







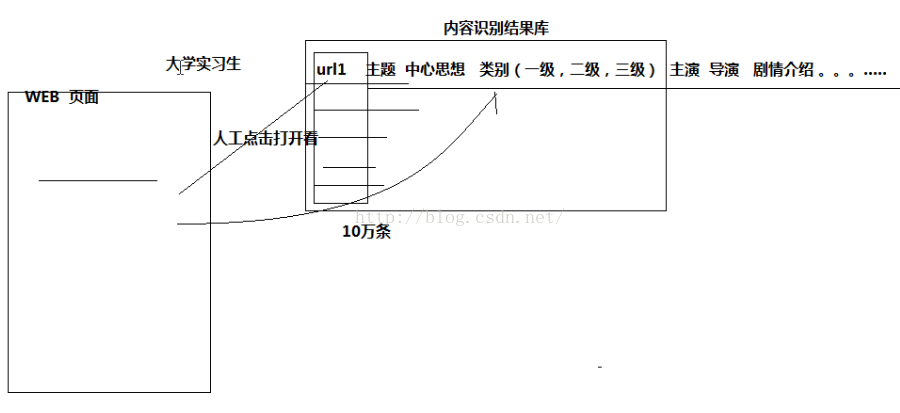
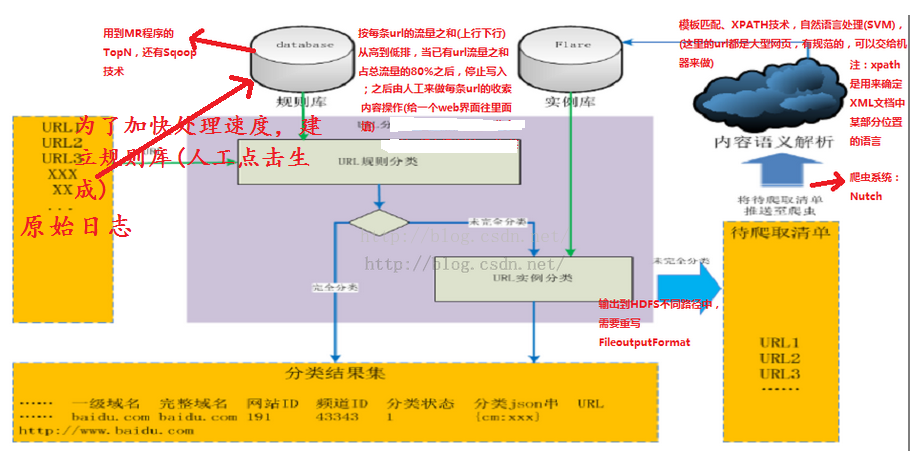
一、项目的核心模块(数据处理流程图)
二、相关代码
1、建立规则数据库(TopN)
public class TopkURLMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
private FlowBean bean = new FlowBean();
private Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\t");
try {
if (fields.length > 32 && StringUtils.isNotEmpty(fields[26])
&& fields[26].startsWith("http")) {
String url = fields[26];
long up_flow = Long.parseLong(fields[30]);
long d_flow = Long.parseLong(fields[31]);
k.set(url);
bean.set("", up_flow, d_flow);
context.write(k, bean);
}
} catch (Exception e) {
System.out.println();
}
}
}public class TopkURLReducer extends Reducer<Text, FlowBean, Text, LongWritable>{
private TreeMap<FlowBean,Text> treeMap = new TreeMap<>();//Treemap默认按照key进行排序,这里重写了FloewBean的ComparedTo方法,按照流量排序
private double globalCount = 0;
// <url,{bean,bean,bean,.......}>
@Override
protected void reduce(Text key, Iterable<FlowBean> values,Context context)
throws IOException, InterruptedException {
Text url = new Text(key.toString());
long up_sum = 0;
long d_sum = 0;
for(FlowBean bean : values){
up_sum += bean.getUp_flow();
d_sum += bean.getD_flow();
}
FlowBean bean = new FlowBean("", up_sum, d_sum);
//每求得一条url的总流量,就累加到全局流量计数器中,等所有的记录处理完成后,globalCount中的值就是全局的流量总和
globalCount += bean.getS_flow();
treeMap.put(bean,url);
}
//cleanup方法是在reduer任务即将退出时被调用一次
@Override
protected void cleanup(Context context)
throws IOException, InterruptedException {
Set<Entry<FlowBean, Text>> entrySet = treeMap.entrySet();
double tempCount = 0;
for(Entry<FlowBean, Text> ent: entrySet){
if(tempCount / globalCount < 0.8){
context.write(ent.getValue(), new LongWritable(ent.getKey().getS_flow()));
tempCount += ent.getKey().getS_flow();
}else{
return;
}
}
}2、读入原始日志数据,抽取其中的url,查询规则库,获得该url指向的网页内容的分析结果,追加到原始日志后;如果没查到,则交给未完全分类去处理
public class LogEnhanceMapper extends
Mapper<LongWritable, Text, Text, NullWritable> {
private HashMap<String, String> ruleMap = new HashMap<>();
// setup方法是在mapper task 初始化时被调用一次
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
DBLoader.dbLoader(ruleMap);//将数据库数据加载至Hashmap
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = StringUtils.split(line, "\t");
try {
if (fields.length > 27 && StringUtils.isNotEmpty(fields[26])
&& fields[26].startsWith("http")) {
String url = fields[26];
String info = ruleMap.get(url);
String result = "";
if (info != null) {
result = line + "\t" + info + "\n\r";
context.write(new Text(result), NullWritable.get());
} else {
result = url + "\t" + "tocrawl" + "\n\r";
context.write(new Text(result), NullWritable.get());
}
} else {
return;
}
} catch (Exception e) {
System.out.println("exception occured in mapper.....");
}
}
}
public class DBLoader {
public static void dbLoader(HashMap<String, String> ruleMap) {
Connection conn = null;
Statement st = null;
ResultSet res = null;
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://weekend01:3306/urlcontentanalyse", "root", "root");
st = conn.createStatement();
res = st.executeQuery("select url,info from urlrule");
while (res.next()) {
ruleMap.put(res.getString(1), res.getString(2));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try{
if(res!=null){
res.close();
}
if(st!=null){
st.close();
}
if(conn!=null){
conn.close();
}
}catch(Exception e){
e.printStackTrace();
}
}
}
}
public class LogEnhanceOutputFormat<K, V> extends FileOutputFormat<K, V> {
@Override
public RecordWriter<K, V> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException {
FileSystem fs = FileSystem.get(new Configuration());
FSDataOutputStream enhancedOs = fs.create(new Path("/output/enhancedLog"));
FSDataOutputStream tocrawlOs = fs.create(new Path("/output/tocrawl"));
return new LogEnhanceRecordWriter<K, V>(enhancedOs,tocrawlOs);
}
public static class LogEnhanceRecordWriter<K, V> extends RecordWriter<K, V>{
private FSDataOutputStream enhancedOs =null;
private FSDataOutputStream tocrawlOs =null;
public LogEnhanceRecordWriter(FSDataOutputStream enhancedOs,FSDataOutputStream tocrawlOs){
this.enhancedOs = enhancedOs;
this.tocrawlOs = tocrawlOs;
}
@Override
public void write(K key, V value) throws IOException,
InterruptedException {
if(key.toString().contains("tocrawl")){
tocrawlOs.write(key.toString().getBytes());
}else{
enhancedOs.write(key.toString().getBytes());
}
}
@Override
public void close(TaskAttemptContext context) throws IOException,
InterruptedException {
if(enhancedOs != null){
enhancedOs.close();
}
if(tocrawlOs != null){
tocrawlOs.close();
}
}
}
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LogEnhanceRunner.class);
job.setMapperClass(LogEnhanceMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setOutputFormatClass(LogEnhanceOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));














 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









