






基于贪吃蛇强化学习的策略损失分析与需求锚定
一、实验复盘:当奖励规则复杂化时,模型究竟在“学”什么?
在《强化学习RL-NPC复杂奖励机制的陷阱与需求简化策略》一文中,我揭示了复杂奖励机制导致模型性能退化的现象。
本文将从训练曲线可视化的视角,解析这一现象背后的深层逻辑,并为AI产品经理提供可落地的需求管理框架。
核心问题:
为什么看似合理的复杂规则,反而让AI变得更“笨”?
二、数据可视化:四张图看懂复杂规则的“失效路径”
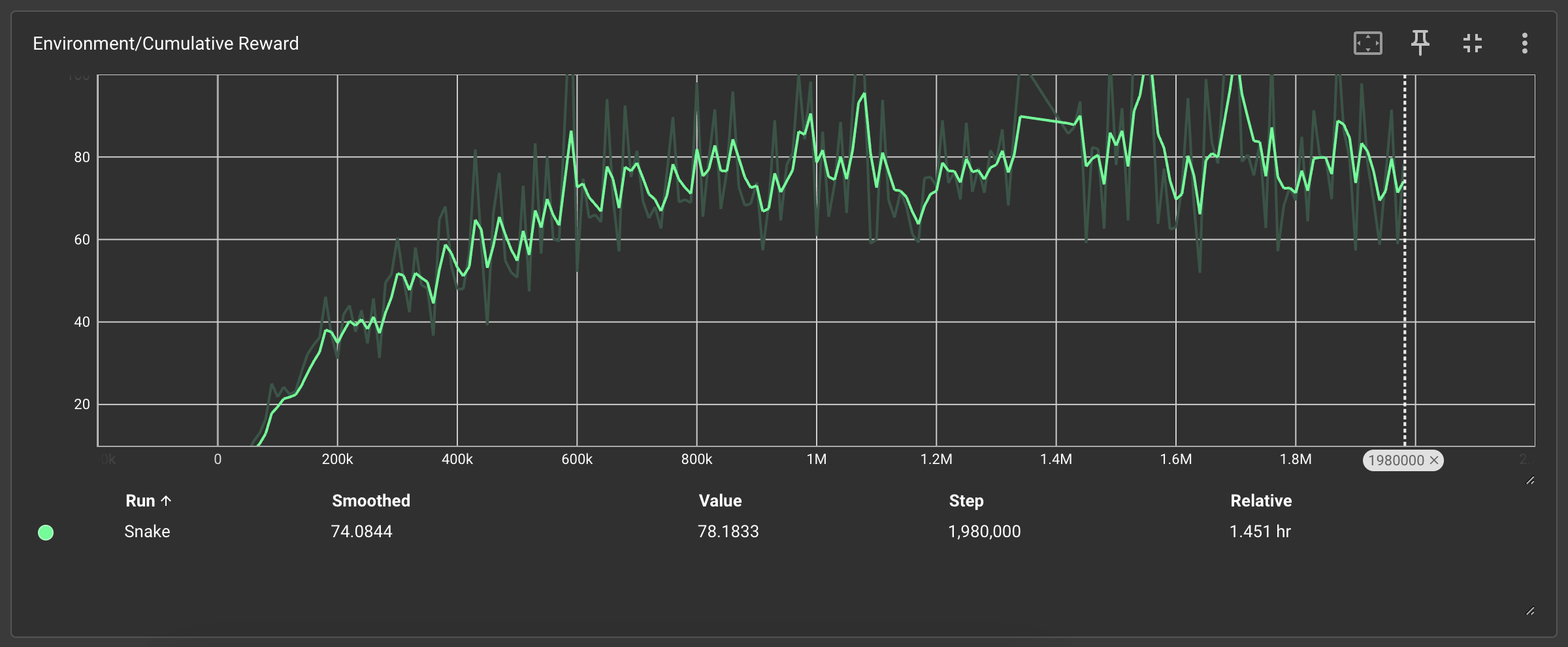
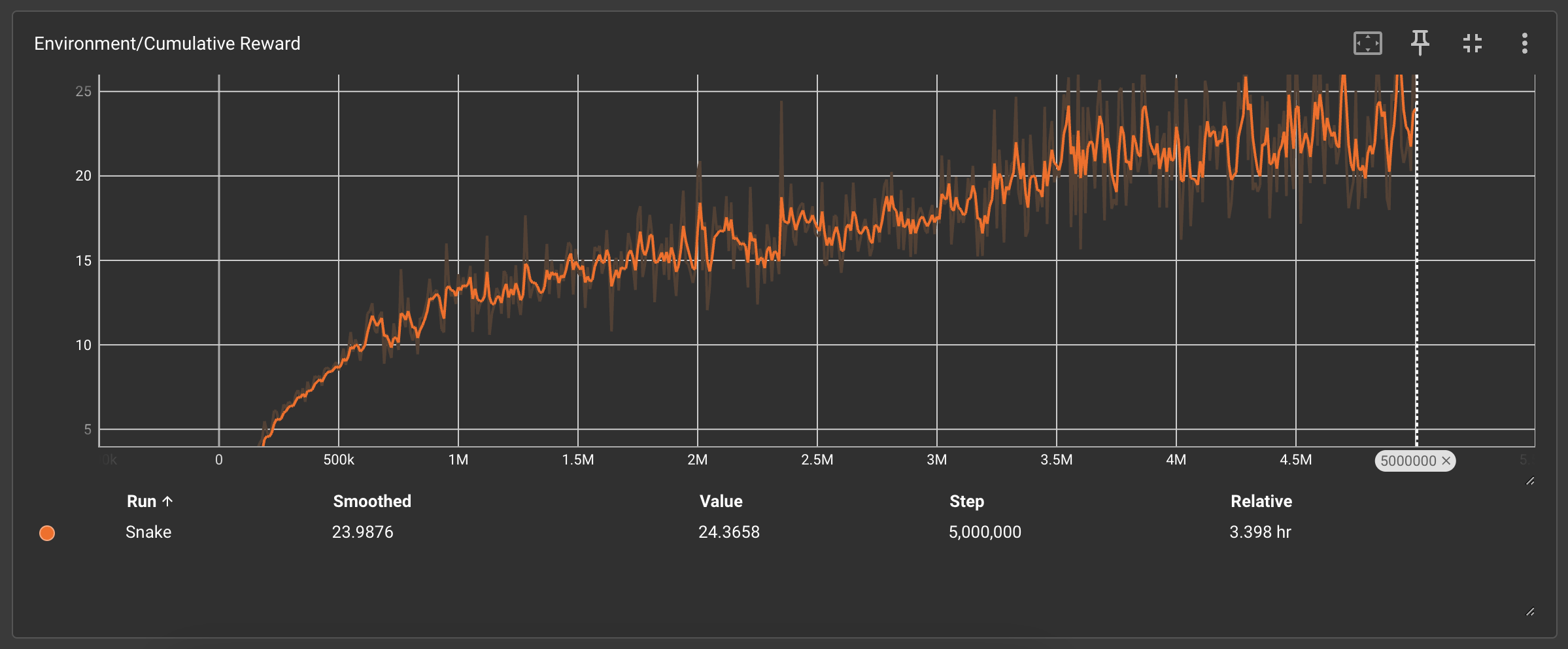
1、Environment/Cumulative Reward(累积奖励曲线)
-
对比分析:
-
🟩 简单规则(4条):奖励随训练步数稳步上升,198万次后趋于稳定(78.2分)
-
🟧 复杂规则(8条):奖励初期短暂上升后剧烈震荡,最终稳定在24.4分
-
-
产品启示:
复杂规则导致模型无法建立稳定的奖励预期,需警惕需求膨胀对技术方案的干扰。
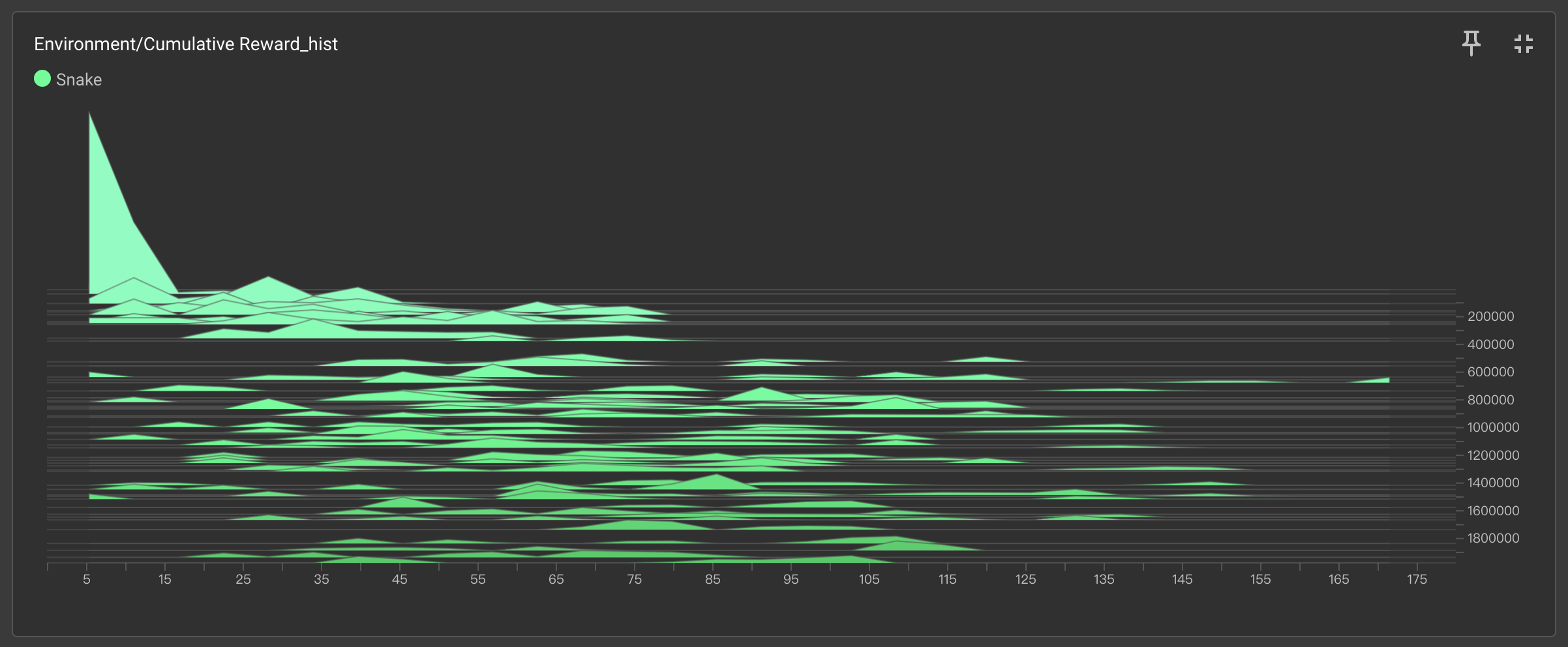
2、Environment/Cumulative Reward_hist(奖励分布直方图)
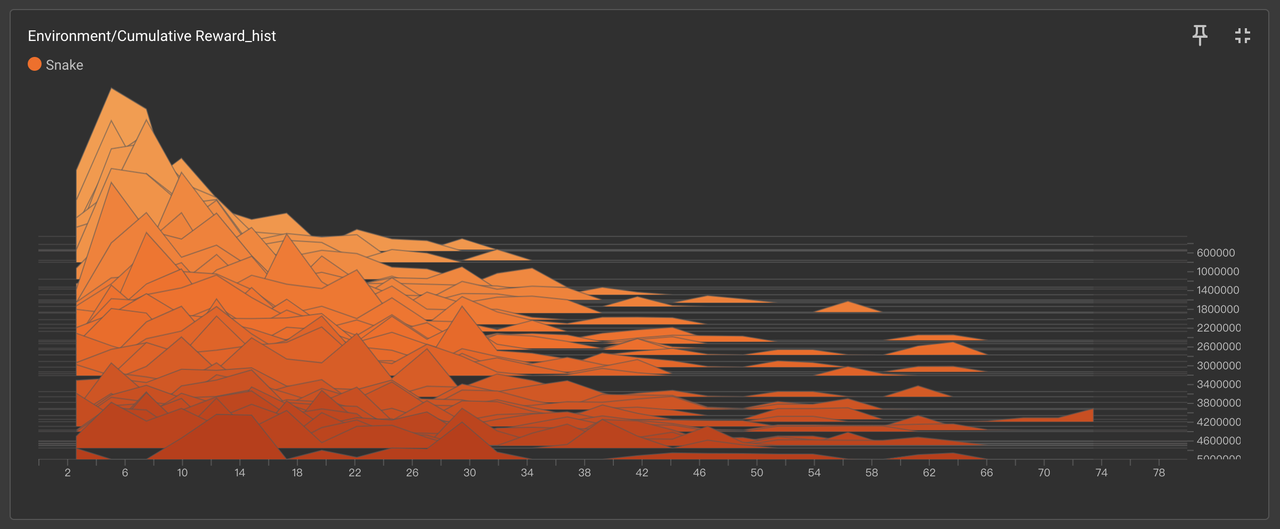
-
关键发现:
-
🟩 简单规则奖励集中在中高区间(40-80分)
-
🟧 复杂规则奖励呈双峰分布(低分20-30分占比65%,偶发高分60+)
-
-
技术归因:
复杂规则下模型陷入局部最优,仅靠随机探索偶获高分,证明规则冲突导致策略失焦。
3、Environment/Episode Length(单局步长曲线)
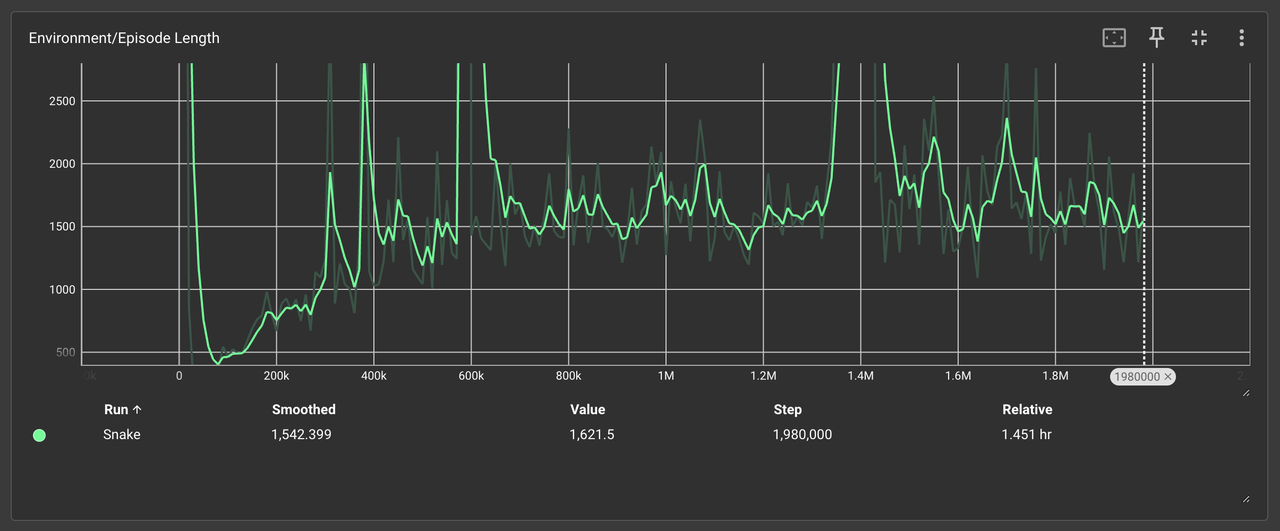
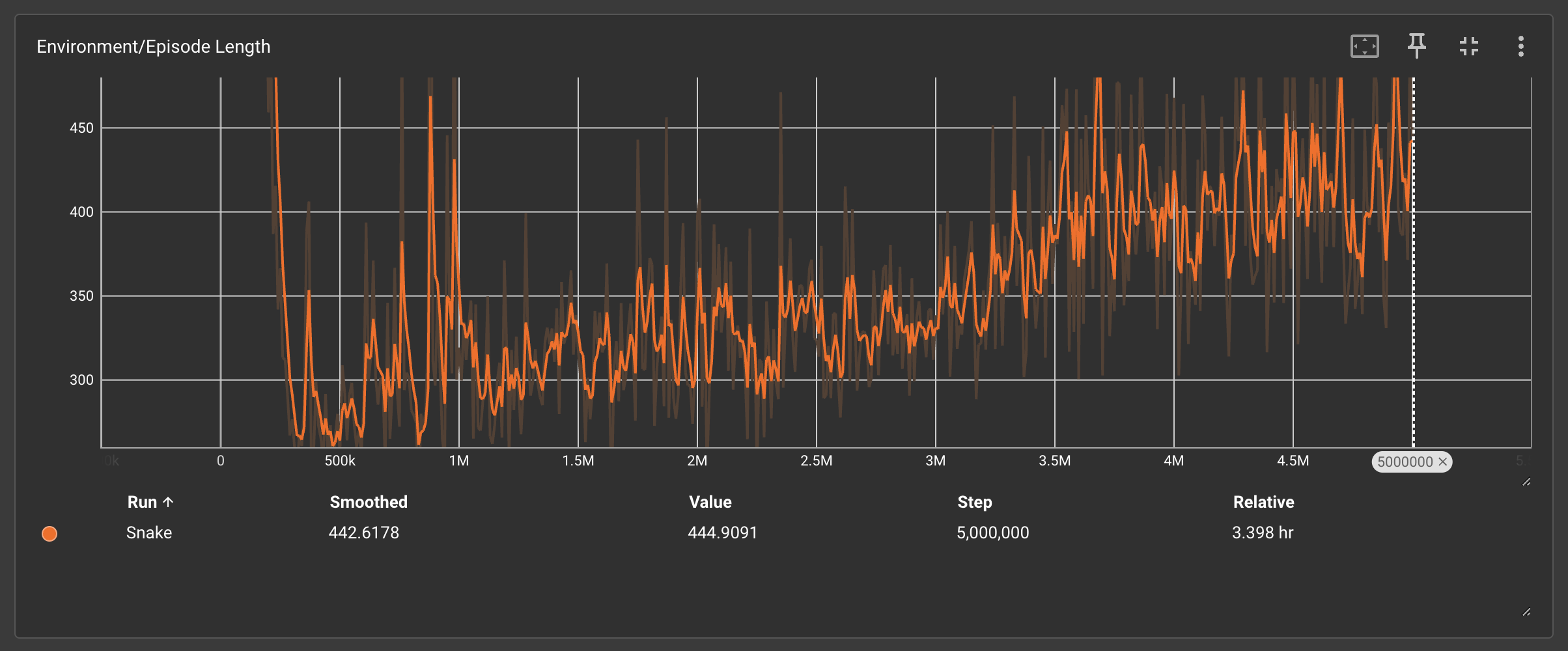
-
行为模式映射:
-
🟩 简单规则:步长随训练增加,AI主动探索环境(最长步数1200+)
-
🟧 复杂规则:步长快速收敛至300-500,AI采取保守绕圈策略
-
-
决策逻辑:
复杂规则中的“生存奖励”促使AI优先延长存活时间,牺牲探索与觅食效率。
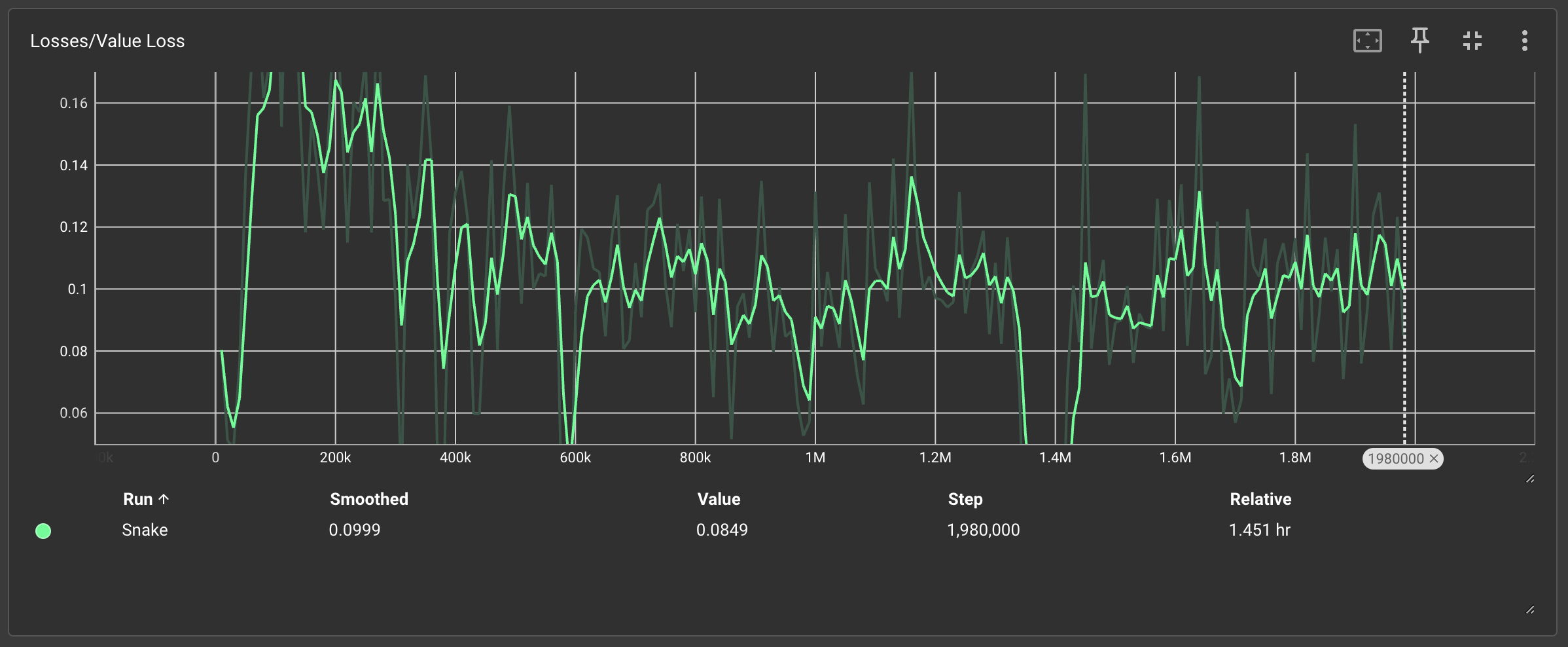
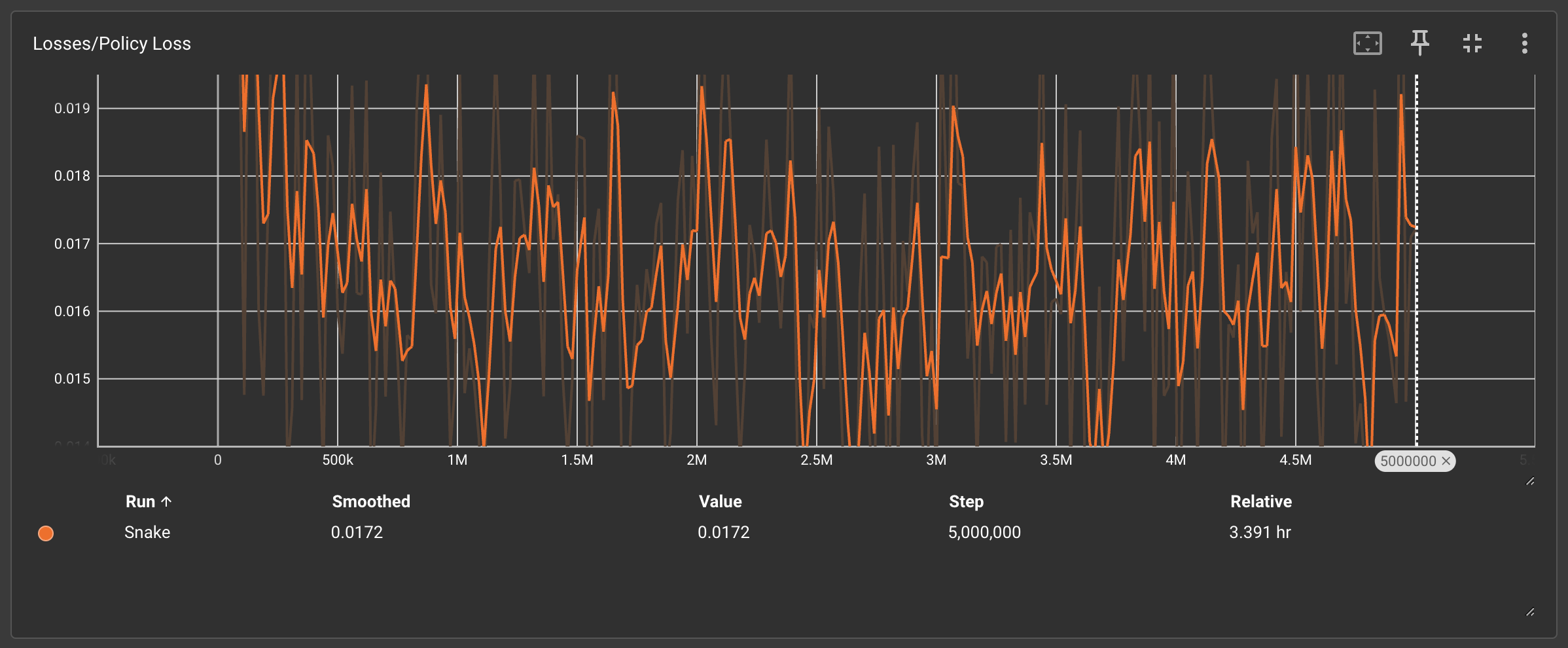
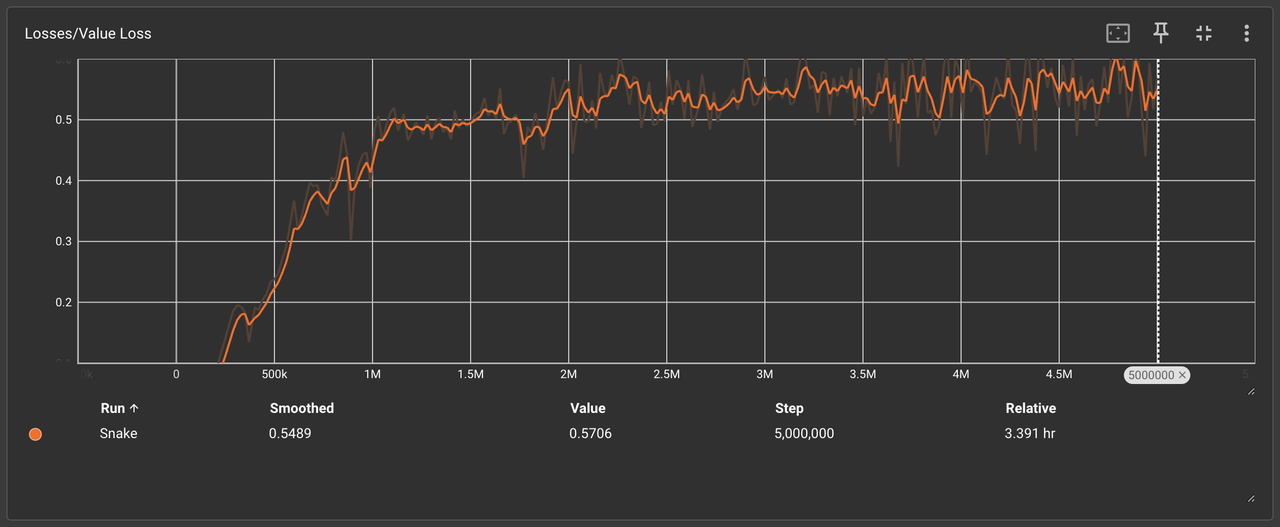
4、Losses/Policy Loss & Value Loss(策略损失曲线和价值损失)
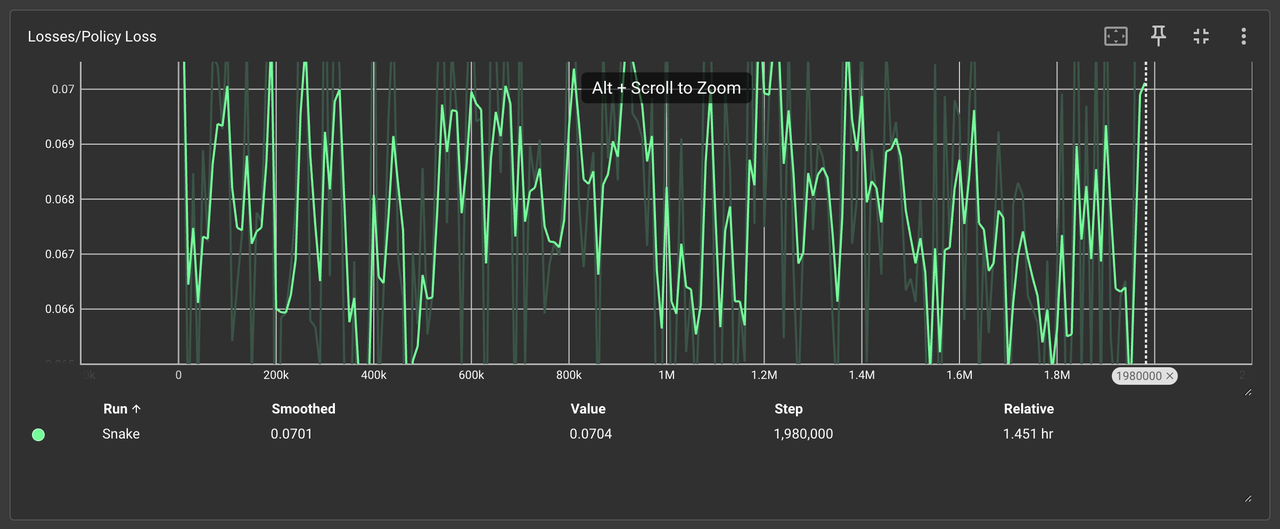
-
收敛效率对比:
-
🟩 简单规则:策略损失稳定下降,50万次后趋于平缓
-
🟧 复杂规则:损失值剧烈波动,500万次仍未收敛
-
-
产品化结论:
复杂规则显著增加策略优化难度,开发周期可能超出合理阈值。
三、需求锚定:AI产品经理的“信号提纯”策略
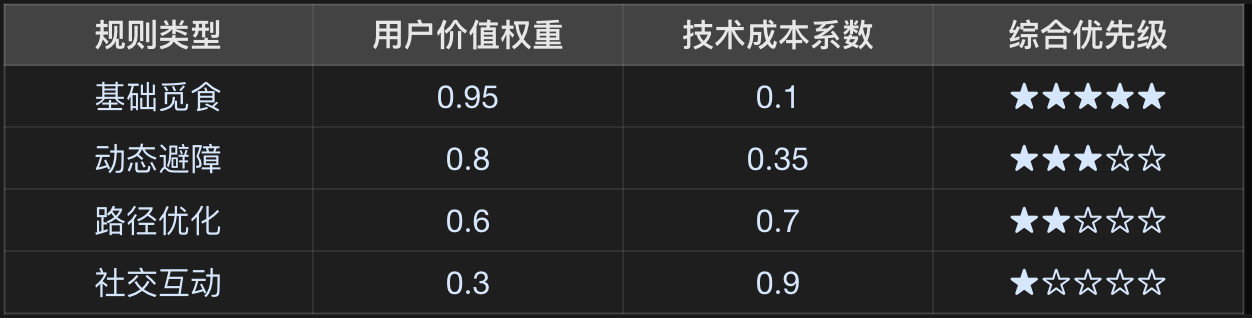
1、需求优先级量化模型
2、技术方案评审的三重过滤
- 信号纯度检测:使用SHAP值分析规则贡献度,剔除权重<5%的干扰项
- 收敛效率评估:对比策略损失曲线的稳定性,拒绝震荡率>30%的方案
- 成本收益测算:若单位得分增益成本>0.5(公式:训练耗时×时薪/得分),触发熔断机制
3、需求文档的“减法模板”
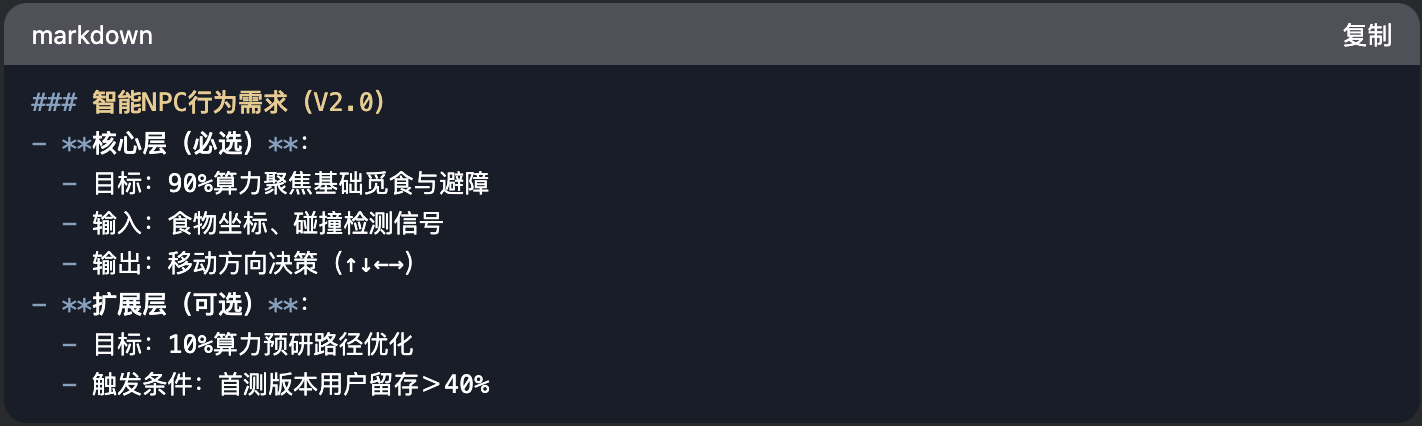
四、项目工程 和 代码仓库:
-
代码仓库:
正在整理已经完成的两个 demo 的运行项目文件,请敬请期待!
-
自查工具:
-
奖励规则冲突检测器(基于PyTorch梯度分析)
-
策略稳定性评估仪表盘(实时监控Loss曲线)
-
注:着急的小伙伴,可以 4️⃣ ✉️ 我索要,我会提供一份[ 临时打包版 ]。
五、操作实录:复杂规则下的“调参灾难”与破局演示
“最危险的AI需求,往往披着‘精细化’的外衣。”
附:[B站视频链接] 贪吃蛇强化学习全流程实录
Mac M1跑AI训练?用强化学习训练贪吃蛇:如何用简单奖励系统突破60单位长度?
关联阅读
-
[上篇]《强化学习RL-NPC复杂奖励机制的陷阱与需求简化策略》
-
[扩展]《如何用马斯洛需求金字塔设计NPC行为树》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









