






DeepSeek无疑是这个春节档AI圈的顶流,2024年12月发布DeepSeek-V3作为全国产自研模型,以其高性能,低价格火爆AI领域。DeepSeek-V3 多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模型,并在性能上和世界顶尖的闭源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲。
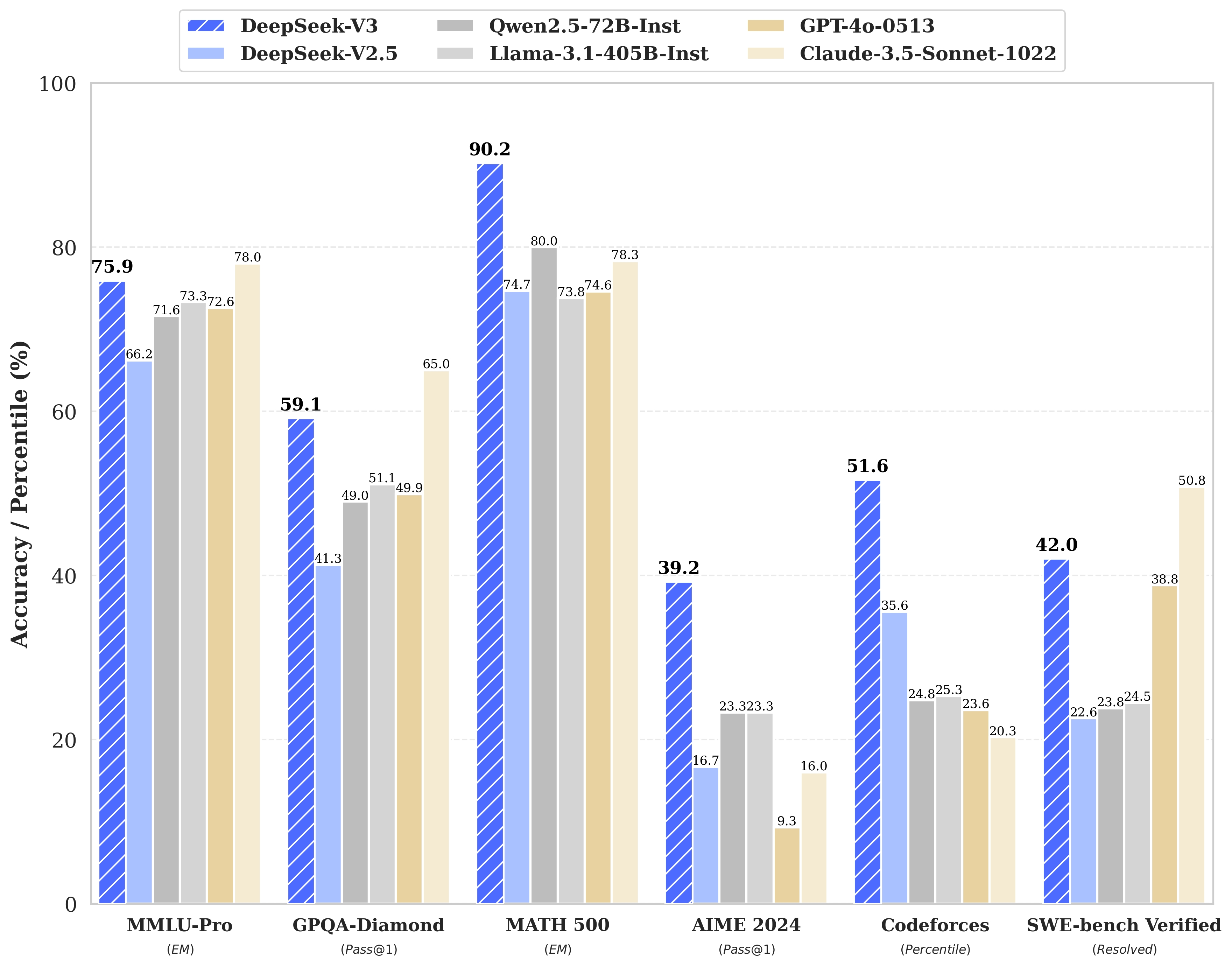
在如此强劲的性能基础上,DeepSeek把价格打下来,实现高性价比。
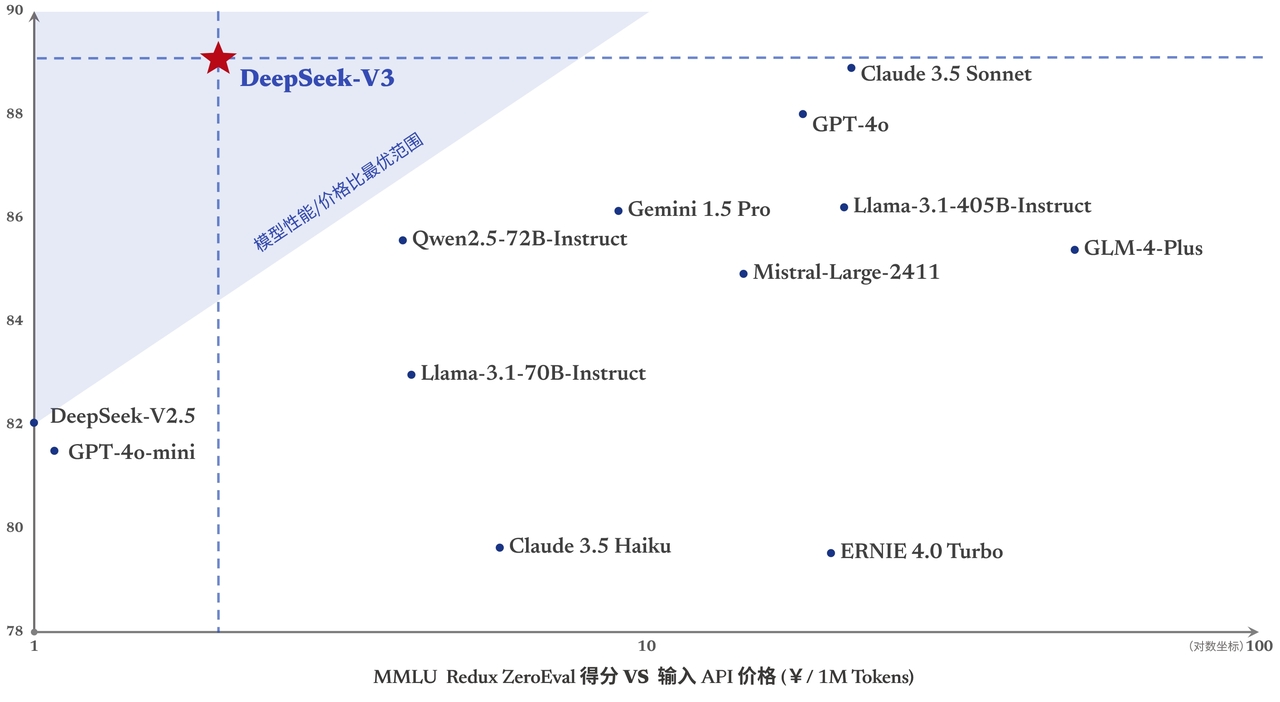
DeepSeek-V3是如何做到降本增效,如果把大模型训练推理比作制造工厂,如何提高生产效率,第一要降低工作量,第二就是压榨工人。接下来主要介绍DeepSeek-V3具体的技术亮点。
MLA多层潜在注意力机制
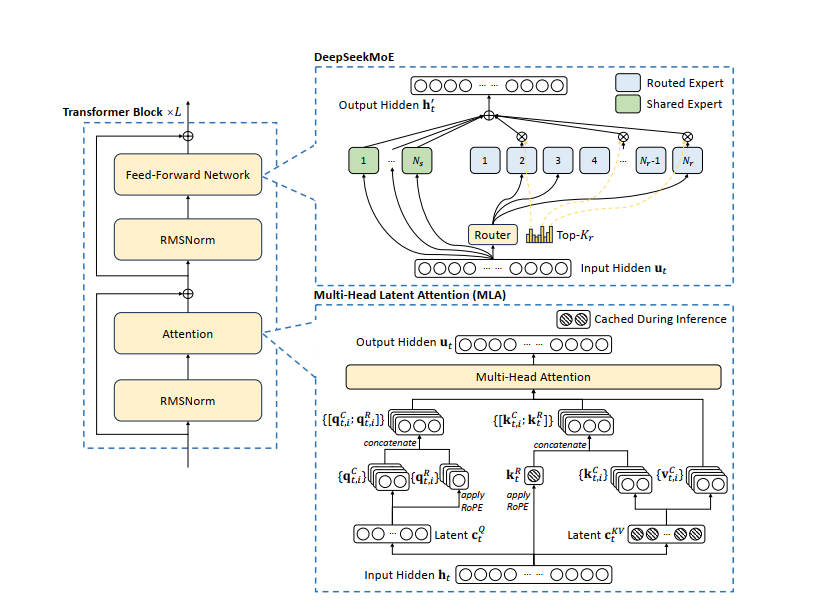
DeepSeek-V3 的基础架构建立在 Transformer 框架之上,基础模型仍然是基于MOE混合专家模型,使用不同的“专家”来解决对应的文本,数学代码等不同的问题,提高效率和性能。在此基础上DeepSeek的技术创新在于在注意力机制方面采用MLA架构,其核心在于对注意力和值进行低秩联合压缩,以降低推理过程中的缓存开销。通俗点就是在记录数据时先简化记录信息,比如在统计公司人员情况时,不在单独某某员工base地和职位而是仅记录员工所属部门,只有在需要进一步了解该员工情况时再做详细的记录。这样一定程度上就减少了计算和缓存量。
FP8混合精度训练框架
DeepSeek-V3在已有低精度训练技术的基础上,设计了专门的 FP8 训练混合精度框架。在这一框架中,大部分计算密集型操作采用 FP8 执行,而关键操作则保持原有数据格式,以实现训练效率和数值稳定性的最优平衡。就是该精确的时候精确,不该精确的时候“四舍五入”的记录。
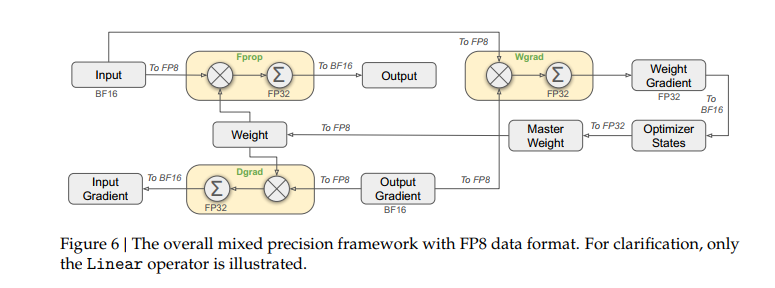
首先,为提高模型训练速度,大部分核心计算操作(尤其是 GEMM 运算),均采用 FP8 精度实现。这些 GEMM 运算接收 FP8 格式的张量输入,输出 BF16 或 FP32 格式的结果。如上图所示,线性运算相关的三个 GEMM 操作,包括 Fprop(前向传播)、Dgrad(激活值反向传播)和 Wgrad(权重反向传播),均采用 FP8 执行。这种设计策略理论上将计算速度提升至原有 BF16 方法的两倍。同时,FP8 格式的 Wgrad GEMM 使得激活值能够以 FP8 格式存储用于反向传播,显著降低了内存使用量。
以上两个技术点都能够在一定程度上降低工作量,提高性能。对于工人的进一步压榨体现在以下两点。
DualPipe流水线并行算法
相比现有 PP 方法,该算法显著减少了流水线停滞现象。更重要的是,它实现了前向和后向过程中计算与通信阶段的重叠,有效解决了跨节点专家并行带来的通信负载问题。数据传输和计算同时进行,双线流水线调度策略,理论效率提升50%。
完整的DualPipe调度机制如下图。它采用创新的双向流水线调度策略,实现了从流水线两端同时输入微批次数据,使得大部分通信过程能够与计算过程完全重叠。这种设计确保了即使在模型规模进一步扩大的情况下,只要维持适当的计算通信比例,就能在节点间实现细粒度的专家分配,同时将全节点通信开销降至接近于零。

在官方给出的技术文档中,即使在通信负载相对较轻的常规场景中,DualPipe 仍然展现出显著的效率优势。
无辅助损失的负载均衡策略
MOE模型下,不平衡的专家负载将会导致路由崩溃,并在装甲并行场景中降低计算效率。传统解决方案通常依赖辅助损失来避免不平衡负载。然而,过大的辅助损失会损害模型的性能。DeepSeek-V3的创新点在于在训练过程中,系统会实施监控每个训练步骤中所有批次的专家负载分布,在每个步骤结束时,对于负载过高的专家,会减少分配量,负载不足的专家,增加分配量。类比外卖派单,根据外卖小哥的实时接单量及时调整派单量,提高工作效率。
以上4种不完全的技术创新点都在一定程度上降低了工作量,提升了性能,那如何保证模型训练的质量呢?
模型够大,数据够好
相比 DeepSeek-V2,本次预训练语料库在提升数学和编程样本占比的同时,扩大了英语和中文之外的多语言覆盖范围。
数据处理流程也经过改进,在保持语料多样性的同时降低了数据冗余。系统采用文档打包方法维持数据完整性,但训练过程中不使用跨样本注意力掩码。最终训练语料库包含 14.8T 经 tokenizer 处理的高质量多样化 token。在挑选数据,清洗数据,处理数据上都做到够好,那么训练的结果也就不错。
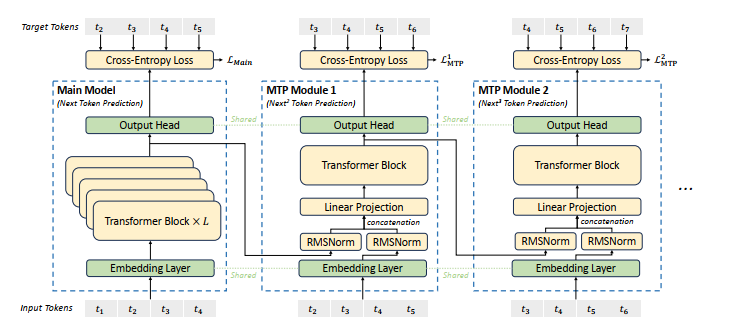
多 token 预测机制 (MTP)
DeepSeek-V3 创新性地采用了 MTP 目标,将预测范围扩展到每个位置的多个后续 token。
这种设计具有双重优势:
首先,MTP 目标通过增加训练信号的密度可能提高数据利用效率;其次,它使模型能够提前规划表征,从而更准确地预测后续 token。
知识蒸馏
DeepSeek-R1蒸馏,提取推理模式和解题策略,将DeepSeek-R1系列模型的推理能力迁移至新模型。
研究发现了一个重要的平衡点:知识蒸馏能提高性能,但同时会显著增加输出长度。为此,DeepSeek-V3 在蒸馏过程中采用了经过优化的参数配置,以平衡模型准确性和计算效率。
研究表明,从推理模型进行知识蒸馏是提升模型后期性能的有效方法。当前研究虽然主要关注数学和编程领域的知识蒸馏,但这种方法在其他领域也展现出广阔前景。其在特定领域的成功表明,长链式思维蒸馏技术有望提升模型在其他需要复杂推理的认知任务中的表现。未来研究将继续探索该方法在不同领域的应用。
基于以上三点,DeepSeek在降低工作量,提高性能的同时,能够确保模型评估的科学性和准确性,做到真正的性价比之王。
本文提到的技术特点仅涉及部分内容,仅限小编自己理解,希望大家轻喷多讨论。
引用参考:
-
https://arxiv.org/abs/2412.19437
-
https://zhuanlan.zhihu.com/p/14890557782
-
【一条全解DeepSeek:低成本做出顶级AI的神秘东方力量【实测|详解|影响分析】】 https://www.bilibili.com/video/BV1KFrYY7ErP/?share_source=copy_web&vd_source=5f89a4bb06698f9bf4c9d20b76088881


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









