






今天的介绍会围绕下面四点展开:
-
Flink CDC 技术
-
海量数据集成的痛点
-
Flink CDC 如何加速海量数据集成
-
开源社区发展
01
Flink CDC 技术
广义的概念上, 能够捕获数据变更的技术, 我们都可以称为 CDC(Change Data Capture)。通常我们说的 CDC 技术主要面向数据库的变更, 是一种用于捕获数据库中数据变更的技术。
CDC 技术主要有三类应用场景:
①数据同步: 用于数据备份、系统容灾
②数据分发: 一个数据源分发给多个下游
③数据采集: 面向数据仓库/数据湖的 ETL 数据集成
业界 CDC 的技术方案非常多,从原理上可以分为两大类:一类是基于查询的 CDC,一类是基于日志的 CDC。
基于查询的 CDC 优点是实现简单,是通过批处理实现的,需要依赖离线调度,不能保证数据强一致性和实时性。基于日志的 CDC 实现比较复杂,但是可以实时消费日志,流式处理,可保证数据一致性和实时性。
与开源 CDC 方案 Debezium、DataX、Canal、Sqoop、Kettle 和闭源 OGG 等方案对比,Flink CDC 在功能和架构方面优势明显。Flink CDC 支持全量和增量一体化同步、断点续传,支持分布式架构、支持事务,生态友好。
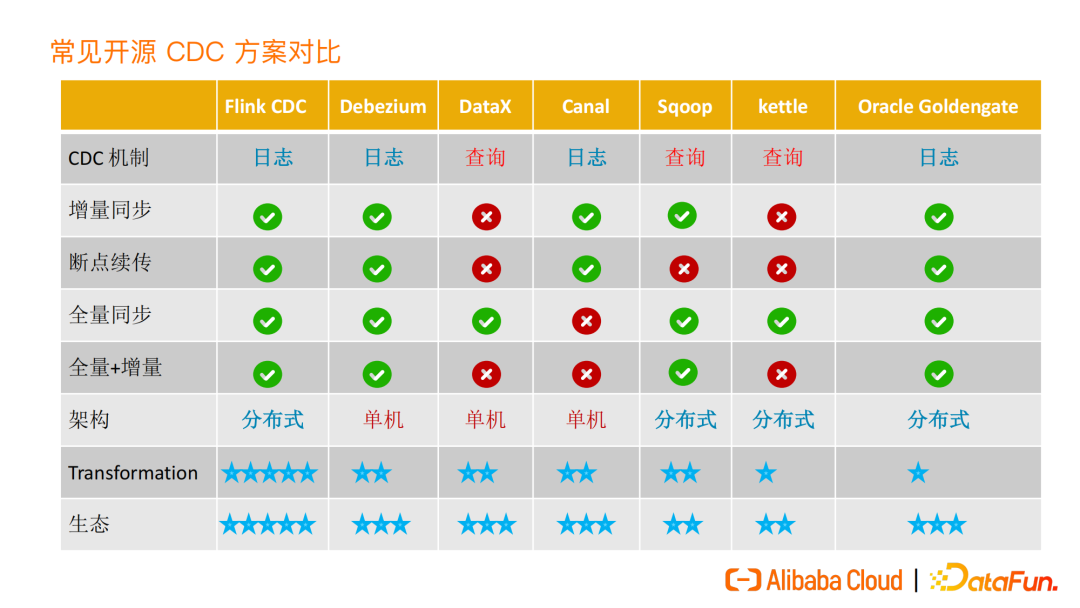
Flink CDC 支持全量和增量数据一体化同步,首先读取数据库中表的历史全量数据,再无缝衔接到读取表的增量数据,为用户提供实时的、一致性的快照。
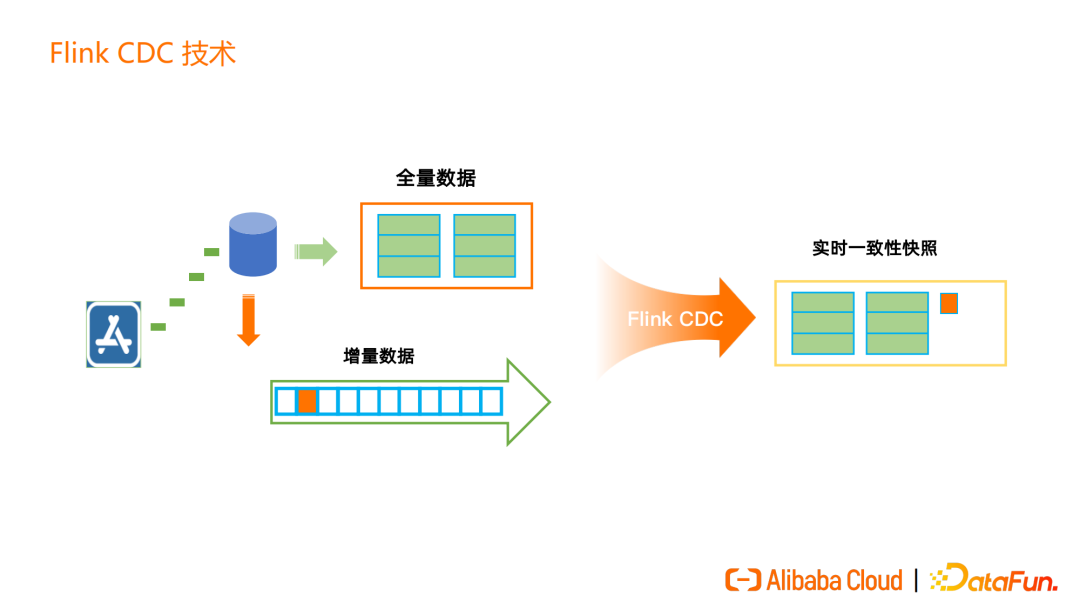
整个过程中,全量同步与增量读取无缝衔接,不需要用户进行手动干预或切换。
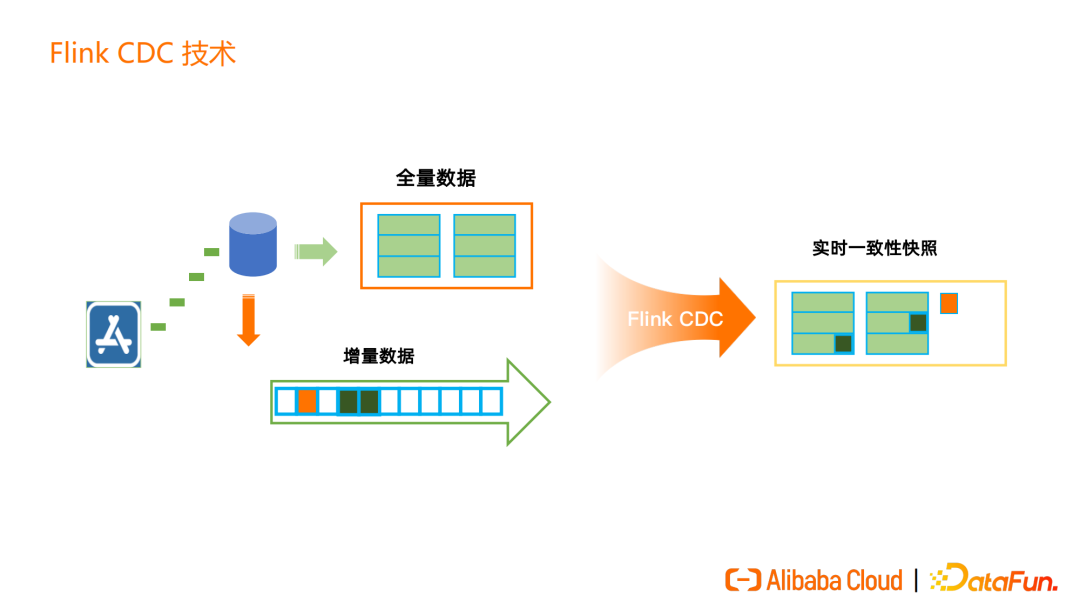
比如一张表中有全量的历史数据,同时增量数据也在不断写入。增量的 update 数据会在实时一致性快照内进行更新,insert 的数据则会追加到实时一致性快照中。
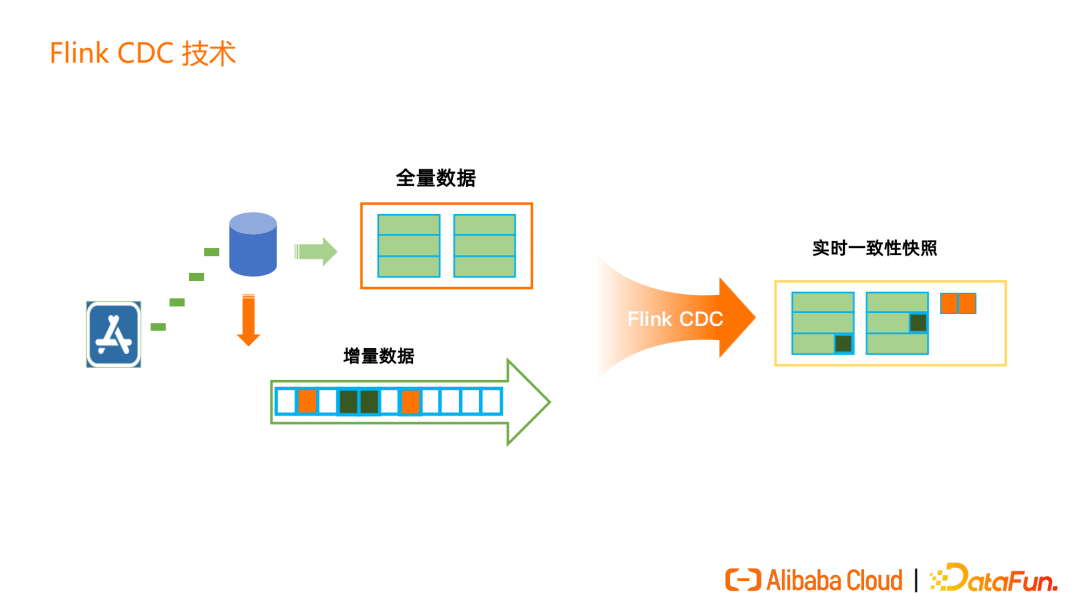
Flink CDC 核心技术就是提供实时的的全增量一体化同步。
02
海量数据集成的痛点
传统数据入仓架构1.0仍然有不少公司在使用,该方案通过 DataX、Sqoop 将数据以全量同步的方式写入到 HDFS 再导入到 Hive 构建离线数仓。
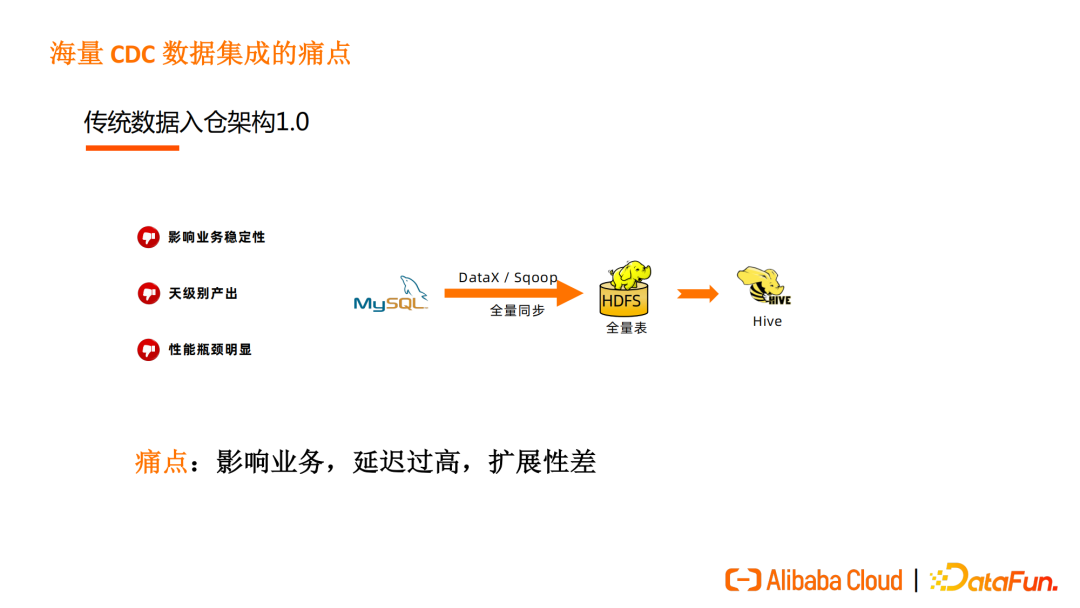
这种方式需要按批从 MySQL 等业务数据库拉取数据,通常一天做一次数据同步。拉取数据时会拖慢业务数据库,同时由于其按批同步、影响业务数据库性能的特点,导致数据延迟高,且该架构扩展性差,当大表越来越多、业务扩展越来越快时,拉取全表的性能会成为数据同步的瓶颈,导致数据延迟增加。
传统数据入仓架构2.0则是典型的 Lamdba 架构,把全量数据和增量数据分为两条链路。依然使用 DataX 和 Sqoop 做全量数据同步,增量同步则使用 Canal 或 Debezium 将数据写入 Kafka,再定时回流将数据写入 HDFS,通过全量表和增量表定时合并数据,得到最终表。
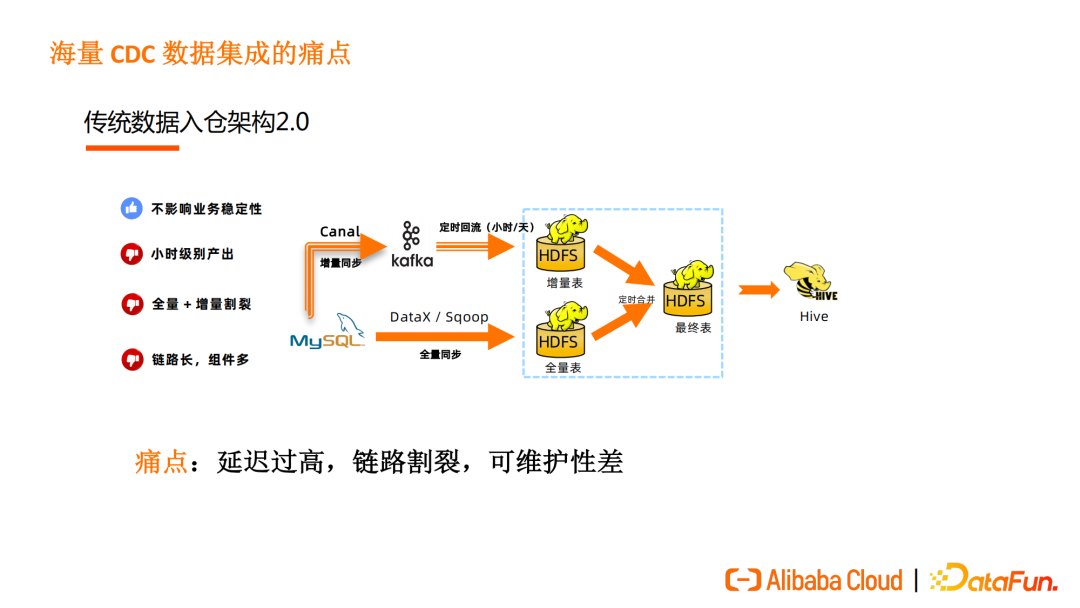
传统数据入仓架构2.0的链路长、组件多,可维护性差,且实时和增量同步之间互相割裂,依然存在数据产出延迟高、无法保证实时性的问题。
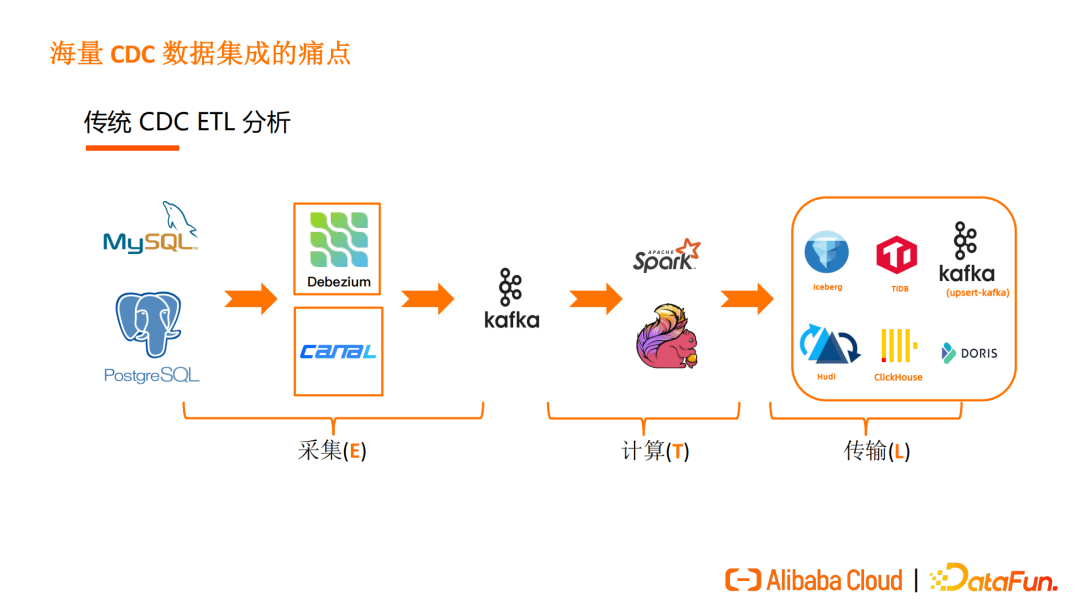
在 ETL 分析的场景下,传统 CDC ETL 分析的数据处理链路如图所示:用户会将数据库内的 CDC 数据通过 Debezium、Canal 等工具进行采集,传入 Kakfa 后经过 Spark 或Flink等计算引擎的加工、处理,写入下游存储。
Debezium 是单并发模型,且存在锁的问题,可能影响吞吐量;Canal 只支持读取增量数据,全量数据导入需要额外引入 DataX 或 Sqoop 组件,全量和增量衔接还需要用户手动合并数据。
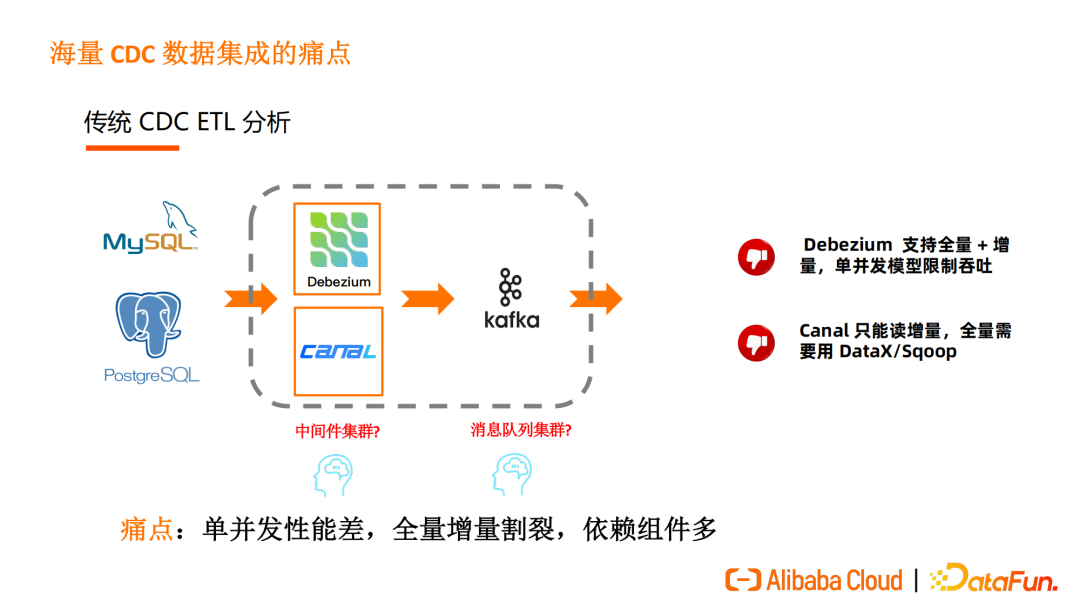
传统ETL的整个链路依赖组件多,维护成本高,单并发性能差,全量增量割裂。
作为新一代数据集成框架,Flink CDC是如何处理、加速海量数据集成过程的?
03
Flink CDC 如何加速海量数据集成
1. 全、增量一体的分布式数据集成框架
Flink CDC 的核心是增量快照读取算法。熟悉 Flink CDC 社区的同学应该了解,Flink CDC 早期使用 Debezium 做了一个单并发的版本。由于 Debezium 会使用锁而且是单并发的,在海量数据的场景下吞吐量受限。在全量同步阶段若发生失败,Debezium 会重跑整个任务,如一张表有上亿条记录,全量同步耗时1天,在运行了23小时后任务失败,此时 Debezium 只能重跑任务,这样的重试在用户的生产环境难以容忍、难以承载海量数据集成的需求。
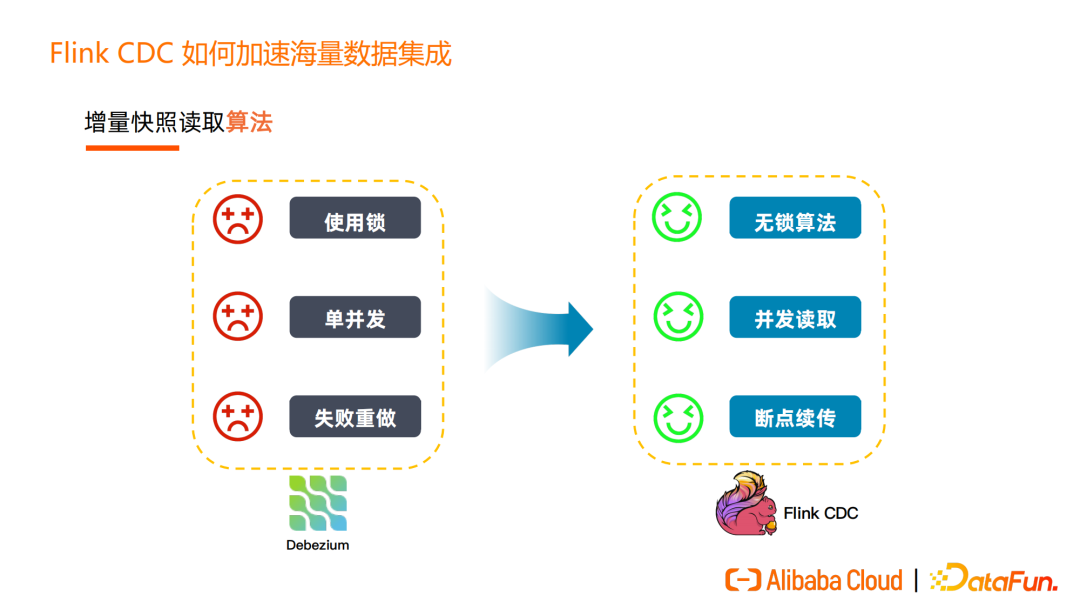
针对这些缺点,Flink CDC 通过快照读取算法进行了改进。Flink CDC 引入了无锁算法,MySQL 生产库不需要上锁即可实现数据集成,降低了风险和数据库压力。Flink CDC 支持并发读取,在全量数据同步阶段可以更快地完成海量数据同步,可以通过水平扩展节点数来加快数据处理速度、加速海量数据的处理。Flink CDC 实现了断点续传,比如同步数据需要1天时间,但是同步任务运行23小时后失败,不需要重跑整个数据同步任务,只需要从发生错误的位置重跑即可。
Flink CDC 增量快照框架处理流程如下图所示:全量阶段把表分为一个个切片(chunk),每个分片被分配到不同task,并行地读取。全量读取完成后,通过无锁算法全自动地完成全量同步到增量同步的无锁一致性切换。
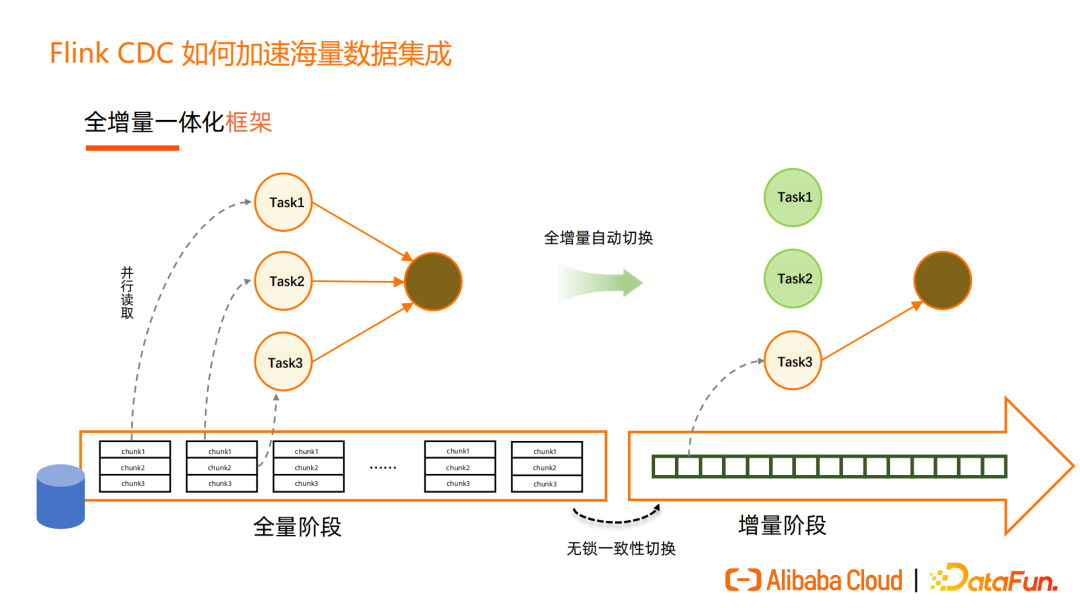
增量阶段,数据库的写入相对较少,如 MySQL 的 Binlog 只有一个文件在写,Flink框架提供了缩容能力,可释放多余的 Task 减少资源消耗,图上中的 Task1、Task2 被释放,达到资源伸缩的效果。
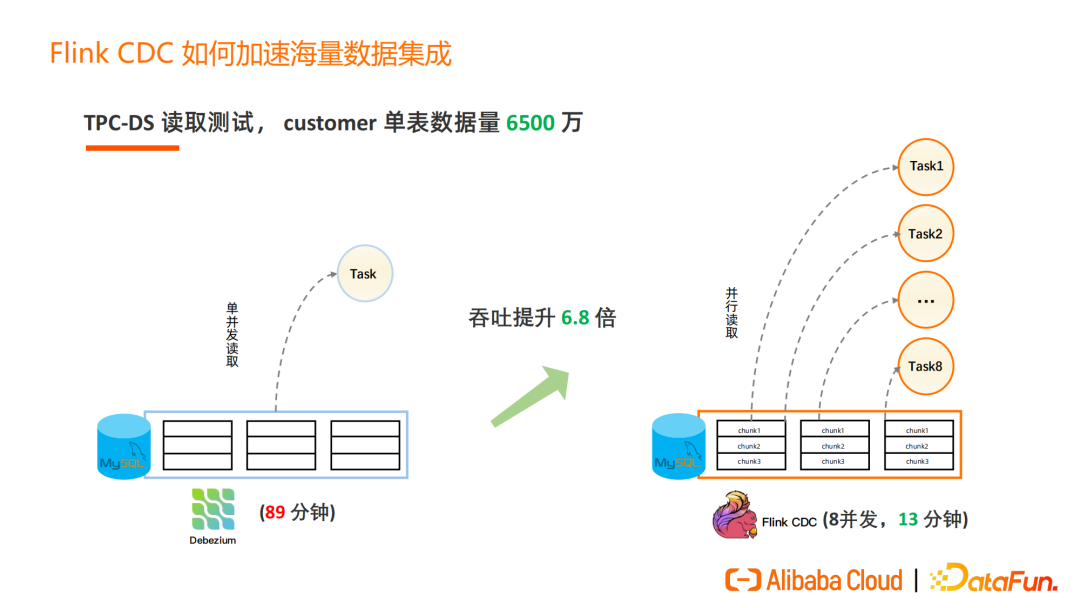
Flink CDC 2.0 增量快照读取算法实现后,我们进行了 TPC-DS 的读取测试。1T标准数据集中的一张 customer 表,单表数据量 6500 万。用 Debezium 单并发读取需要 89 分钟,使用 Flink CDC 时 8 个并发读取,13 分钟便可完成读取,吞吐量提升了 6.8 倍,当然全量同步阶段的并发性能提升和并发数是线性相关的。如果用户需要更大吞吐量,可通过提高并发数达到提升数据同步速度的目的。
Flink CDC 可以很好地把数据导入到 Hudi、Iceberg 和 OLAP 系统,使用 Flink CDC 代替传统的数据入仓、入湖架构,如下图所示,大大简化了入湖链路。
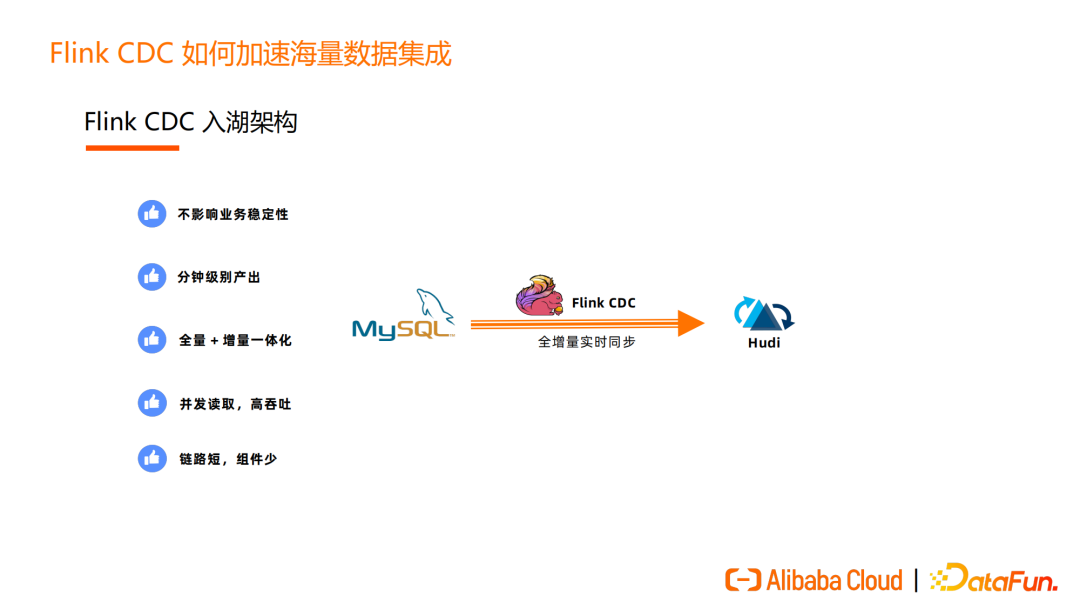
Flink CDC 的数据同步不影响业务稳定性,可以做到分钟级别产出,适合当今海量数据场景和时效性要求高的业务。Flink CDC 的分钟级别数据产出,配合 Hudi 可实现近实时的分析,可满足绝大部分业务分析需求,全量+增量一体化数据同步,并发读取等特性对业务更加友好。
Flink CDC 可以替代传统 ETL 架构,只需通过 Flink CDC 即可完成采集、计算、传输,并且全增量一体化无需人工介入切换模式。Flink CDC 实时地加工数据,在 Flink CDC 内完成 ETL 过程后可将数据导入到下游的 Kafka、消息队列、数据湖、OLAP等,对数据进行进一步分析处理。Flink CDC 可并发读取,数据采集和处理速度快,整个 ETL 链路短、组件少,方便维护。
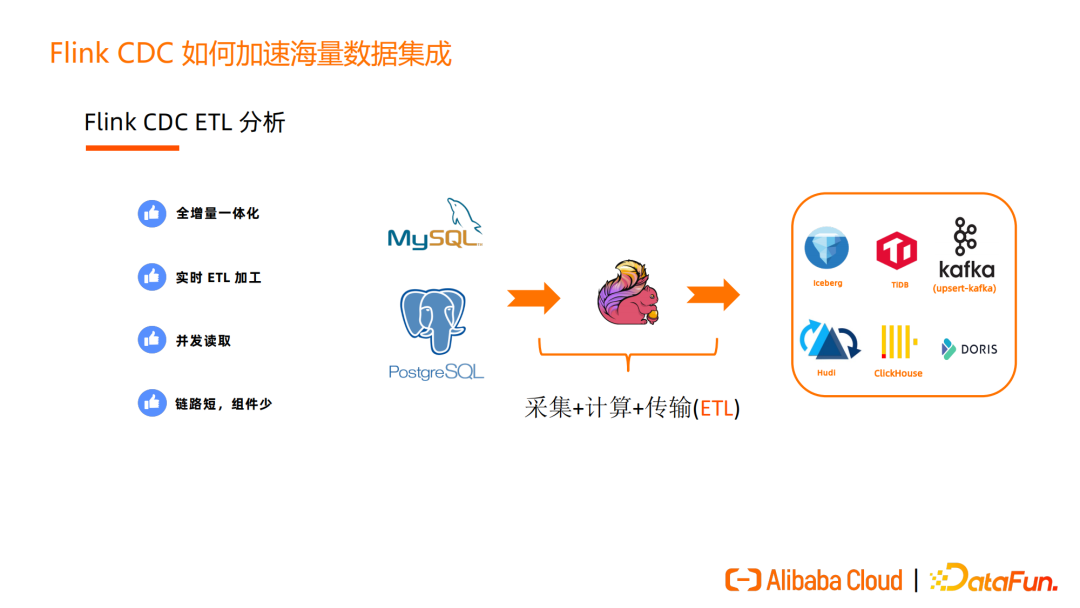
Flink SQL 具有强大的 transformation 能力,通过 Flink SQL 即可完成ETL 中的数据转换,Flink CDC 也把 Flink SQL 这部分能力对外暴露给用户。
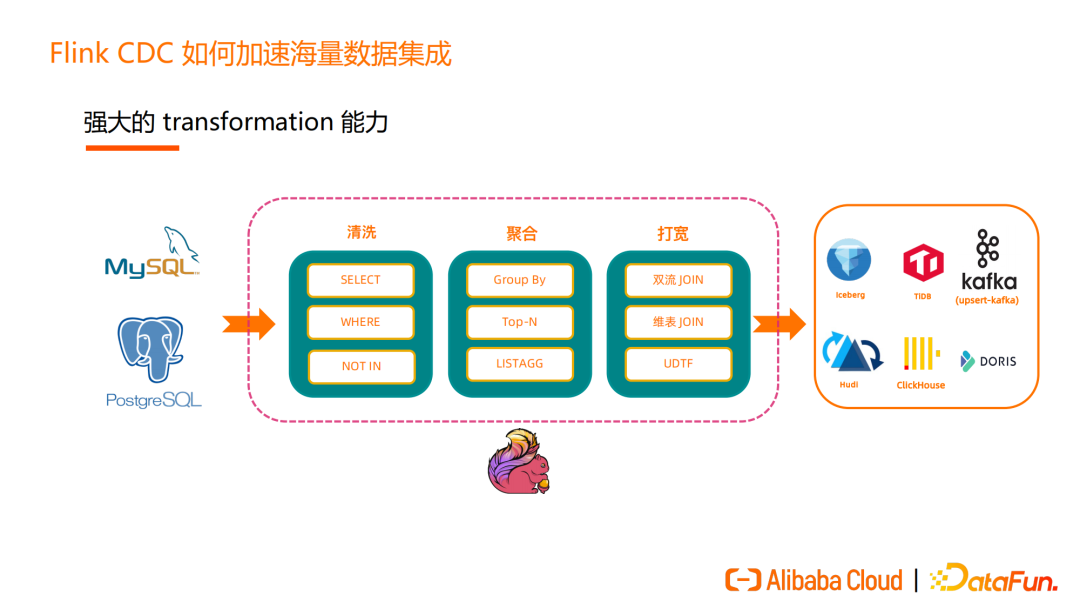
接入Flink CDC后,用户 ETL 可以通过 Flink SQL 实现 select、where、not in 等过滤处理,使用 group by、Top-N 等更复杂的聚合操作,还可以对数据做 Join 打宽。这些是传统的 ETL 工具不具备的能力。
2. 多样的业务场景支持
Flink可以支持多种业务场景下的各种需求:
①异构数据源集成。
②由于业务发展等各种缘故,有的业务数据库是基于 MySQL 的、有的业务基于 PostgreSQL,需要连接两张表做打宽分析。此时引入 Flink CDC 可以做 Streaming Join 的流式加工,将打宽后的表写入到其他存储中。Flink CDC 支持多种数据源的 connector,使用 Flink CDC 可以很方便地完成异构数据源的融合。整个过程中,只需要写5行 Flink SQL 即可实现异构数据源集成。
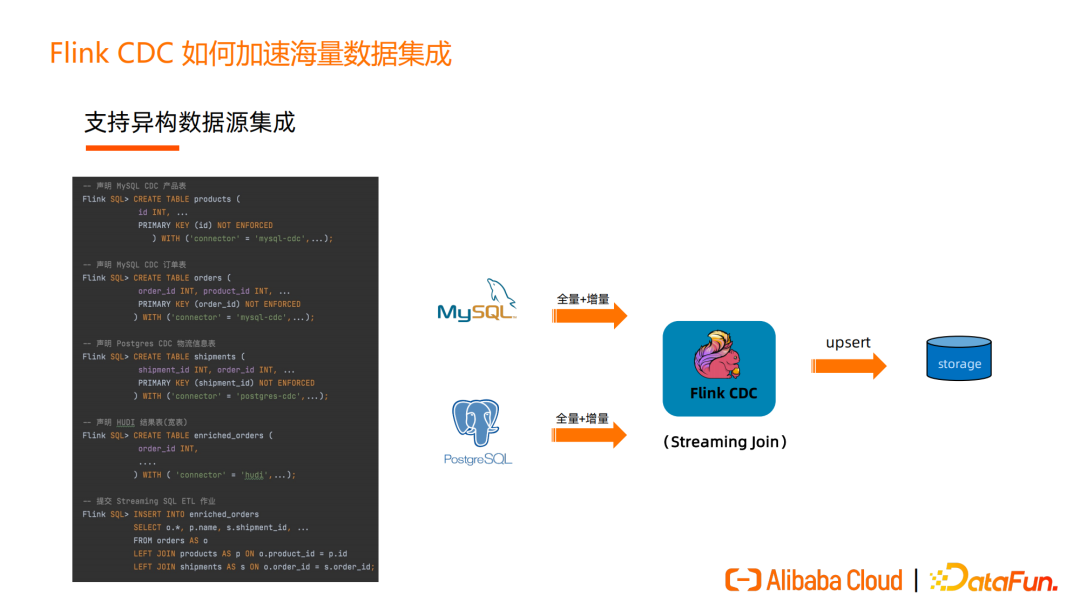
以上图左侧的 SQL 为例,首先声明一张 MySQL CDC 订单表,再声明一张 MySQL CDC 的产品表,再声明一张 PostgreSQL CDC 的物流表,最后声明一张 Hudi 结果表。只需要通过 Flink SQL 即可以完成 Streaming Join 获得大宽表,用户不需要了解底层技术、BI或数据分析人员也可以完成复杂的实时数据处理。
(1)支持分库分表的集成
当业务规模大到一定程度时,基本都会使用 MySQL 的分库分表方案。但传统的数据集成方案中,要把分库分表后的数据同步到下游数仓非常麻烦,需要一张一张表地同步。而使用 Flink CDC 可以很简单地完成分库分表后的数据同步。下图中左侧的 SQL 是把分库分表的 MySQL 数据同步到 Hudi,以此为例,只需3行 Flink SQL 即可实现。

第一行 Flink SQL 是声明 Flink CDC 的用户表。数据库、表参数支持正则表达式,用于匹配多个库和多张表,user_source 表即代表分库分表内的数据。第二行 SQL 声明了 Hudi 结果表,其中 database_name、table_name 是表的元数据信息,通过 Flink SQL 的 Metadata Column 语法支持用户获取表的元数据信息。分库分表数据同步到下游存储中后可以带着这些信息,比如 Hudi 表中的记录可以带上这些信息,只需要三行 SQL 便实现了分库分表的数据集成。Flink CDC 社区用户群中,有些中大型公司使用分库分表的数据同步能达到上万个表,这一功能很好地满足了海量数据集成场景下的刚需。
(2)支持丰富的 Flink 生态
Flink CDC 拥有丰富的生态,支持多种数据源。如下图中展示了一部分数据源,Flink CDC 支持关系型、非关系型数据库,支持云上数据库和传统的数据库。Flink CDC 在数据源方面的支持已经非常完备,Flink CDC 社区也将不断丰富更多数据源。
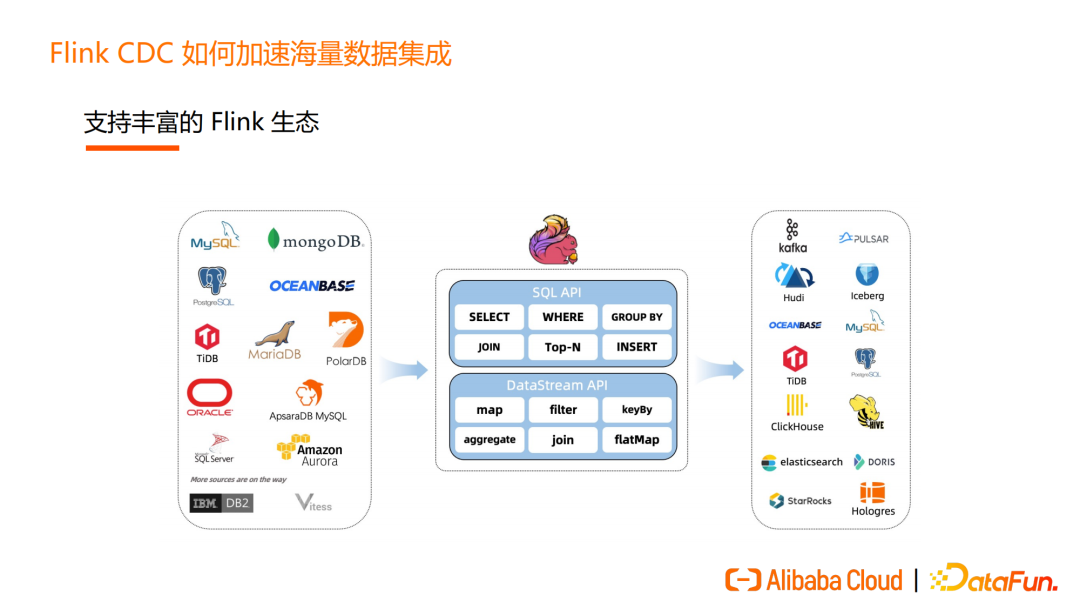
依托于Flink,用户还可以根据场景,选择 SQL API 或 DataStream API实现自己的需求。SQL API 可以让 BI 和分析师轻松完成数据处理需求。DataStream API 被很多用户用来做整库同步、分发数据到不同下游,具备一定开发能力的用户可以选择 DataStream API 方案。Flink CDC 借助了 Flink 丰富的生态,在数据集成时对下游的选择有很大的灵活性和扩展空间。
04
Flink CDC 如何加速海量数据集成
Flink CDC 是一个完全开源的项目,遵循的 Apache Licence 2.0 也是对用户最友好的开源协议。过去一年中,Flink CDC 发布了1.X、2.0、2.1、2.2版本,每个版本的 Commit 数和 contributor 数越来越多,我们最新版本的 commit 数已经达到近 120 个;贡献者达到了 35 人,来自国内外、各中大型公司。
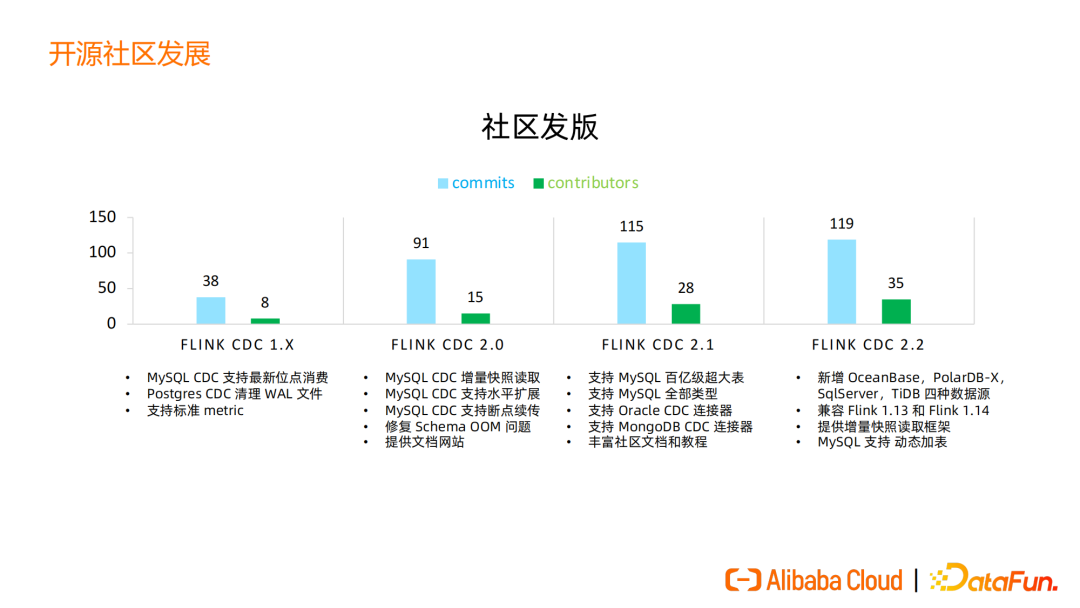
Flink CDC 2.0 是一个里程碑版本,支持了增量快照读取算法、支持了水平扩展、断点续传等功能。
在2.1版本中,我们对 MySQL 这种百亿级超大表达到了生产环境的支持,完成了 MySQL 的全类型,新增了 Oracle 和 MongoDB 数据源。Flink CDC 2.2 版本增加了 OceanBase、PolarDB-X、SQLServe、TiDB 四种数据源,同时提供了兼容 Flink 1.13 和 Flink 1.14 的功能,同一个 CDC connector 既可以在 Flink 1.13 的集群上运行,也可以在 Flink 1.14 集群运行,用户不需要去做定制化适配,非常友好。
2.2版本还提供了增量快照读取框架。此前只有 MySQL CDC 可以实现增量快照读取算法,这一框架可以让其他数据源也可以更方便地扩展、实现增量快照读取。目前 OceanBase 社区的增量快照读取已经有开发者完成了, SqlServer 等数据库的增量快照读取的 PR、Issue 都已经陆续开放。2.2版本支持了动态加表,Flink CDC 的数据同步作业可以动态地添加表,让数据同步任务不停止可增加,方便维护,减少新建数据同步任务的工作。
作为一个开源社区,社区的文档是非常重要的,Flink CDC 提供了独立的社区文档网站,前端页面由贡献者开发。我们提供了完善的入门文档和FAQ手册,FAQ手册提供中文英文版本,帮助用户降低上手门槛。

上手文档中的 demo 都是通过 docker 容器运行的,不需要任何依赖,只需要在电脑上装好 docker 即可体验 Flink CDC。
在 GitHub 上,Flink CDC 项目放在 Flink 商业公司 ververica 的 Flink CDC connector 项目下,目前有2.3k star、700多Fork,活跃Issue 300+,已经解决掉400多Issue。
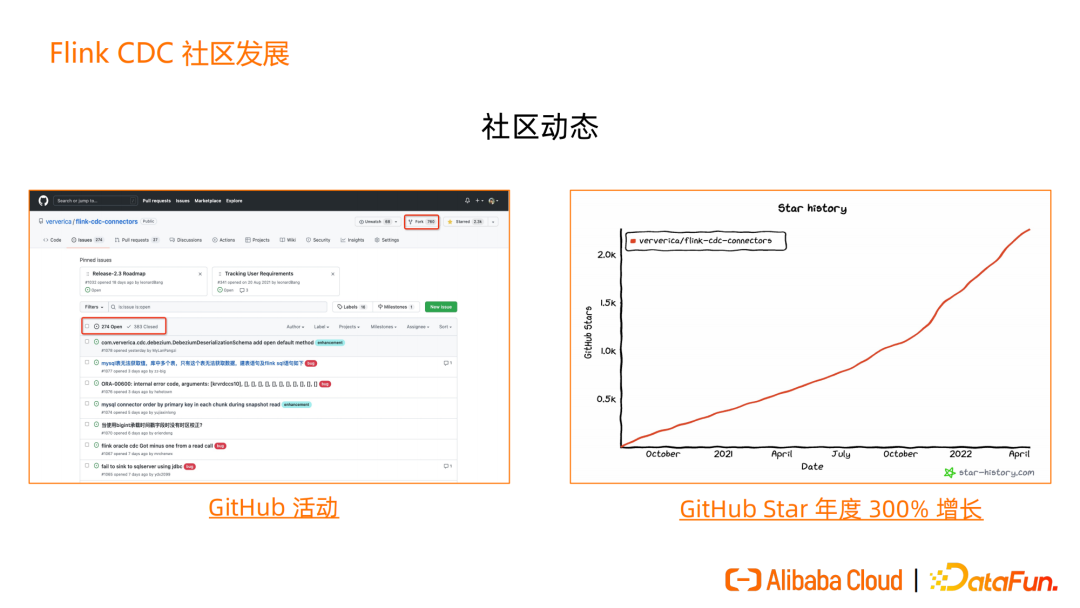
GitHub star 数量在 2021 年达到了 300% 增长。















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









