










集群版本:HDP3.1.5
Hadoop版本:Hadoop3.1.1
源码地址:https://github.com/hortonworks/hadoop-release/tree/HDP-3.1.5.152-1-tag
一、前置知识
大家都知道hadoop的核心组件是HDFS和YARN,HDFS负责存储,YARN负责计算资源管理,今天要重点扯一扯YARN。YARN的架构跟众多分布式架构一样是主从式,为了维护可靠性,ResourceManager(RM)支持High Available(HA)功能。在所有人的认知中,只要是主从架构,挂了一个slave节点或master节点,框架内部的容错机制都会保证整个系统的正常运行,加上下游的计算应用的重试机制,甚至对用户无感知。貌似所有人都关心一种情况,就是某个或者某种类型的节点挂掉,但是,还有没有其它情况呢?非死即生?不,还有一种叫stop the world生不如死,类似jvm的gc,这也是java生态框架最头疼问题之一。当然,今天要讲的不是gc,而是另一种情况下的java进程stop the world导致的严重问题——锁。
为什么需要锁
RM作为资源管理服务,必然要维护存储资源的信息,最简单的,比如Container被客户端申请分配,多线程的情况下,要保证Container数值的准确性,多线程下客户端要申请资源,会对数值进行更改,避免可能会出现数据不一致的问题,因此对此类资源的操作必须要加锁。在RM相关的代码中,有大量的加锁操作,在hadoop2.x中,RM对资源操作的锁都是最原始的syncrinized锁,而在hadoop3.x中,社区考虑到性能问题,把syncrinized锁全部换成了ReentrantReadWriteLock锁。
ReentrantReadWriteLock
ReentrantReadWriteLock可以多个Thread可以同时进行读取操作,但是同一时刻只允许一个Thread进行写入操作,而synchronized 不论读写,只要线程进入synchronized代码就互斥,所以,会出现一个线程读另一个线程不能进入的现像。ReentrantReadWriteLock里其实是加了两把锁,写锁排斥读、写,读锁只排斥 写,所以能达到并发读的效果,克服了synchronized 读互斥的缺点,所以说 ReentrantReadWriteLock比synchronized 快,这也是hadoop3.x版本中对锁进行优化原因。
二、事发背景
考虑成本问题公司今年迁移到新集群,由原来的cdh5.13和hdp2.6两个集群(都是hadoop2.x)迁移到HDP3.1.5,最后一个开源版本,打包的组件版本都比较新,众多新特性等待发掘,不至于技术基础上落后。迁移之初,业务并没有从其余两个集群完全迁移过来,迁移过来的业务也并没有对外服务,考虑到中间磨合过程。俗话说小病重启,大病重装,某一天,突然发现所有任务都提交不到yarn上去,正在运行的任务也无法结束,但是yarn的8088 web ui能够正常打开。看RM的log也没看到任何报错信息,于是直接重启RM,一切恢复正常。我大意了啊,没有进一步排查,这好吗?这不好。之后的一段时间里,貌似平静许多,后面才知道,同样的情况原来越来越频繁,运维小哥哥每天凌晨偷偷起来重启RM保障集群稳定,传说中的人肉运维。随着集群迁移的完成,所有业务正式上线,每天在yarn上跑的任务越来越多,好几万个实例。然鹅RM出现这种情况的频率从一周一次变成几个小时一次,啪的一下又hang住了,挂掉还好,会主备切换,但是hang住后zkfc并不会判断active节点不可用,所以不会切换,几百上千个任务卡住无法运行,严重影响业务,导致集群完全不可用!!濒临奔溃边缘!看样子Hadoop3.X显然是有bear而来不讲武德!
三、问题分析
-
分析日志
出问题,第一时间看日志,我们分析了每一次出问题时候的RM日志,基本的现象是,RM hang住前,控制container生命周期的打印的log越来越少,比如申请、分配、完成、释放等等,等到hang住后,这些日志完全没打印了,也没有任何报错信息,没结果。
-
分析监控
接着我们把RM的所有监控metrics都看了个遍,包括rpc、gc、cpu、内存、网络、资源分配等等,包含了RM大部分常用的指标和RM所在服务器的指标,大概上百个,我们分析出问题的那一刻指标的异动情况,中间只要有个别指标的异常,都刨根问底的查到低,最后也没查出个所以然。
-
分析任务
为了找出RM hang住的原因,无所不用其极啊,甚至有人把调度任务跟出事的时间点扯上关系,看是不是某些在yarn上跑的特殊的任务导致RM处理问题,在之前hadoop2.x中跑任务从来没出过这样的问题。然鹅,还是没有结果。
-
分析现象
每次出问题的时候,RM的webui能够正常打开,但是有个地方一直不会跳转,如下图:
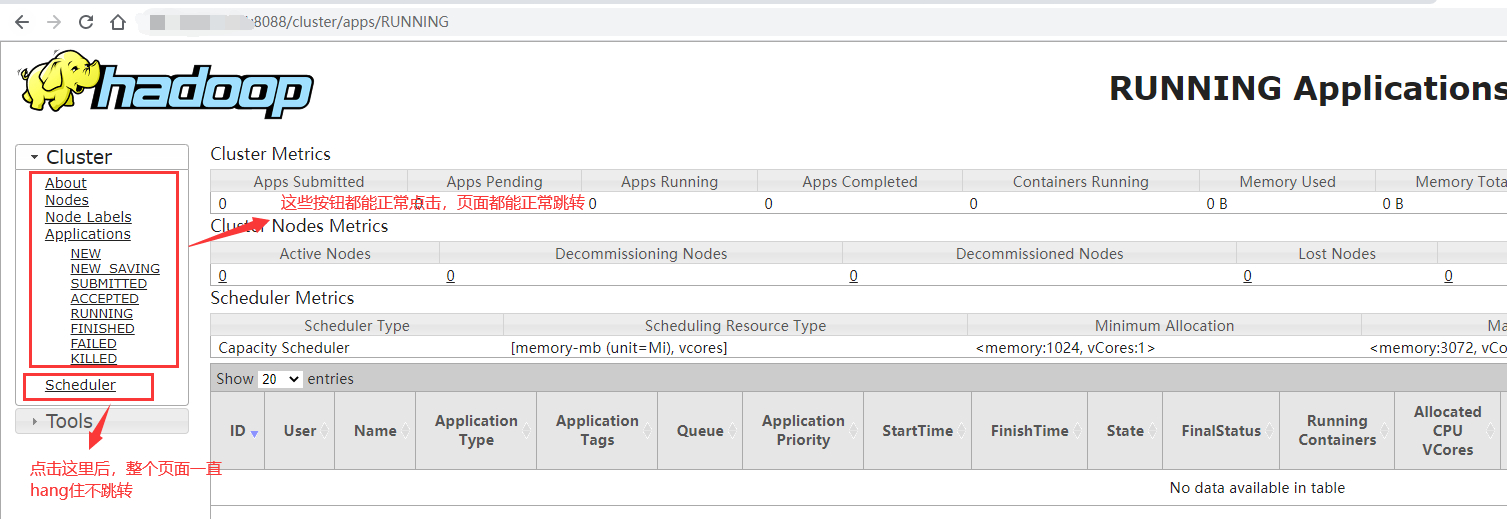
终于有了突破口,这个问题跟Scheduler有关!
-
线程堆栈分析
一般非jvm gc导致的进程卡死的问题,都是线程问题。查了一圈关于死锁问题分析的资料,可参阅:https://blog.csdn.net/liwenxia626/article/details/80791704。我把正常状态下和非正常住状态下的RM的jvm线程堆栈日志dump出来,执行
jstack <RM PID> > rm.stack毕竟是头一回正儿八经的在生产上分析jvm的堆栈,事先也补了大量的课,前面所有的分析步骤都像无头苍蝇乱打乱撞,对比两个日志,虽然没有明显的dead lock字眼,但是有了重大发现,看到了曙光,非正常日志下:
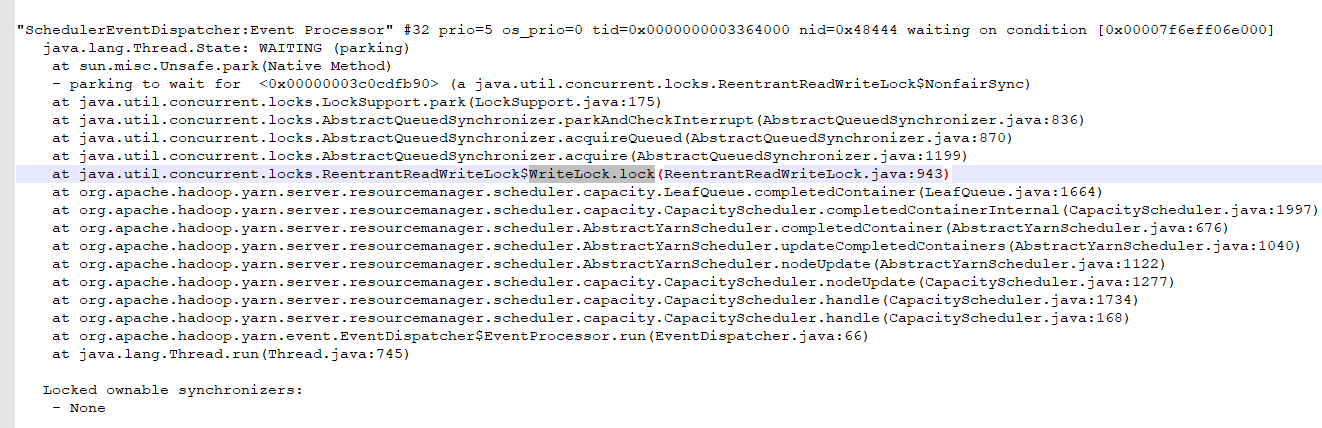
RM内部有线程在等待某个锁的释放,但是一直没释放!根据上面的信息,可以知道是由于
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.LeafQueue#completedContainer里面有写锁的操作,有写锁必然会有释放锁,但是根据上面的线程堆栈日志,显然是有进程在等待它释放锁,但是它没有进入finally释放锁,而另一个进程一直在等待它释放,于是出现了死锁!!
public void completedContainer(Resource clusterResource,
FiCaSchedulerApp application, FiCaSchedulerNode node, RMContainer rmContainer,
ContainerStatus containerStatus, RMContainerEventType event, CSQueue childQueue,
boolean sortQueues) {
// Careful! Locking order is important!
try {
// 获取锁
writeLock.lock();
// 中间逻辑略
} finally {
// 释放锁
writeLock.unlock();
}
}
除了上面日志的WriteLock.lock(),堆栈日志中同样有ReadLock.lock()
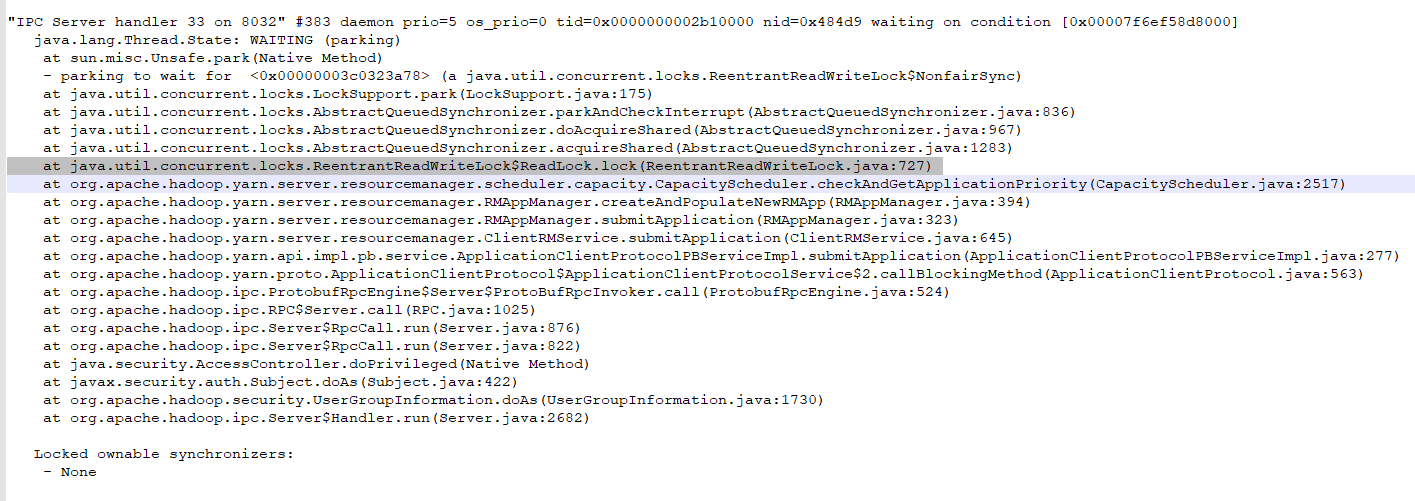
根据堆栈日志锁出现的地方,均在Scheduler相关的类方法,org.apache.hadoop.yarn.server.resourcemanager.scheduler.*下存放的是RM资源调度相关的类,有我们熟知的FIFO、Fair、 CapacityScheduler。本集群使用CapacityScheduler,CS调度下每个队列内默认FIFO。这也解释了上面点击web ui只有Scheduler那一栏卡住不动,可以肯定的是点击前端页面有后端方法进入了scheduler包下相关的类方法。
四、定位问题
上面就定位到根本问题了么?只知道是锁的问题,但不知道为何会导致死锁问题。翻了yarn的源码所有锁的操作都没问题,找不到任何毛病,此时又进入无头苍蝇模式,病急乱投医之下疯狂的调yarn参数,最后还是没有任何作用。在社区jira上疯狂的提问,YARN-10440 , YARN-10482 , YARN-10483。最后都没得到想要的结果。估计现在没有多少大公司在生产环境使用hadoop3.X,99%还停留在2.x的时代。花了很长时间排查hadoop源码的锁这一块,最终还是没头绪。自己解决不了的还不能找人帮忙么?最后,所幸想起参加过开源社区的线下meetup加了一位京东yarn开发组大佬,同时也是hadoop的commitor,在这里要感谢他抽时间帮我看这个问题,最后确定了这是一个jdk1.8的bug引起的,而不是hadoop的bug,详情参考bug地址:https://bugs.openjdk.java.net/browse/JDK-8134855,ReentrantReadWriteLock在某些情况下会导致解锁失败,进而导致死锁问题,这个bug在jdk9及以上版本中已修复。
五、解决方案
由于现在大部分公司都使用jdk1.8,已经找到了根本原因是jdk的bug,这下就有了正确的解决方向
更换jdk
我们集群使用的是oracle jdk1.8,jdk9由于社区不再维护,不知道更换后有没有其它会不会有其它问题,考虑风险就直接放弃了。
于是直接更换到jdk11,但是发现更换后RM根本起不来,仔细一查,原来hadoop3还不支持jdk11的runtime,此路不通,也放弃了。
修改yarn的锁
没法解决的bug,只能想办法避开,亦是另一种解决方式,参考hadoop2.x的源码,CapacityScheduler相关的类几乎都使用的synchronized锁,于是 ,我参考Hadoop2.7的源码,把当前Hadoop3.1.1的ReentrantReadWriteLock全部改回synchronized锁,这样虽然性能会有些损失,对于没达到一定量级的公司来说,可以忽略不计。
patch已提交到 YARN-10482
也可以参考本人单独维护的hadoop3.1.1完整提交记录:https://github.com/lijufeng2016/HDP-hadoop3.1.1/tree/yarn-capacity-hotfix-20201104,
或者同样是HDP3.1.5版本的hadoop3.1.1可以直接使用编译好的jar包:hadoop-yarn-server-resourcemanager-3.1.1.3.1.5.0-152.jar
最后,集群终于稳定!
六、小结
这是从业以来解决的跨度时间最大的一个问题,从最初出现,到彻底解决,中间跨度3-4个月,其中花了整整一周时间集中排查解决这个问题,中间排查解决的过程远不止上面描述的这个简单。引入新技术框架,出现问题,要接的住,化解的了,最后发到社区给同样遇到问题的人,不会接化发,年轻人不要轻易在生产环境使用过新的技术,不然碰到棘手问题,耗子尾汁。















 6965
6965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









