






设计目标:
-(硬件故障是常态,而非偶然)自动快速检测应对硬件错误
-流式访问数据(数据批处理)
-转移计算比移动数据本身更划算(减少数据传输)
-简单的数据一致性模型(一次写入,多次读取的文件访问模型)
-异构平台可移植
HDFS体系结构

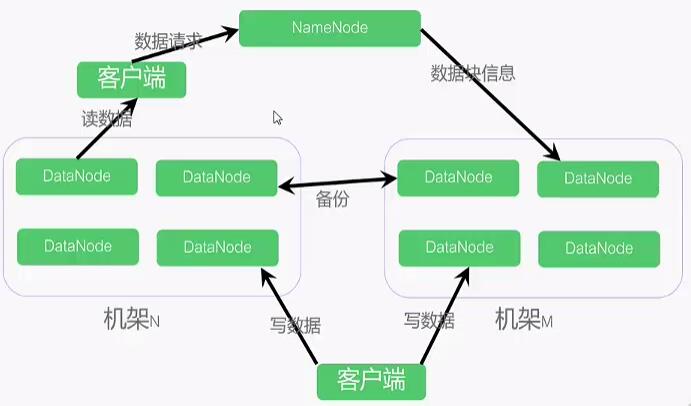
 Hadoop的HDFS设计目标包括处理硬件故障、流式数据访问和数据一致性。系统采用Master-Slave模式,NameNode作为中心服务器管理文件系统,而DataNode分布在全球各地存储并检索数据块。每个DataNode保存文件的3个副本,其中2个在同一机架,另一个在不同机架。元数据通过Fsimage和EditLog备份,NameNode结合两者更新内存中的元数据。HDFS使用TCP协议进行节点间通信,DataNode每3秒发送心跳,10次心跳后报告数据块信息。数据写入和读取流程涉及NameNode和DataNode的交互,确保数据可靠性和可用性。
Hadoop的HDFS设计目标包括处理硬件故障、流式数据访问和数据一致性。系统采用Master-Slave模式,NameNode作为中心服务器管理文件系统,而DataNode分布在全球各地存储并检索数据块。每个DataNode保存文件的3个副本,其中2个在同一机架,另一个在不同机架。元数据通过Fsimage和EditLog备份,NameNode结合两者更新内存中的元数据。HDFS使用TCP协议进行节点间通信,DataNode每3秒发送心跳,10次心跳后报告数据块信息。数据写入和读取流程涉及NameNode和DataNode的交互,确保数据可靠性和可用性。
设计目标:
-(硬件故障是常态,而非偶然)自动快速检测应对硬件错误
-流式访问数据(数据批处理)
-转移计算比移动数据本身更划算(减少数据传输)
-简单的数据一致性模型(一次写入,多次读取的文件访问模型)
-异构平台可移植
HDFS体系结构
 1241
1703
1241
1703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















