







上回分析了run_model函数的configuration过程,其中load_placeholder_into_network函数用于构建该语音识别系统中RNN网络的基本结构,本回将分析以下该网络。
1.RNN简介
人们并不是从每秒钟他接收到的信息开始处理的,就像在看一篇论文的时候,大家都是先理解前文,然后根据现在的信息逐渐获得完整的信息。关于这些带有时间信息的序列处理时,传统的DNN可能无能为力。RNN就是为这类问题而设计的,通常RNN的结构如下图所示:
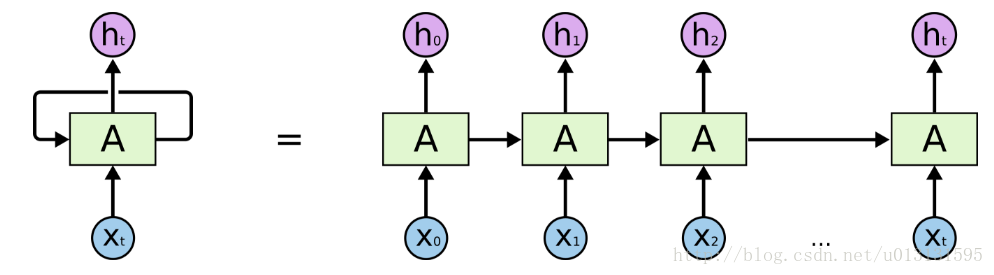
由上图可以看出,每个时刻的输出h即于当前的输入x有关,同时也于上一状态c有关。
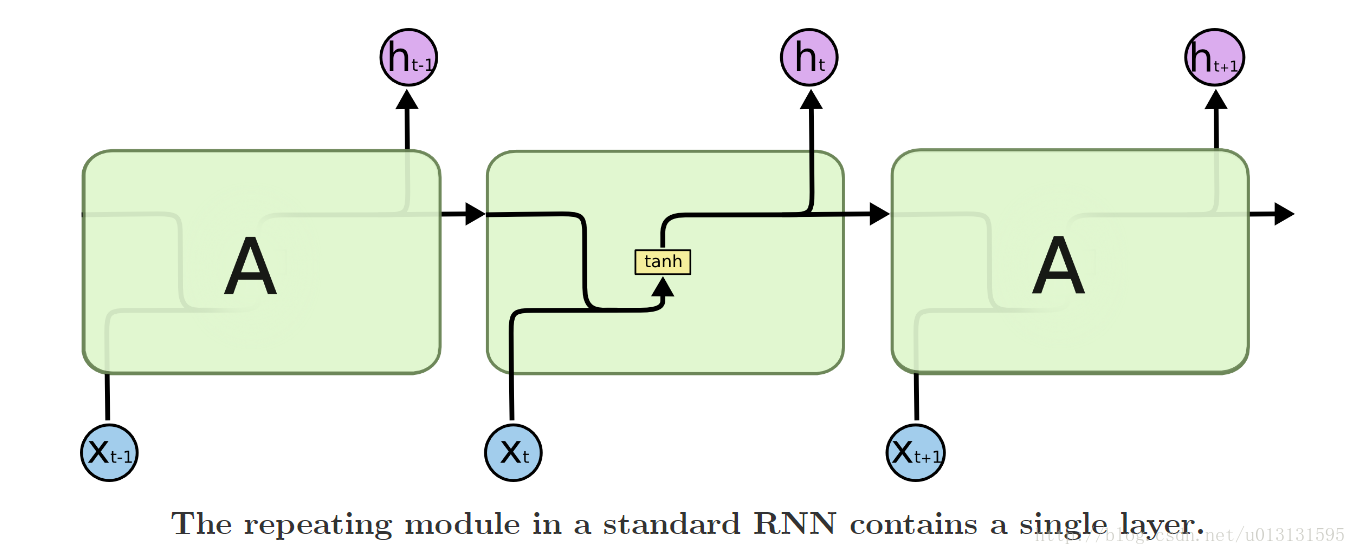
2.LSTM简介
由上文可知RNN可以处理与时序相关的问题,但是由于梯度扩散以及消失的问题,RNN只能记录到较短的时序信息。为了解决上述问题,引入了LSTM结构,如下图所示:
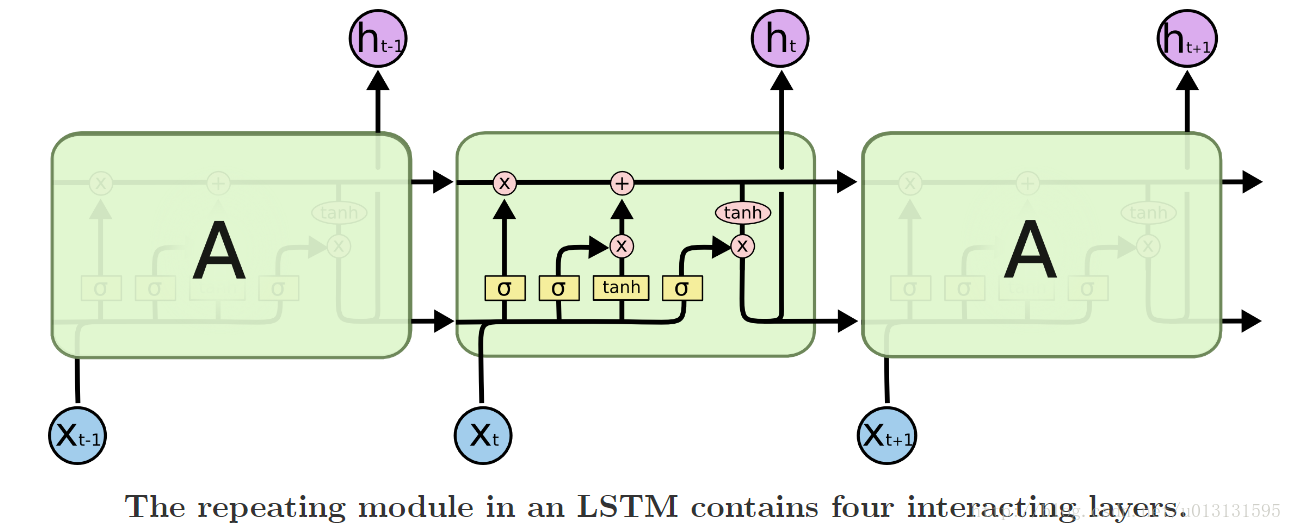
由上图可以看出,LSTM的内部结构比RNN要复杂一些,主要增加了遗忘门、输入门和输出门三个部件,对存储到RNN中的状态进行处理,使其能够记住较长的序列。
首先,输入门“ input gate”的作用是提供一个是否接收当前正常输入(包含信号和隐结点状态)信息的权重(0~1)。其值取决于当前输入信号和前一时刻隐含层的输出,结构如下图所示:
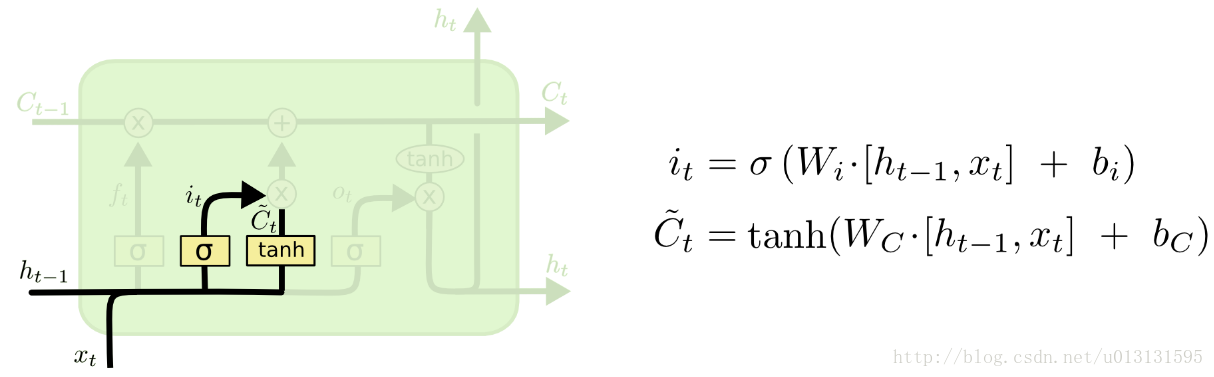
然后,遗忘门“ forget gate”的作用是提供一个遗忘当前状态的权重(0~1)。其值取决于当前输入信号和前一时刻隐含层的输出,结构如下图所示:
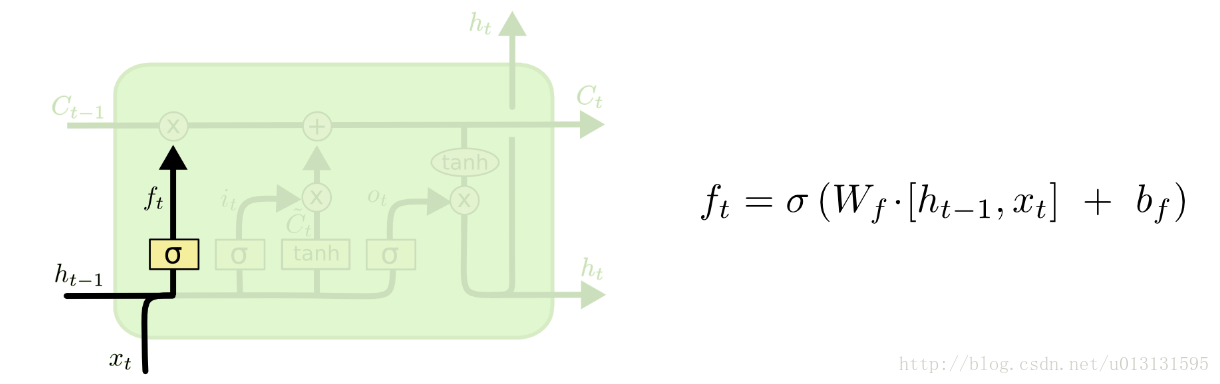
其中,LTSM 细胞产生的新记忆,由输入与遗忘两部分组成,如下图所示:
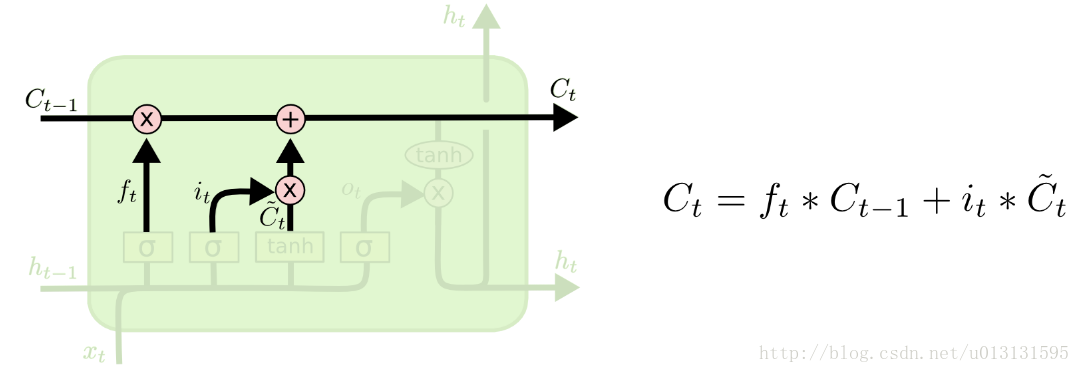
最后,输出门“ output gate”的作用是对当前输出提供一个 0~1之间的权重(对输出的认可程度)。其值取决于当前输入信号和前一时刻隐含层的输出,结构如下图所示:
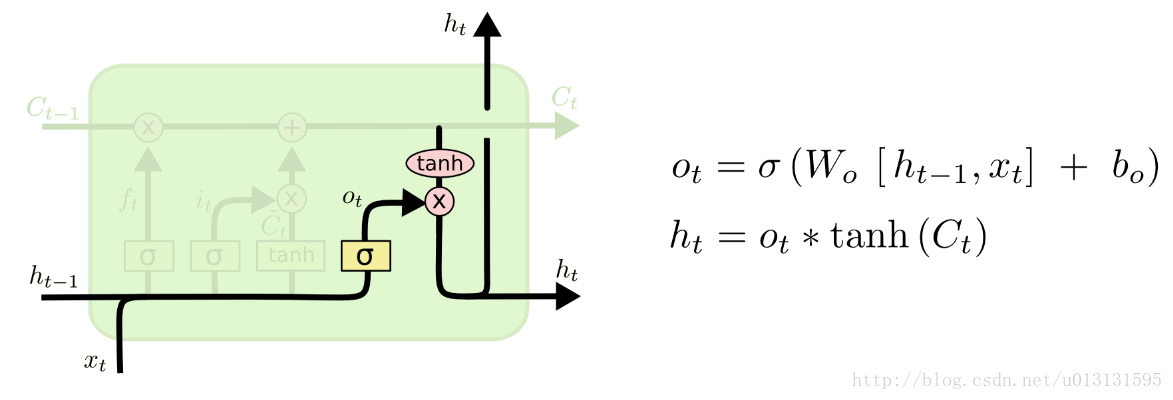
3.BiRNN简介
由上文可知RNN可以在时序上处理信息,但是当前的信息只能根据前面时刻的信息推测得出,这就忽略了未来的信息对现在的影响。访问未来的上下文,对于很多序列标注任务是十分有益的。因此,我们的语音识别系统采用该种网络结构。
那么如何构建这种特殊的网络结构呢?一种显而易见的办法是在输入和目标之间添加延迟,进而可以给网路一些时间步加入一些未来的上下文信息。双向循环神经网络(BiRNN)的基本思想是提出每一个训练序列向前和向后分别是两个循环神经网络(RNN),而且这两个都连接着一个输出层。这个结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息。下图展示的是一个沿着时间展开的双向循环神经网络。六个独特的权值在每一个时步被重复的利用,六个权值分别对应:输入到向前和向后隐含层(w1, w3),隐含层到隐含层自己(w2, w5),向前和向后隐含层到输出层(w4, w6)。值得注意的是:向前和向后隐含层之间没有信息流,这保证了展开图是非循环的。
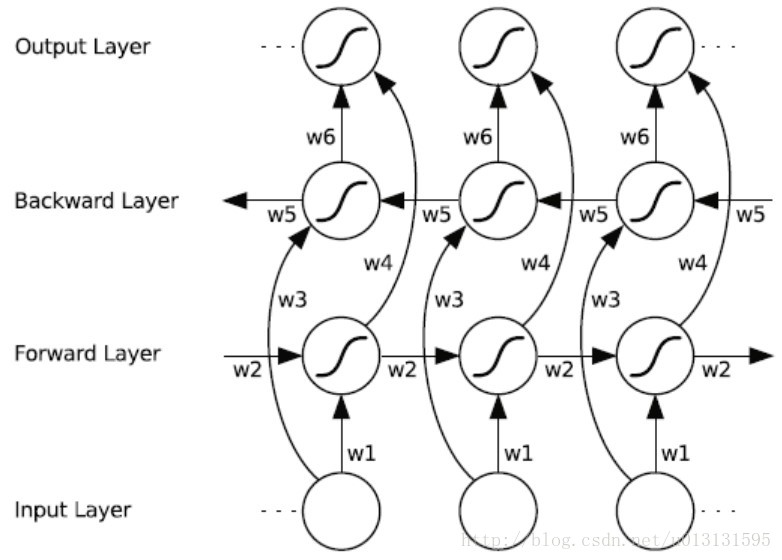
4.代码分析
上文简单介绍了RNN以及该网络的相关变式,现在我们根据上文所讲,简单分析一下我们的语音识别系统的实现。具体代码如下(位于rnn.py中):
def BiRNN(conf_path, batch_x, seq_length, n_input, n_context):
parser = ConfigParser(os.environ)
parser.read(conf_path)
dropout = [float(x) for x in parser.get('birnn', 'dropout_rates').split(',')]
relu_clip = parser.getint('birnn', 'relu_clip')
b1_stddev = parser.getfloat('birnn', 'b1_stddev')
h1_stddev = parser.getfloat('birnn', 'h1_stddev')
b2_stddev = parser.getfloat('birnn', 'b2_stddev')
h2_stddev = parser.getfloat('birnn', 'h2_stddev')
b3_stddev = parser.getfloat('birnn', 'b3_stddev')
h3_stddev = parser.getfloat('birnn', 'h3_stddev')
b5_stddev = parser.getfloat('birnn', 'b5_stddev')
h5_stddev = parser.getfloat('birnn', 'h5_stddev')
b6_stddev = parser.getfloat('birnn', 'b6_stddev')
h6_stddev = parser.getfloat('birnn', 'h6_stddev')
n_hidden_1 = parser.getint('birnn', 'n_hidden_1')
n_hidden_2 = parser.getint('birnn', 'n_hidden_2')
n_hidden_5 = parser.getint('birnn', 'n_hidden_5')
n_cell_dim = parser.getint('birnn', 'n_cell_dim')
n_hidden_3 = int(eval(parser.get('birnn', 'n_hidden_3')))
n_hidden_6 = parser.getint('birnn', 'n_hidden_6')
# Input shape: [batch_size, n_steps, n_input + 2*n_input*n_context]
batch_x_shape = tf.shape(batch_x)
# Reshaping `batch_x` to a tensor with shape `[n_steps*batch_size, n_input + 2*n_input*n_context]`.
# This is done to prepare the batch for input into the first layer which expects a tensor of rank `2`.
# Permute n_steps and batch_size
batch_x = tf.transpose(batch_x, [1, 0, 2])
# Reshape to prepare input for first layer
batch_x = tf.reshape(batch_x,
[-1, n_input + 2 * n_input * n_context]) # (n_steps*batch_size, n_input + 2*n_input*n_context)
# The next three blocks will pass `batch_x` through three hidden layers with
# clipped RELU activation and dropout.
# 1st layer
with tf.name_scope('fc1'):
b1 = variable_on_cpu('b1', [n_hidden_1], tf.random_normal_initializer(stddev=b1_stddev))
h1 = variable_on_cpu('h1', [n_input + 2 * n_input * n_context, n_hidden_1],
tf.random_normal_initializer(stddev=h1_stddev))
layer_1 = tf.minimum(tf.nn.relu(tf.add(tf.matmul(batch_x, h1), b1)), relu_clip)
layer_1 = tf.nn.dropout(layer_1, (1.0 - dropout[0]))
tf.summary.histogram("weights", h1)
tf.summary.histogram("biases", b1)
tf.summary.histogram("activations", layer_1)
# 2nd layer
with tf.name_scope('fc2'):
b2 = variable_on_cpu('b2', [n_hidden_2], tf.random_normal_initializer(stddev=b2_stddev))
h2 = variable_on_cpu('h2', [n_hidden_1, n_hidden_2], tf.random_normal_initializer(stddev=h2_stddev))
layer_2 = tf.minimum(tf.nn.relu(tf.add(tf.matmul(layer_1, h2), b2)), relu_clip)
layer_2 = tf.nn.dropout(layer_2, (1.0 - dropout[1]))
tf.summary.histogram("weights", h2)
tf.summary.histogram("biases", b2)
tf.summary.histogram("activations", layer_2)
# 3rd layer
with tf.name_scope('fc3'):
b3 = variable_on_cpu('b3', [n_hidden_3], tf.random_normal_initializer(stddev=b3_stddev))
h3 = variable_on_cpu('h3', [n_hidden_2, n_hidden_3], tf.random_normal_initializer(stddev=h3_stddev))
layer_3 = tf.minimum(tf.nn.relu(tf.add(tf.matmul(layer_2, h3), b3)), relu_clip)
layer_3 = tf.nn.dropout(layer_3, (1.0 - dropout[2]))
tf.summary.histogram("weights", h3)
tf.summary.histogram("biases", b3)
tf.summary.histogram("activations", layer_3)
# Create the forward and backward LSTM units. Inputs have length `n_cell_dim`.
# LSTM forget gate bias initialized at `1.0` (default), meaning less forgetting
# at the beginning of training (remembers more previous info)
with tf.name_scope('lstm'):
# Forward direction cell:
lstm_fw_cell = tf.contrib.rnn.BasicLSTMCell(n_cell_dim, forget_bias=1.0, state_is_tuple=True)
lstm_fw_cell = tf.contrib.rnn.DropoutWrapper(lstm_fw_cell,
input_keep_prob=1.0 - dropout[3],
output_keep_prob=1.0 - dropout[3],
# seed=random_seed,
)
# Backward direction cell:
lstm_bw_cell = tf.contrib.rnn.BasicLSTMCell(n_cell_dim, forget_bias=1.0, state_is_tuple=True)
lstm_bw_cell = tf.contrib.rnn.DropoutWrapper(lstm_bw_cell,
input_keep_prob=1.0 - dropout[4],
output_keep_prob=1.0 - dropout[4],
# seed=random_seed,
)
# `layer_3` is now reshaped into `[n_steps, batch_size, 2*n_cell_dim]`,
# as the LSTM BRNN expects its input to be of shape `[max_time, batch_size, input_size]`.
layer_3 = tf.reshape(layer_3, [-1, batch_x_shape[0], n_hidden_3])
# Now we feed `layer_3` into the LSTM BRNN cell and obtain the LSTM BRNN output.
outputs, output_states = tf.nn.bidirectional_dynamic_rnn(cell_fw=lstm_fw_cell,
cell_bw=lstm_bw_cell,
inputs=layer_3,
dtype=tf.float32,
time_major=True,
sequence_length=seq_length)
tf.summary.histogram("activations", outputs)
# Reshape outputs from two tensors each of shape [n_steps, batch_size, n_cell_dim]
# to a single tensor of shape [n_steps*batch_size, 2*n_cell_dim]
outputs = tf.concat(outputs, 2)
outputs = tf.reshape(outputs, [-1, 2 * n_cell_dim])
with tf.name_scope('fc5'):
# Now we feed `outputs` to the fifth hidden layer with clipped RELU activation and dropout
b5 = variable_on_cpu('b5', [n_hidden_5], tf.random_normal_initializer(stddev=b5_stddev))
h5 = variable_on_cpu('h5', [(2 * n_cell_dim), n_hidden_5], tf.random_normal_initializer(stddev=h5_stddev))
layer_5 = tf.minimum(tf.nn.relu(tf.add(tf.matmul(outputs, h5), b5)), relu_clip)
layer_5 = tf.nn.dropout(layer_5, (1.0 - dropout[5]))
tf.summary.histogram("weights", h5)
tf.summary.histogram("biases", b5)
tf.summary.histogram("activations", layer_5)
with tf.name_scope('fc6'):
# Now we apply the weight matrix `h6` and bias `b6` to the output of `layer_5`
# creating `n_classes` dimensional vectors, the logits.
b6 = variable_on_cpu('b6', [n_hidden_6], tf.random_normal_initializer(stddev=b6_stddev))
h6 = variable_on_cpu('h6', [n_hidden_5, n_hidden_6], tf.random_normal_initializer(stddev=h6_stddev))
layer_6 = tf.add(tf.matmul(layer_5, h6), b6)
tf.summary.histogram("weights", h6)
tf.summary.histogram("biases", b6)
tf.summary.histogram("activations", layer_6)
# Finally we reshape layer_6 from a tensor of shape [n_steps*batch_size, n_hidden_6]
# to the slightly more useful shape [n_steps, batch_size, n_hidden_6].
# Note, that this differs from the input in that it is time-major.
layer_6 = tf.reshape(layer_6, [-1, batch_x_shape[0], n_hidden_6])
summary_op = tf.summary.merge_all()
# Output shape: [n_steps, batch_size, n_hidden_6]
return layer_6, summary_op
其中,
第2-25行代码读入neural_network.ini中存储的[birnn]网络的配置参数,如下图所示:
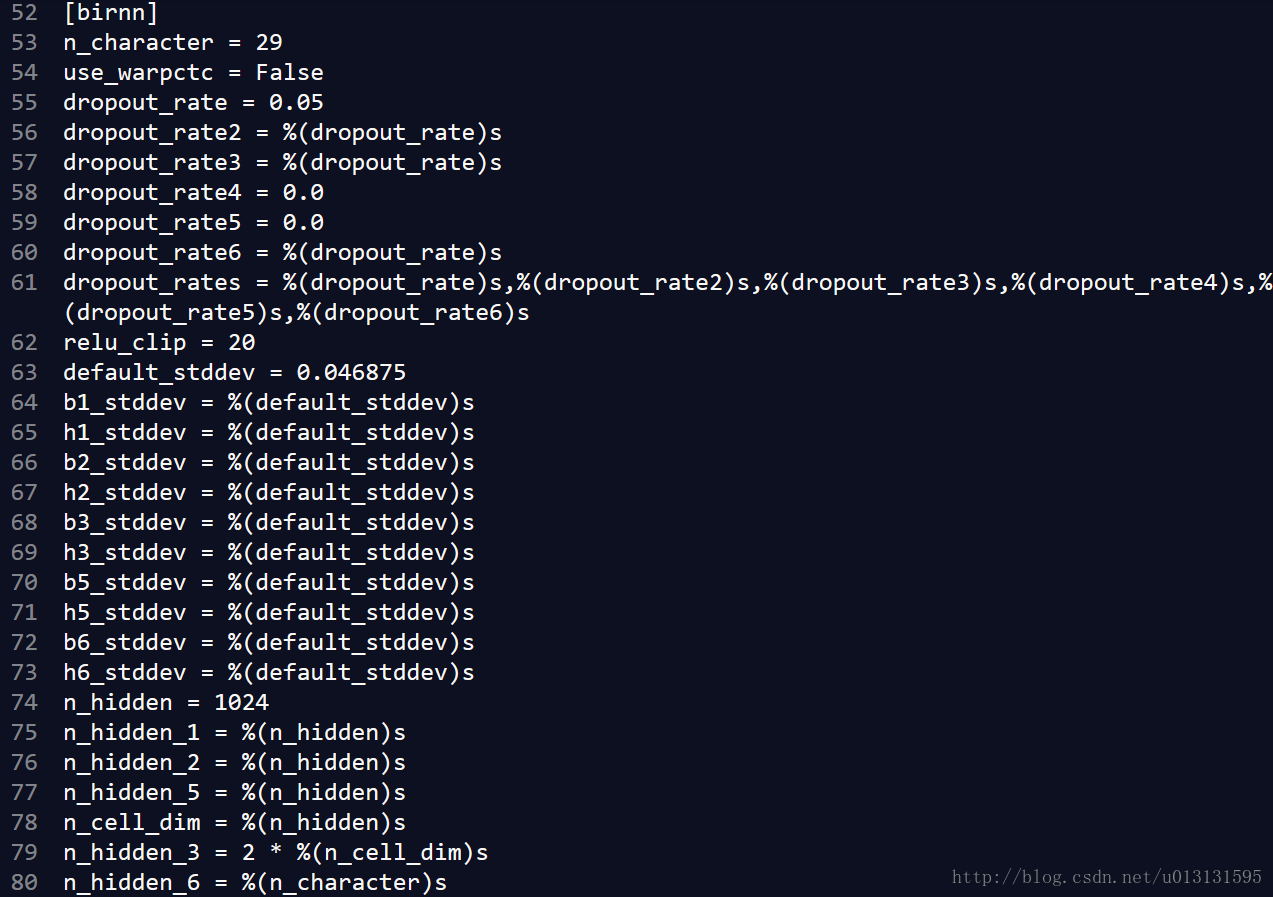
第27-37行对网络进行输入数据进行处理,可知每个batch_x为2维的,第一个参数为-1,第二个参数为n_input + 2*n_input*n_context=26+2*26*9=494(前文中已给出n_input、n_context的获取方式)。第二个参数表示网络的输入向量的宽度。
第42-144行代码使用tensorflow中的库函数对整个网络进行建模,使用tensorboard画出其结构图如下:
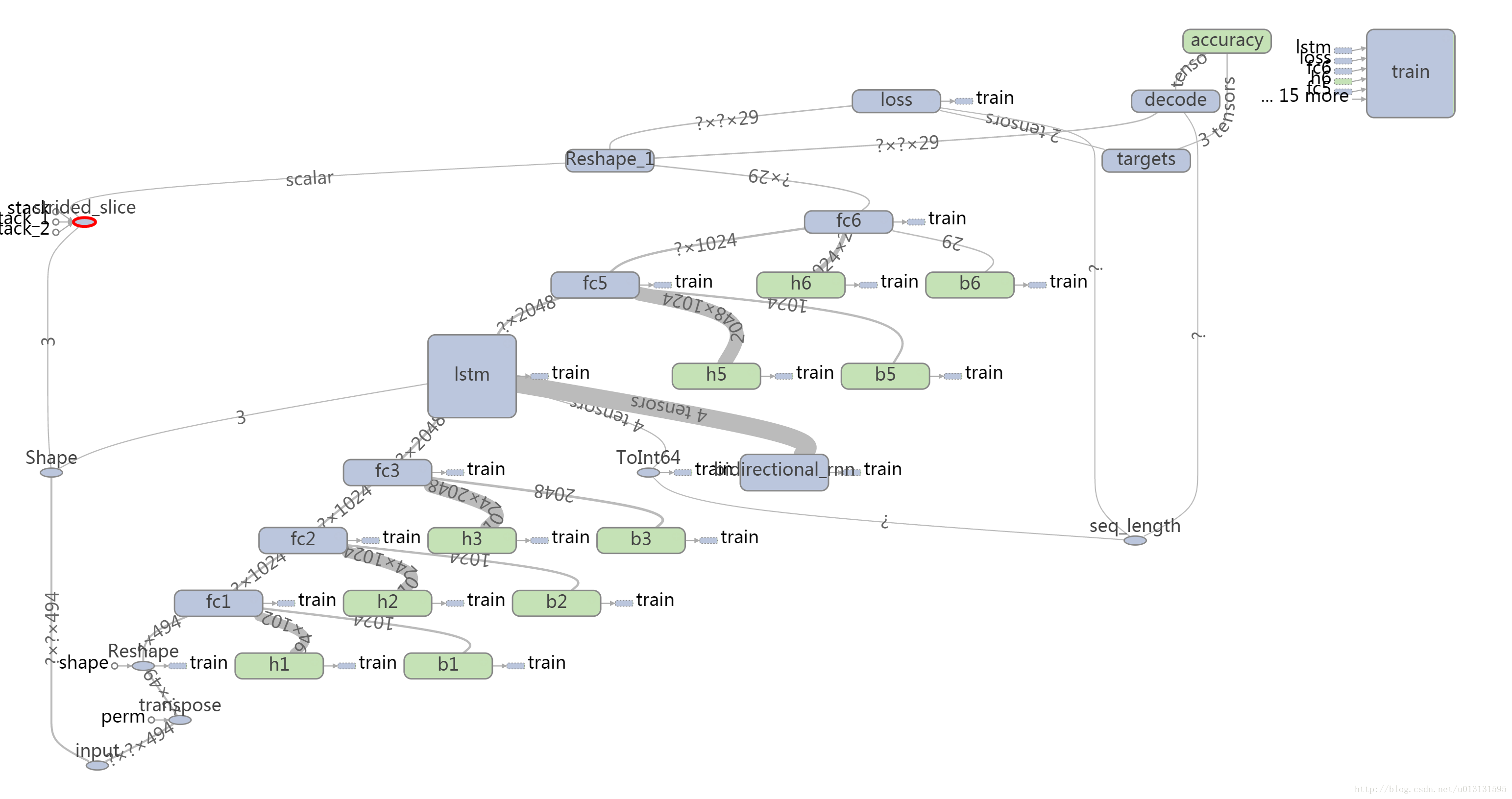
结合上图以及代码可以看出,该网络主要有6层,参数结构如下表所示:
| 层数 | 输入 | 输出 | 其它说明 |
|---|---|---|---|
| fc1 | 494 | 1024 | 输出大于20被置为20,dropout=0.05 |
| fc2 | 1024 | 1024 | 输出大于20被置为20,dropout=0.05 |
| fc3 | 1024 | 2048 | 输出大于20被置为20,dropout=0.05 |
| lstm | 2048 | 2048 | 关键部分后文分解 |
| fc5 | 2048 | 1024 | 输出大于20被置为20,dropout=0.05 |
| fc6 | 1024 | 29 | 输出层 |
其中,全连接层fc1/fc2/fc3/fc5/fc6就是简单的全连接层,下面详细分析lstm结构。
由代码中第79-105行可以看出,该网络主要使用tf.contrib.rnn构建,下面我们来分析以下BasicLSTMCell代码,如下所示:
class BasicLSTMCell(RNNCell):
def __init__(self, num_units, forget_bias=1.0, input_size=None,
state_is_tuple=True, activation=tanh, reuse=None):
"""Initialize the basic LSTM cell.
Args:
num_units: int, The number of units in the LSTM cell.
forget_bias: float, The bias added to forget gates (see above).
input_size: Deprecated and unused.
state_is_tuple: If True, accepted and returned states are 2-tuples of
the `c_state` and `m_state`. If False, they are concatenated
along the column axis. The latter behavior will soon be deprecated.
activation: Activation function of the inner states.
reuse: (optional) Python boolean describing whether to reuse variables
in an existing scope. If not `True`, and the existing scope already has
the given variables, an error is raised.
"""
if not state_is_tuple:
logging.warn("%s: Using a concatenated state is slower and will soon be "
"deprecated. Use state_is_tuple=True.", self)
if input_size is not None:
logging.warn("%s: The input_size parameter is deprecated.", self)
self._num_units = num_units
self._forget_bias = forget_bias
self._state_is_tuple = state_is_tuple
self._activation = activation
self._reuse = reuse
@property
def state_size(self):
return (LSTMStateTuple(self._num_units, self._num_units)
if self._state_is_tuple else 2 * self._num_units)
@property
def output_size(self):
return self._num_units
def __call__(self, inputs, state, scope=None):
"""Long short-term memory cell (LSTM)."""
with _checked_scope(self, scope or "basic_lstm_cell", reuse=self._reuse):
# Parameters of gates are concatenated into one multiply for efficiency.
if self._state_is_tuple:
c, h = state
else:
c, h = array_ops.split(value=state, num_or_size_splits=2, axis=1)
concat = _linear([inputs, h], 4 * self._num_units, True)
# i = input_gate, j = new_input, f = forget_gate, o = output_gate
i, j, f, o = array_ops.split(value=concat, num_or_size_splits=4, axis=1)
new_c = (c * sigmoid(f + self._forget_bias) + sigmoid(i) *
self._activation(j))
new_h = self._activation(new_c) * sigmoid(o)
if self._state_is_tuple:
new_state = LSTMStateTuple(new_c, new_h)
else:
new_state = array_ops.concat([new_c, new_h], 1)
return new_h, new_state其中__call__ 函数实现了前面所讲的LSTM结构。
同时第100行中tf.nn.bidirectional_dynamic_rnn函数将两个lstm结构合并成一个BiRNN结构,代码如下:
def bidirectional_dynamic_rnn(cell_fw, cell_bw, inputs, sequence_length=None,
initial_state_fw=None, initial_state_bw=None,
dtype=None, parallel_iterations=None,
swap_memory=False, time_major=False, scope=None):
"""Creates a dynamic version of bidirectional recurrent neural network.
Similar to the unidirectional case above (rnn) but takes input and builds
independent forward and backward RNNs. The input_size of forward and
backward cell must match. The initial state for both directions is zero by
default (but can be set optionally) and no intermediate states are ever
returned -- the network is fully unrolled for the given (passed in)
length(s) of the sequence(s) or completely unrolled if length(s) is not
given.
Args:
cell_fw: An instance of RNNCell, to be used for forward direction.
cell_bw: An instance of RNNCell, to be used for backward direction.
inputs: The RNN inputs.
If time_major == False (default), this must be a tensor of shape:
`[batch_size, max_time, input_size]`.
If time_major == True, this must be a tensor of shape:
`[max_time, batch_size, input_size]`.
[batch_size, input_size].
sequence_length: (optional) An int32/int64 vector, size `[batch_size]`,
containing the actual lengths for each of the sequences in the batch.
If not provided, all batch entries are assumed to be full sequences; and
time reversal is applied from time `0` to `max_time` for each sequence.
initial_state_fw: (optional) An initial state for the forward RNN.
This must be a tensor of appropriate type and shape
`[batch_size, cell_fw.state_size]`.
If `cell_fw.state_size` is a tuple, this should be a tuple of
tensors having shapes `[batch_size, s] for s in cell_fw.state_size`.
initial_state_bw: (optional) Same as for `initial_state_fw`, but using
the corresponding properties of `cell_bw`.
dtype: (optional) The data type for the initial states and expected output.
Required if initial_states are not provided or RNN states have a
heterogeneous dtype.
parallel_iterations: (Default: 32). The number of iterations to run in
parallel. Those operations which do not have any temporal dependency
and can be run in parallel, will be. This parameter trades off
time for space. Values >> 1 use more memory but take less time,
while smaller values use less memory but computations take longer.
swap_memory: Transparently swap the tensors produced in forward inference
but needed for back prop from GPU to CPU. This allows training RNNs
which would typically not fit on a single GPU, with very minimal (or no)
performance penalty.
time_major: The shape format of the `inputs` and `outputs` Tensors.
If true, these `Tensors` must be shaped `[max_time, batch_size, depth]`.
If false, these `Tensors` must be shaped `[batch_size, max_time, depth]`.
Using `time_major = True` is a bit more efficient because it avoids
transposes at the beginning and end of the RNN calculation. However,
most TensorFlow data is batch-major, so by default this function
accepts input and emits output in batch-major form.
dtype: (optional) The data type for the initial state. Required if
either of the initial states are not provided.
scope: VariableScope for the created subgraph; defaults to
"bidirectional_rnn"
Returns:
A tuple (outputs, output_states) where:
outputs: A tuple (output_fw, output_bw) containing the forward and
the backward rnn output `Tensor`.
If time_major == False (default),
output_fw will be a `Tensor` shaped:
`[batch_size, max_time, cell_fw.output_size]`
and output_bw will be a `Tensor` shaped:
`[batch_size, max_time, cell_bw.output_size]`.
If time_major == True,
output_fw will be a `Tensor` shaped:
`[max_time, batch_size, cell_fw.output_size]`
and output_bw will be a `Tensor` shaped:
`[max_time, batch_size, cell_bw.output_size]`.
It returns a tuple instead of a single concatenated `Tensor`, unlike
in the `bidirectional_rnn`. If the concatenated one is preferred,
the forward and backward outputs can be concatenated as
`tf.concat(outputs, 2)`.
output_states: A tuple (output_state_fw, output_state_bw) containing
the forward and the backward final states of bidirectional rnn.
Raises:
TypeError: If `cell_fw` or `cell_bw` is not an instance of `RNNCell`.
"""
# pylint: disable=protected-access
if not isinstance(cell_fw, rnn_cell_impl._RNNCell):
raise TypeError("cell_fw must be an instance of RNNCell")
if not isinstance(cell_bw, rnn_cell_impl._RNNCell):
raise TypeError("cell_bw must be an instance of RNNCell")
# pylint: enable=protected-access
with vs.variable_scope(scope or "bidirectional_rnn"):
# Forward direction
with vs.variable_scope("fw") as fw_scope:
output_fw, output_state_fw = dynamic_rnn(
cell=cell_fw, inputs=inputs, sequence_length=sequence_length,
initial_state=initial_state_fw, dtype=dtype,
parallel_iterations=parallel_iterations, swap_memory=swap_memory,
time_major=time_major, scope=fw_scope)
# Backward direction
if not time_major:
time_dim = 1
batch_dim = 0
else:
time_dim = 0
batch_dim = 1
def _reverse(input_, seq_lengths, seq_dim, batch_dim):
if seq_lengths is not None:
return array_ops.reverse_sequence(
input=input_, seq_lengths=seq_lengths,
seq_dim=seq_dim, batch_dim=batch_dim)
else:
return array_ops.reverse(input_, axis=[seq_dim])
with vs.variable_scope("bw") as bw_scope:
inputs_reverse = _reverse(
inputs, seq_lengths=sequence_length,
seq_dim=time_dim, batch_dim=batch_dim)
tmp, output_state_bw = dynamic_rnn(
cell=cell_bw, inputs=inputs_reverse, sequence_length=sequence_length,
initial_state=initial_state_bw, dtype=dtype,
parallel_iterations=parallel_iterations, swap_memory=swap_memory,
time_major=time_major, scope=bw_scope)
output_bw = _reverse(
tmp, seq_lengths=sequence_length,
seq_dim=time_dim, batch_dim=batch_dim)
outputs = (output_fw, output_bw)
output_states = (output_state_fw, output_state_bw)
return (outputs, output_states)其中调用了dynamic_rnn函数,代码如下:
def dynamic_rnn(cell, inputs, sequence_length=None, initial_state=None,
dtype=None, parallel_iterations=None, swap_memory=False,
time_major=False, scope=None):
"""Creates a recurrent neural network specified by RNNCell `cell`.
This function is functionally identical to the function `rnn` above, but
performs fully dynamic unrolling of `inputs`.
Unlike `rnn`, the input `inputs` is not a Python list of `Tensors`, one for
each frame. Instead, `inputs` may be a single `Tensor` where
the maximum time is either the first or second dimension (see the parameter
`time_major`). Alternatively, it may be a (possibly nested) tuple of
Tensors, each of them having matching batch and time dimensions.
The corresponding output is either a single `Tensor` having the same number
of time steps and batch size, or a (possibly nested) tuple of such tensors,
matching the nested structure of `cell.output_size`.
The parameter `sequence_length` is optional and is used to copy-through state
and zero-out outputs when past a batch element's sequence length. So it's more
for correctness than performance, unlike in rnn().
Args:
cell: An instance of RNNCell.
inputs: The RNN inputs.
If `time_major == False` (default), this must be a `Tensor` of shape:
`[batch_size, max_time, ...]`, or a nested tuple of such
elements.
If `time_major == True`, this must be a `Tensor` of shape:
`[max_time, batch_size, ...]`, or a nested tuple of such
elements.
This may also be a (possibly nested) tuple of Tensors satisfying
this property. The first two dimensions must match across all the inputs,
but otherwise the ranks and other shape components may differ.
In this case, input to `cell` at each time-step will replicate the
structure of these tuples, except for the time dimension (from which the
time is taken).
The input to `cell` at each time step will be a `Tensor` or (possibly
nested) tuple of Tensors each with dimensions `[batch_size, ...]`.
sequence_length: (optional) An int32/int64 vector sized `[batch_size]`.
initial_state: (optional) An initial state for the RNN.
If `cell.state_size` is an integer, this must be
a `Tensor` of appropriate type and shape `[batch_size, cell.state_size]`.
If `cell.state_size` is a tuple, this should be a tuple of
tensors having shapes `[batch_size, s] for s in cell.state_size`.
dtype: (optional) The data type for the initial state and expected output.
Required if initial_state is not provided or RNN state has a heterogeneous
dtype.
parallel_iterations: (Default: 32). The number of iterations to run in
parallel. Those operations which do not have any temporal dependency
and can be run in parallel, will be. This parameter trades off
time for space. Values >> 1 use more memory but take less time,
while smaller values use less memory but computations take longer.
swap_memory: Transparently swap the tensors produced in forward inference
but needed for back prop from GPU to CPU. This allows training RNNs
which would typically not fit on a single GPU, with very minimal (or no)
performance penalty.
time_major: The shape format of the `inputs` and `outputs` Tensors.
If true, these `Tensors` must be shaped `[max_time, batch_size, depth]`.
If false, these `Tensors` must be shaped `[batch_size, max_time, depth]`.
Using `time_major = True` is a bit more efficient because it avoids
transposes at the beginning and end of the RNN calculation. However,
most TensorFlow data is batch-major, so by default this function
accepts input and emits output in batch-major form.
scope: VariableScope for the created subgraph; defaults to "rnn".
Returns:
A pair (outputs, state) where:
outputs: The RNN output `Tensor`.
If time_major == False (default), this will be a `Tensor` shaped:
`[batch_size, max_time, cell.output_size]`.
If time_major == True, this will be a `Tensor` shaped:
`[max_time, batch_size, cell.output_size]`.
Note, if `cell.output_size` is a (possibly nested) tuple of integers
or `TensorShape` objects, then `outputs` will be a tuple having the
same structure as `cell.output_size`, containing Tensors having shapes
corresponding to the shape data in `cell.output_size`.
state: The final state. If `cell.state_size` is an int, this
will be shaped `[batch_size, cell.state_size]`. If it is a
`TensorShape`, this will be shaped `[batch_size] + cell.state_size`.
If it is a (possibly nested) tuple of ints or `TensorShape`, this will
be a tuple having the corresponding shapes.
Raises:
TypeError: If `cell` is not an instance of RNNCell.
ValueError: If inputs is None or an empty list.
"""
# pylint: disable=protected-access
if not isinstance(cell, rnn_cell_impl._RNNCell):
raise TypeError("cell must be an instance of RNNCell")
# pylint: enable=protected-access
# By default, time_major==False and inputs are batch-major: shaped
# [batch, time, depth]
# For internal calculations, we transpose to [time, batch, depth]
flat_input = nest.flatten(inputs)
if not time_major:
# (B,T,D) => (T,B,D)
flat_input = tuple(array_ops.transpose(input_, [1, 0, 2])
for input_ in flat_input)
parallel_iterations = parallel_iterations or 32
if sequence_length is not None:
sequence_length = math_ops.to_int32(sequence_length)
if sequence_length.get_shape().ndims not in (None, 1):
raise ValueError(
"sequence_length must be a vector of length batch_size, "
"but saw shape: %s" % sequence_length.get_shape())
sequence_length = array_ops.identity( # Just to find it in the graph.
sequence_length, name="sequence_length")
# Create a new scope in which the caching device is either
# determined by the parent scope, or is set to place the cached
# Variable using the same placement as for the rest of the RNN.
with vs.variable_scope(scope or "rnn") as varscope:
if varscope.caching_device is None:
varscope.set_caching_device(lambda op: op.device)
input_shape = tuple(array_ops.shape(input_) for input_ in flat_input)
batch_size = input_shape[0][1]
for input_ in input_shape:
if input_[1].get_shape() != batch_size.get_shape():
raise ValueError("All inputs should have the same batch size")
if initial_state is not None:
state = initial_state
else:
if not dtype:
raise ValueError("If there is no initial_state, you must give a dtype.")
state = cell.zero_state(batch_size, dtype)
def _assert_has_shape(x, shape):
x_shape = array_ops.shape(x)
packed_shape = array_ops.stack(shape)
return control_flow_ops.Assert(
math_ops.reduce_all(math_ops.equal(x_shape, packed_shape)),
["Expected shape for Tensor %s is " % x.name,
packed_shape, " but saw shape: ", x_shape])
if sequence_length is not None:
# Perform some shape validation
with ops.control_dependencies(
[_assert_has_shape(sequence_length, [batch_size])]):
sequence_length = array_ops.identity(
sequence_length, name="CheckSeqLen")
inputs = nest.pack_sequence_as(structure=inputs, flat_sequence=flat_input)
(outputs, final_state) = _dynamic_rnn_loop(
cell,
inputs,
state,
parallel_iterations=parallel_iterations,
swap_memory=swap_memory,
sequence_length=sequence_length,
dtype=dtype)
# Outputs of _dynamic_rnn_loop are always shaped [time, batch, depth].
# If we are performing batch-major calculations, transpose output back
# to shape [batch, time, depth]
if not time_major:
# (T,B,D) => (B,T,D)
flat_output = nest.flatten(outputs)
flat_output = [array_ops.transpose(output, [1, 0, 2])
for output in flat_output]
outputs = nest.pack_sequence_as(
structure=outputs, flat_sequence=flat_output)
return (outputs, final_state)其中调用了_dynamic_rnn_loop函数,代码如下:
def _dynamic_rnn_loop(cell,
inputs,
initial_state,
parallel_iterations,
swap_memory,
sequence_length=None,
dtype=None):
"""Internal implementation of Dynamic RNN.
Args:
cell: An instance of RNNCell.
inputs: A `Tensor` of shape [time, batch_size, input_size], or a nested
tuple of such elements.
initial_state: A `Tensor` of shape `[batch_size, state_size]`, or if
`cell.state_size` is a tuple, then this should be a tuple of
tensors having shapes `[batch_size, s] for s in cell.state_size`.
parallel_iterations: Positive Python int.
swap_memory: A Python boolean
sequence_length: (optional) An `int32` `Tensor` of shape [batch_size].
dtype: (optional) Expected dtype of output. If not specified, inferred from
initial_state.
Returns:
Tuple `(final_outputs, final_state)`.
final_outputs:
A `Tensor` of shape `[time, batch_size, cell.output_size]`. If
`cell.output_size` is a (possibly nested) tuple of ints or `TensorShape`
objects, then this returns a (possibly nsted) tuple of Tensors matching
the corresponding shapes.
final_state:
A `Tensor`, or possibly nested tuple of Tensors, matching in length
and shapes to `initial_state`.
Raises:
ValueError: If the input depth cannot be inferred via shape inference
from the inputs.
"""
state = initial_state
assert isinstance(parallel_iterations, int), "parallel_iterations must be int"
state_size = cell.state_size
flat_input = nest.flatten(inputs)
flat_output_size = nest.flatten(cell.output_size)
# Construct an initial output
input_shape = array_ops.shape(flat_input[0])
time_steps = input_shape[0]
batch_size = input_shape[1]
inputs_got_shape = tuple(input_.get_shape().with_rank_at_least(3)
for input_ in flat_input)
const_time_steps, const_batch_size = inputs_got_shape[0].as_list()[:2]
for shape in inputs_got_shape:
if not shape[2:].is_fully_defined():
raise ValueError(
"Input size (depth of inputs) must be accessible via shape inference,"
" but saw value None.")
got_time_steps = shape[0].value
got_batch_size = shape[1].value
if const_time_steps != got_time_steps:
raise ValueError(
"Time steps is not the same for all the elements in the input in a "
"batch.")
if const_batch_size != got_batch_size:
raise ValueError(
"Batch_size is not the same for all the elements in the input.")
# Prepare dynamic conditional copying of state & output
def _create_zero_arrays(size):
size = _state_size_with_prefix(size, prefix=[batch_size])
return array_ops.zeros(
array_ops.stack(size), _infer_state_dtype(dtype, state))
flat_zero_output = tuple(_create_zero_arrays(output)
for output in flat_output_size)
zero_output = nest.pack_sequence_as(structure=cell.output_size,
flat_sequence=flat_zero_output)
if sequence_length is not None:
min_sequence_length = math_ops.reduce_min(sequence_length)
max_sequence_length = math_ops.reduce_max(sequence_length)
time = array_ops.constant(0, dtype=dtypes.int32, name="time")
with ops.name_scope("dynamic_rnn") as scope:
base_name = scope
def _create_ta(name, dtype):
return tensor_array_ops.TensorArray(dtype=dtype,
size=time_steps,
tensor_array_name=base_name + name)
output_ta = tuple(_create_ta("output_%d" % i,
_infer_state_dtype(dtype, state))
for i in range(len(flat_output_size)))
input_ta = tuple(_create_ta("input_%d" % i, flat_input[0].dtype)
for i in range(len(flat_input)))
input_ta = tuple(ta.unstack(input_)
for ta, input_ in zip(input_ta, flat_input))
def _time_step(time, output_ta_t, state):
"""Take a time step of the dynamic RNN.
Args:
time: int32 scalar Tensor.
output_ta_t: List of `TensorArray`s that represent the output.
state: nested tuple of vector tensors that represent the state.
Returns:
The tuple (time + 1, output_ta_t with updated flow, new_state).
"""
input_t = tuple(ta.read(time) for ta in input_ta)
# Restore some shape information
for input_, shape in zip(input_t, inputs_got_shape):
input_.set_shape(shape[1:])
input_t = nest.pack_sequence_as(structure=inputs, flat_sequence=input_t)
call_cell = lambda: cell(input_t, state)
if sequence_length is not None:
(output, new_state) = _rnn_step(
time=time,
sequence_length=sequence_length,
min_sequence_length=min_sequence_length,
max_sequence_length=max_sequence_length,
zero_output=zero_output,
state=state,
call_cell=call_cell,
state_size=state_size,
skip_conditionals=True)
else:
(output, new_state) = call_cell()
# Pack state if using state tuples
output = nest.flatten(output)
output_ta_t = tuple(
ta.write(time, out) for ta, out in zip(output_ta_t, output))
return (time + 1, output_ta_t, new_state)
_, output_final_ta, final_state = control_flow_ops.while_loop(
cond=lambda time, *_: time < time_steps,
body=_time_step,
loop_vars=(time, output_ta, state),
parallel_iterations=parallel_iterations,
swap_memory=swap_memory)
# Unpack final output if not using output tuples.
final_outputs = tuple(ta.stack() for ta in output_final_ta)
# Restore some shape information
for output, output_size in zip(final_outputs, flat_output_size):
shape = _state_size_with_prefix(
output_size, prefix=[const_time_steps, const_batch_size])
output.set_shape(shape)
final_outputs = nest.pack_sequence_as(
structure=cell.output_size, flat_sequence=final_outputs)
return (final_outputs, final_state)
这段代码看的还不是太清楚,留到以后分析。
自此我们对我们的语音识别系统中的网络结构已经有了一定的认识了,后面我们将分析一下该网络是如何运行起来的。
主要参考:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
http://blog.csdn.net/jojozhangju/article/details/51982254















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









