







 本文详细介绍了HiveSQL,包括DDL(数据定义语言)操作,如创建、删除和修改表,以及DML(数据操作语言)和DQL(数据查询语言)操作,如加载数据、查询和数据处理。Hive基于Hadoop,提供SQL查询功能,适合大规模数据分析,但不支持实时查询和UPDATE、DELETE操作。
本文详细介绍了HiveSQL,包括DDL(数据定义语言)操作,如创建、删除和修改表,以及DML(数据操作语言)和DQL(数据查询语言)操作,如加载数据、查询和数据处理。Hive基于Hadoop,提供SQL查询功能,适合大规模数据分析,但不支持实时查询和UPDATE、DELETE操作。
Hive 是基于Hadoop构建的一套数据仓库分析系统,他以SQL查询的方式来分析存储在Hadoop分布式文件系统中的数据,将结构化的数据文件映射成一张表,并且提供了完整的SQL查询功能,可以将SQL语句转化成为MapReduce任务运行。这一套SQL就是HiveSQL。对于不熟悉MapReduce的人来说,使用类似SQL的语句就可以很方便地通过查询语句来分析数据。而MapReduce的开发人员,也可以把自己编写的mapper和reducer作为插件支持hive进行更加复杂的数据分析工作。
HiveSQL与关系数据库中的SQL略有不同:HiveSQL支持绝大多数的DDL,DML以及连接查询、条件查询和聚合函数。但是HIVE不支持OLTP,也不支持实时查询。
一、 DDL操作(Data Definition Language)
DDL
•建表
•删除表
•修改表结构
•创建/删除视图
•创建数据库
•显示命令
1. 创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[ STORED AS file_format ]
[LOCATION hdfs_path]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[ STORED AS file_format ]
[LOCATION hdfs_path]
•CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常
•EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
•LIKE 允许用户复制现有的表结构,但是不复制数据
•COMMENT可以为表与字段增加描述
•ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
- STORED AS
SEQUENCEFILE
| TEXTFILE
| RCFILE
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE 。
1). External: 外部表和内部表
Hive的数据表分为两种:
外部表和内部表
。内部表是Hive创建并通过load data inpath加载到数据库中的表。这种表可以理解为数据和表结构都保存在一起的表。
当你通过DROP TABLE table_name 删除元数据中表结构的同时,表中的数据也同样会从hdfs中被删除。
外部表指在表结构创建以前,数据已经保存在hdfs中了,通过创建表结构,将数据格式化到表的结构里。当DROP TABLE table_name 的时候,hive仅仅会删除元数据的表结构,而不会删除hdfs上的文件,所以,相比内部表,外部表可以更放心大胆的使用。
内部表的创建:
CREATE TABLE database.table1
(
column1 STRING COMMENT 'comment1',
column2 INT COMMENT 'comment2'
);
外部表创建,下面是hdfs中文件不用LZO压缩,纯文本保存时,如何创建外部表:
CREATE EXTERNAL TABLE IF NOT EXISTS database.table1
(
column1 STRING COMMENT 'comment1',
column2 STRING COMMENT 'comment2'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION 'hdfs:///data/dw/asf/20120201';CREATE EXTERNAL TABLE IF NOT EXISTS database.table1
(
column1 STRING COMMENT 'comment1',
column2 STRING COMMENT 'comment2'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
STORED AS INPUTFORMAT "com.hadoop.mapred.DeprecatedLzoTextInputFormat" OUTPUTFORMAT "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"
LOCATION 'hdfs:///data/dw/asf/20120201';2)创建分区表:
在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。分区表指的是在创建表时指定的partition的分区空间。如果需要创建有分区的表,需要在create表的时候调用可选参数partitioned by,详见表创建的语法结构。
技术细节:
a、一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
b、表和列名不区分大小写。
c、 分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
d、 分区建表分为2种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式。
单分区表:
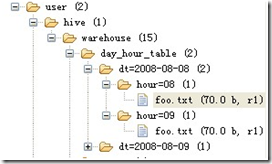
create table day_table (id int, content string) partitioned by (dt string);create table day_hour_table (id int, content string) partitioned by (dt string, hour string);双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。表文件夹目录示意图(多分区表):
e、 添加分区表语法(表已创建,在此基础上添加分区)
ALTER TABLE table_name ADD
partition_spec [ LOCATION 'location1' ]
partition_spec [ LOCATION 'location2' ] ...
partition_spec:
: PARTITION (partition_col = partition_col_value,
partition_col = partiton_col_value, ...)
ALTER TABLE day_table ADD
PARTITION (dt='2008-08-08', hour='08')
location '/path/pv1.txt'
PARTITION (dt='2008-08-08', hour='09')
location '/path/pv2.txt';ALTER TABLE table_name DROP
partition_spec, partition_spec,...
用户可以用 ALTER TABLE DROP PARTITION 来删除分区。分区的元数据和数据将被一并删除。例:
ALTER TABLE day_hour_table DROP PARTITION (dt=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 705
705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









