







最近工作中涉及到文本分类问题,于是就简单的看了一下朴素贝叶斯算法(Naive Bayes),以前对该算法仅仅停留在概念上的了解,这次系统的查阅资料学习了一下。朴素贝叶斯算法以贝叶斯定理为理论基础,想起大学时学习概率论与数理统计时,老师仅仅讲授贝叶斯定理,却没有引申讲一下朴素贝叶斯算法。上学时,学习很多数学定理时,心里都有个疑问,这个到底有什么用?到底哪些领域用到了这个定理?但是老师往往就是按照所谓的讲义、教学大纲授课,如果能做一下引申,相信大家对所学知识会有一个感性认识,理解的也会更深入,相信学习也会更有积极性。
那么,到底什么是朴素贝叶斯算法呢,基本可以一句话概括:贝叶斯定理 + 条件独立假设。贝叶斯定理就是我们数理统计课上学的定理, P(A|B) = P(B|A) P(A) / P(B);而条件独立假设指的是:解决分类问题时,会选取很多数据特征,为了降低计算复杂度,那么假设数据各个维度的特征相互独立。而算法的计算过程也可以用一句话概括:把计算“具有某特征的条件下属于某类”的概率转换成需要计算“属于某类的条件下具有某特征”的概率。整个算法没有什么复杂的计算环节,无非就是计算概率,真的很朴素。由于网络上资料很多,我就不面面俱到的介绍了,下面是我学习该算法过程中参考的一些链接,有纯理论介绍,也有的诙谐幽默介绍。看了下面几篇文章,朴素贝叶斯算法应该基本掌握了。
上面文章中,提到朴素贝叶斯算法训练问题,我对训练的理解是:开始迭代、梯度下降、更新权值w、偏至b,在打乱样本,在迭代这个过程。而朴素贝叶斯里的训练,其实并不是上述过程,而是一个构建查找表的过程,对于离散特征值,其实就是计算各种概率,然后把概率存起来,感觉就是一个数据预处理的过程,但是大家都这么说,应该是我理解的训练过于狭义了。而预测就是解析所有后验概率,并找出最大值。所以所谓的训练集其实也是可以作为测试集的,反正都是统计。
另外,根据数据特征的数据类型,朴素贝叶斯算法还可以分为三种模型:多项式、高斯、伯努利,不同的模型,适用不同的场景。当特征值是离散的时候,使用多项式模型,如:文本中词语的重复数;当特征值是连续的时候,使用高斯模型,如:人的身高、体重;当特征值取值仅为1和0时,使用伯努利模型,该模型相当于多项式模型的简化版。
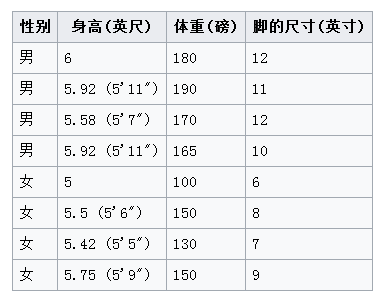
下面是代码示例, 不过我并没有从头编写朴素贝叶斯算法,而是直接调用sklearn机器学习库中的贝叶斯模块。刚开始用python不久,python代码写的一般。写python不像写c,写c代码时,基本写完每一个代码块都会考虑是不是最优,是不是最简洁实现,有没有及时释放内存,甚至还会考虑cpu缓存命中。而写python,还谈不上代码优化,仅停留在功能实现上。python版本为3.5,以朴素贝叶斯高斯模型为例,数据来自维基百科:根据身体测量特征,判断一个人是男性还是女性。
import numpy
from sklearn.naive_bayes import GaussianNB
def test_gaussian_nb():
X = numpy.array([
[6, 180, 12],
[5.92, 190, 11],
[5.58, 170, 12],
[5.92, 165, 10],
[5, 100, 6],
[5.5, 150, 8],
[5.42, 130, 7],
[5.75, 150, 9],
])
Y = numpy.array([1, 1, 1, 1, 0, 0, 0, 0])
gnb = GaussianNB()
gnb.fit(X, Y)
test = numpy.array([6, 130, 8]).reshape(1, -1)
result = gnb.predict(test)
print(result)
print("\n")
result = gnb.predict_proba(test)
print(result[0][0])
print(result[0][1])
if __name__ == '__main__':
test_gaussian_nb()















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









