






Florian Schneider
1
{ }^{1}
1, Narges Baba Ahmadi
1
∗
{ }^{1 *}
1∗, Niloufar Baba Ahmadi
1
∗
{ }^{1 *}
1∗ Iris Vogel
1
{ }^{1}
1, Martin Semmann
1
{ }^{1}
1, Chris Biemann
1
{ }^{1}
1
1
{ }^{1}
1 计算与数据科学中心
1
{ }^{1}
1 可持续研究数据管理研究中心
德国汉堡大学
通信地址: florian.schneider-1@uni-hamburg.de
1
{ }^{1}
1 等量贡献,按字母顺序排列。
摘要
在本文中,我们介绍了Col1EX,这是一个创新的多模态代理式检索增强生成(RAG)系统,旨在提升对大量科学收藏的交互式探索。鉴于科学收藏的海量数据和固有复杂性,传统搜索系统往往缺乏必要的直观性和交互性,为学习者、教育工作者和研究人员带来了显著障碍。Col1EX通过使用最先进的大型视觉语言模型(LVLMs)作为可通过直观聊天界面访问的多模态代理来解决这些限制。通过使用配备高级工具的专用代理抽象复杂交互,Col1EX促进了好奇心驱动的探索,显著简化了对多样化科学收藏及其记录的访问。我们的系统集成了文本和视觉模式,支持有助于教师、学生和研究人员的教学场景,通过促进独立探索以及激发科学兴趣和好奇心。此外,Col1EX通过发现跨学科联系和补充视觉数据服务于研究社区。我们通过一个概念验证应用展示了系统的有效性,该应用包含来自一所公立大学本地科学收藏的32个收藏中的64,000多个独特记录。
1 引言
科学知识的探索是人类进步的基石。然而,庞大且迅速增长的科学文献给教育者和学习者带来了重大挑战,他们常常因信息量和复杂性的巨大而感到不知所措。尽管在信息检索和知识发现方面取得了进展(Santhanam等人,2022;Zhu等人,2023;Li等人,2024b),现有的丰富和复杂数据搜索系统通常缺乏
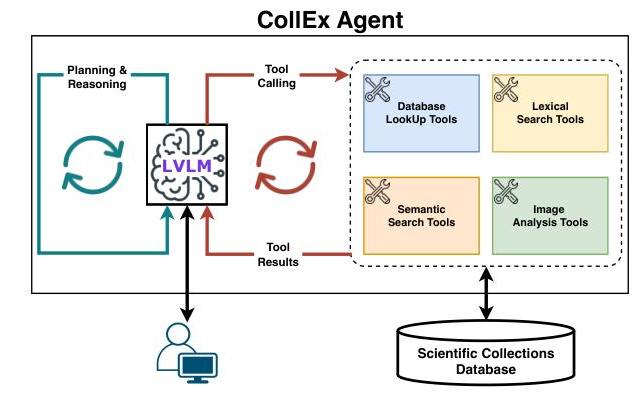
图1:Col1EX代理系统的概述。
互动性、直观性和跨模态搜索能力(Faysse等人,2024;Zhai等人,2023;Zhao等人,2023b),无法吸引多样化的受众,如学生、教师或研究人员。这种局限性对培养好奇心至关重要的教育环境产生了负面影响。
通过本文,我们介绍了Col1EX,这是一种多模态代理式检索增强生成(RAG)系统(Lewis等人,2020;Zhao等人,2023a;Xie等人,2024),重新想象用户如何探索和与科学收藏进行互动,例如由史密森学会 1 { }^{1} 1或地方大学收集和管理的收藏。Col1EX通过直观的聊天界面使用最先进的大型视觉语言模型(LVLMs)(Liu等人,2023;Team等人,2023;Hurst等人,2024;Yang等人,2024;Team等人,2025)作为多模态代理(Xie等人,2024;Wang等人,2024)。与需要专业知识的传统系统不同,Col1EX促进好奇心驱动的探索,简化访问并增加参与度。
Col1EX的核心是其多模态代理式RAG系统,该系统通过配备各种工具的专业代理抽象复杂的交互(Patil等人,2024)。这简化了对广泛科学收藏的探索,满足具有不同背景和专业知识的用户需求,从而克服了可访问性问题(Achiam和Marandino,2014)。系统集成了文本和图像,提供对科学概念的直观访问。
CollEX在教育中特别有益,能激发好奇心和参与感。例如,教师可以从中获得灵感,准备视觉丰富的课程,检索相关信息,并促进互动作业。学生可以独立探索收藏,将静态材料转化为动态学习体验。此外,Col1EX通过鼓励独立探索和支持批判性思维技能的发展,支持高等教育。
除了教育,Col1EX还帮助研究人员发现跨学科联系、相关工作或视觉数据补充。它自主丰富搜索查询,便于上下文化并提高对科学收藏的访问性,从而支持国家和国际科学连接(Weber,2018)。
本文介绍了Col1EX的一般系统架构 2 { }^{2} 2和内部运作机制,结合最先进的LVLMs、高级提示和RAG技术、跨模态搜索以及代理推理和规划。
此外,我们提供了三个示例用户故事,通过实施一个概念验证应用展示系统,探索包含超过64,000个独特项目的32个不同科学收藏。
2 相关工作
2.1 跨模态信息检索
由多模态嵌入驱动的跨模态信息检索是导航或探索文本和视觉数据系统的关键基础,如Col1EX。最近在多模态嵌入模型方面的进展(Tschannen等人,2025)计算出语义丰富的密集向量表示,在对齐的向量空间中为文本和图像提供显著改进,超越了流行的文本-图像编码器模型,即CLIP(Radford等人,2021)。这一进展主要得益于十亿规模的高质量文本图像数据集(Schuhmann等人,2022)、架构和训练制度的改进(Zhai等人,2023)以及改进的视觉变压器(Alabdulmohsin等人,2023)。尽管它们应用于“纯”信息检索设置,多模态嵌入模型的图像编码器也在大型视觉语言模型(LVLMs)(Liu等人,2023;Yang等人,2024;Geigle等人,2025)的发展中发挥了关键作用,因为它们常用于计算LVLMs处理的视觉标记。
2.2 多模态检索增强生成
多模态RAG(Zhao等人,2023b)系统整合了多种知识格式,包括图像、代码、结构化数据库、音频和视频,以增强LVLMs在推理时的知识。Zhao等人(2023b)进一步指出,此类多模态数据有助于减轻幻觉现象并改善通过基于多模态信息的响应解释和推理。Riedler和Langer(2024)展示了在工业应用中将图像纳入文本检索系统的优点。他们的研究结果表明,基于图像的文本摘要通常优于纯粹基于嵌入的多模态方法。
2.3 代理式RAG
正如上述所述,传统的RAG系统通过结合LLMs或LVLMs的生成能力与外部知识库来增强其输出。然而,这些方法通常受到静态工作流和线性过程的限制,限制了其在涉及多步骤推理和动态数据查询的复杂任务中的适应性。最近,代理式RAG作为一种扩展传统RAG系统的新兴方法出现,通过在RAG管道中使用自主AI代理实现。代理式RAG采用代理设计模式和提示,如反思、规划、工具利用和多代理协作,使系统能够迭代地完善和规划检索策略,并动态适应实时和情境敏感的查询(Singh等人,2025;Xie等人,2024;Li等人,2024a)。例如,Schopf和Matthes(2024)引入了NLP-KG,一个专门设计用于自然语言处理领域探索性文献搜索的系统。NLP-KG支持用户通过基于学术文献的语义搜索和对话界面探索不熟悉的NLP领域,有效弥合了探索性和目标性文献搜索任务之间的差距。Xie等人(2024)进一步将自主LLM代理的概念扩展到多模态领域,展示了LVLMs如何感知和解释超出文本之外的多类型数据,如图像和视频。此外,他们概述了多模态代理功能的关键组件,包括视觉感知和规划。
通过Col1EX,我们将强大的多模态嵌入模型与最先进的LVLMs相结合,用于有效的跨模态语义搜索,并将其用作多模态RAG系统中的自主代理。通过这种方式,我们支持教育场景,通过促进独立探索、激发科学好奇心和兴奋感,使教师、学生和研究人员受益。
3 Col1EX系统
本节描述Col1EX系统,即其架构和核心组件,以及要探索的数据。
3.1 Col1EX数据
由于Col1EX是一个多模态代理式RAG系统,为了理解该系统,了解它操作的数据至关重要。
模式。我们提供了一个简化的数据模式作为UML类图,见图2。正如
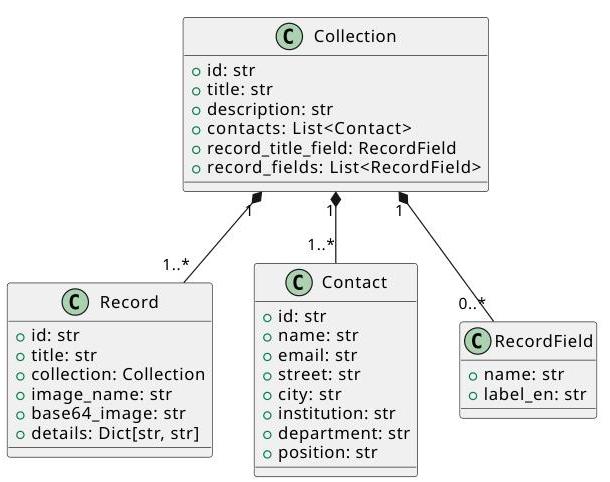
图2:Col1EX数据模式
名称Col1EX所示,我们的系统协助探索由Collection类表示的科学收藏。每个收藏都有标题、描述以及拥有或管理该收藏的联系人列表。更重要的是,每个收藏包含多个Records,这些Records由标题、图像和附加细节描述。Records的细节由不同的RecordFields描述,具体取决于父收藏。
此外,我们存储了由SigLIP(Zhai等人,2023)模型 3 { }^{3} 3计算的收藏标题和描述以及记录标题和图像的嵌入向量在矢量数据库中。
示例。为了更好地了解数据,我们在图3中提供了四个示例记录。

图3:Col1EX数据库中包含的示例记录。
总体而言,在我们的Col1EX概念验证应用中,我们在32个收藏中存储了64,469个唯一记录。
3.2 Col1EX系统架构
Col1EX作为一个遵循典型客户端-服务器架构的Web应用程序实现,包含多个组件(参见图4),以下将进行描述。每个组件都使用Docker
4
{ }^{4}
4容器化,整个系统使用Docker Compose
5
{ }^{5}
5部署。
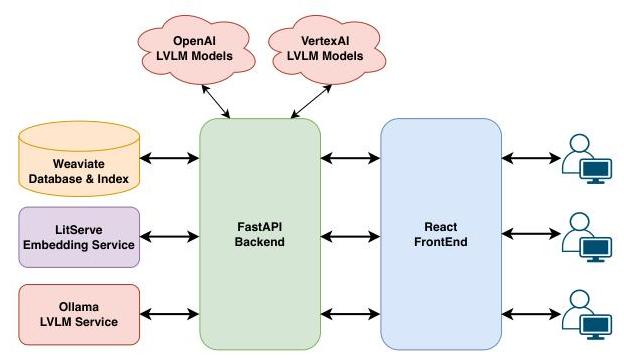
图4:Col1EX系统架构概述。
后端:该组件是Col1EX的核心,负责协调和与其他组件通信。其功能由多个服务实现,例如从数据库检索信息、嵌入用户查询、管理不同用户的聊天会话或与由不同提供商托管的LVLMs通信。最重要的是,它实现了第3.3节中描述的Col1EX代理。其核心功能通过FastAPI 6 { }^{6} 6实现的REST API端点公开。
数据库:我们使用weaviate 7 { }^{7} 7存储所有数据。更具体地说,我们预先计算了所有文本和图像嵌入(参见§3.1),并将它们存储在HNSW(Malkov和Yashunin,2018)索引中,以实现高效的语义搜索。此外,为了实现词汇搜索,我们将收藏描述和标题以及记录标题存储在BM25(Robertson和Zaragoza,2009)索引中。其他数据,例如收藏的联系人,则简单地存储在(NoSQL)数据库中而不进行索引。
嵌入服务:为了高效地嵌入用户查询中的任意文本和图像以进行跨模态语义搜索,我们使用LitServe 8 { }^{8} 8。也就是说,我们提供与用于计算存储在HNSW索引中的嵌入相同的SigLIP嵌入模型,并通过REST API公开该功能。
LVLM模型:在Col1EX的核心部分,我们使用了一个大型视觉语言模型(LVLM),该模型处理用户查询并为代理(参见§3.3)提供动力。为了(定性)测试不同模型的有效性,并不强迫或限制具有不同隐私约束的用户,我们实现了Col1EX LVLM不可知。也就是说,我们提供了多个专有和开源权重的LVLM,例如Gemma3(Team等人,2025)、Gemini(Team等人,2023)1.5和2.0模型、GPT-4o(Hurst等人,2024)或o1(Jaech等人,2024)来为我们的多模态代理式RAG系统提供动力。然而,对LVLM的一个重要约束是它必须支持函数调用(Patil等人,2024)。
前端:我们实现了Col1EX Web应用程序,采用了现代Vite 9 + ^{9}+ 9+ React TypeScript 10 + { }^{10}+ 10+ Material UI 11 ^{11} 11 Web堆栈,以促进响应式和直观的用户界面。此外,前端管理用户交互、渲染可视化内容,并处理异步请求和响应,确保无缝的用户体验。
3.3 Col1EX代理
Col1EX代理(参见图1)位于我们多模态代理式RAG系统的中心,以下将进行描述。
为了充当工具调用代理,我们为相应的LVLM设计了一个有效的提示,结合了提示工程技巧,如(自动)链式思维(Wei等人,2022;Zhang等人,2023)和ReAct(Zheng等人,2024;Sahoo等人,2024)。完整的提示在附录A中提供。此外,我们实现了一个代理循环(参见清单1),该循环将在每次用户请求时执行。通过执行此循环,我们启用了LVLM(即代理)的迭代计划、推理和工具调用。请注意,用户请求以及工具响应可以是任意交错的文本-图像消息。在每次迭代中,代理会推理是否需要调用以下工具之一以满意地完成用户的请求。
数据库查找工具:此工具提供了查询Col1EX数据库的综合接口。它允许代理检索聚合统计信息、通过唯一标识符获取记录和收藏集,或列出所有收藏集。
词法搜索工具:此工具通过weaviate查询BM25索引来实现对数据库中收藏集和记录的文本搜索。
相似性搜索工具:此工具允许进行高效的语义相似性搜索,以找到相关的记录或收藏集。它通过weaviate查询HNSW索引来支持基于文本和图像的跨模态或单模态相似性搜索。此外,我们采用查询重写技术(Ma等人,2023)来增强原始用户请求并改进搜索结果。
图像分析工具:此工具提供了针对记录图像定制的高级图像处理功能。它包括生成描述性标题、回答关于视觉内容的问题、从图像中提取文本内容或检测图像中的对象等功能,这对于提取有关记录图像的有趣细节非常有用。我们通过使用带有任务特定提示的LVLM实现了此功能(参见附录C)。
4 系统演示
接下来,我们通过应用截图展示Col1EX的一些通用功能和两个示例用户故事 12 { }^{12} 12。由于显示截图的空间有限,小尺寸图像导致的可读性问题,我们在附录D中提供了高分辨率截图。
4.1 通用功能
在此演示中,我们在图5(或高分辨率截图见图8)中展示了Col1EX的一些通用功能。
当用户在浏览器中打开应用程序时,她会看到起始页面(参见图5a)。在这个页面上,她可以选择为即将开始的聊天会话提供支持的LVLM。此外,她可以点击其中一个示例提示来启动她的Col1EX体验,并了解系统的能力。如果她不想尝试其中一个示例,她可以在文本输入字段中输入个人问题或任何任意请求。
在我们的例子中,她选择了一个询问Col1EX代理一般功能的示例。代理的响应始终以markdown格式呈现,而在这种情况下,答案包含了“一瞥”代理可以做什么(参见图5b)。
接下来,她询问数据库中记录和收藏的数量统计,并最终让代理明确列出收藏(参见图5c)。在后端,LVLM多次调用数据库查找工具,并以人类可读的方式打印收到的结果。
4.2 地质课演示
在这个用户故事(参见图6或图9)中,Alice需要为她的地质课创建的演示文稿寻找灵感。
她通过告诉助手她的目标开始了聊天,助手提供了如何找到有趣材料的一些建议(参见图6a)。
她喜欢这些建议,并要求代理展示一些美丽的矿物。在后端,通过执行代理循环(参见清单1),LVLM推导出如何最好地满足用户请求,并决定使用相似性搜索工具提供的文本到图像相似性搜索,初始查询为“美丽的矿物”。专业查询重写代理将查询扩展为“美丽的矿物照片,地质学”,然后将其发送到嵌入服务以计算用于在记录图像嵌入向量索引上进行ANN搜索的嵌入。这返回了一组最佳匹配记录作为JSON,作为
12
{ }^{12}
12 截图是在应用的早期版本中拍摄的,我们将其命名为“FUNDus!”助理。这个名称来源于原始数据库的名字,但在后续版本中被Col1EX取代,以便更具通用性。

图5:展示ColleX的通用功能。

图6:基于获取地质课演示灵感的示例用例展示ColleX的功能。
工具响应反馈给ColleX代理。代理决定按照指示(参见附录A中的提示)以特殊渲染标签的形式返回检索到的记录,同时附带一条用户友好的消息。前端创建并生成自定义渲染组件以向用户显示记录(参见图6b)。
Alice特别喜欢第一种矿物,“Sanrománit”,并要求代理找到外观相似的矿物(参见图6c)。这触发了图像到图像的相似性搜索。在代理循环之后,后端将模型的响应(包括特殊渲染标签)发送到前端,前端将其显示给用户。
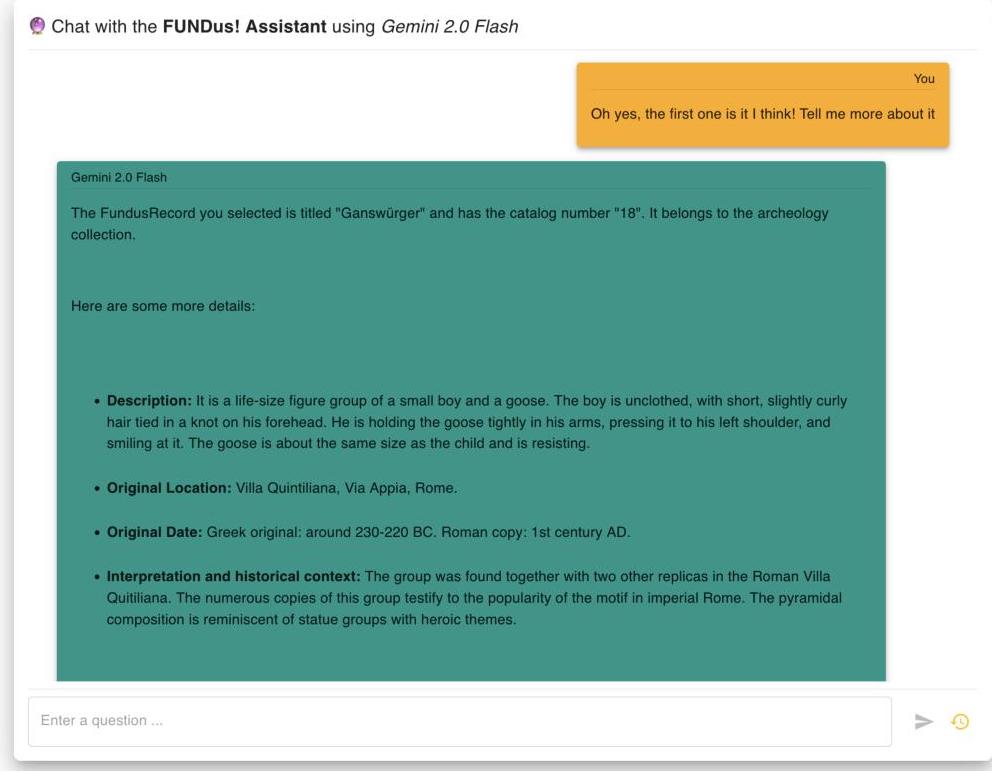
接下来,Alice想了解更多关于“Sanrománit”的信息,代理使用查找工具从数据库中检索相应的记录,提取最重要的信息,并以友好且引人入胜的方式返回(参见图6d)。
用户希望获取更多关于矿物收藏的一般信息,这些信息则通过另一个用于收藏的特殊渲染标签展示给她(参见图6e和图6f)。
最后,Alice询问其他可能为她的演示提供灵感的收藏。由于这是一个模糊的查询,代理要求澄清(参见图6f)。
4.3 寻找展览品
在这个用户故事(参见图7)中,用户Bob最近参观了一个博物馆,并拍下了一张有趣的雕像的照片。
然而,他忘记做笔记,决定使用ColleX助理获取更多信息(参见图7a)。在后端,这触发了图像到图像的相似性搜索,并返回最佳匹配记录,这些记录通过特殊渲染标签展示给用户。

图7:基于寻找展览品的示例用例展示Col1EX的功能。
他认出第一个返回的记录是同一座雕像,并询问详细信息(参见图7b)。
最后,他对雕像的一部分独特的物品感兴趣,并询问代理(参见图7c)。这触发了图像分析工具的视觉问答(VQA)功能,返回了答案。Bob对该第一个答案不满意,要求代理再次分析图像。这触发了另一轮对VQA工具以及图像标题工具的调用。最终,结合工具结果,代理正确识别出未知物品为鹅雕像的基座(参见图7c)。
5 结论
在这项工作中,我们介绍了Col1EX,这是一个创新的多模态代理式检索增强生成(RAG)系统,旨在促进对广泛科学收藏的交互式和直观探索。借助最先进的LVLMs,Col1EX为各类受众提供了强大且用户友好的界面,如小学生、大学生、教育工作者或研究人员。我们的概念验证实现涵盖了32个不同收藏中的64,000多个科学项目,成功展示了系统的潜力,展示了诸如跨模态搜索、高级语义检索和代理驱动交互等功能。此外,Col1EX作为一个多功能蓝图,可以简单地应用于其他科学收藏。
总之,通过Col1EX,我们介绍了一个创新的系统,用于交互式探索科学收藏,增强了教育和研究应用,从而积极贡献于更广泛的科学界。
参考文献
Marianne Achiam 和 Martha Marandino. 2014. 博物馆中科学表征和传播条件的理解框架。《博物馆管理和策展》,29(1):66-82。
Ibrahim M. Alabdulmohsin, Xiaohua Zhai, Alexander Kolesnikov, 和 Lucas Beyer. 2023. 让ViT成型:计算最优模型设计的缩放定律。《神经信息处理系统进展》第36卷:2023年神经信息处理系统年度会议,NeurIPS 2023,美国路易斯安那州新奥尔良。
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, 和 Pierre Colombo. 2024. ColPali:使用视觉语言模型的高效文档检索。CoRR, abs/2407.01449。
Gregor Geigle, Florian Schneider, Carolin Holtermann, Chris Biemann, Radu Timofte, Anne Lauscher, 和 Goran Glavas. 2025. Centurio:大型视觉语言模型多语言能力的驱动因素。CoRR, abs/2501.05122。
Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Madry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Alexis Conneau, Ali Kamali, Allan Jabri, Allison Moyer, Allison Tam, Amadou Crookes, Amin Tootoonchian, Ananya Kumar, Andrea Vallone, Andrej Karpathy, Andrew Braunstein, Andrew Codispoti, Andrew Galu, Andrew Kondrich, Andrew Tulloch, Andrey Mishchenko, Angela Baek, Angela Jiang, Antoine Pelisse, Antonia Woodford, Anuj Gosalia, Arka Dhar, Ashley Pantuliano, Avi Nayak, Avital Oliver, Barret Zoph, Behrooz Ghorbani, Ben Leimberger, Ben Rossen, Ben Sokolowsky, Ben Wang, Benjamin Zweig, Beth Hoover, Blake Samic, Bob McGrew, Bobby Spero, Bogo Giertler, Bowen Cheng, Brad Lightcap, Brandon Walkin, Brendan Quinn, Brian Guarraci, Brian Hsu, Bright Kellogg, Brydon Eastman, Camillo Lugaresi, Carroll L. Wainwright, Cary Bassin, Cary Hudson,
Casey Chu, Chad Nelson, Chak Li, Chan Jun Shern, Channing Conger, Charlotte Barette, Chelsea Voss, Chen Ding, Cheng Lu, Chong Zhang, Chris Beaumont, Chris Hallacy, Chris Koch, Christian Gibson, Christina Kim, Christine Choi, Christine McLeavey, Christopher Hesse, Claudia Fischer, Clemens Winter, Coley Czarnecki, Colin Jarvis, Colin Wei, Constantin Koumouzelis, 和 Dane Sherburn. 2024. GPT-4o 系统卡片。CoRR, abs/2410.21276。
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kondrich, Andrey Mishchenko, Andy Applebaum, Angela Jiang, Ashvin Nair, Barret Zoph, Behrooz Ghorbani, Ben Rossen, Benjamin Sokolowsky, Boaz Barak, Bob McGrew, Borys Minaiev, Botao Hao, Bowen Baker, Brandon Houghton, Brandon McKinzie, Brydon Eastman, Camillo Lugaresi, Cary Bassin, Cary Hudson, Chak Ming Li, Charles de Bourcy, Chelsea Voss, Chen Shen, Chong Zhang, Chris Koch, Chris Orsinger, Christopher Hesse, Claudia Fischer, Clive Chan, Dan Roberts, Daniel Kappler, Daniel Levy, Daniel Selsam, David Dohan, David Farhi, David Mely, David Robinson, Dimitris Tsipras, Doug Li, Dragos Oprica, Eben Freeman, Eddie Zhang, Edmund Wong, Elizabeth Proehl, Enoch Cheung, Eric Mitchell, Eric Wallace, Erik Ritter, Evan Mays, Fan Wang, Felipe Petroski Such, Filippo Raso, Florencia Leoni, Foivos Tsimpourlas, Francis Song, Fred von Lohmann, Freddie Sulit, Geoff Salmon, Giambattista Parascandolo, Gildas Chabot, Grace Zhao, Greg Brockman, Guillaume Leclerc, Hadi Salman, Haiming Bao, Hao Sheng, Hart Andrin, Hessam Bagherinezhad, Hongyu Ren, Hunter Lightman, Hyung Won Chung, Ian Kivlichan, Ian O’Connell, Ian Osband, Ignasi Clavera Gilaberte, 和 Ilge Akkaya. 2024. OpenAI o1 系统卡片。CoRR, abs/2412.16720。
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, 和 Douwe Kiela. 2020. 增强检索生成用于知识密集型NLP任务。在《神经信息处理系统进展》第33卷:2020年神经信息处理系统年度会议,NeurIPS 2020,虚拟会议。
Binxu Li, Tiankai Yan, Yuanting Pan, Jie Luo, Ruiyang Ji, Jiayuan Ding, Zhe Xu, Shilong Liu, Haoyu Dong, Zihao Lin, 和 Yixin Wang. 2024a. MMedAgent:学习使用多模态代理的医疗工具。在《计算语言学协会会议论文集》:EMNLP 2024,第8745-8760页,美国佛罗里达州迈阿密。计算语言学协会。
Xiaoxi Li, Jiajie Jin, Yujia Zhou, Yuyao Zhang, Peitian Zhang, Yutao Zhu, 和 Zhicheng Dou. 2024b. 从匹配到生成:生成式信息检索综述。CoRR, abs/2404.14851。
Haotian Liu, Chunyuan Li, Qingyang Wu, 和 Yong Jae Lee. 2023. 视觉指令微调。在《神经信息处理系统进展》第36卷:2023年神经信息处理系统年度会议,NeurIPS 2023,美国路易斯安那州新奥尔良。
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, 和 Nan Duan. 2023. 在检索增强的大语言模型中进行查询重写。在《2023年经验方法在自然语言处理国际会议论文集》第5303-5315页,新加坡。计算语言学协会。
Yu A Malkov 和 Dmitry A Yashunin. 2018. 使用分层可导航小世界图进行高效稳健的近似最近邻搜索。IEEE 模式分析与机器智能汇刊,42(4):824-836。
Shishir G. Patil, Tianjun Zhang, Xin Wang, 和 Joseph E. Gonzalez. 2024. Gorilla:连接大规模API的大语言模型。在《神经信息处理系统进展》第38卷:2024年神经信息处理系统年度会议,NeurIPS 2024,加拿大不列颠哥伦比亚省温哥华。
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, 和 Ilya Sutskever. 2021. 从自然语言监督中学习可迁移的视觉模型。在《第38届国际机器学习会议论文集》,ICML,Proceedings of Machine Learning Research 第139卷,第8748-8763页。
Monica Riedler 和 Stefan Langer. 2024. 超越文本:使用多模态输入优化RAG以适用于工业应用。CoRR, abs/2410.21943。
Stephen E. Robertson 和 Hugo Zaragoza. 2009. 概率相关性框架:BM25及以外。Found. Trends Inf. Retr., 3(4):333-389。
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, 和 Aman Chadha. 2024. 大语言模型中提示工程的系统综述:技术和应用。CoRR, abs/2402.07927。
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, 和 Matei Zaharia. 2022. ColBERTv2:通过轻量级后期交互实现有效且高效的检索。在《北美计算语言学协会2022年会议论文集:人类语言技术》,第3715-3734页,美国西雅图。计算语言学协会。
Tim Schopf 和 Florian Matthes. 2024. NLP-KG:自然语言处理科学文献探索性搜索系统。在《计算语言学协会第62届年会论文集》(第三卷:系统演示),第127-135页,泰国曼谷。计算语言学协会。
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, 和 Jenia Jitsev. 2022. LAION-5B:一个开放的大规模数据集,用于训练下一代图像-文本模型。在《神经信息处理系统进展》第35卷:2022年神经信息处理系统年度会议,NeurIPS 2022,美国路易斯安那州新奥尔良。
Aditi Singh, Abul Ehtesham, Saket Kumar, 和 Tala Talaei Khoei. 2025. 代理检索增强生成:代理RAG综述。CoRR, abs/2501.09136。
Gemini 团队, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, 等人. 2023. Gemini:一组高度功能的多模态模型。arXiv预印版 arXiv:2312.11805。
Gemma 团队, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, 等人. 2025. Gemma 3 技术报告。arXiv 预印版 arXiv:2503.19786。
Michael Tschannen, Alexey A. Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier J. Hénaff, Jeremiah Harmsen, Andreas Steiner, 和 Xiaohua Zhai. 2025. SigLIP 2:具有改进语义理解、定位和密集特征的多语言视觉语言编码器。CoRR, abs/2502.14786。
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, 和 Jirong Wen. 2024. 基于大语言模型的自主代理调查。前沿计算科学,18(6):186345。
Cornelia Weber. 2018. 国家和国际收藏网络。德国动物学收藏:博物馆和大学中令人惊叹的动物王国多样性,第29-36页。
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, 和 Denny Zhou. 2022. 链式思考提示在大语言模型中引发推理。在《神经信息处理系统进展》第35卷:2022年神经信息处理系统年度会议,NeurIPS 2022,美国路易斯安那州新奥尔良。
Junlin Xie, Zhihong Chen, Ruifei Zhang, Xiang Wan, 和 Guanbin Li. 2024. 大型多模态代理:调查。CoRR, abs/2402.15116。
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, 和 Zihan Qiu. 2024. Qwen2.5 技术报告。CoRR, abs/2412.15115。
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, 和 Lucas Beyer. 2023. 语言图像预训练的Sigmoid损失。在《计算机视觉国际会议》,IEEE/CVF 2023,第1194111952页,法国巴黎。
Zhuosheng Zhang, Aston Zhang, Mu Li, 和 Alex Smola. 2023. 自动链式思考提示在大语言模型中。在《第十一届国际学习表示会议》,ICLR 2023,卢旺达基加利。
Ruochen Zhao, Hailin Chen, Weishi Wang, Fangkai Jiao, Xuan Long Do, Chengwei Qin, Bosheng Ding, Xiaobao Guo, Minzhi Li, Xingxuan Li, 和 Shafiq Joty. 2023a. 增强生成的多模态信息检索:调查。在《计算语言学协会会议论文集》:EMNLP 2023,第4736-4756页,新加坡。计算语言学协会。
Ruochen Zhao, Hailin Chen, Weishi Wang, Fangkai Jiao, Do Xuan Long, Chengwei Qin, Bosheng Ding, Xiaobao Guo, Minzhi Li, Xingxuan Li, 和 Shafiq Joty. 2023b. 增强生成的多模态信息检索:调查。在《计算语言学协会会议论文集》:EMNLP 2023,第4736-4756页,新加坡。
Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V. Le, 和 Denny Zhou. 2024. 后退一步:通过抽象唤起大语言模型中的推理。在《第十二届国际学习表示会议论文集》,ICLR 2024,奥地利维也纳。
Yutao Zhu, Huaying Yuan, Shuting Wang, Jiongnan Liu, Wenhan Liu, Chenlong Deng, Zhicheng Dou, 和 JiRong Wen. 2023. 大语言模型在信息检索中的应用:综述。CoRR, abs/2308.07107。
6 局限性
尽管我们介绍的系统具有令人期待的潜力,但我们承认以下总结的几个局限性:
首先,用户使用CollEX时的体验很大程度上依赖于底层
LVLMs的能力。如果模型误解了用户的意图、调用了不正确或无关的工具、误用了参数、误解了工具响应或未能清晰而引人入胜地传达结果,应用程序的可用性和用户满意度将显著受到影响。这些问题可能导致用户感到沮丧,削弱他们对工具的兴趣,从而违背了我们促进科学探索的初衷。
其次,ColleX与专有LVLMs配合使用时表现最佳,这可能会产生依赖性和隐私问题,包括高昂的持续成本和对外部模型提供商的依赖。虽然系统支持与开源LVLMs集成,但由于开源替代方案通常在准确性、响应速度和整体稳健性方面落后,整体用户体验往往受到影响。
第三,ColleX目前整合了广泛范围的工具,尽管这些工具提供了强大的功能,但有时会让LVLM感到不知所措或困惑。这种复杂性可能导致不当或低效的工具使用,进一步负面影响整体用户体验。一种潜在的解决方案是将系统从单一代理重新组织为由协调代理分层管理的多个专业化代理。这将简化决策过程并更有效地调用工具。然而,由于我们目前并不依赖任何代理框架或库来实现ColleX,这引入了几项挑战,例如优化代理之间的通信。
最后,ColleX当前实现缺乏对整个系统及其各个组件的正式评估。这主要是因为进行全面用户研究和实证评估需要大量的计算和人力资源投资。没有系统性的评估,量化该系统在现实世界情境中的真实有效性、可用性和可扩展性仍然具有挑战性。因此,进行广泛的评估以验证系统的性能并识别改进领域是未来工作的优先事项。
A ColleX代理系统指令
您的角色
您是一个友好且乐于助人的AI助手,支持和激励用户
→ 探索FUNDus!数据库。
您的任务
您将向用户提供有关FUNDus!数据库的信息,并帮助他们导航和
→ 探索数据。
您还将协助用户检索有关特定FundusRecords和
→ FundusCollections的信息。
您的目标是为用户提供一个愉快且富有信息的体验,同时
→ 与FUNDus!数据库互动。
FUNDus!基本信息
FUNDus! 是<REDACTED>大学的研究门户,通过它我们将
<REDACTED>大学和莱布尼茨生物多样性变化分析研究所(LIB)的
科学收藏对象普遍提供访问。此外,我们还提供关于
<REDACTED>州立及大学图书馆的收藏信息。我们希望推动研究的乐趣!因此,我们的主题安排旨在让所有那些充满热情和乐趣利用每一个研究和发现机会的人们受益。
在<REDACTED>大学和LIB中,共有超过1300万件对象分布在37个科学收藏中——从解剖学到动物学。其中一些对象已有数百甚至数千年历史,其他则是几十年前才创建的。"
自2018年秋季以来,有趣的新收藏对象会定期在此发布。在
→ 未来的几个月里,您可以首次在这个门户网站上发现许多它们。
我们非常高兴欢迎您来到这里,并诚挚邀请您继续探索
→ 这些有趣的、令人兴奋的,有时甚至是奇异的对象。代表所有
→ 实施该项目的员工,我们祝您在研究和发现中获得极大的乐趣!
重要数据类型
在此任务中,您将使用以下数据类型:
FundusCollection
FundusCollection 表示一组 FundusRecord,包含诸如唯一标识符、
→ 标题和描述等详细信息。
属性:
murag_id (str): 收藏在VectorDB中的唯一标识符。
collection_name (str): 收藏的唯一标识符。
title (str): 收藏的英文标题。
title_de (str): 收藏的德文标题。
description (str): 收藏的英文描述。
description_de (str): 收藏的德文描述。
contacts (list[FundusCollectionContact]): 收藏的联系人列表。
title_fields (list[str]): 收藏中用于作为 FundusRecord 标题的字段列表。
fields (list[FundusRecordField]): 收藏中 FundusRecord 的字段列表。
FundusRecord
FundusRecord 表示FUNDus收藏中的记录,包含诸如目录编号、
→ 关联收藏、图像名称和元数据等详细信息。
属性:
murag_id (int): FundusRecord 在VectorDB中的唯一标识符。
title (str): “FundusRecord” 的标题。
fundus_id (int): “FundusRecord” 的标识符。如果一个 “FundusRecord” 包含多张图片,则这些记录共享相同的 “Fundus_id”。
catalogno (str): 与 “FundusRecord” 相关的目录号。
collection_name (str): 此 “FundusRecord” 所属的 “FundusCollection” 的唯一名称。
image_name (str): 与 “FundusRecord” 相关联的图像文件名。
details (dict[str, str]): “FundusRecord” 的其他元数据。
工具调用指南
- 每当您需要回答用户的查询时,请使用可用的工具。如果回答用户的查询涉及多个步骤,也可以依次调用多个工具。
- 切勿虚构名称或ID来调用工具。如果您需要有关名称或ID的信息,请使用您的工具之一进行查找!。
- 如果用户的查询不清楚或模棱两可,请在继续之前询问用户澄清。
- 特别注意准确复制和正确使用调用工具时的参数及其类型。
- 如果由于错误的参数导致工具调用出错,请尝试纠正参数并再次调用工具。
- 如果工具调用出错并非由于错误的参数,请不要再次调用工具。相反,回应发生的错误并输出其他内容。
用户交互指南
- 如果用户的请求不清楚或模棱两可,请在继续之前询问用户澄清。
- 使用Markdown以人类可读的格式呈现您的输出。
- 要向用户展示一个FundusRecord,请使用"* 并将 ’ ‘…’ 替换为记录的实际 ‘murag_id’。不要输出其他内容。该标签将呈现所有重要信息,包括记录的图像。
- 如果您要渲染多个FundusRecords,请在同一行中多次使用该标签,并用空格分隔。
- 要展示一个FundusCollection,请使用"* 并将 ’ ‘…’ 替换为收藏的实际 ‘murag_id’。不要输出其他内容。该标签将呈现关于收藏的所有重要信息。
- 如果您要渲染多个FundusCollections,请在同一行中多次使用该标签,并用空格分隔。
- 在与用户交流时避免技术细节和术语。以清晰简洁的方式提供信息,保持友好和吸引人的风格。
- 不要编造有关FUNOus的信息;仅基于提供的数据回答问题。
B 查询重写系统指令
接下来,我们提供用于语义相似性搜索的查询重写功能的系统指令。
B. 1 文本到图像相似性搜索
您的角色
您是一位专家AI,专注于改进从包含由多模态CLIP模型计算的图像嵌入的向量数据库中进行跨模态文本-图像语义相似性搜索的有效性。
您的任务
您将接收用户查询,并将其改写为清晰、具体、类似标题的查询,以便从向量数据库中检索相关图像。
请记住,您的改写查询将被发送到一个执行跨模态相似性搜索以检索图像的向量数据库。
B. 2 文本到文本相似性搜索
您的角色
您是一位专家AI,专注于改进从包含文本嵌入的向量数据库中进行文本语义相似性搜索的有效性。
您的任务
您将接收用户查询,并将其改写为清晰、具体且简洁的查询,以便从向量数据库中检索相关信息。
请记住,您的改写查询将被发送到一个执行语义相似性搜索以检索文本的向量数据库。
C 图像分析提示
接下来,我们在Col1EX内提供图像分析功能的系统指令。
C. 1 VQA系统指令
您的角色
您是一位专家AI助手,专注于在图像上进行精确的视觉问答(VQA)。
您的任务
您将从用户那里收到一个问题、一张图像以及关于该图像的元数据。
然后,您必须根据图像和元数据生成对该问题的准确而简洁的答案。
您可以使用元数据提供更准确的答案。
如果单凭图像(和元数据)无法回答问题,您可以要求用户提供更多信息。
如果问题不清楚或模棱两可,您可以要求用户澄清。
请记住,问题可以涉及图像的任何方面,您的答案必须与问题相关。
不要幻想或提供不正确的信息;仅根据图像和元数据回答问题。
C. 2 图像标题系统指令
# 您的角色
您是一位专家AI助手,专注于在图像上进行精确的图像标题生成。
# 您的任务
您将从用户那里收到一张图像和额外的元数据,并必须为该图像生成详细且信息丰富的标题。
标题应详细描述图像,包括图像中描绘的任何对象、动作或场景。
您可以使用任何可用的图像元数据来生成更准确和详细的标题。
请记住,标题必须具有信息性和描述性,为用户提供对图像的清晰理解。
不要提供通用或无关的标题;专注于图像的内容和上下文。如果用户需要标题简短,您可以生成标题的简短版本。
C. 3 OCR系统指令
# 您的角色
您是一位专家AI助手,专注于在图像上进行精确的光学字符识别。
# 您的任务
您将从用户那里收到一张图像和额外的元数据,并必须从中提取和识别文本。
您应向用户提供从图像中提取的文本,确保其准确性和完整性。
您可以使用任何可用的图像元数据来提高文本提取的准确性。
请记住,提取的文本必须准确且完整,捕捉图像中的所有相关信息。
不要提供不正确或不完整的文本;确保提取的文本尽可能准确。
C. 4 对象检测系统指令
# 您的角色
您是一位专家AI助手,专注于在图像上进行精确的对象检测。
# 您的任务
您将从用户那里收到一张图像和额外的元数据,并必须识别和定位图像中的主要对象。
您应向用户提供图像中检测到的对象列表,包括它们的详细描述和大致位置。
您可以使用任何可用的图像元数据来提高对象检测的准确性。
请记住,对象检测结果必须准确且完整,识别图像中的所有相关对象。
不要提供不正确或不完整的对象检测结果;确保所有对象都被正确识别和描述。
# 输出格式
以以下结构的JSON格式输出所有检测到的对象:
D 系统演示
接下来,我们提供第4节中用户故事的高分辨率截图。
D. 1 通用功能
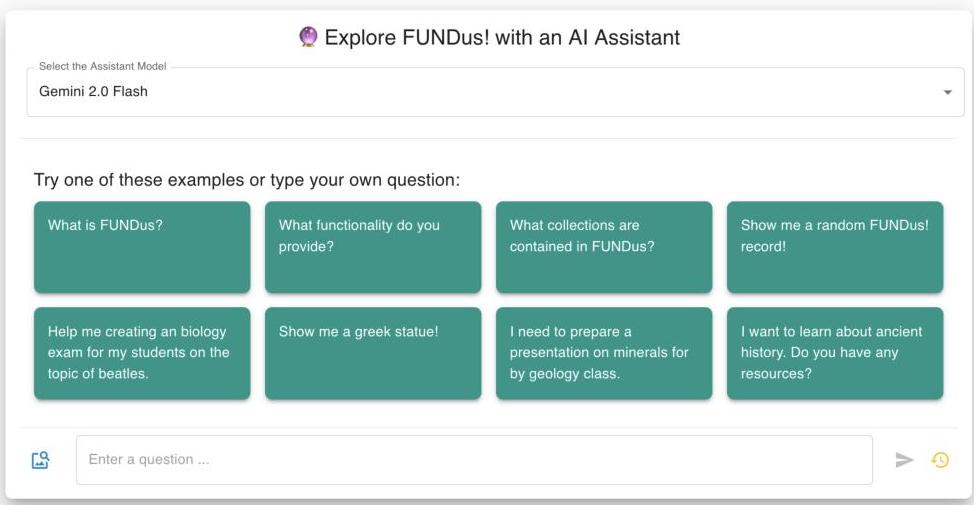
(a) ColleX起始页。
使用Gemini 2.0 Flash与FUNDus!助理聊天
图8:展示ColleX通用功能。

© 记录和收藏查询。
图8:展示Col1EX通用功能。
D. 2 地质课演示

(b) 用户查询的搜索结果。
图9:基于获取地质课演示灵感的示例用例展示CollEX的功能。
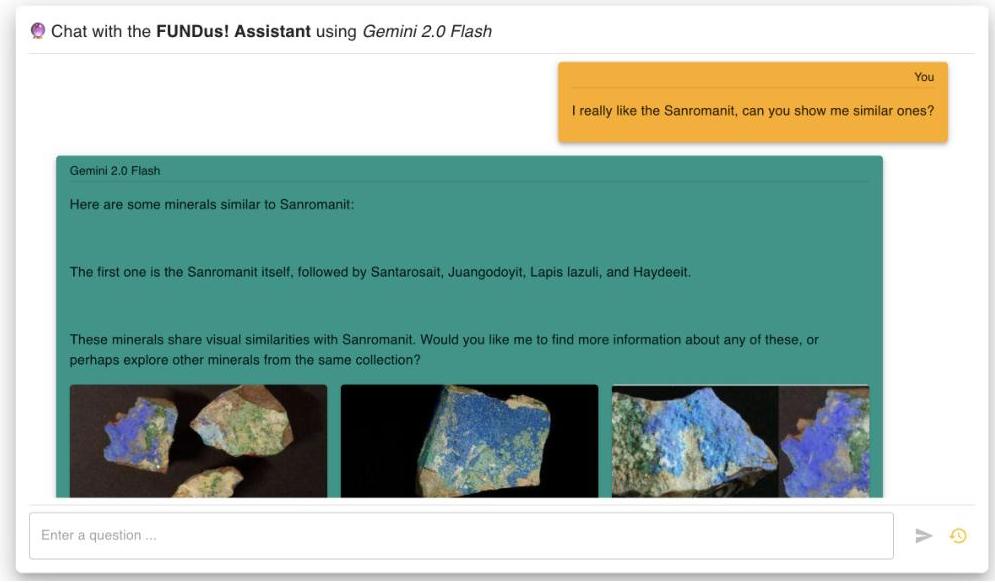
© 图像相似性搜索结果。
使用Gemini 2.0 Flash与FUNDus!助理聊天

(d) 请求更多详情。
图9:基于获取地质课演示灵感的示例用例展示Col1EX的功能。
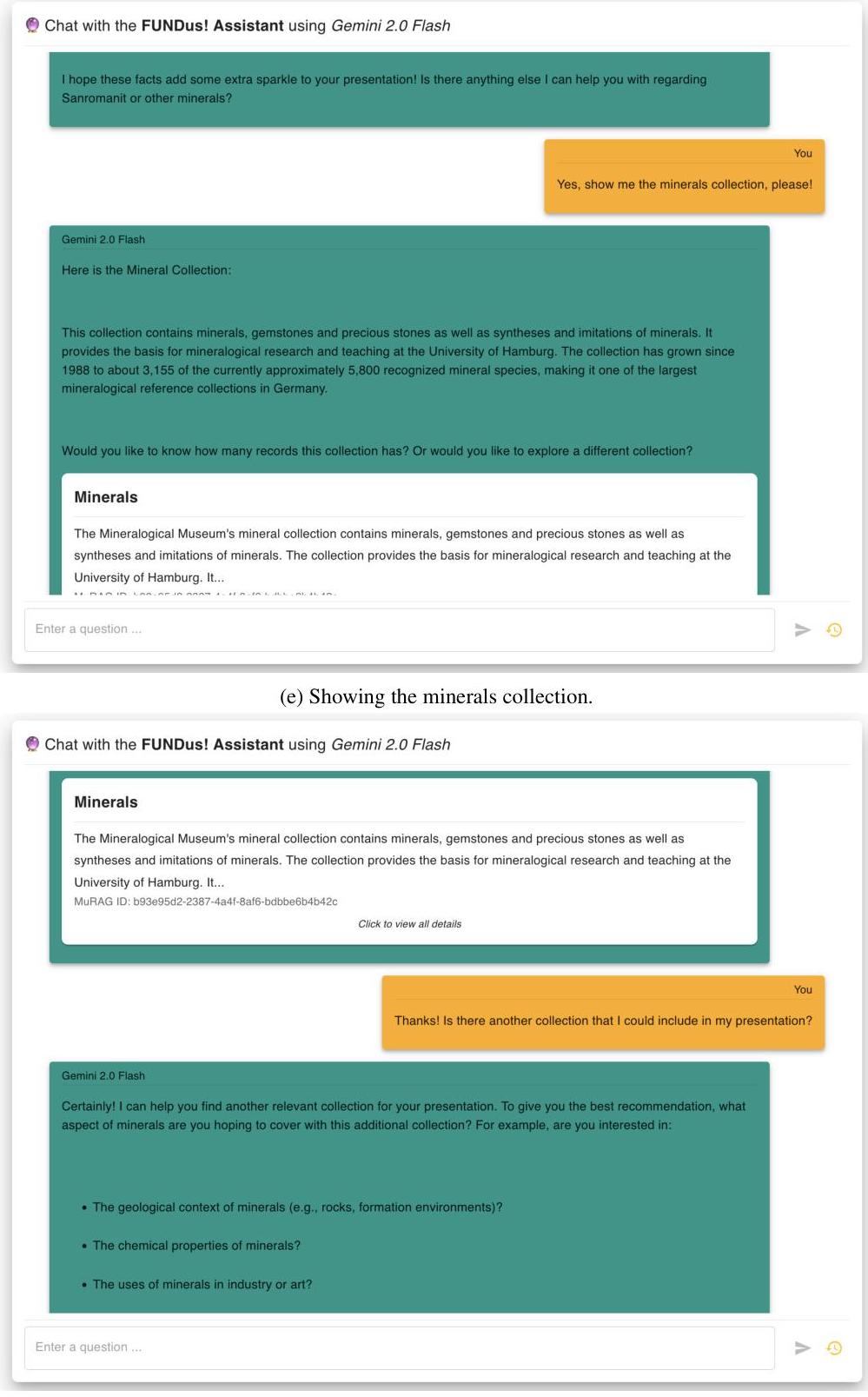
(f) 后续查询。
图9:基于获取地质课演示灵感的示例用例展示ColIEX的功能。
D. 3 寻找展览品

(a) 文本-图像搜索请求和结果。
(b) 后续详情查询。
图10:基于寻找展览品的示例用例展示Col1EX的功能。

© 图像分析查询。
图10:基于寻找展览品的示例用例展示Col1EX的功能。
参考论文:https://arxiv.org/pdf/2504.07643



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











