







目录
文档含项目摘要、前言、技术介绍、可行性分析、流程图、结构图、ER属性图、数据库表结构信息、功能介绍、测试致谢等约1万字等
数据库表有注释,可以导出数据字典及更新数据库时间,欢迎交流学习
课题背景
随着高校教育改革的不断深入和科技水平的快速发展,实验室在高等教育和科研工作中的地位日益显著。一个高效、有序的实验室管理系统对于提升实验教学质量、保障科研工作顺利进行具有重要意义。然而,许多高校的实验室管理仍停留在传统的人工管理阶段,存在效率低、资源利用率不高、安全风险难以控制等问题。
目的
基于Python的实验室管理系统旨在:
1. 提高实验室管理效率,降低管理成本。
2. 实现实验室资源的优化配置,提高资源利用率。
3. 加强实验室安全管理,降低安全事故风险。
4. 促进实验室教学与科研工作的信息化、智能化。
意义
1. 提升管理水平:系统可以实时监控实验室的运行状态,及时调整资源分配,提高管理效率。
2. 优化资源配置:通过系统进行设备使用预约、实验任务分配等,实现资源的合理配置。
3. 保障安全:系统可以对实验室安全进行监控,及时处理安全隐患,降低事故发生概率。
4. 促进教学科研:方便教师和学生进行实验预习、资料查询,提高教学质量和科研效率。
用户角色
1. 管理员:负责整个系统的维护、用户管理、数据备份与恢复等。
2. 老师:可以发布实验任务、查看实验课程表、管理自己负责的实验室等。
3. 学生:可以查看实验课程表、实验规章制度,提交实验报告,预约实验设备等。
功能模块
1. 规章制度:发布、查看实验室规章制度和安全管理条例。
2. 课程表:管理实验课程安排,支持查询、打印等功能。
3. 实验室介绍:展示实验室的基本信息、研究方向、成果等。
4. 设备介绍:提供实验室设备的详细信息,包括设备状态、使用说明等。
5. 实验任务:发布、管理实验任务,学生可以提交实验报告,教师可以批改作业。
6. 用户管理:管理员可以对用户进行增删改查操作,保障系统安全。
7. 预约系统:学生和教师可以根据设备使用情况预约实验时间。
综上所述,基于Python的实验室管理系统具有重要的现实意义和应用价值,有利于推进教育信息化进程,提高高等教育的质量和效益。
一、整体目录:
文档含项目摘要、前言、技术介绍、可行性分析、流程图、结构图、ER属性图、数据库表结构信息、功能介绍、测试致谢等约1万字等

二、运行截图













三、代码部分(示范):
商品推荐、内容推荐算法
/**
* 前端智能排序
*/
@IgnoreAuth
@RequestMapping("/autoSort")
public R autoSort(@RequestParam Map<String, Object> params,NaichashangpinEntity naichashangpin, HttpServletRequest request,String pre){
EntityWrapper<NaichashangpinEntity> ew = new EntityWrapper<NaichashangpinEntity>();
Map<String, Object> newMap = new HashMap<String, Object>();
Map<String, Object> param = new HashMap<String, Object>();
Iterator<Map.Entry<String, Object>> it = param.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, Object> entry = it.next();
String key = entry.getKey();
String newKey = entry.getKey();
if (pre.endsWith(".")) {
newMap.put(pre + newKey, entry.getValue());
} else if (StringUtils.isEmpty(pre)) {
newMap.put(newKey, entry.getValue());
} else {
newMap.put(pre + "." + newKey, entry.getValue());
}
}
params.put("sort", "clicknum");
params.put("order", "desc");
PageUtils page = naichashangpinService.queryPage(params, MPUtil.sort(MPUtil.between(MPUtil.likeOrEq(ew, naichashangpin), params), params));
return R.ok().put("data", page);
}
/**
* 协同算法(按用户购买推荐)
*/
@RequestMapping("/autoSort2")
public R autoSort2(@RequestParam Map<String, Object> params,NaichashangpinEntity naichashangpin, HttpServletRequest request){
String userId = request.getSession().getAttribute("userId").toString();
String goodtypeColumn = "naichafenlei";
List<OrdersEntity> orders = ordersService.selectList(new EntityWrapper<OrdersEntity>().eq("userid", userId).eq("tablename", "naichashangpin").orderBy("addtime", false));
List<String> goodtypes = new ArrayList<String>();
Integer limit = params.get("limit")==null?10:Integer.parseInt(params.get("limit").toString());
List<NaichashangpinEntity> naichashangpinList = new ArrayList<NaichashangpinEntity>();
//去重
List<OrdersEntity> ordersDist = new ArrayList<OrdersEntity>();
for(OrdersEntity o1 : orders) {
boolean addFlag = true;
for(OrdersEntity o2 : ordersDist) {
if(o1.getGoodid()==o2.getGoodid() || o1.getGoodtype().equals(o2.getGoodtype())) {
addFlag = false;
break;
}
}
if(addFlag) ordersDist.add(o1);
}
if(ordersDist!=null && ordersDist.size()>0) {
for(OrdersEntity o : ordersDist) {
naichashangpinList.addAll(naichashangpinService.selectList(new EntityWrapper<NaichashangpinEntity>().eq(goodtypeColumn, o.getGoodtype())));
}
}
EntityWrapper<NaichashangpinEntity> ew = new EntityWrapper<NaichashangpinEntity>();
params.put("sort", "id");
params.put("order", "desc");
PageUtils page = naichashangpinService.queryPage(params, MPUtil.sort(MPUtil.between(MPUtil.likeOrEq(ew, naichashangpin), params), params));
List<NaichashangpinEntity> pageList = (List<NaichashangpinEntity>)page.getList();
if(naichashangpinList.size()<limit) {
int toAddNum = (limit-naichashangpinList.size())<=pageList.size()?(limit-naichashangpinList.size()):pageList.size();
for(NaichashangpinEntity o1 : pageList) {
boolean addFlag = true;
for(NaichashangpinEntity o2 : naichashangpinList) {
if(o1.getId().intValue()==o2.getId().intValue()) {
addFlag = false;
break;
}
}
if(addFlag) {
naichashangpinList.add(o1);
if(--toAddNum==0) break;
}
}
}
page.setList(naichashangpinList);
return R.ok().put("data", page);
}
数据库配置连接
validationQuery=SELECT 1
jdbc_url=jdbc:mysql://127.0.0.1:3306/ssmt375d?useUnicode=true&characterEncoding=UTF-8&tinyInt1isBit=false
jdbc_username=aicood
jdbc_password=aicood
#jdbc_url=jdbc:sqlserver://127.0.0.1:1433;DatabaseName=ssmt375d
#jdbc_username=sa
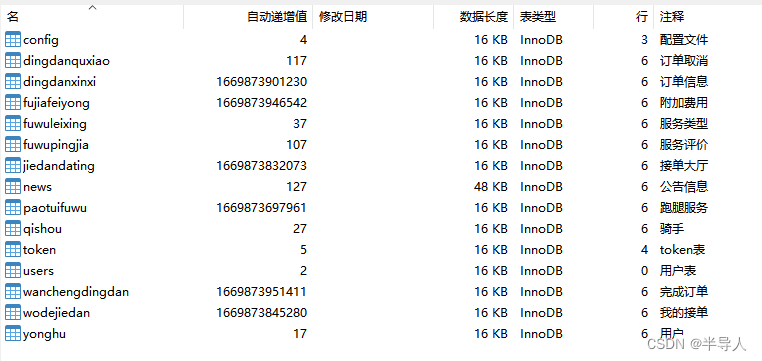
#jdbc_password=123456四、数据库表(示范):
数据库表有注释,可以导出数据字典及更新数据库时间,欢迎交流学习
五、项目技术栈:
1.前端:
a.小程序框架:Uniapp(小程序专用)
Uni-app 是一个使用 Vue.js 开发所有前端应用的框架,目标是通过一套代码可以发布到 iOS、Android、H5、以及各种小程序 (微信/支付宝/百度/头条/QQ/京东) 等多个平台。
b.前端框架:Vue.js
Vue.js 是一个用于构建用户界面的渐进式框架,易于上手,且具有良好的性能。它通过组合不同的功能模块,可以快速构建复杂的单页面应用。
c.页面库:Element UI
Element UI 是一个基于 Vue.js 的组件库,提供了丰富的组件,可以帮助开发者快速构建美观且易于维护的前端界面。
2.后端:
a.后端框架:Django
Django 是一个高性能、安全且易于扩展的 Python Web 框架。它提供了丰富的功能,如认证、权限控制、ORM(对象关系映射)等,便于开发者构建高质量的后端服务。
b.数据库:MySQL
MySQL 是一款流行的关系型数据库,具有高性能、易使用、成本低等优点。在这个推荐阅读系统中,可以使用 MySQL 存储用户信息、书籍信息和用户与书籍之间的关系等数据。
3.开发工具:
a.代码编辑器:PyCharm、Visual Studio Code
PyCharm 和 Visual Studio Code 都是优秀的代码编辑器,支持多种编程语言,具有良好的代码编辑和调试功能,大幅提升开发效率。
b.数据库管理工具:Navicat
Navicat 是一款强大的数据库管理工具,支持多种数据库,如 MySQL、PostgreSQL 等。它可以方便地创建、管理和查询数据库,提高数据库管理效率。
c.Python 版本:3.7
本项目采用 Python 3.7 版本进行开发。Python 3.7 具有性能提升、更好的兼容性和安全性等优点,适合用于 Web 开发。
d.HBuilderX: 是一款国产的跨平台集成开发环境(IDE),HBuilderX 支持多种编程语言和开发框架,如 HTML5、CSS3、JavaScript、PHP、Java、C++ 等,可以用于开发 Web 应用、移动应用、微信小程序等。
e.微信开发者工具:是微信官方提供的一款针对微信小程序的集成开发环境(IDE)。微信开发者工具支持小程序和公众号的开发、调试和预览,提供了丰富的功能,如代码编辑、调试、预览、代码模板等。
通过以上技术路线,可以构建一个高效、稳定且易于维护的基于 Django 的个性化推荐阅读系统。在实际开发过程中,根据需求和项目规模,可以进一步优化技术选型,以满足项目的需求。
六、项目调试学习(点击查看)
七、更多项目展示
大屏可视化项目
基于django的财经新闻文本挖掘分析与可视化应用
基于Python的沧州地区空气质量数据分析及可视化
django基于大数据的房价数据分析
基丁Python的个性化电影推荐系统的设计与实现
django基于Python的热门旅游景点数据分析系统的设计与实现
django基于协同过滤的图书推荐系统的设计与实现
django基于Spark的国漫推荐系统的设计与实现
django基于大数据的学习资源推送系统的设计与实现
django基于协同过滤算法的小说推荐系统
python基于爬虫的个性化书籍推荐系统
python基于Flask的电影论坛
django基于python的影片数据爬取与数据分析
django基丁Python可视化的学习系统的设计与实现
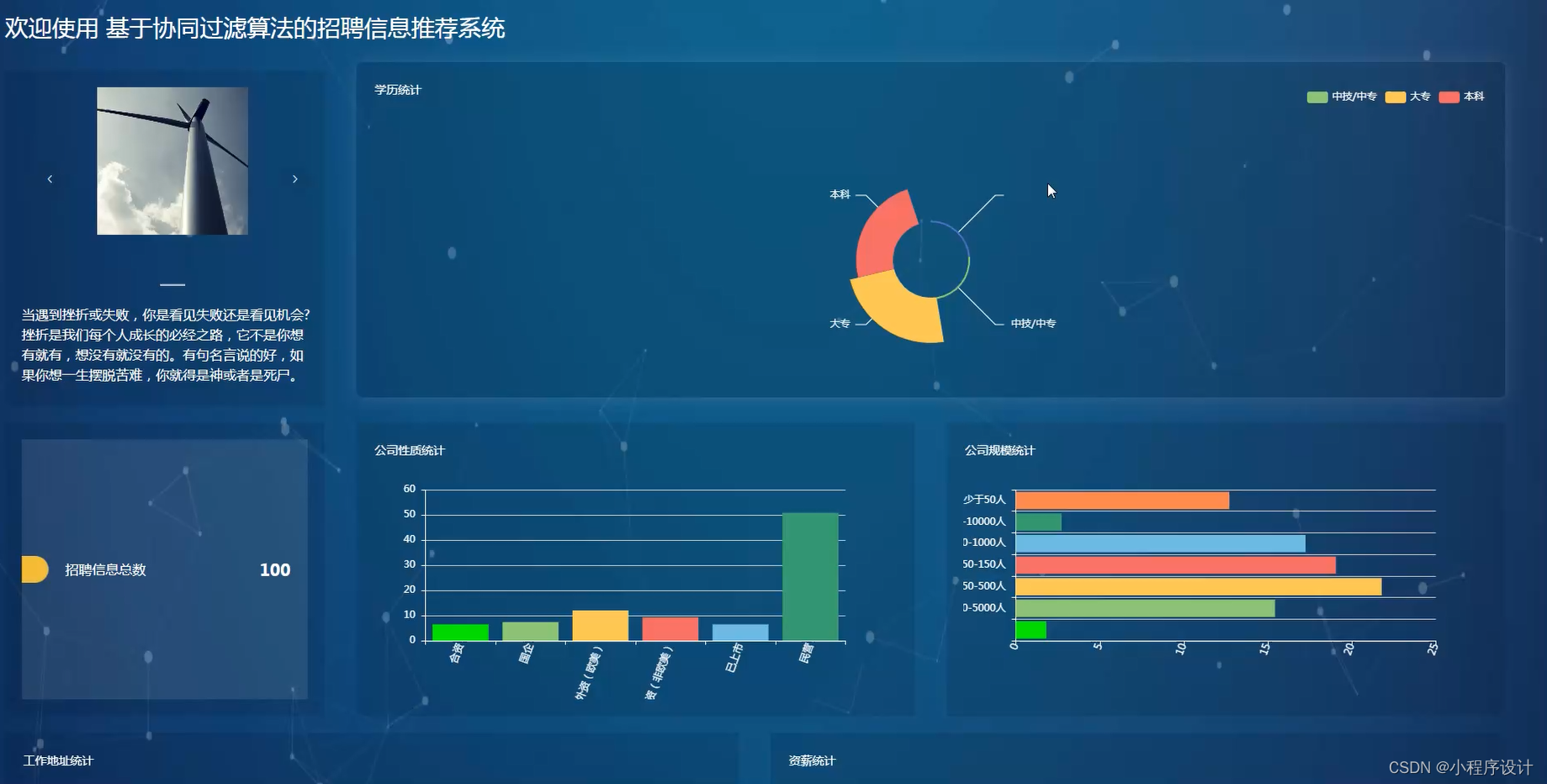
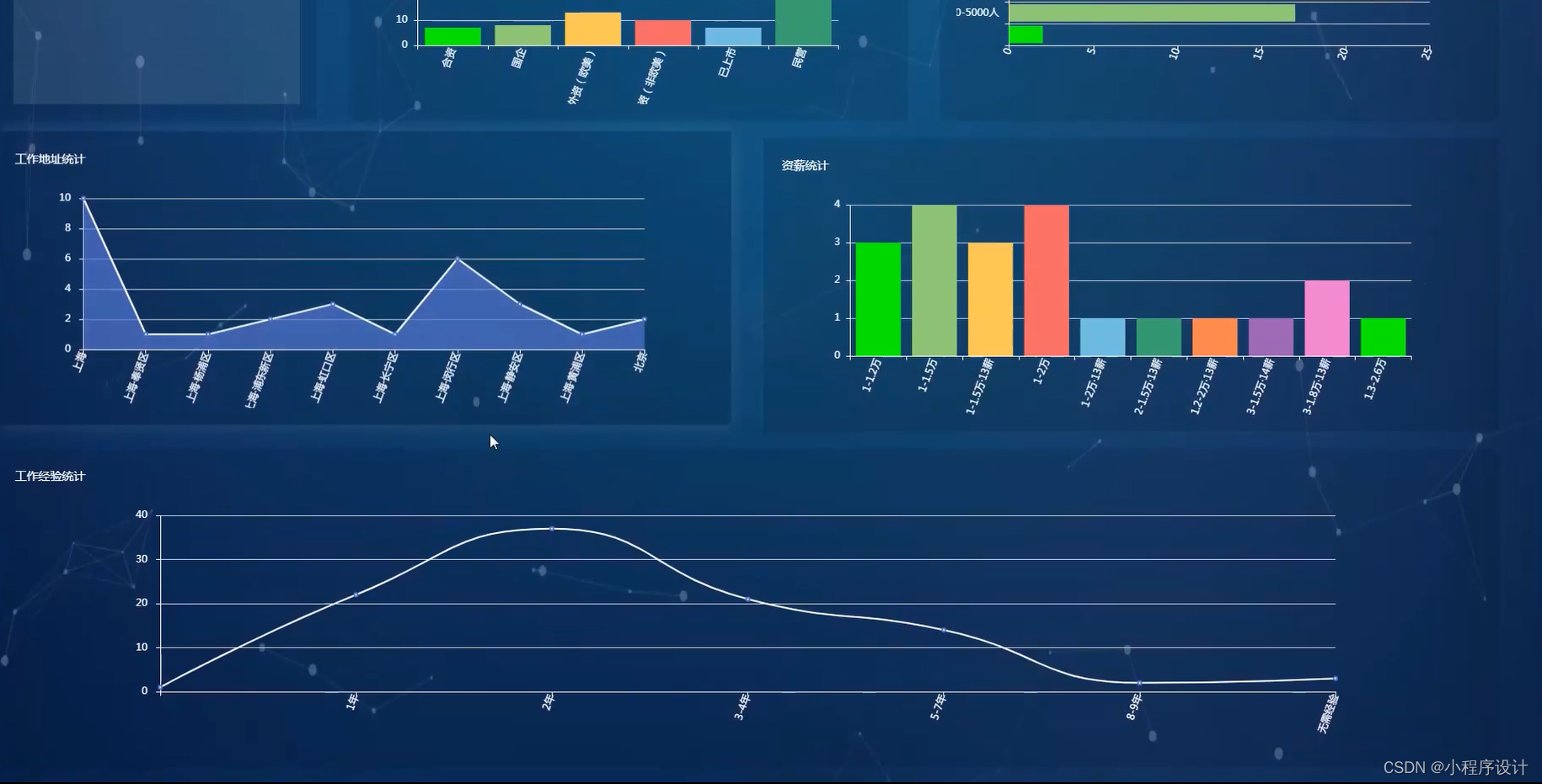
django基于协同过滤算法的招聘信息推荐系统
时尚前沿渐变色ui
首页动态显示图


前后台配色统一美观
人性化的后台功能
















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









