







原文:https://my.oschina.net/yjwxh/blog/620368
目前zeppelin最新版本是0.5.6,http://zeppelin.incubator.apache.org/
zepplin是 apache孵化器中的一个项目,但是由于其提供的简单,易操作的web版交互式以及可视化分析工具,也较为受欢迎。
本文就先简单介绍 zeppelin on spark的应用。
下载、安装zeppelin
zeppelin的启动 $ZEPPELIN_HOME/bin/zeppelin-dameon.sh start , 默认端口8080,启动成功后即可在浏览器访问:

Zeppelin在构建的时候就默认将spark构建在了项目内部,因此在启动zeppelin后,会自动注入SparkContext, SparkSQL实例。默认情况下zeppelin会以本地模式启用其内部自带的spark环境,如果你想使用自己部署的spark集群,那么就需要做一些简单的配置:
- 添加SPARK_HOME环境变量,在zeppelin安装文件conf/zeppelin-env.sh文件中添加 export SPARK_HOME=$spark_home_path
- 在启动起来的zeppelin web界面的interpreter菜单下,设置spark master属性。该属性的设置规则是:
-
- local[*] in local mode
- spark://master:7077 in standalone cluster
- yarn-client in Yarn client mode
- mesos://host:5050 in Mesos cluster
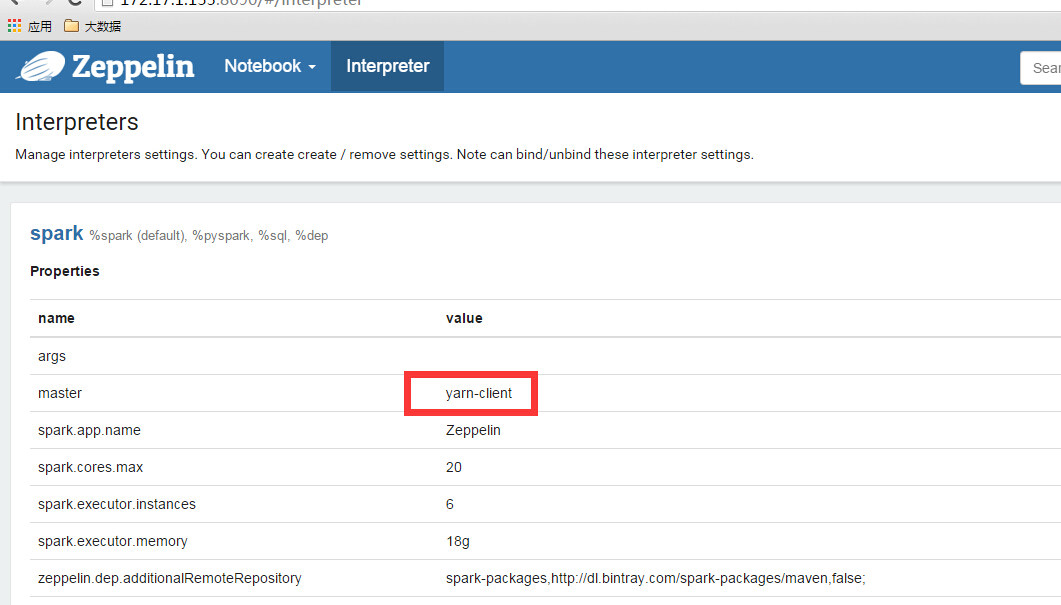
OK ,完成以上配置之后,就可以重新启动zeppelin,并创建一个新的Notebook, 来测试spark,
因为zeppelin默认情况下是提供spark上下文环境,所以在编写spark代码的时候,不需要加%spark,
首先通过一个 sc.version 来查看spark版本, 注意:默认情况下zeppelin启动成功以后,并没有将spark启动,只有当有spark的操作请求的时候,才会开始启动,所以在第一次执行spark请求的时候会比较慢。

如果执行结果显示出了spark的版本信息,那么就说明与spark后端执行引擎对接成功了。
在此再额外补充一个可能出现的问题,因为我在第一次尝试的时候就出现了,当我执行sc.version的时候报异常:
com.fasterxml.jackson.databind.JsonMappingException: Could not find creator property with name 'id' (in class org.apache.spark.rdd.RDDOperationScope)冲突原因:zeppelin 0.5.6使用的jackson版本是2.5.3 ,而spark1.6使用的jackson版本是2.4.4,所以导致json解析的时候异常。
该问题的解决方法就是: 删除zeppelin安装文件下lib文件夹中jackson-*2.5.3.jar, 将jackson2.4.4版本的jar包复制到该文件夹下。进行替换。
重启zeppelin,该问题即可解决。
zeppelin on spark环境已经配置完成,那么接下来的工作就是 执行spark应用,然后使用zeppelin查看统计分析结果,当然目前用的比较方便的还是spark sql ,下面给出基于zeppelin on spark分析结果展示。

总结: Zeppelin是一个比较让人惊喜的发现,在发现他之前对于spark的分析结果,我们一般都是通过命令行的方式来查询,如果要给用户或者别人演示结果,那就更麻烦了,要不就将就的看看后端命令行结果,要不你就写个简单的web ui来进行结果展示。 这样又会带来一些问题,每次一个新的需求模型过来都要重新编程,每次一些小的参数变动都要修改代码。带来了极大的不方便。 但是自从有了zeppelin,这些问题都能够很好的解决,并且不用再担心数据分析结果的展示问题,也为分析统计的测试带来很大的方便。
当然Zeppelin目前还处于孵化器阶段也有不足的地方,例如一些动态表单的支持还比较少,目前仅仅有文本框和下拉框。
关于Zeppelin更多的功能还在慢慢探索中:
(1) 各种Interpreter的测试,自定义Interpreter的接入方式
(2) zeppelin丰富的展示系统
(3) zeppelin的更多使用场景挖掘等等。















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









