






一。MAC OS下的JDK安装及其路径
1、首先安装jdk,直接百度或者Google搜索就有MAC版本的jdk,本实验环境是jdk1.8.0_66.jdk,Hadoop的安装也必须在jdk 1.6版本以上。
2、MAC中自带有安装的jdk,查看其默认路径如图:
/Java>/System/Library/Frameworks/JavaVM.framework/Versions/Current/Commands/java是系统默认的java路径,但是安装的JDK,会被安装到/Library/Java/JavaVirtualMachines/下面,比如:
/Library/Java/JavaVirtualMachines/jdk1.8.0_66.jdk/,JAVA_HOME是/Library/Java/JavaVirtualMachines/jdk1.8.0_66.jdk/Contents/Home。
二。ssh免密登录

2.在终端中输入:
- 1
- 1
ssh-keygen表示生成秘钥;-t表示秘钥类型;-P用于提供密语;-f指定生成的秘钥文件。这个命令在”~/.ssh/“文件夹下创建两个文件id_dsa和id_dsa.pub,是ssh的一对儿私钥和公钥。接下来,将公钥追加到授权的key中去,输入:
- 1
- 1
3.直接用ssh命令连接本地主机或远程主机时会遇到下列错误提示:
- 1
- 1
则为未打开远程登录。解决方法如下:
更改设置:进入Mac的系统偏好设置 –> 共享 –> 勾选remote login,并设置allow access for all users。再到命令行下输入“ssh localhost”,可以看到ssh成功。
三。Hadoop 2.7下载
1. 进入:http://hadoop.apache.org/releases.html,选择相应版本下载。例如我选择的是binary的hadoop-2.7.3-src.tar.gz

选择source后:

2.下载下来后解压缩,放到自己认为合适的目录下,实验中将其放在了:~/Documents 下,即MAC文稿文件夹下。
四。设置环境变量
1. 在终端中输入:vi ~/.bash_profile
在bash_profile最后面添加环境变量,其类似windows设置java环境变量,此时的JAVA_HOME与开头将的路径设置一样,如下:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_112.jdk/Contents/Home
export JRE_HOME=$JAVA_HOME/jre
export HADOOP_HOME=/Users/time/Documents/hadoop-2.7.3
export HADOOP_HOME_WARN_SUPPRESS=1
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$PATH其中:
- 1
- 1
- 1
- 1
是java的系统环境变量。
- 1
- 1
是配置Hadoop的系统环境变量
- 1
- 1
是防止出现:Warning: $HADOOP_HOME is deprecated的警告错误。
上述环境变量增加完成后,退回到终端,输入:
- 1
- 1
使得环境变量设置生效!
五。配置hadoop-env.sh
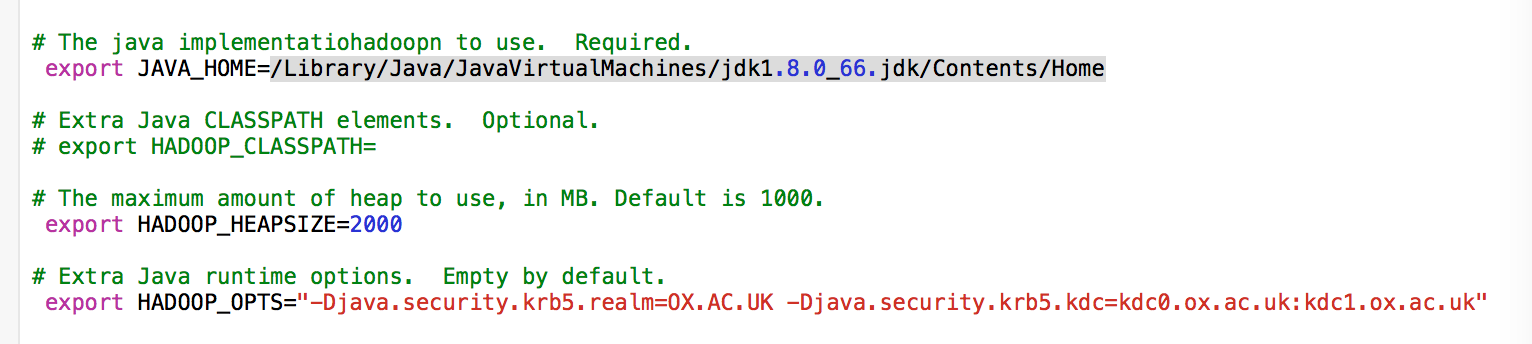
在Hadoop->conf目录下,找到hadoop-env.sh,打开编辑进行如下设置:
export JAVA_HOME=${JAVA_HOME}(去掉注释)
export HADOOP_HEAPSIZE=2000(去掉注释)
export HADOOP_OPTS=”-Djava.security.krb5.realm=OX.AC.UK -Djava.security.krb5.kdc=kdc0.ox.ac.uk:kdc1.ox.ac.uk”(去掉注释)
注意第三个配置在OS X上最好进行配置,否则会报“Unable to load realm info from SCDynamicStore”
配置如图:
1.配置core-site.xml——指定了NameNode的主机名与端口
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/Users/time/Documents/hadoop-2.7.3/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:8000</value>
</property>
</configuration>2. 配置hdfs-site.xml——指定了HDFS的默认参数副本数,因为仅运行在一个节点上,所以这里的副本数为1
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>3. 配置mapred-site.xml——指定了JobTracker的主机名与端口
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>2</value>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>2</value>
</property>
</configuration>
4. yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
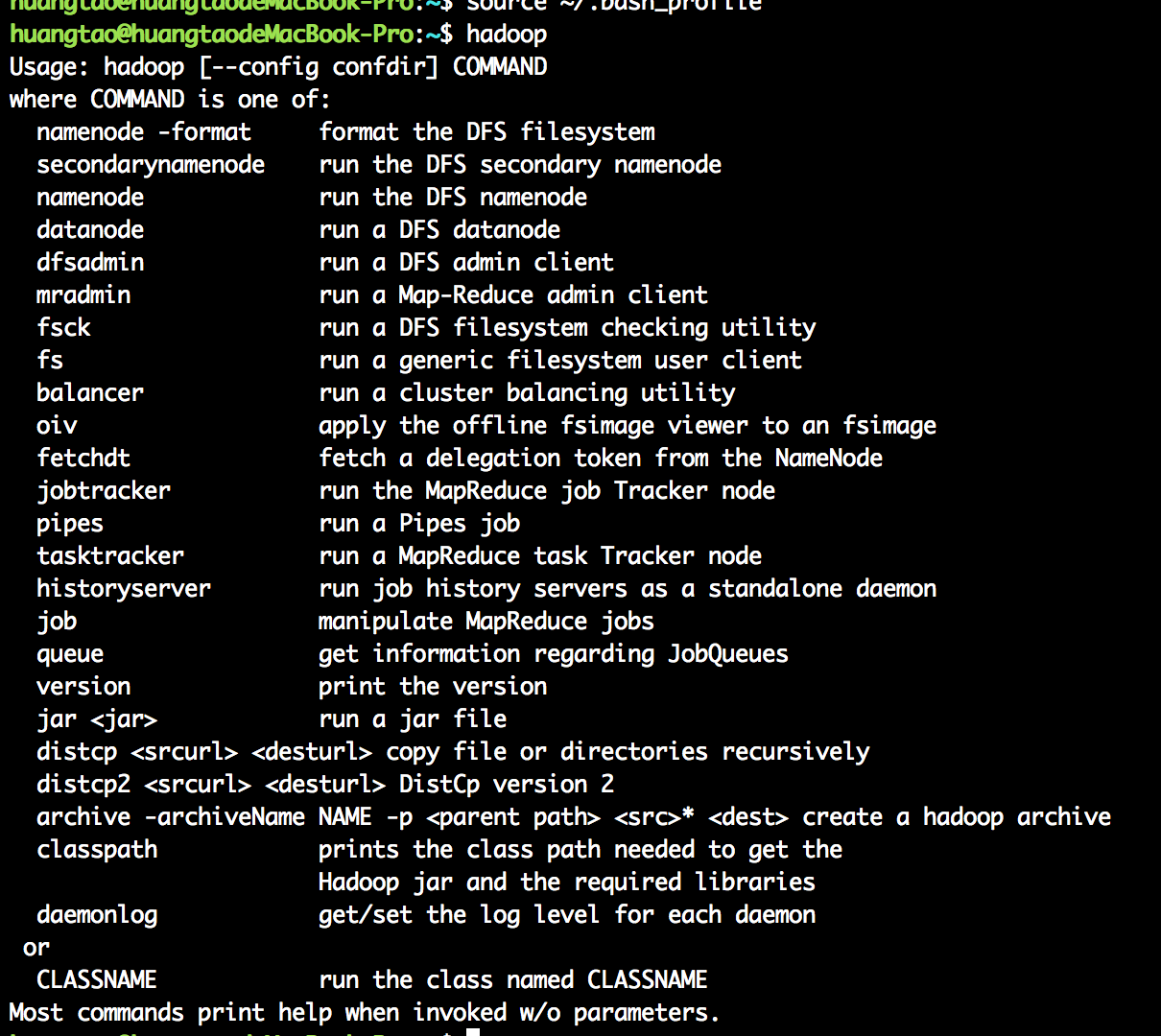
七。至此,在terminal中输入:hadoop,出现如下界面,
表示已经可以找到Hadoop的执行程序。
八。格式化namenode
hdfs namenode -format九。 启动hadoop
1.启动:
sbin/start-all.sh3.输入jps,查看当前进程,如下图所示:
表示Hadoop已经启动。

十。运行测试用例
-
创建hdfs目录:
$ bin/hdfs dfs -mkdir /user $ bin/hdfs dfs -mkdir /user/robin - 拷贝一些文件到input目录:
$ bin/hdfs dfs -put etc/hadoop input - 运行样例:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+' -
在localhost:50070中的Utilities标签下找到/user/robin目录,下载part-r-00000文件,可以看到其中内容如下所示:
4 dfs.class 4 dfs.audit.logger 3 dfs.server.namenode. 2 dfs.period 2 dfs.audit.log.maxfilesize 2 dfs.audit.log.maxbackupindex 1 dfsmetrics.log 1 dfsadmin 1 dfs.servers 1 dfs.replication 1 dfs.file
以上;















 559
559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









