







ELK+kafka+logback日志采集
概述
传统查看日志的方式一般是tail+grep或者把日志下载下来再搜索。这样的做法可以应付不多的主机和应用不多的部署场景,但对于多机多应用部署就不合适了。这里的多机多应用指的是同一种应用被部署到几台服务器上,每台服务器上又部署着不同的多个应用。可以想象,这种场景下,为了监控或者搜索某段日志,需要登陆多台服务器,执行多个tail -f和grep命令。一方面这很被动。另一方面,效率非常低,数次操作下来,程序员的心情也会变糟。
方案
传统elk解决方案虽然能解决大部分问题,但在实际运用中还是存在一些问题:
1. 每台机器都要部署一个logstash应用,logstash本身占用资源还是蛮多的。
2. 每部署一套新的应用,都要修改logstash的配置文件,从而去采集新的日志文件。
3. 日志的流量大小不可控,高峰期可能会冲击到下游的elasticSearch服务,导致整套elk瘫痪。
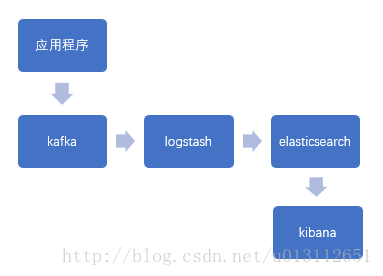
针对这些问题,加入了kafka和logback集成
1. 应用程序使用logback异步发送日志到外部,避免每台机器都要安装logstash的弊端。
2. 每部署一套应用程序不用再去修改logstash配置文件。
3. kafka承担了缓冲的角色,避免高峰期应用对于elk的冲击。
环境
- jkd8
- elasticsearch-5.4.0
- logstash-5.4.0
- kibana-5.4.0
- zookeeper-3.4.9
- kafka_2.12-0.10.2.1
elk最新版资源下载https://www.elastic.co/downloads
zookeeper最新版本资源下载http://www.apache.org/dyn/closer.cgi/zookeeper
kafka最新版本资源下载http://kafka.apache.org/downloads
部署
1、 jdk8
略······
2、 elasticsearch(非root用户)
tar zxvf elasticsearch-5.4.0.tar.gz #解压
cd elasticsearch-5.4.0 #进入安装目录
vi config/elasticsearch.yml #修改配置文件
network.host: ip #服务器地址
bootstrap.system_call_filter: false
bin/elasticsearch -d #后台方式启动项目
curl -X GET http://ip:9200 #检查是否启动成功
tail -500f logs/elasticsearch.log #启动失败,查看日志
可能会碰到的问题
报错max number of threads [1024] for user [lishang] likely too low, increase to at least [2048]
vi /etc/security/limits.d/90-nproc.conf
* soft nproc 1024
* soft nproc 2048
报错max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
vi /etc/sysctl.conf
vm.max_map_count=262144
报错max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
3、 zookeeper
tar zxvf zookeeper-3.4.9.tar.gz #解压
cd zookeeper-3.4.9
mkdir data logs
vi config/zoo.cfg #修改配置文件
dataDir=/home/admin/zookeeper/zookeeper-3.4.9/data
dataLogDir=/home/admin/zookeeper/zookeeper-3.4.9/logs
bin/zkServer.sh start #启动zookeeper
jps -m | grep zookeeper #检查zk是否启动
4、 kafka
tar zxvf kafka_2.12-0.10.2.1.tgz #解压
cd kafka_2.12-0.10.2.1
vi config/server.properties #修改配置文件
delete.topic.enable=true #topic是否可删除
advertised.listeners=PLAINTEXT://ip:9092
log.dirs=/home/hc/kafka/kafka_2.12-0.10.2.1/log
zookeeper.connect=ip:2181 #kafka启动需要zk
log.retention.hours=4 #消息存活时间
nohup bin/kafka-server-start.sh config/server.properties & #启动
bin/kafka-topics.sh --create --zookeeper ip:2181 --replication-factor 1 --partitions 1 --topic topic-test #创建topic
bin/kafka-topics.sh --list --zookeeper ip:2181 #查看topic
bin/kafka-topics.sh --delete --zookeeper ip:2181 --topic topic-test #删除topic
bin/kafka-console-producer.sh --broker-list ip:9092 --topic topic-test #发送消息
bin/kafka-console-consumer.sh --zookeeper ip:2181 --from-beginning --topic topic-test #接收消息
如果发送接收成功,说明kafka正常启动了
注:最好不要使用9092之外的端口,logstash监听不到
5、 logstash
tar zxvf logstash-5.4.0.tar.gz #解压
cd logstash-5.4.0
vi config/logstash_conf.conf #新增配置文件
input {
kafka {
topics => ["topic-test"]
bootstrap_servers => "ip:9092"
type => "topic-test"
consumer_threads => 5
decorate_events => true
}
}
filter {
grok {
match => {"message" => "%{WORD:level} %{GREEDYDATA:message}"}
overwrite => [ "message" ]
}
}
output {
elasticsearch {
hosts => "ip"
action => "index"
index => "%{type}-%{+YYYYMMdd}"
}
}
nohup bin/logstash -f config/logstash_config.conf & #启动项目,加入—debug参数可以看到更多细节
6、 kibana
tar zxvf kibana-5.4.0-linux-x86_64.tar.gz #解压
cd kibana-5.4.0-linux-x86_64 #修改配置文件
vi config/kibana.yml
server.host:"ip"
elasticsearch.url:"http://ip:9200"
vi /optimize/bundles/kibana.bundle.js #修改样式,堆栈太多会显示不下
truncateMaxHeight = maxHeight+"px !important" 改成 truncateMaxHeight = "none"
nohup bin/kibana & #启动项目
http://ip:5601 #登录地址
management->add index(支持通配符topic-test*)->discover
kibaba高级搜索(es语法)http://blog.csdn.net/hu948162999/article/details/51258257
7、 结束
至此整个环境搭建完毕
应用接入logback
应用jdk版本为1.7或1.8
参考https://github.com/danielwegener/logback-kafka-appender
Elasticsearch索引定期清理
es索引会不断变大,影响搜索效率,所以要定时清除
curl '192.168.111.129:9200/_cat/indices?v' #查询所有索引
curl -XDELETE "192.168.111.129:9200/face-web*" #删除指定索引
创建定时任务
crontab -e
* 23 * * * /home/hc/cron/elasticsearch_index_delete_cron.sh ip:9200
vi elasticsearch_index_delete_cron.sh
#! /bin/sh
rm -rf delete.tmp
today=`date +%Y%m%d`
yesterday=`date -d -1day +%Y%m%d`
curl $1'/_cat/indices?v' | awk '{print $3}' | grep '[0-9]\{8\}' | grep -v
$today'\|'$yesterday >> delete.tmp
for line in `cat delete.tmp`
do
curl -XDELETE $1'/'$line
done
rm -rf delete.tmp
预告
kafka和elasticsearch集群部署

















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









