







 本文详细解读Spark论文,探讨Spark如何通过弹性分布式数据集(RDD)改进非周期数据流模型,支持迭代计算和交互式数据分析。RDD作为Spark的核心,提供容错性和高效内存管理,使得Spark在机器学习任务中比Hadoop快10倍,并能在亚秒级别响应39GB数据集的交互查询。此外,文章还讨论了Spark与MapReduce的区别及其优势,包括内存缓存、容错机制和编程模型。
本文详细解读Spark论文,探讨Spark如何通过弹性分布式数据集(RDD)改进非周期数据流模型,支持迭代计算和交互式数据分析。RDD作为Spark的核心,提供容错性和高效内存管理,使得Spark在机器学习任务中比Hadoop快10倍,并能在亚秒级别响应39GB数据集的交互查询。此外,文章还讨论了Spark与MapReduce的区别及其优势,包括内存缓存、容错机制和编程模型。
为了尽可能完整地了解Spark的整个原理,并有一个层次性的认知,找了几篇最初Spark提出的论文来看
论文题目为:Cluster Computing with Working Sets。
一是希望 借此进一步加深对于Spark的理解进而指导之后的使用。
二是闲的 没事可干 那就虐虐自己吧。
首篇论文在这里可下
note: 并非完整翻译,这样也没什么意思,而基本流程是阅读内容–>理解内容–>总结内容–>提出想法吧。当然其中会添加进去一些自己理解相关知识点请的”外援“。
现在正式开始我们的边翻译边理解的进程吧:
摘要:
MapReduce和其一系列变型非常成功地实现商用集群所要求的 大规模 数据密集型应用。然而其中的很大一部分围绕着非循环数据流模型所建设,并不适用于其他一些热门的应用。这篇论文关注的是在多并行操作中对于数据的可复用性。 其中包括:包含迭代过程的机器学习算法和交互型的数据处理工具。 这里提出的名为Spark的新框架在保持和MapReduce同规模 同容错性基础上,很好地支持了上文中所述的两个应用。为了达到这个目的,Spark引入了抽象性:弹性分布式数据集(resilient distributed datsets)即RDD。RDD是只读的,分区的记录集合,其对一组机器可见,同时当其中一个分区丢失后可以进行此分区的重建。在迭代的机器学习任务中Spark十倍优于Hadoop,同时其可在亚秒级别时间中交互式访问39GB数据集。
从摘要可以提出并解决这几个问题:
1. 什么是anayclic data flow model(非周期数据流模型)?
2. Spark提出的初衷是什么?
3. Spark产生这些优势的核心思想是什么?
4. Spark优势何在?
A1. 即为其对于数据的使用和处理无法周期性,数据从一个稳定的来源输入,进行加工处理后,输出到一个稳定的目的地,这是一个单向过程,无法形成数据的环向流动和周期性使用。
A2. 其初衷是为了弥补以MapReduce为主体的Hadoop在涉及迭代和循环这类对于数据有循环使用和处理应用上的不足。
A3. 一个抽象的系统,弹性分布式数据集,RDD。
A4. 不但保持了Hadoop所拥有的能力基础上,增加了1.对于含有迭代思想型应用的支持 2.对于实时交互的满足。
介绍:
集群计算变得普及,其基于自动提供局部性调度,容错,负载均衡的系统,利用并不那么优良的机器集群执行数据的并行计算。MapReduce是完成这类任务模型的首创,像Dryad和MapReduce一般化了对于数据流的支持。他们为使用者提供了一套可编程的模型以实现其可拓展和容错性能,使用者利用这个可编程模型创建非周期数据流图完成对输入数据的一系列操作。底层系统无需用户介入即可完成管理调度同时对错误做出相应反应,这使得使用者可将重心放在对数据的操作上。
从这段获悉这类已有模型有这样几个优势:其实现了在集群上针对数据的并行计算;提供了可编程的模型供使用者操作,并为使用者掩藏了底层繁杂的操作,使得可以专注于应用。
尽管上述这类数据流可编程模型对于很大一部分应用非常给力,但是存在一大类应用无法有效地用非周期数据流来表达。本文志在解决这类上述模型无法解决的问题上:即在多并行操作中要反复使用工作数据集。这包括了:(很多Hadoop使用者反馈Hadoop在这类问题上的低效性)
1. 迭代型工作:大多数的机器学习算法通过在同一数据集上反复应用一函数从而最优化函数参数(例如通过梯度下降)。尽管每一次迭代可以被表达成MapReduce/Dryad工作,然而每一次都需要从磁盘重新加载数据,多么蛋疼啊,这不把io累死。
2. 交互分析:Hadoop常通过像Pig和Hive这样的SQL接口在大数据集上跑ad-hoc搜索查询。理想化而言,用户可以通过大量机器将感兴趣数据加载进内存并反复查询。但是,像Hadoop,由于其作为一个独立的MapReduce来运行并需要从磁盘中加载文件,故每次查询都要承受显著的延迟(数百秒)。
*从上边可以很清楚地看到Hadoopde不足之处
至于为什么Hadoop会有这样的不足,研究下MapReduce的工作方式和原理。*
这篇paper提出了称为Spark的新集群计算框架,….
Spark中主要的抽象就是弹性分布式数据集,其通过一系列机器展现了一个只读的对象分区集合,如果分区丢失可以分分钟重建。用户可以通过机器显式地将一个RDD**缓存到内存**中,并在类MapReduce的并行操作中对其反复使用。RDD通过血统(lineage)的概念来实现容错:如果一个RDD的分区丢失,那么其余RDD拥有充足的信息显示其他RDD如何产生这个分区,进而可以利用未丢失部分对丢失部分进行恢复。
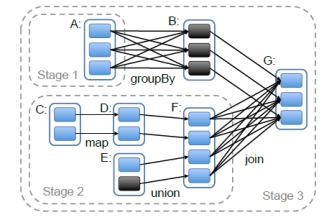
如图,太显然了,除非大规模的丢失,否则其前后均有相应的操作和生成关系,只要找到丢失分区所属的”血统”(lineage),那么再“生”一个太简单。
note:图中大写的ABC..等每个代表一个RDD,其中的小颜色矩形代表RDD中的分区。本来在这篇文章实现的Spark中不包括groupBy,join这类操作的,这是作者针对实现"shuffle"的下一步操作。
尽管RDD并非一般性的共享内存的抽象,其在表达力这方面和可拓展性以及可靠性方面找到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









