









1、bert4rec提出动机
用户行为动态变化,序列行为建模取得了不错的效果
单向结构限制了行为序列中隐藏信息的挖掘
序列神经网络顺序依赖,无法并行计算
为此,提出了
- 基于双向self-attention和Cloze task的用户行为序列建模方法。据我们所知,这是第一个将深度序列模型和Cloze task引入推荐系统的研究。
- 将我们的模型与最先进的方法进行了比较,并通过对四个基准数据集的定量分析,证明了本文算法的有效性。
- 我们进行了一项消融分析,分析了模型中关键部件的贡献。
2、bert4rec结构
2.1、推荐中行为序列建模的问题定义

2.2、模型的结构
2.2.1、模型整体结构
bert4rec整体架构如下图(b)所示,bert4rec是一个含有L层的transformer,每一层都可以利用上一层的信息,通过self-attention并行捕获任意位置的信息。
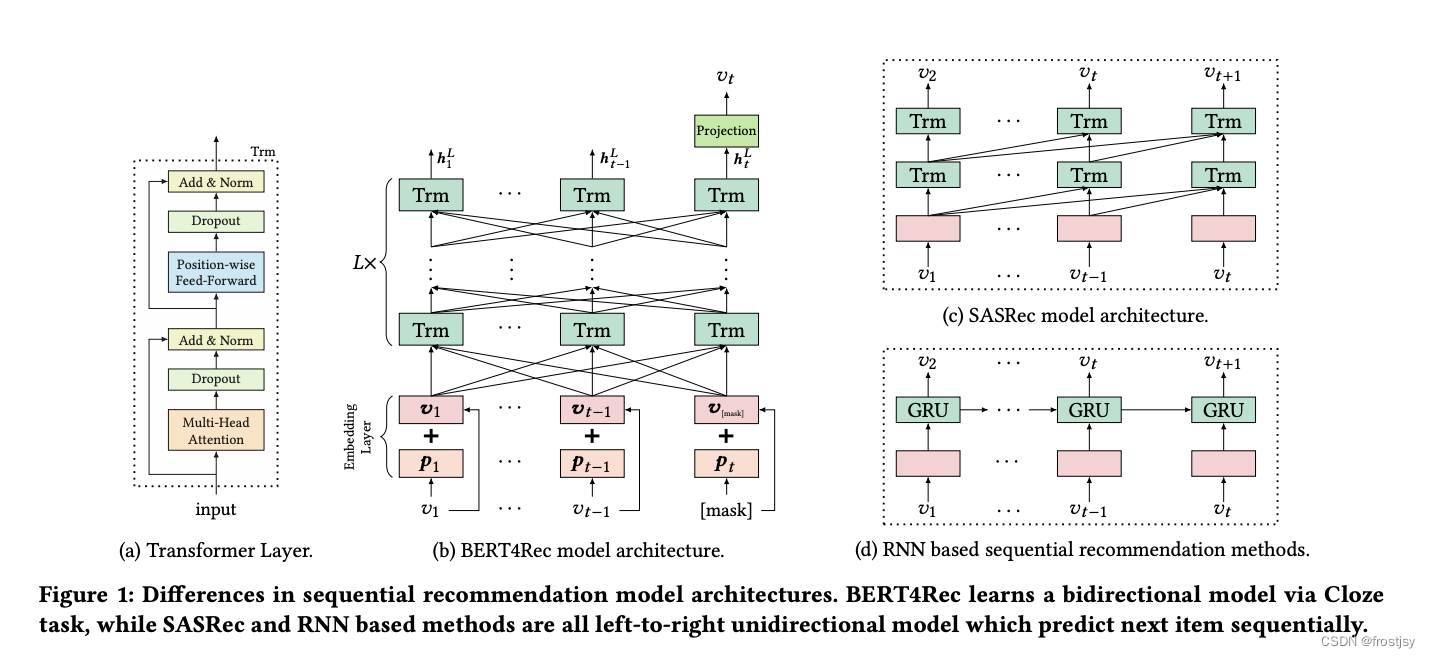
2.2.2、模型结构拆解
由上图(a)所示,bert4rec的transformer由multi-head self-attention和position-wise ffn构成。
2.2.2.1、Embedding layer
Embedding层加入了位置嵌入,本文的位置向量是学到的,不是transformer中的正弦。位置向量矩阵可以给定任意位置的向量,但是要明确最大的长度,因此需要对输入序列进行截断。
![]()
2.2.2.2、multi-head self-attention

引入温度 ![]() 以产生更柔和的注意力分布,以避免极小的梯度
以产生更柔和的注意力分布,以避免极小的梯度
2.2.2.3、position-wise FFN
由于只有线性映射,为了使得模型具有非线性的性质,所以采用了Position-wise Feed-Forward Network。Position-wise的意思是说,每个位置上的向量分别输入到前向神经网络中,计算方式如下:

最终的隐层向量表示为

2.2.2.4、 Output layer
全链接层的一个映射

3、模型训练
预测下一个item的表示形式
输入为 ![]() ,向右shift一个即得到下一个序列的预测
,向右shift一个即得到下一个序列的预测![]()
而在BERT4Rec中,由于是双向模型,每一个item的最终输出表示都包含了要预测物品的信息,这样就造成了一定程度的信息泄漏。因此采用Cloze taske,也就是将输入序列中的p%的物品进行masked,然后根据上下文信息预测masked的物品。
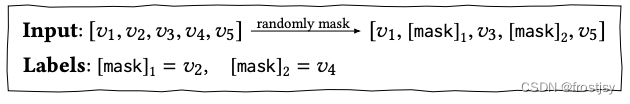
损失函数

4、实验对比
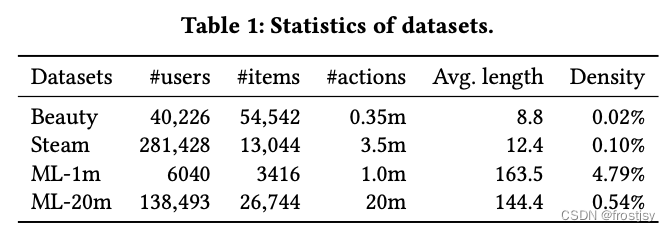
4.1、数据集
4.2、评价指标
在top-K推荐中,HR是一种常用的衡量召回率的指标,计算公式为:
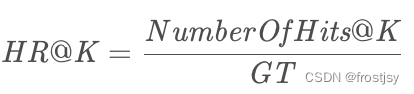
分母是所有的测试集合,分子表示每个用户top-K列表中属于测试集合的个数的总和。
举个简单的例子,三个用户在测试集中的商品个数分别是10,12,8,模型得到的top-10推荐列表中,分别有6个,5个,4个在测试集中,那么此时HR的值是
(6+5+4)/(10+12+8) = 0.5。
4.3、实验对比方法
POP:最简单的基线,根据ud统计信息来排序(受欢迎程度)。
BPR-MF [39]:它使用成对排序损失优化带有隐式反馈的矩阵分解。
NCF [12]:它在mlp中模拟用户与item交互,而不是矩阵分解中的内积。
FPMC [40]:它通过将 MF 与一阶 MC 相结合来捕捉用户的喜好及其行为序列。
GRU4Rec [15]:它使用 GRU 和基于排名的损失来建模 基于会话的推荐的用户序列。
GRU4Rec+ [14]:它是 GRU4Rec 的改进版本,具有一类新的损失函数和采样策略。
Caser [49]:它在水平和垂直方向都使用了 CNN 为顺序推荐建模高阶 MC 的方法。
SASRec [22]:它使用从左到右的 Transformer 语言 模型来捕获用户的顺序行为
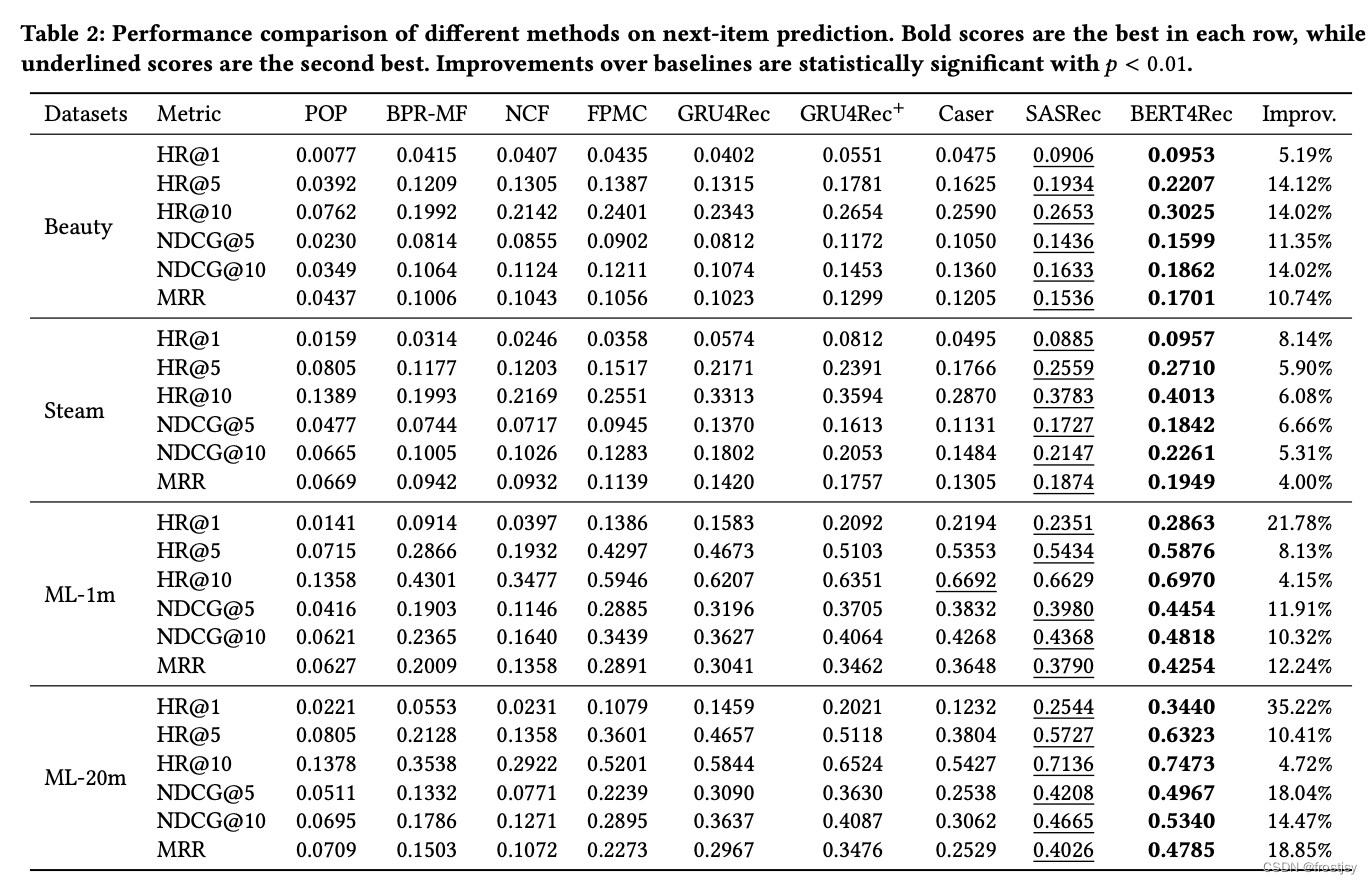
4.4、实验数据对比
不同数据集上效率指标的比较
双向transformer的影响
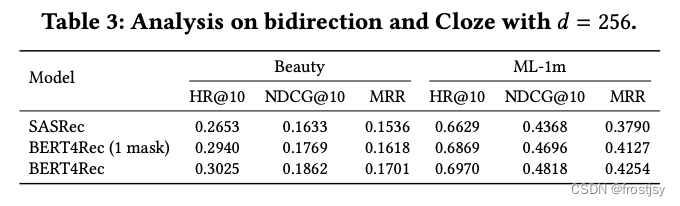
BERT4Rec (1 mask)表示每条序列中只mask一个词
序列最大长度对实验的影响

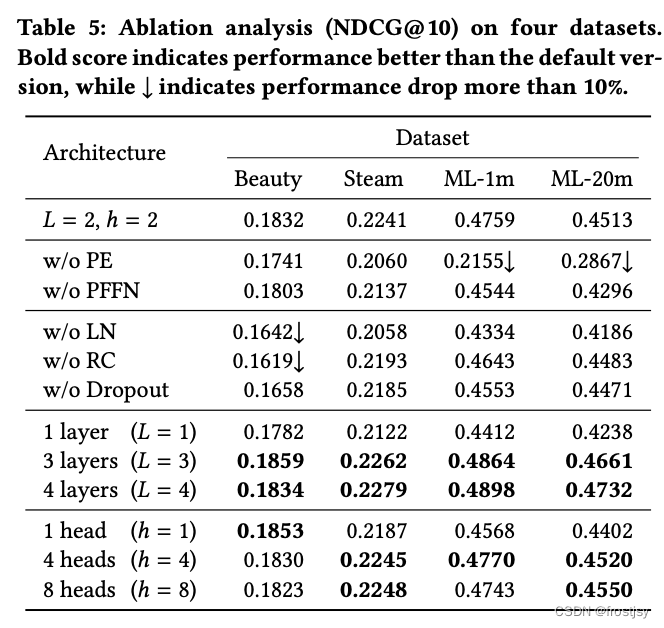
实验参数/结构对实验的影响
5、参考文档
BERT4Rec:使用Bert进行序列推荐 - 知乎 (BERT4Rec:使用Bert进行序列推荐)
https://arxiv.org/pdf/1904.06690.pdf (论文地址)
BERT4Rec:使用Bert进行序列推荐 - 知乎 (知乎 bert4rec)
https://arxiv.org/pdf/1904.06690.pdf (bert4rec论文)
Self-Attention与Transformer (Self-Attention与Transformer)
从Transformer到BERT模型 (从Transformer到BERT模型)
BERT模型精讲 (BERT模型精讲)
推荐算法常用评价指标:NDCG、MAP、MRR、HR、ILS、ROC、AUC、F1等_mrr和map计算f1_十三吖的博客-CSDN博客

















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









