






目录
es的相关概念:
倒排序原理:
倒排索引的基本原理是:
将 一个句子、文章进行分词 得到term,创建倒排序索引,以term为key,句子是否包含来确定评分,计算总分进行排序
具体如下:
1. 通过分析网页内容,提取网页中出现的所有词语,并记录每个词语出现在哪些网页中。
2. 将上述信息倒排过来,以词语为主要索引建立索引。每个词语下面都指向包含该词语的网页列表。
3. 当搜索词输入后,搜索引擎通过倒排索引找到包含每个搜索词的网页,然后计算它们的交集,得到最终结果。
例如:举个简单例子:
假设有3个网页,内容如下:
网页1:我喜欢打篮球和足球 文档1
网页2:我喜欢听音乐和看书 文档2
网页3:我喜欢游泳和跑步 文档3
将上述网页内容进行分词,得到的term如下:
我、喜欢、打、篮球、和、足球
我、喜欢、听、音乐、和、看、书
我、喜欢、游泳、和、跑步
构建标准索引如下:
我:网页1,网页2,网页3
喜欢:网页1,网页2,网页3
打:网页1
篮球:网页1
和:网页1,网页2,网页3
足球:网页1
听:网页2
音乐:网页2
看:网页2
书:网页2
游泳:网页3
跑步:网页3
倒排索引如下:
我:网页1,网页2,网页3
喜欢:网页1,网页2,网页3
打:网页1
篮球:网页1
足球:网页1
和:网页1,网页2,网页3
听:网页2
音乐:网页2
看:网页2
书:网页2
游泳:网页3
跑步:网页3
当用户输入查询“我喜欢音乐”,搜索引擎会在倒排索引中查找:
我:网页1,网页2,网页3
喜欢:网页1,网页2,网页3
音乐:网页2由于只有网页2同时包含我、喜欢和音乐这3个词,
所以,搜索引擎会将网页2返回作为查询结果。
以上:
整个列表 称之为 索引
句子(即 文档)被分词器分词后得到的是 term(term是搜索引擎理解网页和查询的基本单位)
当输入“我爱中国”,搜索引擎根据倒排索引,我→网页1,网页2;爱→网页1,网页2;中国→网页2。取交集,得到结果为网页2。所以,倒排索引通过倒转标准索引的结构,使用词语作为主要索引,指向包含每个词语的网页,加速了搜索引擎的查询检索过程,是分布式搜索引擎的基础
1、安装
1)下载:
官方下载地址: Download Elasticsearch | Elastic
我是去历史版本里下载的 7.10.1版本

2、安装/运行
下载后,解压缩,运行bin目录的:elasticsearch.bat即可运行

运行后看到如下界面:

然后访问: localhost:9200

说明:安装成功!
(坑:之前作者安装了 但是死活访问不了,后面可能是因为安装了node.js才解决,不确定解决的方法)
额外的配置:
4.打开 config/elasticsearch.yml ,末尾添加跨域的配置:
http.cors.enabled: true http.cors.allow-origin: "*"
修改后记得重新运行elasticsearch.bat
3)、安装可视化界面
1.安装GitHub elasticsearch-head插件: 下载地址:GitHub - mobz/elasticsearch-head: A web front end for an elastic search cluster

2、安装Node.js:下载地址 Download | Node.js

在window的cmd中执行:
node -v 查看nodejs是否安装成功
npm -v 查看npm是否安装成功

cd C:\Users\tzcon\Desktop\es\elasticsearch-head-master 进入head目录下
npm install -g grunt-cli //grunt是一个很方便的构建工具,可以进行打包压缩、测试、执行等等的工作 npm install

启动:可视化界面
grunt server这时候可以访问:
http://localhost:9100/使用:

参考:
(81条消息) Windows环境下安装ES全文搜素引擎与head插件_我的世界没光的博客-CSDN博客
2、java 使用ES
(请参考:扩展:(推荐的使用方式))
项目目录结构:

1、项目pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.sxw</groupId>
<artifactId>springboot-elasticsearch</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot-elasticsearch</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.10.1</elasticsearch.version>
</properties>
<dependencies>
<!--使用springboot的 component装配等注解-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--免得写set、get方法-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!--一会单元测试 java的操作es的函数测试-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--以下两个都是 es的内容-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.10.1</version>
</dependency>
<!--引入IOUtil-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.3</version>
</dependency>
<!--json字符串的转换-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.4</version>
</dependency>
<!--解决配置文件application.yml 的语法不识别-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2、配置文件中es的配置编写

spring:
rest:
host: 127.0.0.1
port: 9200
protocol: http
username:
password:3、创建es的配置类
①将配置文件的属性已对象的方式封装
package com.sxw.elasticsearch.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Data
@Component
@ConfigurationProperties(prefix = "spring.rest")
public class RestProperties {
private String host;
private int port;
private String protocol;
private String username;
private String password;
}②ES的配置类:
package com.sxw.elasticsearch.config;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.HttpHost;
import org.apache.http.impl.nio.reactor.IOReactorConfig;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Slf4j
@Configuration
@EnableConfigurationProperties(RestProperties.class)
public class RestClientConfig {
@Autowired
@Qualifier("restProperties")
private RestProperties properties;
@Bean
public RestHighLevelClient client() {
RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost(properties.getHost(), properties.getPort(), properties.getProtocol()));
restClientBuilder.setRequestConfigCallback(builder -> {
// 连接超时(默认为1秒)
builder.setConnectTimeout(5000);
// 套接字超时(默认为30秒)
builder.setSocketTimeout(60000);
return builder;
});
restClientBuilder.setHttpClientConfigCallback(builder -> {
// 线程数
builder.setDefaultIOReactorConfig(IOReactorConfig.custom().setIoThreadCount(1).build());
return builder;
});
return new RestHighLevelClient(restClientBuilder);
}
}
4、ES的工具类编写
摘抄自网络上:亲测可用
package com.sxw.elasticsearch.util;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.IOUtils;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.admin.indices.mapping.put.PutMappingRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.Strings;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.GeoDistanceQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.reindex.BulkByScrollResponse;
import org.elasticsearch.index.reindex.DeleteByQueryRequest;
import org.elasticsearch.index.reindex.UpdateByQueryRequest;
import org.elasticsearch.script.Script;
import org.elasticsearch.script.ScriptType;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.aggregations.AggregationBuilder;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.metrics.Cardinality;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.ClassPathResource;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
@Slf4j
@Component
@Data
public class RestClientService {
/**
* ES最大数据限制
*/
public static final int MAX_DATA_SIZE = 100;
@Autowired
private RestHighLevelClient restHighLevelClient;
/********************************************创建mapping********************************************/
/**
* 加载文件内容
*
* @param path
* @return
*/
public String loadText(String path) {
String textData = null;
try {
ClassPathResource classPathResource = new ClassPathResource(path);
try (InputStream inputStream = classPathResource.getInputStream()) {
textData = IOUtils.toString(inputStream, StandardCharsets.UTF_8);
}
} catch (Exception e) {
log.error("load mappping file error, cause {0}", e);
}
return textData;
}
/**
* 创建mapping映射
*
* @param index
* @param path
* @return
*/
public boolean createIndexMapping(String index, String path) {
PutMappingRequest request = new PutMappingRequest(index);
request.source(loadText(path), XContentType.JSON);
try {
AcknowledgedResponse response = restHighLevelClient.indices().putMapping(request, RequestOptions.DEFAULT);
return response.isAcknowledged();
} catch (IOException e) {
log.error("create index mapping error, cause {0}", e);
}
return false;
}
/********************************************索引(创建,删除,存在)********************************************/
/**
* 创建索引,若索引不存在且创建成功,返回true,若同名索引已存在,返回false
*
* @param index 索引名称
* @return
*/
public boolean createIndex(String index) {
//创建索引请求
CreateIndexRequest request = new CreateIndexRequest(index);
//执行创建请求IndicesClient,请求后获得响应
try {
CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
return response.isAcknowledged();
} catch (Exception e) {
log.error("create index error, cause {0}", e);
}
return false;
}
/**
* 删除索引,删除成功返回true,删除失败返回false
*
* @param index 索引名称
* @return true/false
*/
public boolean deleteIndex(String index) {
if (!existsIndex(index)) {
log.debug("deleteIndex error, cause: {} not exists", index);
return false;
}
DeleteIndexRequest request = new DeleteIndexRequest(index);
try {
AcknowledgedResponse response =restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
return response.isAcknowledged();
} catch (Exception e) {
log.error("delete index error, cause {0}", e);
}
return false;
}
/**
* 判断索引是否存在,若存在返回true,若不存在或出现问题返回false
*
* @param index 索引名称
* @return
*/
public boolean existsIndex(String index) {
GetIndexRequest request = new GetIndexRequest(index);
try {
restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
} catch (Exception e) {
log.error("existsIndex error, cause {0}", e);
}
return false;
}
/********************************************文档(创建,更新,删除,存在)********************************************/
/**
* 新增/修改文档信息
*
* @param index 索引名称
* @param id 文档id
* @param data 数据
* @return
*/
public boolean createDocument(String index, String id, JSONObject data) {
try {
IndexRequest request = new IndexRequest(index);
if (id != null && id.length() > 0) {
request.id(id);
}
request.source(JSON.toJSONString(data), XContentType.JSON);
IndexResponse response =restHighLevelClient.index(request, RequestOptions.DEFAULT);
String status = response.status().toString();
if ("CREATED".equals(status) || "OK".equals(status)) {
return true;
}
} catch (Exception e) {
log.error("put data error, cause {0}", e);
}
return false;
}
/**
* 批量插入文档,id是随机的
*
* @param index 索引名称
* @param datas 数据的集合
* @return
*/
public boolean createDocuments(String index, List<JSONObject> datas) {
try {
BulkRequest bulkRequest = new BulkRequest();
if (!CollectionUtils.isEmpty(datas)) {
for (Object obj : datas) {
bulkRequest.add(new IndexRequest(index).source(JSON.toJSONString(obj), XContentType.JSON));
}
BulkResponse response =restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
log.debug("putDataBulk:{}", response);
if (!response.hasFailures()) {
return true;
}
}
} catch (Exception e) {
log.error("put data bulk error, cause {0}", e);
}
return false;
}
/**
* 更新文档
*
* @param index 索引名称
* @param id 文档id
* @param data 数据
* @return
*/
public boolean updateDocumentById(String index, String id, JSONObject data) {
try {
UpdateRequest request = new UpdateRequest(index, id);
request.doc(JSON.toJSONString(data), XContentType.JSON);
UpdateResponse response =restHighLevelClient.update(request, RequestOptions.DEFAULT);
String status = response.status().toString();
if ("OK".equals(status)) {
return true;
}
} catch (Exception e) {
log.error("update data error, cause {0}", e);
}
return false;
}
/**
* 删除文档
*
* @param index 索引名称
* @param id 文档id
* @return
*/
public boolean deleteDocument(String index, String id) {
try {
DeleteRequest request = new DeleteRequest(index, id);
DeleteResponse response =restHighLevelClient.delete(request, RequestOptions.DEFAULT);
String status = response.status().toString();
if ("OK".equals(status)) {
return true;
}
} catch (Exception e) {
log.error("delete data error, cause {0}", e);
}
return false;
}
/**
* 批量删除文档
*
* @param index 索引名称
* @param ids 文档id的集合
* @return
*/
public boolean deleteDataBulk(String index, List<String> ids) {
BulkRequest request = new BulkRequest();
for (String id : ids) {
request.add(new DeleteRequest().index(index).id(id));
}
try {
BulkResponse response =restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
return !response.hasFailures();
} catch (Exception e) {
log.error("delete data bulk error, cause {0}", e);
}
return false;
}
/**
* 条件删除
*
* @param index 索引名称
* @param queryBuilder 删除条件
* @return
*/
public boolean deleteByQuery(String index, QueryBuilder queryBuilder) {
DeleteByQueryRequest request = new DeleteByQueryRequest(index);
request.setRefresh(true);
request.setQuery(queryBuilder);
try {
BulkByScrollResponse response =restHighLevelClient.deleteByQuery(request, RequestOptions.DEFAULT);
return response.getStatus().getDeleted() > 0;
} catch (IOException e) {
log.error("delete by query error, cause {0}", e);
}
return false;
}
/**
* 条件更新
*
* @param index 索引名称
* @param queryBuilder 更新条件
* @return
*/
public boolean updateByQuery(String index, QueryBuilder queryBuilder, String script) {
UpdateByQueryRequest request = new UpdateByQueryRequest(index);
request.setConflicts("proceed");
request.setQuery(queryBuilder);
request.setScript(new Script(ScriptType.INLINE, "painless", script, Collections.emptyMap()));
try {
BulkByScrollResponse response =restHighLevelClient.updateByQuery(request, RequestOptions.DEFAULT);
return response.getStatus().getUpdated() > 0;
} catch (IOException e) {
log.error("update by query error, cause {0}", e);
}
return false;
}
/**
* 判断文档是否存在
*
* @param index 索引名称
* @param id 文档id
* @return
*/
public boolean existsDocument(String index, String id) {
GetRequest request = new GetRequest(index, id);
try {
GetResponse response =restHighLevelClient.get(request, RequestOptions.DEFAULT);
return response.isExists();
} catch (Exception e) {
log.error("existsData error, cause {0}", e);
}
return false;
}
/********************************************文档(查询)********************************************/
/**
* 条件查询
*
* @param index 索引名称
* @param queryBuilder 查询条件
* @param aggregationBuilder 聚合条件
* @return
*/
public SearchResponse query(String index, QueryBuilder queryBuilder, AggregationBuilder aggregationBuilder) {
SearchRequest searchRequest = new SearchRequest(index);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.trackTotalHits(true);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
// 查询条件
if (queryBuilder != null) {
searchSourceBuilder.query(queryBuilder);
}
// 聚合条件
if (aggregationBuilder != null) {
searchSourceBuilder.aggregation(aggregationBuilder);
}
searchRequest.source(searchSourceBuilder);
try {
restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("select distinct count error cause: {0}", e);
}
return null;
}
/**
* 查询数量
*
* @param index 索引名称
* @param queryBuilder 查询条件
* @return
*/
public Long selectCount(String index, QueryBuilder queryBuilder) {
SearchResponse response = query(index, queryBuilder, null);
if (response == null) {
return 0L;
}
return response.getHits().getTotalHits().value;
}
/**
* 聚合查询-返回统计数值
*
* @param index 索引名称
* @param aggName 聚合名称
* @param queryBuilder 查询条件
* @param aggregationBuilder 聚合条件
* @return 统计值
*/
public Long selectCount(String index, String aggName, QueryBuilder queryBuilder, AggregationBuilder aggregationBuilder) {
SearchResponse response = query(index, queryBuilder, aggregationBuilder);
if (response == null) {
return 0L;
}
Aggregations aggregations = response.getAggregations();
// 根据聚合名称获取统计值
Cardinality cardinality = aggregations.get(aggName);
return cardinality.getValue();
}
/**
* 批量新增
*
* @paramrestHighLevelClient
* @param indexName
* @param list
*/
public static void multiAdd(RestHighLevelClient restHighLevelClient, String indexName, List<Object> list) {
BulkRequest request = new BulkRequest();
request.timeout("10s");
//批量请求,批量更新,删除都差不多!!!不设置id就会自动生成随机id,演示为批量插入
for (int i = 0; i < list.size(); i++) {
request.add(new IndexRequest(indexName)
.id("" + (i + 1))
.source(JSON.toJSONString(list.get(i)), XContentType.JSON));
}
try {
BulkResponse response =restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
log.info("=====> multiAdd():" + JSONObject.toJSONString(response));
} catch (IOException e) {
log.error("=====> multiAdd()出错:" + e.getMessage());
}
}
/**
* 通过ID获取数据
* @param index 索引,类似数据库
* @param id 数据ID
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @return
*/
public Map<String,Object> searchDataById(String index, String id, String fields) throws IOException {
GetRequest request = new GetRequest();
request.index(index);
request.id(id);
if (!StringUtils.isEmpty(fields)){
//只查询特定字段。如果需要查询所有字段则不设置该项。
request.fetchSourceContext(new FetchSourceContext(true,fields.split(","), Strings.EMPTY_ARRAY));
}
GetResponse response =restHighLevelClient.get(request, RequestOptions.DEFAULT);
return response.getSource();
}
/**
* 根据经纬度查询范围查找location 经纬度字段,distance 距离中心范围KM,lat lon 圆心经纬度
* @param index
* @param longitude
* @param latitude
* @param distance
* @return
*/
public SearchResponse geoDistanceQuery(String index,Float longitude, Float latitude,String distance) throws IOException {
if(longitude == null || latitude == null){
return null;
}
//拼接条件
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// QueryBuilder isdeleteBuilder = QueryBuilders.termQuery("isdelete", false);
// 以某点为中心,搜索指定范围
GeoDistanceQueryBuilder distanceQueryBuilder = new GeoDistanceQueryBuilder("location");
distanceQueryBuilder.point(latitude, longitude);
//查询单位:km
distanceQueryBuilder.distance(distance, DistanceUnit.KILOMETERS);
boolQueryBuilder.filter(distanceQueryBuilder);
// boolQueryBuilder.must(isdeleteBuilder);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(boolQueryBuilder);
SearchRequest searchRequest = new SearchRequest(index);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse =restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
return searchResponse;
}
/**
* 获取低水平客户端
* @return
*/
public RestClient getLowLevelClient() {
return restHighLevelClient.getLowLevelClient();
}
/**
* 高亮结果集 特殊处理
* map转对象 JSONObject.parseObject(JSONObject.toJSONString(map), Content.class)
* @param searchResponse
* @param highlightField
*/
private List<Map<String, Object>> setSearchResponse(SearchResponse searchResponse, String highlightField) {
//解析结果
ArrayList<Map<String,Object>> list = new ArrayList<>();
for (SearchHit hit : searchResponse.getHits().getHits()) {
Map<String, HighlightField> high = hit.getHighlightFields();
HighlightField title = high.get(highlightField);
Map<String, Object> sourceAsMap = hit.getSourceAsMap();//原来的结果
//解析高亮字段,将原来的字段换为高亮字段
if (title!=null){
Text[] texts = title.fragments();
String nTitle="";
for (Text text : texts) {
nTitle+=text;
}
//替换
sourceAsMap.put(highlightField,nTitle);
}
list.add(sourceAsMap);
}
return list;
}
/**
* 查询并分页
* @param index 索引名称
* @param query 查询条件
* @param size 文档大小限制
* @param fields 需要显示的字段,逗号分隔(缺省为全部字段)
* @param sortField 排序字段
* @param highlightField 高亮字段
* @return
*/
public List<Map<String, Object>> searchListData(String index,
SearchSourceBuilder query,
Integer from,
Integer size,
String fields,
String sortField,
String highlightField) throws IOException {
SearchRequest request = new SearchRequest(index);
SearchSourceBuilder builder = query;
if (!StringUtils.isEmpty(fields)){
//只查询特定字段。如果需要查询所有字段则不设置该项。
builder.fetchSource(new FetchSourceContext(true,fields.split(","), Strings.EMPTY_ARRAY));
}
from = from <= 0 ? 0 : from*size;
//设置确定结果要从哪个索引开始搜索的from选项,默认为0
builder.from(from);
builder.size(size);
if (!StringUtils.isEmpty(sortField)){
//排序字段,注意如果proposal_no是text类型会默认带有keyword性质,需要拼接.keyword
builder.sort(sortField+".keyword", SortOrder.ASC);
}
//高亮
HighlightBuilder highlight = new HighlightBuilder();
highlight.field(highlightField);
//关闭多个高亮
highlight.requireFieldMatch(false);
highlight.preTags("<span style='color:red'>");
highlight.postTags("</span>");
builder.highlighter(highlight);
//不返回源数据。只有条数之类的数据。
// builder.fetchSource(false);
request.source(builder);
SearchResponse response =restHighLevelClient.search(request, RequestOptions.DEFAULT);
log.info("result:"+response.getHits().getTotalHits());
System.out.println(JSON.toJSONString(response.getHits()));
if (response.status().getStatus() == 200) {
// 解析对象
return setSearchResponse(response, highlightField);
}
return null;
}
}
5、ES的工具类使用:
package com.sxw.elasticsearch.test;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.sxw.elasticsearch.MyBaseTest;
import com.sxw.elasticsearch.model.Product;
import com.sxw.elasticsearch.util.RestClientService;
import lombok.extern.slf4j.Slf4j;
import org.apache.lucene.search.join.ScoreMode;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import java.io.IOException;
import java.util.*;
/**
* @author wangjianwei
* * @date 2022/4/19
*/
@Slf4j
public class eeee extends MyBaseTest {
@Autowired
RestHighLevelClient client;
@Test
public void aa() throws IOException {
// Create the "products" index
IndexRequest request = new IndexRequest("posts");
request.id("1");
String jsonString = "{" +
"\"user\":\"kimchy\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"trying out Elasticsearch\"" +
"}";
request.source(jsonString, XContentType.JSON);
System.out.println();
}
@Autowired
RestClientService restClientService;
@Test
public void createIndex() {
boolean blog2 = restClientService.createIndex("blog3");
System.out.println();
}
//如果没有blog1索引,则会自动创建
@Test
public void createDocument() {
JSONObject data= JSON.parseObject("{\"age\":\"10\",\"name\":\"李四\",\"address\":{\"area1\":\"萧山区\",\"area2\":\"杭州市\"} }");
boolean blog1 = restClientService.createDocument("blog1","1",data);
System.out.println(blog1);
}
//批量插入
@Test
public void createDocuments() {
JSONObject data1= JSON.parseObject("{\"age\":\"10\",\"name\":\"李四11\",\"address\":{\"area1\":\"萧山区11\",\"area2\":\"杭州市\"} }");
JSONObject data2= JSON.parseObject("{\"age\":\"10\",\"name\":\"李四22\",\"address\":{\"area1\":\"萧山区22\",\"area2\":\"杭州市\"} }");
ArrayList<JSONObject> arrayList = new ArrayList<>();
arrayList.add(data1);
arrayList.add(data2);
boolean blog1 = restClientService.createDocuments("blog1",arrayList);
System.out.println(blog1);
}
@Test
public void existsIndex() {
boolean blog2 = restClientService.existsIndex("blog3");
System.out.println(blog2);
}
@Test
public void deleteIndex() {
boolean flag = restClientService.deleteIndex("blog3");
System.out.println(flag);
}
@Test
public void deleteDocumentById() {
boolean flag = restClientService.deleteDocument("blog1","1");
System.out.println(flag);
}
@Test
public void updateDocument() {
JSONObject data= JSON.parseObject("{\"age\":\"99\",\"name\":\"李四7\",\"address\":{\"area1\":\"萧山区\",\"area2\":\"杭州市1\"} }");
boolean flag = restClientService.updateDocumentById("blog1","1",data);
System.out.println(flag);
}
@Test
public void searchDataById() throws IOException {
Map<String, Object> stringObjectMap = restClientService.searchDataById("blog1", "1", "");
Map<String, Object> stringObjectMap1 = restClientService.searchDataById("blog1", "1", "address");
System.out.println(stringObjectMap);
}
//复合分页的查询
@Test
public void searchListData1() throws IOException {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
RestHighLevelClient restHighLevelClient = restClientService.getRestHighLevelClient();
restHighLevelClient.search()
List<Map<String, Object>> maps = restClientService.searchListData("patpat-products", searchSourceBuilder, 0, 2, "", "", "");
String datas = JSON.toJSONString(maps);
System.out.println(datas);
}
}
扩展:(推荐的使用方式)
事实上,springboot的自动配置已经有了elasticsearch的配置,我们只需要告诉springboot的es地址、用户、密码、端口就可以了如:

配置好这一行后,spring容器中自动给我们注入了 restHighLevelClient 的对象,如果我们想要像其他数据库的常规用途:XXXTemplate。这时Maven引入:
restHighLevelClient 的对象,如果我们想要像其他数据库的常规用途:XXXTemplate。这时Maven引入:
<!--如果想要使用ElasticsearchRestTemplate 那就引入此依赖没否则-->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>4.0.9.RELEASE</version>
<scope>compile</scope>
<exclusions>
<exclusion>
<artifactId>transport</artifactId>
<groupId>org.elasticsearch.client</groupId>
</exclusion>
</exclusions>
</dependency>源码理解:

使用:
@Autowired
// ElasticsearchRestTemplate 类中有 RestHighLevelClient作为属性,我们配置 RestClientConfig 后 会在spring容器中注入了 该属性,
ElasticsearchRestTemplate elasticsearchRestTemplate;
//复合分页的查询
@Test
public void searchListData() throws IOException {
//模拟参数
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
//该条件构造器 各种条件的拼接 类似于mybatis-plus 中的 queryWrapper
NativeSearchQueryBuilder builder = new NativeSearchQueryBuilder();
builder.withPageable(PageRequest.of(0, Integer.parseInt(String.valueOf(1000))));
builder.withQuery(QueryBuilders.boolQuery()
.must(QueryBuilders.termsQuery("product_id", list))
.must(QueryBuilders.nestedQuery(
"sale_status",
QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("sale_status.store_id", 30000))
.must(QueryBuilders.termQuery("sale_status.status", 11)),
ScoreMode.None)));
NativeSearchQuery build = builder.build();
//上面条件器构造好了, 现在要去查哪个 索引呢? 其实spring注解有简便的方法,在返回的解析类中进行标记,如下:语句
SearchHits<Product> it = elasticsearchRestTemplate.search(build, Product.class);
System.out.println("");
// //使用elasticsearchRestTemplate查询索引aa的结构
Map<String, Object> index_name = elasticsearchRestTemplate.indexOps(IndexCoordinates.of("aa")).getMapping();
}其中: Product为:
debug结果: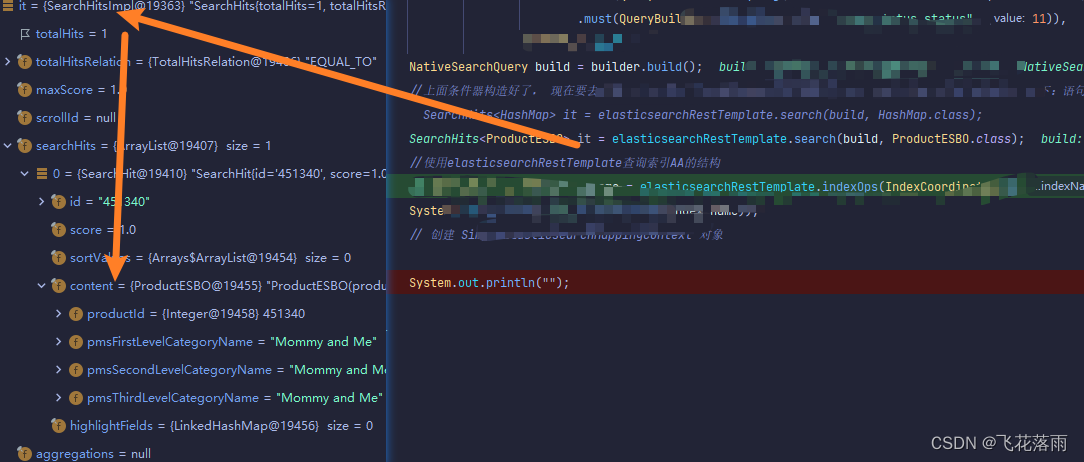
XXQueryBuilder的“翻译”:

es的查询技巧 类比sql:
sql转es的在线工具:
在线工具:SQL转ElasticSearch DSL - 潇洒哥和黑大帅
好文参考:
(下文中可能由于版本不同 部分语法不同,但基本变化不大)
2、bool 组合多个 filter 搜索 | MRCODE-BOOK
扩展:一些语句和区分
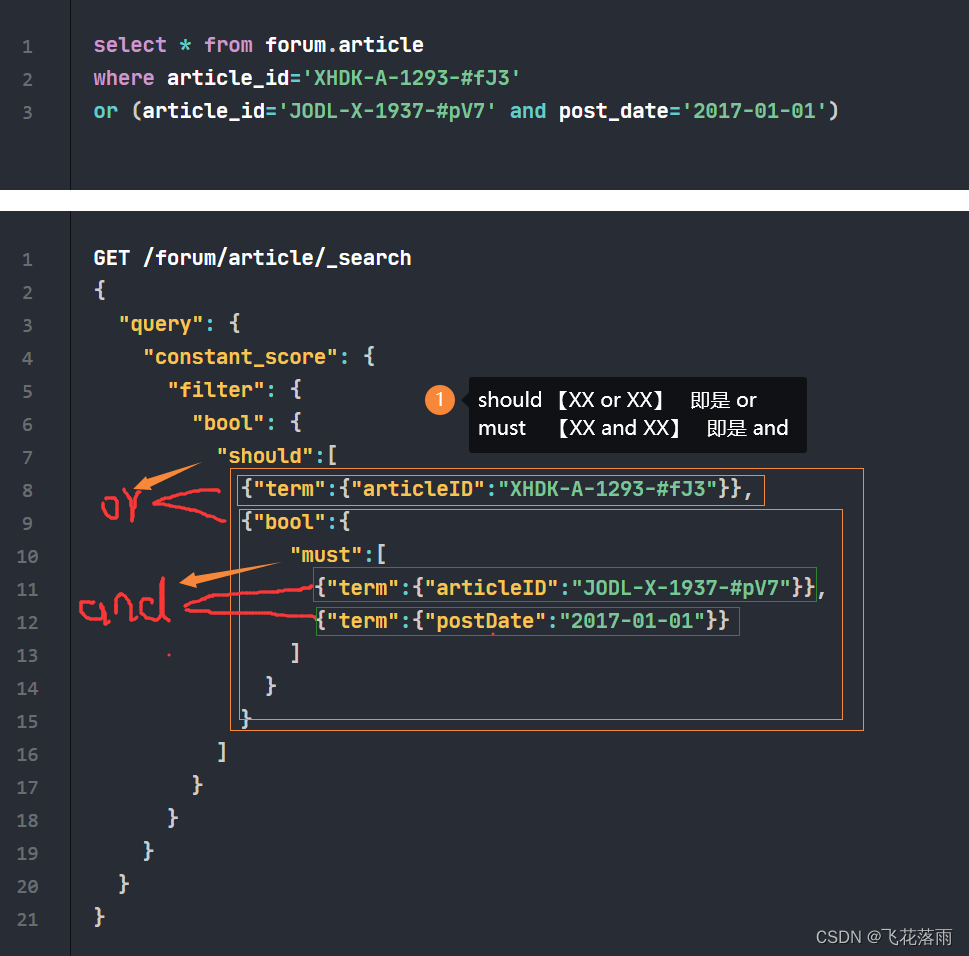
- 外层的
bool查询包含了几个should查询,这意味着满足任何一个内层的bool查询即可匹配。bool |__should |__should |__should 3个should只要有一个匹配到就算 - 如果
bool查询同时包含must或filter子句和should子句,那么即使should子句的条件不被满足,文档也有可能被查出来,只要它们满足must和filter中的条件。在这种情况下,should子句的作用是提高满足其条件的文档的相关性得分(_score),而不是作为硬性的匹配条件bool |__should (此刻should不是必须匹配了) |__must |__must |__filter - term和
filter的区别特性 term查询filter子句目的 用于精确匹配字段的值 用于过滤文档,确保它们符合某些标准 评分 计算并使用相关性得分(_score)进行排序 不计算相关性得分,不影响排序 性能 相对较慢,因为需要计算得分 相对较快,因为不计算得分且结果可以被缓存 缓存 通常不缓存查询结果 可以缓存结果,提高重复查询的性能 使用场景 当你需要根据精确值进行搜索且关心文档的排名时使用 当你只需要过滤文档且不关心文档的排名时使用 示例 {
"term": {
"status": "active"
}
}{
"bool": {
"filter": {
"term": {
"status": "active"
}
}
}
}














 908
908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









