







前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见1000个问题搞定大数据技术体系
目录
思维导图
正文
6 评估
原文翻译
我们通过在 Amazon EC 2 上进行一系列的实验以及用用户的应用做基准测试来评估 Spark,总的来说,下面是我们的结论:
- 在迭代式机器学习和图计算中,spark 以 20 倍的速度超过了 hadoop。提速的点主要是在避免了 I / O 操作以及将数据以 java 对象的形式存在内存中从而降低了反序列化的成本。
- 用户写的应用程序运行平稳以及很好扩展。特别的,我们利用 Spark 为一个分析报表相对于 hadoop 来说提速 了 40 倍。
- 当节点失败的时候,Spark 可以通过重新计算失去的 RDD 分区数据达到快速的恢复。
- Spark 在查询 1 TB 的数据的时候的延迟可以控制在 5 到 7 秒。
我们通过和 hadoop 对比,展示迭代式机器学习(6.1 节)和 PageRank(6.2 节)的基准测试。
然后我们评估了 Spark 的错误恢复机制(6.3 节)以及当内存不足以存储一个数据集的行为(6.4 节),最后我们讨论了用户应用(6.5 节)和交互式数据挖掘(6.6 节)的结果
除非另外声明,我们都是用类型为 m1.xlarge 的 EC 2 节点,4 核以及 15 GB 内存。
我们使用数据块大小为 256 M 的 HDFS 存储系统。
在每一次测试之前,我们都会清理 OS 的缓存,以达到准确的测量 IO 成本的目的
解析
关于具体的评估内容不需要过多关注,只需要了解 Spark 官方曾经提出的结论:
Apache Spark 相比于 Apache Hadoop
单纯使用硬盘来计算快 10 倍,
使用内存来加速,会快 100 倍!
6.1 迭代式机器学习应用
原文翻译
我们实现了两种迭代式机器学习应用,线性回归核 K - means,来和下面的系统进行性能的对比:
- Hadoop:版本号为 0.20.0 的稳定版。
- HadoopBinMem:这个系统在迭代的一开始会将输入数据转换成底开销的二进制形式,这样可以为接下来的迭代消除解析文本数据的开销,并且将数据存储在 hdfs 实例的内存中。
- Spark:我们的 RDDs 的实现。
我们在 25-100 台机器上存储 100 G 数据,两种算法都是对这 100 G 数据跑 10 次迭代。
两个应用之间的关键不同点是他们对相同数据的计算量不一样。
K-means 的迭代时间都是花在计算上,然而线性回归是一个计算量不大,时间都是花在反序列化和 I/O 上。
由于典型的机器学习算法都是需要上千次的迭代来达到收敛,所以我们将第一次迭代花的时间和接下来的迭代时间分开显示。
我们发现通过 RDDs 的共享数据极大的提高了后续的迭代速度。
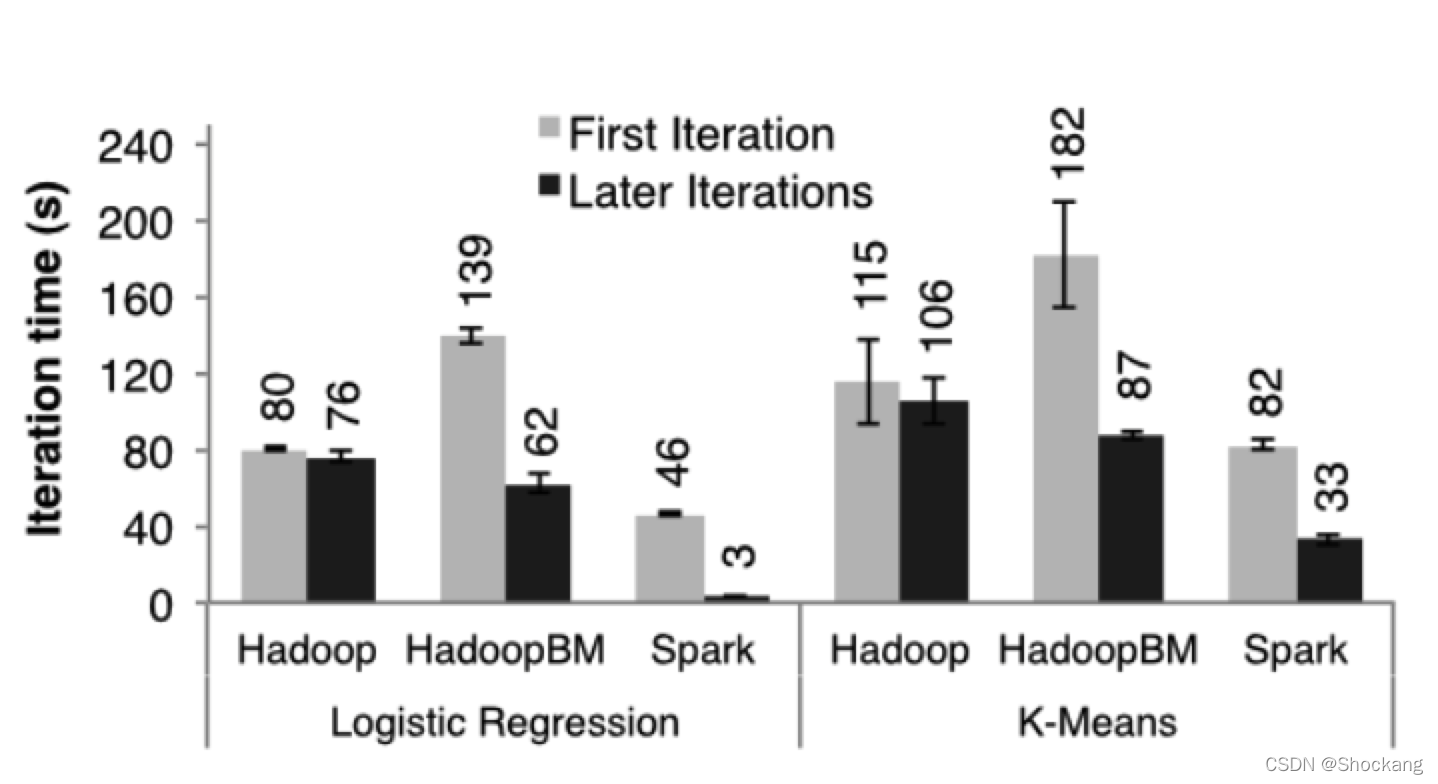
图七:在 100 台机器的集群上分别用 hadoop 、 hadoopBinMem 以及 spark 对 100 GB 的数据进行,线性回归和 k - means 的首次迭代和随后迭代花的时间
首次迭代
三个系统在首次迭代中都是读取 HDFS 中的数据,从图七的条形图中我们可以看出,在实验中,spark 稳定的比 hadoop 要快。
这个是由于 hadoop 主从节点之间的心跳信息的信号开销导致的。
HadoopBinMen 是最慢的,这个是因为它启动了一个额外的 MapReduce 任务来将数据转换为二进制,它还需要通过网络传输数据以达到备份内存中的数据的目的。
随后的迭代
图七也显示了随后迭代花的平均时间。
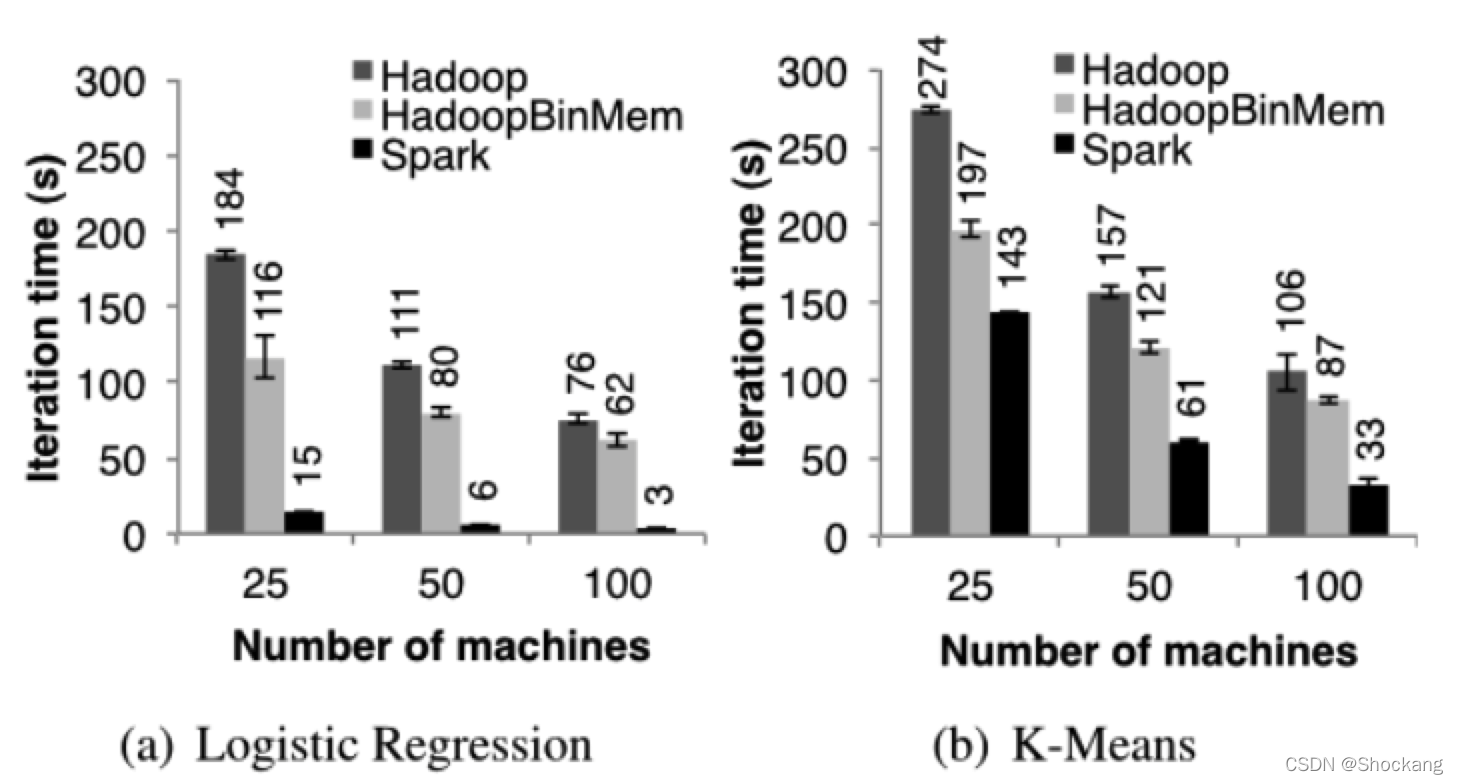
图八: hadoop 、 hadoopBinMem 以及 spark 在随后的迭代花的时间,都是处理 100 G 的数据
图八则是显示了集群大小不断扩展时候花费的时间。
对于线性回归,在 100 台机器上,spark 分别比 hadoop 和 hadoopBinMem 快上 25.3 倍和 20.7 倍。
对于计算型的 k - means 应用,spark 仍然分别提高了 1.9 倍和 3.2 倍。
理解为什么提速了
我们惊奇的发现 spark 甚至比基于内存存储二进制数据的 hadoopBinMem 还要快 20 倍。
在 hadoopBinMem 中,我们使用的是 hadoop 标准的二进制文件格式(sequenceFile)和 256 m 这么大的数据块大小,以及我们强制将 hadoop 的数据目录放在一个内存的文件系统中。
然而,Hadoop 仍然因为下面几点而比 spark 慢:
- Hadoop 软件栈的最低开销。
- HDFS 提供数据服务的开销。
- 将二进制数据转换成有效的内存中的 java 对象的反序列化的成本开销。
我们依次来调查上面的每一个因素。
为了测量第一个因素,我们跑了一些空的 hadoop 任务,我们发现单单完成 job 的设置、任务的启动以及任务的清理等工作就花掉了至少 25 秒钟。
对于第二个元素,我们发现 HDFS 需要执行多份内存数据的拷贝以及为每一个数据块做 checksum 计算。
最后,为了测试第 3 个因素,我们在单机上做了一个微型的基准测试,就是针对不同文件类型的 256 M 数据来跑线性回归计算。
我们特别的对比了分别从 HDFS 文件(HDFS 技术栈的耗时将会很明显)和本地内存文件(内核可以很高效的将数据传输给应用程序)中处理文本和二进制类型数据所话的时间。
图九展示的事我们的测试结果。
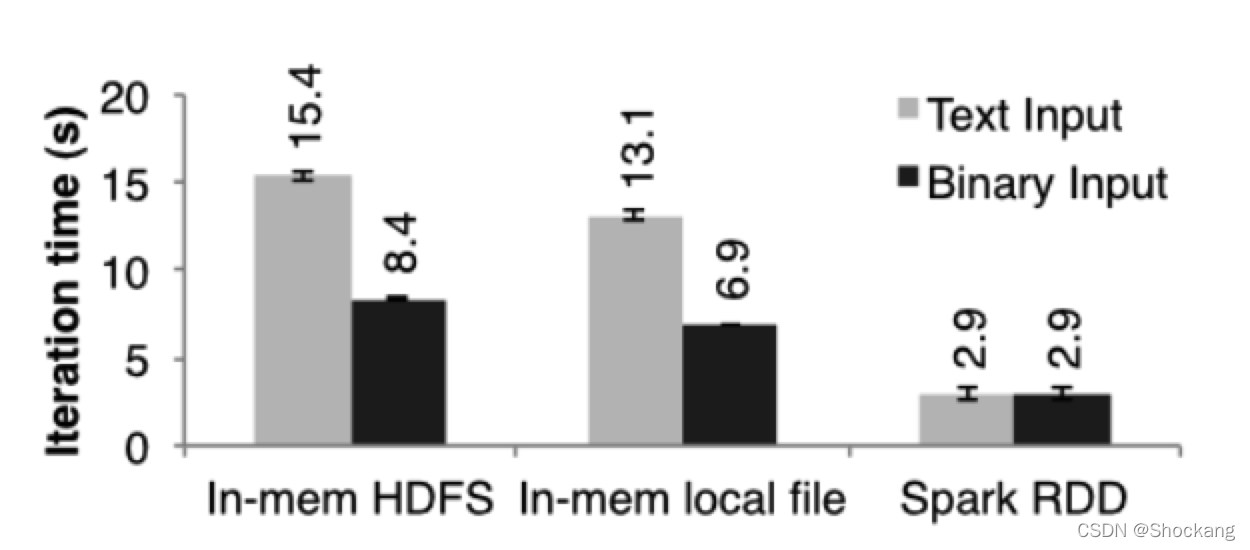
图九:不同机器上面来自不同的输入源 256 MB 数据 逻辑回归的迭代时间
从 In - memory HDFS(数据是在本地机器中的内存中)中读数据比从本地内存文件中读数据要多花费 2 秒钟。
解析文本文件要比解析二进制文件多花费 7 秒钟。
最后,即使从本地内存文件中读数据,但是将预先解析了二进制数据转换成 java 对象也需要 3 秒钟,这个对于线性回归来说也是一个非常耗时的操作。
Spark 将 RDDs 所有元素以 java 对象的形式存储在内存中,进而避免了上述说的所有的耗时。
6.2 PageRank
原文翻译
我们分别用 spark 和 hadoop 对 54 GB 的维基百科的转储数据进行了 PageRank 机器学习,并比对了它们的性能。
我们用 PageRank 的算法处理了大约 4 百万相互连接的文章,并进行了 10 次迭代。
图十展示了在 30 个节点上,只用内存存储使得 spark 拥有了比 hadoop 2.4 倍的性能提升。
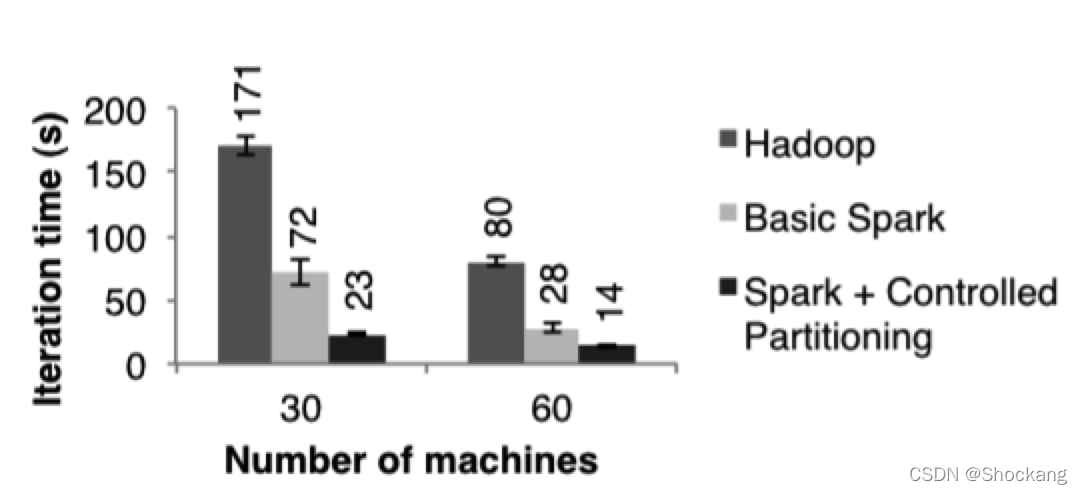
图十:分别基于 Hadoop 和 spark 的 PageRank 的性能对比
另外,就和 3.2.2 小节讨论的,如果控制 RDD 的分区使的迭代之间数据的平衡更可以使的性能速度提升到 7.2 倍。
将节点数量扩展到 60 个,spark 的性能速度提升也是上面的结果。
我们也评估了在第 7.1 节中提到的用我们基于 spark 而实现的 Pregel 重写的 PageRank。
迭代次数和图十是一样的,但是慢了 4 秒钟,这个是因为每一次迭代 Pregel 都要跑额外的操作来让顶点进行投票决定是否需要结束任务。
6.3 容错
原文翻译
我们评估了当在 k - means 应用中一个节点失败了而利用 RDD 的血缘关系链来重建 RDD 的分区需要的成本。
图十一对比的是在 75 个节点中运行 10 次迭代的 k - means 正常情况和在第 6 次迭代一个节点失败的情况。
如果没有任何失败的话,每一次迭代都是在 100 GB 的数据上跑 400 个 tasks。
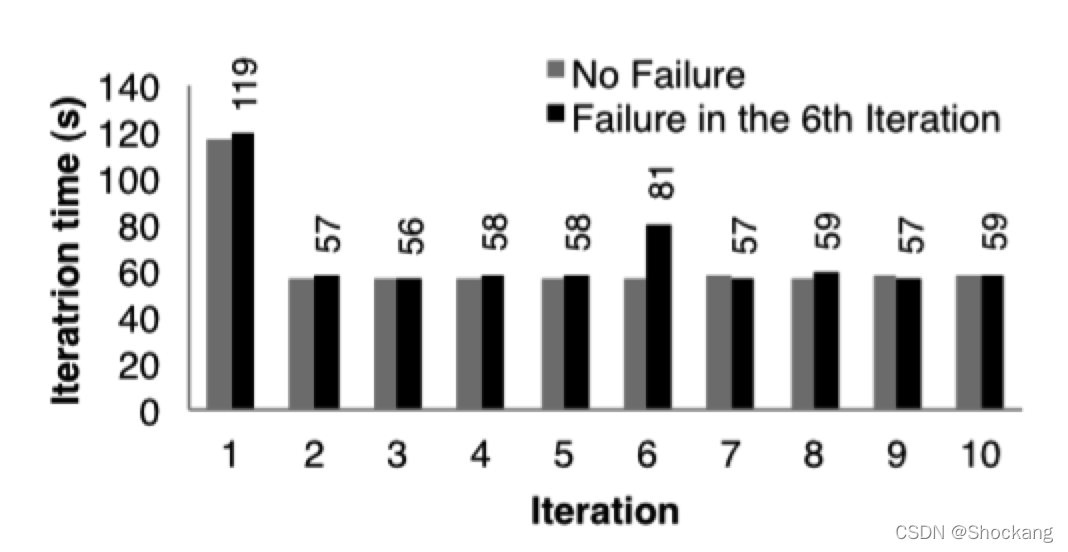
图十一:出现了失败的 k - means 每次迭代时间。在第 6 次迭代中一台机器被杀掉了,导致需要利用血缘关系链重建 RDD 的部分分区。
第五次迭代的时间是 58 秒。
在第 6 次迭代,一台机器被杀死了,导致丢失了运行在这台机器上的 tasks 以及存储在这台机器上的 RDD 分区数据。
Spark 在其他机器节点上重新读取相应的输入数据以及通过血缘关系来重建 RDD,然后并行的重跑丢失的 tasks,使的这次迭代的时间增加到 80s。
一旦丢失的 RDD 分区数据重建好了,迭代的时间又回到了 58s。
需要注意的是,如果是基于 checkpoint 的容错机制的话,那么需要通过重跑好几个迭代才能恢复,需要重跑几个取决于 checkpoints 的频率。
此外,系统需要通过网络传输来备份应用需要的 100GB 数据(被转化为二进制的文本数据),以及为了达到在内存中备份数据而消耗掉 2 倍的内存,或者等待将 100GB 数据写入到磁盘中。
与此相反的是,在我们的例子中每一个 RDDs 的血缘关系图的大小都是小于 10KB 的。
6.4 内存不足的行为
原文翻译
在目前为止,我们都是假设集群中的每一台机器都是有足够的内存来存储迭代之间的 RDDs 的数据的。
当没有足够的内存来存储任务的数据的时候 spark 是怎么运行的呢?
在这个实验中,我们给 spark 每一个节点配置很少的内存,这些内存不足以存储的下 RDDs。
我们在图十二中,我们展示了不同存储空间下的运行线性回归应用需要的时间。
可以看出,随着空间的减少,性能速度慢慢的下降:
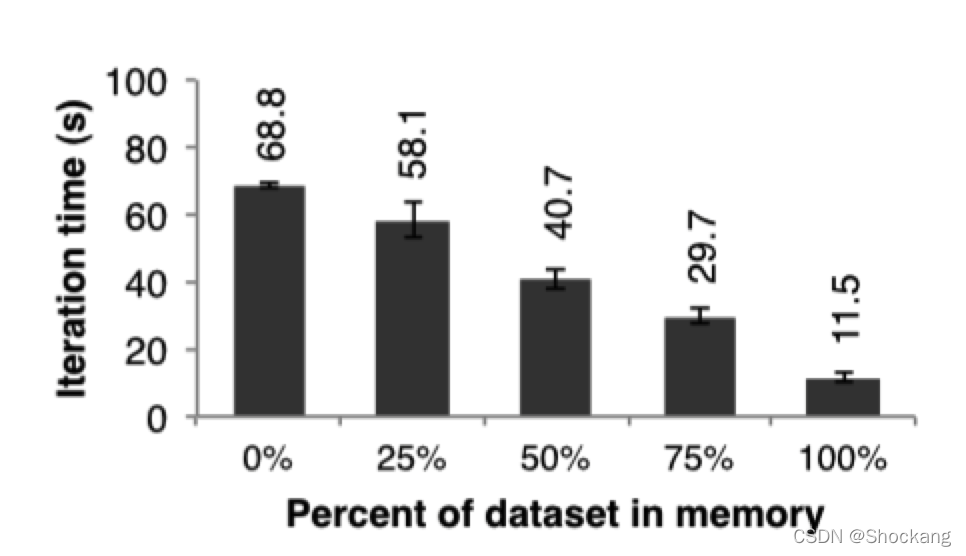
十二:每次都是使用不同的内存,然后在 25 台机器中对 100 GB 的数据运行线性回归的性能对比图
6.5 用 spark 构建的用户应用
原文翻译
内存中分析
Conviva Inc 是一个视频提供商,他们用 spark 来加速之前在 hadoop 上运行的几个数据报表分析。
比如,其中一个报表是运行一系列的 Hive 查询来计算一个用户的各种统计信息。
这些查询都是基于相同的数据子集(基于自定义的过滤器过滤出来的数据)但是需要很多 MapReduce 任务来为分组字段进行聚合运算(平均值、百分位数值以及 count distinct)。
将这些数据子集创建成一个可以共享的 spark 中的 RDD 来实现这些查询使的这个报表的速度提升了 40 倍。
对 200 GB 已经压缩的数据在 hadoop 集群上跑这个报表花了 20 个小时,但是利用 2 台机器的 spark 只用了 30 分钟而已。
此外,spark 程序只花了 96 G 的内存,因为只需要将报表关心的列数据存储在内存中进行共享就行,而不是所有的解压后的数据。
交通模型
伯克利分校的 Mobile Millennium 项目组的研究员在收集到的零星的汽车的 GPS 信息上并行运行一个机器学习算法试图推断出道路交通是否拥挤。
在都市区域道路网络中的 10000 条道路和 600000 个装有 GPS 设备的汽车点对点的旅行时间(每一条路线的旅行时间可能包含了多条道路)样本是数据源。
利用交通模型可以估算出通过每一条独立的道路需要多长时间。
研究人员利用 EM 算法来训练模型,这个算法在迭代的过程中重复执行 map 和 reduceByKey 步骤。
这个应用近似线性的将机器规模从 20 台扩展到 80 台,每台机器 4 个 cores,如图 13(a)所示。
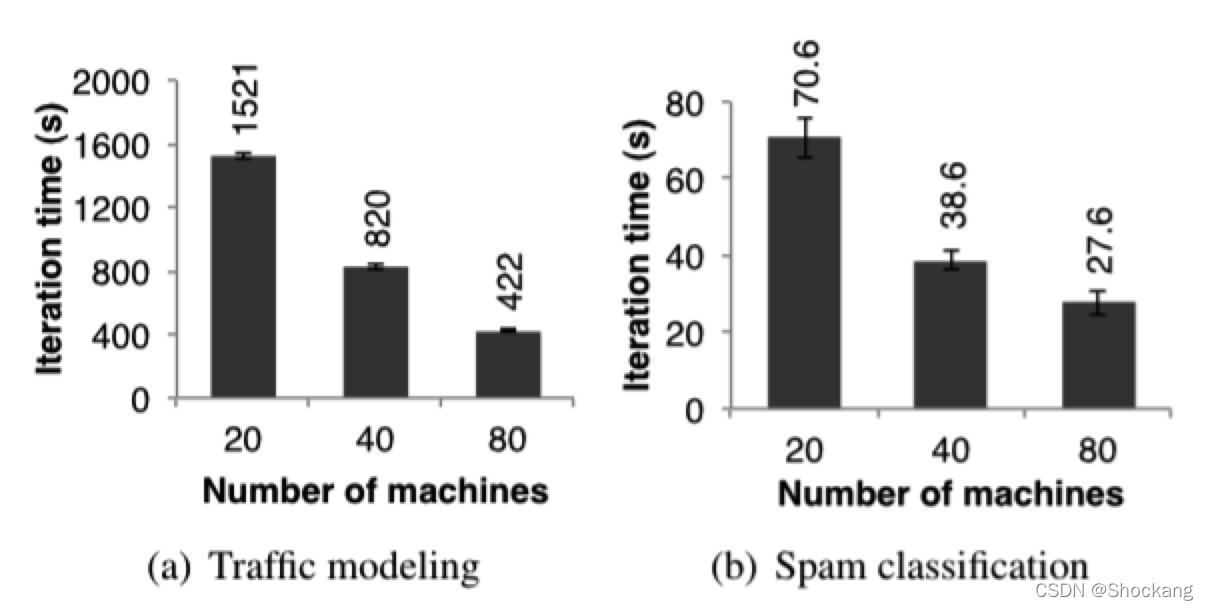
图十三:两个用 spark 实现的用户应用的每次迭代的时间,误差线表示标准误差
推特垃圾邮件分类
伯克利分校的 Monarch 项目利用 spark 来标记推特消息中的垃圾链接。
它们实现的线性回归分类器和第 6.1 节中很相似,但是他们利用了分布式的 reduceByKey 来并行的累加梯度向量值。
图 13(b) 中显示了对 50 GB 的数据子集进行分类训练需要的时间(随着机器扩展),这个数据子集中包含了 25000 URLs 以及每一个 url 对应的页面的网络和内容属性相关的 10000000 个特征/纬度。
图 13(b) 中的时间不是线性的下降是因为每一次迭代花费了很高的且固定的通讯成本。
6.6 交互性的数据挖掘
原文翻译
为了演示 spark 在交互查询大数据集的能力,我们来分析 1 TB 的维基页面访问日志数据(2 年的数据)。
在这个实验中,我们使用 100 个 m 2.4 xlarge EC 2 实例,每一个实例 8 个 cores 以及 68 G 内存。
我们查询出
- 所有页面的浏览量
- 页面标题等于某个单词的页面的浏览量
- 页面标题部分的等于某个单词的页面的浏览量。
每一个查询都是扫描整个输入数据集。
图十四展示的分别是查询整个数据集、一半数据集一集十分之一的数据集的响应时间。
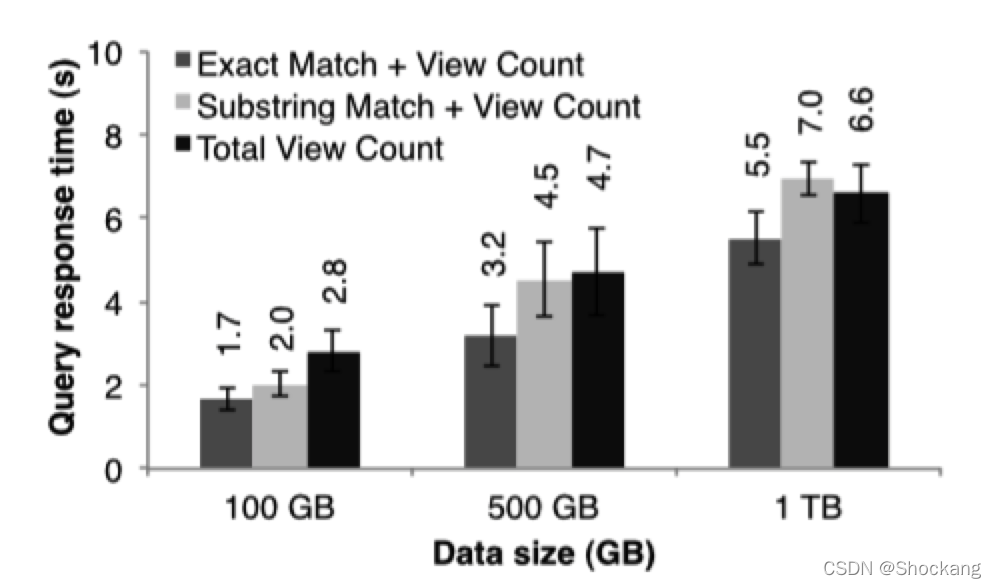
图14:对 Spark 上交互式查询的响应时间,扫描100台机器上越来越大的输入数据集。
即使是 1 TB 的数据,用 spark 来查询仅仅花了 5-7 秒而已。
这个比查询磁盘数据的速度快了一个数量级,比如,查询磁盘文件中的 1 TB 数据需要 170 秒。
这个可以说明 RDDs 使得 spark 是一个非常强大的交互型数据挖掘的工具。
















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









