







1.认识目录结构
安装略过,使用命令创建项目
scrapy startproject myfirstpjt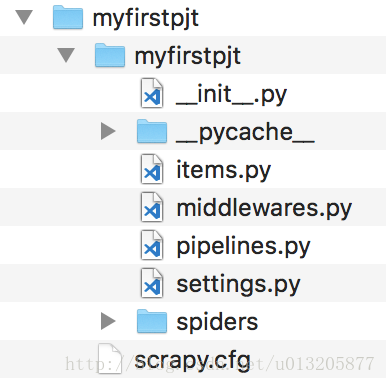
这里面 scrapy.cfg 是爬虫项目配置文件,项目的同名子文件夹中,init.py 是初始化文件,items.py 是爬虫项目的数据容器文件,piplines.py 是爬虫的管道文件 seetings.py爬虫项目的设置文件
2.常用的命令
1.创建所需参数帮助信息 :
scrpy startproject -h
2.全局命令
全局命令不依靠 scrapy 可以全局使用,参数帮助信息 scrapy -h
a.scrap fetch -h
在项目外使用就是用 scrapy 默认的爬虫来爬取,项目内则使用项目中的来爬取
显示爬取百度的过程
scrapy fetch http://baidu.comb.scrapy runspider 爬虫文件名.py
可以直接运行爬虫文件不依赖项目
c.scrapy seetings –get BOT_NAME
查看配置信息















 61万+
61万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









