







 本文介绍如何使用scrapy爬取豆瓣电影信息,包括item.py、movie_spider.py、pipelines.py的设置,以及处理MySQL编码问题的提示。在爬取过程中,需要注意数据的UTF-8编码与MySQL数据库的匹配,同时分享了如何通过Chrome开发者工具获取XPath。爬取的内容包括电影名称、年份、导演、类型、演员、评分和评论URL。
本文介绍如何使用scrapy爬取豆瓣电影信息,包括item.py、movie_spider.py、pipelines.py的设置,以及处理MySQL编码问题的提示。在爬取过程中,需要注意数据的UTF-8编码与MySQL数据库的匹配,同时分享了如何通过Chrome开发者工具获取XPath。爬取的内容包括电影名称、年份、导演、类型、演员、评分和评论URL。
scrapy 的组件和 流程:
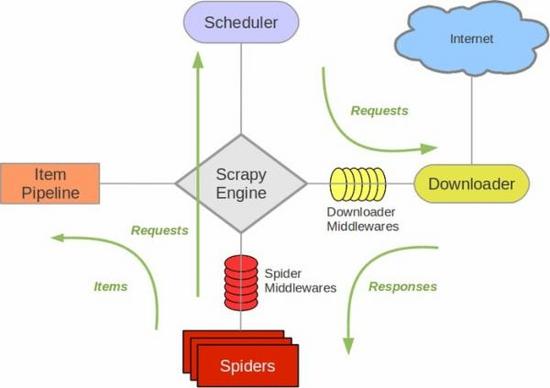
前段时间因为需要,爬了几部豆瓣电影,才开始接触scrapy ,不过网上代码很多,而且文档里也有不少例子。所以 入门还是很容易的。
这里附一下 文档的地址:
https://scrapy-chs.readthedocs.org/zh_CN/0.24/index.html;
https://scrapy-chs.readthedocs.org/zh_CN/1.0/;
其实 英文版更好一点,奈何水平有限,看英文版实在费劲。
item.py
# -*- coding: UTF-8 -*-
from scrapy.item import Item, Field
class DoubanmovieItem(Item):
name=Field()
year=Field()
score=Field()
director=Field()
classification=Field()
actor=Field()
commenturl = Field()
ID = Field()
passmovie_spider.py
# -*- coding: utf-8 -*-
from scrapy.selector import Selector
from scrapy.spiders import CrawlSpider,Rule
from scrapy.linkextractors.sgml import SgmlLinkExtractor
from doubanmovie.items import DoubanmovieItem
class MoiveSpider(CrawlSpider):
name=& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3909
3909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









