







搜索一个图是有序地沿着图的边访问所有定点, 图的搜索算法可以使我们发现很多图的结构信息, 图的搜索技术是图算法邻域的核心。
一、 图的两种计算机表示
1、 邻接表: 这种方法表示稀疏图比较简洁紧凑。
typedef struct{
int adjvex;//邻接顶点的位置
struct ArcNode *next;
int weight;//边的权重
}ArcNode;
typedef struct{
VertexType data;
ArcNode *firstarc;
}VNode, AdjList[MAX_VERTEX_NUM];
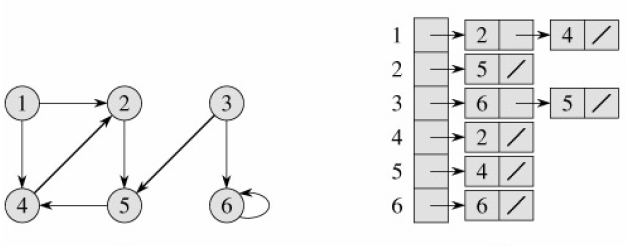
b、 邻接表中的顶点数即图中的节点数V,若G是无向图,那么所有邻接表的长度和为2E,若G是有向图,所有邻接表的长度和为E。
c、 无论有向图还是无向图,所需要的存储容量为O(V+E)。
d、 不足:确定边是否存在需要在顶点的邻接表中搜索所有顶点。
2、 邻接矩阵法:这种方法适合稠密图,能很快判断两个顶点是否相邻。
邻接矩阵先对图中的顶点进行编号1...|V|,编号之后,用一个|V| X |V| 矩阵来表示图,矩阵中的元素aij是否为0表示Vi和Vj之间是否有边,存储矩阵的空间为O(|V|^2),与边数无关。
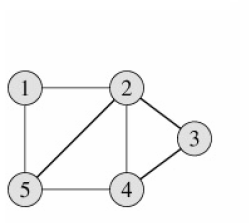
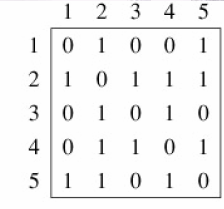
a、 在无向图的有些应用中,为了节省存储空间可以只存储上三角或者下三角矩阵;
b、 边的权重可以用矩阵元素存储;
c、 对于非加权图用一个二进制位来表示是否有边可以节省存储空间。
二、 广度优先的图搜索算法
给定一个图G=(V, E)和源点s, 广度优先搜索算法系统地探寻G所有的边,从而发现从s可达的所有 的顶点,并计算s到所有这些顶点的距离(最少边数)。该算法同时生成一棵根为s且包含所有可达顶点的广度优先树。对于从s出发的任意节点,广度优先树中从s到v的路径对应G中从s到v的最短路径。算法对有向图和无向图都同样有效。算法自始至终通过已找到和未找到顶点之间的边界向外扩展。
1、 执行过程:广度优先搜索为每个顶点着色(白灰黑),开始的时候都是为白色。第一次碰到一个顶点的时候,称顶点被发现,此时顶点由白色变成非白色。灰色和黑色顶点都是被发现的顶点。与黑色顶点邻接的所有顶点都是已被发现的。灰色顶点可以与一些白色顶点邻接,代表已发现和未发现的边界。
2、 广度优先搜索建立了一棵广度优先树,每当一个白色顶点被发现时,该顶点与相关的边就被添加到树中。
3、 附加数据结构:存储颜色的数组color,存储父母节点的pi,以及存储从源点s到顶点的最短距离的d,存放灰色节点的先进先出队列Q。
BFS(G, s)
1 for each vertex v in {G}-{s}
2 do color[v]<--white
3 d[v]<--0
4 pi[v]<--0
5 color[s]<--gray
6 d[s]<--0
7 pi[s]<--nil
8 Q<--NULL
9 Enqueue(Q, s)
10while Q != NULL
11 do u<--Dequeue(Q)
12 for each v in Adj[u]
13 do if color[v]<--white
14 then color[v]<--gray
15 d[v]<--d[u]+1
16 pi[v]<--u
17 Enqueue(Q, v)
18 color[u]<--black4、 广度优先搜索的结果与12行中给定顶点的邻接点的访问顺序有关,产生的广度优先树可能不同,但是计算出来d是一样的。
5、 灰色顶点的父节点未必是黑色顶点,在11-18行中间产生灰色节点的时候,其父节点尚未变黑。
6、 运行时间:第13行的测试保证每个节点至多只入队列一次,因而也至多只出队列一次,队列操作所用时间为O(V),每个顶点出队列时访问其邻接表,因此每个顶点的邻接表至多只访问一次,所有邻接表表长之和为O(E),因此总的时间复杂度为O(v+E)。
7、 对于一个图,广度优先搜索可以得到从s可达的每个节点的距离。
8、 广度优先树:在BFS的搜索图的同时建立了一棵广度优先树,这棵树是由每个结点的pi域表示。
前驱子图:对于图G=(V,E),给定原点s,其前驱子图Gpi = {Vpi, Epi}
其中,Vpi = {v∈V, pi(v) != nil} ∪{s}
Epi = {(pi(v), v) : v∈ Vpi - {s}}
如果Vpi由从s可达的所有定点构成,那么Gpi是一棵广度优先树,且| Epi | = | Vpi | - 1
定理: 如果DFS应用于一个有向图或无向图,该过程同时建立的pi域满足条件:其前驱子图 Gpi = {Vpi, Epi}是一棵广度优先树。
Print-Path(G, s, v)
1 if s = v
2 then print s
3 else if pi[v] = nil
4 then print error "no path exist"
5 else Print-Path(G, s, pi[v])
6 print v三、 深度优先的图搜索算法
深度优先搜索所遵循的策略是尽可能深的搜索图。在深度优先搜索的过程中,对于新发现的节点,如果还有以此节点为起点而为探寻到的边,就沿着此边继续探寻下去。当节点v的所有边已被探索过或者无边可探,就回溯到以发现此节点v的节点为起点的边,这个过程一直进行到发现从原点可达的所有节点为止。如果还存在未发现的节点,就从中选一个为起点重新开始探索。如果此反复,直到所有的节点都被探寻到为止。
1、 深度优先搜索的先辈子图形成一个由数个深度优先树组成的深度优先森林。
2、 深度优先搜索也为节点着色,最开始为白色,探寻到的时候置为灰色,结束时置为黑色。这样可以保证每个节点只存在于一棵深度优先树中。
3、 除了创建一棵深度优先树之外,DFS还为每个节点加盖时间戳,当节点第一次被发现时(置为灰色)记下第一个时间戳d[v],当结束检查v的邻接表时(置为黑色),记下第二个时间戳f[v]。在d[v]之前v是白色的,在f[v]之后v是黑色的,在d[v]和f[v]之间v是灰色的。
4、 深度优先搜索算法:有DFS和DFS-Visit两个过程组成
DFS(G)
1 for each vertex v in V
2 do color[v]<--white
3 d[v]<--0
4 f[v]<--0
5 pi[v]<--nil
6 time<--0
7 for each vertex u in V
8 do if color[u] = white
9 then DFS-Visit(G, u)
DFS-Visit(G, u)
1 color[u]<--gray
2 time<--time+1
3 d[u]<--time
4 for each vertex v in Adj[u]
5 do if color[v] = white
6 pi[v]<--u
7 DFS-Visit(G, v)
8 color[u]<--black
9 time<--time+1
10f[u]<--time时间复杂度为Θ(V+E)。
5、 边的分类:根据DFS产生的深度优先森林,可以将边分成四类——树边,正向边,反向边,交叉边。6、 深度优先搜索的发现和完成时间具有括号性质。
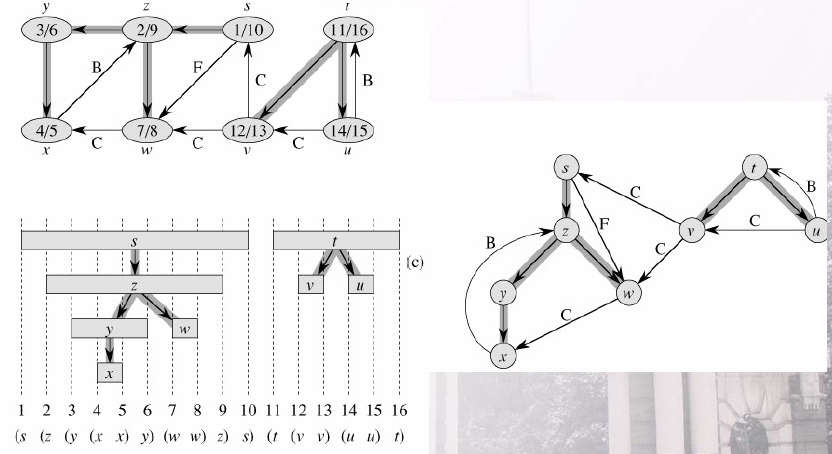
7、 白色路径定理: 在一个图G=(V,E)(有向或无向图)的深度优先森林中,结点v是结点u的后裔当且仅当在搜索中于d[u]时刻发现u时,可以从顶点u出发,经过一条完全由白色顶点组成的路径到达v。
8、 可以对算法DFS进行一些修改,使之遇到边时能对其进行分类。算法的核心思想在于对于每条边(u,v),当该边第一次被探寻到时,即根据所到达的结点v的颜色,来对该边进行分类(但正向边和交叉边不能用颜色区分出):
a、 白色表明它是树边;
b、 灰色说明它是反向边;
c、 黑色表示他是正向边或者交叉边。如果d[u]<d[v],则边(u,v)就是正向边,反之就是交叉边。
9、 以上分类对于无向图来说,可能会有歧义。在对无向图G进行深度优先搜索的过程中,G的每条边要么是树边,要么是反向边。
四、 拓扑排序
一个图的拓扑排序可以看成是图的所有顶点沿水平线排成的一个序列,使得所有的有向边均从左指向右。
1、 下面简答的算法可以对有向图进行拓扑排序:
TOPOLOGICAL-SORT(G)
a、 调用DFS(G)计算每个节点v的f[v];
b、 当每个顶点完成后,把它插入链表前端;
c、 返回由顶点组成的链表。
因为深度优先搜索的运行时间为Θ(V+E),而将|V|个顶点中的每一个插入链表所占用的时间为O(1),因此进行拓扑排序的运行时间为Θ(V+E)。
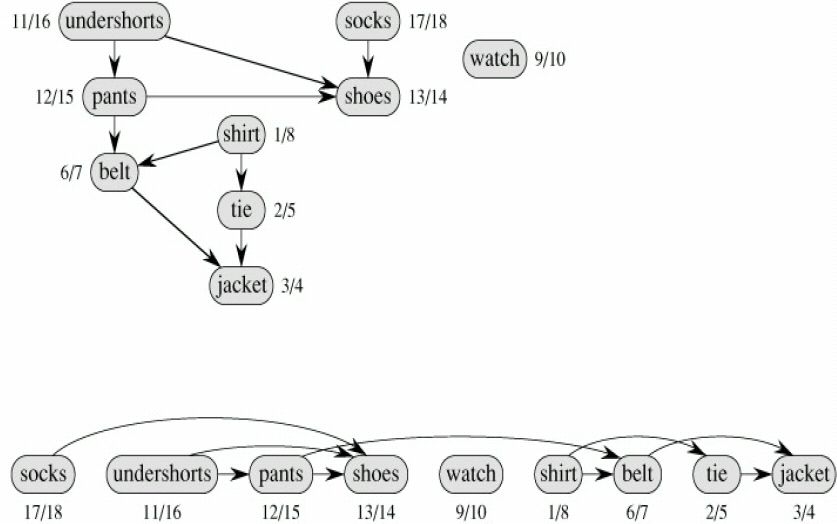
上述算法是否可以改成当探寻到每个定点d[v]的时候,就将定点插入到链表的尾端呢?不行。如下图所示,如果这样的话,shoes就在socks的前面了,事实上,socks到shoes有一条有向边,shoes应该在socks的后面,矛盾。
2、 引理:有向图G无回路当且仅当对G进行深度优先搜索没有得到反向边。
3、 定理: TOPOLOGICAL-SORT (G) 算法可产生有向无回路图G的拓扑排序。
五、 强连通分枝
1、 在有向图中,如果任何两个不同的定点都相互可达,则称有向图是强连通的。一个有向图的极大强连通子图称为其强连通分枝。
2、 很多有关有向图的算法都从分解步骤开始,这种分解可把原始的问题分成数个子问题,其中每个子子问题对应 一个强连通分支。构造强连通分支之间的联系也就把子问题的解决方法联系在一起,我们可以用一种称之为分支图的图来表示这 种构造。
3、 寻找图G=(V,E)的强连通分支的算法中使用了G 的转置,即E‘由G中的边改变方向后组成。若已知图G的邻接表,则建立GT所需时间为O(V+E)。G和G’有着完全相同的强连通支, 即在G中u和v互为可达当且仅当在GT中它们互为可达。
4、 下列运行时间为Θ(V+E)的算法可得出有向图G=(V,E)的强连通分支,该算法使用了两次深度优先搜索,一次在 图G上进行,另一次在图G‘上进行:
Strongly_Connected_Components(G)
a、 调用DFS(G)以计算出每个结点u的完成时刻f[u];
b、 计算出G’;
c、 调用DFS(GT),但在DFS的主循环里按f[u]递减的顺序考虑各结点(和第一行中一样计算);
d、 输出第3步中产生的深度优先森林中每棵树的顶点, 作为各自独立的强连通分支。
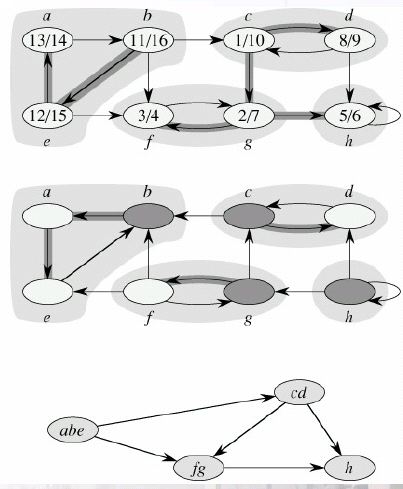
Strongly_Connected_Component算法的思想来自于分支图GSCC = (VSCC, ESCC)的一个重要性质:
假设G的强连通分支为C1 , C2 ,..., Ck。顶点集Vscc 为{v1 , v2 ,..., vk }, 对于G的每一个强连通分支Ci ,都包含一个顶点vi。如果对于某个x ∈Ci 以及某个y ∈Cj,G中包含了一条有向边(x, y) 的话,则就有一条边(vi , vj ) ∈Escc;从另一方面看,收缩那些其关联顶点都处于G的同一强连通分支内的边,即可得到图Gscc。
5、 引理:设C和C′是有向图G = (V, E)中的两个不同的强连通分支,设u, v ∈C, u′, v′∈C′, 并假设G中存在着一条通路u→u′,那么G中就不可能同时存在通路v′→ v。
6、 引理: 设C和C’为有向图G=(V,E)中的两个不同的强连通分支。假设一条边(u,v) ∈E,其中u ∈C,v ∈C’,则f(C)>f(C’)。
推论:设C和C’为有向图G=(V,E)中两个不同强连通分支,假设存在着一条边(u, v) ∈ET, u ∈C且v ∈ C′. 那么f(C) < f(C′)。
7、 Strongly_Connected_Components(G)能正常工作的原因:
a、 第二次在GT 上执行深度优先搜索:从强连通分支C开始,f(C)是最大的,搜索从C的某个顶点x开始,访问C 所有顶点。
b、 根据推论,GT没有从C到其他连通分支的边。根为x的树仅包含C中的顶点。
c、 接下来访问C’,f(C’)是f(C)外最大的,与访问C过程类似当算法第3行对GT 进行深度优先搜索时,该分支出来的任何边都指向已被访问过的分支。
因此,每颗深度优先树都是一个强连通分支。















 1945
1945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









