









写在前面
感谢原作认可,时过两年,重新根据最新版本再次翻译。
当前版本:V2,from Version2021-07-29
存储有价,数据无价,谨慎使用,请勿用于非法用途。

译文发表记录声明
当前版本:V2,from Version2021-07-29
「掘金:北岸冷若冰霜」[译]A better zip bomb,比例28000000:1「掘金首发V2」
「CSDN:北岸冷若冰霜」A better zip bomb,比例28000000:1已发版本:V1,from Version2019-07-06
「个站:北岸冷若冰霜」A better zip bomb
「看雪:北岸冷若冰霜」ZBLG:非递归zip炸弹,比例为28000000:1
「CSDN:北岸冷若冰霜」ZBLG:非递归zipbomb炸弹,比例为28000000:1
原创声明
原文:https://www.bamsoftware.com/hacks/zipbomb/
作者:David Fifield
Email:david@bamsoftware.com一切版权原作者所有。
2019-07-02 updated 2019-07-03, 2019-07-05, 2019-07-06, 2019-07-08, 2019-07-18, 2019-07-20, 2019-07-22, 2019-07-24, 2019-08-05, 2019-08-19, 2019-08-22, 2019-10-14, 2019-10-18, 2019-10-30, 2019-11-28, 2020-07-28, 2021-01-21, 2021-02-02, 2021-05-03, 2021-07-29
[译]Part 1:A better zip bomb,比例28000000:1「掘金首发V2」
[译]Part 2:A better zip bomb,比例28000000:1「掘金首发V2」
summary
本文展示了如何构建一个 非递归的 Zip_bomb ,通过在 zip 容器内重叠文件来实现高压缩率。“非递归”意味着它不依赖于解压器递归解压嵌套在 zip 文件中的 zip 文件:它在单轮解压后完全展开。输出大小与输入大小成二次方增加,达到压缩比超过2800万 (10 MB → 281 TB) ,在 zip 格式的限制中。
仅使用 64 位扩展甚至可以实现更大的扩展。该构造仅使用最常见的压缩算法DEFLATE,并且可以与大多数 zip 解析器兼容。

| zbsm.zip | 42 kB | → | 5.5 GB |
|---|---|---|---|
| zblg.zip | 10 MB | → | 281 TB |
| zbxl.zip | 46 MB | → | 4.5 PB (Zip64, less compatible) |
源代码:
git clone https://www.bamsoftware.com/git/zipbomb.git
或者:
wget https://www.bamsoftware.com/hacks/zipbomb/zipbomb-20210121.zip
数据和数据来源
git clone https://www.bamsoftware.com/git/zipbomb-paper.git
翻译:
Русский перевод от @m1rko.
中文翻译: 北岸冷若冰霜.
| non-recursive | recursive | ||||
|---|---|---|---|---|---|
| zipped size | unzipped size | ratio | unzipped size | ratio | |
| Cox quine | 440 | 440 | 1.0 | ∞ | ∞ |
| Ellingsen quine | 28 809 | 42 569 | 1.5 | ∞ | ∞ |
| 42.zip | *42 374 | 558 432 | 13.2 | 4 507 981 343 026 016 | 106 billion |
| this technique | 42 374 | 5 461 307 620 | 129 thousand | 5 461 307 620 | 129 thousand |
| this technique | 9 893 525 | 281 395 456 244 934 | 28 million | 281 395 456 244 934 | 28 million |
| this technique (Zip64) | 45 876 952 | 4 507 981 427 706 459 | 98 million | 4 507 981 427 706 459 | 98 million |
- 关于42.zip
有两个版本的42.zip,一个较老版本的42 374字节,以及更新版本的42 838字节。不同之处在于新版本在解压缩之前需要密码,新版本解压密码为:42。我们仅与旧版本进行比较。如果需要,提供以下副本: 42.zip。
我想知道并感谢 42.zip 的制作者,但一直无法找到来源 - 如果您有任何信息,请告诉我。
使用 zip 格式的Compression bombs必须应对这样一个事实,即 zip 解析器最常支持的压缩算法DEFLATE无法实现大于 1032 的压缩率。因此,zip bombs 通常依赖递归解压,在其中嵌套 zip 文件zip 文件以获得每层 1032 的额外因子。但是这个技巧只适用于递归解压缩的实现,大多数都没有。最著名的 zip 炸弹 42.zip扩展为一个强大的4.5 PB ,如果它的所有六个层都被递归解压缩,但是一个微不足道的 0.6 MB在顶层。Zip quines 与Ellingsen 和Cox 的那些一样,它们包含自身的副本,因此如果递归解压缩则无限扩展,同样可以完全安全地解压缩一次。
16 x 4294967295 = 68.719.476.720 (68GB)
16 x 68719476720 = 1.099.511.627.520 (1TB)
16 x 1099511627520 = 17.592.186.040.320 (17TB)
16 x 17592186040320 = 281.474.976.645.120 (281TB)
16 x 281474976645120 = 4.503.599.626.321.920 (4,5PB)
这篇文章展示了如何构造一个压缩比超过 1032 的 DEFLATE 限制的非递归 zip bombs。 它的工作原理是在 zip 容器内重叠文件,以便在多个文件中引用一个高度压缩数据的“内核”,而不需要使它的多个副本。zip bombs的输出大小与输入大小成二次方增长;即,压缩率随着bomb变大而变好。该构造取决于 zip 和 DEFLATE 的特性——它不能直接移植到其他文件格式或压缩算法。它与大多数 zip 解析器兼容,例外是“流式”解析器,它们一次解析而无需先咨询 zip 文件的中央目录。我们试图平衡两个相互冲突的目标:
- 最大化压缩比
我们将压缩率定义为 zip 文件中包含的所有文件的大小之和除以 zip 文件本身的大小。它不计算文件名或其他文件系统元数据,只计算内容。 - 兼容
Zip 是一种棘手的格式,解析器各不相同,尤其是在边缘情况和可选功能方面。避免利用仅适用于某些解析器的技巧。我们将评论某些方法来提高 zip bombs的效率,但会损失一些兼容性。
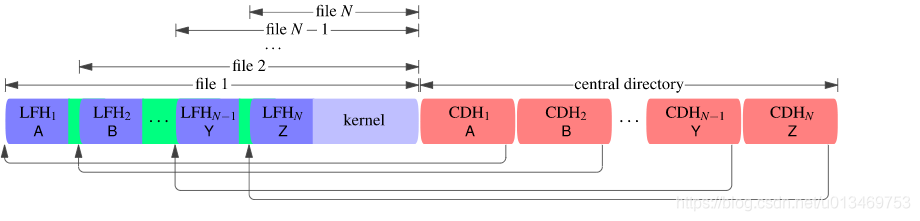
zip文件的结构
zip文件由引用 文件 的 中央目录 组成。

中央目录位于 zip 文件的末尾。它是一个 中央目录标题 列表。每个中央目录头都包含单个文件的元数据,如文件名和 CRC-32 校验和,以及指向本地文件头的向后指针。中央目录头是 46 字节长,加上文件名的长度。
一个文件由一个 本地文件头 和紧跟其后的压缩 文件数据组成 。本地文件头的长度为 30 个字节,加上文件名的长度。它包含来自中央目录头的元数据的冗余副本,以及紧随其后的文件数据的压缩和未压缩大小。Zip 是一种容器格式,而不是一种压缩算法。每个文件的数据都使用元数据中指定的算法进行压缩 - 通常是DEFLATE。
zip 格式的这种描述省略了许多理解 zip bombs不需要的细节。有关完整信息,请参阅 APPNOTE.TXT 的第 4.3 节 或Florian Buchholz撰写的 PKZip 文件的结构,或查看源代码。
zip 格式中的许多冗余和歧义允许各种恶作剧。zip bombs只是触及表面。进一步阅读的链接:
- 一万个安全陷阱:ZIP 文件格式,Gynvael Coldwind 演讲
- Zip - 如何不设计文件格式,作者 Gregg Tavares
- 模糊的 zip 解析允许对 linter 和 reviewers 隐藏附加文件,这是我在 addons.mozilla.org 中发现的一个漏洞
Insight #1: overlapping files 重叠文件
通过压缩一长串重复字节,我们可以生成 高度压缩数据的内核。就其本身而言,内核的压缩率不能超过 DEFLATE 限制 1032,因此我们希望有一种方法可以在许多文件中重用内核,而无需在每个文件中制作单独的副本。我们可以通过重叠文件来实现:使许多中央目录头指向单个文件,其数据是内核。
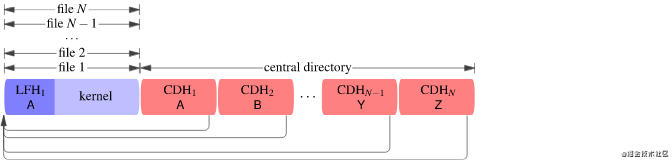
让我们看一个例子,看看这种结构如何影响压缩比。假设内核是1000 字节 并解压到 1 MB. 那么第一个MB 产出“成本” 1078 字节 输入:
- 31 字节 对于本地文件头(包括 1 字节的文件名)
- 47 字节 对于中央目录头(包括 1 字节的文件名)
- 1000 字节 对于内核本身
但每 1 MB 仅在第一次成本后的产出 47 字节——我们不需要另一个本地文件头或内核的另一个副本,只需要一个额外的中央目录头。因此,虽然内核的第一个参考具有 1 000 000 / 1078 ≈ 928 的压缩比,但每个额外的参考都将压缩比拉近 1 000 000 / 47 ≈ 21 277。更大的内核会提高上限。
这个想法的问题是缺乏兼容性。由于许多中央目录头指向单个本地文件头,因此元数据(特别是文件名)无法与每个文件匹配。一些解析器对此犹豫不决。 Info-ZIP UnZip (标准 Unixunzip程序)提取文件,但有警告:
unzip overlap.zip
inflating: A
B: mismatching "local" filename (A),continuing with "central" filename version
inflating: B
...
$ python3 -m zipfile -e overlap.zip .
Traceback (most recent call last):
...
__main__.BadZipFile: File name in directory 'B' and header b'A' differ.
接下来我们将看到如何修改结构以保持文件名的一致性,同时仍然保留重叠文件的大部分优势。
Insight #2: quoting headers:引用本地文件头
我们需要为每个文件分离本地文件头,同时仍然重用单个内核。简单地连接所有本地文件头是行不通的,因为 zip 解析器会在它期望找到 DEFLATE 流的开头的地方找到一个本地文件头。但是这个想法会奏效,只需稍作修改。我们将使用 DEFLATE 的一个特性,非压缩块,来“引用”本地文件头,使它们看起来是在内核中终止的同一个 DEFLATE 流的一部分。每个本地文件头(除了第一个)都将以两种方式解释:作为代码(zip 文件结构的一部分)和作为数据(文件内容的一部分)。
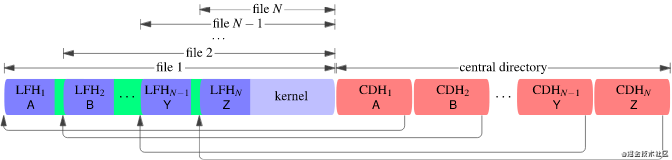
DEFLATE 流是一个块序列 ,其中每个块可以被压缩或未压缩。压缩块就是我们通常想到的;例如内核是一个大的压缩块。但也有未压缩的块,它们以5 字节的标头开头,其中 的长度字段仅表示“逐字输出接下来的n个字节”。解压缩未压缩的块意味着仅剥离 5 字节的标头。压缩和非压缩块可以在 DEFLATE 流中自由混合。输出是按顺序解压缩所有块的串联。“非压缩”的概念只在 DEFLATE 层有意义;无论使用什么类型的块,文件数据在 zip 层仍然算作“压缩”。
从内到外理解这种引用重叠结构是最容易的,从最后一个文件开始,然后倒退到第一个文件。首先插入内核,它将形成每个文件的文件数据的结尾。预先 添加本地文件头 LFH N并添加指向它的中央目录头 CDH N。将 LFH N和 CDH N 中的“压缩大小”元数据字段设置为内核的压缩大小。现在预先添加一个 5 字节的非压缩块头(图中的绿色),其长度字段等于 LFH N的大小。预先 添加第二个本地文件头 LFH N -1并添加中央目录头 CDH N -1那指向它。将两个新头中的“压缩大小”元数据字段设置为内核的压缩大小 加上非压缩块头的大小(5 个字节) 加上LFH N的大小。
此时 zip 文件包含两个文件,名为“Y”和“Z”。让我们来看看 zip 解析器在解析它时会看到什么。假设内核压缩后的大小为 1000 字节,LFH N的大小为 31 字节。我们从 CDH N -1开始, 并跟随指向 LFH N -1的指针。第一个文件的文件名为“Y”,其文件数据的压缩大小为 1036 字节。将接下来的 1036 个字节解释为 DEFLATE 流,我们首先遇到了一个非压缩块的 5 字节标头,它说要复制接下来的 31 个字节。我们写入接下来的 31 个字节,它们是 LFH N,我们将其解压缩并附加到文件“Y”中。在 DEFLATE 流中继续前进,我们找到一个压缩块(内核),我们将其解压为文件“Y”。现在我们已经到了压缩数据的末尾,并且完成了文件“Y”。继续下一个文件,我们沿着从CDH N 到LFH N的指针找到一个名为“Z”的文件,其压缩大小为1000字节。将这 1000 个字节解释为 DEFLATE 流,我们立即遇到一个压缩块(再次是内核)并将其解压缩为文件“Z”。现在我们已经到达最终文件的末尾并完成了。输出文件“Z”包含解压后的内核;输出文件 “Y” 是相同的,但另外以 LFH N的 31 个字节为前缀。
2019-08-22: 还有一个额外的小优化可能是我最初没有想到的。不要只引用紧随其后的本地文件头,而是尽可能多地引用本地文件头——包括它们自己的引用块——每个非压缩块最多 65535 字节。优点是本地文件头之间的引用块现在额外成为输出文件的一部分,为我们设法包含的每个文件获得 5 个字节的输出。这是一个小的优化,只获得154 380zbsm.zip 中的字节数,或 0.003%。(远小于字段外引用增益。)源代码中的
--giant-steps选项激活了此功能。
仅当您不受最大输出文件大小的限制时,巨型步骤功能才会付费。在 zblg.zip 中,我们实际上希望尽可能减慢文件的增长速度,以便包含内核的最小文件尽可能大。在 zblg.zip 中使用巨大的步骤实际上会降低压缩率。
我 感谢Kevin Farrow在dc303 演讲中激发了此增强功能的想法。Carlos Javier González Cortés (Lethani) 在他关于重叠拉链炸弹的文章 ( Español ) 中也提出了这个想法 。
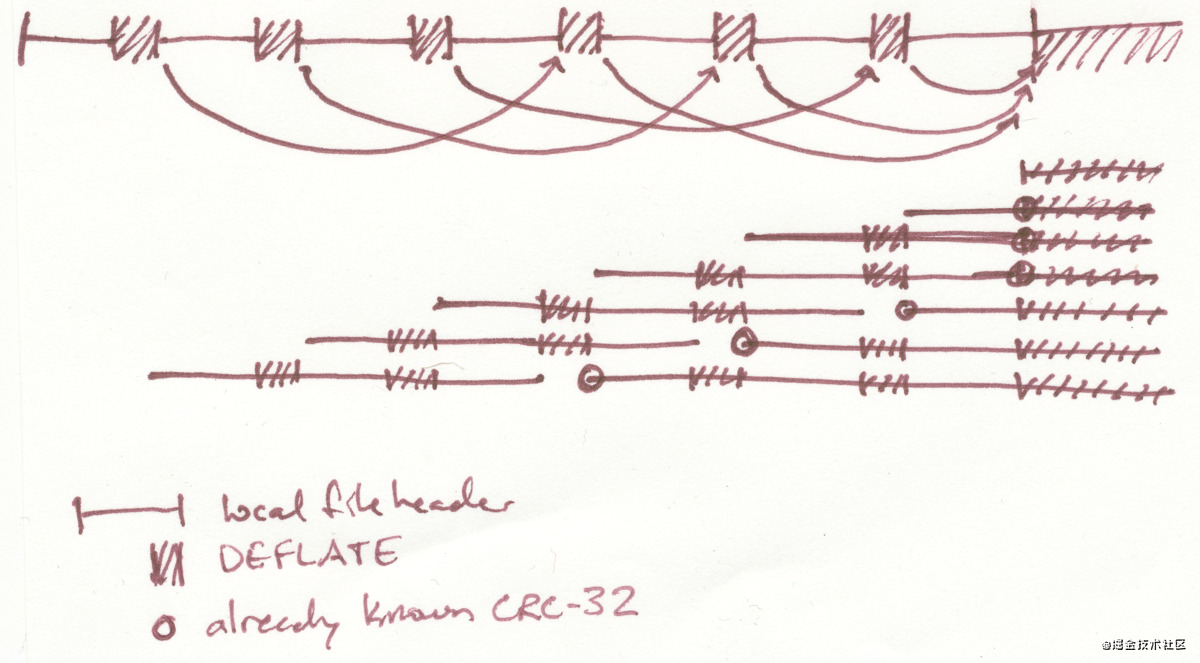
我们通过重复引用过程来完成构建,直到 zip 文件包含所需数量的文件。每个新文件添加一个中央目录头、一个本地文件头和一个非压缩块以引用紧随其后的本地文件头。压缩文件数据通常是一连串 DEFLATE 非压缩块(引用的本地文件头),然后是压缩内核。内核中的每个字节为输出大小贡献了大约 1032 N,因为每个字节都是所有N 的一部分文件。输出文件的大小不尽相同:在 zip 文件中较早出现的文件比出现在后面的文件大,因为它们包含更多引用的本地文件头。输出文件的内容不是特别有意义,但没有人说它们必须有意义。
这种引用重叠结构比上一节的全重叠结构具有更好的兼容性,但兼容性是以压缩比为代价的。在那里,每个添加的文件只需要一个中央目录头;在这里,它需要一个中央目录头、一个本地文件头和另外 5 个字节的引用头。
优化
现在我们有了基本的 zip 炸弹结构,我们将尝试使其尽可能高效。我们想回答两个问题:
- 对于给定的 zip 文件大小,最大压缩率是多少?
- 考虑到 zip 格式的限制,最大压缩比是多少?
内核压缩
尽可能密集地压缩内核是值得的,因为每个解压缩的字节都会被放大N倍。为此,我们使用名为 bulk_deflate 的自定义 DEFLATE 压缩器,专门用于压缩重复字节的字符串。
当给定无限的重复字节流时,所有体面的 DEFLATE 压缩器都将接近 1032 的压缩率,但我们更关心特定的有限大小而不是渐近。与通用压缩器相比,bulk_deflate 将更多数据压缩到相同的空间:比 zlib 和 Info-ZIP 多约 26 kB,比Zopfli多约 15 kB ,后者是一种以速度换密度的压缩器。
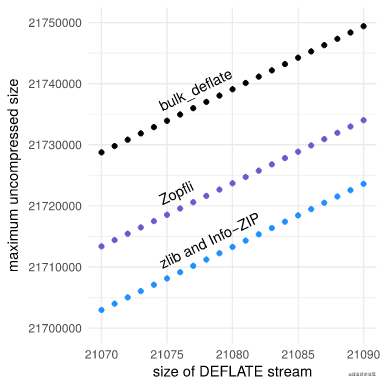
bulk_deflate 高压缩比的代价是缺乏普遍性。bulk_deflate 只能压缩单个重复字节的字符串,并且只能压缩特定长度的字符串,即整数k ≥ 0 时为517 + 258 k。实际写出压缩字符串的工作。
文件名
就我们的目的而言,文件名大多是无用的。虽然文件名作为引用的本地文件头的一部分确实对输出大小有所贡献,但文件名中的一个字节几乎没有内核中的一个字节贡献。我们希望文件名尽可能短,同时保持它们都不同,并考虑兼容性问题。
花在文件名上的每个字节是未花在内核上的 2 个字节。(2 因为每个文件名出现两次,在中央目录头和本地文件头中。)一个文件名字节导致平均只有 (
N+ 1) / 4 个字节的输出,而内核中的一个字节计为 1032否。
第一个兼容性考虑是字符编码。zip 格式规范指出,如果设置了某个标志位(APPNOTE.TXT 附录 D),文件名将被解释为CP 437或UTF-8。但这是 zip 解析器不兼容的一个主要问题,它可能会将文件名解释为某些固定的或特定于语言环境的编码。所以为了兼容性,我们必须限制在 CP 437 和 UTF-8 中具有相同编码的字符;即 US-ASCII 的 95 个可打印字符。
我没有考虑的一件事是 Windows 保留文件名,如 “PRN” 和 “NUL”。
我们进一步受到文件系统命名限制的限制。某些文件系统不区分大小写,因此“a”和“A”不算作不同的名称。常见的文件系统如 FAT32 禁止某些字符, 如 ‘*’ 和 ‘?’。
作为一种安全但不一定是最佳折衷方案,我们的 zip 炸弹将使用由 36 个字符的字母表中的字符组成的文件名,不依赖大小写区分或使用特殊字符:
0 1 2 3 4 5 6 7 8 9 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
文件名以明显的方式生成,在可能的字符中循环每个位置并在溢出时添加一个位置:
“0”, “1”, “2”, …, “Z”,
“00”, “01”, “02”, …, “0Z”,
…,
“Z0”, “Z1”, “Z2”, ……、“ZZ”、
“000”、“001”、“002”、……
有 36 个长度为 1 的文件名,36 个2长度为 2 的文件名,依此类推。第n个文件名的长度为⌊log 36 (( n + 1) / (36 / 35))⌋ + 1. 四个字节足以表示 1 727 604 不同的文件名。
鉴于zip 文件中的N 个文件名的长度通常不相同,我们应该按照哪种方式对它们进行排序,从最短到最长还是从最长到最短?稍微反思一下,最好把最长的名字放在最后,因为那些名字被引用最多。排序文件名最长的最后添加900 MB输出到zblg.zip,与首先对它们进行最长排序相比。不过,这是一个次要的优化,因为那些900 MB 只包括 0.0003% 的总输出大小。
内核大小
引用重叠结构允许我们放置一个压缩的数据内核,然后廉价地多次复制它。对于给定的 zip 文件大小 X,我们应该投入多少空间来存储内核,以及制作副本需要多少空间?
为了找到最佳平衡,我们只需要优化单个变量N,即 zip 文件中的文件数。N 的每个值都需要一定量的中央目录头、本地文件头、引用块头和文件名的开销。所有剩余的空间都可以被内核占用。因为N必须是一个整数,并且在内核大小降为零之前您只能容纳这么多文件,所以测试N 的每个可能值 并选择产生最多输出的值就足够了。
将优化程序应用于X = 42 374,即 42.zip 的大小,在N = 250处找到最大值。这 250 个文件需要21 195 字节的开销,离开 21 179内核的字节数。该大小的内核解压为21 841 249 字节(比率为 1031.3)。解压内核的 250 个副本,加上来自引用的本地文件头的一点点额外,产生 5 461 307 620 字节的整体解压缩输出和压缩比12.9万.
zbsm.zip 42 kB → 5.5 GB
zipbomb --mode = quoted_overlap --num-files = 250 --compressed-size = 21179> zbsm.zip
优化在分配给内核的空间和分配给文件头的空间之间产生了几乎均匀的分配。这并非巧合。让我们看一下引用重叠结构的简化模型。在简化模型中,我们忽略了文件名,以及由于引用本地文件头而导致的输出文件大小的轻微增加。对简化模型的分析将表明内核和文件头之间的最佳分割近似均匀,并且当分配最佳时,输出大小呈二次方增长。
定义一些常量和变量:
| X | zip文件大小(固定) | |
|---|---|---|
| N | zip文件中的文件数(要优化的变量) | |
| CDH | = 46 | 中央目录头的大小(没有文件名) |
| LFH | = 30 | 本地文件头的大小(没有文件名) |
| Q | = 5 | DEFLATE非压缩块头的大小 |
| C | ≈1032 | 内核的压缩比 |
设H(N)为N个文件所需的头部开销量。请参考下图以了解此公式的来源。
H
(
N
)
=
N
⋅
(
C
D
H
+
L
F
H
)
+
(
N
−
1
)
⋅
Q
H(N) = N ·(CDH + LFH)+(N -1)·Q
H(N)=N⋅(CDH+LFH)+(N−1)⋅Q
内核剩余的空间是 X - H(N)。总解压缩大小 S X(N)是内核的N个副本的大小,以比率C解压缩。(在此简化模型中,我们忽略了来自引用的本地文件头的次要附加扩展。)
S
X
(
N
)
=
(
X
−
H
(
N
))
C
N
.
=
(
X
−
(
N
⋅
(
C
D
H
+
L
F
H
)
+
(
N
−
1
)
⋅
Q
))
C
N
.
=
−
(
C
D
H
+
L
F
H
+
Q
)
C
N
2
+
(
X
+
Q
)
C
N
.
S X(N) =(X - H(N))C N. =(X - (N ·(CDH + LFH)+(N -1)·Q))C N. = - (CDH + LFH + Q)C N 2 +(X + Q)C N.
SX(N)=(X−H(N))C N.=(X−(N⋅(CDH+LFH)+(N−1)⋅Q))C N.=−(CDH+LFH+Q)C N2+(X+Q)C N.
小号X(Ñ)是一个多项式Ñ,因此它的最大必须一个地方衍生物 小号 ’ X(Ñ)是零。取导数并找到零给我们 N OPT,最佳文件数。
小
号
′
X
(
N
~
O
P
T
)
=
−
2
(
C
D
H
+
L
F
H
+
Q
)
C
N
O
P
T
+
(
X
+
Q
)
C
0
=
−
2
(
C
D
H
+
L
F
H
+
Q
)
C
N
O
P
T
+
(
X
+
Q
)
C
N
O
P
T
=
(
X
+
Q
)
/
(
C
D
H
+
L
F
H
+
Q
)
/
2
小号 ' X(Ñ OPT) = -2(CDH + LFH + Q)C N OPT +(X + Q)C 0 = -2(CDH + LFH + Q)C N OPT +(X + Q)C N OPT =(X + Q)/(CDH + LFH + Q)/ 2
小号′X(N~OPT)=−2(CDH+LFH+Q)C NOPT+(X+Q)C0=−2(CDH+LFH+Q)C NOPT+(X+Q)CNOPT=(X+Q)/(CDH+LFH+Q)/2
H(N OPT)为文件头分配了最佳的空间量。它独立于CDH,LFH和C,接近X / 2。
H
(
N
O
P
T
)
=
N
O
P
T
⋅
(
C
D
H
+
L
F
H
)
+
(
N
O
P
T
−
1
)
⋅
Q
=
(
X
−
Q
)
/
2
H(N OPT) = N OPT ·(CDH + LFH)+(N OPT - 1)·Q =(X - Q)/ 2
H(NOPT)=NOPT⋅(CDH+LFH)+(NOPT−1)⋅Q=(X−Q)/2
S X(N OPT)是分配最佳时的总解压缩大小。由此我们看到输出大小在输入大小上呈二次方增长。
S
X
(
N
O
P
T
)
=
(
X
+
Q
)
2
C
/
(
C
D
H
+
L
F
H
+
Q
)
/
4
S X(N OPT) =(X + Q)^2 C /(CDH + LFH + Q)/ 4
SX(NOPT)=(X+Q)2 C/(CDH+LFH+Q)/4
它有点复杂,因为精确的限制取决于实现。Python zipfile 忽略 文件数。Go archive / zip 允许 更大的文件计数,只要它们在低16位中相等即可。但是为了广泛的兼容性,我们必须坚持所述的限制。
随着我们将zip文件扩大,最终我们遇到了zip格式的限制。zip文件最多可包含2 个 16-1个文件,每个文件的未压缩大小最多为2^32 - 1个字节。更糟糕的是, 一些实现 采用最大可能值作为64位扩展的存在的指示符,因此我们的限制实际上是2^16 - 2和2^32 - 2. 碰巧我们遇到的第一个限制是关于未压缩的文件大小。在zip文件大小为8 319 377字节时,天真优化将使我们的文件数为47 837,最大文件为2^32 + 311字节。
接受我们不能无限制地增加N和内核的大小,我们希望找到可达到的最大压缩比,同时保持在zip格式的限制内。继续进行的方法是使内核尽可能大,并拥有最大数量的文件。即使我们不能再维持内核和文件头之间的大致均匀分割,每个添加的文件确实会增加压缩比 - 只是没有像我们能够继续增长内核那样快。实际上,当我们添加文件时,我们需要减小内核的大小,以便为每个添加的文件获得稍大的文件大小腾出空间。
该计划产生一个zip文件,其中包含2^16 - 2个文件和一个解压缩到2^32 - 2 178 825字节的内核。文件在zip文件的开头变长 - 第一个和最大的文件解压缩到2^32 - 56个字节。这与我们可以使用bulk_deflate-encoding的粗略输出大小一样接近,最后54个字节的成本将超过它们的价值。(zip文件整体压缩率是2800万,最后54个字节最多可以获得54⋅1032⋅(2^16 - 2)…“3650万字节,所以只有54个字节可以用1个字节编码才有用 - 我不能用不到2个字节进行编码。)所以除非你能将54个字节编码成1个字节,否则只会降低压缩率。)输出大小这个zip炸弹,281 395 456 244 934字节,是理论最大值(2^32 - 1)⋅(2^16 - 1)的99.97%。 压缩比的任何重大改进只能来自减小输入大小,而不是增加输出大小。
zblg.zip 10 MB → 281 TB
zipbomb --mode = quoted_overlap --num-files = 65534 --max-uncompressed-size = 4292788525> zblg.zip
高效的CRC-32计算
中央目录头和本地文件头中的元数据是 未压缩文件数据的 CRC-32校验和。这带来了一个问题,因为直接计算每个文件的 CRC-32 需要做与总解压缩大小成比例的工作,这在设计上很大。(毕竟这是一个拉链炸弹。)我们更愿意做在最坏的情况下与拉链成正比的工作**尺寸。我们的优势有两个因素:所有文件共享一个共同的后缀(内核),未压缩的内核是一串重复的字节。我们将 CRC-32 表示为矩阵乘积——这将使我们不仅可以快速计算内核的校验和,还可以跨文件重用计算。本节中描述的技术是crc32_combine zlib 中函数的轻微扩展 ,Mark Adler在此处解释了 这一点。
您可以将 CRC-32 建模为状态机,它为每个传入位更新 32 位状态寄存器。0 位和 1 位的基本更新操作是:
uint32 crc32_update_0(uint32 state) {
// Shift out the least significant bit.
bit b = state & 1;
state = state >> 1;
// If the shifted-out bit was 1, XOR with the CRC-32 constant.
if (b == 1)
state = state ^ 0xedb88320;
return state;
}
uint32 crc32_update_1(uint32 state) {
// Do as for a 0 bit, then XOR with the CRC-32 constant.
return crc32_update_0(state) ^ 0xedb88320;
}
如果您将状态寄存器视为一个 32 元素的二进制向量,并使用 XOR 进行加法和使用 AND 进行乘法,那么 crc32_update_0就是 线性变换;即,它可以表示为乘以一个 32×32 的二进制 变换矩阵。要了解原因,请观察将矩阵乘以向量只是在将每列乘以向量的相应元素之后对矩阵的列求和。移位操作state >> 1 只是将状态向量的每一位 i乘以一个向量,该向量除第i − 1 位(从右到左编号)外,其他地方都为 0 。state ^ 0xedb88320 仅在位时发生 的条件最终异或bis 1 可以表示为首先乘以 b0xedb88320 然后将其异或到状态。
此外,crc32_update_1只是 crc32_update_0加(XOR)一个常数。这进行crc32_update_1了 仿射变换:矩阵乘法后跟平移(即向量加法)。如果我们将变换矩阵的维度扩大到 33×33 并将一个额外的元素附加到始终为 1 的状态向量,我们可以在一个步骤中同时表示矩阵乘法和平移。(这种表示称为 齐次坐标。)
矩阵M 0如下
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
矩阵M1如下
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
33×33变换矩阵M 0和M 1分别计算由0位和1位影响的CRC-32状态变化。列向量存储在底部的最高有效位:从下到上读取第一列,您会看到CRC-32多项式常量edb88320 16 = 1 1 1 0 1 1 0 11 0 1 1 1 0 0 0 1 0 0 0 0 0 1 1 0 0 1 0 0 0 00 2。两个矩阵仅在最终列中不同,最终列表示齐次坐标中的平移向量。在M 0中,平移为零,并且在M 1中,它是edb88320 16,CRC-32多项式常数。正好在对角线上方的1表示换档操作state >> 1。
这两种操作crc32_update_0和crc32_update_1 可以由33×33的变换矩阵来表示。示出了矩阵M 0和M 1。矩阵表示的好处是矩阵组成。假设我们想要表示通过处理ASCII字符’a’而产生的状态变化,其二进制表示为01100001 2。我们可以在单个变换矩阵中表示这8位的累积CRC-32状态变化:
M
a
=
M
0
M
1
M
1
M
0
M
0
M
0
M
0
M
1
M a = M 0 M 1 M 1 M 0 M 0 M 0 M 0 M 1
Ma=M0M1M1M0M0M0M0M1
我们可以通过将M a 的许多副本相乘来表示一串重复的 ‘a’ 的状态变化——矩阵求幂。我们可以使用平方和乘法算法快速进行矩阵求幂,该算法允许我们以 大约 log 2 n步计算M ``n。例如,表示一串 9 'a’s 状态变化的矩阵是
$$
(Ma)9 = M M M M M M M M Ma a a a a a a a a
=(M M M M)2 M.a a a a a
=((M M)2)2 M.a a a
=(((Ma)2)2)2 M.a
$$
square-and-multiply算法对于计算M kernel是非压缩内核的矩阵很有用,因为内核是一串重复的字节。要从矩阵生成CRC-32校验和值,请将矩阵乘以零向量。(齐次坐标中的零向量,即:32 0后跟1。这里我们省略校正和预处理和后处理的次要复杂性。)为了计算每个文件的校验和,我们向后工作。首先初始化M := M 内核。内核的校验和也是最终文件的校验和,文件 N,因此将M乘以零向量并将得到的校验和存储在CDH N和LFH中ñ。的文件的文件数据 ñ - 1相同的文件的文件数据 Ñ,但随着LFH添加的前缀 Ñ。这样计算中号LFH Ñ,用于LFH状态改变矩阵 Ñ,和更新中号 := 中号 中号LFH Ñ。现在 M表示处理LFH N后跟内核的累积状态变化。 通过再次将 M乘以零向量来计算文件 N -1的校验和。继续该过程,将状态变化矩阵累积到 M中,直到所有文件都已处理完毕。
扩展名:Zip64
早些时候,由于 zip 格式的限制,我们在扩展方面遇到了障碍——无论 zip 文件打包得多么巧妙,都不可能产生超过 281 TB 的输出。使用Zip64可以超越这些限制,Zip64是 zip 格式的扩展,可将某些标头字段的大小增加到 64 位。对 Zip64 的支持绝不是普遍的,但它是更常见的扩展之一。至于压缩率,Zip64 的效果是将中央目录头的大小从 46 字节增加到 58 字节,将本地目录头的大小从 30 字节增加到 50 字节。参考 公式 为了在简化模型中实现最佳扩展,我们看到 Zip64 格式的 zip 炸弹仍然呈二次方增长,但由于分母较大而更慢——这在下图 中 Zip64 行略低的垂直位置中可见 。作为兼容性的丧失和增长缓慢的交换,我们取消了所有实际的文件大小限制。
假设我们想要一个 zip 炸弹扩展到 4.5 PB,与 42.zip 递归扩展到的大小相同。zip 文件必须有多大?使用二进制搜索,我们发现解压大小超过 42.zip 解压大小的最小 zip 文件的压缩大小为 46 MB.
zipbomb --mode=quoted_overlap --num-files=190023 --compressed-size=22982788 --zip64 > zbxl.zip
4.5 PB大致是Event Horizon Telescope捕获的数据大小,用于制作黑洞,堆栈和硬盘堆栈的 第一张图像。
4.5 PB大约是事件视界望远镜拍摄的数据大小,用于制作黑洞的 第一张图像,堆叠和堆叠的硬盘驱动器。
使用 Zip64,考虑最大压缩率实际上不再有趣,因为我们可以不断增加 zip 文件的大小,以及随之而来的压缩率,直到压缩的 zip 文件也大得令人望而却步。不过,一个有趣的阈值是 2 64 字节 (18 EB 要么 16 EIB)——大多数文件系统都放不下那么多数据 。二分搜索找到至少产生那么多输出的最小 zip 炸弹:它包含1200万 文件并有一个压缩的内核 1.5 GB. zip文件的总大小为 2.9 GB 它解压到 2 64 + 11 727 895 877 字节, 压缩比超过 62亿. 我没有让这个下载,但你可以使用源代码自己生成它。它包含的文件如此之大,以至于它发现 了 Info-ZIP UnZip 6.0 中的一个错误。
zipbomb --mode=quoted_overlap --num-files=12056313 --compressed-size=1482284040 --zip64 > zbxxl.zip
扩展名:bzip2
DEFLATE 是 zip 格式中最常用的压缩算法,但它只是众多选项中的一种。第二个最常用的算法可能是bzip2,虽然不如 DEFLATE 兼容,但可能是第二个最常用的压缩算法。从经验上看,bzip2 的最大压缩比约为 140 万,这允许对内核进行更密集的打包。忽略兼容性的损失,bzip2 是否启用了更高效的 zip 炸弹?
是的,但仅适用于小文件。问题是 bzip2 没有像我们用来引用本地文件头的 DEFLATE的非压缩块那样的东西 。所以不可能重叠文件和重用内核——每个文件必须有自己的副本,因此整体压缩率并不比任何单个文件的比率好。在图中,我们看到无重叠 bzip2 仅在大约 1 兆字节以下的文件中优于引用的 DEFLATE。
仍然有希望使用 bzip2——下一节中讨论的本地文件头引用的替代方法。此外,如果您碰巧知道某个 zip 解析器支持 bzip2 并容忍不匹配的文件名,那么您可以使用完全重叠结构,无需引用。
bzip2 以运行长度编码步骤开始,该步骤将重复字节串的长度减少 51 倍。然后将数据分成 900 KB块和每个块单独压缩。根据经验,运行长度编码后的一个块可以压缩到 32 个字节。900 000 × 51 / 32 = 1 434 375。
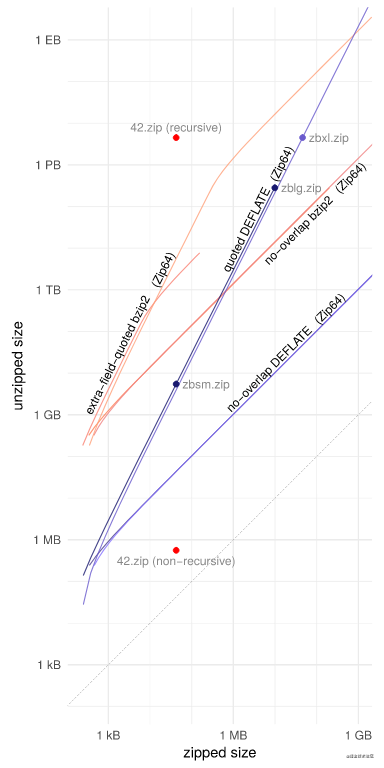
各种拉链炸弹结构的压缩尺寸与解压缩尺寸。请注意对数-对数比例。每个结构都显示有和没有 Zip64。无重叠结构具有线性增长率,这在线条的 1:1 斜率中可见。bzip2 行的垂直偏移表明 bzip2 的压缩比比 DEFLATE 大一千倍左右。引述的 DEFLATE 结构具有二次增长率,如 2:1 的线斜率所示。Zip64 变体的效率稍低,但允许输出超过 281 TB。在达到最大文件大小 (2 32 − 2 字节),或额外字段引用允许的最大文件数。
扩展:额外字段引用
到目前为止,我们已经使用了 DEFLATE 的一个特性来引用本地文件头,我们刚刚看到同样的技巧不适用于 bzip2。有另一种引用方式,但比较有限,它仅使用 zip 格式的功能,不依赖于压缩算法。
在本地文件头结构的末尾有一个可变长度的 额外字段, 其目的是存储不适合头的普通字段的信息(APPNOTE.TXT 第 4.3.7 节)。额外信息可能包括,例如,高分辨率时间戳或 Unix uid/gid;Zip64 通过使用额外字段来工作。额外的字段是一个长度值结构:如果我们增加长度字段而不增加值,那么它将增长以包含 zip 文件中它后面的任何内容 - 即下一个本地文件头。每个本地文件头通过将它们包含在其自己的额外字段中来“引用”跟随它的本地文件头。字段外引用相对于 DEFLATE 引用的好处有三方面:
-
- Extra-field 引用只需要 4 个字节的开销,而不是 5 个,为内核留出更多空间。
-
- Extra-field 引用不会增加文件的大小,这在 zip 格式的限制下运行时为更大的内核留下了更多的空间。
-
- Extra-field 引用提供了一种将引用与 bzip2 结合使用的方法。
Android 的zipalign工具将文件对齐到 4 字节边界。它的工作原理是 用 0x00 字节填充额外的字段。因此可以考虑使用标头 ID 0x0000,它“保留供 PKWARE 使用”。但是因为它可能会添加 0、1、2 或 3 个字节的填充,并且一个额外的字段头是 4 个字节,所以它产生的额外字段可能无论如何都是无效的。
尽管有这些好处,但字段外引用不如 DEFLATE 引用灵活。它不链接:每个本地文件头不仅必须包含紧随其后的头,而且必须包含其后的所有头。额外字段的长度随着它们接近 zip 文件的开头而增加。因为额外字段的最大长度为 2 16 − 1 字节,它最多只能包含 1808 个本地文件头,或 1170 个 Zip64,假设文件名按描述分配。(使用DEFLATE,可以对最早的本地文件头使用extra-field 引用,然后对其余部分切换到DEFLATE 引用。)另一个问题是,为了符合extra字段的内部数据结构,必须选择16 位标头 ID (APPNOTE.TXT 部分 4.5.2)。在引用的数据之前。我们想要一个标题 ID,它可以让解析器忽略引用的数据,而不是尝试将其解释为有意义的元数据。Zip 解析器应该忽略未知的标头 ID,因此我们可以随机选择一个,但存在将来可能分配 ID 的风险,从而破坏兼容性。
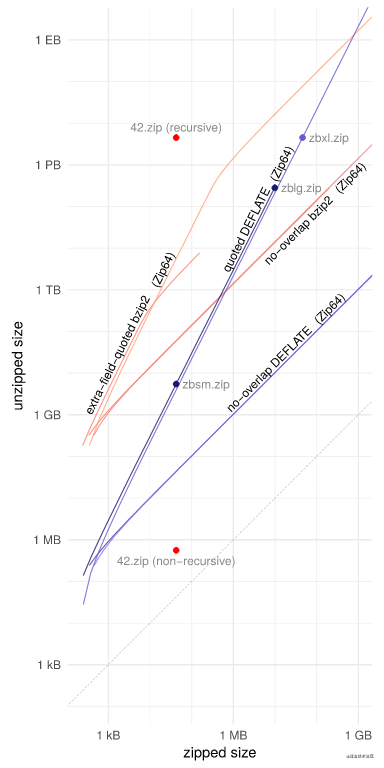
上图说明了将字段外引用与 bzip2 结合使用和不使用 Zip64 的可能性。两条“extra-field-quoted bzip2”行都有一个拐点,在该拐点处,增长从二次曲线过渡到线性曲线。在非 Zip64 的情况下,拐点出现在最大未压缩文件大小 (2 32 − 2 字节); 在这一点之后,只能增加文件的数量,而不能增加它们的大小。当文件数达到 1809 时,该行完全停止,并且我们用完了额外字段中的空间。在 Zip64 的情况下,拐点出现在 1171 个文件处,之后可以增加文件的大小,但不能增加它们的数量。字段外引用也可以与 DEFLATE 一起使用,但改进非常小,因此已从图中省略。将 zbsm.zip的压缩率提高了 1.2%; zblg.zip 增加 0.019%; 和 zbxl.zip 为 0.0025%。
讨论
在相关工作中, Plötz 等人。 使用重叠文件创建近乎自我复制的 zip 文件。Gynvael Coldwind之前曾建议(幻灯片 47)重叠文件。 佩莱格里诺等人。 发现系统容易受到压缩炸弹和其他资源耗尽攻击,并列出了规范、实现和配置中的常见陷阱。
为了兼容性,我们设计了引用重叠 zip 炸弹结构,同时考虑了许多实现差异,其中一些差异如下表所示。生成的构造与以通常的从后到前方式工作的 zip 解析器兼容,首先查询中央目录并将其用作文件索引。其中包括Nail 中包含的示例 zip 解析器,它是从形式语法自动生成的。然而,该构造与“流式”解析器不兼容,这些解析器在不首先读取中央目录的情况下一次通过从头到尾解析 zip 文件。就其性质而言,流解析器不允许任何类型的文件重叠。最可能的结果是他们将只提取第一个文件。此外,它们甚至可能引发错误,就像sunzip的情况一样,它在最后解析中央目录并检查它与它已经看到的本地文件头的一致性。
如果您需要提取的文件以某个前缀开头(例如,以便将它们标识为某种文件类型),您可以在引用下一个标题的块之前插入一个带有数据的 DEFLATE 块。并非每个文件都必须参与炸弹构建:如果您需要 zip 文件符合某种更高级别的格式,您可以在炸弹文件旁边包含普通文件。(源代码有一个--template 选项来促进这个用例。)许多文件格式使用 zip 作为容器;例如 Java JAR、Android APK 和 LibreOffice 文档。
PDF 在许多方面类似于 zip。它在文件末尾有一个交叉引用表,指向文件中较早的对象,并且它支持通过 FlateDecode 过滤器对对象进行 DEFLATE 压缩。迪迪埃·史蒂文斯( Didier Stevens) 写到 在一个 2.6 KB通过堆叠 FlateDecode 过滤器的 PDF 文件。如果 PDF 解析器限制了堆叠数量,那么可能可以使用 DEFLATE 引用思想来重叠 PDF 对象。
中央目录使用另一种称为中央目录结尾(EOCD) 的结构间接定位。EOCD 以可变长度的注释字段结尾,找到它需要扫描一个幻数。libziparchive 通话 过程中的“传统EOCD狙击猎杀” 😃
检测我们在本文中开发的特定类别的 zip 炸弹很容易:查找重叠文件。Mark Adler 已经 为 Info-ZIP UnZip编写了一个补丁,就是这样做的。 但是,一般而言,拒绝重叠文件本身并不能确保处理不受信任的 zip 文件的安全。有不依赖重叠文件的 zip 炸弹,也有不是炸弹的恶意 zip 文件。此外,任何此类检测逻辑都必须在解析器本身内部实现,而不是作为单独的预过滤器。zip 格式描述中省略的细节之一是,没有一个明确定义的算法用于在 zip 文件中定位中央目录:两个解析器可能会找到两个不同的中央目录,因此 甚至可能不同意 zip 文件包含哪些文件 (幻灯片 67-80)。通常,通过对所有文件的大小求和来预测未压缩的总大小是行不通的,因为元数据中存储的大小 可能与 实际的未压缩大小不匹配(第 4.2.2 节)。(请参阅兼容性表中的“允许太短的文件大小”行。)针对 zip 炸弹的强大保护包括对解析器进行沙盒处理以限制其使用时间、内存和磁盘空间——就像您在处理图像文件一样,或者任何其他容易出现解析器错误的复杂文件格式。

| Info-ZIP UnZip 6.0 | Python 3.7 zipfile | 去1.12 档案/邮编 | yauzl 2.10.0 (Node.js) | 指甲 示例/zip | Android 9.0.0 r1 libziparchive | sunzip 0.4 (流媒体) | |
|---|---|---|---|---|---|---|---|
| DEFLATE | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| ZIP64 | ✓ | ✓ | ✓ | ✓ | ✖ | ✖ | ✓ |
| bzip2的 | ✓ | ✓ | ✖ | ✖ | ✖ | ✖ | ✓ |
| 允许不匹配的文件名 | 警告 | ✖ | ✓ | ✓ | ✓ | ✖ | ✓ |
| 允许错误的CRC-32 | 警告 | ✖ | 如果为零 | ✓ | ✖ | ✓ | ✖ |
| 允许太短的文件大小 | ✓ | ✖ | ✖ | ✖ | ✖ | ✖ | ✖ |
| 允许文件大小为2 32 - 1 | ✓ | ✓ | ✓ | ✖ | ✓ | ✓ | ✓ |
| 允许文件数为2 16 - 1 | ✓ | ✓ | ✓ | ✖ | ✓ | ✓ | ✓ |
| unzips overlap.zip | 警告 | ✖ | ✓ | ✓ | ✓ | ✖ | ✖ |
| 解压缩zbsm.zip和zblg.zip | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✖ |
| 解压缩zbxl.zip | ✓ | ✓ | ✓ | ✓ | ✖ | ✖ | ✖ |
选定的 zip 解析器与各种 zip 功能、边缘情况和 zip 炸弹结构的兼容性。背景颜色表示从限制较少到限制较多的比例。为了获得最佳兼容性,请使用没有 Zip64 的 DEFLATE 压缩,匹配中央目录头和本地文件头中的名称,计算正确的 CRC,并避免 32 位和 16 位字段的最大值。
感谢
Mark Adler、 Blake Burkhart、 Gynvael Coldwind、 Russ Cox、 Brandon Enright、 Joran Dirk Greef、 Marek Majkowski、 Josh Wolfe和USENIX WOOT 2019审阅者对本文或草稿的评论。Caolán McNamara 评估了 LibreOffice 中 zip bomb的安全影响。 @m1rko 写了俄文翻译。 北岸冷若冰霜 写了中文翻译。Daniel Ketterer 报告说,--template在添加--giant-steps.
本文的一个版本出现在 USENIX WOOT 2019 研讨会上。提供研讨会谈话 视频、幻灯片和成绩单 。论文的源代码是可用的。 准备提交的工件是zipbomb-woot19.zip。
你有没有发现一个系统会被这些 zip bomb中的一个阻塞?他们是否帮助您展示漏洞或赢得错误赏金? 让我知道,我会试着在这里提到它。
-
LibreOffice 6.1.5.2
zblg.zip 重命名为 zblg.odt 或 zblg.docx 将导致 LibreOffice 在尝试确定文件格式时创建和删除一些 ~4 GB 的临时文件。它最终会完成,并且会在执行过程中删除临时文件,因此它只是一个不会填满磁盘的临时 DoS。Caolán McNamara 回复了我的错误报告。
-
Mozilla 插件服务器 2019.06.06
我针对本地安装的 addons-server 尝试了 zip bomb,它是 addons.mozilla.org 背后软件的一部分。该系统处理它摆好,强加时间限制 的110 秒在提取上。zip bomb的扩展速度与磁盘允许的时间限制一样快,但在那之后,该进程将被终止,解压缩的文件最终会被自动清理。
-
解压 6.0
Mark Adler 为 UnZip编写 了一个补丁来检测此类 zip bomb。
2019-07-05:我注意到CVE-2019-13232 被分配给 UnZip。就我个人而言,我认为 UnZip(或任何 zip 解析器)处理此处讨论的 zip bomb 的能力必然代表安全漏洞,甚至是错误。这是一个自然的实现,不会以我能说的任何方式违反规范。本文中讨论的类型只是 zip bomb的一种类型,并且 zip 解析出错的方式有很多种,但都不是zip bomb。如果要抵御资源耗尽攻击,你应该不尝试枚举、检测和阻止每个已知的攻击;相反,您应该对时间和其他资源施加外部限制,以便解析器无论面临什么样的攻击,都不会表现得过多。尝试检测和拒绝某些构造作为第一遍优化并没有错,但您不能就此止步。如果您最终不隔离和限制对不受信任数据的操作,您的系统可能仍然容易受到攻击。考虑与HTML 中的跨站点脚本进行类比:正确的防御不是尝试过滤掉可能被解释为代码的字节,而是正确地转义所有内容。
Mark Adler 的补丁在错误 #931433 中进入了 Debian 。 有一些意想不到的后果:解析某些 Java JAR 时出现问题(错误 #931895)和 Firefox 的 omni.ja 文件的突变 zip 格式问题(错误 #932404)。SUSE 决定 不对 CVE-2019-13232采取任何措施。我认为 Debian 和 SUSE 的选择都是有道理的。
-
罗诺蒙/拉链
在这篇文章发表后不久,Joran Dirk Greef 发布了一个 限制性的 zip 解析器(JavaScript),它禁止出现文件重叠或文件之间未使用空间等违规行为。虽然它可能因此拒绝某些有效的 zip 文件,但其想法是确保任何下游解析器将只接收干净、易于解析的文件。
-
防病毒引擎
总体而言,恶意软件扫描程序似乎已慢慢开始将此类 zip bomb(或至少可下载的特定样本)识别为恶意。看看检测是健壮的还是脆弱的会很有趣。例如,您可以颠倒中央目录中条目的顺序,然后查看是否仍然检测到 zip 文件。在源代码中,有一个生成 zbsm.extra.zip 的方法,它类似于 zbsm.zip,除了它使用 字段外引用而不是 DEFLATE 引用——如果您是检测 zbsm.zip 的 AV 服务的客户,但是不是 zbsm.extra.zip,你应该要求解释。另一个简单的变体是 在zip bomb文件之间插入间隔文件,这可能会欺骗某些重叠检测算法。
Twitter 用户@TVqQAAMAAAAEAAA 报告 “我的测试机器上的 McAfee AV 刚刚爆发。” 我没有独立确认它,也没有版本号等详细信息。
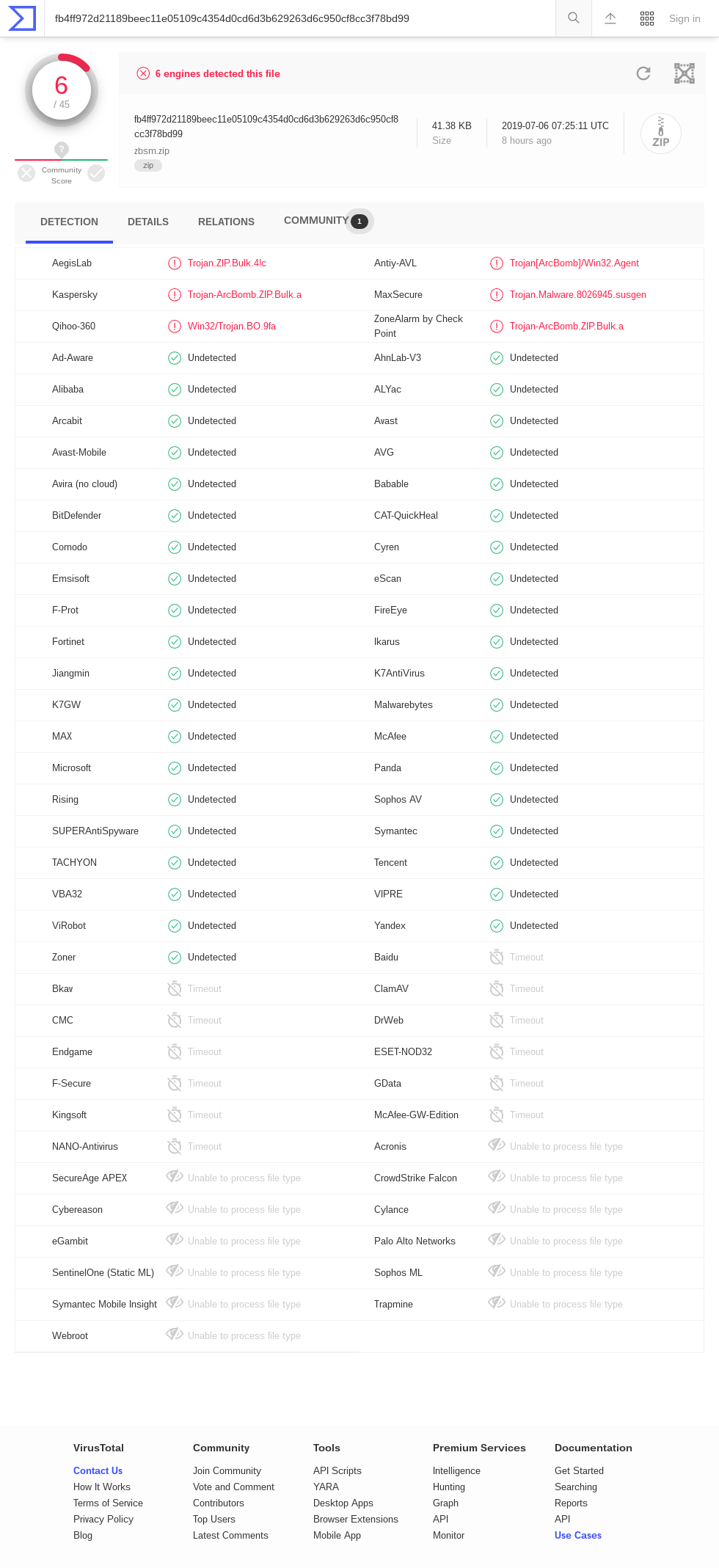
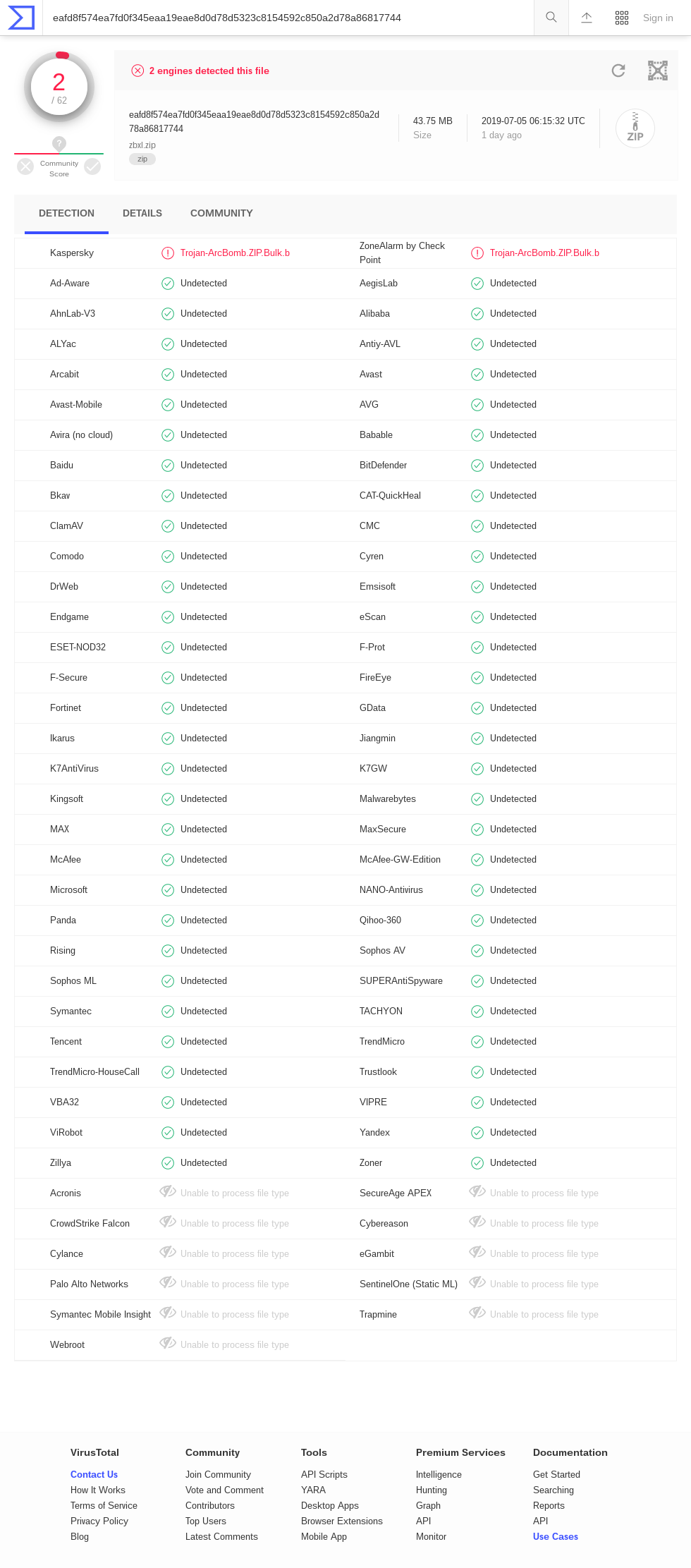
Tavis Ormandy指出 zblg.zip 的 VirusTotal 中有许多“超时”结果 (截图2019-07-06)。 AhnLab-V3、ClamAV、DrWeb、Endgame、F-Secure、GData、K7AntiVirus、K7GW、MaxSecure、McAfee、McAfee-GW-Edition、Panda、Qihoo-360、Sophos ML、VBA32。 zbsm.zip 的结果 (截图2019-07-06) 是相似的,但有一组不同的超时引擎:Baido、Bkav、ClamAV、CMC、DrWeb、Endgame、ESET-NOD32、F-Secure、GData、Kingsoft、McAfee-GW-Edition、NANO-Antivirus、Acronis . 有趣的是, zbxl.zip 的结果中没有超时 ; (截屏2019-07-06) 也许这意味着某些防病毒软件不支持 Zip64?
论坛用户 100报告 某个 ESET 产品未检测到 zbxl.zip,可能是因为它使用 Zip64。三天后线程中的更新显示该产品正在更新以检测它。
在ClamAV 错误 12356 中,Hanno Böck 报告说 zblg.zip 导致 clamscan 中的 CPU 使用率过高。 检测重叠文件 的初始补丁被证明是不完整的, 因为它只检查了相邻的文件对。(我个人通过在错误跟踪器上发布解决方法的详细信息而不是私下报告来错误地处理了这个问题。) 后来的补丁 对文件分析施加了时间限制。
2020-07-28:FlyTech Videos 展示了针对 Windows Defender、Windows Explorer 和 7-zip测试各种 zip bomb(包括zbxl.zip)的 视频。
在我的 Web 服务器日志中,我注意到许多引用者似乎指向错误跟踪器。
- http://jira.athr.ru/browse/WEB-12882
- https://project.avira.org/browse/ENGINE-2307
- https://project.avira.org/browse/ENGINE-2363
- https://topdesk-imp.cicapp.nl/tas/secure/mango/window/4
- https://jira-eng-rtp3.cisco.com/jira/browse/AMP4E-4849
- https://jira-eng-sjc1.cisco.com/jira/browse/CLAM-965
- https://flightdataservices.atlassian.net/secure/RapidBoard.jspa?selectedIssue=FDS-136
- https://projects.ucd.gpn.gov.uk/browse/VULN-1483
- https://testrail-int.qa1.immunet.com/index.php?/cases/view/923720
- http://redmine-int-prod.intranet.cnim.net/issues/5596
- https://bugs.drweb.com/view.php?id=159759
- https://dev-jira.dynatrace.org/browse/APM-188227
- https://webgate.ec.europa.eu/CITnet/jira/browse/EPREL-2150
- https://jira.egnyte-it.com/browse/IN-8480
- https://jira.hq.eset.com/browse/CCDBL-1492
- https://bugzilla.olympus.f5net.com/show_bug.cgi?id=819053
- https://mantis.fortinet.com/bug_view_page.php?bug_id=0570222
- https://redmine.joesecurity.org:64998/issues/4705
- http://dev.maildev.jp/mantis/view.php?id=5839
- https://confluence.managed.lu/pages/viewpage.action?pageId=47974242
- https://jira-lvs.prod.mcafee.com/browse/TSWS-653
- https://jira.modulbank.ru/browse/PV-33012
- http://jira.netzwerk.intern:8080/browse/SALES-81
- https://jira-hq.paloaltonetworks.local/browse/CON-43391
- https://jira-hq.paloaltonetworks.local/browse/GSRT-11680
- https://jira-hq.paloaltonetworks.local/browse/PAN-124201
- https://paynearme.atlassian.net/browse/PNM-4494
- https://jira.proofpoint.com/jira/browse/PE-29410
- https://dev.pulsesecure.net/jira/browse/PRS-379163
- https://qualtrics.atlassian.net/browse/APP-326
- https://jira.sastdev.net/browse/CIS-2819
- https://jira.sastdev.net/secure/RapidBoard.jspa?selectedIssue=EC-709
- https://bugzilla.seeburger.de/show_bug.cgi?id=89294
- https://svm.cert.siemens.com/auseno/create_edit_vulnerability.php?vulnid=48573
- https://jira.sophos.net/browse/CPISSUE-6560
- https://jira.vrt.sourcefire.com/browse/TT-1070
- https://task.jarvis.trendmicro.com/browse/JPSE-10432
- https://segjira.trendmicro.com:8443/browse/SEG-55636
- https://segjira.trendmicro.com:8443/browse/SEG-58824
- https://ucsc-cgl.atlassian.net/secure/RapidBoard.jspa?selectedIssue=SEAB-327
- https://jira.withbc.com/browse/BC-43950
- https://zscaler.zendesk.com/agent/tickets/849971
-
网络浏览器
这个我自己没有直接体验过,不过网上有报道说Chrome和Safari下载后可能会自动解压文件。
- ittakir : "Скачал самый маленький файл на 5GB, Chrome тут же начал его распаковывать, хотя его об этом нерикорить. “我下载了 5GB 的最小文件,Chrome 立即开始解压缩它,虽然它没有被要求,好吧,吃掉处理器和磁盘。”
- Rzah:“下载后打开安全文件是一个愚蠢的网络浏览器默认设置的另一个原因。”
Chromium commit f04d9b15bd1cba1433ad5453bc3ebff933d0e3bb可能是相关的:
添加检测异常高 ZIP 压缩率的指标
即使我们只扫描小的 ZIP 档案,单个 ZIP 条目也可能非常大。这些指标将衡量这种情况发生的频率。
-
文件系统
我没想到的是:在压缩文件系统上解压缩其中一个zip bomb可能相对安全。
- fly_gel:“如果我将其解压缩到压缩的 zfs 数据集上,生成的文件会很小吗?编辑:刚刚用 42KB->5.5GB 的 zip bomb做了一个小测试。我最终得到了 165MB 的文件,所以只有 3%在完整的zip bomb中,它仍然是 4028 倍的膨胀。…我只启用了标准的 LZ4 压缩,没有重复数据删除。”
-
推特
从那时起,这篇文章的链接就在 Twitter 上被广泛分享 2019-07-02,但周围 2019-07-20它开始显示 “不安全链接”插页式广告 (屏幕截图、存档)。
-
安全浏览
某个时候 2019-07-23似乎该页面以及*.bamsoftware.com 域上的每个页面都被添加到 Web 浏览器用来阻止恶意软件和网络钓鱼站点的安全浏览服务中。 网站状态检查, 屏蔽页面截图。从一些快速检查来看,bamsoftware.com 上的页面似乎也已在 google.com 搜索引擎上降级或除名。
Safe Browsing 块有点烦人,因为它破坏了Snowflake,这是一个完全不相关的服务,碰巧使用域 snowflake-broker.bamsoftware.com,它甚至不托管任何文件,但严格来说是一个 Web API 服务器。请参阅#31230 Firefox 插件被 Google 安全浏览服务阻止。
安全浏览块似乎在或之前结束 2019-08-16.
-
Xfinity xFi 保护浏览
在 2019-11-26,我从 Hooman Mohajeri Moghaddam 那里得知 Comcast Xfinity xFi “受保护的浏览” 功能阻止了 bamsoftware.com 域,包括此页面(截图)。
-
D标准.zip
D 编程语言 对std.zip 模块进行了修改 以检测重叠文件。
-
苹果 iOS 和 iPadOS
Dzmitry Plotnikau 向我发送了一份报告,称 zip bomb可能会耗尽运行 iOS 12 和 13 的 iPhone 上的所有缓存存储,即使仅使用“快速查看”打开。存储空间耗尽可能会产生各种副作用,包括行为不当的应用程序、本地云文件的删除和操作系统崩溃,在某些情况下需要恢复出厂设置才能补救。该错误在 iOS 14.0 中得到缓解(可能还有其他同期发布的 iOS 和 iPadOS)。请参阅 “libarchive”标题下的HT211850。
A final plea
原文
It’s time to put an end to Facebook. Working there is not ethically neutral: every day that you go into work, you are doing something wrong. If you have a Facebook account, delete it. If you work at Facebook, quit.And let us not forget that the National Security Agency must be destroyed.















 3093
3093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}