









接上篇《22.Hystrix Dashboard的使用(上)》 Spring Cloud版本为Finchley.SR2版
上一篇我们简单介绍了Hystrix Dashboard是什么,以及如何使用Hystrix Dashboard来以图形化界面的方式来显示单体应用的API监控。
本篇我们继续讲解,如何Hystrix Dashboard的集群监控。
本部分官方文档:https://cloud.spring.io/spring-cloud-static/Finchley.SR4/single/spring-cloud.html#_turbine
注:好像Finchley.SR2的文档已经挂了,最新的是Finchley.SR4的文档。
回顾一下之前使用Hystrix Dashboard实现单体应用监控图形化展示的步骤:
1、创建一个Spring Boot工程,引入spring-cloud、hystrix、hystrix-dashboard以及actuator的依赖。
2、在启动类中,添加“@EnableHystrixDashboard”注解,以开启仪表盘功能。
3、在resource文件夹下创建配置application.yml的基本配置项(应用名和应用端口)
4、访问“http://localhost:2001/hystrix”,可以看到Dashboard主页面,输入要监控工程的hystrix.stream监控地址即可看到监控页面。
其实上面的原理我们不难理解,就是使用hystrix.stream服务可以查看该应用实例API的监控状况,而Hystrix Dashboard做的就是将hystrix.stream服务中的监控状况的JSON进行了判断、分析,并以一个图形化界面的方式展示出来。
我们知道,在生产环境中应用往往是集群部署的,监控单个实例的意义不大。而Spring Cloud提供的Turbine就是将监控信息进行聚合,并将聚合的监控信息提供给Hystrix Dashboard进行集中的展示和监控的组件,使用它可以实现监控整个集群的效果。
下面我们来实现一个使用Turbine聚合监控信息的Hystrix Dashboard。
1、创建一个名为“microserver-hystrix-dashboard-turbine”的Spring Boot工程: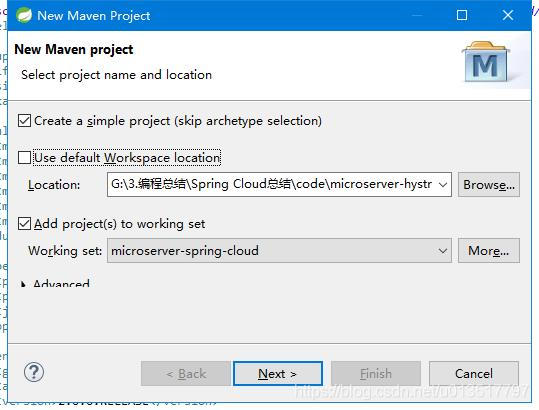
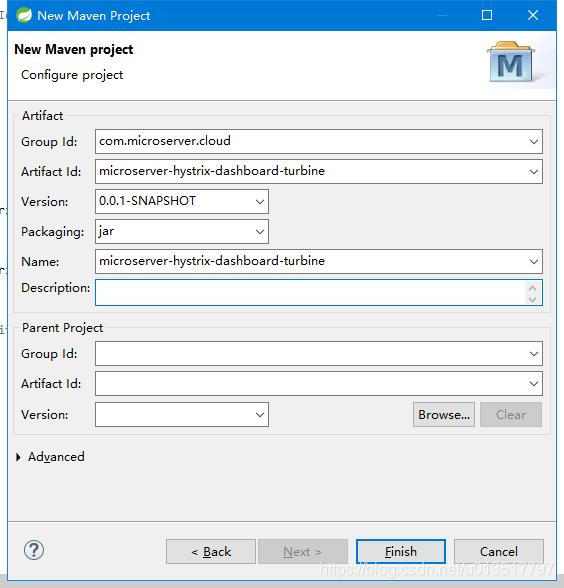
2、创建好工程之后,在工程的pom.xml中,新增Spring Cloud的父工程,以及turbine、actuator的依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.microserver.cloud</groupId>
<artifactId>microserver-hystrix-dashboard-turbine</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>microserver-hystrix-dashboard-turbine</name>
<parent>
<groupId>com.microserver.cloud</groupId>
<artifactId>microserver-spring-cloud</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-turbine</artifactId>
</dependency>
</dependencies>
</project>注意,这里为了便于版本统一管理,该工程的parent父工程和我们User、Movie工程一样,均依赖于microserver-spring-cloud工程(此父工程统一引入了spring-cloud-dependencies的Finchley.SR2版,这个在前面的章节已经讲过)。
父工程pom.xml的modules中别忘记加入这个新工程(microserver-hystrix-dashboard-turbine):
<modules>
<module>microserver-provider-user</module>
<module>microserver-consumer-movie</module>
<module>microserver-discovery-eureka</module>
<module>microserver-discovery-eureka-high-availability</module>
<module>microserver-hystrix-dashboard</module>
<module>microserver-hystrix-dashboard-turbine</module>
</modules>创建完毕之后工程结构如下: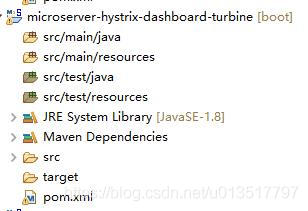
3、新建启动类,在启动类中,添加“@EnableTurbine”注解,以开启Turbine功能:
package com.microserver.cloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.turbine.EnableTurbine;
@SpringBootApplication
@EnableTurbine
public class MicroserverTurbineApplication {
public static void main(String[] args) {
SpringApplication.run(MicroserverTurbineApplication.class, args);
}
}4、然后在resource文件夹下创建application.yml,配置以下参数:
spring:
application:
name: microserver-turbine
server:
port: 2002
eureka:
client:
serviceUrl:
defaultZone: http://user:password123@eureka1:8761/eureka
instance:
prefer-ip-address: true
turbine:
app-config: microserver-consumer-movie
cluster-name-expression: "'default'"
combine-host-port: true除了应用的应用名和服务端口号,我们还添加了eureka的注册中心地址,是为了将我们的Turbine服务注册到注册中心,并同时可以通过eureka Server获得其他应用的信息。
然后下面的turbine的几个参数的解释:
(1)turbine.app-config指定要监控的应用名字,多个可以使用逗号隔开。上面我们监控的是“microserver-consumer-movie”服务。
(2)turbine.cluster-name-expression=default,表示集群的名字为default
(3)turbine.combine-host-port=true表示同一主机上的服务通过host和port的组合来进行区分,默认情况下是使用host来区分,这样会使本地调试有问题。
5、检验
我们上面的服务创建完成之后,启动原来的eureka-server、服务消费者movie和服务提供者user,其中movie启动两个实例,两个实例的端口不一致(7901、7902),然后再启动hystrix-dashboard和turbine: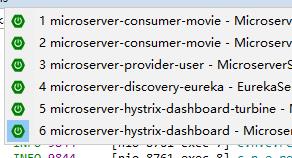
此时在eureka-server首页可以看到:
可以看到我们分别启动了一个服务提供者user,和两个服务消费者movie,还有我们的监控信息聚合服务turbine。
turbine提供聚合服务的访问节点为“turbine.stream”,这里我们可以访问“http://localhost:2002/turbine.stream”看一下: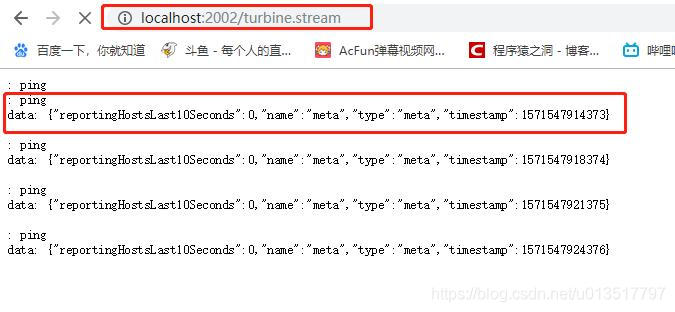
可以看到,该节点在一直不停在ping,但是没有结果,我们分别连续访问一下两个端口的服务消费者movie: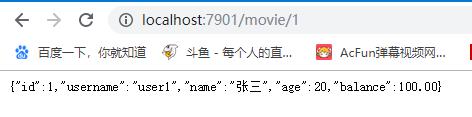
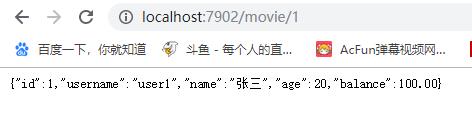
然后回到turbine.stream节点,可以看到Turbine收集到了监控信息:
此时我们打开hystrix-dashboard首页,将turbine.stream的监控端点粘贴进去: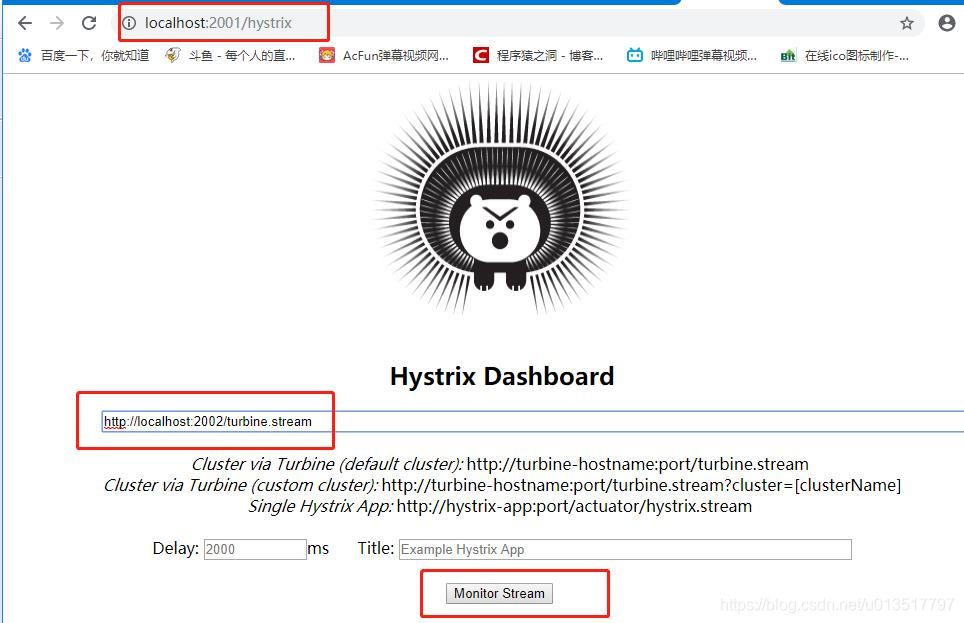
点击“Monitor Stream”按钮,就可以看到监控Movie集群的图形化面板了: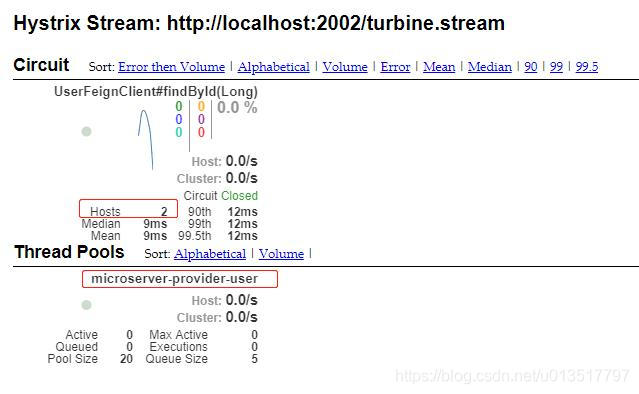
我们可以看到,Turbine将两个相同微服务(不同端口)的监控信息聚合在一起显示,可以通过“hosts”看到有几个端口的服务在运行,这里是“2”,表示我们启动了两个“microserver-provider-user”服务。
如果我们想再监控其它的服务,可以修改application.yml,为“turbine.app-config”参数再添加一个服务实例的名称即可。
如果我们想将Eureka的serviceId用作dashboard的集群名称。这可以通过设置turbine.aggregator.clusterConfig来完成(去掉cluster-name-expression的default配置):
turbine:
app-config: microserver-consumer-movie
combine-host-port: true
aggregator:
cluster-config:
- MICROSERVER-CONSUMER-MOVIE然后我们可以通过点击/clusters端点来检查Turbine应用程序中当前已配置的集群:
可以通过将turbine.endpoints.clusters.enabled设置为false来禁用此端点。
所以,现在我们可以通过Eureka ID访问turbine.stream服务,在有多个Eureka ID的集群时,来查看单个服务集群的情况,例如:http://localhost:2002/turbine.stream?cluster=MICROSERVER-CONSUMER-MOVIE: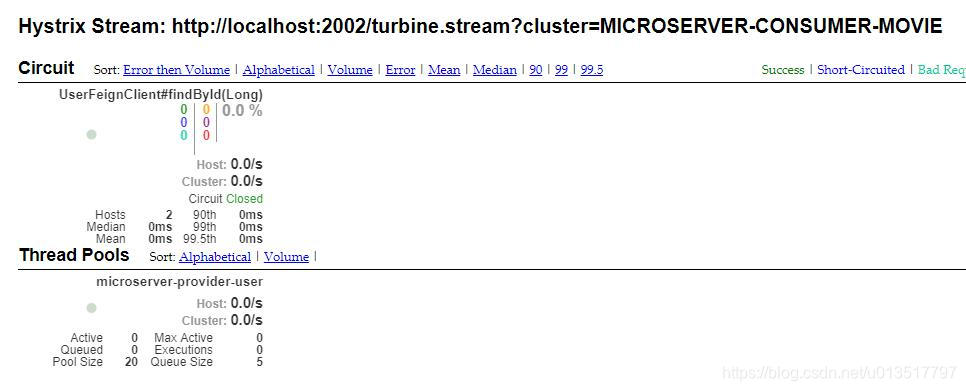
这样如果有许多Eureka ID对应的集群,Turbine将按照集群进行分拣并将其显示在结果中。
本部分源码下载地址:https://download.csdn.net/download/u013517797/11888180
参考:《51CTO学院Spring Cloud高级视频》
https://my.oschina.net/xiaominmin/blog/1788456
https://www.cnblogs.com/liululee/p/10989256.html
转载请注明出处:https://blog.csdn.net/acmman/article/details/102648397















 2591
2591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











