







 本文介绍了线性时间排序的三种算法:计数排序、基数排序和桶排序。计数排序通过计算每个元素出现的次数确定输出位置,时间代价为O(k+n);基数排序利用数字的每一位进行排序,最优时间复杂度为Θ(bn/lgn);桶排序则是将元素分布到不同桶中再分别排序,期望运行时间为Θ(n)。这些算法在特定条件下能实现线性时间复杂度,但并非总是优于O(nlgn)的比较排序算法。
本文介绍了线性时间排序的三种算法:计数排序、基数排序和桶排序。计数排序通过计算每个元素出现的次数确定输出位置,时间代价为O(k+n);基数排序利用数字的每一位进行排序,最优时间复杂度为Θ(bn/lgn);桶排序则是将元素分布到不同桶中再分别排序,期望运行时间为Θ(n)。这些算法在特定条件下能实现线性时间复杂度,但并非总是优于O(nlgn)的比较排序算法。
之前我们介绍了几种O(nlgn)的排序算法:快速排序、合并排序和堆排序,本节我们介绍基于比较的排序算法的下界以及几个线性时间的排序算法——计数排序、基数排序、桶排序。
一、 比较排序算法的下界
1、 决策树模型:比较排序可以被抽象的视为决策树。一棵决策树是一棵满二叉树,表示某排序算法 作用于给定输入所做的所有比较。
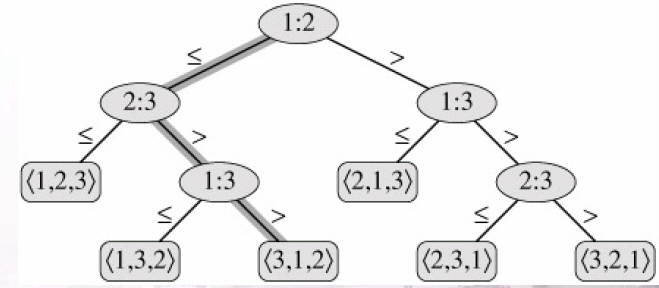
排序算法的执行对应于遍历一条从树的根到叶结点的路径。在每个内节结点处要做比较。
要使排序算法能正确的工作,其必要条件是,n 个元素的n!种排列中的每一种都要作为决策树 的一个叶子而出现。
2、 在决策树中,从根到任意一个可达叶节点之间最长路径的长度,表示对应的排序算法中最坏 情况下的比较次数。这样,一个比较排序算法 中的最坏情况比较次数就与其决策树的高度相等。
3、 定理: 任意一个比较排序算法在最坏情况下,都需要Ω(nlgn)次的比较。
证明: 对于一棵每个排列都作为一个可达叶结点出现的决策树,根据前面的讨论即可确定其高度。考虑一棵高 度为h的、具有l个可达叶结点的决策树,它对应于对n 个元素所做的比较排序。因为n个输入元素共有n!种排列,每一种都作为一个叶子出现在树中,故有n!≤l。又由于在一棵高为h的二叉树中,叶子的数目不多于2^h,则有
n!<= l <= 2^h
对该式取对数,得到
h≥lg(n!)=Ω(nlgn)
3、 推论:堆排序和归并排序是渐进最优的比较算法。
证明:堆排序和归并排序的运行时间上界O(nlgn)与定理8.1给出的最坏情况下界Ω (nlgn)一致。
注: 快速排序不是渐进最有的比较算法,因为快速排序的最坏情况运行时间是O(n^2)
二、 计数排序
计数排序假设n个输入元素中的每一个都是介于0到k之间的整数,此处k为某个整数,当k=O(n) 时,技术排序的运行时间是O(n)。
1、 基本思想: 计数排序的基本思想就是对每一个输入元素x, 确定出小于x的元素个数。有了这一信息,就可以把x直接放到它在最终输出数组中的位置上。
Count-Sort(A, B, k)
1 for i <-- 0 to k
2 do C[i] <-- 0
3 for i <-- 1 to length[A]
4 do C[A[i]] <-- C[A[i]] + 1
5 for i <-- 1 to k
6 do C[i] <-- C[i-1] + C[i]
7 for j <-- length[A] downto 1
8 do B[C[A[j]]] <-- A[j]
9 C[A[j]] <-- C[A[j]] - 12、 计数排序时间代价:Θ(k+n), 实践中当k=O(n)时,运行时间为O(n)。
3、 计数排序的特点:
a、 计数排序算法没有用到元素间的比较,它利用元素的实际值来确定它们在输出数组中的位置,不是一个基于比较的 排序算法,从而它的计算时间下界不再是Ω(nlogn);
b、 由于算法第4行使用了downto语句,经计数排序,输出序列中值相同的元素之间的相对次序与他们在输入序列中的相 对次序相同,因此计数排序算法是一个稳定的排序算法。 在卫星数据排序和基数排序中间应用。
三、 基数排序
基数排序(radix sort)是一种用在老式穿卡机上的算法。
1、 直觉上,大家可能觉得应该按最重要的一位排序,然后对每个盒子中的数递归地排序,最后把结果合并起来。与人 们的直觉相反,基数排序是首先按最低有效位数字进行排 序,以解决卡片排序问题。
2、 基数排序算法
Radix-Sort(A, d)
1 for i <-- 1 to d
2 do use a stable sort to sort array A on digit i3、 引理:给定n个d位数,每一个数可以取k中可能的值。如果所用的稳定排序需要Θ(n+k)的时间,基数排序算法能以Θ(d(n+k))的时间正确的对这些数进行排序。
4、 引理:给定n个b位数和任何正整数r≤b, RADIX-SORT能在Θ( (b/r)*(n + 2^r) ) 时间内正确的对这些数进行排序。
对于给定的n值和b值,我们希望所选择的r值(r ≤ b) 能够最小化表达式(b/r)(n+2^r).
a、 如果b < floor(log n), 则对任何满足r <= b的r值,都有(n+2^r)= Θ(n)。于是,选择r=b得到的运行时间为(b/b)(n+r^b)= Θ(n),从渐进意义上来看,这一时间是最优的。
b、 如果b >= floor(log n),则选择r = floor(log n), 可以给出在某一常数因子内的最佳时间,如此选择得到的运行时间为 Θ(bn/lgn)。
如果增大r,分子中的2^r增大的会比分母中的r快,导致运行时间增加。
如果减少r,b/r项会增大,但是分子仍为Θ(n),最后的结果还是导致运行时间增加。
5、 基数排序与比较排序:
a、 如果根据常见的情况有b=O(lgn)并选择r≈lgn,则基数排序的运行时间为O(n),这看上去要比快速排序的平均情况时间O(nlgn)更好些。
b、 在这两个时间中隐含在O记号中的常数因子是不同的。对于要处理的n个关键字,尽管基数排序执行的遍数可能要比快速排序要少,但每一遍所需的时间 都要长得多。
c、 此外,利用计数排序作为中间稳定排序的基数排序不是原地排序,而很多O(nlgn)时间的比较排序算法则可以做到原地排序。因此当内存容量比较宝贵 时,像快速排序这样的原地排序算法可能是更为可 取的。
四、 桶排序
1、 基本思想:桶排序的思想就是把区间[0,1)划分成n个相同大小的子区间,或称桶。然后,将n个输入数分布到各个桶中去。因为输入数均匀且独立均匀分布在[0,1)上,所以,一般不会有很多数落在一个桶中的情况。为得到结 果,先对各个桶中的数进行排序,然后按次序把各个桶 中的元素列出来即可。
2、 在桶排序算法的代码中,假设输入是个含n个元素的数组A,且每个元素满足0≤A[i]<1。另外还需要一个辅助数组B[0..n-1]来存放链表实现的桶,并假设可以用某种机制来维护这些表。
Bucket-Sort(A)
1 n<--length[A]
2 for i <-- 1 to n
3 do insert A[i] into list B[floor(n*A[i])]
4 for i <-- 0 to n-1
5 do sort list B[i] with insertion sort
6 concatenate the list B[0]...B[n-1] together in order因为插入排序以二次时间运行, 因而桶排序的运行时间:
两边求期望,利用线性性质:
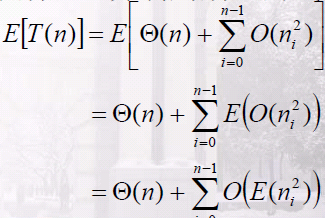
下式对每一个i都成立,因为输入数组A中的每一个值都是等可能地落在任何桶内的
为证明上式,我们定义我们定义指示器随机变量Xij = I { A[j]落在桶i中 }, Xij为1 的 概率为1/n
于是第i个桶中的元素个数为:
将平方项扩展重新组合:
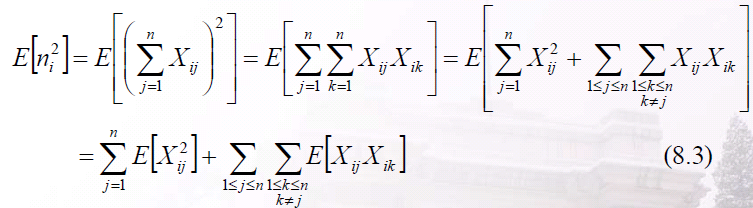
由于Xij为1 的概率为1/n,故
所以,
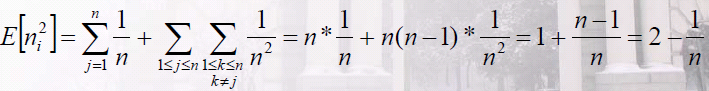
因此,桶排序的期望运行时间为Θ(n) + n*O(2- 1/n)= Θ(n)















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









