







 博客探讨了推荐系统中如何根据用户行为分析计算相似度,涉及基于用户的协同过滤和基于物品的协同过滤。介绍了三种相似度计算方法:同现相似度、欧式距离相似度和余弦相似度,用于衡量用户或物品间的偏好匹配程度。
博客探讨了推荐系统中如何根据用户行为分析计算相似度,涉及基于用户的协同过滤和基于物品的协同过滤。介绍了三种相似度计算方法:同现相似度、欧式距离相似度和余弦相似度,用于衡量用户或物品间的偏好匹配程度。
对用户的行为进行分析得到用户的偏好后,可以根据用户的偏好计算相似用户和物品,然后可以基于相似用户或物品进行推荐。这就是协同过滤中的两个分支了,即基于用户的协同过滤和基于物品的协同过滤。
关于相似度的计算,现有的几种方法都是基于向量(Vector)的,其实也就是计算两个向量的距离,距离越近相似度越大。在推荐场景中,在用户-物品偏好的二维矩阵中,我们可以将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,或者将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度。
1.同现相似度
计算公式为:
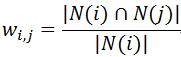
分母|N(i)|是喜欢物品
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









