







1 导论
-
面向对象的语言大概有一下五个特性
- 万物皆为对象。
- 程序是对象的集合,他们通过发送消息来告知彼此所要做的事。
- 每个对象都有自己的由其他对象所构成的存储。
- 每个对象都有其类型。
- 某一特定类型的所有对象都可以接受同样的消息。
-
接口定义了对某一特定对象所能发出的请求。每一个对象都有一个接口,都提供服务。
-
类创建者的目标是构建类,这种类只向客户端程序员暴露必须的部分而隐藏其他部分
- 三个关键字:public、private、protected及默认。
-
这种概念称之为组合。如果组合是动态发生的,通常被称为聚合。视为"has-a"关系。
-
继承,即你可以以现有的类为基础,复制它,然后通过添加和修改这个副本来创建新类。当继承现有类型时,也就创造了新的类型。这个新的类型不仅包括现有类型的所有成员,并且复制了基类的接口。也就是说,所有可以发送给基类对象的消息同时也可以发送给导出类对象。
-
有两种方法可以使基类与其导出类产生差异。
- 直接在导出类中添加新方法。这些新方法不是基类接口的一部分。
- 改变现有基类方法的行为,称之为覆盖(overriding)。
-
只覆盖基类的方法,这样做二者具有相同的类型和相同的接口。这种情况下基类与导出类的关系称之为is-a关系。如果在导出类添加了新的接口元素,也就是扩展了接口,这种情况描述为is-like-a关系。
-
java默认动态绑定,不需要额外关键字来实现多态。将导出类看作是它的基类的过程称为向上转型
-
除了C++以外的所有OOP语言,所有的类最终都继承自单一的基类,这个终极基是Object。
-
如果不知道解决某个特定问题需要多少个对象,或者它们将存活多久,解决方案是用这个被称为容器的新对象在任何需要时都可以 扩充自己以容纳你置于其中的所有东西。虽然单一类型的容器可以满足所有操作,但是还是需要对容器有所选择
-
单根继承导致容器容易被复用,解决这个问题可以运用到转型,不过这里是向下转型,转型为更为具体的类型。这里可以以参数化类型机制的解决方案。
-
Java采用动态内存分配方式。每当想要创建新对象,就使用new关键字来构建此对象的动态实例。
-
在堆上创建对象,编译器对它的生命周期一无所知。java提供了垃圾回收器机制,它可以自动发现对象何时不再被使用,并继而销毁它。
-
异常是一种对象,从出错地点被抛出,并被专门设计用来处理特定类型错误的相应的异常处理器捕获。
-
程序中,彼此独立运行的部分称之为线程,多个独立运行的部分称之为并发。并发看起来简单,但是有个隐患:共享资源。为了解决这一问题,可以共享的资源,必须在使用期间被锁定。
2 一切都是对象
-
引用可以独立存在,并不要求一定需要和对象关联。
String s; -
创建了引用,可以与一个新的对象关联,通常使用new操作符来实现。
String s = new String("asdf"); -
五个不同存储位置:
- 寄存器:速度最快,处于处理器内部。
- 堆栈:位于通用RAM(随机访问存储器)中,通过堆栈指针从处理器那里获得直接支持。指针上移,释放内存;指针下移,分配内存。
- 堆:一种通用的内存池(也位于RAM区),用于存放所有的Java对象。
- 常量存储:通常直接存放在程序代码内部;
- 非RAM存储:数据存活于程序之外,可以不受程序的任何控制,程序不运行也可存在,典型例子:流对象和持久化对象
-
基本类型:
-
Java SE5后提供自动包装功能:
Character ch = ‘x’;char c = ch;高精度数字:
java提供了两个用于高精度计算的类:BigInter和BigDecimal。属于包装器类型,没有对应的基本类。
前者对应任意精度的整数;后者支持任意精度的定点数。
-
作用域由花括号的位置决定。java对象不具备和基本类型一样的生命周期。new一个对象,可以存活与作用域之外。
-
定义了一个类,可以在类中设置两种类型元素:字段(也称数据成员)和方法(也称成员函数)。字段可以是任何类型的对象或基本类型的一种。字段是对的某个对象的引用,则必须初始化.
-
若类的某个成员是基本数据类型,即使没有进行初始化,java也会确保它获得一个默认值。

-
方法基本组成:名称、参数、返回值、方法体。
ReturnType methodName( /* Argument list */ ) { /* Method body */ } -
java中的方法只能作为类的一部分创建。方法只有通过对象才能被调用,且这个对象必须能够执行这个方法的调用。
-
方法的参数列表指定要传递给方法什么样的信息。参数列表中必须指定每个所传递对象的类型和名字。传递的实际上是引用。
在程序中使用预先定义好的类,可以使用关键字:import;如果含类众多,可以使用通配符“*”;
- 声明一个事物是static,这个域或方法不会与包含它的那个类的任何对象实例关联在一起。即使从未创建某个类的任何对象,也可以调用其static方法或访问其static域。
- 引用static变量的两种方法:如上创建对象引用他;通过类名直接引用
所有的javadoc命令都只能在“/**”注释中出现,于“/*”结束。独立文档标签是以“@”字符开头的命令,且要置于注释行的最前面
-
共有三种类型的注释文档,分别对应于注释位置后面的三种元素:类、域和方法。
-
javadoc只能为public和protected成员进行文档注释
3 操作符
. () {} ; ,
++ -- ~ !(data type)
* / %
+ -
<< >> >>>
< > <= >= instanceof
== !=
&
^
|
&&
||
? :
= *= /= %=
+= -= <<= >>=
>>>= &= ^= |=
- 在为对象赋值的时候,如果对一个对象进行操作,我们操作的是对对象的引用.浮点型默认数据类型是double。
+=、-=、*=、/=、%=这些符号包含了强制转换。字符串与基本类型的操作要注意。- 等于与不等于适用于所有类型,其他比较符不适用于boolean。
- 逻辑操作符“与”(&&)、“或”(||)、“非”(!)根据参数的逻辑关系,生成一个布尔值。逻辑操作符只能用于boolean,不可将一个非布尔值当做布尔值在逻辑表达式中使用。
- 使用&&或||会出现一种短路的情况。
- 移位操作符的运算对象是二进制的位,只可用来处理整数类型。java中增加了无符号右移位操作符(>>>),无论正负,高位插0。
- 如果对char,byte,short类型进行移位处理,在移位之前要先转换为int类型。
三元操作符称作为条件操作符,它的表达式形式为:
boolean-exp?value0:value1,如果boolean-exp(布尔表达式)
- 字符串操作符是用来连接不同的字符串。即+与+=。 如果表达式一一个字符串起头,那么后续所有操作数必须是字符串型。
- 适当的时候,java会自动将一种数据转换为另一种数据类型,例如为浮点数赋予整数值,java会自动将整数值转换为浮点型。
- 大容量数据类型转换为小容量数据类型可能就会出现数据错误,而且浮点数数据类型转换为整数型数据类型是将小数点后的数舍去掉。
- “类”数据类型不允许进行类型转换
4 控制执行流程
-
java使用了c所有的控制流程语句,涉及到的关键字有:if-else、while、do-while、for、return、break以及选择语句break.java并不支持goto语句。
-
java中唯一用到逗号操作符的就是for循环的控制表达式。
-
**Java SE5引入了更简洁的for语法用于数组和容器。**即foreach语句,格式为:
for(datatype tempName:Name){ statement; } -
在任何迭代语句的主体部分都可以使用break和continue,其中使用break强行退出循环,不执行循环中的剩余语句,而continue则是停止执行当前的迭代,退回到循环起始处,开始下一次迭代。
-
java使用标签完成goto功能,利用break或continue与标签配合,可以中断循环,直到标签的所在位置。 (break 标签中断了所有迭代,并回到了标签,但不重新进入迭代;continue 标签同时中断内部迭代和外部迭代,直接转到标签处;随后它继续迭代)
-
在循环中退出方法,直接使用return语句即可。
-
switch(表达式)中的返回值必须是:byte,short,char,int,枚举,String,没有long类型;case子句中的值必须是常量,且所有case值应该是不同的。
5 初始化与清理
-
面向对象三大特征:封装;继承;多态
-
类与类之间的关系:关联,继承,聚集,组合。
-
构造器采用和类相同的名称。不显示声明类的构造器的话,程序会默认提供一个无参构造器;一旦显示定义了类的构造器,那么默认的构造器就不再提供。格式:
修饰符 类名(参数列表){ 初始化语句; } -
不能被static、final、synchronized、abstract、native修饰,不能有return语句返回值
-
Java语言中,每个类都至少有一个构造器;默认构造器的修饰符与所属类的修饰符一致;一个类可以创建多个重载的构造器;父类的构造器不可被子类继承
-
类中属性赋值的先后顺序:1.属性的默认初始化2数据的显示赋值3.通过构造器给属性初始化4.创建对象后,通过对象。方法的形式给属性赋值
方法区:含字符串常量;静态域:声明为static的变量;类的方法:提供某种功能的实现
-
方法内可以调用本类的其他方法或者属性,但是不能在方法内再定义方法。
-
相同的词表达不同的含义——即重载。重载格式规定很大一部分是由构造器造成的。使用方法名相同但是参数列表不同的构造器来实现,即实现了方法的重载。
-
方法重载的特点:与返回值类型无关,只看参数列表,且参数列表必须不同。(参数个数或参数类型或参数前后顺序)。
-
**方法重载时候,要注意传入的实际参数和方法中的形参的比较。**如果实参小于形参,实参会被提升。如果实参大于形参,没有进行类型转换,则出现异常。例如将
void find(int i)改为void find(byte i)。
this关键字只能在方法的内部使用,表示对“调用方法的那个对象”的引用。this在构造器中使用,表示该构造器正在初始化的那个对象。this表示当前对象或者当前正在创建的对象,可以调用类的属性,方法和构造器。
-
在方法内需要用到调用该方法的对象时,就用this
-
形参与成员变量重名的时候,如果方法内部需要使用成员变量,必须添加this来表明该变量是类成员
-
任意方法内,如果使用当前类的成员变量或者成员方法可以在其前面添加this,增加可读性。
-
使用this()必须放在构造器的首行!
-
使用this调用本类中其他的构造器,保证至少有一个构造器是不用this的。
-
static方法就是没有this的方法。在static方法内部是不能调用非静态方法,反过来可以。而且在没有任何对象的前提下,仅仅通过类本身来调用static方法。
finalize()不是作为通用的清理方法,关于finalize()方法的真正用途需牢记:垃圾回收只和内存有关。
-
当对某个对象不再感兴趣——也就是可以被清理。这个对象应该处于某种状态,使它占用的内存可以被安全地释放。
-
System.gc()用于强制执行终结动作。
System.gc()与System.runFinalization()不能确保finalize()方法一定被执行,没有办法保证finalize()会被调用
(垃圾回收器工作机制见Java虚拟机)
属 性:对应类中的成员变量 ;行 为:对应类中的成员方法
Field = 属性 = 成员变量,Method = (成员)方法 = 函数
-
类及类的构成成分:属性,方法,构造器,代码块,内部类
-
成员变量VS局部变量
- 声明的位置不一样:成员变量声明在类里,方法外;局部变量:声明在方法里,方法的形参部分,代码块内。
- 成员变量的修饰符有四个:public,private,protected 缺省
局部变量没有修饰符,与所在的方法修饰符一致。 - 初始化值:成员变量在声明时不显示赋值,则不同的数据类型一定会有默认的初始化值。
局部变量一定要显示赋值(无默认初始化值,除形参外) - 内存中存放位置不同:成员变量存在于堆空间中,局部变量在栈空间中。
-
可以在定义变量处赋值或构造器初始化或调用方法初始化
-
无论创建多少个对象,静态数据都只占一份存储内存区域。static关键字不能应用于局部变量。
关于数组的初始化可以有如下几种方式:
-
直接赋值(在已经数组的具体元素时)
int []a1={1,2,3,4,5}; -
静态初始化(分配空间和赋值同时进行)数组变量=new 数据类型[长度];
int a[] =new int[]{3,9,5}; -
动态初始化(只为数组申请分配空间)
int []a=new int[5]; -
为数组分配好内存空间,每个数组元素都会有自己的默认初始值,int是0,boolean类型是false等等,与成员变量相同。
-
二维数组
声明与申请存储空间:int mat[][]; mat = new int[2][3]; Or int mat[][]=new int[2][3]; Or 直接赋值 int mat[][]={{1,2,3},{4,5,6}};Mat.length//返回二维数组的长度,即二维数组的行数
Mat[0].length//返回一维数组的长度,即二维数组的列数
数组一旦初始化,长度是不可变的。 -
不规则的二维数组。
int mat[][]; mat=new int[2][]; //申请第一维的存储空间,即数组的行数 mat[0]=new int[2]; //申请第二维的存储空间],每行的列数 mat[1]=new int[3]; -
在java SE5中,添加了可变得参数列表,等价于数组
//下面采用数组形参来定义方法 public static void test(int a ,String[] books); //以可变个数形参来定义方法 public static void test(int a ,String…books);格式:形参:数据类型…形参名
该方法与同名的方法之间构成重载。
在调用可变个数的形参时,个数是0到无穷。
可变参数方法的使用与方法参数部分使用数组是一致的,即上述两种方法是一致的。
方法的参数部分有可变形参,需要放在形参声明的最后
在Java SE5中添加了enum关键字,使得我们在需要群组并使用枚举类型集的时候,可以很方便的处理。例如:
public enum Spiciness{
NOT,MILD,MEDIUM,HOT,FLAMING
}
这里创建了一个名为Spiciness的枚举类型,它具有5个具名值,由于枚举类型的实例是常量,因此按照命名惯例它们都是用大写字母表示。
6 访问权限控制
-
java提供了访问权限修饰词,供类库开发人员向客户端程序员指明哪些是可用的,哪些是不可用的,权限等级从大到小依次为:public、protected、包访问权限(默认)、private。
-
包内含有一组类,它们在单一的名字空间下被组织在了一起。java.util中有一个叫做ArrayList的类。使用ArrayList的一种方式是使用全名。另一种方式就是使用import语句。如果想导入util包下的其他类,可以使用
import java.util.*; -
java解释器的运行过程?
| 修饰符 | 类内部 | 同一个包 | 子类 | 任何地方 |
|---|---|---|---|---|
| private | YES | |||
| (缺省) | YES | YES | ||
| protected | YES | YES | YES | |
| public | YES | YES | YES | YES |
- 默认访问权限没有任何关键字,即指包访问权限。对于这个包之外的所有类,这个成员却是private。
- 使用关键字public,意味着public之后紧跟着的成员声明自己对每个人都是可用的。尤其是使用类库的客户端程序员。
- 如果类没有声明自己所在的包,java将这样的文件看作是隶属于该目录的默认包之中。
- 关键字private意思是:除了包含这个成员的类之外,其他任何类都无法访问这个成员。
- 关键字protected处理的是继承的概念。类的创建者希望有某个特定的成员,把对它的访问权限赋予派生类而不是所有类,这就需要protected来完成这一个工作。
7 复用类
-
达到复用这个目的的方法有两种:
- 只需在新的类中产生现有类的对象。由于新的类是现有类的对象所组成,这种方法称之为组合
- 按照现有类的类型来创建新类。无需改变现有类的形式,采用现有类的形式并在其中添加新代码。这种方式称之为继承。
-
组合,只需将对象引用至于新类中即可。
-
每一个非基本类型的对象都有一个toString()方法。
-
继承语法规则:
class Subclass extends Superclass{} -
关于继承语法,一般的规则是将所有的数据成员都指定为private,将所有的方法都指定为public,特殊情况下可以做出调整。
-
继承的作用:
- 继承的出现提高了代码的复用性。
- 让类与类之间产生了关系,提供了多态的前提。
- 不要仅为了获取其他类中某个功能而去继承。
-
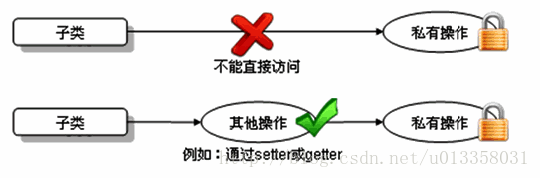
子类不能直接访问父类中私有的(private)的成员变量和方法
-
在子类中,可以使用父类中定义的方法和属性,也可以创建新的数据和方法。
-
Java只支持单继承,不允许多重继承:一个子类只能有一个父类;一个父类可以派生出多个子类
-
可以为每个类都创建一个main()方法。在每个类中都设置一个main()方法的技术可使每个类的单元测试简单可行
-
对于基类的初始化至关重要,构建过程是从基类“向外”扩散,基类在导出类构造可以访问它之前,就已经完成了初始化。
-
如果想调用带参数的基类构造器,这时候就必须使用super关键字,可以调用基类的构造器。
代理为第三种关系,这是继承和组合之间的中庸之道。
-
使用代理可以得到更多的控制力,可以选择只提供在成员对象中某个方法的子集。
-
如果想要某个类清理一些东西,就必须显式地编写一个特殊方法来做这个事,并要确保客户端程序员知晓他们必须要调用这一方法。首要任务就是,必须将这一清理动作置于finally子句之中,预防异常的出现。
-
如果java基类拥有某个已被多次重载的方法名称,在导出类中重新定义该方法名称并不会屏蔽其在基类中的任何一个版本。
-
组合与继承的区别:
- 组合技术通常用于想在新类中使用现有类的功能而非它的接口这种形式。即需要在新类中嵌入一个现有类的private类。
- 在继承的时候使用某个现有类,并开发一个它的特殊版本。通常“is-a”的关系用继承表达,而“has-a”的关系用组合表达。
-
实际项目中,经常想要将某些事物尽可能的隐藏起来,但仍然允许导出类的成员访问它们。关键字protected就是起的这个作用
向上转型:
-
新类是现有类的一种类型。向上转型还可以用来作为选择组合还是继承的判断,如果必须使用向上转型,则继承是必要的。
-
final通常指这是无法改变的。可能使用final的有三种情况:数据,方法,类。
-
对于编译期常量(既是static又是final的域)必须是基本数据类型,在对这个常量进行定义时必须对其进行赋值,其占据一段不能改变的存储空间。
-
java允许生成空白final,即被声明为final但未给定初始的域。必须在域的定义处或者每个构造器中用表达式对final进行赋值。(这里不可以有static表示)
-
final 参数:java允许在参数列表中以声明的方式将参数指明为final。意味着无法再方法中更改参数引用所指向的对象。即你可以读参数,但是不可以修改参数。
-
类中所有的private方法都隐式的指定是final的。无法取用private方法,也就无法覆盖它。
-
当将某个类整体定义为final,则表明禁止继承,不希望它有子类。在final类中可以给方法添加final修饰词,但是这没有意义。对于方法指明为final时要慎重。
static表示静态的,可以用来修饰属性,方法,代码块(初始化块),内部块。(除了构造器不行)
-
static 修饰属性(类变量)
- 由类创建的所有对象,都共用一个属性
- 当其中一个对象对此属性进行修改,会导致其他对象对此属性的调用VS 实例对象(非static修饰属性)
- 类变量随着类的加载而加载,而且独一份
- 静态的变量可以直接通过“类.类变量”的形式来调用。
-
修饰方法(类方法)
- 随着类的加载而加载,在内存中也是独一份
- 可以直接通过“类.类方法”的方式调用。
- 在静态方法内部,可以调用静态的属性或方法,而不能调用非静态的属性或方法。反之非静态的方法是可以调用静态的属性或方法,静态的生命周期更长,同时消亡被回收也要晚于非静态结构。
- static方法内部不能有this,也不能有super
- 重载的方法需要同时为static或非static
方法重写的要求:
- 重写方法必须和被重写方法具有相同的方法名称、参数列表和返回值类型。
- 重写方法不能使用比被重写方法更严格的访问权限。
- 重写和被重写的方法须同时为static的,或同时为非static的
- 子类方法抛出的异常不能大于父类被重写方法的异常
在继承结构中,想要调用基类构造器被重写的方法,属性等,可使用super关键字。
-
修饰方法:调用父类被重写的方法:
super.method(); -
修饰属性:子父类出现同名成员,可用super区分。
-
修饰构造器:调用父类中指定的构造器
-
子类所有构造器都会默认访问父类中空参数构造器
-
父类无空参构造器,子类构造器必须通过this或super语句指定调用本类或父类中相应的构造器,且必须放在构造器第一行。this(形参列表)和super(形参列表)只能出现一个。
-
设计类,尽量设计一个空参构造器。
-
8 多态
-
将一个方法调用同一个方法主体关联起来被称为绑定。在程序执行前进行绑定,叫做前期绑定(面向过程)。这里解决前述多态问题的方法是后期绑定。
-
后期绑定的含义:在运行时根据对象的类型进行绑定。后期绑定也可以叫做动态绑定或者运行时绑定。
-
若编译时类型和运行时类型不一致,就出现多态,调用方法的版本,是实际赋给该变量的对象决定的。
Person是父类,Man是子类 Person p = new Man();//体现子类对象的多态性父类的引用指向子类对象。 -
(成员变量不具备多态性)
-
如果某个方法是静态的,它的行为不具备多态性。因为静态方法是与类,而非与单个对象相关联。
-
构造器不同于其他种类的方法,不具有多态性。(他们实际上是static方法,不过是隐式声明)。
-
构造器的调用顺序:
- 调用基类构造器,这个步骤会不断地反复递归下去,首先是构造这种层次结构的根,然后是下一层导出类,知道最底层导出类。
- 按照声明顺序调用成员的初始化方法。
- 调用导出类构造器主体。
-
由于继承的缘故,如果有其他作为垃圾回收一部分的特殊清理工作,就必须在导出类中覆盖dispose()方法。当覆盖被继承类的dispose()方法,务必调用基类版本的dispose()方法,否则,清理动作就不会发生。
-
销毁顺序应该和初始化顺序相反
-
。如果这些成员对象存在于其他一个或多个对象共享的情况,问题就变得复杂,不能简单地假设你可以调用dispose()了。这种情况下也许就必须使用引用计数来跟踪仍旧访问着共享对象的对象数量了。
如果要调用构造器内部的一个动态绑定方法,就要用到那个方法的被覆盖后的定义。然而这个调用的效果可能相当难以预料,因为被覆盖的方法在对象被完全构造之前就会被调用,可能造成一些难以发现的隐藏错误。
-
编写构造器准则:用尽可能简单的方法使对象进入正常状态;如果可以的话,避免调用其他方法。构造器中唯一安全调用的那些方法是基类中的final方法。
-
Java SE5中添加了协变返回类型,它表示在导出类中的被覆盖方法可以返回基类方法的返回类型的某种导出类型。
-
通用准则:用继承表达行为间的差异,用字段表达状态上的变化。通过继承得到了两个不同的类,用于表达act()发发的差异;而Stage通过运用组合使自己状态发生变化,这种状态的改变也就产生了行为的改变。
纯继承就是纯粹的将基类中已经建立的方法才可以在导出类中被覆盖。这被称为纯粹的“is-a”关系。
还有一种是他有着和基类相同的接口,但是它还具有额外方法实现其他特性,这个可以称作为“is-like-a”关系。
- 向上转型会丢失具体类型信息,可以通过向下转型——基类到导出类——获取类型信息。向上转型是安全的,因为基类不会具有大于导出类的接口。
- java中提供了instacneof操作符,用来确保向下转型的正确性。
- x instanceof A:检验x是否为类A的对象,返回值为boolean型。即对象a instanceof 类A 判断对象a是否是类A的一个实例,是的话返回true。
- 要求x所属的类与类A必须是子类和父类的关系,否则编译错误。
- 如果x属于类A的子类B,x instanceof A值也为true。
9 接口
-
有时将一个父类设计得非常抽象,以至于它没有具体的实例,这样的类叫做抽象类,或者抽象基类。
- 用abstract关键字来修饰一个类时,这个类叫做抽象类;
- 用abstract来修饰一个方法时,该方法叫做抽象方法。( 抽象方法:只有方法的声明,没有方法的实现。以分号结束:
abstract int abstractMethod( int a );) - 含有抽象方法的类必须被声明为抽象类。(否则,编译器会报错。)
- 抽象类不能被实例化。抽象类是用来被继承的,抽象类的子类必须重写父类的抽象方法,并提供方法体。若没有重写全部的抽象方法,仍为抽象类。
- 不能用abstract修饰属性、私有方法、构造器、静态方法、final的方法。即private,static,final。
- (即使不能被实例化,但是还是有构造器)抽象方法所在的类一定是抽象类.抽象类中可以没有抽象方法。也可以同时有抽象方法,也可以有实体方法。
-
interface这个关键字产生了一个完全抽象的类,他根本就没有提供任何具体实现,它允许创建者确定方法名,参数列表和返回类型,但是没有任何方法体。接口只提供了形式,并且接口提供了多重继承,总的来说就是
- 有时必须从几个类中派生出一个子类,继承它们所有的属性和方法。但是,Java不支持多重继承。有了接口,就可以得到多重继承的效果。
- 接口(interface)是抽象方法和常量值的定义的集合
- 从本质上讲,接口是一种特殊的抽象类,这种抽象类中只包含常量和方法的定义,而没有变量和方法的实现。
- 一个类可以实现多个接口,接口也可以继承其它接口:
class A impelments InterfaceB,InterfaceC{}
-
接口的特点:
- 用关键字interfacet替代class来定义。可添加修饰符
- 接口中的所有成员变量都默认是由public static final修饰的。
- 接口中的所有方法都默认是由public abstract修饰的。
- 没有构造器并且采用多继承机制。
- 实现接口的类中必须提供接口中所有方法的具体实现内容,方可实例化,否则仍为抽象类。
- 与继承类似,接口与实现类之间存在多态性
创建一个能够根据所传递的参数对象的不同而具有不同行为的方法,被称为策略设计模式。
- 如果知道某事物应该成为一个基类,那么第一选择应该是使它成为一个接口。
- 通过继承,可以很容易的在接口中添加新的方法声明,还可以通过继承在新接口中组合数个接口。
- 组合的不同接口中使用相同的方法名通常会造成代码可读性的混乱,需要尽量避免。
10 内部类
-
可以将一个类的定义放在另一个类的定义内部,这就是内部类。内部类与组合是两种完全不同的概念。内部类看起来就像是一种代码隐藏机制:将类置于其他类的内部。
-
创建内部类:
创建内部类就是把类的定义治愈外围类里面。 -
链接到外部类:
生成一个内部类对象时,此对象与制造它的外围对象之间就有了一种联系,它能访问其外围对象的所有成员,而不需要任何特殊条件。此外,内部类还拥有其外围类的所有元素的访问权。 -
使用.this 与.new
如果需要生成对外部类对象的引用,可以使用外部类名字后面紧跟圆点和this。//: innerclasses/DotThis.java // Qualifying access to the outer-class object. public class DotThis { void f() { System.out.println("DotThis.f()"); } public class Inner { public DotThis outer() { return DotThis.this; // A plain "this" would be Inner's "this" } } public Inner inner() { return new Inner(); } public static void main(String[] args) { DotThis dt = new DotThis(); DotThis.Inner dti = dt.inner(); dti.outer().f(); } } /* Output: DotThis.f() *///:~如果需要告知某些其他对象,去创建其某个内部类的对象。要实现此目的,必须在new表达式中提供对其他外部类对象的引用,这需要使用.new语法。
//: innerclasses/DotNew.java // Creating an inner class directly using the .new syntax. public class DotNew { public class Inner {} public static void main(String[] args) { DotNew dn = new DotNew(); DotNew.Inner dni = dn.new Inner(); } } ///:~在拥有外部类对象之前是不可能创建内部类对象的。但是如果创建的是嵌套类(静态内部类),那么它就不需要对外部类对象的引用。
-
内部类与向上转型:
内部类向上转型为其基类,尤其是转型为一个接口时,某个接口的实现能够完全不可见且不可用,方面隐藏实现细节。
public interface Destination{ String readLabel(); } public interface Contents{ int value(); }//: innerclasses/TestParcel.java class Parcel4 { private class PContents implements Contents { private int i = 11; public int value() { return i; } } protected class PDestination implements Destination { private String label; private PDestination(String whereTo) { label = whereTo; } public String readLabel() { return label; } } public Destination destination(String s) { return new PDestination(s); } public Contents contents() { return new PContents(); } } public class TestParcel { public static void main(String[] args) { Parcel4 p = new Parcel4(); Contents c = p.contents(); Destination d = p.destination("Tasmania"); // Illegal -- can't access private class: //! Parcel4.PContents pc = p.new PContents(); } } ///:~ -
在方法和作用域内定义的内部类
**例如在一个方法里或者作用域内定义内部类。**这被称之为局部内部类。这种做法的缘由是:实现了某类型的接口,可以创建并返回对其的引用或者想要解决一个复杂问题,创建一个类来辅助但是又不希望这个类是公共可用的时候。内部类被嵌入在if语句的作用域内,这个类与其他类都一起被编译了,但是在作用域之外,这个类是不可用的,除此之外与其他类一样。
14 类型信息
-
在java中我们在运行时识别对象和类的信息主要有两种方式:
- 传统的“RTTI”,假定我们在编译时已知所有类型
- “反射”机制,允许在运行时发现和使用类的信息。
-
RTTI:在运行时识别一个对象的类型
-
Class对象是用来创建类的所有的“常规”对象的。类是程序的一部分,每个类都有一个Class对象,每当编写并编译了一个新类,就会产生一个Class对象。为了生成这个类的对象,运行这个程序的Java虚拟机使用**“类加载器**”这个子系统。
-
类加载器首先检查这个类的Class对象是否已经加载。如果尚未加载,默认的类加载器就会根据类名查找.class文件。一旦某各类的Class对象被加载到内存,它就被用来创建这个类的所有对象。
-
Class.forName("Gum")- 这个方法是Class类的一个static成员,Class对象就和其他对象一样,可以获取并操作它的引用。
forName()是取得Class对象引用的一种方法。字符串参数必须使用含包名的全限定名。 forName()调用作用:如果类。。。还没有被加载就加载它。- 如为找到需要加载的类,抛出异常
- 这个方法是Class类的一个static成员,Class对象就和其他对象一样,可以获取并操作它的引用。
-
getClass():如果已经拥有了一个类型的对象,可以通过调用getClass()方法来获取Class引用,这个方法属于Obje的一部分 -
getName():产生全限定的类名 -
getSimpleName():产生不包含包名的类名 -
getCanonicalName():全限定的类名 -
isInterface():表示这个Class对象是否表示某个接口 -
getInterfaces():返回Class对象,表示在感兴趣的Class对象中所包含的接口 -
getSuperclass():查询直接基类(赋予Object类型,但可知确切类型) -
newInstance():实现虚拟构造器。使用这种方法的类必须带有默认的构造器
Java还提供了另一种方法来生成对Class对象的引用,及使用类字面常量。
示例:FancyToy.class;
这样做更简单,安全,在编译时就会受到检查,并且根除对forName()的方法调用,更高效。
-
类字面常量不仅可以应用于普通的类,还可以应用于接口,数组以及基本数据类型。对于基本数据类型的包装器类,还有一个标准字段TYPE。

-
当使用**
.class来创建对Class对象的引用时,不会自动初始化该Class对象**,为了使用类实际做的准备工作包含三个步骤:加载;链接;初始化。- (仅使用
.class语法来获得类的引用不会引发初始化,但是Class.forName()立即就进行初始化) - 如果一个static域不是final,在对它访问前,总是要求在它被读取前,要先进行链接和初始化。如果一个static final值是编译期常量,那么这个值不需要对类进行初始化就可以被读取。(仅由static和final修饰不能确保就是编译期常量)
- (仅使用
泛型类引用只能赋值为指向其声明的类型,普通的类引用可以重新赋值为指向任何其他的Class对象。**如果希望稍微放松这种限制,则可使用通配符?,**表示任何事物。
-
如果想要将创建的Class引用限定为某种类型或该类型的任何子类型,可以将通配符和extends相结合,创建一个范围。
Class<? extends T>..... -
泛型语法应用在Class对象上,则
newInstance()的使用将受到限制,不再返回该对象的确切类型- 如果是超类,编译器会允许你声明超类引用是“某个类,它是XXX的超类”。不会接受
Class<XX>这样的声明。getSuperClass()返回的是基类(非接口)。由于泛型语法的含糊性,这时候的newInstance()的返回值不是精确类型,而只是Object。
- 如果是超类,编译器会允许你声明超类引用是“某个类,它是XXX的超类”。不会接受
-
Java SE5 添加了用于Class引用转型语法,即
cast()方法:Building b = new House(); Class<House> houseType = House.class; House h = houseType.cast(b);上述代码与
h = (House)b;实现同样的功能,主要用于无法使用普通转型的情况。
传统的类型转换错误会抛出一个转换异常。RTTI在java中有一种形式,即关键字instanceof。返回一个布尔值,告诉我们对象是不是某个特定类型的实例。
-
instanceof使用限制:只可将其与命名类型进行比较,不能与Class对象做比较。 -
@SuppressWarnings注解不能直接置于静态初始化子句之上。 -
如果程序中编写了许多instanceof表达式,则证明你的设计存在瑕疵
-
Class.isInstance()方法提供了一种动态地测试对象的途径。
示例:B.Class.isInstance(a)表示a能否强转为B类型 -
isAssignableFrom()方法从类继承的角度去判断是否为某个类的父类,调用者和参数都是java.lang.Class类型。
示例:Object.class.isAssignableFrom(String.class)即Object是String的父类,返回true
如果在系统中已经存在了继承结构的常规的基础,然后在其上添加更多的类,那么就有可能会出现问题。可以使用工厂方法设计模式。将对象的创建工作交给类自己去完成。
- 查询类型信息时,以
instanceof的形式与直接比较Class对象有一个重要差别:instanceof与·isInstance()生成的结果完全一样,equals()方法与==也一样- 前者保持了类型的概念,考虑了继承的结构;后者没有考虑继承结构,比较实际对象
-
使用RTTI有一个限制,这个类型在编译时必须是已知的,如果你获取一个指向某个并不在你程序空间的对象的引用,编译时你的程序无法获知这个对象所属的类。则可以使用反射来解决
-
Class类与java.lang.reflect类库一起对反射的概念进行了支持,该类库包含了Filed、method、constructor类(每个类都实现了member接口)。这些类型的对象是由jvm在运行时创建的,用以表示未知类里对应的成员变量。
-
可以用Constructor创建新对象,用
get()和set()方法读取和修改与Field对象关联的字段,用invoke()方法调用与method对象关联的方法;另外,可以调用getField()、getMethods()和getConstructor()等便利的方法。对于反射机制来说,.class文件在编译是是不可获取的,所以是在运行时打开和检查.class文件。
-
(待补充的反射机制)
动态代理可以动态地创建代理并动态地处理对所代理方法的调用。在动态代理上所做的所有调用都会被重定向到单一的调用处理器上,它的工作是揭示调用的类型并确定相应的对策。
在空对象模式(Null Object Pattern)中,一个空对象取代 NULL 对象实例的检查。Null 对象不是检查空值,而是反应一个不做任何动作的关系。这样的 Null 对象也可以在数据不可用的时候提供默认的行为。
- 在空对象模式中,我们创建一个指定各种要执行的操作的抽象类和扩展该类的实体类,还创建一个未对该类做任何实现的空对象类,该空对象类将无缝地使用在需要检查空值的地方。
示例:

接口与类型信息(即反射可以突破访问限制)
15 泛型
-
泛型:即适用于许多许多的类型。泛型实现了参数化类型的概念,使代码可以应用于多种类型。
-
泛型详解:泛型详解参考文章
-
泛型的主要目的之一就是用来指定容器要持有什么类型的对象,而且由编译器来保证类型的正确性。即暂时不指定类型,而是使用这个类的时候再用实际类型替换此类型参数
格式:使用尖括号参数,放在类名后面(T为类型参数) -
多态与泛型不冲突
-
元组:将一组对象直接打包存储于其中的一个单一对象。这个容器对象允许读取其中元素,但是不允许向其中存放新的对象。
-
通过泛型可以实现简单的堆栈类,Randomlist等
泛型也可以应用于接口,例如生成器,这是一种专门负责创建对象的类。一个生成器只定义一个方法。(可以用于生成Fibonacci数列)
-
java泛型有一个局限:基本类型无法作为类型参数。
-
泛型方法使得该方法能够独立于类产生变化,有一个基本指导原则:无论何时,只要你能做到,就应该尽量使用泛型方法,即如果使用泛型方法可以取代整个类泛型化,就应该只使用泛型方法。
格式:public <T> void f(T x)- public与返回值中间的
<T>非常重要,可以理解为声明此方法为泛型方法 - 只有声明了
<T>的方法才是泛型方法,此时才可以在方法中使用泛型类型T - 此处的T可以随便写为任意标识,常见的如:T、E、K、V等形式参数
- public与返回值中间的
-
泛型类中声明一个泛型方法,使用泛型E,这种泛型可以为任意类型。可以类型与T相同。
-
在泛型类中声明了一个泛型方法,使用泛型T,这个T是个全新的类型,可以与泛型类中声明的T不是同一种类型。
-
显示类型说明:要显式地指明类型,必须在点操作符与方法名之间插入尖括号,然后把类型置于尖括号内。在定义该方法的类内,在点操作符之前使用this关键字;如果是使用static方法,必须在点操作符之前加上类名。
示例:f(New.<Person, List<pet>>map()); -
泛型可以与可变参数很好共存。
在泛型代码内部,无法获得任何有关泛型参数类型的信息
java泛型是使用擦除来实现的,意味着当你使用泛型时,任何具体的类型信息都被擦除了。
-
Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉。这个过程就称为类型擦除。
-
通俗地讲,泛型类和普通类在 java 虚拟机内是没有什么特别的地方。
-
在泛型类被类型擦除的时候,之前泛型类中的类型参数部分如果没有指定上限,如
<T>,则会被转译成普通的Object类型;如果指定了上限,如<T extends String>则类型参数就被替换成类型上限。 -
因为类型擦除,会抹掉很多继承相关特性,带来一些问题与限制:
-
泛型是先检查,再编译,以及检查编译的对象和引用传递问题。
-
泛型限制了参数类型,但是基于对类型擦除的了解,可以利用反射,绕过这个限制
-
泛型中参数化类型不考虑继承关系,因为类型检查是针对引用。
-
JVM采用了桥方法来解决泛型与多态的冲突。
- 编译器自己生成的桥方法的参数类型是object,子类中真正覆盖父类的方法是桥方法,桥方法内部实现,调用我们自己重写的那两个方法。
-
泛型类型变量不能是基本数据类型不存在诸如
ArrayList<double>等 -
重载方法将产生相同的类型签名,必须提供有明显区别的方法名。
-
运行时类型检查
-
运行时进行类型查询中
if( arrayList instanceof ArrayList<String>)是错误的,Java中限定了这种类型的查询方式:
if( arrayList instanceof ArrayList<?>)
-
-
异常中使用泛型的问题
-
不能抛出也不能捕获泛型类的对象。泛型类扩展Throwable都不合法。因为类型信息被擦除后,catch的异常变为原始类型Object。
-
不能在catch子句中使用泛型变量
public static <T extends Throwable> void doWork(Class<T> t){ try{ ... }catch(T e){ //编译错误 ... }catch(IndexOutOfBounds e){ } } -
在异常声明中可以使用类型变量,是合法的:
public static<T extends Throwable> void doWork(T t) throws T{ try{ ... }catch(Throwable realCause){ t.initCause(realCause); throw t; } } -
不能声明参数化类型的数组(任何想要创建泛型数组的地方都使用
ArrayList) -
不能实例化泛型类型
first = new T(); //ERROR -
要支持擦除的转换,需要强行制一个类或者类型变量不能同时成为两个接口的子类,而这两个子类是同一接品的不同参数化
class Calendar implements Comparable<Calendar>{ ... } class GregorianCalendar extends Calendar implements Comparable<GregorianCalendar>{...} //ERROR -
泛型类中的静态方法和静态变量不可以使用泛型类所声明的泛型类型参数
public class Test2<T> { public static T one; //编译错误 public static T show(T one){ //编译错误 return null; } }
-
-
一旦执行类型的向上转型,就将丢失掉向其中传递任何对象的能力,甚至是传递object也不行。
List<? extends Fruit> list = new ArrayList<Apple>();
从上述这个描述中,编译器不能了解这里面需要Fruit的哪个具体子类型,不会接受任何类型的Fruit,但是可以使用contain()等不涉及通配符的读取操作。
-
超类型通配符:方法是指定
<? super extends MyClass>或者使用类型参数<? extends T>。使得可以安全地传递一个类型对象到泛型类型中。static void writeTo(List<? super Apple> apples) { apples.add(new Apple()); apples.add(new Jonathan()); // apples.add(new Fruit()); // Error } -
无界通配符:
<?>声明想要用java的泛型来编写代码,泛型参数可以支持任何类型。表示“具有某种特定类型”的非原生。。。- 如果向一个使用
<?>的方法传递原生类型,那么对编译器来说,可能会推断出实际的类型参数,使得这个方法可以回转并调用另一个使用这个确切类型的方法。称为捕获转换。
- 如果向一个使用
16 数组
-
数组与其他种类容器之间的区别:效率,类型和保存基本类型的能力。
-
无论使用哪种类型的数组,数组标识符其实只是一个引用,指向在堆中创建的一个真实对象,这个对象用以保存指向其他对象的引用。
-
Java SE5 的
Arrays.deepToString()方法可以将多维数组转换为多个String。 -
数组不能与泛型很好的结合,但是可以参数化数组本身的类型
class ClassParameter<T> { public T[] f(T[] args) {return args;} }-
编译器不允许实例化泛型数组,但是允许创建这种数组的引用:
List<String> ls; List[] la = new List[10]; ls = (List<String>[]) la; ls[0] = new ArrayList<String>();
-
创建测试数据:
-
Arrays.fill():只能用同一个值填充各个位置。可以填充这个数组或部分区域。Arrays.fill(a8, 47); Arrays.fill(a8, 3, 5, 88); -
Arrays中核心实用功能:
System.arraycopy(Object src, int srcPos, Object dest, int destPos, int length):这是java标准库提供的一个static方法,用来复制数组,其中形参为:源数组;源数组开始复制的位置偏移量;目标数组;目标数组开始复制的偏移量;复制的元素个数;System.arraycopy不会执行自动包装和自动拆包,数组必须具有相同的确切类型
equals():数组的比较。数组相等的条件是元素个数相等切对应位置的元素也相等。(基本类型与包装类不同)- 数组元素的比较方式
- 实现
java.lang.Comparable接口 Collections类中包含一个reverseOrder()方法,可以产生一个Comparator,反转自然排序的顺序。Arrays.sort()
- 实现
Arrays.binarySearch():数组已经排序好了,可以执行该方法快速查找。
17 容器深入研究
Java SE5新添加了:
1.Queue接口(LinkedList已经为实现该接口做了修改)及其实现PriorityQueue和各种风格的BlockingQueue。
2.ConcurrentMap接口及其实现ConcurrentHashMap,用于多线程机制
3.CopyOnWriteArrayList和CopyOnWriteArraySet,用于多线程机制
4.EnumSet和EnumMap,为使用enum而设计的set和map的特殊实现
5.在Collections类中的多个便利方法
虚线框表示abstract类,它们只是部分实现了特定接口的工具。例如,如果要创建自己的Set,那并不用从Set接口开始并实现其中全部方法,只需从AbstractSet继承,然后执行一些创建新类必须的工作。
-
容器的填充方法:
Collections.nCopies(int n, T o):返回一个不可变的列表,其中包含指定对象的n个副本。Collections.fill():替换已经在list中的元素- 一种
Generator解决方案 - Map生成器
- 使用abstract类
-
Collection执行的所有操作。


HashSet:如果没有其他限制,应该默认选择,其对速度进行了优化。
SortSet中的元素可以保证处于排序状态Object first():返回容器中的第一个元素Object last():返回容器中的最末一个元素SortedSet subSet(fromElement, toElement):生成此set的子集,范围从fromElement到toElement。SortedSet headSet(toElement):声称此Set的子集,由小于toElement的元素组成SortedSet tailSet(fromElement):生成此Set的子集,由大于或等于fromElement的元素组成。
双向队列Deque:可以在任何一端添加或移除元素。
public class Deque<T> {
private LinkedList<T> deque = new LinkedList<T>();
public void addFirst(T e) { deque.addFirst(e); }
public void addLast(T e) { deque.addLast(e); }
public T getFirst() { return deque.getFirst(); }
public T getLast() { return deque.getLast(); }
public T removeFirst() { return deque.removeFirst(); }
public T removeLast() { return deque.removeLast(); }
public int size() { return deque.size(); }
public String toString() { return deque.toString(); }
// And other methods as necessary...
} ///:~
- Map:标准Java类库中包含了Map的几种基本实现,包括:HashMap、TreeMap、LinkedHashMap、WeakHashMap、ConcurrentHashMap、IdentityHashMap。它们都有同样的基本接口Map,但行为特征各不相同,表现在效率、键值对的保存及呈现次序、对象的保存周期、映射表如何让在多线程程序中工作和判定键等价的策略等方面。
- 关联数组中基本方法是:
put()和get(),get方法使用的可能是能想象到的效率最差的方式来定位值的:从数组的头部开始,使用equals方法依次比较键,但这里的关键是简单性而不是效率。上面例子同时还存在固定尺寸问题,但java.util中的各种Map都没有这些问题。

-
HashMap使用特殊值,称作散列码,来取代对键的缓慢搜索。HashMap上打星号表示如果没有其他的限制,应该成为默认选择,因为他对速度进行了优化。其他实现强调了其他的特性,因此都不如HashMap快。
-
对Map中使用键的要求与对Set中的元素要求一样。任何键都必须具有一个equals方法;如果键被用于散列Map,那它还必须具有恰当的hashCode方法;如果键被用于TreeMap,必须实现Comparable。
SortedMap:(TreeMap是现阶段其唯一实现),可以确保键处于排序状态。
-
Comparator comparator():返回当前Map使用的Comparator;或者返回null,表示以自然方式排序
-
T firstKey:返回Map中的第一个键
-
T lastKey:返回Map中的最末一个键
-
SortedMap subMap(fromKey,toKey):生成此Map的子集,范围由fromKey(包括)到toKey(不包含)的键确定
-
SortedMap headMap(toKey):生成此Map的子集,由键小于toKey的所有键值对组成
-
SortedMap tailMap(fromkey):生成此Map的子集,由键大于或等于fromKey的所有键值对组成
-
LinkedHashMap:
- LinkedHashMap散列化所有的元素,但在遍历键值对时,却又以元素的插入顺序返回键值对。此外,可以在构造器中设定LinkedHashMap,使之使用基于访问的最近最少使用(LRU)算法,于是没有被访问过的元素就会出现在队列的前面。
-
散列与散列码:正确的equals必须满足5个条件:
1.自反省,对任意x,x.equals(x)一定返回true
2.对称性,对任意x和y,如果x.equals(y)为true,则y.equals(x)也为true
3.传递性,对任意x,y,z,如果有x.equals(y)返回true,y.equals(z)返回true,则x.equals(z)一定返回true
4.一致性,对任意x和y,如果对象中用于等价比较的信息没有改变,那么无论调用x.equals(y)多少次,返回结果应该保持一致5.对任何不是null的x,
x.equals(null)一定返回false; -
默认的Object.equals只是比较对象的地址,所以一个Groundhog(3)并不一定等于另一个Groundhog(3)。要使用自己类作为HashMap键,必须同时重载hashCode和equals;
-
使用散列的数据结构:
HashSet、HashMap、LinkedHashSet或LinkedHashMap- 目的:想要使用一个对象来查找另一个对象。使用TreeMap或自己实现Map也可以达到这个目的。
- 散列的价值在于速度,散列使得查询得以快速进行。存储一组元素最快的数据结构是数组,用它来表示键的信息。数组并不保存键本身,而是通过键对象生成一个数字,将其作为数组的下标,这个数字就是散列码。不同的键可以产生相同的下标,可能会有冲突。冲突由外部链接处理:数组并不直接 保存值,而是保存值的list,然后对list中的值使用
equals()方法进行线性的查询。 - 无论何时,同一个对象调用
hashCode()都应该生成同样的值。不应该使hashCode()依赖于具有唯一性的对象信息,尤其使使用this值。
-
hashCode()指导准则:-
给int变量result赋予某个非零值常量,例如17;
-
为对象内每个有意义的域f计算出一个int散列码c
-

-
合并计算得到的散列码:
result = 37 * result + c; -
返回result
-
检查hashCode()最后生成的结果,确保相同的对象有相同的散列码。
Hashtable、Vector和Stack的特征是,它们是过去遗留下来的类,目的只是为了支持老的程序(不建议在新程序中使用)
-
一种查看容器实现之间差异的方式是使用性能测试:page(499)
-
关于list容器的建议:将ArrayList作为默认首选,只有你需要使用额外的功能,或者当程序的性能因为经常从表中间进行插入和删除而变差的时候,采取选择LinkedList。如果使用的是固定数量的元素,既可以选择使用List,也可以使用真正的数组。
-
Set选择:HashSet的性能基本上总是比TreeSet号,特别是在添加和查询元素是。TreeSet可以维持元素的排序状态,只有需要一个排好序的Set时,才应该使用TreeSet。TreeSet迭代通常比HashSet更快。
-
Map选择:Hashtable性能与HashMap大体相当。TreeMap通常比HashMap要慢。TreeMap是一种创建有序列表的方式。LinkedHashMap在插入时比Hashmap慢一点,它维护散列数据结构的同时还要维护链表(保持插入顺序)。其迭代速度更快。
-
HashMap性能因子:
- 容量:表中桶位数
- 初始容量:表在创建时所拥有的桶位数。HashMap和HashSet具有允许你指定初始容量的构造器
- 尺寸:表中当前存储的项数。
- 负载因子:尺寸/容量。HashMap和HashSet都具有允许你指定负载因子的构造器,表示当负载情况达到负载因子的水平时,容器将自动增加其容量。HashMap使用的默认负载因子是0.75.
Java.util.Collections类内部静态方法中有:addAll()、reverseOrder()、binarySearch()等。


**min()和max()**只作用于Collection对象,而不能作用于List。
-
创建一个只读的Collection或Map。Collections类中有一个方法,参数为原本的容器,返回值是容器的只读版本。
unmodifiableList() -
Collections类中有办法能够自动同步整个容器,语法与
不可修改的方法相似。 -
Java容器类类库采用了快速报错机制。它会探查容器上的任何除了你进程所进行的操作以外的所有操作。发现其他进程修改了容器,就立即抛出ConcurrentModificationException异常。
-
ConcurrentHashMap、CopyOnWreteArrayList和CopyOnWriteArraySet都使用了可以避免
ConcurrentModificationException的技术。
java.lang.ref类库包含了一组类,这些类为垃圾回收提供了更大的灵活性。当存在可能会耗尽内存的大对象时,这些类显得特别有用。有三个继承自抽象类Reference的类:SoftReference、WeakReference和PhantomReference
-
WeakHashMap用来保存WeakReference。它使得规范映射更易于使用,在这种映射中,每个值只保存一份实例以节省存储空间。当程序需要那个值的时候,便在映射中查询现有的对象,然后使用它。映射可将值做为其初始化的一部分,不过通常在需要的时候才生成值。
这是一种节约存储空间的技术,因为WeakHashMap允许垃圾回收器自动清理键和值,所以十分便。对于WeakHashMap添加键和值的操作,则没有什么特殊要求,映射会自动使用WeakReference包装他们。允许清理元素的触发条件是,不再需要此键了。
-
Vector和Enumeration
- 在Java 1.0/1.1 中,Vector是唯一可以自我扩展的序列。基本可以看做ArrayList,但是具有又长又难的方法名。在订正过Java容器类类库中,Vector被改造过,可将其归类为Collection和List。
- Java 1.0/1.1版的迭代器发明了一个新名字——枚举,Enumeration接口比Iterator小,包含两个方法:一个为
boolean hasMoreElements(),如果此枚举包含更多的元素,该方法就返回true;另一个为Object nextElement(),该方法返回此枚举中的下一个元素,否则抛出异常。 - 可以通过使用
Collections.enumeration()方法从Collection生成一个Enumeration。
-
如果需要栈的行为,应该使用LinkedList,或者从LinkedList类中创建的stack类。
-
高效率存储大量“开/关”信息,BitSet是最好的选择。不过它的效率仅是对空间而言;如果需要搞笑的访问时间,BitSet比本地数组稍慢一点。此外,BitSet的最小容量是long:64位。如果存储的内容比较小,例如8位,那么BitSet就浪费了一些空间。因此如果空间对你很重要,最好撰写自己的类,或者直接使用数组。
- BitSet与普通容器一样,会随着元素加入而扩充。
18 Java I/O系统


-
File类:既能代表一个特定文件的名称,又能代表一个目录下的一组文件的名称。
- 查看一个目录列表,可用两种方法:一是不带参数的**list()**方法,获得此File对象包含的全部列表;如果想要获得一个受限列表,就要用到“目录过滤器”。
-
流,表示任何有能力产出数据的数据源对象或者是有能力接收数据的数据端对象。“流”屏蔽了实际的I/O设备中处理数据的细节。
- Java类库中的I/O类分成输入和输出两个部分,通过继承,任何子Inputstream或Reader派生而来的类都含有read()的基本方法,用于读取单个字节或字节数组;任何自OutputStream或Write派生而来的类都含有write()基本方法,用于写单个字节或字节数组。
- InputStream和Reader与数据源相关联,OutputStream和writer与目标媒介相关联
-
InputStream的作用是用来表示那些从不同数据源产生输入的类,这些数据源包括:字节数组;String对象;文件;“管道”,工作方式与实际管道相似,即一端输入,一端输出;一个由其他种类的流组成的序列;其他数据源;
-
OutputStream类型类别的类决定了输出所要去往的目标:字节数组(不是String),文件或管道。

- FilterInputStream 属于一种InputStream,为装饰器类提供基类,其中“装饰器”类可以把属性或有用的接口与输入流连接在一起。FilterOutputStream为装饰器类提供一个基类,装饰器类把属性活着有用的接口与输出流连接在一起。



设计Reader和Writer继承层次结构只要是为了国际化。老的IO流继承层次结构仅支持8位字节流,并且不能很好地处理16位的Unicode字符。所以Reader和Writer继承层次结构就是为了在所有IO操作中都支持Unicode。


有一些类未做改变,例如:DataOutputStream,File,RandomAccessFile,SequenceInputStream。

I/O流典型使用用法
-
缓冲输入文件:如果想要打开一个文件用于字符输入,可以使用以String或File对象作为文件名的FileInputReader。如果希望提高速度对其进行缓冲,可将产生的引用传给一个BufferedReader构造器。BufferedReader提供
readLine()方法。当readLine()返回null时,达到文件末尾。调用close()关闭文件。 -
从内存输入:从
BuffereredInputFile.read()读入的String结果被用来创建一个StringReader。调用read()每次读取一个字符,把它发送到控制台。public class MemoryInput { public static void main(String[] args) throws IOException { StringReader in = new StringReader(BufferedInputFile.read("MemoryInput.java")); int c; while ((c = in.read()) != -1) { System.out.print((char) c); } } }read()是以int形式返回下一个字节,因此类型转换为char才能正确打印。 -
格式化的内存输入:读取格式化的数据,可以使用DataInputStream,其面向字节,因此必须使用InputStream类而不是Reader类。
DataInputStream in = new DataInputStream(new ByteArrayInputStream(BufferedInputFile.read("E:\\JAVA\\IdeaProjects\\untitled\\src\\io\\FormattedMemoryInput.java").getBytes())); while (true) { System.out.print((char) in.readByte());必须为ByteArrayInputStream提供字节数组,包含了一个可实现该工作的getBytes()方法。
如果从DataInputStream 用readByte()一次一个字节地读取字符:
DataInputStream in = new DataInputStream(new BufferedInputStream(new FileInputStream("TestEOF.java"))); // 使用available()方法查询还有多少个可供存取的字符 while (in.available() != 0) { System.out.print((char) in.readByte());available()的工作方式会随着所读取的媒介类型的不同而有所不同,要谨慎使用。
-
基本文件输出:FileWrite对象可以向文件写入数据。首先,创建一个与指定文件连接到FileWrite。通常会用BufferedWriter将其包装起来用以缓冲输出。
BufferedReader in = new BufferedReader(new StringReader( BufferedInputFile.read("BasicFileOutput.java"))); PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter(file))); int lineCount = 1; String s; while ((s = in.readLine()) != null) { out.println(lineCount++ + ": " + s); } out.close(); System.out.println(BufferedInputFile.read(file));前例中为了提供格式化机制,它被装饰成了PrintWriter。Java SE5在PrintWriter中添加了一个辅助构造器,使得你不必在每次希望创建文本文件并向其中写入时,都趋执行所有的装饰工作。
-
存储和恢复数据:PrintWriter可以对数据进行格式化,单数为了输出可供另一个“流”恢复的数据,需要用DataOutputStream写入数据,并用DataInputStream恢复数据。
DataOutputStream out = new DataOutputStream( new BufferedOutputStream( new FileOutputStream("Data.txt"))); out.writeDouble(3.14159); out.writeUTF("That was pi"); out.writeDouble(1.41413); out.writeUTF("Square root of 2"); out.close(); DataInputStream in = new DataInputStream( new BufferedInputStream( new FileInputStream("Data.txt"))); System.out.println(in.readDouble()); System.out.println(in.readUTF()); System.out.println(in.readDouble()); System.out.println(in.readUTF());如果使用DataOutputStream写入数据,Java保证可以使用DataInputStream准确地读取数据——无论读和写数据的平台多么不同,只要两个平台都有Java。
-
读写随机访问文件:使用RandomAccessFile时,类似组合使用了DataInputStream和DataInputStream。可以利用**seek()**在文件中到处移动,修改文件中的某个值。
在使用RandomAccessFile时,必须知道文件排版,这样才能正确地操作它。RandomAccessFile拥有读取基本数据和UTF-8字符串的各种具体方法。
可以自行选择第二个构造器参数:可以指定以“只读”(r)方式或“读写”(rw)方式打开一个RandomAccessFile文件。
-
TextFile类包含的static方法可以像简单字符串那样读写文本文件,并且可以创建一个TextFile对象,用一个ArrayList来保存文件的若干行。
程序所有的输入都可以来自标准输入,所有的输出也都可以发送到标准输出,以及所有的错误信息都可以发送到标准错误。Java提供了System.in、System.out、System.err
-
System.in是未加工的InputStream。通常使用readLine()一次一行读取输入,为此将System.in包装成BufferedReader来使用。这就要求必须用InputStreamReader把System.in转换成Reader。
BufferedReader stdin = new BufferedReader(new InputStreamReader(System.in)); String s; while ((s = stdin.readLine()) != null && s.length() != 0) { System.out.println(s);System.out是一个PrintStream,而PrintStream是一个OutputStream。PrintWriter可以接受OutputStream做为参数的构造器。
PrintWriter out = new PrintWriter(System.out, true); out.println("Hello, world");第二个参数true,以便开启自动清空功能;否则看不到输出。
-
Java的System类提供了静态方法调用,以允许对标准输入输出和错误IO流进行重定向:
setIn(InputStream)
setOut(PrintStream)
setErr(PrintStream)
JDK 1.4的java.nio.*包中引入了新的IO类库,其目的在于提高速度。实际上,旧的IO包已经使用nio重新实现过,以便充分利用这种速度提高。速度提高源自于所使用的结构更接近于操作系统执行IO的方式:通道和缓冲器。
-
唯一直接与通道交互的缓冲器是ByteBuffer,可以存储未加工字节的缓冲器。旧IO类库有三个类被修改了,用以产生FileChannel。这三个被修改类是FileInputStream、FileOutputStream以及用于既读又写的RandomAccessFile。这些都是字节操作流,与底层nio性质一致。Reader和Writer这些字符模式类不能用于产生通道;但是java.nio.channels.Channels类提供了使用方法,用于在通道中产生Reader和Writer。
public class GetChannel { private static final int BSIZE = 1024; public static void main(String[] args) throws Exception { FileChannel fc = new FileOutputStream("data.txt").getChannel(); fc.write(ByteBuffer.wrap("Some text ".getBytes())); fc.close(); fc = new RandomAccessFile("data.txt", "rw").getChannel(); fc.position(fc.size()); fc.write(ByteBuffer.wrap("Some more".getBytes())); fc.close(); fc = new FileInputStream("data.txt").getChannel(); ByteBuffer buff = ByteBuffer.allocate(BSIZE); fc.read(buff); buff.flip(); while (buff.hasRemaining()) { System.out.print((char) buff.get()); } } } /* Some text Some more */getChannel()将会产生一个FileChannel。通道是一种相当基础的:可以向它传送用于读写的ByteBuffer,并且可以锁定文件的某些区域用于独占式访问。使用
warp()方法将已存在的字节数组包装到ByteBuffer中。 对于只读访问,必须显式地使用静态的allocate()方法来分配ByteBuffer。-
一旦调用
read()来告知FileChannel向ByteBuffer存储字节,就必须调用缓冲器上的flip(),让它做好让别人读取字节的准备。如果打算使用缓冲器执行进一步read()操作,也必须得使用clear()来为每个read()做好准备。在下面简单文件复制程序可以看到:FileChannel in = new FileInputStream(args[0]).getChannel(), out = new FileOutputStream(args[1]).getChannel(); ByteBuffer buffer = ByteBuffer.allocate(BSIZE); while(in.read(buffer) != -1) { buffer.flip(); out.write(buffer); buffer.clear(); } -
特殊方法
transferTo()和transferFrom()则允许将一个通道和另一个通道直接相连:FileChannel in = new FileInputStream(args[0]).getChannel(), out = new FileOutputStream(args[1]).getChannel(); in.transferTo(0, in.size(), out); // Or: // out.transferFrom(in, 0, in.size());
-
-
转换数据:前述每次只读取一个字节的数据,然后将每个byte类型强制转换成char类型。而java.nio.CharBuffer有一个toString方法:返回一个包含缓冲器中所有字符的字符串。??
-
获取基本类型:向缓冲器插入基本类型数据最简单的方法是:利用asCharBuffer()、**asShortBuffer()等获得该缓冲器上的视图,然后使用视图的put()方法。适用于所有基本数据类型,除了使用ShortBuffer的put()**方法,需要类型转换。
-
视图缓冲器:可以让我们通过某个特定的基本数据类型的视窗查看其底层的ByteBuffer。
ByteBuffer bb = ByteBuffer.allocate(BSIZE); IntBuffer ib = bb.asIntBuffer(); ib.put(new int[]{ 11, 42, 47, 99, 143, 811, 1016 }); System.out.println(ib.get(3)); ib.put(3, 1811); ib.flip(); while(ib.hasRemaining()) { int i = ib.get(); System.out.println(i); } -
big endian高位优先将最重要的字节存放在地址最低的存储器单元。而little endian低位优先相反。ByteBuffer是以高位优先的形式存储数据的。可以使用参数ByteOrder.Big_ENDIAN和ByteOrder.LITTER_ENDIAN的
order()方法来改变排序方式。

-
Buffer有数据和可以高效地访问及操作这些数据的四个索引组成,mark(标记)、position(位置)、limit(界限)和capacity(容量)。

public class UsingBuffers { private static void symmetricScramble(CharBuffer buffer){ while(buffer.hasRemaining()) { buffer.mark(); char c1 = buffer.get(); char c2 = buffer.get(); buffer.reset(); buffer.put(c2).put(c1); } } public static void main(String[] args) { char[] data = "UsingBuffers".toCharArray(); ByteBuffer bb = ByteBuffer.allocate(data.length * 2); CharBuffer cb = bb.asCharBuffer(); cb.put(data); print(cb.rewind()); symmetricScramble(cb); print(cb.rewind()); symmetricScramble(cb); print(cb.rewind()); } } /* UsingBuffers sUniBgfuefsr UsingBuffers */ -
内存映射文件:内存映射文件允许我们创建和修改那些因为太大而不能放入内存的文件。
MappedByteBuffer out = new RandomAccessFile("test.dat", "rw").getChannel() .map(FileChannel.MapMode.READ_WRITE, 0, length); for (int i = 0; i < length; i++) { out.put((byte) 'x'); } print("Finished writing"); for (int i = length / 2; i < length / 2 + 6; i++) { printnb((char) out.get(i)); }使用map()产生MappedByteBuffer,一个特殊类型的直接缓冲器,必须指定映射文件初始位置和映射区域长度。 MappedByteBuffer由ByteBuffer继承而来,因此它具有ByteBuffer的所有方法。
-
文件加锁:JDK 1.4引入了文件加锁机制,允许同步访问某个做为共享资源的文件。文件锁对其他的操作系统进程是可见的,因为Java的文件加锁直接映射到本地操作系统的加锁工具。
public class FileLocking { public static void main(String[] args) throws Exception { FileOutputStream fos= new FileOutputStream("file.txt"); FileLock fl = fos.getChannel().tryLock(); if(fl != null) { System.out.println("Locked File"); TimeUnit.MILLISECONDS.sleep(100); fl.release(); System.out.println("Released Lock"); } fos.close(); } } /* Locked File Released Lock */通过对FileChannel调用
tryLock()或lock(),就可以获得整个文件的FileLock。SocketChannel、DatagramChannel和ServerSocketChannel不需要加锁,因为它们是从单进程实体继承而来,通常不在两个进程之间共享socket。tryLock()是非阻塞式的,它设法获取锁,如果不能得到(当其他一些进程已经持有相同的锁,并且不共享时),它将直接从方法调用返回。lock()是阻塞式的,它要阻塞进程直至锁可以获得,或调用lock()的线程中断,或调用lock()的通道关闭。使用FileLock.release()可以释放锁。- 可以对文件的部分上锁:
tryLock(long position, long size, boolean shared)或者lock(long position, long size, boolean shared)。锁的类型可以通过FileLock.isShared()进行查询。
- 可以对文件的部分上锁:
-
Java IO类库中的类支持读写压缩格式的数据流。
这些类属于InputStream和OutputStream继承层次结构的一部分。因为压缩类库是按字节方式而不是字符方式处理的。

-
Zip格式也被应用于JAR(Java ARchive,Java档案文件)文件格式中。将一组文件压缩到单个压缩文件中。同Java中任何其他东西一样,JAR也是跨平台的。由于采用压缩技术,可以使传输时间更短,只需向服务器发送一次请求即可。
Sun的JDK自带jar程序,可根据选择自动压缩文件:
jar [options] destination [manifest] inputfile(s)

示例:
-
创建一个名为myJarFile.jar的JAR文件,包含当前目录下所有类文件,以及自动产生的清单文件:
-
jar cf myJarFile.jar *.class -
下面的命令与前例类似,但添加了一个名为myManifestFile.mf的用户自建清单文件:
-
jar cmf myJarFile.jar myHanifestFile.nf *.class -
下面的命令会产生myJarFile.jar内所有文件的一个目录表:
-
jar tf myJarFile.jar -
下面的命令添加“v”(详尽)标志,可以提供有关myJarFle.jar中的文件的更详细的信息:
jar tvf myJarFile.jar -
Java的对象序列化将那些实现了Serializable接口的对象转换成一个字节序列,并能够在以后将这个字节序列完全恢复为原来的对象。
要序列化一个对象,首先要创建某些
OutputStream对象,然后将其封装在一个ObjectOutputStream对象内。这时,只需调用writeObject()即可将对象序列化,并将其发送给OutputStream(对象化序列是基于字节的,因要使用InputStream和OutputStream继承层次结构)。要反向进行该过程(即将-一个序列还原为一个对象),需要将个InputStream封装在ObjectmputStream内,然后调用readObject()。和往常一样,我们最后获得的是一个引用,它指向一个向上转型的Object,所以必须向下转型才能直接设置它们。
19 枚举类型
-
基本enum特性:
enum Shrubbery {GROUND, CRAWLING, HANGING} public class EnumClass { public static void main(String[] args) { for (Shrubbery s : Shrubbery.values()) { print(s + " ordinal: " + s.ordinal()); printnb(s.compareTo(Shrubbery.CRAWLING) + " "); printnb(s.equals(Shrubbery.CRAWLING) + " "); print(s == Shrubbery.CRAWLING); print(s.getDeclaringClass()); print(s.name()); print("----------------------"); } // Produce an enum value from a string name: for (String s : "HANGING CRAWLING GROUND".split(" ")) { Shrubbery shrub = Enum.valueOf(Shrubbery.class, s); print(shrub); } } } /* GROUND ordinal: 0 -1 false false class Shrubbery GROUND ---------------------- CRAWLING ordinal: 1 0 true true class Shrubbery CRAWLING ---------------------- HANGING ordinal: 2 1 false false class Shrubbery HANGING ---------------------- HANGING CRAWLING GROUND */- 使用static import能够将enum实例的标识符带入当前的命名空间,无需再用enum类型来修饰enum实例。
-
可以向enum中添加方法。enum甚至可以有main()方法。必须在enum实例序列的最后添加一个分号。Java要求必须先定义enum实例,如果在实例之前定义任何方法或属性,编译时会报错。有意将构造器声明为private,但对于他的可访问性并没有什么影响,因为即使不声明为private,我们只能在enum内部使用其构造器创建enum实例。一旦enum的定义结束,编译器就不允许在使用其构造器来创建任何实例了。
-
覆盖enum的方法:覆盖toString()方法,给我们提供了另一种方式来为枚举实例生成不同的字符串描述信息。覆盖enum的toString方法与覆盖一般类的方法没有区别。
public enum SpaceShip { SCOUT, CARGO, TRANSPORT, CRUISER, BATTLESHIP, MOTHERSHIP; @Override public String toString() { String id = name(); String lower = id.substring(1).toLowerCase(); return id.charAt(0) + lower; } public static void main(String[] args) { for (SpaceShip s : values()) { System.out.println(s); } } } /* Scout Cargo Transport Cruiser Battleship Mothership */ -
在switch中使用enum,是enum提供的一项非常便利的功能。
-
values()方法是由编译器插入到enum定义中的static方法。如果你将enum实例向上转型为Enum,那么values()方法就不可访问了。Class中有一个getEnumConstants方法,所以即便Enum接口中没有vlaues方法,仍然可以通过Class对象取得所有enum实例:
-
在一个接口的内部,创建实现该接口的枚举,再次将元素进行分组,可以达到将枚举元素分类组织的目的。对于enum而言,实现接口是其子类化的唯一方法。
public interface Food { enum Appetizer implements Food { SALAD, SOUP, SPRING_ROLLS; } enum MainCourse implements Food { LASAGNE, BURRITO, PAD_THAI, LENTILS, HUMMOUS, VINDALOO; } enum Dessert implements Food { TIRAMISU, GELATO, BLACK_FOREST_CAKE, FRUIT, CREME_CARAMEL; } enum Coffee implements Food { BLACK_COFFEE, DECAF_COFFEE, ESPRESSO, LATTE, CAPPUCCINO, TEA, HERB_TEA; } } public class TypeOfFood { public static void main(String[] args) { Food food = Appetizer.SALAD; food = MainCourse.LASAGNE; food = Dessert.GELATO; food = Coffee.CAPPUCCINO; } }- 如果需要和一堆类型打交道,接口不如enum好用。可以创建一个枚举的枚举,创建一个enum,然后用其实例包装好Food中的每一个enum类。
-
Java SE5引入了EnumSet,是为了通过enum创建一种替代品,以替代传统的基于int的“位标志”。这种标志可以用来表示某种开关信息,不过,使用这种标志,最终操作的只是一些bit。使用EnumSet的有点是,它在说明一个二进制位是否存在时,具有更好的表达能力,并且无需担心性能。
EnumSet中的元素必须来自一个enum。
Enum的基础是long,一个long值有64位,一个enum实例只需一位bit表示其是否存在,EnumSet可以应用于最多不超过64个元素的enum。超过了,可能会在必要的时候增加一个long。 -
使用EnumMap:EnumMap是一种特殊的Map,要求其中的键必须来自一个enum。由于enum本身的限制,所以EnumMap内部是数组实现。因此EnumMap速度很快,可以放心进行查找操作。其操作与Map差不多。
与常量相关的方法相比,EnumMap有一个优点,那EnumMap允许改变值对象,而常量相关方法在编译期就被固定了 -
enum允许为enum实例编写方法,。要实现常量相关方法,需要为enum定义一个或多个abstract方法,然后为每个enum实例实现该抽象方法。
public enum ConstantSpecificMethod { DATE_TIME { String getInfo() { return DateFormat.getDateInstance().format(new Date()); } }, CLASSPATH { String getInfo() { return System.getenv("CLASSPATH"); } }, VERSION { String getInfo() { return System.getProperty("java.version"); } }; abstract String getInfo(); public static void main(String[] args) { for (ConstantSpecificMethod csm : values()) { System.out.println(csm.getInfo()); } } }编译器不允许将enum实例当作class类型。
-
除了实现abstract方法以外,可以覆盖常量相关的方法。
public enum OverrideConstantSpecific { NUT, BOLT, WASHER { void f() { print("Overridden method"); } }; void f() { print("default behavior"); } public static void main(String[] args) { for(OverrideConstantSpecific ocs : values()) { printnb(ocs + ": "); ocs.f(); } } } /* Output: NUT: default behavior BOLT: default behavior WASHER: Overridden method *///:~ -
多路分发:java只支持单路分发。如果要执行的操作包含了不止一个类型未知的对象时,java的动态绑定机制只能处理其中一个的类型。如果要实现多路分发,一般要调用多个方法。一种方式是使用构造器来初始化每个enum实例,并以“一组”结果作为参数。另一种方法是使用常量相关方法。
-
使用EnumMap能够实现真正的两路分发。
-
可以使用二维数组,将竞争者映射到竞争结果。
enum RoShamBo6 implements Competitor<RoShamBo6> { PAPER, SCISSORS, ROCK; private static Outcome[][] table = { { DRAW, LOSE, WIN }, // PAPER { WIN, DRAW, LOSE }, // SCISSORS { LOSE, WIN, DRAW }, // ROCK }; public Outcome compete(RoShamBo6 other) { return table[this.ordinal()][other.ordinal()]; } public static void main(String[] args) { RoShamBo.play(RoShamBo6.class, 20); } }
-
20 注解(代码待确认)
-
注解(也称元数据)为在代码中添加信息提供了一种形式化的方法,注解的语法除了使用**@之外,基本与java固有的语法一致。Java SE5内置了三种,定义在java.lang**中的注解。
@Override:表示当前的方法定义将覆盖超类中的方法@Deprecated:如果使用了注解为它的元素,编译器会发出警告信息@SuppressWarnings:关闭不当的编译器警告信息。
-
注解的定义看起来很像接口的定义。事实上与任何 Java 文件一样,注解也会被编译为 class 文件。
import java.lang.annotation.*; @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface Test{}在注解中一般都会包含某些元素用以表示某些值。当分析出来注解时,程序和工具可以利用这些值。注解的元素看起来就像接口的方法,唯一的区别是你可以为他指定默认值。没有元素的注解被称为标记注解
注解的元素在使用时表现为名—值的形式。 -
Java目前只内置了三种标准注解以及四种元注解(专职负责注解其他注解的)
@Target注解:表示该注解可以用于什么地方。可能的ElementType参数包括:- CONSTRUCTOR:构造器的声明
- FIELD:域声明(包括enum实例)
- LOCAL_VARIABLE:局部变量声明
- METHOD:方法声明
- PACKAGE:包声明
- PARAMETER:参数声明
- TYPE::类,接口或枚举声明
@Retention注解:表示需要在什么级别保存该注解信息。该注解与RetentionPolicy枚举类联合使用。RetentionPolicy枚举常量定义了注解在代码中的保留策略:- SOURCE:仅保留在源码中,注解将被编译器丢弃
- CLASS:编译器把注解记录在类文件中,但会被JVM丢弃
- RUNTIME:编译器把注解记录在类文件中,在运行时JVM将保留注解,因此可以通过反射机制读取注解。
@Documented:将此注解包含在Javadoc中@Inherited:允许子类继承父类中的注解
编写注解处理器:
@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME)
public @interface UseCase {
public int id();
public String description() default "没有描述";
}
import java.util.*;
public class PasswordUtils{
@UseCase(id = 47, description = “Passwords must contain at least one numeric”)
public Boolean validatePassword(String password){
return (password.mathes(“\\w*\\d\\w*”));
}
@UseCase(id = 48)
public String encryptPassword(Srring password){
return new StringBuilder(password).reverse().toString();
}
@UseCase(id = 49, description = “New passwords can’t equal previously used ones”)
public Boolean checkForNewPassword(List<String> prevPasswords, String password){
return !prevPasswords.contains(password);
}
}
import java.lang.reflect.*;
import java.util.*;
public class UseCaseTracker{
public static void traceUseCases(List<Integer> useCases, Class<?> clazz){
//获取指定类中所有声明的方法
for(Method m : clazz.getDeclaredMethods()){
//获取方法上指定类型的注解
UseCase uc = m.getAnnotation(UseCase.class);
if(uc != null){
System.out.println(“Found Use Case:” + uc.id() + “ ” + uc.description());
useCases.remove(new Integer(uc.id()));
}
}
for(int i : useCases){
System.out.println(“Warning: Missing use case-” + i);
}
}
public static void main(String[] args){
List<Integer> useCases = new ArrayLis<Integer>();
Collections.addAll(useCases, 47, 48, 49, 50);
trackUseCases(useCases, PasswordUtils.class);
}
}
-
Annotation注解中的元素只能是下面的数据类型:
- 8中基本类型,如果可以自动装箱和拆箱,可以使用对应的对象包装类型
- String类型
- Class类型
- Enums类型
- Annotation类型
- 上面类型的数组
-
注解中的元素要么指定默认值,要么由使用的类赋值,如果即没有默认值,使用类也没有赋值的话,注解元素是不会像普通类成员变量一样给定默认值,即必须赋值或者显示指定默认值。
import java.lang.annotation.*; @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface DefaultValue{ public int id() default -1; public String description() default “”; } -
使用Annotation实现ORM:
import java.lang.annotation.*; @Target(ElementType.TYPE)//该注解只能应用在类上 @Retention(RetentionPolicy.RUNTIME) public @interface DBTable{//指定数据库名称 public String name() default “”; } @Target(ElementType.FIELD) @Retention(RetentionPolicy.RUNTIME) public @interface Constraints{//数据库约束 boolean primaryKey() default false; boolean allowNull() default true; boolean unique() default false; } @Target(ElementType.FIELD) @Retention(RetentionPolicy.RUNTIME) public @interface SQLString{//String类型数据 int value() default 0; String name() default “”; Constraints constraints() default @Constraints;//注解的属性元素也是注解 } @Target(ElementType.FIELD) @Retention(RetentionPolicy.RUNTIME) public @interface SQLInteger{//int类型数据 String name() default “”; Constraints constraints() default @Constraints; }使用Annotation注解的实体类:
@DBTable(name=”MEMBER”) public class Member{ @SQLString(30)//当只指定一个属性的值,并且该属性名为value时,不用写属性名称 String firstName; @SQLString(50) String lastName; @SQLInteger Integer age; @String(value=30, constraints=@Constraints(primaryKey = true)) String handle; static int memberCount; }- 当为注解多于1个以上的属性指定值时,即使有value属性也要写value的属性名称。
实现自定义的注解处理器:
import java.lang.annotation.*; import java.lang.reflect.*; import java.util.*; public class TableCreator{ public static void mian(String[] args)throws Exception{ Member m = new Member(); Class clazz = m.getClass(); String tableName = null; DBTable dbTable = class.getAnnotation(DBTable.class); if(db != null){ tableName = db.name(); } If(tableName == null){//如果没有指定Table名称,使用类名 tableName = clazz.getName().toUpperCase; } List<String> columnDefs = new ArrayList<String>(); //构造SQL创建列语句 for(Field f : clazz.getDeclaredFields()){//遍历类中声明的所有字段 String columnName = null; //获取当前字段上声明的所有注解 Annotationn[] anns = f.getDeclaredAnnotationns(); if(anns.length() < 1){//当前字段上没有声明注解 continue; } if(anns[0] instanceof SQLInteger){//注解数组第一个定义的是数据类型 SQLInteget sInt = (SQLInteger) anns[0]; if(sInt.name().length() < 1){//如果没有指定列名称,则使用字段名称 columnName = f.getName().toUpperCase(); }else{ columnName = sInt.name(); } columnDefs.add(columnName + “ INT” + getConstraints(sInt.constraints())); } if(anns[0] instanceof SQLString){ SQLString sString = (SQLString) anns[0]; if(sString.name().length() < 1){//如果没有指定列名称,则使用字段名称 columnName = f.getName().toUpperCase(); }else{ columnName = sInt.name(); } columnDefs.add(columnName + “ VARCHAR(” + sString.value() +”)” + getConstraints(sString.constraints())); } } StringBuilder createCommand = new StringBuilder(“CREATE TABLE” + tableName + “(”); for(String columnDef : columnDefs){ createCommand.append(“\n ” + columnDef + “,”); } //删除最后的”,” String tableCreate = createCommand.subString(0, createCommand.length() - 1) + “);”; System.out.println(“Table creation SQL for ” + className + “ is :\n” + tableCreate); } //获取约束 Private static String getConstraints(Constraints con){ String constraints = “”; if(!con.allowNnull()){ constraints += “ NOT NULL”; } if(con.primaryKey()){ constraints += “ PRIMARY KEY”; } if(con.unique()){ constraints += “ UNIQUE”; } return constraints; } }/* Table creation SQL for Member is: CREATE TABLE MEMBER( FIRSTNAME VARCHAR(30), LASTNAME VARCHAR(50), AGE INT, HANDLE VARCHAR(30) PRIMARY KEY); */ -
使用apt处理注解:Annotation processing tool, apt是sun提供的第一个版本的Annotation注解处理器,apt的使用和javac类似,是真的未编译的源码,而非已经编译的class字节码文件,使用apt的时候不能使用java的反射机制,因为源码尚未编译,需要使用mirrorAPI,mirror API可以使得apt看到未编译源代码中的方法,字段和类信息。
(1)注解
package annotations; import java.lang.annotation.*; @Target(ElementType.TYPE) @Retention(RetentionPolicy.SOURCE) public @interface ExtractInterface{ public String value(); }该注解用于从一个使用了该注解的类中抽取抽象公共的的方法,并为该类生成一个接口。
(2)使用注解的类package annotations; @ExtractInterface(“IMultiplier”) public class Multiplier{ public int multiply(int x, int y){ int total = 0; for(int i = 0; I < x; i++){ total = add(total, y); } return total; } private int add(int x, int y){ return x + y; } }(3)处理注解处理器
package annotations; import com.sun.mirror.apt.*; import com.sun.mirror.declaration.*; import java.io.*; import java.util.*; public class InterfaceExtractorProcessor implements AnnotationProcessor{ //注解处理器的工作环境 private final AnnotationProcessorEnvironment env; private List<MethodDeclaration> interfaceMethods = new ArrayList< MethodDeclaration>(); public InterfaceExtractorProcessor(AnnotationProcessEnvironment env){ this.env = env; } public void process(){ //查询注解处理器环境中的类型声明 for(TypeDeclaration typeDecl : env.getSpecifiedTypeDeclarations()){ //获取注解 ExtractInterface annot = typeDecl.getAnnotation(ExtractInterface.class); if(annot == null){ break; } //遍历所有添加注解的方法 for(MethodDeclaration m : typeDecl.getMethods()){ //方法签名中的访问控制符是public的,且不是静态方法 if(m.getModifiers().contains(Modifier.PUBLIC) && !(m.getModifiers().contains(Modifier.STATIC))){ interfaceMethods.add(m); } } if(interfaceMethods.size() > 0){ try{ PrintWriter writer = env.getFiler().createSourceFile(annot.value()); writer.println(“package ” + typeDecl.getPackage().getQualifiedName() + “;”); writer.println(“public interface ” + annot.value() + “{“); //写方法声明 for(MethodDeclaration m : interfaceMethods){ writer.print(“ public’); writer.print(m.getReturnType() + “ ”); writer.print(m.getSimpleName() + “ ”); int i = 0; //写方法参数列表 for(ParametherDeclaration parm : m.getParameters()){ writer.print(parm.getType() + “ ” + parm.getSimpleName()); if( ++i < m.getParameters().size()){ writer.print(“, ”); } } writer.println(“);”) } writer.println(“}”); writer.close(); }catch(Exception e){ Throw new RuntimeException(e); } } } } }使用sun的mirror API可以获取源码中的Field, type, method等信息。
(4)为apt工厂提供注解处理器
package annotations; import com.sun.mirror.apt.*; import com.sun.mirror.declaration.*; import java.util.*; public class InterfaceExtractorProcessorFactory implements AnnotationProcessorFactory{ //获取注解处理器 public AnnotationProcessor getProcessorFor(Set<AnnotationTypeDeclaration> atds, AnnotationProcessorEnvironment env){ return new InterfaceExtractorProcess(env); } //定义注解处理器所支持的注解类型 public Collection<String> supportedAnnotationTypes(){ return Collections.singleton(“ExtractInterface”); } //定义注解处理器支持的选项 public Collection<String> supportedOptions(){ return Collections.emptySet(); } }(5)运行apt
apt-factory annotations.InterfaceExtractorProcessorFactory Multiplier.java –s ../annotations输出结果:
package annotations; public interface IMultiplier{ public int multiply(intx, int y); }
21 并发
-
并发的多面性:并发解决问题大体可以分为速度和设计可管理性。
-
更快的执行:
如果你想让一个程序运行的更快,那么可以将其断开为多个片段,在单独的处理器上运行每个片段。并发是用于多处理器编程的基本工具。
并发通常是提高运行在单处理器上的程序的性能。在单处理器上运行的并发编程开销确实比改程序的所有部分都顺序执行的开销大,因为并发增加了上下文的切换的代价。表面上看,将程序的所有部分当做单个的任务运行好像是开销更小一点。但是我们要考虑到阻塞的问题。如果程序中的某个任务因为程序控制范围之外的某个条件而导致不能继续执行,那么我们就说这个任务或线程阻塞了。如果没有并发,则整个程序都将停下来,直至外部条件发生变化。但是,如果使用了并发来编写程序,那么当一个任务阻塞时,程序中的其他任务还可以继续执行,因此这个程序可以保持继续向前执行。事实上,从性能角度看,如果没有任务会阻塞,那么在单处理器机器上使用并发就没有任何意义。
-
改进代码的设计:
Java 的线程机制是抢占式的,这表示调度机制会周期性地中断线程,将上下文切换到另一个线程,从而为每个线程都提供时间片段,使得每个线程都分配到数量合理的时间去驱动它的任务。在协作式系统中,每个任务都会自动的放弃控制,这要求程序员有意识的在每个任务中插入让步语句。协作系统的优势是双重的:上下文切换的开销比抢占式要低廉的多,可以同时执行的线程数量理论上没有限制。当你处理大量的仿真元素时,这是一种理想的解决方案。但是注意,某些协作式系统并未设计为可以在多个处理器之间分配任务,这可能会非常有限。
-
-
线程基本机制:
并发编程使得我们可以将程序划分为多个分离的、独立的任务。通过使用多线程机制,这些独立任务中的每一个都将由执行程序来驱动**。一个线程就是进程中的一个单一的顺序控制流**,因此,单个进程可以拥有多个并发执行的任务,但是你的程序使得每个任务都好像有其自己的 CPU 一样。其底层机制是切分 CPU 时间,但我们通常不需要考虑他。-
定义任务:
线程可以驱动任务,因此需要一种描述任务的方式,这可以由 Runnable 接口来提供。要想定义任务**,只需要实现 Runnable 接口并编写 run() 方法**,使得该任务可以执行你的命令。
任务的run()方法通常总会有某种形式的循环,所以要设定跳出循环的条件。 -
Thread类:
将 Runnable 对象转变为一个工作任务的方式是把它提交给一个 Thread 构造器public class BasicThreads { public static void main(String[] args) { // TODO Auto-generated method stub Thread thread = new Thread(new LiftOff()); thread.start(); System.out.println("任务开始"); } }/*任务开始 #0(9), #0(8), #0(7), #0(6), #0(5), #0(4), #0(3), #0(2), #0(1), #0(Liftoff!), */Thread 构造器只需要一个 Runnable 对象。调用 start() 方法为该线程执行提供必须的初始化操作,然后调用 Runnable 的 run() 方法,以便在这个线程中启动任务。可以看到,输出语句先输出了,任务的语句后输出。这表明 start() 语句直接返回了。实际上只是产生了对 LiftOff.run() 方法的调用,并且这个方法还没有完成,但是由于 run() 方法是由不同的线程执行的,所以 main() 方法中的任务还可以继续执行。因此,程序会同时运行两个方法。
-
使用Executor:
Java SE5 的 java.util.concurrent 包中的执行器 (Executor) 将为你管理 Thread 对象,简化了并发编程。Executor 在客户端和任务之间建立了一个中间层;与客户端直接执行任务不同,这个中介将直接执行任务。Executor 允许你管理异步任务的执行,而无需显示的管理线程和生命周期。public class CachedThreadPool { public static void main(String[] args) { // TODO Auto-generated method stub ExecutorService executorService = Executors.newCachedThreadPool(); for (int i = 0; i < 3; i++) { executorService.execute(new LiftOff()); } executorService.shutdown(); } }**Executors.newCachedThreadPool()**方法创建缓冲线程池,shutdown() 方法的调用可以防止新任务被提交给这个 Executor ,当前线程将继续运行在 shutdown() 被提交之前提交的所有任务。
**Executors.newFixedThreadPool(intsize)**方法创建固定数目的线程池,即程序会创建指定数量的线程。缓冲线程池效率和性能高,推荐优先考虑使用。
**Executors.newSingleThreadPool()**创建单线程池,即固定数目为1的线程池,一般用于长时间存活的单任务,例如网络socket连接等,如果有多一个任务需要执行,则会放进队列中顺序执行。
-
从任务中产生回值:
Runnable 是执行工作的独立任务,但是他不反回任何值。如果你希望在任务执行完成时能够返回值,那么可以实现 Callable 接口。它是具有类型参数的泛型,它的类型参数表示的是从方法 call() 中返回的值,并且必须使用 ExecutorService.submit() 方法调用它public class TaskWithResult implements Callable<String>{ private int id; protected TaskWithResult(int id) { super(); this.id = id; } @Override public String call() throws Exception { // TODO Auto-generated method stub return "任务执行完毕"+id; } public static void main(String[] args) { // TODO Auto-generated method stub ExecutorService executorService = Executors.newCachedThreadPool(); ArrayList<Future<String>> result = new ArrayList<>(); for (int i = 0; i < 3; i++) { result.add(executorService.submit(new TaskWithResult(i))); } for (Future<String> future : result) { try { System.out.println(future.get()); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (ExecutionException e) { // TODO Auto-generated catch block e.printStackTrace(); }finally { executorService.shutdown(); } } } }submit 方法会产生 Future 对象,它用 Callable 返回结果的特定类型进行了参数化。可以使用 isDone() 方法查询 Future 对象是否完成。当任务完成时可以调用 get() 方法获取结果。未用isDone()方法直接用get()方法将阻塞,直至结果准备就绪。
-
休眠:
影响任务行为的一种简单方法是调用 sleep(),这将使任务终止执行给定的时间。try { while(countDown-- > 0) { System.out.print(status()); // Old-style: // Thread.sleep(100); // Java SE5/6-style: TimeUnit.MILLISECONDS.sleep(100); } } catch(InterruptedException e) { System.err.println("Interrupted"); }对sleep()的调用可以抛出InterruptedException异常,在**run()**中捕获。因为一场不能跨线程传播回main(),所以必须在本地处理所有在任务内产生的异常。
-
优先级:
可以使用 getPriority() 来读取现有线程的优先级,可以通过 setPriority() 来修改它。public class SimplePriorities implements Runnable{ private int countDown = 5; private volatile double d; // No optimization private int priority; protected SimplePriorities(int priority) { // super(); this.priority = priority; } public String toString() { return Thread.currentThread() + ": " + countDown; } @Override public void run() { Thread.currentThread().setPriority(priority); while(true) { // An expensive, interruptable operation: for(int i = 1; i < 100000; i++) { d += (Math.PI + Math.E) / (double)i; if(i % 1000 == 0) Thread.yield(); } System.out.println(this); if(--countDown == 0) return; } } public static void main(String[] args) { ExecutorService exec = Executors.newCachedThreadPool(); for(int i = 0; i < 5; i++) exec.execute(new SimplePriorities(Thread.MIN_PRIORITY)); exec.execute(new SimplePriorities(Thread.MAX_PRIORITY)); exec.shutdown(); } }JDK 有 10 个优先等级,但是与大多数操作系统的映射不好。唯一可移植的方法是当调整优先级的时候,只使用MAX_PRIORITY、NORM_PRIORITY、MIN_PRIORITY三种级别。
-
让步:
如果你已经知道你的一次循环迭代过程中的工作已经完成,就可以给线程调度机制一个暗示:你的工作完成的差不多了,可以让别的线程使用 CPU 了。这个暗示将通过调用 yield() 来完成。注意,这只是一种暗示,没有任何机制保证它将会被采纳。当调用 yield() 时,你也是在建议具有相同优先级的其他线程可以运行。 -
后台线程:
后台线程就是指在程序运行的时候在后台提供一种通用服务的线程,这种线程不是程序必须的一部分。因此,当所有的非后台线程结束时,程序也就终止了,同时户杀死进程中的所有后台进程。反过来说,**只要有任何非后台进程还在运行,程序就不会被终止。**比如 main() 就是一个非后台线程。
public class SimpleDaemons implements Runnable { public void run() { try { while(true) { TimeUnit.MILLISECONDS.sleep(100); print(Thread.currentThread() + " " + this); } } catch(InterruptedException e) { print("sleep() interrupted"); } } public static void main(String[] args) throws Exception { for(int i = 0; i < 10; i++) { Thread daemon = new Thread(new SimpleDaemons()); //比如在调用之前设置为后台线程才会生效 daemon.setDaemon(true); // Must call before start() daemon.start(); } print("All daemons started"); TimeUnit.MILLISECONDS.sleep(175); } }必须在线程启动之前调用 setDaemon() 方法,才能把他设置为后台线程。
可以通过 isDaemon() 方法来确定线程是否是一个后台线程。如果是一个后台线程,那么它创建的任何线程都将被自动设置为后台线程后台线程在不执行 finally 的时候就会终止其 run() 方法。
-
编码的变体:
前述我们都是直接实现 Runnable 接口。我们也可以直接从 Thread 继承这种可替换的方式。public class SimpleThread extends Thread{ private int countDown = 5; private static int threadCount = 0; protected SimpleThread() { super(Integer.toString(++threadCount)); start(); } @Override public String toString() { // TODO Auto-generated method stub return"#" + getName()+"(" +countDown + ")"; } @Override public void run() { // TODO Auto-generated method stub while (true) { System.out.println(this); if (--countDown ==0) { return; } } } public static void main(String[] args) { for (int i = 0; i < 2; i++) { new SimpleThread(); } } }另外一种常用的方法是自管理的Runnable:
public class SelfManaged implements Runnable { private int countDown = 5; private Thread t = new Thread(this); public SelfManaged() { t.start(); } public String toString() { return Thread.currentThread().getName() + "(" + countDown + "), "; } public void run() { while(true) { System.out.print(this); if(--countDown == 0) return; } } public static void main(String[] args) { for(int i = 0; i < 2; i++) new SelfManaged(); } }start() 是在构造器中被调用的。但是应该意识到,在构造器中启动线程可能会变得有问题,因为另一个任务可能在构造器结束之前开始执行,这意味着该任务能够访问处于不稳定状态的对象。这也是我们优先选择 Executor 而不是显示的创建 Thread的原因。
-
可以通过内部类将线程代码隐藏在类中,如果内部类具有你在其他方法中需要访问的特殊能力,这么做很有意义。大多数时候创建线程只是为了使用Thread的能力。
-
加入一个线程:
一个线程可以在其他线程之上调用join()方法,其效果是等待一段时间直到第二个线程结束才执行。 如果某个线程在另一个线程 t 上调用 join() 方法,此线程将会被挂起,直到目标线程 t 结束才恢复。也可以在调用 join() 时带上一个超时参数,这样如果目标线程在这段时期没有完成结束,join() 方法总能返回。对 join() 方法的调用可以被中断,做法是在调用线程上调用 interrupt() 方法,这时需要用到try-catch子句。 -
捕获异常:
由于线程的本质特征,使得你不能捕获从线程中逃逸的异常。一旦异常逃出任务的 run() 方法,它就会向外传播到控制台,除非你采取特殊的步骤捕获这种错误的异常。在 Java SE5 之后,可以用 Executor 来解决这个问题。异常逃出任务的run()方法,在main方法中将主体放入try-catch子句中还是无法捕获异常。为了解决该问题,修改Executor产生线程的方式。Thread.UncaughtExceptionHandler是Java SE5中的新接口,它允许在每个Thread对象上都附着一个异常处理器。Thread.UncaughtExceptionHandler.uncaughtException()会在线程因未捕获的异常而临近死亡时被调用。为了使用它,要创建一个TreadFactory,它将在每个新创建的Thread对象上附着一个Thread.UncaughtExceptionHandler:
-
自定义一个异常捕获器:
public class MyUncaughtExceptionHandler implements UncaughtExceptionHandler{ @Override public void uncaughtException(Thread t, Throwable e) { // TODO Auto-generated method stub System.out.println("自定义的异常捕获"+e); } } -
实现一个线程工厂,将产生的线程加入异常捕获:
public class HandlerThreadFactory implements ThreadFactory{ @Override public Thread newThread(Runnable r) { System.out.println("创建一个新的线程"); Thread thread = new Thread(r); thread.setUncaughtExceptionHandler(new MyUncaughtExceptionHandler()); System.out.println("添加异常捕获结束"); return thread; } } -
测试
public class CaptureUncaughtException { public static void main(String[] args) { //添加进到构造方法 ExecutorService executorService = Executors.newCachedThreadPool(new HandlerThreadFactory()); executorService.execute(new ExceptionThread()); } }如果你要在代码中使用相同的异常处理器,那么更简单的方法是在 Thread 类中设置一个静态域,并将这个处理器设置为默认的异常捕获处理器:
public class SettingDefaultHandler { public static void main(String[] args) { Thread.setDefaultUncaughtExceptionHandler( new MyUncaughtExceptionHandler()); ExecutorService exec = Executors.newCachedThreadPool(); exec.execute(new ExceptionThread()); } }默认的异常处理器只有在线程未设置专有的异常处理器情况下才会被调用。
-
-
-
共享受限资源:
单个线程每次只能做一件事情。因为只有一个实体所以永远不用担心两个人在同一个地方停车的问题。但是多线程会在同时访问一个资源-
解决共享资源竞争:
对于并发操作,你需要某种方式来防止两个任务访问相同的资源,至少在关键阶段不能出现这种情况。防止这种冲突的方法是当资源被一个任务使用时,在其上加锁。第一个访问某项资源的任务必须锁定这个资源,使其他任务在其被解锁前无法访问他,而在其解锁之时,另一个任务就可以锁定并使用它,以此类推。
基本上所有的并发模式在解决线程冲突问题的时候,都是采用序列化访问共享资源的方案。这意味着在给定时刻只允许一个任务访问共享资源。通常这种是通过在代码前面加上一句锁语句来实现的,这就使得在一段时间内只有一个任务可以运行这段代码。因为锁语句产生一种相互排斥的效果,这种机制称为互斥量(mutex)。
另外当一个锁被解锁的时候,我们并不能确定下一个使用锁的任务,因为线程调度机制并不是确定性的。可以通过 yield() 和 setPriorit() 来给线程调度器提供建议。
- synchronized
Java 以提供关键字 synchronized 的形式,为防止资源冲突提供了内在支持。当任务要执行被 synchronized 关键字保护的代码片段的时候,它将检查锁是否可用,然后获取锁,执行代码,释放锁。共享资源一般是以对象像是存在于内存片段,可以是文件、输入输出端口。要控制对共享资源的访问,得先把它包装进一个对象。然后把所有要访问这个资源的方法标记为 synchronized。
声明synchronized方法的方式:
synchronized void f(){};所有对象都自动含有单一的锁(监视器)。当在对象上调用其任意 synchronized 方法的时候,此对象被加锁,这时这个对象上的其他 synchronized 方法只有等到前一个方法调用完毕并释放了锁之后才能被调用。对于某个特定对象来说,其所有 synchronized 方法共享同一个锁,这可以被用来防止多个任务同时访问被编码为对象内存。
使用并发时将对象设置为 private 是非常重要的,否则,synchronized 关键字就不能防止其他的任务直接访问域,这样就会产生冲突。
针对每个类也有一个锁,所以 synchronized static 方法可以在类的范围内防止对 static 数据的并发访问。
//如果你正在写一个变量,它可能接下来被另一个线程读取,或者正在读取一个上一次被另一个线程写过的变量,那么你必须使用同步,并且,读写线程都必须用相同的监视器锁同步。每个访问临界共享资源的方法都必须被同步,否则它们就不会正确地工作。
-
使用显式地Lock对象
Java SE5 的类库中还包含定义在 java.util.concurrent.locks 中的显示的互斥机制。Lock 对象必须被显示地创建、锁定和释放。因此,它与内建的锁形式相比,代码缺乏有雅性。但是对于解决某些类型的问题时更加的灵活。public class EvenGenerator extends IntGenerator{ private int currentEvenValue = 0; //创建锁 private Lock lock = new ReentrantLock(); @Override public int next() { //锁定 lock.lock(); try { ++currentEvenValue; Thread.yield(); ++currentEvenValue; return currentEvenValue; }finally { //计算完毕后释放锁 lock.unlock(); } } public static void main(String[] args) { EvenChecker.test(new EvenGenerator()); } }对 unlock() 方法的调用必须放在 try-finlly 语句中。注意,return 语句必须在 try 子句中出现,以确保 unlock() 不会过早的发生,从而将数据暴露在第二个任务。
ReentrantLock 允许我们尝试着获取锁但是最终未获取锁tryLock(),这样如果其他人已经获取了锁,那么你就可以决定离开做一些其他的事情,而不是一直等待这个锁被释放。
-
原子性与易变性
原子性可以应用于除了 long 和 double 之外的所有基本类型之上的 “简单操作”。但是 jvm 会把 64 位的 long 和 double 操作当做两个分离的 32 位的操作来执行,这就产生了一个读取和写入操作之间产生上下文切换,从而导致了不同的任务产生不正确结果的可能性。但是如果我们使用 volatile 关键字就会获得原子性在多核处理器上,可视性问题远比原子性问题多得多。一个任务做出的修改可能对其他任务是不可见的。因为每个任务都会暂时把信息存储在缓存中。同步机制强制在处理器中一个任务做出的修改必须是可见的。volatile 关键字确保了这种可视性。一个任务修改了对这个修饰对象的操作,那么其他的任务读写操作都能看到这个修改。即使是用了缓存也能被看到,因为 volatile 会被立即写入主存。而读写操作就发生在主存中。同步也会导致向主存中刷新,所以如果一个对象是 synchronized 保护的那么久不必使用 volatile 修饰。使用 volatile 而不是 synchronized 的唯一安全的情况是类中只有一个可变的域。我们的第一选择应该是 synchronized 关键字,这是最安全的方式。
如果一个域可能会被多个任务同时访问,或者这些任务中至少有一个是写入任务,你就应该将这个域设置为volatile。
-
原子类:
Java SE5 中引入了诸如 AtomicInteger、AtomicLong、AtomicReference 等等特殊的原子性变量类,提供了下面的原子更新形式:boolean compareAndSet(expectedValue,updateValue);Atomic 类被设计为构建 Java.util.concurrent 中的类,因此只有在特殊情况下才在代码中使用他们。
-
临界区:
有时我们需要防止多个线程同时访问方法内部的部分代码而不是防止访问整个方法。通过这种方式分离出来的代码被称为临界区,也是使用 synchronized 关键字修饰。synchronized (syncObject){ //被同步控制的代码块 }这被称之为同步代码块;在进入此段代码之前,必须得到 syncObject 对象的锁。如果其他线程已经得到锁,那么就得等到锁被释放之后,才能进入临界区。
-
在其他对象上同步:
ynchronized 块必须给定一个在其上同步的对象,并且合理的方式是,使用其方法正在被调用的当前对象:synchronized(this),在这种方式中如果获得了 synchronized 块上的锁,那么该对象其他的 synchronized 方法和临界区就不能被调用了。class DualSynch { private Object syncObject = new Object(); public synchronized void f() { for(int i = 0; i < 5; i++) { print("f()"); Thread.yield(); } } public void g() { synchronized(syncObject) { for(int i = 0; i < 5; i++) { print("g()"); Thread.yield(); } } } } public class SyncObject { public static void main(String[] args) { final DualSynch ds = new DualSynch(); new Thread() { public void run() { ds.f(); } }.start(); ds.g(); } } -
线程本地存储:
防止任务在共享资源上产生冲突的第二种方式是根除对变量内存的共享。线程本地存储是一种自动化机制,可以**使用相同变量的每个不同的线程创建不同的存储。**创建和管理线程本地存储可以由 java.lang.ThreadLocal 类来实现
private static ThreadLocal<Integer> value = new ThreadLocal<Integer>(){ private Random dRandom = new Random(47); protected synchronized Integer initialValue(){ return dRandom.nextInt(10000); } }; public static void increment() { value.set(value.get()+1); } public static int get() { return value.get(); }ThreadLocal 对象通常当做静态存储域。创建 ThreadLocal 方法时只能通过 get() 和 set() 方法来访问内容,其中,get() 方法返回与对象相关联的副本,而 set() 将会将参数插入到为其线程存储的对象中,并返回存储中原有对象。运行这个程序的时候会发现每个单独的线程都分配了自己的存储,因为他们每个都要跟踪自己的计数值。
-
终结任务:
-
在阻塞时终结:
线程状态:
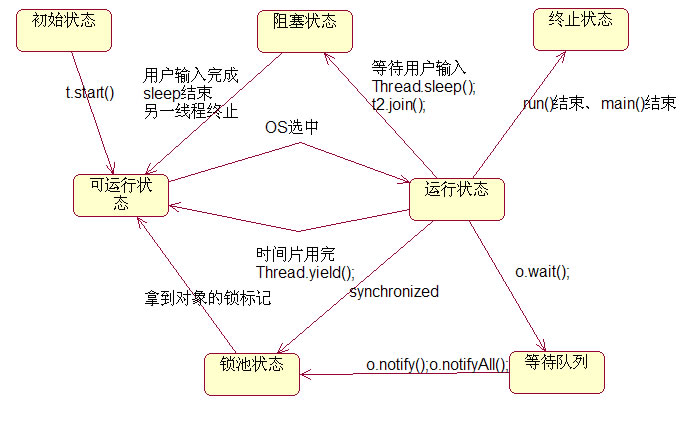
- 新建 (new):当线程被创建时,他只会短暂的处以这种状态。此时已经分配了必要的资源,并执行初始化。此刻线程已经有资格获得 cpu 时间了,之后调度器会把这个线程转变为可运行状态或阻塞状态。
- 就绪 (Runnable):在这种状态下只要调度器把时间片分配给线程,线程就可以运行。在任意时刻线程可以运行也可以不运行,取决于调度器是否分配给线程时间片。
- **阻塞 (Blocked):**线程能够运行,但有个条件组织它运行。当线程处于阻塞状态时,调度器将忽略线程不会分配给他任何 cpu 时间。
- 死亡 (Dead):处于死亡和终止状态的线程将不再可被调度,并且再也不会得到 cpu 时间,它的任务已经结束,或不再是可运行的。任务死亡的方式通常是从 run() 方法返回,但是任务的线程还可以被中断。
进入阻塞状态,可能有如下原因:
- 通过调用 sleep() 使任务进入休眠状态,在这种情况下任务在指定的时间内不会运行。
- 你通过调用 wait() 使线程挂起。直到线程得到了 notif() 或 notifall() 消息,线程才会进入就绪状态。
- 任务在等待某个输入或输出完成。
- 任务试图在某个对象上调用其同步控制方法,但是对象锁不可用,因为另一个任务已经获取了锁。
有时我们希望能够终止处于阻塞状态的任务。我们决定让其主动终止,那么必须强制这个任务跳出阻塞状态。
-
中断:
Thread 类包含 interrupt() 方法,因此你可以终止被阻塞的任务,这个方法将设置线程的中断状态。如果一个线程被阻塞或者试图执行一个阻塞操作,那么设置这个线程的阻塞状态将抛出 InterruptedException。当抛出该异常或者改任务调用 Thread.interrupt() 时,中断状态将被复位。Thread.interrupt() 提供了离开 run() 循环而不抛出异常的办法。
你可以中断对sleep()的调用,但是不能中断正在获取Synchronized锁或者试图执行I/O操作的线程。对于这类问题,一种笨拙的方法是关闭任务在其发生阻塞的底层资源。nio类提供了更人性化的I/O中断,被阻塞的nio通道会自动地响应中断。
-
互斥阻塞:
如果你尝试在一个对象上调用其 synchronized 方法,而这个对象的锁已经被其他任务获得,那么调用任务将会被挂起,直至这个锁被获得。
与I/O调用不同,interrupt()可以打断被互斥所阻塞的调用。
-
-
线程之间的协作:
当任务协作时,关键问题是这些任务之间的握手。为了实现握手,我们使用了相同的基础特性:互斥。在这种情况下,互斥能够确保只有一个任务可以响应某个信号,这样就能根除任何可能的竞争条件。这种握手可以通过Object的方法wait()和notify()来安全实现。Java SE5 并发类库还提供了具有await()和signal()方法的Condition对象。-
wait()和notifyAll():
wait() 可以使你等待某个条件发生变化,而改变这个条件通常是由另一个任务来改变。**wait() 会在外部条件发生变化的时候将任务挂起,并且只有在 notif() 或 notifAll() 发生时,这个任务才会被唤醒并去检查所发生的变化。**因此,wait() 提供了一种在任务之间对活动同步的方式。
调用 sleep() 时候锁并没有被释放,调用 yield() 也是一样。当一个任务在方法里遇到对 wait() 调用时,线程执行被挂起,对象的锁被释放。这就意味着另一个任务可以获得锁,因此在改对象中的其他 synchronized 方法可以在 wait() 期间被调用。有两种形式的wait()
- 第一种是接受毫秒作为参数:再次暂停的事件
在wait()期间对象锁是被释放的
可以通过notify()或notifyAll(),或者指令到期,从wait()中回复执行 - 第二种不接受参数的wait()
这种wait()将无限等待下去,直到线程接收到notify()或notifyAll()。
wait(),notify()和notifyAll()方法必须只能在synchronized线程同步方法中调用,因为在调用这些方法之前必须首先获得线程锁,如果在非线程同步的方法中调用时,编译时没有问题,但在运行时会抛IllegalMonitorStateException异常,异常信息是当前线程不是方法对象的监视器对象所有者。
比如,如果向对象 x 发送 notifAll(),那就必须在能够得到 x 的锁的同步控制块中这么做:
synchronized(x){ x.notifAll(); }必须用一个检查感兴趣的条件的while循环包围wait(),其本质就是要检查所有感兴趣的特定条件,并在条件不满足的情况下返回到wait()中。
错失信号
当两个线程使用notify()/wait()或notifyAll()/wait()进行协作时,有可能会错过某个信号。 - 第一种是接受毫秒作为参数:再次暂停的事件
-
notify()和notifyAll()
可能有多个任务在单个Car对象上处于wait()状态,因此调用notifyAll()比只调用notify()更安全。notify()并不是notifyAll的一种优化,notify()在众多等待同一个锁的任务中只有一个会被唤醒。 当notifyAll()因某个特定锁而被调用时,只有等待这个锁的任务才会被唤醒。 -
生产者与消费者:
示例:public class Meal { private final int orderNum; public Meal(int orderNum) { this.orderNum = orderNum; } public String toString() { return "Meal " + orderNum; } } public class WaitPerson implements Runnable { private Restaurant restaurant; public WaitPerson(Restaurant r) { restaurant = r; } public void run() { try { while(!Thread.interrupted()) { synchronized(this) { while(restaurant.meal == null) wait(); // ... for the chef to produce a meal } Print.print("Waitperson got " + restaurant.meal); synchronized(restaurant.chef) { restaurant.meal = null; restaurant.chef.notifyAll(); // Ready for another } } } catch(InterruptedException e) { Print.print("WaitPerson interrupted"); } } } public class Chef implements Runnable { private Restaurant restaurant; private int count = 0; public Chef(Restaurant r) { restaurant = r; } public void run() { try { while(!Thread.interrupted()) { synchronized(this) { while(restaurant.meal != null) wait(); // ... for the meal to be taken } if(++count == 10) { Print.print("Out of food, closing"); restaurant.exec.shutdownNow(); } Print.printnb("Order up! "); synchronized(restaurant.waitPerson) { restaurant.meal = new Meal(count); restaurant.waitPerson.notifyAll(); } TimeUnit.MILLISECONDS.sleep(100); } } catch(InterruptedException e) { Print.print("Chef interrupted"); } } } public class Restaurant { Meal meal; ExecutorService exec = Executors.newCachedThreadPool(); WaitPerson waitPerson = new WaitPerson(this); Chef chef = new Chef(this); public Restaurant() { exec.execute(chef); exec.execute(waitPerson); } public static void main(String[] args) { new Restaurant(); } }/* Order up! Waitperson got Meal 1 Order up! Waitperson got Meal 2 Order up! Waitperson got Meal 3 Order up! Waitperson got Meal 4 Order up! Waitperson got Meal 5 Order up! Waitperson got Meal 6 Order up! Waitperson got Meal 7 Order up! Waitperson got Meal 8 Order up! Waitperson got Meal 9 Out of food, closing Order up! WaitPerson interrupted Chef interrupted */- 使用显式地lock和Condition对象
使用互斥并允许任务挂起的基本类是 Condition,你可以通过在 Condition 上调用 await() 来挂起一个任务。当外部条件发生变化时,意味着某个任务应该继续执行,你可以通过调用 signal() 来通知这个任务,从而唤醒一个任务,或者调用 signalAll() 来唤醒所有在这个 Condition 上被挂起的任务。(signalAll() 比 notifAll() 是更安全的方式)
- 使用显式地lock和Condition对象
-
生产者消费者队列:
wait()和 notifAll() 方法以一种非常低级的方式解决了任务的互操作的问题,即每次交互时都握手。许多时候我们可以使用同步队列来解决协作的问题,同步队列在任何时刻只允许一个任务插入或移除元素。在 Java.util.concurrent.BlockingQueue 接口中提供了这个队列,这个接口有大量的标准实现。可以使用 LinkedBlockingQueue 他是一个无界队列,还可以使用ArrayBlockingQueue,它具有固定的尺寸,可以在它被阻塞之前向其中放置有限数量的元素。
如果消费者任务试图从队列中获取对象,而该队列为空时,那么这些队列就可以挂起这些任务,并且当有更多的元素可用时恢复这些消费任务。
public class LiftOff implements Runnable{ protected int countDown = 10; // Default private static int taskCount = 0; private final int id = taskCount++; public LiftOff() {} public LiftOff(int countDown) { this.countDown = countDown; } public String status() { return "#" + id + "(" + (countDown > 0 ? countDown : "Liftoff!") + "), "; } public void run() { while(countDown-- > 0) { System.out.print(status()); Thread.yield(); } } }LiftOffRunner类:
public class LiftOffRunner implements Runnable{ private BlockingQueue<LiftOff> rockets; protected LiftOffRunner(BlockingQueue<LiftOff> rockets) { super(); this.rockets = rockets; } public void add(LiftOff lo) { try { rockets.put(lo); } catch (InterruptedException e) { // TODO Auto-generated catch block System.out.println("添加失败"); } } @Override public void run() { // TODO Auto-generated method stub try { while (!Thread.interrupted()) { LiftOff rocket = rockets.take(); rocket.run(); } } catch (InterruptedException e) { // TODO Auto-generated catch block System.out.println("运行中断"); } System.out.println("退出运行"); } }public class TestBlockingQueues { static void getkey(){ try { new BufferedReader(new InputStreamReader(System.in)).readLine(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } static void getkey(String message) { Print.print(message); getkey(); } static void test(String msg,BlockingQueue<LiftOff> queue){ LiftOffRunner runner = new LiftOffRunner(queue); Thread thread = new Thread(runner); thread.start(); //启动了,但是内容是空的,就一直挂起,等待有新的内容进去 for (int i = 0; i < 5; i++) { runner.add(new LiftOff(5)); } getkey("Press Enter "+ msg); thread.interrupt(); } public static void main(String[] args) { test("LinkedBlockingQueue", new LinkedBlockingQueue<LiftOff>()); test("ArrayBlockingQueue", new ArrayBlockingQueue<>(3)); test("SynchronousQueue", new SynchronousQueue<>()); } }示例2:(吐司BlockingQueue)
class Toast { public enum Status { DRY, BUTTERED, JAMMED } private Status status = Status.DRY; private final int id; public Toast(int idn) { id = idn; } public void butter() { status = Status.BUTTERED; } public void jam() { status = Status.JAMMED; } public Status getStatus() { return status; } public int getId() { return id; } public String toString() { return "Toast " + id + ": " + status; } } class ToastQueue extends LinkedBlockingQueue<Toast> {} class Toaster implements Runnable { private ToastQueue toastQueue; private int count = 0; private Random rand = new Random(47); public Toaster(ToastQueue tq) { toastQueue = tq; } public void run() { try { while(!Thread.interrupted()) { TimeUnit.MILLISECONDS.sleep( 100 + rand.nextInt(500)); // Make toast Toast t = new Toast(count++); print(t); // Insert into queue toastQueue.put(t); } } catch(InterruptedException e) { print("Toaster interrupted"); } print("Toaster off"); } } // Apply butter to toast: class Butterer implements Runnable { private ToastQueue dryQueue, butteredQueue; public Butterer(ToastQueue dry, ToastQueue buttered) { dryQueue = dry; butteredQueue = buttered; } public void run() { try { while(!Thread.interrupted()) { // Blocks until next piece of toast is available: Toast t = dryQueue.take(); t.butter(); print(t); butteredQueue.put(t); } } catch(InterruptedException e) { print("Butterer interrupted"); } print("Butterer off"); } } // Apply jam to buttered toast: class Jammer implements Runnable { private ToastQueue butteredQueue, finishedQueue; public Jammer(ToastQueue buttered, ToastQueue finished) { butteredQueue = buttered; finishedQueue = finished; } public void run() { try { while(!Thread.interrupted()) { // Blocks until next piece of toast is available: Toast t = butteredQueue.take(); t.jam(); print(t); finishedQueue.put(t); } } catch(InterruptedException e) { print("Jammer interrupted"); } print("Jammer off"); } } // Consume the toast: class Eater implements Runnable { private ToastQueue finishedQueue; private int counter = 0; public Eater(ToastQueue finished) { finishedQueue = finished; } public void run() { try { while(!Thread.interrupted()) { // Blocks until next piece of toast is available: Toast t = finishedQueue.take(); // Verify that the toast is coming in order, // and that all pieces are getting jammed: if(t.getId() != counter++ || t.getStatus() != Toast.Status.JAMMED) { print(">>>> Error: " + t); System.exit(1); } else print("Chomp! " + t); } } catch(InterruptedException e) { print("Eater interrupted"); } print("Eater off"); } } public class ToastOMatic { public static void main(String[] args) throws Exception { ToastQueue dryQueue = new ToastQueue(), butteredQueue = new ToastQueue(), finishedQueue = new ToastQueue(); ExecutorService exec = Executors.newCachedThreadPool(); exec.execute(new Toaster(dryQueue)); exec.execute(new Butterer(dryQueue, butteredQueue)); exec.execute(new Jammer(butteredQueue, finishedQueue)); exec.execute(new Eater(finishedQueue)); TimeUnit.SECONDS.sleep(5); exec.shutdownNow(); } }
-
-
死锁:
某个任务在等待另一个任务,而后者又在等待别的任务,这样一直下去,直到这个链条上的任务又在等待第一个任务释放锁。这就形成了一个相互等待的循环,没有那个线程能够继续。这被称之为死锁。产生死锁的四个条件:
- 互斥条件。任务使用的资源中至少有一个是不能共享的。
- 至少有一个任务必须持有一个资源,并且正在等待获取一个当前被别的任务持有的资源。
- 资源不能被任务抢占,任务必须把资源释放当做普通事件。
- 必须有循环等待,这时一个任务等待其他任务所持有的资源,后者又在等待另一个任务所持有的资源,这样循环下去直到有一个任务等待第一个任务所持有的资源,使得大家都被锁住。
死锁要发生则必须要满足上述的四个条件,防止死锁只需破坏其中的一种就可以了,最容易的是破坏第四个循环条件。
-
新类库中的构件:
-
CountDownLatch:
他被用来同步一个或多个任务,强制他们等待由其他的任务执行的一组操作完成。你可以向CountDownLatch对象设置一个初始计数值,任何在这个对象上调用 wait() 的方法都将阻塞,直至这个计数值到达 0。其他任务在结束其工作时,可以在该对象上调用 countDown() 来减小这个计数值。CountDownLatch被设计为只触发一次,计数值不能被重置。如果需要重置计数值的版本,则可以使用 CyclicBarrier 版本。调用 countDown() 的任务在产生这个调用时并没有被阻塞,只有对 await() 的调用会被阻塞,直至技术值到达 0。 -
CyclicBarrier:
你希望创建一组任务,他们并行的执行工作,然后在进行下一个步骤之前等待,直至所有任务都完成。他使得所有的任务都在栅栏处等待,因此可以一致的向前移动。与CountDownLatch类似,只是CountDownLatch是只触发一次事件,而CyclicBarrier可以多次重用。 -
DelayQueue:
这是一个无界的 BlockingQueue,用于放置实现 Delayed接口的对象,其中的对象只能在其到期时才能从队列中取走。这种队列是有序的,即队列对象的延迟到期的时间最长。如果没有任何延迟到期时间,那么就不会有任何头元素,并且 poll() 将返回 null。DelayedTask 包含一个称为 sequence 的 List,它保存了任务被创建的顺序,因此我们看到排序是按照实际发生的顺序执行的。Delsyed 接口有一个方法名叫 getDealay(),他可以用来告知延迟到期多长时间,或者延迟在多长时间以前已经到期。这个方法将强制我们使用 TimeUnit 类,因为这就是参数类型。
-
PriorityBlockingQueue:
基础的优先级队列,具有可阻塞的读取操作。 -
ScheduledThreadPoolExecutor:
一种并发问题,每个期望的事件都是一个预定事件运行的任务。通过使用 schedule() 运行一次任务或者使用 scheduleAtFixedRate() 每隔规则的时间重复执行任务,你可以将 Runnable 对象设置为在将来的某个时刻执行。 -
semaphore:
正常的锁在任何时刻都只允许一个任务访问资源,而技术信号量允许 n 个任务同时访问这个资源。 -
Exchanger:
Exchanger是在两个任务之间交换对象的栅栏。当这些任务进入栅栏时,他们各自拥有一个对象,当它们离开时,它们都拥有之前由对象持有的对象。
-
-
性能调优:
-
比较互斥技术:
使用 Lock 要比使用 synchronized 要高效的多,而且 synchronized 的开销看起来变化范围太大,而 Lock 相对比较一致。
这里有两个因素要考虑:首先要看互斥方法体的大小,在实际开发中互斥部分可能会非常大,因此在方法体中所花费的时间的百分比可能会明显大于进入和退出互斥的开销,这样就是淹没了提高互斥速度所带来的好处。当然对于这一点我们需要在性能调优时尝试各种不同的方法观察他们的影响。其次,很明显 synchronized 关键字所产的代码要比 Lock 要少的多,可读性也提高了许多。代码被阅读的次数远高于被编写的次数。在编程时与其他人的交流相对于与计算机的交流要重要的多,因此代码的可读性至关重要。
-
免锁容器:
免锁容器背后的通用策略是:对容器的修改可以和读取操作同时发生,只要读取者只能看到完成修改后的结果即可。修改是在容器数据结构的某个部分的一个单独的副本上执行的,并且这个副本在修改过程中是不可见的。只有当修改完成时,被修改的结构才会自动地与主数据结构交换,之后读取者就可以看到修改之后的结果了
在 CopyOnWriteArrayList 中,写入将导致创建整个底层数组的副本,而源数组将保留在原地,使得复制的数组再被修改时,读取操作可以安全的执行。当修改完成时,一个原子性的操作将把新的数组换入,使得新的读取操作可以看到这个新的修改
。CopyOnWriteArrayList的好处之一是当多个迭代器同时遍历和修改这个列表时,不会抛出ConcurrentModificationException。CopyOnWriteArraySet将使用CopyOnWriteArrayList来实现其免锁行为。
ConcurrentHashMap 和 ConcurrentLinkedQueue 使用了类似的技术,允许并发的读取和写入,但是容器中只有部分内容而不是整个容器可以被复制和修改。然而,任何修改在完成之前,读取者仍旧不能看到他们。乐观锁
只要你主要是从免锁容器中读取,那么就会比其对应的 synchronized 快许多,因为获取和释放锁的开销被省掉了。如果要向免锁容器执行少量的写入,那么情况也是如此。 -
比较Map实现:
比较一下synchronizedHashMap和ConcurrentHashMap在性能方面比较。
向ConcurrentHashMap添加写入的影响甚至还不如CopyOnWriteArrayList明显,这是因为ConcurrentHashMap使用了一种不同的技术,它可以明显地最小化写入所造成的影响。 -
乐观加锁:
尽管 Atomic 对象将执行像 decrementAndGet() 这样的原子操作,但是某些 Atomic 类还允许你执行所谓的乐观加锁。这意味着当你执行某项计算时,实际上没有使用互斥,但是在这个对象计算完成并且准备更新这个对象时,你需要使用一个 compareAndSet() 的方法。你将旧值和新值一起提交给这个方法,如果不一样,那么这个操作失败。这意味着某个地方的任务在这个操作期间修改了这个对象。但是我们是乐观的,因为我们保持数据在未锁定的状态,并希望没有任何其他的任务插入修改它。通过使用 Atomic 来替代 synchronized 或 lock,可以获得性能上的好处。 -
ReadWriteLock:
ReadWriteLock 对于那种向数据结构中不频繁的写入,但是有多个任务要经常读取这个数据结构的情况进行了优化。ReadWriteLock 使得你可以同时有多个读取者,只要他们都不试图写入即可。如果写锁已经被其他任务持有,那么任何读取者都不能访问,直至这个写锁被释放。
-
-















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









