







HDFS
1. HDFS 深入理解
1.1 解决了什么问题?优点是什么?
- 还记得第一章中的 文件存储 设计么?当存储数据 大小,超出了一台服务器的承载能力时,该怎么存储?
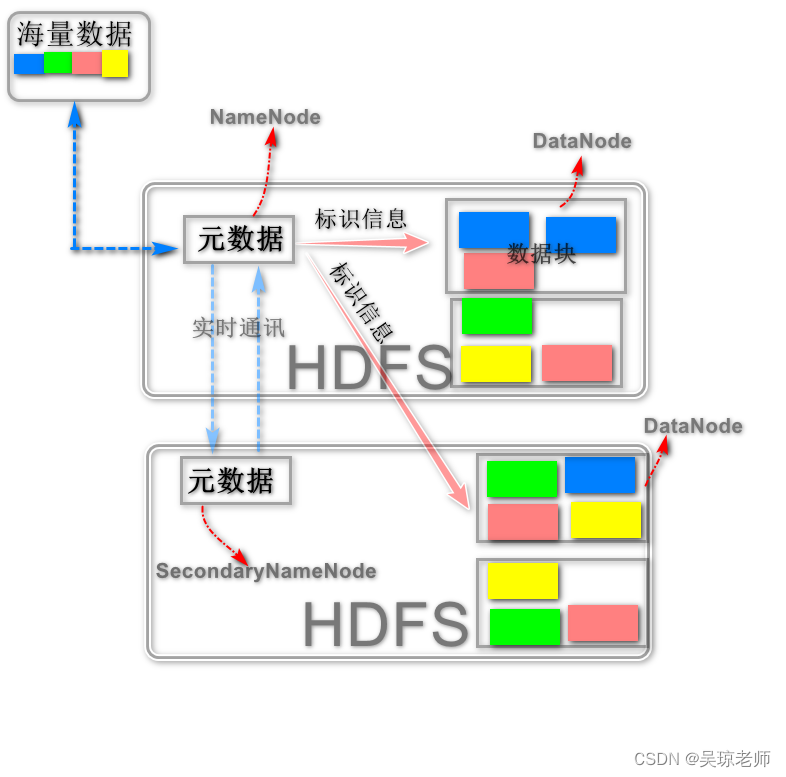
1.2 HDFS基本结构
- 从执行的进程中可以发现以下几个进程
jps
1.2.1 NameNode
- 类似于一个"老大",是HDFS的管理者,它的职责主要有3个方面:
- 负责管理元数据文件,Namespace镜像文件(Namespace image)和 操作日志文件(edit log)
- 负责管理DataNode上数据块(Block)映射(位置)>文件名–数据块,维持副本数量 (默认3份)。
- 负责客户端的请求,如 文件操作,上传,下载创建目录等。
- 一句话:管理,存放目录与块之间的关系(通过两个镜像文件实现),数据与节点之间的关系。
1.2.2 SecondaryNameNode
- 类似于一个“副手”,主要工作是从NameNode上 下载元数据信息,
- 然后二者合并,并更新,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits(防止edits文件过大,导致Namenode启动时间过长)。
- 可以充当NameNode中一个 “冷备份”。
1.2.3 DataNode
- 是HDFS中真正存储数据的地方,那就必须要提到一个概念 “文件块(Block)”,因为DataNode读取数据是按照Block去读取的,Block也是hdfs中读取的基本单位。
- 同时DataNode也需要定期向NameNode报告自己的状态,3s一次,告诉NameNode我一切正常,如果出现失联状态,比如10分钟,没有联系,NameNode会尝试唤醒这个节点,如果唤醒失败,则宣告该节点不能使用, 同时会将其节点上得数据块复制到其他机器上。
- DataNode 节点会从其他节点复制文件块,并同时接受客户端的读写操作。
1.3 HDFS 缺点
- 不适合处理低延迟的数据访问,啥意思?
- 负责管理元数就是你用户操作完立马需要数据,它做不到!HDFS主要处理高数据,海量数据的吞吐量的应用。
- 不适合处理大量的小文件,啥意思?
- NameNode会把文件元数据在内存中加载,文件系统的容量是由NameNode内存大小决定的(NameNode中的元数据,每个小文件都占150bytes,所以如果小文件很多的话, 内存就吃紧了。注意:不是不适合存小文件,而是不适合纯海量小文件。),小文件太多会消耗NameNode的内存。
- 不适合处理多用户写入和任意修改文件,啥意思?
- HDFS不支持多个客户端对同一个文件的写操作,以及在文件的任意位置进行修改数据。它适流式的数据的读取工作。write-once-read-many
2. NameNode中元数据
2.1 格式化NameNode作用
- 当第一次执行
hadoop namenode -format之后,这个指令动作后会生成fsimage 和 edits这两个核心文件。- fsimage: 保存HDFS所有文件系统的目录树(id、类型、目录、所属用户、用户权限、时间戳……)。
- edits: HDFS客户端执行所有的写操作都会被记录到editlog中。
- 并且格式化NameNode会产生新的 集群id,是DateNode和NameNode,其它DataNode的通讯身份标识。
- 如果频繁格式化会导致NameNode和DataNode的集群id不一致,集群启动不成功,或者找不到数据。
2.2 话题:fsimage和edits合并原理
-
假设两个文件不合并: 当HDFS集群运行一段时间后,猜一猜会出现什么问题 ?
- HDFS主要是存储和管理数据,肯定会涉及到频繁的增删改查,会产生大量的 操作动作记录。
- fsimage文件会越来越大,因为管理记录很多文件目录,导致越来越臃肿,每次重启都需要加载此文件和edits文件。 时间越长,重启越慢。
-
所以为了解决此类问题产生,减轻NameNode的压力,就需要
SecondaryNameNode去实行它的工作职责去定期合并这两个文件。 -
因为这个合并过程很长,如果让NameNode自己去做,可能会影响正常的读写操作,这两个合并的整个过程就叫做 CheckPoint, 叫做元数据备份机制。
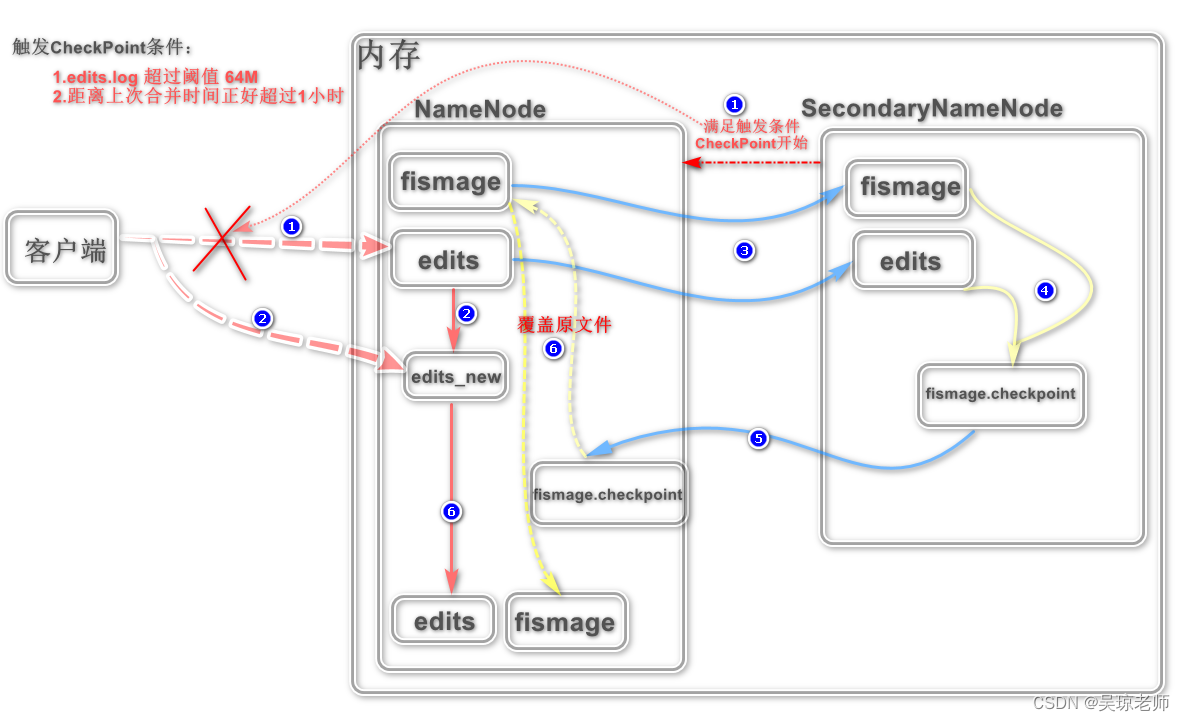
- 合并图原理简要说明:
- 客户端正常更新数据时,NameNode通常会先将操作数据动作,记录在
edits.log上,然后在加载内存中修改实际数据。
假设,此时正好又触发了CheckPoint的条件, 停止正在更新操作,并将操作一半的数据需要回滚,同时会将操作行为记录在新生成的edits_new.log上。 - 因为触发了CheckPoint 需要合并文件,所以客户端的操作行为记录,会记录在新的
edits_new.log上。 - 此时 SecondaryNameNode 会将两个文件通过远程协议拷贝到SecondaryNameNode 节点上,进行合并操作。
- 将拷贝过来的两个文件,合并生成新的镜像文件
fismage.checkpoint。 - 将新生成的 **
fismage.checkpoint**发送给NameNode所在的节点机器,这个时候注意, 根据hdfs-site.xml中的配置,如果不修改默认为备份2个fismage,所以当新生成第三个的时候就会覆盖。 - 当将新的fismage生成的同时,edits_new.log 会生成新的edits.log。
- 客户端正常更新数据时,NameNode通常会先将操作数据动作,记录在
总结一下: SecondaryName 相当图NameNode的冷备份,因为SecondaryNanmeNode拿到的是以前的历史数据。
3. Block 文件块
-
Hadoop存储数据是以Block存储的,也是HDFS读取的最小基本单位。
- 这个是物理上真真实实的进行了划分,数据文件上传到HDFS里的时候,需要划分成一块一块,每块的大小由
hadoop-default.xml里配置选项进行划分。
<property> <name>dfs.block.size</name> <value>67108864</value> // 64*1024*1024 64M <description>The default block size for new files.</description> </property> - 这个是物理上真真实实的进行了划分,数据文件上传到HDFS里的时候,需要划分成一块一块,每块的大小由
-
在Hadoop1.x 时 默认每个Block 是切割64M,在Hadoop 2.x时 为128M。
-
文件块,切块的大小可以设置, 128M ,256M,主要根据磁盘IO能力去设定。
- 假如,一个文件 129M,就会分成2个Block。 (实际只会占用129M空间)。
- block备份的位置就在配置的
tmp中。

3. 1 使用Block的好处
- 假设一个PB级别的文件,很少有单个服务器能存储的,所以,如果使用块的概念, 会把文件分割成许多块,这样这个文件可以使用集群中的任意节点进行存储。
- 数据存储要考虑容灾备份,即多地备份,可以在不同的地点,这就需要考虑传输问题,这样以块为单位非常有利于进行备份, HDFS默认每个块备份3份,这样如果这个块上或这个节点坏掉,可以直接找其他节点上的备份块。
- 因为备份机制,多个副本,可以使客户端在多个节点上去读取数据。
- 这样的好处:能够分散机群的读取负载,因为可以在多个节点中寻找到目标数据,减少单个节点读取。
3. 2 思考:HDFS上适合存储海量的小文件么?
-
首先,我们来一组数据实验然后再过来讨论这个问题 ?
- 为了方便计算,一个文件或者文件块占用NameNode的内存空间是
150字节(主要是文件信息和块信息数据,路径,id等)。
假设:
按照正常hdfs设置,现在有一个129M的文件,按照128M块大小会切割成2个block。
- 一个文件对象,2个块对象 相当于 3x150字节 = 450字节。假设有129个1M文件存储,会产生128个Block对象。
- 129个文件对象和 129个块对象 相当于 256x150字节 = 38400字节。针对于数据来说,存一个129M占 450字节,但是存129M小文件占 38400字节。 海量的小文件占更大的NameNode映射空间。
- 为了方便计算,一个文件或者文件块占用NameNode的内存空间是
-
其次,这里还涉及到一个点,硬盘寻道时间 ?
- 意思就是,指硬盘在接收到系统指令后,磁头从开始移动,到移动至数据所在的磁道(可以理解为找到数据) ,所花费时间的平均值,在一定程度上体现硬盘读取数据的能力。
- 如果,寻道时间为10ms,就是说找到一个block是10ms。那如果大量的小文件会大大增加了查找时间。
- 针对于,流式读取的方式,如果访问大量小文件,则必须从一个datanode跳转到另外一个datanode,这样大大降低了读取性能。
-
老吴认为:只能说Hdfs不善于存,而不是不能存,毕竟设计之初是为了解决大文件存储而设计的。
4. HDFS API
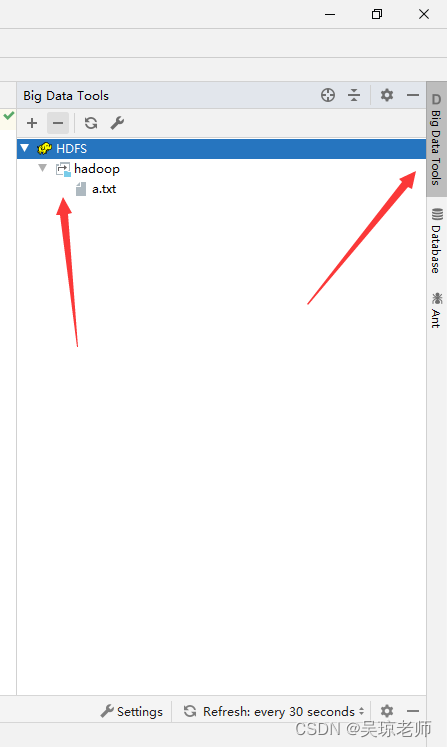
4.1 IDEA Big Data Tools
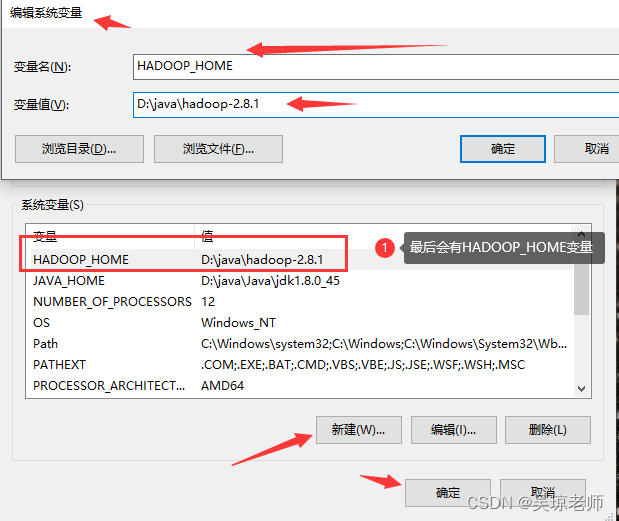
- 将Hadoop安装版本放拷贝到一个你自己喜欢的目录下,进行解压,然后配置环境变量。
- 需要注意的是,
hadoop-2.8.1.tar.gz将该安装包进行解压,要与linux中版本一致。 - 提示:每个电脑的环境不一样,不使用该工具也无所谓,不用强求。使用IDEA自带的可视化工具,该工具只是为了方便。也可以使用xshell一样。
- 需要注意的是,
- 此步骤时,正常连接不上,会报两个错误,解决方案做以下两个步骤:
- 配置HADOOP_HOME 环境变量的配置,同jdk配置一样。
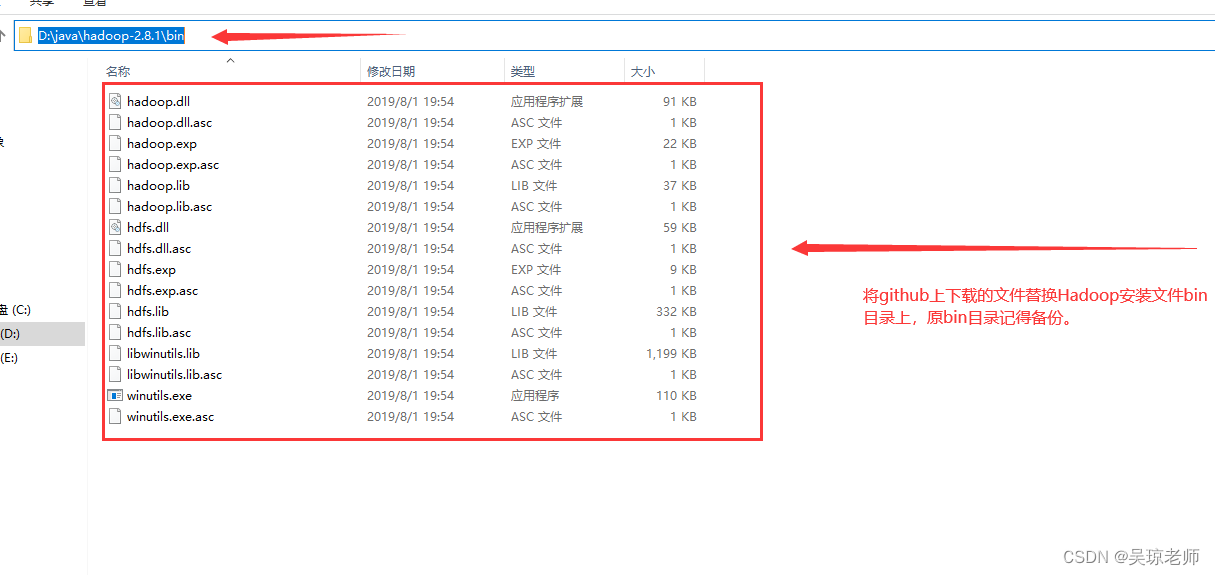
- 还有一个关于hadoop.dll 依赖问题,需要到githhub上下载,替换bin目录。
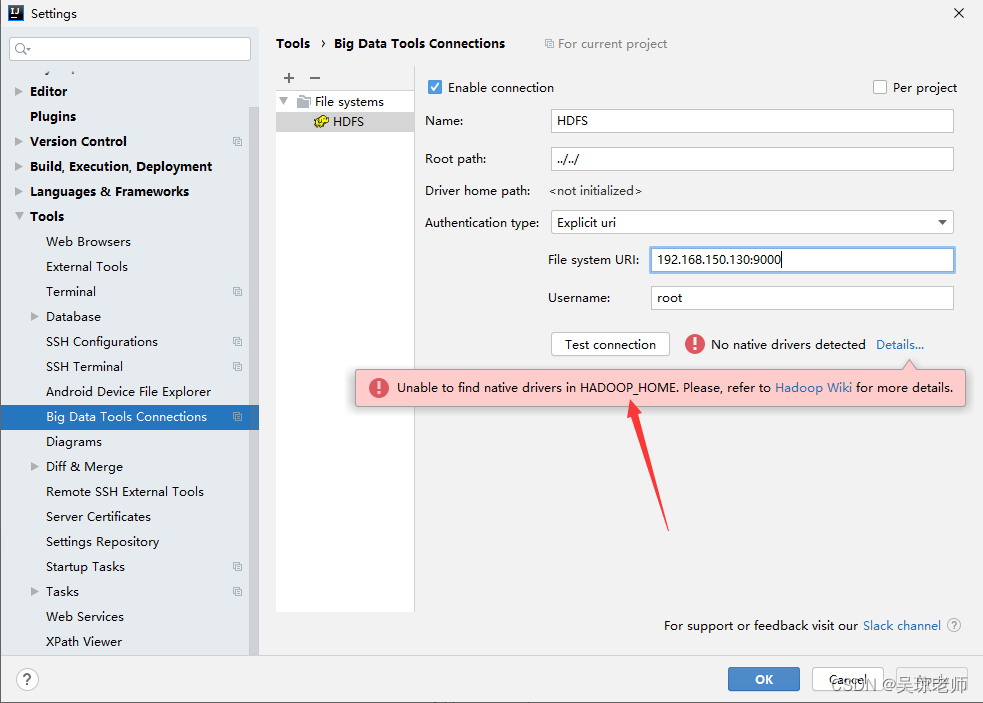
- 第二个错误提示:
On Windows you should have HADOOP_HOME environment variable defined or Java property hadoop.home.dir. Please, refer to Hadoop Wiki for more details
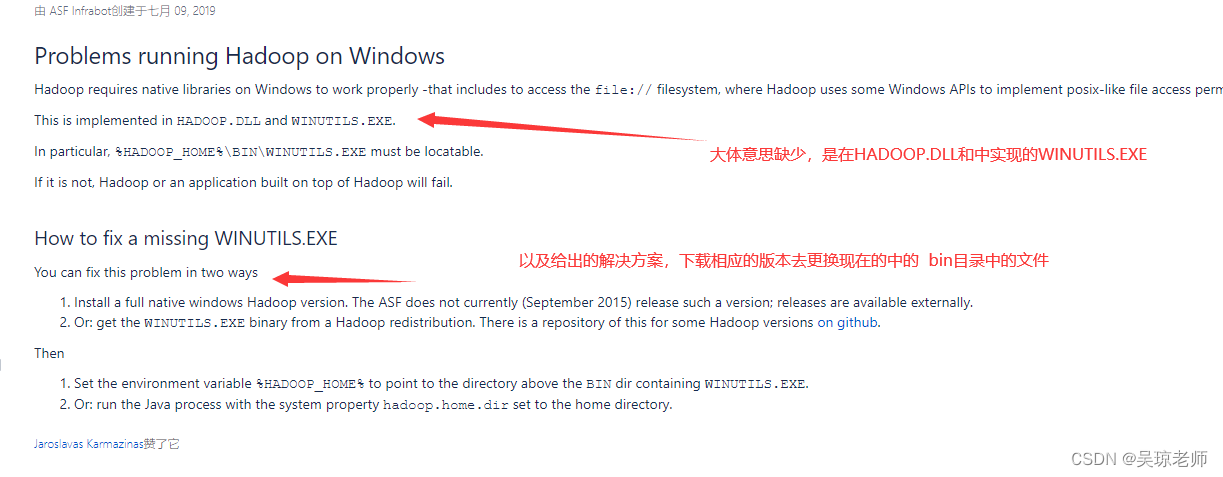
- 下载在GitHub上,有该配置文件。
- 下载目录,替换文件。
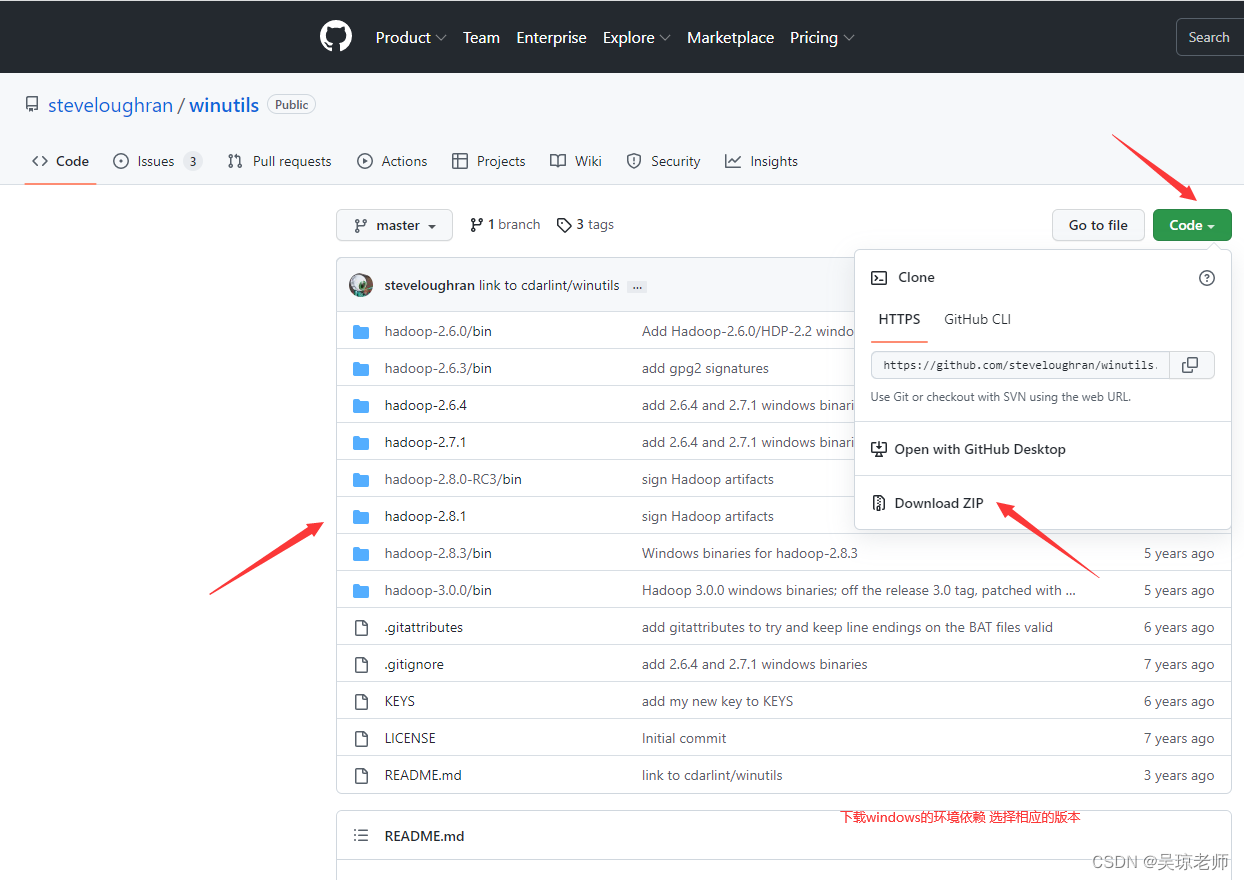
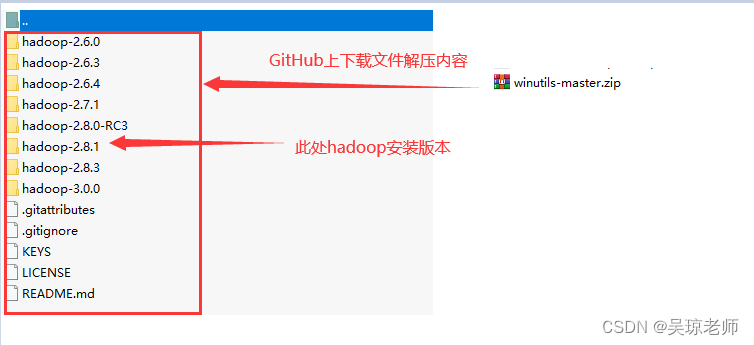
- 提示二:将下载的GitHub相应hadoop文件版本中的bin也需要,在
C:\Windows\System32下也来上一份,以免不生效 (如果单独拷贝一个hadoop.dll不成功的话)。
-
将安装版本的目录文件替换到,配置HADOO_HOME中的bin目录下,进行替换,注意原有bin保存。
-
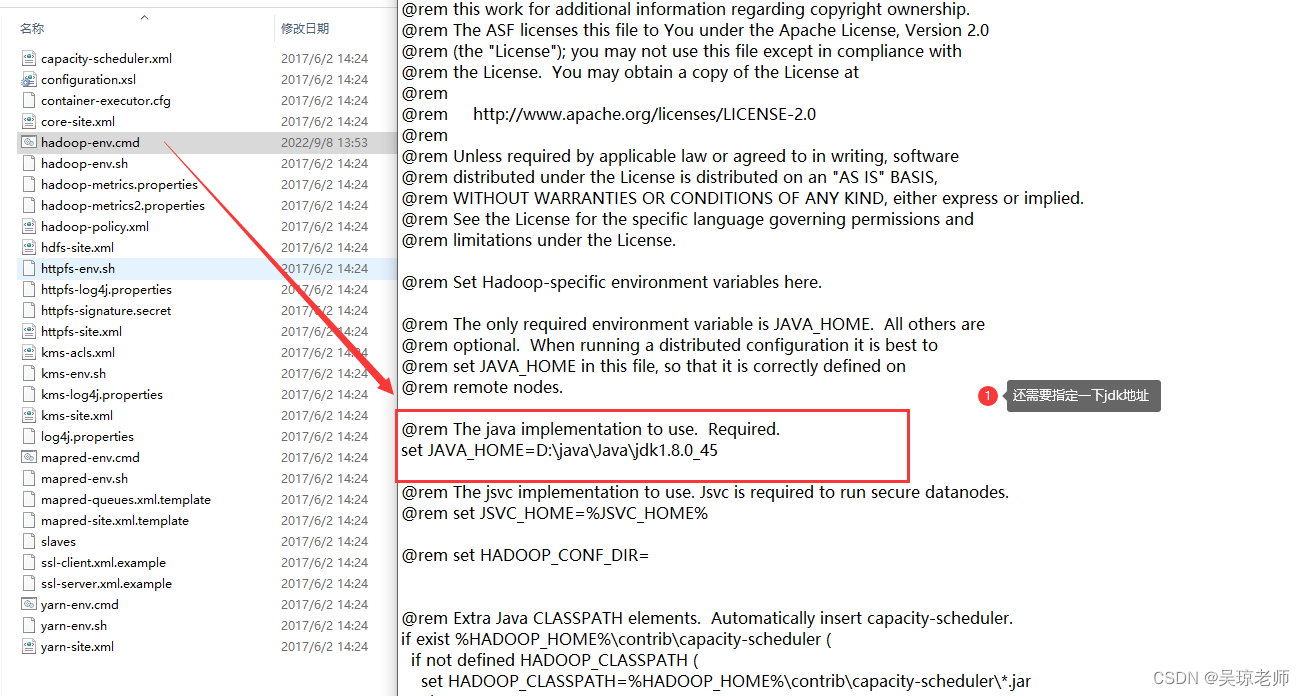
配置环境变量。和在Hadoop环境安装包中
D:\java\hadoop-2.8.1\etc\hadoop\hadoop-env.cmd中指定jdk目录
-
所有配置好后,到此步骤之前,记得要重启电脑。
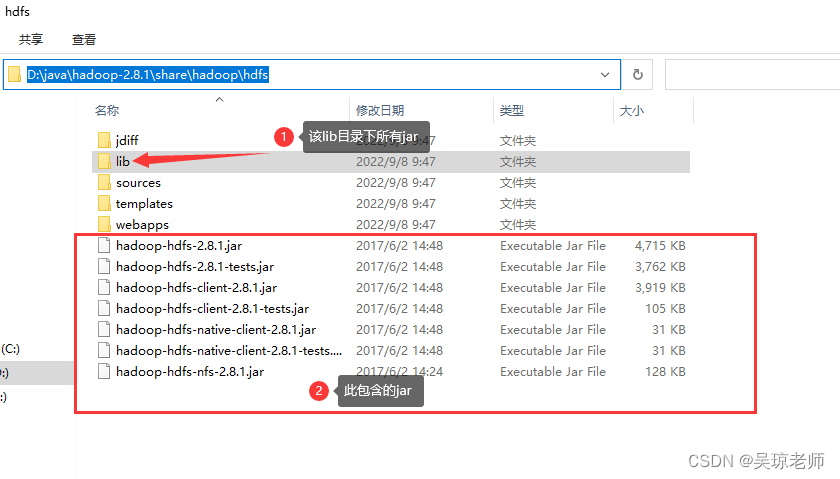
4.2 Hadoop 相关依赖jar包
- 将Hadoop的依赖jar包,复制到工程中的lib目录中。
- 具体需要多少jar为了,根据下图提示。
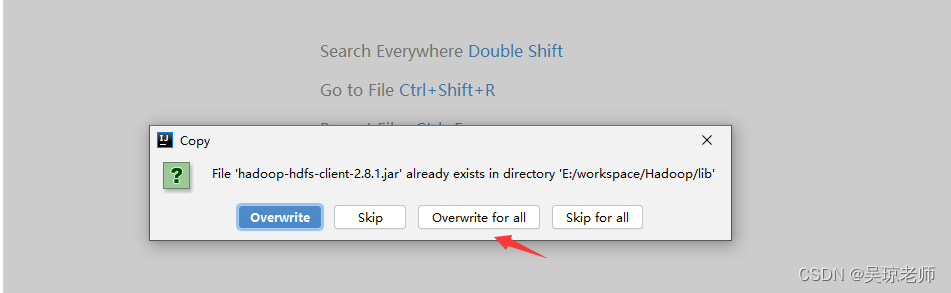
- 具体需要多少jar为了,根据下图提示。
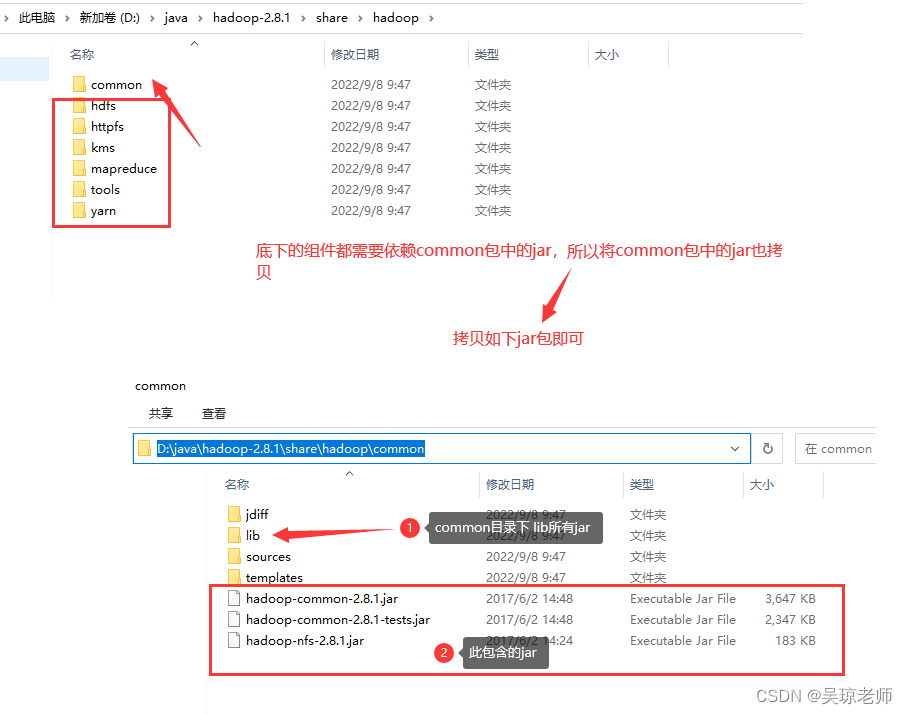
- 依赖的jar包会有重复,则直接覆盖即可。
4.3 HDFS客户端api入门使用
- Hadoop 的命令写法已经练习过,但是,真正使用时是通过java进行编程的。
- 如: 增加,删除,修改,查询,上传,下载 ,移动 api入门操作。
- 注意使用的都是
import org.apache.hadoop.*下的jar包 - 有兴趣的同学,具体使用中参数可以参考 Hadoop官方网址
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
/**
针对hdfs客户端操作
包括hdfs,增加,删除,修改,查询,上传,下载等。
为了测试方便,所有测试方法都使用的junit单元测试。
*/
public class HdfsClient_Test {
FileSystem fileSystem = null;
/* @Before 意思在其他方法执行之前,执行该方法。
该方法主要是初始化数据。
*/
@Before
public void init()throws Exception{
Configuration conf = new Configuration();
conf.setInt("dfs.replication",2); //修改配置参数上传文件备份2份。
conf.set("dfs.blocksize","64M"); //将切块设置成64M
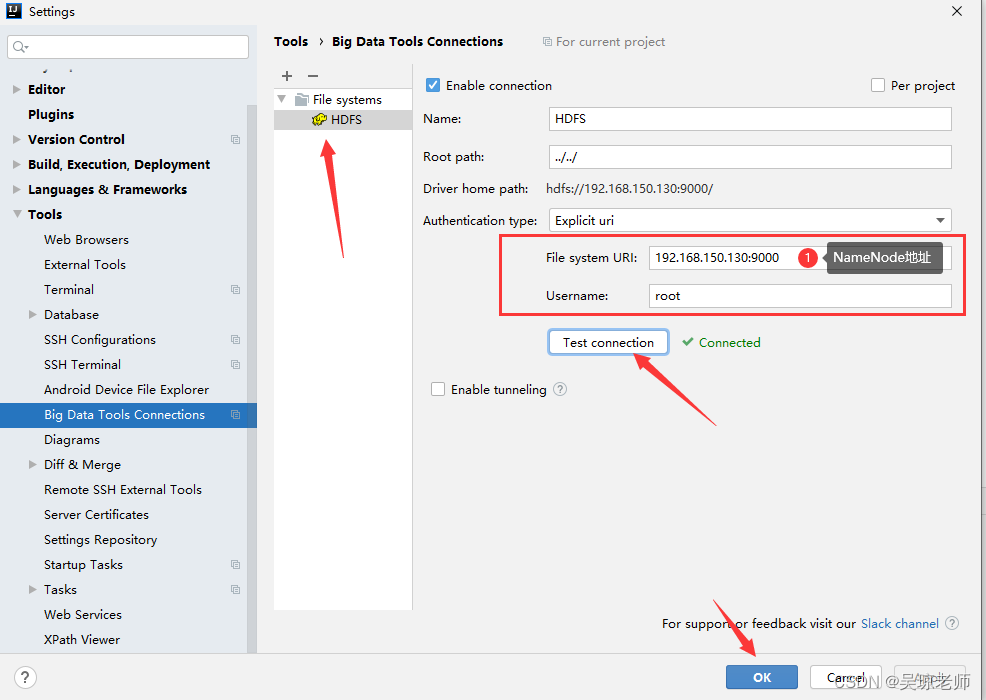
fileSystem = FileSystem.get(new URI("hdfs://192.168.150.130:9000"),conf,"root");
}
/*
1. 上传文件,注意从本地上传,现在是windows操作就是从windows上传。
*/
@Test
public void fileUpload() throws Exception{
/*
//2.创建配置文件
Configuration conf = new Configuration();
//2.1 可以设置 如版本备份,切块大小等,还记得哪个配置文件hdfs-site.xml
conf.setInt("dfs.replication",2); //修改配置参数上传文件备份2份。
conf.set("dfs.blocksize","256M"); //将切块设置成256M
//1.获取客户端的连接FileSystem.get(url,conf,user);需要三个参数
fileSystem = FileSystem.get(new URI("hdfs://192.168.150.130:9000"),conf,"root");
*/
//3 上传文件 该文件174M
fileSystem.copyFromLocalFile(new Path("D:\\jdk-8u121-linux-x64.tar.gz"),new Path("/"));
fileSystem.close(); //关流
}
/*
2. 删除文件
*/
@Test
public void fileDelete() throws IOException {
//true 的意思是询问,要不要递归删除。
fileSystem.delete(new Path("/hadoop/"),true);
fileSystem.close();
}
/*
3. 下载文件
这就是为什么我们需要配置Hadoop 环境变量还有 windows的hadoop.dll操作等
因为是从hadoop下载到windows上需要windows去操作,客户端就需要本地库开发。
*/
@Test
public void fileDownload() throws IOException {
fileSystem.copyToLocalFile(new Path("/jdk-8u121-linux-x64.tar.gz"),new Path("D:\\"));
fileSystem.close();
}
/*
4.创建目录,递归创建
*/
@Test
public void fileMkdir()throws Exception{
fileSystem.mkdirs(new Path("/hadoop/aaa"));
fileSystem.close();
}
/*
5.查看目录信息,列出文件和文件夹。
*/
@Test
public void fileDir() throws IOException {
//1.可以指定查看,也可以查看根目录下所有
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));
// 2.遍历查看是目录还是文件。
for (FileStatus f:fileStatuses){
//2中情况,
if (f.isDirectory()){
System.out.println("是目录"+f.getPath().getName());
System.out.println(f.getReplication());
}else if (f.isFile()){
System.out.println("是文件"+f.getPath().getName());
}
}
}
/*
6.递归查看目录下所有文件,只有文件,不列出文件夹,支持递归。
true ,代表是否递归查看所有。 flase 代表不递归。
hadoop fs -ls -R /
*/
@Test
public void flieList() throws IOException {
RemoteIterator<LocatedFileStatus> lr = fileSystem.listFiles(new Path("/"),true);
//遍历迭代器
while (lr.hasNext()){
//System.out.println(lr.next());
LocatedFileStatus next = lr.next(); //判断是否有数据,
System.out.println("1 :"+next.getPath());
System.out.println("2 :"+next.getBlockSize());
System.out.println("3 :"+next.getLen());
System.out.println("4 :"+next.getAccessTime());
System.out.println("5 :"+next.getBlockLocations());
System.out.println("6 :"+next.getOwner());
System.out.println("7 :"+next.getReplication());
}
}
/*
7.移动(改名)
*/
@Test
public void fileMove() throws IOException {
//注意,移动的意思是将文件移动到另一个地方。
// 最后只有一份,相当于改名字。
fileSystem.rename(new Path("/hadoop/aaa/a.txt"),new Path("/hadoop/Move_a.txt"));
fileSystem.close();
}
}
4.4 HDFS “读”和“写”
- 从文件中,读数据。
- 读的时候可以设置偏移量
seek(字节)。 - 两种方式
fileSystem.open,第一,采用流对接方式,第二种,正常读。
- 读的时候可以设置偏移量
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.Before;
import org.junit.Test;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
public class HdfsClient2 {
FileSystem fileSystem = null;
@Before
public void init() throws Exception{
Configuration conf = new Configuration();
conf.set("dfs.blocksize","256M"); //设置备份大小
fileSystem = FileSystem.get(new URI("hdfs://192.168.150.130:9000"),conf,"root");
}
/*
第一种,正常读取
*/
@Test
public void fileReader() throws IOException {
//1.选择要读取的地址
FSDataInputStream fdis = fileSystem.open(new Path("/hadoop/aaa/seek.txt"));
/* 偏移量
seek.txt 文件内容 24bytes 回车占2byts
Hello Hadoop
Hello HDFS
*/
fdis.seek(15); //相当于从第15个字节开始读,回车算2个
//创建缓存
byte[] buf = new byte[1024];
int b =0;
while ((b=fdis.read(buf))!=-1){
System.out.println(new String(buf,0,b));
}
fdis.close();
fileSystem.close();
}
/*
第二种,使用对流读取,输出到磁盘中。
*/
@Test
public void fileReader2() throws IOException {
//1.选择要读取的地址
FSDataInputStream fdis = fileSystem.open(new Path("/hadoop/aaa/seek.txt"));
FileOutputStream fos = new FileOutputStream("D://a/seek_a.txt");
fdis.seek(5); //从第5个字节开始
IOUtils.copyBytes(fdis,fos,1024);//使用hadoop提供的io工具
}
}
- 往文件中,写数据。
- 是
fileSystem.create(), - 思考一个问题: 写入指定编码的数据怎么查看 ? 需要指定编码读取。
- 是
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
public class HdfsClient3 {
FileSystem fileSystem = null;
@Before
public void init() throws Exception{
Configuration conf = new Configuration();
conf.set("dfs.blocksize","256M"); //设置备份大小
fileSystem = FileSystem.get(new URI("hdfs://192.168.150.130:9000"),conf,"root");
}
@Test
public void fileWirte() throws IOException {
// 将数据写到hdfs上。
FSDataOutputStream fdos = fileSystem.create(new Path("/wirte.txt"));
//1.创建一组数据
String s = "仙人之下我无敌,仙人之上一换一。";
int age = 18;
double salary = 1.2d;
//2.告诉长度
fdos.writeUTF(s);
fdos.writeInt(age);
fdos.writeDouble(salary);
fdos.close();
// Todo 结果会发现,出现问题没有显示全? 0仙人之下我无敌,仙人之上一换一。 ?�333333
// 假设我要读 上面输入的文件? 怎么办?
}
}
5. 话题:HDFS 读写机制的原理
- 这是一个HDFS官方的架构图。
- Rack 是机房的服务器存放的地方,俗称机架(这玩意维护贵),所以,小公司一般采用云服务。
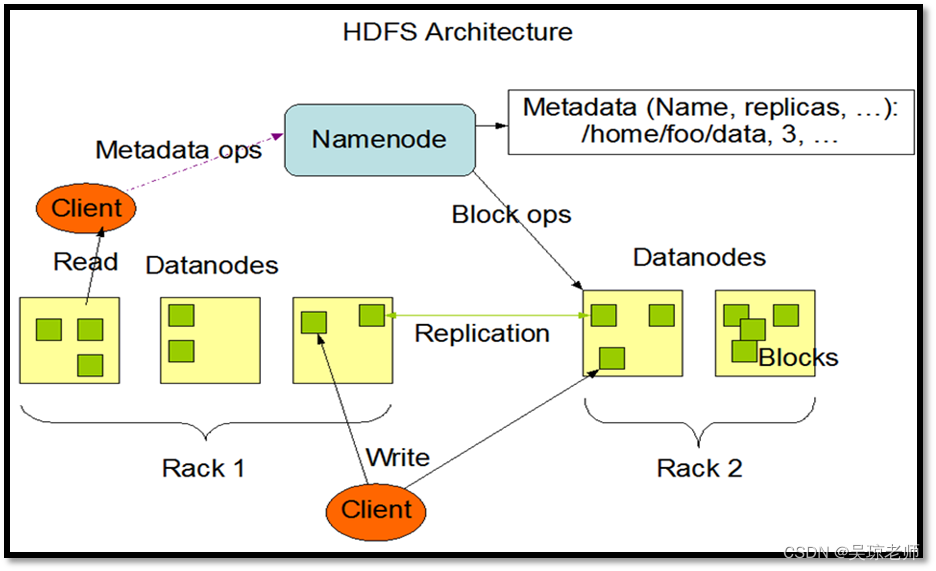
5.1 客户端读取数据流程
- 首先搞清楚一件事情,什么是读数据? 从底层操作来看,只要涉及到块的操作,如 ,在hdfs上查看文件
hadoop fs -cat /下载文件等操作,都属于读数据。- 下图是一张官方客户端读数据的流程:
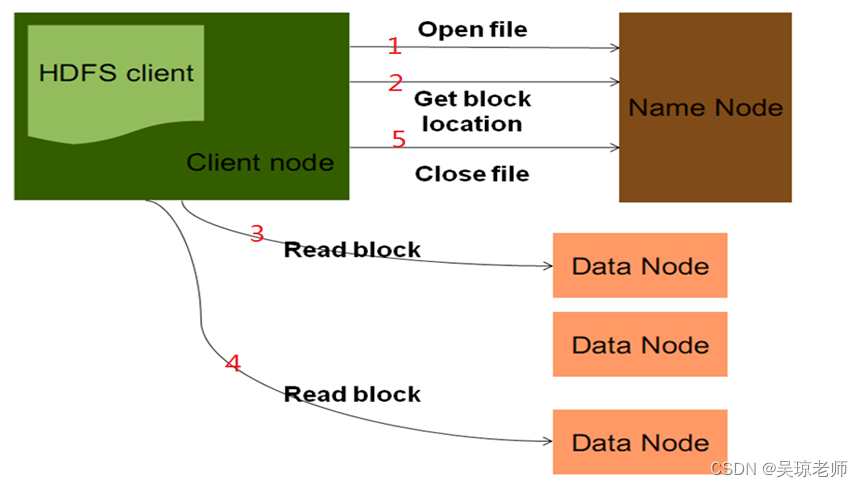
- 下图是一张官方客户端读数据的流程:
- 过程分析: 可以参考数据的读取。
- 客户端通过
FileSystem对象中的open(uri,conf,user),方法打开要读的文件,相当于文件的输入流,获取了指定的文件路径。 FileSystem对象会负责向远程NameNode所在的节点发起RPC调用,得到文件的数据块 信息(Get block location),包含:数据块列表,数据块的地址值等信息。- 拿到块地址和列表之后,
FileSystem对象会返回一个FSDataInputStream对象给客户端,通过使用FSDataInputStream对象中的 调用read()方法开始读取数据,直到该节点的数据完整传回客户端。 - 当其中一个节点的数据块读完之后,当前读取流节点会关闭,去下一个数据块最近的节点,读取该数据的另一个块文件。
- 读取数据块都是分批次读取,根据就近原则,然后读的时候会检查数据块的完整性,如果该节点块有损坏,或不完整,会从下一个附近的备份节点接着读取。
- 当读取的文件块,合并完成之后,会关流
close();
5.2 客户端写数据流程
- 首先搞清楚一件事情,什么是写数据? 如 ,**在hdfs上查看文件
hadoop fs -put /usr/1.txt /hdfs/1.txt从本地往hdfs上传递文件。- 下图是一张官方写数据的流程;
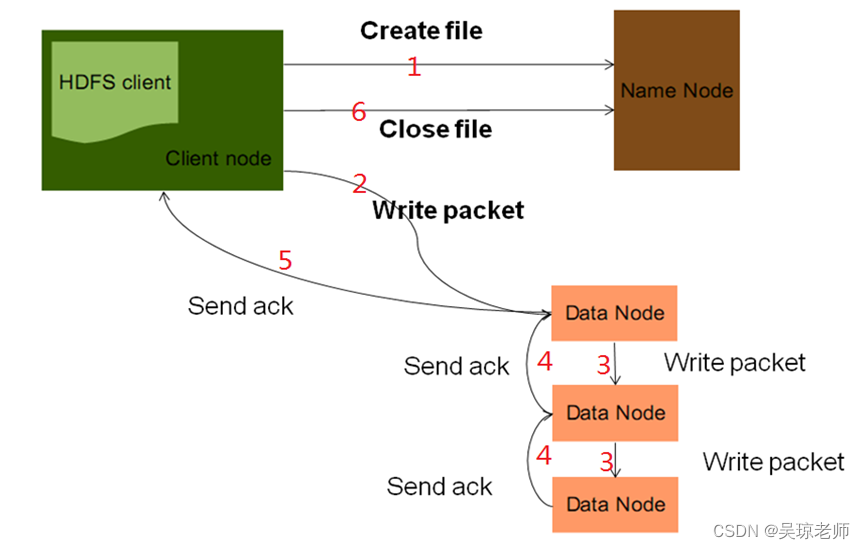
- 下图是一张官方写数据的流程;
- 过程分析: 可以参考数据的写入。
-
客户端通过
FileSystem对象中的create(new Path()),方法创建一个输出流对象,相当于创建文件的输出流,向指定路径上传文件(写出文件)。- 此时的
NameNode会检查,文件是否存在,路径是否合法,并且检查,客户端是否具备相应操作权限。如果都没有问题才 会将输出流交给客户端。
- 此时的
-
FileSystem对象会返回一个FSDataInputStream对象给客户端,并调用该对象中的write()方法,写数据。此时数据会先写入缓冲区, 然后被切分成多个 “数据包packet” 大小默认64k 在内部会形成一个数据队列(data queue),来管理这些packet。然后向NameNode申请block(根据 replication值来确定的,即备份几份)用来存储的合适DataNode列表。- 此时在数据队列中,会有生成一份相同的packet 叫
ack_packet, 用于验证数据包的完整性。相当于拿着版本去比较,是不是一样的,是不是传输正确
- 此时在数据队列中,会有生成一份相同的packet 叫
-
客户端以
pipeline(管道线)的形式将所有的packet写入所有的备份(replication)中, 然后,当写入第一个DataNode1(块和blockid块id)中,该DataNode1把packet存储之后,由DataNode1立刻传给此pipeline(管道)中的下一个DataNode2中,在由DataNode2传递给DataNode3,直到所有的packet储存完成。 -
管道上得节点,会按照反方向顺序返回确认信息,相当于告诉上一个我完成了,数据正确,通过
ack_packet确认信息完整性。 -
通过 pipeline 返回给客户端相应信息。同时删除
data queue队列中生成的ack_packet,说明数据完成。 -
然后告诉 NameNode写入成功,然后调用
close();
6. 浅谈:HDFS 租约管理
6.1 租约的产生
- hdfs客户端往某一个文件中写数据的时候,为了保持数据的一致性,并且不允许多用户同时对该文件执行写入操作。
- 怎么能控制这样的情况产生,不允许多个用户操作呢?使用锁机制么?那会出现什么样的后果 ?
- 死锁是怎么产生的 ?
两个或者两个以上的线程在执行过程中,因争夺资源而造成的一种互相等待的现象。如果没有外力作用,它们将无法进行下去。
- 死锁是怎么产生的 ?
- 产生死锁的必要条件:
- 互斥使用(独占资源),如:写操作,只能给一个客户端。
- 占有并且等待, 如:自己在申请新资源时,保持对原有资源占有。
- 不可以抢占, 如:不能去抢未释放的资源,只能等资源占有者自愿释放。
- 循环等待。
- 既然单纯的加锁不行,就需要结合另一种办法,在这个锁上加上一个时间的期限,就是租约(Lease)。 可以理解为,每个客户端都会持有这个租约,相当于操作许可证,包括每个租约内部包含有一个租约持有者信息,还有此租约对应的文件Id列表(表示当前租约持有者正在写这些文件Id对应的文件)。
- 如果客户端没有在 预定义的时间内续订租约,则租约到期,这个时候HDFS服务端将关闭并释放租约,以便其它客户端的写入操作可以获取租约,这个过程也称之为租约恢复。

6.2 LeaseManger
- 有租约就必然有租约管理者 LeaseManger类。维护客户端和租约的映射关系;维护了文件和租约的映射关系,还提供了租约的增删改查。
- 添加租约方法LeaseManager.addLease():
- 检查租约方法FsNamesystem.checkLease()方法。
- 租约更新方法LeaseManager.renewLease()
- 删除租约方法removeLease()
- 同时启动独立线程Monitor,对租约进行生命周期和状态的管理。 它的run()方法会每隔2秒调用一次LeaseManager.checkLease()方法检查租约。检查是否超过硬限制。
- 软限制时间与硬限制时间,大体意思是关于租约超时,时间与文件连接时间。
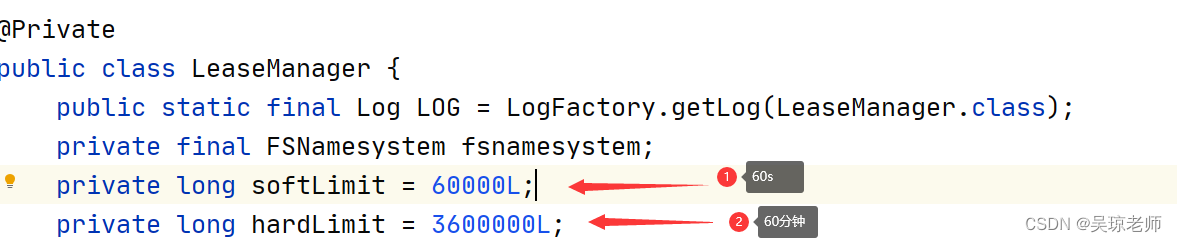
- 软限制时间与硬限制时间,大体意思是关于租约超时,时间与文件连接时间。
7. 副本冗余存储策略
- HDFS 上的文件对应数据块保存可以有多个副本,根据配置
dfs.replication备份数量,且提供了容错机制,即使副本丢失或者宕机都能自动恢复。 - 并且根据相应的RackID 通过算法,会算出两个DataNode之间的距离。
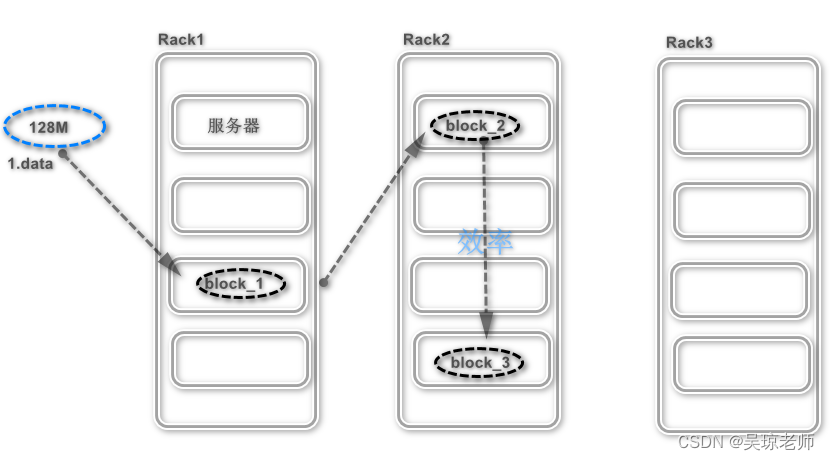
- 原理如下:
- 如果是节点上提交就是直接放在该节点上备份 block_1, 如果在集群外,则随机挑选一台磁盘不太满,CPU不太忙的节点上备份 block_1。
- 第二个block_2 放置与第一个不在同一个机架上得节点。
- 第三个block_3 放置与 第二备份相同机架的,其他节点上。
- 为什么这样做?:
主要是这样的策略,减少了机架之间的数据传输, 提高了写的操作,同时,数据块只放在两个不同的机架上, 所以此策略减少了读数据时所需要的网络的传输总宽带。
在这种策略下,副本并不是均匀分布在不同的Rack上,同时也该进了写的性能。
8. HDFS 高级功能
8.1 回收站
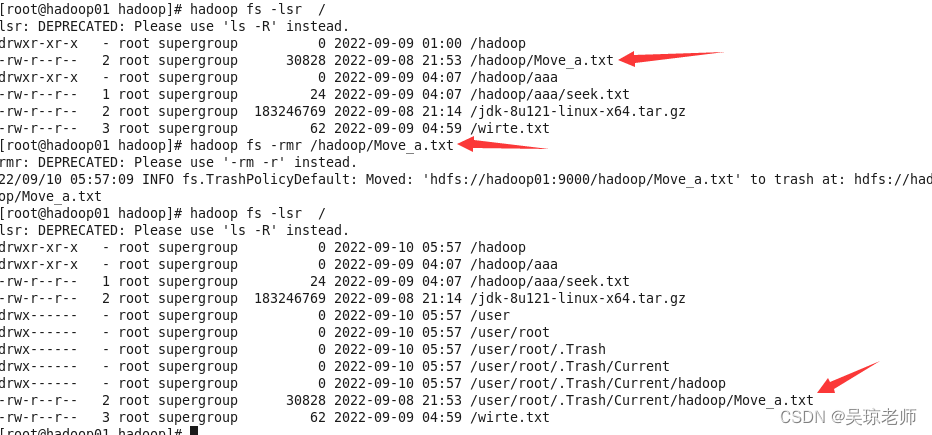
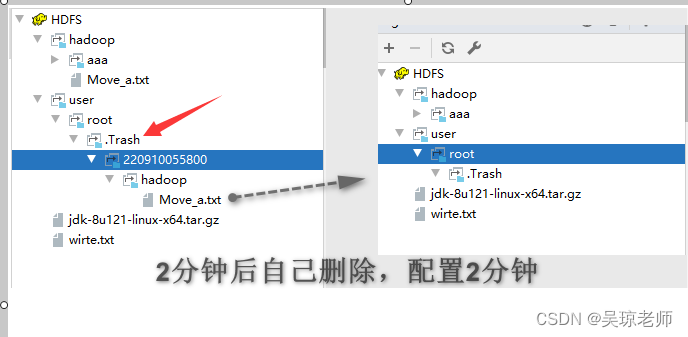
- HDFS 为了每一个用户都创建了一个回收站(Trash) 类似于Windows,当用户删除文件时,文件并不能马上永久删除,会在回收站保留一段时间,这个保留的时间是可以设置的。
- 用户也可以手动清空回收站,回收站默认是关闭模式,需要修改
core-site.xml配置文件。 - 从回收站也可以恢复文件
hadoop fs -mv /。
<configuration>
<property>
<name>fs.trash.interval</name>
<!--相当于 1440分钟,60x24 刚好一天时间-->
<value>1440</value>
</property>
<property>
<!--检查时间间隔,小于回收时间即可-->
<name>fs.trash.cheackpoint.interval</name>
<value>1440</value>
</property>
</configuration>

















 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











