









因为在开发中经常用到HashMap,HashSet等集合结构,但是一直对其中的Hash的意思不太理解。今天抽空查了一下资料,顺便记录一下现在的理解。
事先声明一下, 此文只介绍哈希表的数据结构,不介绍具体的Hash算法
首先我们不要去想Hash表是用来干嘛的,先以实际问题着手。就是现在需要一个能够存储Key-Value的数据结构。再不用Hash表的话,我想到的方法是定义一个有两个属性Key-Value的类,然后用一个数组来存。如下所示,
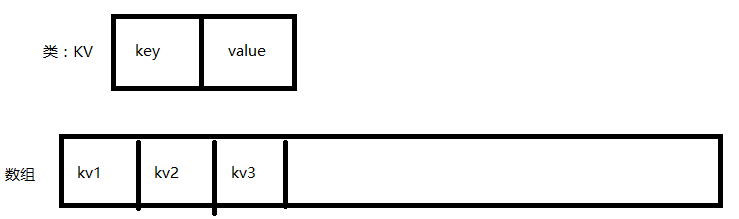
采取这种方法的话,如果要查找某个特定的元素,就需要遍历整个数组,直到找到为止。
有没有什么办法可以提高查找的速率呢?这就轮到Hash表出场的时候了。Hash表在我的理解中就是使用了Hash映射的一个数组。一般我们使用数组的时候,是从索引为1开始,一个一个存数据,但是Hash表的话,不是这样的。
Hash表存数据是这样的一个步骤:
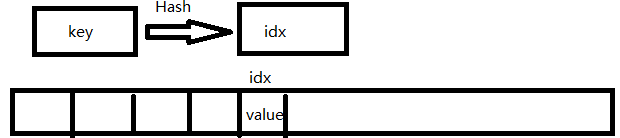
- 通过特定的Hash算法得到Key的Hash的值,即 addr = H(key)
- 将Addr作为存放这个Value的索引值,即 idx = addr
- 然后将Value赋值给数组索引为Idx的值,即 arr[idx] = value
那为什么使用Hash表可以提高查找的效率呢?因为把key变成了Hash值之后,直接可以利用数组的随机访问得到value值,而不用去遍历了,这样就提高了查找效率。如下所示,
如果不同的key计算出了相同的Hash值,那么只需要把此数组存储的value变成一个链表就可以了,这就是HashMap的底层结构了。















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









