






数据库分表的重点
mysql的分库分表分为两个部分
- 如何选择shardingkey,来满足业务的查询需求
- 如何设计根据shardingkey来进行路由,进而找到所在的库表,同时还能够满足在需要扩容的时候,原来在同一个表的数据还在同一个表,进而满足快速的查询
同时还有一个进阶的处理 - 如果有比较多的查询条件的,可以采用数据异构的方式,比如检索字段异构导入到ES当中,然后根据hbase来查询具体内容
1. sharding key的选择
根据查询需求,比如滴滴的订单表,会根绝订单id,司机id,乘客id来进行查询,所以需要有三个sharding id 但是只有一个主sharding id , 其他的需要多余的表来关联对应的主shardding id, 也就是一次查询需要查两次。
参考: 一文读懂分库分表的技术演进
2. sharding 规则设计
一般情况下是一次把数据库表设计到位,比如使用1024张表,但是计算库和表是有规则的,比如最开始使用32个库,每个库32个表。
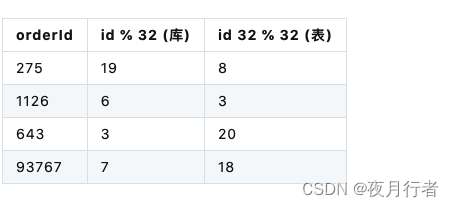
每个实例1000,那么32个就是3.2w qps
这里想证明的是,如果数据后面的请求量级变大之后,可以成倍的增加库,每个库中的表的数量减半,这种情况下数据在库容后,原来在同一个表中的数据还在同一个表当中,只需要多开几个从实例,然后同步相关数据,
然后路由规则,库变成 id%64 表的话变成 id / 64 % 16 得到表,这样的话就只有一半的表会被用到,然后逐渐清除另一半就可以了,但是因为表名不同,所以还是需要进行binlog的异构回放才可以
参考
https://www.modb.pro/db/114588
https://tech.meituan.com/2016/11/18/dianping-order-db-sharding.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









