







RNN处理带有时间序列的数据时具有很大的优势,接下来几篇文章将介绍如何使用RNN训练一个简单的语音识别系统。
主要参考该GitHub项目,https://github.com/silicon-valley-data-science/RNN-Tutorial以及这篇文章http://www.tuicool.com/articles/JvQb2iV
该项目使用tensorflow1.0.1构建(python3.5)
目录结构如下图所示:
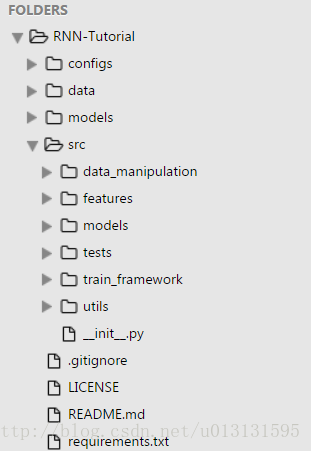
其中,
configs目录放置项目所需要的配置信息;
models目录存放训练结果;
data目录放置待训练的语音数据;
src目录放置项目所有源代码,安排如下:
data_manipulation/datasets.py 操作数据,获取训练时每个batch所需数据
features/utils/load_audio_to_mem.py 获取语音信息(.wav文件)并提取mfcc特征
features/utils/text.py 对训练的语音文本进行相关处理
models/RNN/rnn.py 构建训练所需的BiRNN网络
models/RNN/utils.py 构建训练的AdamOptimizer
train_framework/tf_train_ctc.py 训练的主函数以及类
utils/gpu.py 查看是否能使用gpu
utils/set_dirs.py 一些目录操作
详细的代码分析,从下回开始细细分解。















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









