






在 浅谈java内存模型中,线程的读写都是跟工作内存打交道。而每个线程有自己的工作内存,同一个变量可能在多个工作内存中存在,在一个线程修改变量后,就会出现其他线程的工作内存里还存着该变量的旧值,即其他线程不能看到该变量的最新值,即出现了 可见性的问题。
线程的背后是CPU在运行,CPU本身存在可见性和乱序执行的问题,导致让java抽象出了工作内存的概念。
所以,本文试图讲明白以下几个问题:
1. CPU为什么存在可见性问题
2. CPU内部缓存结构是什么样的?
3. CPU如何解决可见性问题?
首先,从问题就可以看出来,CPU存在缓存。
那CPU为什么需要缓存?
由于现代硬件设备的不断发展,CPU的运算速度远大于内存的读写速度,所以CPU设计中,在CPU和内存中间,添加了各种缓存,来缓解两者速度不匹配的矛盾。(CPU缓存是SRAM做的,SRAM的特点就是非常的昂贵,而内存是用DRAM做的,所以内存跟不上CPU的速度还有钱的问题😅)
下面是CPU读取数据消耗时间表:
| 从CPU到 | 大约需要的CPU周期 | 大约需要的时间(单位ns) |
|---|---|---|
| 寄存器 | 1 cycle | |
| L1 Cache | ~3-4 cycles | ~0.5-1 ns |
| L2 Cache | ~10-20 cycles | ~3-7 ns |
| L3 Cache | ~40-45 cycles | ~15 ns |
| 内存 | ~120-240 cycles | ~60-120ns |
| SSD随机读(间接) | ~150000ns | |
| 机械磁盘寻址(间接) | ~10000000ns |
从上表可以看出,虽然cpu访问内存的速度远比访问磁盘要快的多,但是比起访问寄存器,依然慢了两个数量级。这就是CPU缓存存在的意义。
接下来,我们将走进CPU内部。
一、缓存的结构
缓存的存储结构如下图所示:
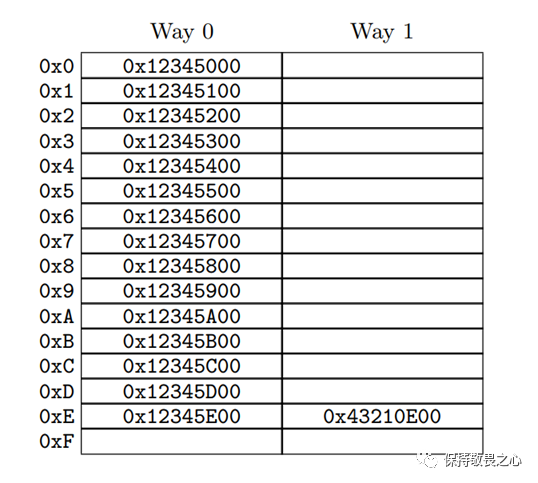
如上图所示,CPU缓存是一个多行两列的结构。
多行的实质是一个硬件hash结构,根据内存的地址,映射到上图中的某一行。比如内存地址0x12345E00映射到0xE行。
而两列则是避免一出现hash冲突就淘汰原内容而增设 备用列。通过这样一个多行两列的结构,根据内存地址实现了缓存的功能。
CPU缓存存储中的最小单位,我们将它称之为 缓存行。(你可以理解为上图中的一个单元格)。
那缓存行它一次缓存多大的数据呢?
缓存行的大小是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。在缓存某个变量的时候,会把该变量周边的连续内存凑成缓存行相等的大小进行缓存。(这带来了伪共享问题,对,就是disruptor中说的伪共享)
而站在整体的角度,CPU是存在多级缓存(一般3-4级缓存)。这里我们先不考虑多级缓存的情况,给出一个简陋的缓存结构图,如下图所示:
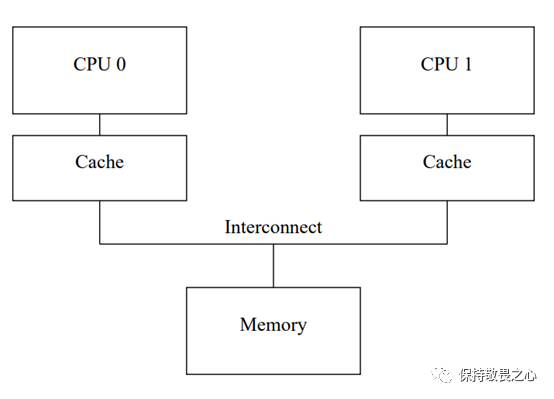
如上图所示,每个CPU都有属于自己的缓存(Cache),CPU会直接访问缓存,由缓存跟内存(Memory)进行交互。
CPU在读变量时,先从缓存里读取变量内容,当缓存发现没有该变量,会从内存中加载变量内容到缓存中,从而cpu读取到变量内容。
而CPU在写变量时,会把修改信息写到缓存中,再从缓存回写到内存中。
在我们平时写代码的时候,一般是使用缓存对数据库的数据进行缓存,会出现缓存的数据和数据库的数据不一致的情况。
同样,CPU在引入缓存时,由于同一份数据存储了多个地方,也会出现数据不一致的情况。
所以,CPU引入了缓存一致性协议MESI。
二、缓存一致性协议MESI
MESI(Modified Exclusive Shared Or Invalid)是一种广泛使用的支持写回策略的缓存一致性协议。
为了保证多个CPU缓存中共享数据的一致性,定义了缓存行(Cache Line)的四种状态。
| 状态 | 描述 | ||
|---|---|---|---|
| M | Modified | 修改 | 当前数据有效,数据已被修改,和内存中的数据不一样,数据只存在当前CPU的缓存中。 |
| E | Exclusive | 独享 | 当前数据有效,数据和内存中的数据一致,只有当前CPU的缓存中有该数据。 |
| S | Shared | 共享 | 当前数据有效,数据和内存中的数据一致,多个CPU的缓存中有该数据。 |
| I | Invalid | 无效 | 当前数据无效 |
举个例子:
- 当只有CPU0访问变量a时,则此时CPU0的缓存中变量a状态为E(独享)
- 而此时CPU1也访问变量a,则此时CPU0和CPU1的缓存中变量a状态都置为S(共享)
- 然后CPU0修改变量a,则CPU1的缓存中变量a的状态从S(共享)变成I(无效),CPU0的状态从S(共享)变成M(修改)。
- 最后CPU0缓存里修改后的变量a信息同步给内存,此时CPU0的缓存状态从M(修改)变成E(独享)。
下面表格展示的是当前CPU或其他CPU发生读或者写事件时,当前CPU会产生的状态变化。
| \事件当前CPU状态 | 当前CPU读 | 当前CPU写 | 其他CPU读 | 其他CPU写 |
|---|---|---|---|---|
| M(Modified) | 无状态变化 | 无状态变化 | M->E->S(需先同步修改信息到内存) | M->E->S->I(需先同步修改信息到内存) |
| E(Exclusive) | 无状态变化 | E->M | E->S | E->S->I |
| S(Shared) | 无状态变化 | S->E>M(需先通知其他CPU置为失效) | 无状态变化 | S->I |
| I(Invalid) | I->S | I->S->E->M(需先通知其他CPU置为失效) | 无状态变化 | 无状态变化 |
可以看出CPU在读和写的时候,都需要沟通其他CPU进行状态变化。
CPU通过在消息总线上传递message进行沟通。主要有以下几种消息:
| 消息 | 含义 |
|---|---|
| Read | 带上数据的物理内存地址发起的读请求消息 |
| Read Response | Read 请求的响应信息,内部包含了读请求指向的数据 |
| Invalidate | 该消息包含数据的内存物理地址,意思是要让其他如果持有该数据缓存行的 CPU 直接失效对应的缓存行 |
| InvalidateAcknowledge | CPU 对Invalidate 消息的响应,目的是告知发起 Invalidate 消息的CPU,这边已经失效了这个缓存行啦 |
| Read Invalidate | Read 和 Invalidate 的组合消息,与之对应的响应自然就是一个Read Response 和 一系列的 Invalidate Acknowledge |
| Writeback | 该消息包含一个物理内存地址和数据内容,目的是把这块数据通过总线写回内存里 |
- 当CPU要读取变量且缓存中没有数据时,就会发送Read,其他CPU返回ReadResponse。
- 当CPU要修改变量时,则需要发送Invalidate,其他CPU置为失效后返回Incalidate Acknowledge。
- 当CPU要修改变量且缓存中没有变量数据时,会发送Read Invalidate,其他CPU返回ReadResponse和Incalidate Acknowledge。
- 当CPU修改变量后,要把修改后信息从缓存回写到内存中,则发送Writeback。
三、Store Buffers
此时,我们会发现一个问题,当多个CPU共享某个变量时,假如其中一个CPU要修改变量时,则它会广播Invalidate消息,然后等待其他CPU把变量置为失效后响应Invalidate Acknowledge。如下图所示:
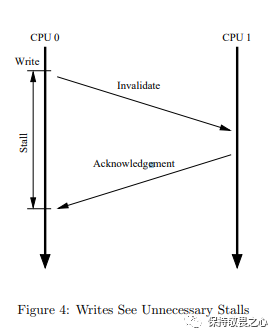
也就是说,CPU会有一个空等期。所以CPU引入了store buffers。然后,CPU缓存结构图就变成下面这样:
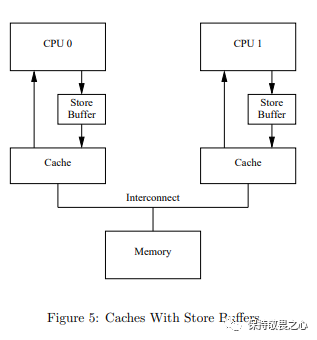
在CPU进行变量的写操作时,Store Buffer 是CPU和Cache之间的缓冲区。CPU无需真正的把变量修改写到缓存中,无需等待其他CPU的反馈,而是写到Store Buffer 就不管了继续执行。
Store Buffer 避免的CPU的空等。简单理解,Store Buffer 把CPU修改变量写缓存的操作从同步变成了异步。
但是,在引入了Store Buffer后,CPU读取变量时,如果直接从缓存中读取,则可能出现 Store Buffer中存在已修改的变量,但是缓存中还是旧的数据。即又出现了可见性的问题。
所以,CPU会先从Store Buffer中读取,Store Buffer中不存在再从缓存中读取,这种机制叫做Store Forwarding
缓存结构图更改如下图所示:
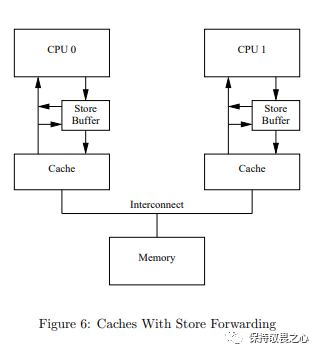
这样能保证在单个CPU 进行顺序执行指令的过程的可见性。
Store Forwarding 解决了单个 CPU 执行顺序性和内存可见性问题,但是对于其他CPU来说,依然存在可见性的问题。
举个例子:
void foo(void)
{
a = 1;
b = 1;
}
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
假设CPU 0执行foo()方法,CPU 1执行bar()方法。
变量a,变量b初始化值为0。再假设变量a被CPU 1所缓存,变量b被CPU 0所缓存。
整个过程可能如下:
- CPU 0执行a = 1。缓存行不在CPU 0的缓存,因此CPU 0设置变量a的新值到CPU 0的缓存中并发送“Read Invalidate”消息。
- CPU 1执行while(b == 0)continue,但是CPU 1的缓存中不包含变量b。它因此发送“Read”消息。
- CPU 0执行b = 1。由于CPU 0的缓存中有变量b,且状态是Exclusive或Modified,因此它直接更新变量b的新值在其对应缓存行中。
- CPU 0接收到CPU 1的“ Read”消息,然后发送变量b的新值给CPU 1,并将该缓存行状态修改Shared。
- CPU 1接收变量b的新值存放在其缓存中。
- CPU 1现在完成了while(b == 0)continue语句的执行,因为它发现了变量b为1,进入下一个语句。
- CPU 1执行assert(a == 1),并且由于CPU 1的缓存中存放的是变量a的旧值,此时断言失败,a == 1结果为false。
- CPU 1收到CPU 0的Read Invalidate消息,把变量a的缓存行信息发送给CPU 0,并将自身变量a对应的缓存行置为Invalid。但是为时已晚。
在上述例子里,造成断言失败的原因,是因为变量a的修改对于CPU 1来说,是不可见的。
对于CPU1来说,foo()方法的执行从逻辑上来说就是乱序的,此时逻辑上foo()先执行了b=1再执行a=1。
要解决上述的问题,要依靠内存屏障。
四、内存屏障
由于cpu并不能知道哪些变量之间存在逻辑关系,所以CPU的设计人员提供了内存屏障,让开发人员通过设置内存屏障来告诉CPU这些关系。
什么是内存屏障?第一次听到这个名字的时候,我觉得这个名字太抽象了。
简单来说,我们可以把内存屏障理解为一个CPU指令,通过这个指令,我们在代码逻辑中告诉CPU此时需要严谨的可见性。
在添加了内存屏障后,上述例子的代码就变成:
void foo(void)
{
a = 1;
smp_mb();
b = 1;
}
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
smp_mb()这行代码就是我们的内存屏障。
我们再来回顾下问题,不同CPU之间存在可见性问题的原因,是因为CPU引入了store buffers,把修改变量同步缓存这一动作从同步变成了异步。
在变量a =1代码后面添加一个smp_mb()代码的作用,会导致 CPU 在后续变量写入之前,把 Store Buffers 的内容同步到CPU缓存。此时CPU 要嘛等待同步缓存的操作完成,要么就把后续的写入操作也放到 Store Buffers 中,直到 Store Buffers 数据顺序刷到缓存。
即通过加入屏障的方式,抵消了加入store buffers带来的问题,把修改变量同步缓存这一动作从异步又改回了同步。
五、Invalidate Queues
我们来回顾下修改变量同步缓存这个操作做了什么事情。假设cpu0在修改变量时,它需要向其他cpu广播Invalidate消息,然后等待其他CPU把该变量对应的缓存置为失效后返回Invalidate Acknowledge消息。
由于Store Buffer的容量很小,而如果修改的变量个数超过了Store Buffer的容量,此时CPU会等待Store Buffer的空间腾出,即CPU还是会出现空等现象。
为了尽量避免Store Buffer的容量被填满的情况,CPU引入Invalidate Queues。在Invalidate Queues之后,cpu在收到Invalidate消息时,不会真正地去把变量对应缓存行置为无效,而是马上响应Invalidate Acknowledge消息。
缓存结构图更改如下图所示:
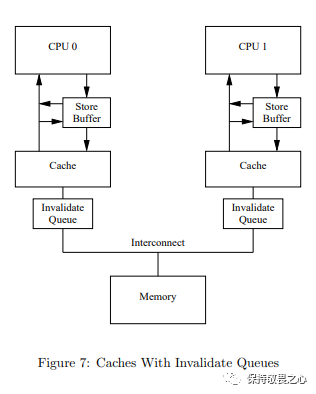
引入了Invalidate Queue后,Invalidate Acknowledge的时延减小了,即对于修改变量从Store Buffer同步到缓存的时延就减小了,即CPU的空等现象就减少了。
引入了Invalidate Queue后,虽然提升cpu的效率,但是也带来了新的可见性问题。
再来看之前加入内存屏障后的代码例子:
void foo(void)
{
a = 1;
smp_mb();
b = 1;
}
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
假设CPU 0执行foo()方法,CPU 1执行bar()方法。
变量a,变量b初始化值为0。再假设变量a被CPU 0和CPU 1所缓存,变量b被CPU 0所缓存。
整个过程可能如下:
- CPU 0执行a = 1。变量a在CPU 0的缓存状态为Shared,所以CPU 0设置变量a的新值到CPU 0的缓存中并发送“Invalidate”消息。
- CPU 1收到 invalidate消息,将其放入Invalidate Queue,并向CPU 0发出Invalidate Acknowledge消息。注意,变量a的旧值仍保留在CPU 1的缓存。
- CPU 0 收到Invalidate Acknowledge后,把 a=1 从 Store Buffer 刷到缓存中。
- CPU 0执行b = 1。由于CPU 0的缓存中有变量b,且状态是Exclusive或Modified,因此它直接更新变量b的新值在其对应缓存行中。
- CPU 1执行while(b == 0)continue,但是CPU 1的缓存中不包含变量b。它因此发送“Read”消息。
- CPU 0接收到CPU 1的“ Read”消息,然后发送变量b的新值给CPU 1,并将该缓存行状态修改Shared。
- CPU 1接收变量b的新值存放在其缓存中。
- CPU 1现在完成了while(b == 0)continue语句的执行,因为它发现了变量b为1,进入下一个语句。
- CPU 1执行assert(a == 1),并且由于CPU 1的缓存中存放的是变量a的旧值,此时断言失败,a == 1结果为false。
- CPU 1处理Invalidate Queue中的Invalidate消息,将自身变量a对应的缓存行置为Invalid。但是为时已晚。
以上就是引入Invalidate Queue之后造成的可见性问题。解决的办法,还是使用内存屏障。
void foo(void)
{
a = 1;
smp_mb();
b = 1;
}
void bar(void)
{
while (b == 0) continue;
smp_mb();
assert(a == 1);
}
如上所示,在assert(a == 1)断言之前加入smp_mb()。这个地方的内存屏障有着更丰富的语义,它会先把 Invalidate Queue 的消息全部标记,并且强制要求 CPU 必须等待 Invalidate Queue 中被标记的失效消息真正应用到缓存后才能执行后续的所有读操作。
六、读写内存屏障
再看上面的代码例子中,其实foo方法中的smp_mb只需要处理store Buffer,不需要处理Invalidate Queue。而bar方法中的smp_mb只需要处理Invalidate Queue而不需要处理Store Buffer。所以cpu的设计者把smp_mb(内存屏障)进行了功能上的拆分,分别拆分成smp_rmb(读内存屏障)和smp_wmb(写内存屏障)。
此时,上述例子就变成了:
void foo(void)
{
a = 1;
smp_wmb();
b = 1;
}
void bar(void)
{
while (b == 0) continue;
smp_rmb();
assert(a == 1);
}
smp_wmb(写内存屏障):**执行后会等待Store Buffer把写入同步到缓存中才能执行后续的写操作。**由于该动作会向其他CPU发送Invalidate消息,即 smp_wmb之前的写操作能被其他CPU所感知。使用 写内存屏障 指令可以保证前后写操作之间的顺序性。
smp_rmb(读内存屏障):**执行后会等待Invalidate Queue的失效消息生效到缓存中才能执行后续的读操作。**该操作会使Invalidate消息对应的缓存真正失效。使用 读内存屏障 指令可以保证前后读操作之间的顺序性。
通过对内存屏障进行功能上的划分,提供更轻量级,性能消耗更小的指令,可在适当场景使用适当的指令,做到保证可见性的同时最小化性能开销。
七、总结
我们梳理下本篇文章的内容和逻辑:
- 由于CPU访问内存的速度太慢,所以在CPU和内存中间加了缓存。
- 由于加入了缓存,导致出现数据不一致的问题,进而使用了MESI缓存一致性协议。
- 由于缓存一致性协议中修改数据同步通知其他CPU会大大降低性能,所以引入Store Buffers和Invalidate Queues,把这个通知动作异步化。
- 由于通知异步化后一样会出现数据不一致的问题,所以出现了内存屏障。
从上述我们可以看出CPU的设计者是如何在性能和数据一致性问题(可见性)中做权衡的。
最终CPU的方案就是尽可能的提高CPU的性能(性能优先),会牺牲内存可见性,会对指令进行乱序执行,它认为大部分的程序我们都不需要关心可见性和乱序问题。
而对于少部分关心可见性和乱序问题的程序,可通过在代码中插入内存屏障指令的方式,牺牲CPU性能去获得内存可见性以及禁止乱序执行的特性。
内存屏障带来了代码上的侵入性,但是也提供了CPU的控制机制,让开发者自己在性能和可见性之间做抉择。
再聊聊CPU的乱序执行:绝大多数的CPU为了提高性能,可以不等待指令结果就执行后面的指令,如果前后指令不存在数据依赖的话。乱序执行不会影响单个CPU的执行结果,但对其他CPU来说就有可能产生不可预估的影响。
我们可以发现,CPU的内存可见性问题和指令乱序问题,其实从某种意义看,两者其实是一码事。
当一个CPU的值修改对于另一个CPU来说不可见时,此时站在另一个CPU的视角上看,该CPU指令就像是被乱序执行了。而当指令被乱序执行后,一样会产生内存的可见性问题。
写在最后,CPU的架构方案也在不断的演进。本文通篇讲述的CPU架构适用于SMP(对称多处理器架构)。对于其他CPU架构(比如NUMA)可能架构差异较大,但是架构设计的出发点都是为了性能。
写在最后的最后,java就是通过内存屏障处理CPU的可见性问题。那,具体细节呢?我们下篇将会进行更详细的说明,我们下期再见💁🏻♂️
果就执行后面的指令,如果前后指令不存在数据依赖的话。乱序执行不会影响单个CPU的执行结果,但对其他CPU来说就有可能产生不可预估的影响。
我们可以发现,CPU的内存可见性问题和指令乱序问题,其实从某种意义看,两者其实是一码事。
当一个CPU的值修改对于另一个CPU来说不可见时,此时站在另一个CPU的视角上看,该CPU指令就像是被乱序执行了。而当指令被乱序执行后,一样会产生内存的可见性问题。
写在最后,CPU的架构方案也在不断的演进。本文通篇讲述的CPU架构适用于SMP(对称多处理器架构)。对于其他CPU架构(比如NUMA)可能架构差异较大,但是架构设计的出发点都是为了性能。
写在最后的最后,java就是通过内存屏障处理CPU的可见性问题。那,具体细节呢?我们下篇将会进行更详细的说明,我们下期再见💁🏻♂️















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









