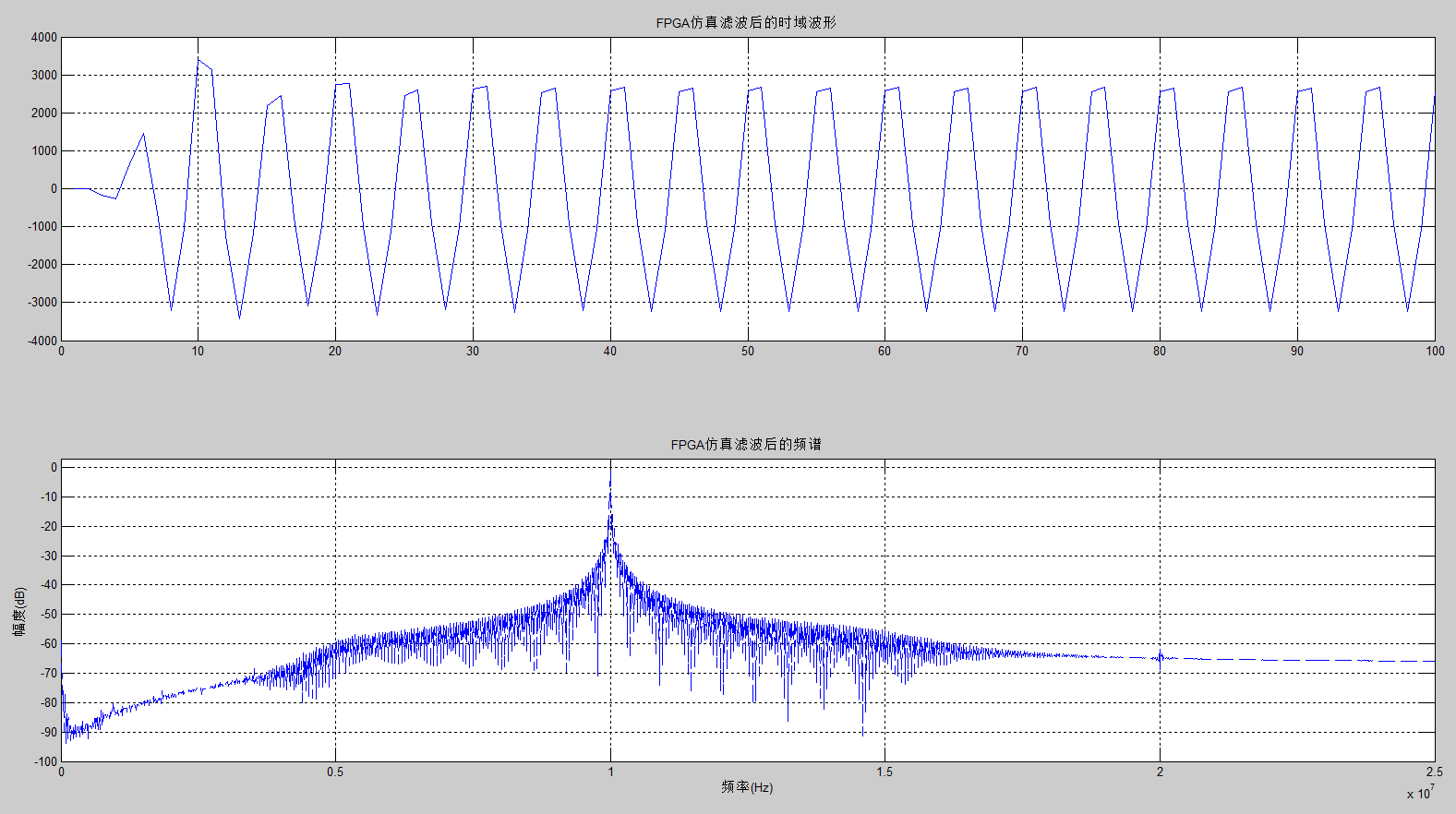
图22
//优化后
/********************************************************************************
模块名:iir_bpf
功能:实现通带为5-15MHz,阻带衰减为60dB的5阶IIR带通滤波器(采样频率为50MHz),采用切比雪夫II型函数设计
时间:2016.3.26
作者:冬瓜
Email:lidong10280528@163.com
********************************************************************************/
module iir_bpf
(
input wire clk, //FPGA时钟50MHz
input wire rst_n, //复位信号,低电平有效
input wire [ 13:0 ] xin, // 数据输入
output reg [ 13:0 ] yout // 滤波后的数据输出
);
//
//变量声明区
reg signed[ 30:0 ] feedforward;
reg signed[ 13:0 ] xin_r1,xin_r2,xin_r3,xin_r4,xin_r5;
reg signed[ 13:0 ] xin_r6,xin_r7,xin_r8,xin_r9,xin_r10;
reg signed[ 13:0 ] yin_r1,yin_r2,yin_r3,yin_r4,yin_r5;
reg signed[ 13:0 ] yin_r6,yin_r7,yin_r8,yin_r9,yin_r10;
wire signed[ 14:0 ] xadd0,xadd1,xadd2,xadd3,xadd4;
wire signed[ 25:0 ] xmult_w0,xmult_w1,xmult_w2,xmult_w3,xmult_w4;
wire signed[ 25:0 ] ymult_w1,ymult_w2,ymult_w3,ymult_w4,ymult_w5;
wire signed[ 25:0 ] ymult_w6,ymult_w7,ymult_w8,ymult_w9,ymult_w10;
wire signed[ 25:0 ] ymult_w1_1,ymult_w1_2;
wire signed[ 25:0 ] ymult_w2_1,ymult_w2_2;
wire signed[ 25:0 ] ymult_w3_1,ymult_w3_2;
wire signed[ 25:0 ] ymult_w5_1,ymult_w5_2;
wire signed[ 25:0 ] ymult_w6_1,ymult_w6_2;
wire signed[ 25:0 ] ymult_w7_1,ymult_w7_2;
wire signed[ 30:0 ] feedback;
wire signed[ 30:0 ] feedback1,feedback2,feedback3,feedback4;
wire signed[ 30:0 ] feedback5,feedback6,feedback7,feedback8;
wire signed[ 30:0 ] feedforward1,feedforward2,feedforward3;
wire signed[ 31:0 ] ysum;
wire signed[ 31:0 ] ydiv;
wire signed[ 13:0 ] yin;
//
always @(posedge clk or negedge rst_n)
if (rst_n == 1’b0) //初始化寄存器
begin
xin_r1 <= ‘d0;
xin_r2 <= ‘d0;
xin_r3 <= ‘d0;
xin_r4 <= ‘d0;
xin_r5 <= ‘d0;
xin_r6 <= ‘d0;
xin_r7 <= ‘d0;
xin_r8 <= ‘d0;
xin_r9 <= ‘d0;
xin_r10 <= ‘d0;
end
else
begin
xin_r1 <= xin;
xin_r2 <= xin_r1;
xin_r3 <= xin_r2;
xin_r4 <= xin_r3;
xin_r5 <= xin_r4;
xin_r6 <= xin_r5;
xin_r7 <= xin_r6;
xin_r8 <= xin_r7;
xin_r9 <= xin_r8;
xin_r10 <= xin_r9;
end
//分子b = [38 -20 -131 27 230 0 -230 -27 131 20 -38]
//系数具有对称性,因此先做减法,再做乘法,节约一半乘法器
assign xadd0 = {xin[13],xin} - {xin_r10[13],xin_r10}; //15bits
assign xadd1 = {xin_r1[13],xin_r1} - {xin_r9[13],xin_r9};
assign xadd2 = {xin_r2[13],xin_r2} - {xin_r8[13],xin_r8};
assign xadd3 = {xin_r3[13],xin_r3} - {xin_r7[13],xin_r7};
assign xadd4 = {xin_r4[13],xin_r4} - {xin_r6[13],xin_r6};
//用移位与加法运算代替乘法运算
assign xmult_w0 = {{10{xadd0[14]}},xadd0,1’d0} + {{9{xadd0[14]}},xadd0,2’d0} + {{6{xadd0[14]}},xadd0,5’d0}; //26bit
assign xmult_w1 = -{{9{xadd1[14]}},xadd1,2’d0} - {{7{xadd1[14]}},xadd1,4’d0}; //26bit
assign xmult_w2 = -{{11{xadd2[14]}},xadd2} - {{10{xadd2[14]}},xadd2,1’d0} - {{4{xadd2[14]}},xadd2,7’d0}; //26bit
assign xmult_w3 = {{6{xadd3[14]}},xadd3,5’d0} - {{11{xadd3[14]}},xadd3} - {{9{xadd3[14]}},xadd3,2’d0}; //26bit
assign xmult_w4 = {{3{xadd4[14]}},xadd4,8’d0} - {{10{xadd4[14]}},xadd4,1’d0} - {{8{xadd4[14]}},xadd4,3’d0} - {{7{xadd4[14]}},xadd4,4’d0};//26bit
///
//由于加法的级数太长,对其拆分,减少组合逻辑延时,提高系统的Fmax
assign feedforward1 = {{4{xmult_w0[25]}},xmult_w0} + {{4{xmult_w1[25]}},xmult_w1};
assign feedforward2 = {{4{xmult_w2[25]}},xmult_w2} + {{4{xmult_w3[25]}},xmult_w3};
assign feedforward3 = {{4{xmult_w4[25]}},xmult_w4} + feedforward1;
///
//计算总的零点系数
always @(posedge clk or negedge rst_n)
if( rst_n == 1’b0)
begin
feedforward <= ‘d0;
end
else
begin
feedforward <= feedforward2 + feedforward3;
end
always @(posedge clk or negedge rst_n)
if (rst_n == 1’b0 )
begin //初始化寄存器
yin_r1 <= ‘d0;
yin_r2 <= ‘d0;
yin_r3 <= ‘d0;
yin_r4 <= ‘d0;
yin_r5 <= ‘d0;
yin_r6 <= ‘d0;
yin_r7 <= ‘d0;
yin_r8 <= ‘d0;
yin_r9 <= ‘d0;
yin_r10 <= ‘d0;
end
else
begin
yin_r1 <= yin;
yin_r2 <= yin_r1;
yin_r3 <= yin_r2;
yin_r4 <= yin_r3;
yin_r5 <= yin_r4;
yin_r6 <= yin_r5;
yin_r7 <= yin_r6;
yin_r8 <= yin_r7;
yin_r9 <= yin_r8;
yin_r10 <= yin_r9;
end
///
//分母a = [1024 -2337 3127 -3241 3071 -2227 1268 -587 238 -60 9]
//用移位与加法运算代替乘法运算
//assign ymult_w1 = -{{12{yin_r1[13]}},yin_r1} - {{7{yin_r1[13]}},yin_r1,5’d0} - {{4{yin_r1[13]}},yin_r1,8’d0} -{{{yin_r1[13]}},yin_r1,11’d0};//26bits
//assign ymult_w2 = {{9{yin_r2[13]}},yin_r2,3’d0} + {{8{yin_r2[13]}},yin_r2,4’d0} + {{7{yin_r2[13]}},yin_r2,5’d0} + {{2{yin_r2[13]}},yin_r2,10’d0} + {{{yin_r2[13]}},yin_r2,11’d0} - {{12{yin_r2[13]}},yin_r2};//26bits
//assign ymult_w3 = -{{12{yin_r3[13]}},yin_r3} - {{9{yin_r3[13]}},yin_r3,3’d0} - {{7{yin_r3[13]}},yin_r3,5’d0} - {{5{yin_r3[13]}},yin_r3,7’d0} - {{2{yin_r3[13]}},yin_r3,10’d0} - {{yin_r3[13]},yin_r3,11’d0};//26bits
//assign ymult_w4 = {yin_r4,12’d0} - {{2{yin_r4[13]}},yin_r4,10’d0} - {{12{yin_r4[13]}},yin_r4}; //26bits
//assign ymult_w5 = -{{12{yin_r5[13]}},yin_r5} - {{11{yin_r5[13]}},yin_r5,1’d0} - {{8{yin_r5[13]}},yin_r5,4’d0} - {{7{yin_r5[13]}},yin_r5,5’d0} - {{5{yin_r5[13]}},yin_r5,7’d0} - {{yin_r5[13]},yin_r5,11’d0};//26bits
//assign ymult_w6 = {{2{yin_r6[13]}},yin_r6,10’d0} + {{4{yin_r6[13]}},yin_r6,8’d0} - {{10{yin_r6[13]}},yin_r6,2’d0} - {{9{yin_r6[13]}},yin_r6,3’d0}; //26bits
//assign ymult_w7 = -{{12{yin_r7[13]}},yin_r7} - {{11{yin_r7[13]}},yin_r7,1’d0} - {{9{yin_r7[13]}},yin_r7,3’d0} - {{6{yin_r7[13]}},yin_r7,6’d0} - {{3{yin_r7[13]}},yin_r7,9’d0};//26bits
//assign ymult_w8 = {{4{yin_r8[13]}},yin_r8,8’d0} - {{11{yin_r8[13]}},yin_r8,1’d0} - {{8{yin_r8[13]}},yin_r8,4’d0}; //26bits
//assign ymult_w9 = {{10{yin_r9[13]}},yin_r9,2’d0} - {{6{yin_r9[13]}},yin_r9,6’d0}; //26bits
//assign ymult_w10 = {{12{yin_r10[13]}},yin_r10} + {{9{yin_r10[13]}},yin_r10,3’d0};
assign ymult_w1_1 = -{{12{yin_r1[13]}},yin_r1} - {{7{yin_r1[13]}},yin_r1,5’d0};//26bits
assign ymult_w1_2 = -{{4{yin_r1[13]}},yin_r1,8’d0} - {{{yin_r1[13]}},yin_r1,11’d0};
assign ymult_w1 = ymult_w1_1 + ymult_w1_2;
assign ymult_w2_1 = {{9{yin_r2[13]}},yin_r2,3’d0} + {{8{yin_r2[13]}},yin_r2,4’d0} + {{7{yin_r2[13]}},yin_r2,5’d0};
assign ymult_w2_2 = {{2{yin_r2[13]}},yin_r2,10’d0} + {{{yin_r2[13]}},yin_r2,11’d0} - {{12{yin_r2[13]}},yin_r2};
assign ymult_w2 = ymult_w2_1 + ymult_w2_2;//26bits
assign ymult_w3_1 = -{{12{yin_r3[13]}},yin_r3} - {{9{yin_r3[13]}},yin_r3,3’d0} - {{7{yin_r3[13]}},yin_r3,5’d0};
assign ymult_w3_2 = -{{5{yin_r3[13]}},yin_r3,7’d0} - {{2{yin_r3[13]}},yin_r3,10’d0} - {{yin_r3[13]},yin_r3,11’d0};
assign ymult_w3 = ymult_w3_1 + ymult_w3_2; //26bits
assign ymult_w4 = {yin_r4,12’d0} - {{2{yin_r4[13]}},yin_r4,10’d0} - {{12{yin_r4[13]}},yin_r4}; //26bits
assign ymult_w5_1 = -{{12{yin_r5[13]}},yin_r5} - {{11{yin_r5[13]}},yin_r5,1’d0} - {{8{yin_r5[13]}},yin_r5,4’d0};
assign ymult_w5_2 = -{{7{yin_r5[13]}},yin_r5,5’d0} - {{5{yin_r5[13]}},yin_r5,7’d0} - {{yin_r5[13]},yin_r5,11’d0};
assign ymult_w5 = ymult_w5_1 + ymult_w5_2; //26bits
assign ymult_w6_1 = {{2{yin_r6[13]}},yin_r6,10’d0} + {{4{yin_r6[13]}},yin_r6,8’d0};
assign ymult_w6_2 = -{{10{yin_r6[13]}},yin_r6,2’d0} - {{9{yin_r6[13]}},yin_r6,3’d0};
assign ymult_w6 = ymult_w6_1 + ymult_w6_2; //26bits
assign ymult_w7_1 = -{{12{yin_r7[13]}},yin_r7} - {{11{yin_r7[13]}},yin_r7,1’d0} - {{9{yin_r7[13]}},yin_r7,3’d0};
assign ymult_w7_2 = -{{6{yin_r7[13]}},yin_r7,6’d0} - {{3{yin_r7[13]}},yin_r7,9’d0};
assign ymult_w7 = ymult_w7_1 + ymult_w7_2; //26bits
assign ymult_w8 = {{4{yin_r8[13]}},yin_r8,8’d0} - {{11{yin_r8[13]}},yin_r8,1’d0} - {{8{yin_r8[13]}},yin_r8,4’d0}; //26bits
assign ymult_w9 = {{10{yin_r9[13]}},yin_r9,2’d0} - {{6{yin_r9[13]}},yin_r9,6’d0}; //26bits
assign ymult_w10 = {{12{yin_r10[13]}},yin_r10} + {{9{yin_r10[13]}},yin_r10,3’d0};
计算总的极点系数,由于加法的级数太长,对其拆分,减少组合逻辑延时,提高系统的Fmax
assign feedback1 = {{4{ymult_w1[25]}},ymult_w1} + {{4{ymult_w2[25]}},ymult_w2};
assign feedback2 = {{4{ymult_w3[25]}},ymult_w3} + {{4{ymult_w4[25]}},ymult_w4};
assign feedback3 = {{4{ymult_w5[25]}},ymult_w5} + {{4{ymult_w6[25]}},ymult_w6};
assign feedback4 = {{4{ymult_w7[25]}},ymult_w7} + {{4{ymult_w8[25]}},ymult_w8};
assign feedback5 = {{4{ymult_w9[25]}},ymult_w9} + {{4{ymult_w10[25]}},ymult_w10};
assign feedback6 = feedback1 + feedback2;
assign feedback7 = feedback3 + feedback4;
assign feedback8 = feedback6 + feedback7;
assign feedback = feedback5 + feedback8;
/
//计算最后的输出
assign ysum = {{{feedforward[30]}},feedforward} - {{feedback[30]},feedback};//31bits
assign ydiv = {{10{ysum[30]}},ysum[30:10]};
assign yin = ydiv[ 13:0 ];
/
//最后结果加一级寄存器,提高系统频率
always @(posedge clk)
yout <= ydiv[ 13:0 ];
/
endmodule















 2604
2604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











