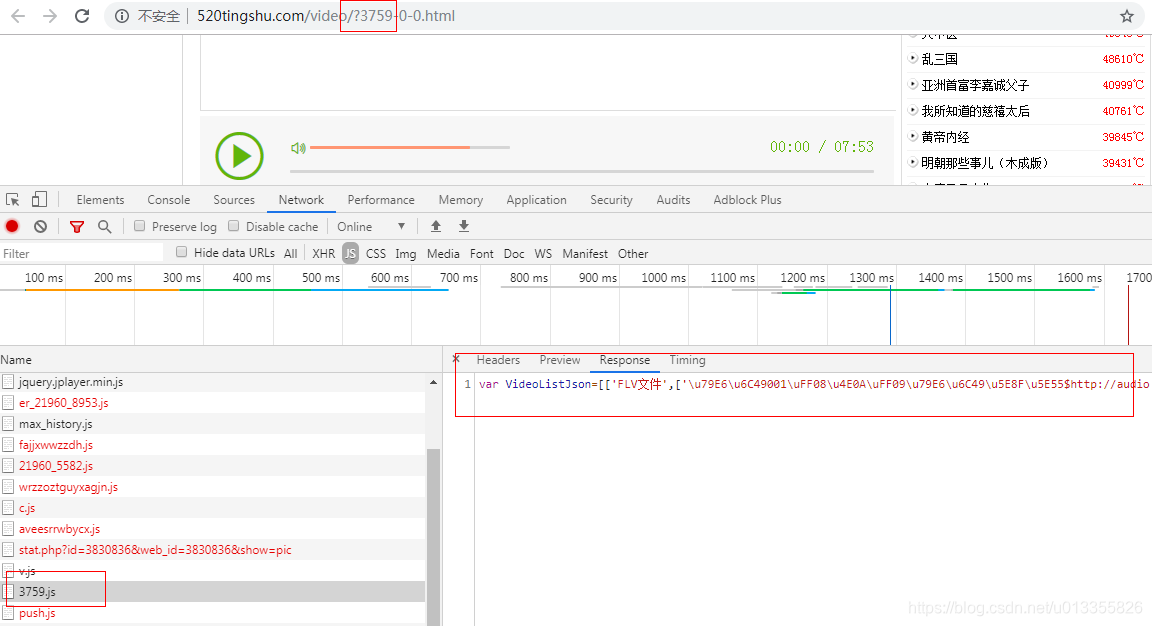
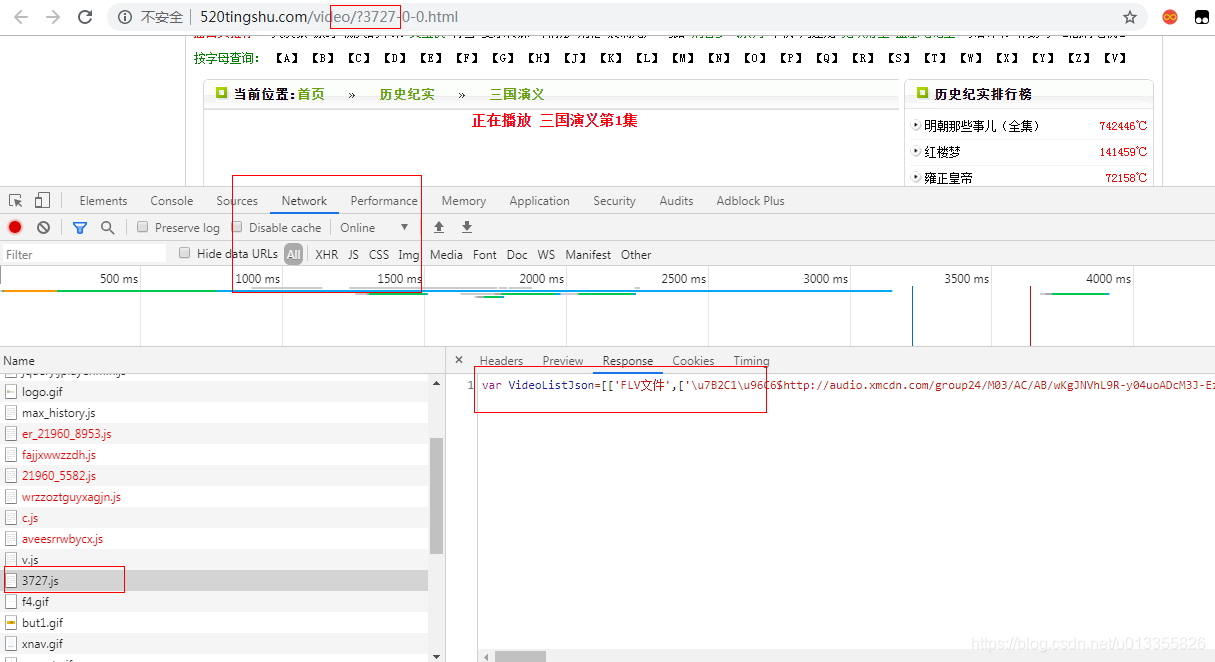
【郑重声明】本教程仅仅用于学习交流,并不诱导读者去恶意爬取520听书网的信息。 我一直很喜欢听书,哈哈,尤其是《听世界系列》,最近听完了听世界的春秋战国,最近听完了春秋战国系列,想听秦汉系列。从520听书网网站找到了,就想怎么从网站中把数据爬出来,分析网站,经过好长好长时间的分析,终于从某个地方看到某个系列的所有的url,如下图: 其中的VideoListJson就是这个系列的所有真实的url,剩下的就是通过request请求,然后保存数据。 我们以三国演义为例


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






