






注:本文章的前提是kafka、es、logstash、kibana组件已经安装完成
1、客户端配置 kafkaAppender (也可以叫其他名字的 appender)
appender为logback里的一种日志处理组件,支持自定义appender用来对日志打印前做各种处理,elk的方式就是使用自定义的appender在日志打印前上报kafka后,再进行打印,会有一定的性能损耗(kafka的配置比较重要),但可接受 。
客户端改造(具体需要接入日志的服务)
POM增加依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!--logback-kafka-appender依赖-->
<dependency>
<groupId>com.github.danielwegener</groupId>
<artifactId>logback-kafka-appender</artifactId>
<version>0.1.0</version>
</dependency>
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.2</version>
</dependency>如果工程存在父子级目录,请在父级POM中增加kafka版本管理
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
<version>3.1.4</version>
</dependency>
</dependencies>
</dependencyManagement>2、logback.xml配置
<!--输出到kafka-->
<appender name="KafkaAppender" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder class="com.github.danielwegener.logback.kafka.encoding.LayoutKafkaMessageEncoder">
<layout class="net.logstash.logback.layout.LogstashLayout" >
<includeContext>false</includeContext>
<includeCallerData>true</includeCallerData>
<!--该系统名称,日志查询时区分 -->
<customFields>{"system":"test"}</customFields>
<fieldNames class="net.logstash.logback.fieldnames.ShortenedFieldNames"/>
</layout>
<charset>UTF-8</charset>
</encoder>
<!--kafka topic -->
<topic>applog</topic>
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.HostNameKeyingStrategy" />
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy" />
<producerConfig>bootstrap.servers=192.168.3.106:9092</producerConfig>
<!-- 这个配置表示不需要等待kafka响应成功就算发送完成,考虑到系统性能一定要用这个配置 -->
<producerConfig>acks=0</producerConfig>
<!-- wait up to 1000ms and collect log messages before sending them as a batch -->
<producerConfig>linger.ms=1000</producerConfig>
<!-- even if the producer buffer runs full, do not block the application but start to drop messages -->
<producerConfig>max.block.ms=0</producerConfig>
</appender>
<!--系统操作日志-->
<root level="info">
<appender-ref ref="KafkaAppender"/>
</root>配置完启动后可以使用kafka的命令去消费该日志topic,查看日志是否上报成功
./kafka-console-consumer.sh --topic applog --bootstrap-server 192.168.3.106:9092
3、logstash配置
如有较强的逻辑处理,这里也可以自己写消费代码消费日志并写入ES。我这里只对日志上报即可,所有选用logstash进行消费并写入。
简单配置如下:
input {
#kafka日志输入
kafka {
topics => "applog"
type => "kafka"
bootstrap_servers => "192.168.3.106:9092"
#根据topic 分区数来设置,不要大于分区数,不然属于浪费资源
consumer_threads => 3
codec => "json"
}
}
#这里logstash上报的时间为UTC时间,会比正常时间少八小时,如果需要上报正常时间,可以使用这个filter,亲测可用。或者这里不改时间,kibana把时区设置为 shanghai 也可以正常查看
filter {
#ruby {
# code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
#}
#ruby {
# code => "event.set('@timestamp',event.get('timestamp'))"
#}
#mutate {
# remove_field => ["timestamp"]
#}
}
#es 配置,索引会自动创建,这里配置每天创建
output {
elasticsearch {
hosts => ["192.168.3.106:9200"]
index => "nelson-applogs-%{+YYYY.MM.dd}"
}
stdout {}
}
启动logstash,进入logstash 的bin目录,-f为你的配置文件路径,&后台启动
./logstash -f /etc/logstash/config.d/xxx.conf &
启动成功如下:

消费到日志如下:
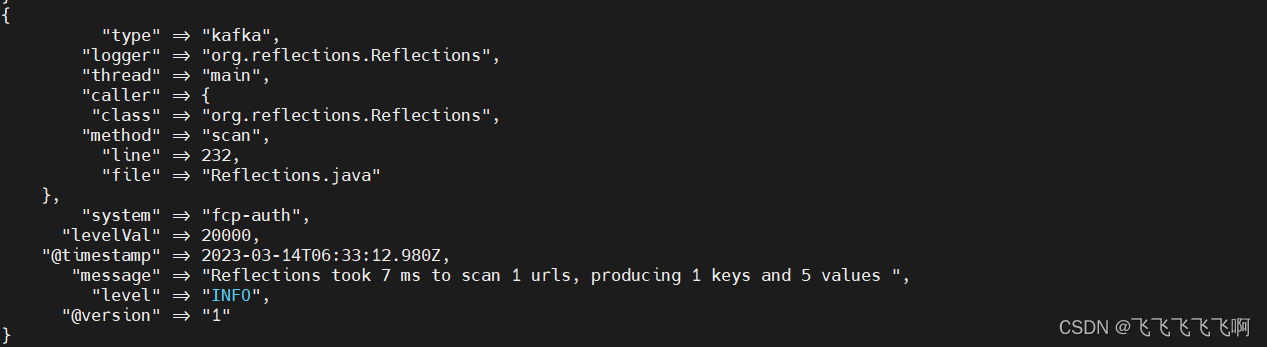
4、kibana查看
logstash 上报写入es成功后即可进行kibana查看日志
可以现在索引模式新增索引模式

使用模糊匹配规则可以查看到所有的相关索引数据

新建完成后点击菜单的Discover即可查看建立的索引配置规则















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









