









目标跟踪是计算机视觉领域里一个很重要的课题,而在线多实例学习方法是应用在视觉跟踪上的。关于这方面的讲解,网上能搜到的很少,于是自己看了若干文献,简单总结下,个人理解的不是很透彻,有不对的地方还望指正。
Visual Tracking with Online MultipleInstance Learning:
通常一个跟踪系统会包含3个部分:image representation,appearance model, and motion model。MIL算法针对的是外观模型这一部分,当然也会用到特征描述。
以往很多现成的算法对跟踪效果不好主要是因为目标外观或者背景的变化,后来有不少针对这方面的研究,思想是利用机器学习的算法来学习一个有可区分度的分类器来把目标从背景分离出来。因为这种方法和目标检测很类似,通常称作“基于检测的跟踪”。训练样本的生成是这种跟踪方法的一个难题。一种普遍的方法是在当前跟踪的位置取一个正样本,在跟踪位置的周围取一些负样本,但是如果跟踪的不准确,那么外观模型得不到好的更新结果,长时间后会造成漂移。另一种方法是在跟踪位置的一个小的邻域范围内取若干正样本,在远离的地方取负样本,这样的问题是因为存在虚检的正样本,分类器在判断最具有区分性的特征时会受到干扰混淆。为了解决这一问题,MIL算法得以提出。不同之处在于,MIL算法里提出样本袋的概念,所有的正样本(当前跟踪位置的小邻域范围里选取)加入到一个样本袋里,正样本袋具有不确定性(含有虚检),每一个负样本单独作为一个样本袋,负样本袋没有不确定性。如下图所示:
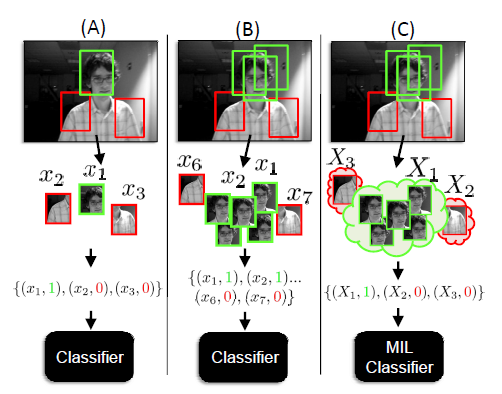
MIL算法基于boosting的思想,从M个特征对应的M个弱分类器中选择出K个弱分类器(对应K个特征,组成新的外观模型),然后组合成强分类器,并告诉我们在这个正样本袋里哪一个实例才是最正确的。新的位置就是这个实例的位置。如下图所示。这篇文章里M=250,K=50。特征选的是类haar特征。
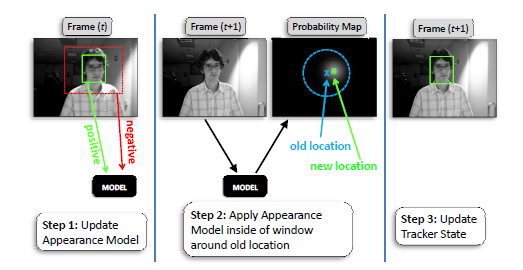
ParticleFilter TrackingWith Online Multiple Instance Learning:
这篇文章是对上面这篇文章的改进,上篇文章里提到关于正样本位置的选取用的很简单的方法,就在当前跟踪位置的一个小邻域里随机抽取,这篇文章改进之一是利用粒子滤波的方法,在粒子的位置上选取正样本。改进之二是对MIL算法的改进,主要有:
- 相比Noisy-OR模型,对bag是正样本的概率计算进行了修改:
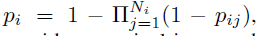 ------------------------>>>>>>
------------------------>>>>>> 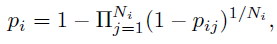
考虑到几何平均的计算可以避免数值过大的问题
- 运用梯度下降的思想,加入了权值w,w是似然函数L的导数
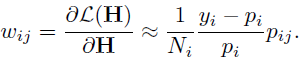
- 弱分类器的选择h
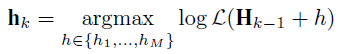 ------------------------>>>>>>
------------------------>>>>>>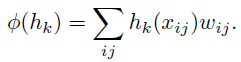
How does personal identity recognition helpmulti-person tracking:
这篇文章里提到外观相似度模型。用到3种特征:颜色、HOG、协方差矩阵。对两幅图片相似度s的计算可以考虑相关系数、巴氏距离等等,特征之间的距离就可以当做一个弱分类器,然后通过学习算法学习各种特征的权值。实验表明:颜色特征被选择的最多,纹理特征选择的最少。颜色特征提取的区域要小,HOG特征提取的范围要大。
CVPR2013-- Multi -Target Tracking by Online Learning of Non-linear Motion Patterns and Robust AppearanceModels:
最后这个跟踪算法的文章。它运用了改进的MIL算法(第二篇文章)和外观相似度模型(第三篇文章)。看了很多天这个MIL算法,简单说下我自己对这个MIL算法的大概理解,其实我也没有完全看懂它的意思。算法如下:

外层循环是选择出T个最具区分性的特征,内层循环是遍历所有的K个特征。
第一句:对每个特征下每个样本对的相似度通过sigmoid函数转化为概率(这个概率实际上是该样本对是同一个目标的概率)。
第二句:每个样本袋里面至少有一个样本对是同一个目标的概率,因为正样本袋只有一个,里面有若干个样本对,所以xi的绝对值为正样本对的总数,而负样本袋有若干个,每个里面只有一个样本对,所以xi的绝对值为1。这里计算概率的时候xi要分正负样本来考虑。
第三句:按照公式来求w,求的是每个样本对的权值。
第四句:按照公式来选择第k个特征,这个特征是当前所有特征中最具区分的特征。
第五句:按照线性搜索的方法给该特征分配权值,使得似然函数最大。另外说下我看了这些文章的感受,我觉得这种方法用在最后那个跟踪算法上有一定的道理,但也觉得比较虚。一方面不同的目标3种特征的区分能力不一样,这种方法的目的就是找出能最大程度区分不同目标的特征,并赋予一定的权值。如果我们赋予固定的权值,或者3种特征不进行筛选,那么对所有目标而言这3种特征的贡献都一样,必然没有MIL算法具有区分性,可能会导致不同目标的轨迹被错误连接(这是我的感觉,可以实现下看看效果)。但是另一方面,前面的文献里提到M=250,K=50,而这里M=3,K<M,K取的是2,感觉特征太少,或者说弱分类器数目太少了,感觉用这种方法很牵强。个人观点。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









