







什么是Spark
Apache Spark™是一个多语言引擎,用于在单节点机器或集群上执行数据引擎、数据科学和机器学习。现在主要强调是数据引擎、数据科学及机器学习。
Spark内置组件
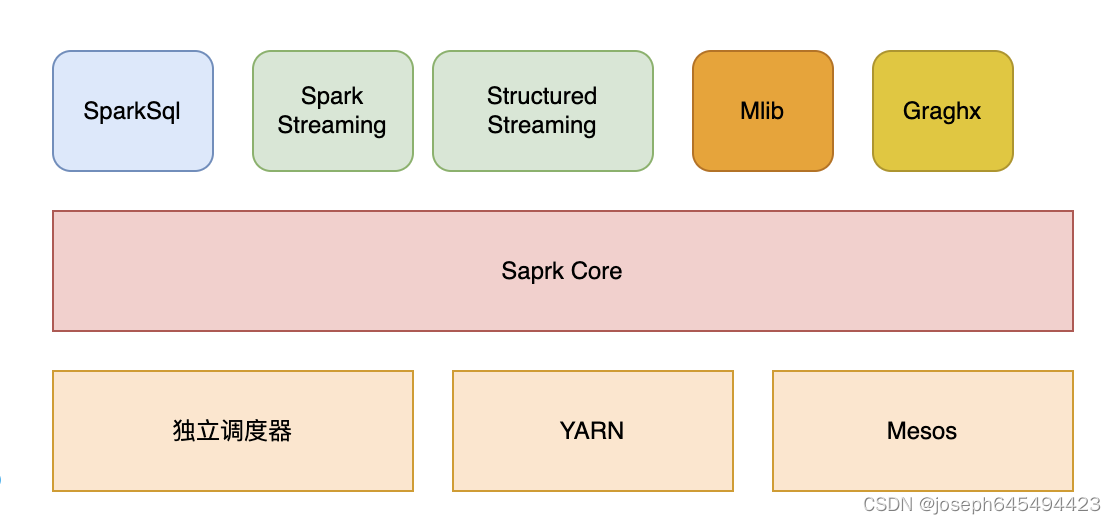
- Spark Core:实现了spark的基本功能,包含任务调度、内存管理、shuffle实现等。这些都是最底层的实现。
- Spark Sql:是spark用来处理结构化数据的,可以使用spark sql直接访问hive的表,用来进行跑任务,spark3已经完全兼容hivesql,并且还兼容hive的自定义函数。
- Spark Streaming:是对实时数据处理的组件,原理上还是对批的数据,只是时间间隔变短,但是这个组件不能做到精确一次。如果要做到精确一次,需要自己进行处理。例如消费kafka,需要自己保存offset,这样就可以做到精确一次处理.
- Structured Streaming:处理结构化流,并且实现流批一体,并且也能做到精确一次处理,可以完全替代Spark Streaming.
- Mlib:提供常用的机器学习的程序库。
- Graghx:用于进行图计算的API,能在海量的数据上进行复杂的图运算。
Spark特点
- 计算速度快
与hadoop相比,spark基于内存的计算要比hadoop快100倍,基于硬盘的运算也要快10倍以上。Spark实现DAG执行计算,可以通过内存进行高效的处理数据流。 - 易用
spark提供java、scala、python和R的API,用户可以选择不同的语言进行编写程序; - 通用
Spark 提供了统一的解决方案。Spark 可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark 统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。 - 兼容性
spark可以用YARN和Mesos作为资源管理和调度器。并且可以处理所有 Hadoop 支持的数据,包括 HDFS、HBase 和 Cassandra 等。这对于已经部署 Hadoop 集群的用户特别重要,因为不需要做任何数据迁移就可以使用 Spark 的强大处理能力。
Spark为什么比hadoop快呢
- spark的设计是基于内存进行数据处理,如果内存不足,可以溢出到磁盘;hadoop的设计是基于磁盘进行数据处理;
- spark基于DAG的有向无环图来进行任务调度,这样可以减少shuffle和落盘的次数;
- spark是申请资源是一次申请足够,如果不够,知道足够才进行数据处理;hadoop有多少就申请多少,如果不够,边执行边申请资源。
Spark的运行模式
- local模式
直接在本地执行,线程数指定用local[2]来指定 - Standalone模式
spark自带的资源调度引擎,构建一个master和slave构成的spark集群,master管理资源 - YARN模式
任务提交到YARN上,YARN来分配资源
WordCount案例
object WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[1]").setAppName("WC")
val sc: SparkContext = new SparkContext(conf)
val value: RDD[(String, Int)] = sc.textFile("data/test.txt").flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
value.foreach(println)
sc.stop()
}
}















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









