







**爬取豆瓣电影信息,分析近年电影行业的发展情况**
本文是完整的数据分析展现,代码有完整版,包含豆瓣电影爬取的具体方式【附带爬虫豆瓣,数据处理过程,数据分析,可视化,以及完整PPT报告】
最近MBA在学习《商业数据分析》,大实训作业给了数据要进行数据分析,所以先拿豆瓣电影练练手,网络上爬取豆瓣电影TOP250较多,但对于豆瓣电影全数据的爬取教程很少,所以我自己做一版。
目录
1.使用User_Agent,仿造浏览器访问 headers
一、爬取豆瓣电影
1.1认识XPath
先简单介绍下XPath,爬虫的时候会用到,尤其是爬取页面的内容不同时,需要对此进行修改。
lxml是一款高性能的 Python HTML/XML 解析器,我们可以利用XPath,来快速的定位特定元素以及获取节点信息。
xpath的节点关系
每个XML的标签我们都称之为节点,其中最顶层的节点称为根节点。

xpath中节点的关系

选取节点
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
使用chrome插件选择标签时候,选中时,选中的标签会添加属性class=”xh-highlight”
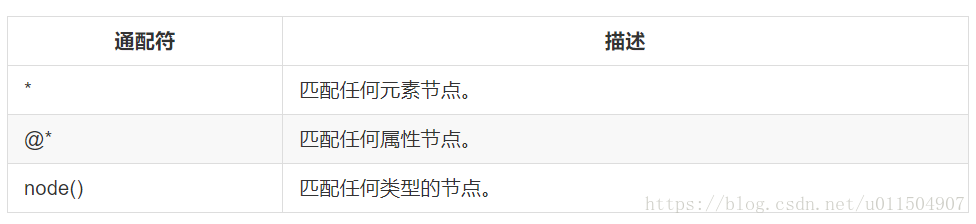
下面列出了最有用的表达式:

实例
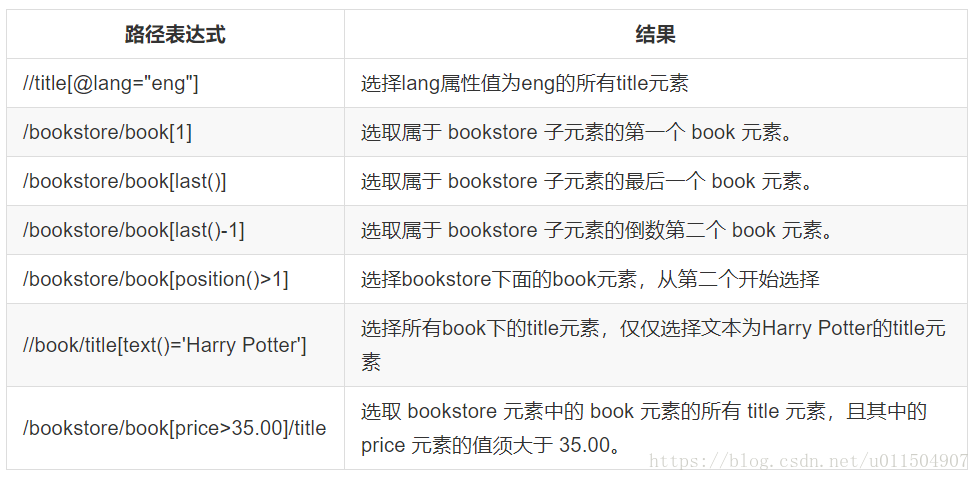
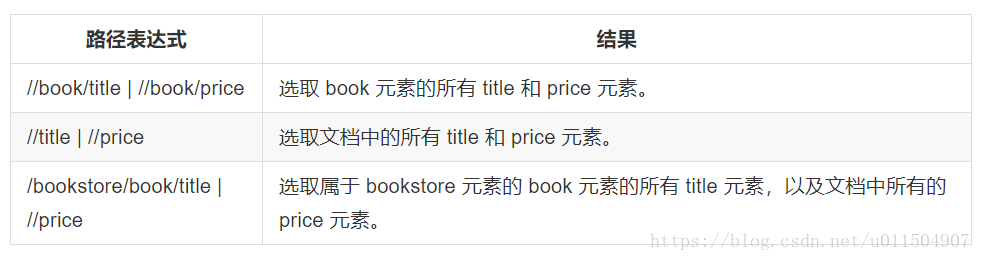
在下面的表格中,已列出了一些路径表达式以及表达式的结果:

xpath基础语法练习:
选择所有的h1下的文本
//h1/text()
获取所有的a标签的href
//a/@href
获取html下的head下的title的文本
/html/head/title/text()
获取html下的head下的link标签的href
/html/head/link/@href
查找特定的节点

1.2豆瓣电影信息
(1)主页数据探索
接下来开始正式爬取豆瓣电影的数据
对应关系如下:

1. sort
排序方式,有三种: U:近期热门排序,T:标记最多排序, R:最新上映排序, S:评价最高排序:
playbale=1:表示可播放
unwatched=1:表示还没看过的
“加载更多”分析
1) 首先要能看网页发回来的JSON数据,步骤如下:
- 打开chrome的“检查”工具
- 切换到network界面
- 选择XHR
- 在页面上点击“加载更多”后会看到浏览器发出去的请求
- Preview界面可以看到接受到的JSON数据
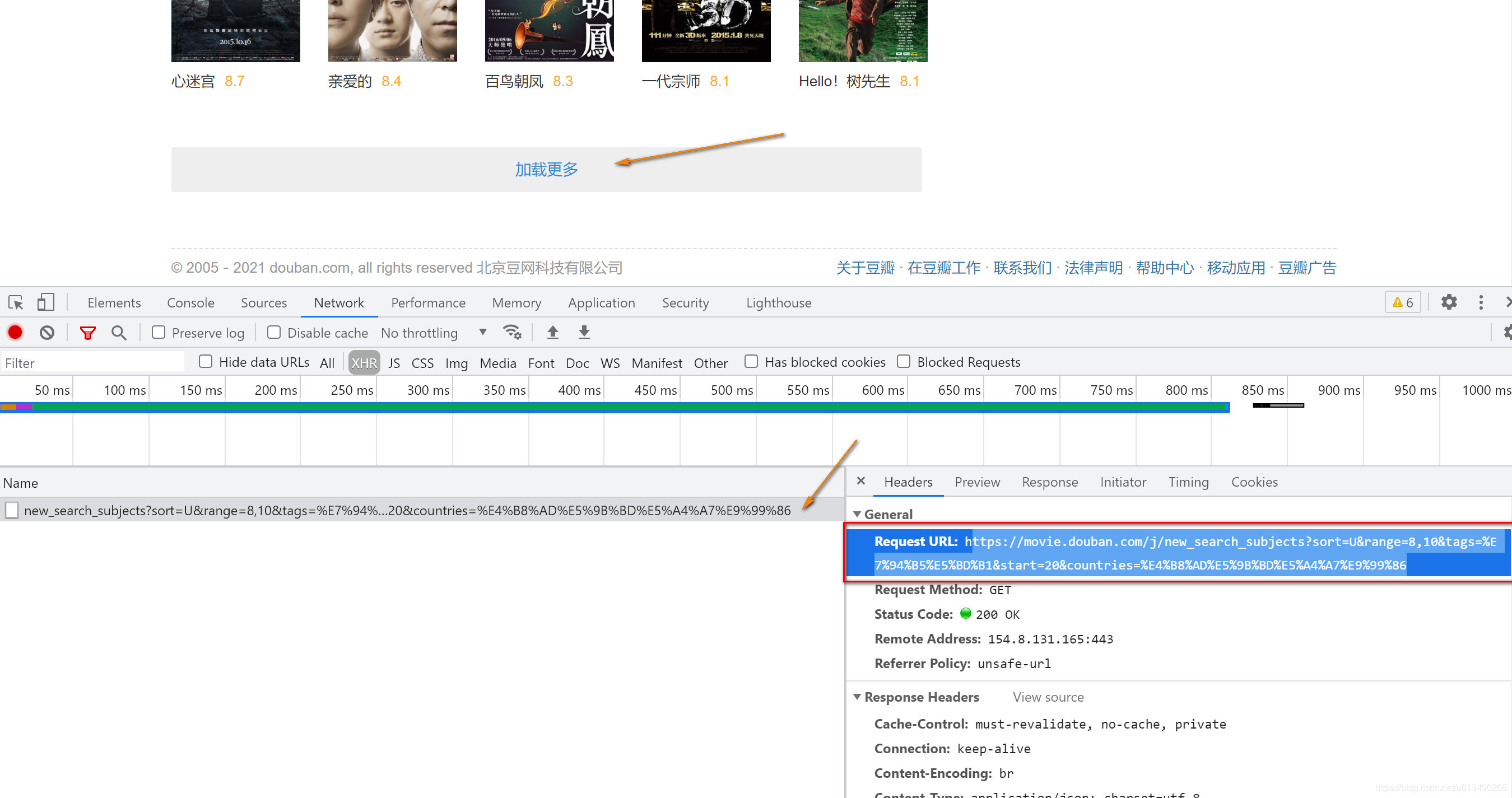
这里可以发现,每次点击“加载更多”,每次会增加显示20个电影,真实URL中的start这个参数从0-20-40…变化,发送回来最新加载出来的20个电影的JSON数据,了解了这些以后,下面就可以用代码实现抓取了。
- page_limit=20 决定请求信息的数量
- page_start=0 决定请求的位置
(2)详细页探索
可以看到,其实主页上已经包含了影片的名称和评分数据,详细的内容还要点击具体的影片,打开如下:

这些都是我们要获取的信息。

通过以上就可以确定超链接位置所在,具体的方法是点击上图红色方框内的“箭头”,之后选择你想获取的信息即可,然后下面就会显示出来。
具体的内容如下,语法见前面内容:
name=html.xpath('//span[@property="v:itemrevi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1859
1859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









