







前言:
最近在研究短文本的自动摘要生成,在试验测试方面国内外研究学者普遍使用Rouge评价体系如 Rouge-1、Rouge-2、Rouge-L 今天我们就讲一下他的python实现。
你去百度搜索资料看到各种配置各种安装啊 如下:特别麻烦

其实不用这么麻烦
如果你只是单纯的使用Rouge-1、Rouge-2、Rouge-L这三个评价体系的话实现很简单
步骤1:使用pip安装rouge
pip install rouge步骤二 计算生成文本与 参考文本的Rouge值
# coding:utf8
from rouge import Rouge
a = ["i am a student from china"] # 预测摘要 (可以是列表也可以是句子)
b = ["i am student from school on japan"] #真实摘要
'''
f:F1值 p:查准率 R:召回率
'''
rouge = Rouge()
rouge_score = rouge.get_scores(a, b)
print(rouge_score[0]["rouge-1"])
print(rouge_score[0]["rouge-2"])
print(rouge_score[0]["rouge-l"])以上就是计算一对数据的Rouge的值如下
{'p': 1.0, 'f': 0.7272727226446282, 'r': 0.5714285714285714}
{'p': 1.0, 'f': 0.6666666622222223, 'r': 0.5}
{'p': 1.0, 'f': 0.6388206388206618, 'r': 0.5714285714285714}f:F1值 p:查准率 R:召回率 这和我们在论文中看到的值可是不一样,论文中都是一个 这里为什么是三个 那像论文中的值应该怎么计算那?
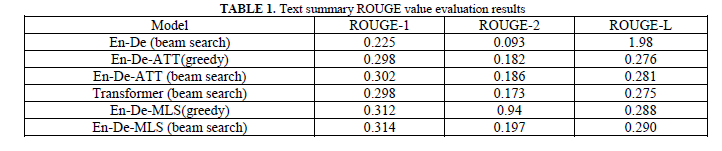
步骤三:Rouge值得选取和选取原理
-------------------------------------------------------------------------------原理---------------------------------------------------------------------------
Rouge(Recall-Oriented Understudy for Gisting Evaluation),是评估自动文摘以及机器翻译的一组指标。它通过将自动生成的摘要或翻译与一组参考摘要(通常是人工生成的)进行比较计算,得出相应的分值,以衡量自动生成的摘要或翻译与参考摘要之间的“相似度”。
Rouge-1、Rouge-2、Rouge-N的定义是这样的

分母是n-gram的个数,分子是参考摘要和自动摘要共有的n-gram的个数。
举个例子:
the cat was found under the bed #生成的摘要the cat was under the bed #参考摘要两者n-gram的计算

所以 对于Rouge1和Rouge2应该就是n-gram下召回率Recall
Rouge-L
L即是LCS(longest common subsequence,最长公共子序列)的首字母,因为Rouge-L使用了最长公共子序列。Rouge-L计算方式如下图:


本博客参考:
https://www.jianshu.com/p/2d7c3a1fcbe3
https://blog.csdn.net/qq_25222361/article/details/78694617
-------------------------------------------------------------------------原理-------------------------------------------------------------------------------------















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









