







在spark的开发中,经常会出现需要为dataframe添加id列的地方,特别对于一些需要存到关系型数据库中的结果,话不多说,下面直接上代码。
1、初始化:
val sparks = SparkSession.builder
.master("local[4]")
.appName("test1")
.getOrCreate()
val sc = sparks.sparkContext;2、从mysql中取一组不带id的数创建dataframe
val mRecord = sparks.read
.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1:3306/spark?user=root&password=root")
.option("dbtable", "(select water from correlation limit 10000) as record") //数据
.option("driver","com.mysql.jdbc.Driver")
.load();
mRecord.show(false);结果如下:
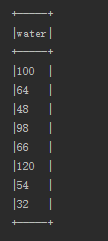
3、将dataframe转换为rdd
val mRdd = mRecord.rdd;
mRdd.collect().foreach{println};结果如下:
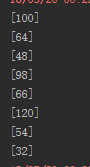
3、为rdd添加需要列,主要使用zipWithIndex()
val newRdd = mRdd.map{x => x.toString().substring(1,x.toString().length - 1)}.zipWithIndex();
newRdd.collect().foreach{println};结果如下:
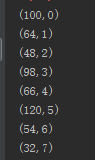
4、rdd转回dataframe,注意newRdd中的内容不是string,是tuple
val rowRdd = newRdd.map(a => Row(a._1.toInt,a._2.toInt));
val schema = StructType(
Array(
StructField("water",IntegerType,true),
StructField("id",IntegerType,true)
)
);
val resDf = sparks.createDataFrame(rowRdd,schema);
resDf.show(false);结果如下:
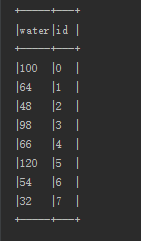















 4018
4018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









