






Flask项目之前端JavaScript动态解码后端多次Base64编码达到数据加密反爬虫的效果(Spider);
Q: 爬虫(Spdier)步骤解析?
1.数据爬取;
规则分析
2.数据提取;
规则匹配
3.数据存储;
数据清洗
Q: 反爬虫爬取方法技巧? (实际上提高了破解成本而已!)
1.数据加密反扒:在服务端对数据进行特定算法的加密, 在客户端利用JS进行动态输出解密(
如何保护前度解密文件是重点!);
Q: 我们为什么要用base64编码?
描述: 它是网络上最常见的用于传输8bit字节代码的编码方式之一, 采用base64编码具有不可读性即所编码的数据不会被人直接看出;
可将二进制数据编码为适合放在URL中的形式, 除此之外还可以放在请求头响应头进行传输
补充: Javascript 原生的 BASE64(ASCII) window.atob() 解码 与 window.btoa() 转码 但是他们并不支持中文的Base64编码需要下面自己写的 utf-8 decode 的实现;
Window.atob() # 函数用来解码一个已经被base-64编码过的数据。
window.btoa() # 将ascii字符串或二进制数据转换成一个base64编码过的字符串反扒开发流程:
(1) 前台数据采用渲染JS(
document.write)加密输出内容;(2) 前台加载JS文件进行解码后动态输出内容;
(3) 请求的JS解密文件被其它请求响应路径所替代,并设置有失效期1000毫秒;
项目实践
Spider Example Request
# Day3\Spider\SpiderReq.py
# coding: utf-8
import requests
from pprint import pprint
def get_data():
response = requests.get('http://127.0.0.1:8000/get/info')
pprint(response.content.decode('utf-8')) #pip install pprint
if __name__ == "__main__":
get_data()Javascript Base64 decode
<script type="text/javascript">
function BASE64() {
// private property
_keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
// public method for encoding
this.encode = function (input) {
var output = "";
var chr1, chr2, chr3, enc1, enc2, enc3, enc4;
var i = 0;
input = _utf8_encode(input);
while (i < input.length) {
chr1 = input.charCodeAt(i++);
chr2 = input.charCodeAt(i++);
chr3 = input.charCodeAt(i++);
enc1 = chr1 >> 2;
enc2 = ((chr1 & 3) << 4) | (chr2 >> 4);
enc3 = ((chr2 & 15) << 2) | (chr3 >> 6);
enc4 = chr3 & 63;
if (isNaN(chr2)) {
enc3 = enc4 = 64;
} else if (isNaN(chr3)) {
enc4 = 64;
}
output = output +
_keyStr.charAt(enc1) + _keyStr.charAt(enc2) +
_keyStr.charAt(enc3) + _keyStr.charAt(enc4);
}
return output;
}
// public method for decoding
this.decode = function (input) {
var output = "";
var chr1, chr2, chr3;
var enc1, enc2, enc3, enc4;
var i = 0;
input = input.replace(/[^A-Za-z0-9\+\/\=]/g, "");
while (i < input.length) {
enc1 = _keyStr.indexOf(input.charAt(i++));
enc2 = _keyStr.indexOf(input.charAt(i++));
enc3 = _keyStr.indexOf(input.charAt(i++));
enc4 = _keyStr.indexOf(input.charAt(i++));
chr1 = (enc1 << 2) | (enc2 >> 4);
chr2 = ((enc2 & 15) << 4) | (enc3 >> 2);
chr3 = ((enc3 & 3) << 6) | enc4;
output = output + String.fromCharCode(chr1);
if (enc3 != 64) {
output = output + String.fromCharCode(chr2);
}
if (enc4 != 64) {
output = output + String.fromCharCode(chr3);
}
}
output = _utf8_decode(output);
return output;
}
// private method for UTF-8 encoding
_utf8_encode = function (string) {
string = string.replace(/\r\n/g,"\n");
var utftext = "";
for (var n = 0; n < string.length; n++) {
var c = string.charCodeAt(n);
if (c < 128) {
utftext += String.fromCharCode(c);
} else if((c > 127) && (c < 2048)) {
utftext += String.fromCharCode((c >> 6) | 192);
utftext += String.fromCharCode((c & 63) | 128);
} else {
utftext += String.fromCharCode((c >> 12) | 224);
utftext += String.fromCharCode(((c >> 6) & 63) | 128);
utftext += String.fromCharCode((c & 63) | 128);
}
}
return utftext;
}
// private method for UTF-8 decoding
_utf8_decode = function (utftext) {
var string = "";
var i = 0;
var c = c1 = c2 = 0;
while ( i < utftext.length ) {
c = utftext.charCodeAt(i);
if (c < 128) {
string += String.fromCharCode(c);
i++;
} else if((c > 191) && (c < 224)) {
c2 = utftext.charCodeAt(i+1);
string += String.fromCharCode(((c & 31) << 6) | (c2 & 63));
i += 2;
} else {
c2 = utftext.charCodeAt(i+1);
c3 = utftext.charCodeAt(i+2);
string += String.fromCharCode(((c & 15) << 12) | ((c2 & 63) << 6) | (c3 & 63));
i += 3;
}
}
return string;
}
}
// 两次 base64.utf8 解密
function showEncodeHtml(content) {
// 类的实例化
var base64=new BASE64();
// 多次base64解码
return base64.decode(base64.decode(content)["\x72\x65\x70\x6c\x61\x63\x65"]('\x48\x74\x74\x70\x73\x77\x77\x77\x57\x65\x69\x79\x69\x47\x65\x65\x6b\x54\x4f\x50','')["\x72\x65\x70\x6c\x61\x63\x65"]('\x50\x4f\x54\x6b\x65\x65\x47\x69\x79\x69\x65\x57\x77\x77\x77\x73\x70\x74\x74\x48',''));
}
</script>脚本解析:
# (1)在线十六进制转字符串: https://www.bejson.com/convert/ox2str/
HttpswwwWeiyiGeekTOP => 487474707377777757656979694765656b544f50 => \x48\x74\x74\x70\x73\x77\x77\x77\x57\x65\x69\x79\x69\x47\x65\x65\x6b\x54\x4f\x50
POTkeeGiyieWwwwspttH => 504f546b65654769796965577777777370747448 => \x50\x4f\x54\x6b\x65\x65\x47\x69\x79\x69\x65\x57\x77\x77\x77\x73\x70\x74\x74\x48
# 字符串反转
var reverse = function( str ){
return str.split('').reverse().join('');
};
reverse('HttpswwwWeiyiGeekTOP');
# hex 编码
var string = "504f546b65654769796965577777777370747448";
var res = "";
for (i = 0; i < string.length; i+=2){
res += "\\x"+string.slice(i,i+2);
}
console.log(res)
# (2) 实际脚本调用解析(以下方式常常用在恶意脚本以及混淆脚本之中)
base64.decode(
base64.decode(context)["replace"]('HttpswwwWeiyiGeekTOP','')["replace"]('POTkeeGiyieWwwwspttH','')
# base64.decode(context).replace('HttpswwwWeiyiGeekTOP','').replace('POTkeeGiyieWwwwspttH','')
)Flask - Templates
Day3\App\templates\Spider\index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>{{ Title }}</title>
<!-- (3) 静态js文件调用 -->
<!-- <script src="{{ url_for('static', filename='Spider/decode.js')}}"></script> -->
<!-- (4) 动态js文件调用(校验请求时间)防止网页上js文件被js编码破解 -->
<script>
document.write('<script src="/get/decode/?t='+Date.parse(new Date())+'"><\/script>')
</script>
</head>
<body>
<h1> 动物信息 </h1>
<div class="animal">
<!--
(1) 常规方式
<ul>
{#
{% for element in Info %}
<li> {{# element.id }} - {{ element.name }} </li>
{% endfor %}
#}
</ul> -->
<!-- (2) 动态输出 -->
<script type="text/javascript">
//方式1.模板引擎渲染得到内容(未加密), 注意此处需要采用safe引擎内置函数进行HTML编码转码
//document.write("{{ Info|safe }}");
//方式2.模板引擎渲染得到内容(已base64编码)才用内置js文件进行反编码输出
document.write(showEncodeHtml("{{ Info|safe }}"));
</script>
</div>
</body>
</html>Day3\App\templates\Spider\info.html
<!-- 注意此处不能有换行否则需要在模板渲染返回字符串时候必须进行换行符替换 -->
<ul>
{% for element in Info %}
<li> {{ element.id }} - {{ element.name }} </li>
{% endfor %}
</ul>Flask - View (蓝图)
Day3\App\views\Spider\demo1.py
# -*- coding: utf-8 -*-
from flask import Blueprint,render_template,request,make_response
from App.models import db,Dog
import base64
import os
import time
pocket = Blueprint('pocket', __name__, url_prefix='/get')
@pocket.route('/info/')
def get_info():
# (1) 注意 in_ 只能用于filter并传入的是列表
dogs = Dog.query.filter(Dog.id.in_([1,3,5,7,9])).all()
# (2) 返回jijia2模板渲染后的结果此处需过滤掉换行符
info = render_template('/Spider/info.html', Info = dogs).replace('\n','')
# (3) 采用多次BASE64编码+自定义字符串拼接加密内容
encode_content = base64.standard_b64encode(info.encode('utf-8')).decode('utf-8')
# HttpswwwWeiyiGeekTOP => 487474707377777757656979694765656b544f50 => \x48\x74\x74\x70\x73\x77\x77\x77\x57\x65\x69\x79\x69\x47\x65\x65\x6b\x54\x4f\x50
# POTkeeGiyieWwwwspttH => 504f546b65654769796965577777777370747448 => \x50\x4f\x54\x6b\x65\x65\x47\x69\x79\x69\x65\x57\x77\x77\x77\x73\x70\x74\x74\x48
splice_content = "HttpswwwWeiyiGeekTOP" + encode_content + "POTkeeGiyieWwwwspttH" # 拼接混淆二进制串
mutil_encode = base64.standard_b64encode(splice_content.encode('utf-8')).decode('utf-8')
print("Base64 编码:",encode_content)
# (4) 向前台模板引擎传递参数
return render_template('/Spider/index.html', Title = '数据内容加密与反扒区演示', Info = mutil_encode)
@pocket.route('/decode/')
def get_decode():
# (6) 访问时间戳先渲染html页面在请求js(重点值得学习)
try:
t = request.args.get('t')
t = int(t)
except:
resp = make_response("alert('请求参数超时')")
resp.headers["Content-type"]="text/javascript;charset=UTF-8"
return resp
c = time.time() * 1000
# 一秒之内正常请求
if ( c - t <= 1000 ) and c > t:
# (5) 加载解密的JS文件 等同于 http://127.0.0.1:8000/static/Spider/decode.js
BASE_DIR = os.path.dirname(__file__)
with open(os.path.join(BASE_DIR, '..\..\static\Spider\decode.js'),encoding='utf-8') as file:
jsdecode=file.read()
resp = make_response(jsdecode)
resp.headers["Content-type"]="text/javascript;charset=UTF-8" # 正式环境中推荐此种方式开发
else:
resp = make_response("alert('请求超时')")
resp.headers["Content-type"]="text/javascript;charset=UTF-8"
return resp效果反馈:
(1) 简单爬取示例 : http://127.0.0.1:8000/get/info

(2) 前端网页显示 : http://127.0.0.1:8000/get/info
Base64 编码: PCEtLSDms6jmhI/mraTlpITkuI3og73mnInmjaLooYzlkKbliJnpnIDopoHlnKjmqKHmnb/muLLmn5Pov5Tlm57lrZfnrKbkuLLml7blgJnlv4Xpobvov5vooYzmjaLooYznrKbmm7/mjaIgLS0+IDx1bD4gICAgPGxpPiAxIC0g6Zi/6buEMOWPtyA8L2xpPiAgICA8bGk+IDMgLSDpmL/pu4Qy5Y+3IDwvbGk+ICAgIDxsaT4gNSAtIOmYv+m7hDTlj7cgPC9saT4gICAgPGxpPiA3IC0g6Zi/6buENuWPtyA8L2xpPiAgICA8bGk+IDkgLSDpmL/pu4Q45Y+3IDwvbGk+ICA8L3VsPg==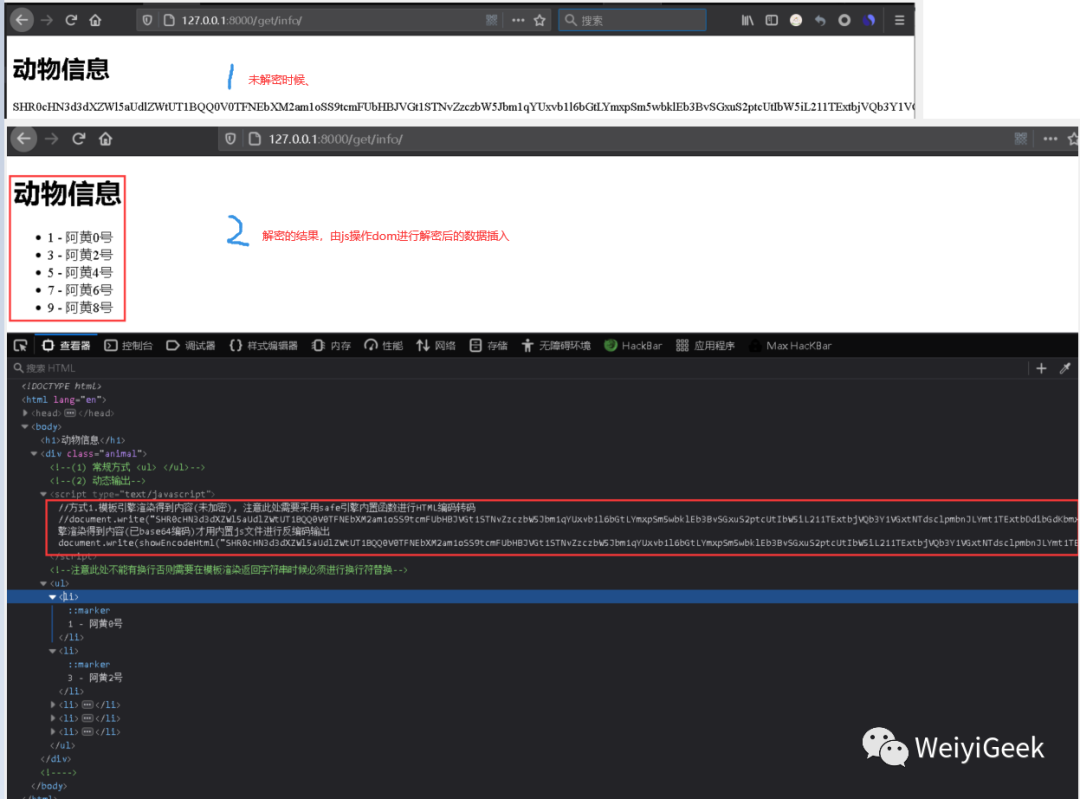
(3) 被包装后js文件(实际上可以加上JS混淆)如果直接访问将会报错即请求与服务器时间超过1秒时不能正常返回js解密代码 :http://127.0.0.1:8000/get/decode/?t=1603810658000

方式缺陷与对应解决办法:
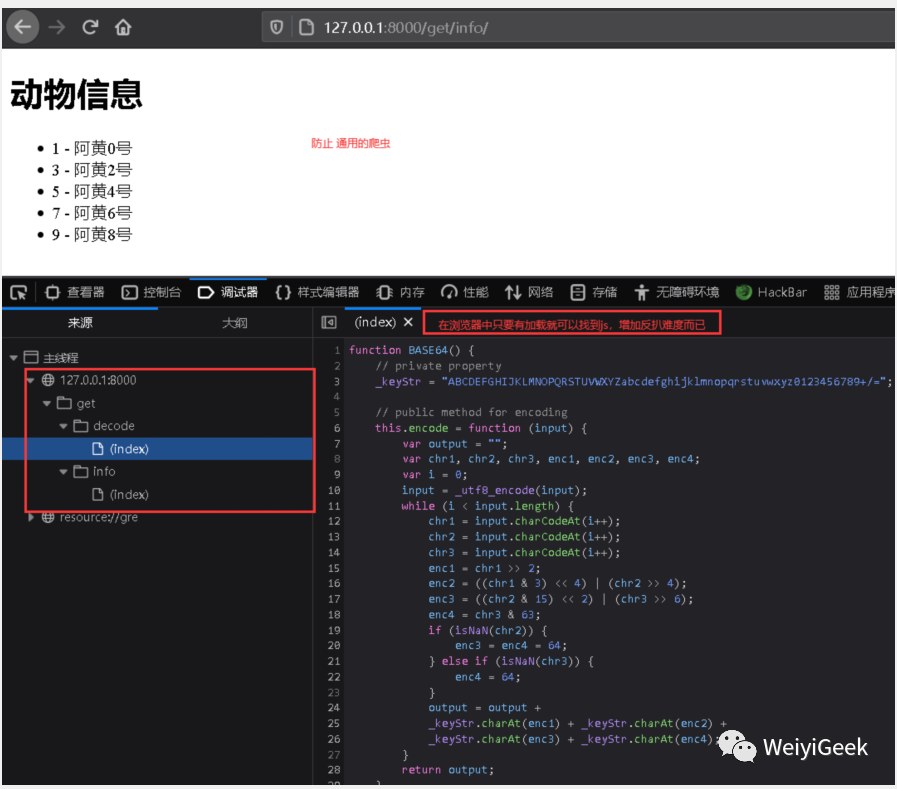
(1) 采用浏览器中的网页交互式(Console)控制台获取JS加密的函数从而逆向解密网页内容(
建议加上JS混淆有一定程度上的作用);
(2) 采用 Selenium + ChormeDriver 它是一个用于Web应用程序测试的工具,它可以操控浏览器来爬取网上的数据是爬虫的终极利器;
(3) 采用 Phantomjs 分析html代码,基于队列的爬虫、数据存储、数据拆分、爬虫限速、网页跟踪,脚本注入等技术。
本文章来源 Blog 站点(友链交换请邮我哟):
https://weiyigeek.top # 国内访问较慢
https://blog.weiyigeek.top # 更新频繁
https://weiyigeek.gitee.io # 国内访问快可能会有更新不及时得情况
更多学习笔记文章请关注 WeiyiGeek 公众账号
【点击我关注】
















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











