







graphx 实现
- 参数调优很简单。LPA 使用最大迭代参数运行,并且使用默认值 5 就可以得到一些好的结果。Raghavan 和她的合作者在几个有标签的网络上测试了 LPA。他们发现至少 95% 的节点在 5 次迭代中被正确分类。
- 运行时间内近线性。LPA 的每次迭代都是 O (m),边的数量是线性的。与 以前的一些社区检测解决方案中的O (n log n) 或 O (m+n) 相比,整个步骤序列的运行时间几乎是线性的。
- 可解释性。当有人问起时,您可以解释为什么将节点分组到某个社区中。
标签传播算法(Label Propagation)及Python实现
https://blog.csdn.net/zouxy09/article/details/49105265
标签传播(Label Propagation)算法详解
http://www.go60.top/view/89.html
(1)为每个节点随机的指定一个自己特有的标签;
(2)逐轮刷新所有节点的标签,直到所有节点的标签不再发生变化为止。对于每一轮刷新,节点标签的刷新规则如下:
对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋值给当前节点。当个数最多的标签不唯一时,随机选择一个标签赋值给当前节点(选择标签值最大的那个)。
算法的每个迭代过程中节点的标签更新是基于它的邻接节点的标签
同步更新是指,节点x在t时刻的更新是基于邻接节点在t-1时刻的标签。异步更新是指,节点x在t时刻更新时,其部分邻接节点是t时刻更新的标签,还有部分的邻接节点是t-1时刻更新的标签。LPA算法在标签传播过程中采用的是同步更新,研究者们发现同步更新应用在二分结构网络中,容易出现标签震荡的现象。因此,之后的研究者大多采用异步更新策略来避免这种现象的出现
在网络中,每一个样本点只能属于一个社区,这样的问题称为非重叠社区划分
对于网络中的每一个节点,在初始阶段,Label Propagation 算法对每个节点初始化一个唯一的标签,在每次的迭代过程中,每个节点根据与其相连的节点所属的标签改变自己的标签,更改的原则是选择与其相连的节点中所属标签最多的社区标签为自己的社区标签,这便是标签传播的含义。随着社区标签不断传播,最终,连接紧密的节点将有共同的标签
Label Propagation算法利用网络自身的结构指导标签的传播过程,在这个过程中无需优化任何函数。在算法开始前我们不必知道社区的个数,随着算法的迭代,在最终的过程中,算法将自己决定社区的个数
在图 2 中所示的标签传播的过程中,对于 c 节点,在选择了与 a 节点一致的标签后,与 d 节点相邻的节点中,属于 a 社区的节点最多,因此 c 节点的标签也被设置成 a,这样的过程不断持续下去,直到所有可能聚集到一起的节点都具有了相同的社区标签,此时,图 2 中的所有节点的标签都变成了 a。在传播过程的最终,具有相同社区标签的节点被划到相同的社区中成为一个个独立的社区。
同步更新是指对于节点 x,在第 t 代时,根据其所有邻居节点在第 t-1 代时的社区标签,对其标签进行更新。即:
其中,Cx(t) 表示的是节点 x 在第 t 代时的社区标签。函数 f 表示的是取的参数节点中所有社区个数最大的社区。同步更新的方法存在一个问题,即对于一个二分或者近似二分的网络来说,这样的结构会导致标签的震荡,如图 3 所示。
图 3 标签震荡
在图 3 中,在第一步的更新中,若左侧节点的标签更改为 a,右侧节点的标签更改为 b,在第二步中,左侧的节点又会更改为 b,右侧的节点又会更改为 a,如此往复,两边的标签会在社区标签 a 和 b 间不停地震荡。
对于异步更新方式,其更新公式为:
其中,邻居节点 xi1 ,…,xim 的社区标签在第t代已经更新过,则使用其最新的社区标签。而邻居节点 xi(m+1) ,…,xik 在第 t 代时还没有更新,则对于这些邻居节点还是用其在第(t-1)代时的社区标签。
上述的迭代终止条件修改为:对于每一个节点,在其所有的邻居节点所属的社区中,其所属的社区标签是最大的
二、标签传播算法
标签传播算法(label propagation)的核心思想非常简单:相似的数据应该具有相同的label。LP算法包括两大步骤:1)构造相似矩阵;2)勇敢的传播吧。
2.1、相似矩阵构建
LP算法是基于Graph的,因此我们需要先构建一个图。我们为所有的数据构建一个图,图的节点就是一个数据点,包含labeled和unlabeled的数据。节点i和节点j的边表示他们的相似度。这个图的构建方法有很多,这里我们假设这个图是全连接的,节点i和节点j的边权重为:
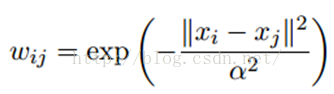
这里,α是超参。
还有个非常常用的图构建方法是knn图,也就是只保留每个节点的k近邻权重,其他的为0,也就是不存在边,因此是稀疏的相似矩阵。
2.2、LP算法
标签传播算法非常简单:通过节点之间的边传播label。边的权重越大,表示两个节点越相似,那么label越容易传播过去。我们定义一个NxN的概率转移矩阵P:
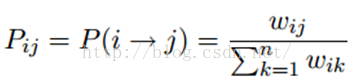
Pij表示从节点i转移到节点j的概率。假设有C个类和L个labeled样本,我们定义一个LxC的label矩阵YL,第i行表示第i个样本的标签指示向量,即如果第i个样本的类别是j,那么该行的第j个元素为1,其他为0。同样,我们也给U个unlabeled样本一个UxC的label矩阵YU。把他们合并,我们得到一个NxC的soft label矩阵F=[YL;YU]。soft label的意思是,我们保留样本i属于每个类别的概率,而不是互斥性的,这个样本以概率1只属于一个类。当然了,最后确定这个样本i的类别的时候,是取max也就是概率最大的那个类作为它的类别的。那F里面有个YU,它一开始是不知道的,那最开始的值是多少?无所谓,随便设置一个值就可以了。
千呼万唤始出来,简单的LP算法如下:
1)执行传播:F=PF
2)重置F中labeled样本的标签:FL=YL
3)重复步骤1)和2)直到F收敛。
步骤1)就是将矩阵P和矩阵F相乘,这一步,每个节点都将自己的label以P确定的概率传播给其他节点。如果两个节点越相似(在欧式空间中距离越近),那么对方的label就越容易被自己的label赋予,就是更容易拉帮结派。步骤2)非常关键,因为labeled数据的label是事先确定的,它不能被带跑,所以每次传播完,它都得回归它本来的label。随着labeled数据不断的将自己的label传播出去,最后的类边界会穿越高密度区域,而停留在低密度的间隔中。相当于每个不同类别的labeled样本划分了势力范围。
2.3、变身的LP算法
我们知道,我们每次迭代都是计算一个soft label矩阵F=[YL;YU],但是YL是已知的,计算它没有什么用,在步骤2)的时候,还得把它弄回来。我们关心的只是YU,那我们能不能只计算YU呢?Yes。我们将矩阵P做以下划分:
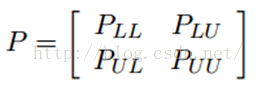
这时候,我们的算法就一个运算:
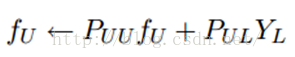
迭代上面这个步骤直到收敛就ok了,是不是很cool。可以看到FU不但取决于labeled数据的标签及其转移概率,还取决了unlabeled数据的当前label和转移概率。因此LP算法能额外运用unlabeled数据的分布特点。
这个算法的收敛性也非常容易证明,具体见参考文献[1]。实际上,它是可以收敛到一个凸解的:
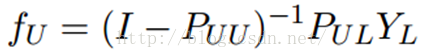
所以我们也可以直接这样求解,以获得最终的YU。但是在实际的应用过程中,由于矩阵求逆需要O(n3)的复杂度,所以如果unlabeled数据非常多,那么I – PUU矩阵的求逆将会非常耗时,因此这时候一般选择迭代算法来实现。















 1016
1016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









