






王继方,杨雪,王龙跃,徐振然,王一瑜,王尧伟,罗维华,张凯富,胡宝天*,张敏
哈尔滨工业大学(深圳),中国深圳
23S151116@stu.hit.edu.cn, {hubaotian, zhangmin2021}@hit.edu.cn
摘要
条件图像生成因其个性化内容的能力而受到广泛关注。然而,该领域在开发任务无关、可靠且可解释的评估指标方面面临挑战。本文介绍了CIGEVAL,这是一种用于全面评估条件图像生成任务的统一代理框架。CIGEVAL利用大型多模态模型(LMMs)作为核心,整合多功能工具箱并建立细粒度评估框架。此外,我们通过综合微调轨迹,使较小的LMM能够自主选择适当的工具并根据工具输出进行细致分析。在七个主要条件图像生成任务上的实验表明,CIGEVAL(GPT-4o版本)与人类评估具有高达0.4625的相关性,接近人类评分员之间的相关性0.47。此外,当仅使用2.3K训练轨迹对7B开源LMMs进行实施时,CIGEVAL超越了以前基于GPT-4o的最先进方法。关于GPT-4o图像生成的案例研究表明,CIGEVAL能够识别与主体一致性及遵循控制指导相关的细微问题,显示出其在以人类水平可靠性自动化评估图像生成任务方面的巨大潜力 1 { }^{1} 1。
1 引言
近年来,大规模文本到图像(T2I)生成模型的发展使得可以根据文本提示和参考图像创建图像,即条件图像生成(Kumari等人,2023;Ruiz等人,2023;Li等人,2023b;He等人,2024)。该领域正在以前所未有的速度发展,并引入了越来越多的任务和模型。其中,
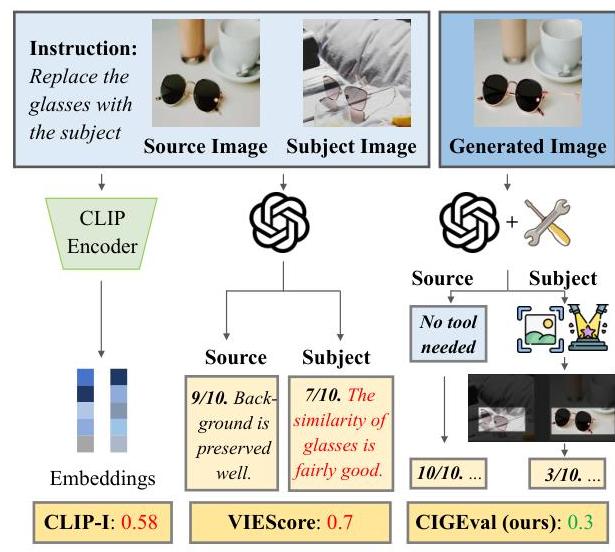
图1:一个带有低分人类注释的主题驱动图像编辑示例。传统指标和基于GPT-4o的VIEScore都赋予高分。通过将GPT-4o与工具集成,我们的代理评估框架CIGEVAL突出了两幅图像中的眼镜对象,并发现了它们不同的形状和设计,从而达到了正确得分。“Source”和“Subject”分别表示“源图像”和“主题图像”。
文本引导的图像生成特别流行(Ramesh等人,2022;Chen等人,2025;Yuan等人,2025)。扩展到文本之外,已经使用各种条件来引导扩散过程:文本引导的图像编辑(Brooks等人,2023),掩码引导的图像编辑(runwayml,2023),主体驱动的图像生成和编辑(Chen等人,2023;Guo等人,2024),多概念图像合成(Kumari等人,2023)以及控制引导的图像生成(Qin等人,2023;Zhang和Agrawala,2023)。
尽管开发了越来越多的生成模型,但在有效评估AI合成图像方面仍存在重大挑战(Peng等人,2024)。当前的评估指标有以下三个限制:(1) 任务特定:传统指标过于狭窄,无法跨不同任务通用。例如,LPIPS(Zhang等人,2018)测量一对图像的感知相似性,而CLIP-Score(Hessel等人,2021)测量单个图像的文本对齐。(2) 可解释性有限:为生成图像分配单一分数而不提供推理过程,无法提供全面评估。图像可以在多个维度上进行评估,如提示遵循和概念保留(Fu等人,2023b)。(3) 缺乏人类一致性:传统指标如DINO(Caron等人,2021)和CLIP(Radford等人,2021)往往与人类产生巨大差异,这是由于它们的图像相似性测量性质。即使基于强大的大型多模态模型(LMM)GPT-4o,如图1所示,当前最先进的VIEScore(Ku等人,2024)也难以捕捉图像的细微差别,在各种图像编辑任务中与人类判断的相关性较低。
为了解决这些问题,我们提出了CIGEVAL,一种基于自主LMM代理框架的条件图像生成评估方法。该代理框架可以集成先进的GPT-4o模型(OpenAI,2023)和开源模型(例如,Qwen2.5-VL(Wang等人,2024))。我们的工作由两个主要动机驱动:(1) 开发能够在没有人类帮助的情况下独立决策和判断的自主评估代理;(2) 使相对较小的模型能够高效地执行复杂评估。为了实现这一目标,我们做出了三个关键技术贡献。首先,我们扩展了LMM的能力,通过策划多功能工具箱来检测和强调高度相似图像之间的细微差异,这与之前仅依赖于LMM感知能力的方法形成对比。其次,我们建立了细粒度评估框架,包括任务分解、工具选择和分析。第三,我们根据评估轨迹综合指令数据以微调LMM,其中我们首先使用GPT-4o执行各阶段,然后筛选与人类评估一致的轨迹。
在已建立的ImagenHub基准测试(Ku等人,2023)上的实验表明,当使用GPT-4o作为底层LMM时,CIGEVAL在所有7项任务中实现了最先进的性能。它与人类评分员的平均斯皮尔曼相关系数为0.4625,接近人类与人类之间的相关系数0.47。主要改进体现在涉及多个条件的任务中,例如控制引导的图像生成和多概念图像合成,这些任务中以前的评估指标表现不佳。仅使用2.3K过滤后的评估轨迹进行调整,CIGEVAL利用7B开源LMMs展示了超过以前基于GPT-4o的最先进方法的性能。进一步的消融研究显示了每个工具的重要性以及我们框架的鲁棒性。此外,我们对GPT-4o的图像生成进行了初步案例研究。CIGEVAL分配的分数与人类注释紧密对齐,并能有效检测4o生成图像中的细微缺陷,特别是在涉及多个输入图像和遵循特定控制信号(例如Canny边缘、OpenPose)的任务中。这些结果表明CIGEVAL在评估合成图像方面具有显著的人类水平性能潜力。
我们的主要贡献如下:
- 我们介绍了CIGEVAL,一种基于LMM的评估代理,旨在评估各种条件图像生成任务。我们的方法以其与人类一致、可解释和统一的评估方法而著称,区别于以前的指标。
- 我们在7个条件图像生成任务中评估了CIGEVAL,证明基于GPT-4o的CIGEVAL优于所有现有基线,并实现了与人类评分员的高度相关性,接近人类与人类之间的相关性。
- 我们微调了开源7B LMMs,显著提高了其评估性能,超过了以前基于闭源GPT-4o的最先进方法。
2 相关工作
2.1 条件图像生成
扩散模型在AI研究中引起了广泛关注,用于图像合成(Ho et al., 2020; Dhariwal and Nichol, 2021)。近年来,几种新模型(Kumari et al., 2023; Ruiz et al., 2023; Li et al., 2023b; Zhang and Agrawala, 2023)被开发出来,以在图像生成中引入可控条件。该领域的普遍任务包括文本到图像生成(Saharia et al., 2022; Rombach et al., 2022; stability.ai, 2023)(称为文本引导的图像生成)、
修复(Avrahami et al., 2022; Lugmayr et al., 2022)(称为掩码引导的图像编辑)和文本引导的图像编辑(Brooks et al., 2023; Couairon et al., 2022; Wu and la Torre, 2023)。最近的研究提出了新的任务,例如主体驱动的图像生成和编辑(Gal et al., 2022; Ruiz et al., 2023; Li et al., 2023b),即将特定主体注入合成图像,以及多概念图像组合(Kumari et al., 2023; Liu et al., 2023; Ding et al., 2024),允许在合成图像中包含多个特定主体。此外,控制引导的图像生成(Zhang and Agrawala, 2023; Qin et al., 2023; Guo et al., 2024)允许除了文本提示外的附加条件来引导图像合成。我们的工作采用基于LMM的代理来评估所有这些讨论的任务。
2.2 合成图像评估
已经引入了各种指标来评估AI生成的图像。例如,CLIP得分(Hessel et al., 2021)和BLIP得分(Li et al., 2022)通常用于测量生成图像与文本提示之间的对齐程度。像LPIPS(Zhang et al., 2018)和DreamSim(Fu et al., 2023b)这样的指标专注于评估感知相似性。LLMScore(Lu et al., 2023)和HEIM-benchmark(Lee et al., 2023)在多个细粒度方面评估文本到图像模型,包括毒性与安全性。然而,这些指标主要集中在文本到图像生成上,范围较窄。对于其他条件图像生成任务,如主体驱动的图像生成和图像编辑(Ruiz et al., 2023; Li et al., 2023b; Peng et al., 2024),有效的自动指标明显缺乏。因此,一些研究工作(Denton et al., 2015; Isola et al., 2017; Meng et al., 2021; Chen et al., 2023; Sheynin et al., 2023)严重依赖人工评估。这种依赖性突显了在该领域中需要更统一、可解释和可靠的自动评估方法。我们的工作旨在通过开发一个与人类判断密切一致的自主代理评估框架来弥补这一差距。
2.3 大型多模态模型作为评估者
受自然语言处理中基于大语言模型(LLM)评估器探索的启发(Zheng et al., 2023; Dubois et al., 2023; Fu et al., 2023a; Cheng et al., 2024b),大型多模态模型(LMMs)已被用于评估视觉问答中的响应(Chen et al., 2024a; Xu et al., 2024)。在图像评估领域,GPT-4系列表现出有希望的能力,尤其是在评估文本-图像对齐方面(Zhang et al., 2023b; Li et al., 2024)。然而,这些模型并非没有局限性。对GPT-4o视觉能力的全面研究表明,在细粒度图像评估任务中存在错误(Yang et al., 2023),例如无法准确区分相似图像之间的差异(Ku et al., 2024)。为了解决这些缺点,我们通过集成一组多功能的图像分析和编辑工具,并采用代理框架来改进AI生成图像的评估,从而增强了LMM的能力。
3 CIGEVAL
在本节中,我们介绍CIGEVAL,这是我们基于LMM的代理框架,旨在评估条件图像生成。首先,我们定义了我们研究关注的七种条件图像生成任务(第3.1节),然后设计了一个多功能工具箱(第3.2节)。接下来,我们介绍我们的细粒度评估框架(第3.3节)。最后,我们综合高质量轨迹数据以微调开源LMM(第3.4节)。
3.1 任务定义
为了构建统一且可解释的评估指标,我们将图像评估问题定义为如方程1所示。函数 f eval f_{\text {eval }} feval 接受指令 I I I、合成图像 O O O和一组条件 C ∗ C^{*} C∗(例如文本提示、主体图像、背景图像、canny-edge等)作为输入。函数 f eval f_{\text {eval }} feval 应根据指令 I I I生成最终分数前,先用自然语言生成中间推理:
f eval ( I , O , C ∗ ) = ( 推理, 分数 ) f_{\text {eval }}\left(I, O, C^{*}\right)=(\text { 推理, 分数 }) feval (I,O,C∗)=( 推理, 分数 )
按照Ku等人(2023)的做法,我们重点关注七个主要条件图像生成任务,每个任务都有不同的条件集 C ∗ C^{*} C∗:
-
文本引导的图像生成: C ∗ = [ p ] C^{*}=[p] C∗=[p],其中 p p p是文本提示。目标是生成与文本描述对齐的图像。
-
掩码引导的图像编辑: C ∗ = [ p , I mask C^{*}=\left[p, I_{\text {mask }}\right. C∗=[p,Imask , I src I_{\text {src }} Isrc ],其中 I mask I_{\text {mask }} Imask 是一个二值化掩码, I src I_{\text {src }} Isrc 是一个源图像。目标是根据 p p p修改 I src I_{\text {src }} Isrc 中的掩码区域。
-
文本引导的图像编辑: C ∗ = [ p , I src ] C^{*}=\left[p, I_{\text {src }}\right] C∗=[p,Isrc ]。此任务类似于掩码引导的图像编辑,但不提供掩码。模型必须自动识别要编辑的区域。
-
主题驱动的图像生成: C ∗ = [ p C^{*}=[p C∗=[p, S ] S] S],其中 S S S是特定主体的图像。目标是生成反映相对于主体 S S S的 p p p的图像。
-
主题驱动的图像编辑: C ∗ = [ S , p C^{*}=\left[S, p\right. C∗=[S,p, I src I_{\text {src }} Isrc ],其中 I src I_{\text {src }} Isrc 是源图像, S S S是主体参考。目标是将 I src I_{\text {src }} Isrc 中的主体替换为 S S S。
-
多概念图像组合: C ∗ = C^{*}= C∗= [ S 1 , S 2 , p , I src ] \left[S_{1}, S_{2}, p, I_{\text {src }}\right] [S1,S2,p,Isrc ],其中 S 1 S_{1} S1和 S 2 S_{2} S2是两个主体的图像。任务是根据 p p p将它们结合起来创建新图像。
-
控制引导的图像生成: C ∗ = C^{*}= C∗= [ I control , p I_{\text {control }}, p Icontrol ,p ],其中 I control I_{\text {control }} Icontrol 是控制信号,如深度图、canny边缘或边界框。目标是生成遵循这些低级视觉线索的图像。
在本文中,按照先前的工作(Mañas et al., 2024; Lin et al., 2024),我们调查生成图像与上述条件的语义一致性。
3.2 工具箱
评估涉及多种条件的图像生成可能具有挑战性。借鉴先前的研究(Cheng等人,
2024a;Zhang等人,2024),我们开发了一个多功能工具箱,包括Grounding、Difference、Highlight和Scene Graph。每个工具都针对图像分析或编辑的具体方面设计,并输出修改后的图像或文本信息。详细的工具描述见表1。
具体来说,我们使用GroundingDino(Liu等人,2024)实现Grounding。Scene Graph使用与CCoT(Mitra等人,2024)相同的提示方法,基于GPT-4o。该工具也可以与其他开源LMMs有效配合(参见第4.4节)。为了协助LMMs检测编辑图像之间的细微差异,Difference工具比较两张图像的像素并识别变化的位置。Highlight工具通过将突出区域外部的像素值减少到原始值的 1 / 4 1/4 1/4,从而使这些区域变暗并强调突出区域。这个工具通常在Grounding和Difference工具提供了区域坐标后使用。
3.3 框架
在我们的方法中,我们将图像评估过程概念化为一个代理任务。如图2所示,CIGEvAL的核心是一个经过良好指导的LMM,它可以自主利用工具来评估广泛的条件图像生成任务。
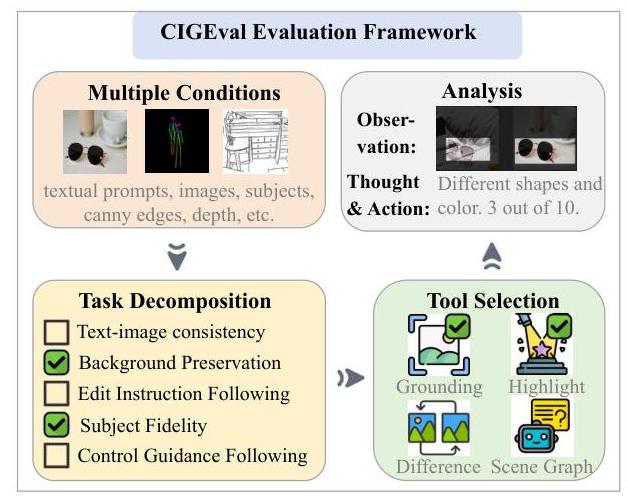
图2:CIGEVAL对图1示例的评估过程。CIGEVAL自主选择适合每个分解子任务的适当工具,然后基于观察到的工具输出进行细粒度分析。
本框架中使用的提示列在附录A中。
具体来说,我们采用分而治之的方案来评估在多个条件下生成的图像。例如,在图1中的主题驱动图像编辑任务中,期望的合成图像将结合来自主题参考的对象,同时保持源图像的背景。因此,我们将每个评估任务分解为几个细粒度的子问题,如下所述:(1) 图像生成是否遵循提示?(2) 图像编辑是否遵循指令?(3) 图像是否在不改变背景的情况下进行最小编辑?(4) 图像中的对象是否遵循提供的主题?(5) 图像是否遵循控制指导?然后,对于每个子问题,CIGEVAL从其工具箱中选择最适合的工具,专注于评估的具体方面。例如,Grounding和Highlight用于比较图像的具体区域,而Scene Graph则评估背景保留和过度编辑的程度。借助这些中间结果,LMM分析工具输出并在ReAct格式(Yao等人,2023)中分配分数,范围从0到10,归一化到 [ 0.0 , 1.0 ] [0.0,1.0] [0.0,1.0]范围内以便与人类评分进行比较。这些细粒度分数通过以下公式聚合:
O = min ( α 1 , … , α i ) O=\min \left(\alpha_{1}, \ldots, \alpha_{i}\right) O=min(α1,…,αi)
其中
α
i
\alpha_{i}
αi代表其中一个子分数。在
Ku等人(2023)的设置下,我们假设每个子分数权重相同,并使用最小操作来强调满足所有标准的重要性。
3.4 代理微调
以往的研究主要依赖闭源LMMs来解决代理任务,主要是因为它们在工具调用和指令跟随方面具有优越能力(Chen等人,2024b;Song等人,2024;Zeng等人,2024;Xu等人,2023)。正如表3所示,开源模型的表现显著逊色于GPT-4o。为了弥补这一差距并增强较小LMMs作为有效评估者的功能,我们旨在对7B模型进行监督微调以整合代理能力。
为了策划高质量的轨迹数据,我们使用GPT-4o执行第3.3节中的评估过程。过程开始时向GPT40提供评估指令和相应的图像。每一轮中,代理接收观察结果,制定计划和想法作为thought,并通过action调用相关工具。工具输出作为后续回合的新观察结果。通过迭代上述过程,我们可以构建完整的评估轨迹,包括初始指令、中间步骤(即观察、思考、行动)和最终评分结果。为了确保这些轨迹的质量,我们排除预测分数与人类评估分数差异超过0.3的样本。使用ImagenHub数据的60%,我们最终收集了2,274条高质量轨迹以进行监督微调。
使用这种结构化的轨迹数据,我们对Qwen2-VL-7B-Instruct和Qwen2.5-VL-7B-Instruct(Wang等人,2024)进行监督微调。正式地,每个样本的评估轨迹表示为 ⟨ o 0 , t 1 , a 1 , … , o n − 1 , t n , a n , o n ⟩ \left\langle o_{0}, t_{1}, a_{1}, \ldots, o_{n-1}, t_{n}, a_{n}, o_{n}\right\rangle ⟨o0,t1,a1,…,on−1,tn,an,on⟩,其中 o i , t i o_{i}, t_{i} oi,ti和 a i a_{i} ai分别表示每轮 ( i ) (i) (i)的观察、思考和行动。具体来说, o 0 o_{0} o0指代由评估指令和伴随图像组成的初始观察,而 o n o_{n} on表示最终分数。在每轮中,基于先前的轨迹 c i = c_{i}= ci= ⟨ o 0 , t 1 , a 1 , … , o i − 1 ⟩ \left\langle o_{0}, t_{1}, a_{1}, \ldots, o_{i-1}\right\rangle ⟨o0,t1,a1,…,oi−1⟩,代理的目标是生成思考 t i t_{i} ti和行动 a i a_{i} ai。在微调过程中,我们仅计算 t i t_{i} ti和 a i a_{i} ai的交叉熵损失,而 c i c_{i} ci被屏蔽:
L = − log ∑ i = 1 n Pr ( t i , a i ∣ c i ) \mathcal{L}=-\log \sum_{i=1}^{n} \operatorname{Pr}\left(t_{i}, a_{i} \mid c_{i}\right) L=−logi=1∑nPr(ti,ai∣ci)
4 实验
4.1 评估基准
ImagenHub(Ku等人,2023)是一个标准化的基准,用于使用人类评分员评估条件图像生成模型。ImagenHub的统计信息如表2所示。这个大规模基准涵盖了7个主流任务、29个模型、4.8K合成图像和14.4K人类评分,适合计算自动评估指标与人类评分员之间的相关性分数。29个评估模型的列表可在附录B中找到。
每张图像根据定义任务的指南由三位人类评分员评估,并报告了平均分数范围 [ 0.0 , 1.0 ] [0.0,1.0] [0.0,1.0]的最终分数。图像在两个方面进行评分:(1) 语义一致性评估生成图像与给定条件(如提示和主题标记)的对齐程度,确保与指定任务标准的一致性和相关性。(2) 感知质量评估生成图像在视觉上看起来真实和传达自然感的程度。在本工作中,我们专注于语义一致性分数,而感知质量的探索留待未来研究。
4.2 现有自动指标
这里我们列出一些突出的自动指标:
- CLIP-Score(Hessel等人,2021):该指标计算提示和生成图像CLIP嵌入之间的平均余弦相似度,使其成为评估图像-文本对齐的流行选择。
- LPIPS(Zhang等人,2018)测量两种图像之间的相似性,方式与人类感知一致。
- CLIP-I(Gal等人,2022)计算生成图像和源图像CLIP嵌入之间的平均成对余弦相似度。
- DINO(Ruiz等人,2023)由ViT-S/16(Caron等人,2021)的DINO嵌入计算得出,通过对合成图像和源图像计算均值余弦相似度。
| # 指令 | # 图像 | # 人类评分 |
|---|---|---|
| 文本引导的图像生成(5个模型) | ||
| 197 | 985 | 2955 |
| 掩码引导的图像编辑(4个模型) | ||
| 179 | 716 | 2148 |
| 文本引导的图像编辑(8个模型) | ||
| 179 | 1432 | 4296 |
| 主体驱动的图像生成(4个模型) | ||
| 150 | 600 | 1800 |
| 主体驱动的图像编辑(3个模型) | ||
| 154 | 462 | 1386 |
| 多概念图像组合(3个模型) | ||
| 102 | 306 | 918 |
| 控制引导的图像生成(2个模型) | ||
| 150 | 300 | 900 |
| 7项任务总计 | ||
| 1111 | 4801 | 14403 |
表2:ImagenHub的统计数据:本文使用的指令数量、评估模型、合成图像和人类评分的数量。
- VIESCORE(Ku等人,2024)提示大型多模态模型以可解释和细粒度的方式评估生成图像。基于GPT-4o,它目前在ImagenHub的所有七项任务中代表最先进的水平。
4.3 实现细节
在所有实验中,GPT-4o指的是模型版本GPT-40-2024-05-13,与原始VIESCORE论文(Ku等人,2024)一致。对于第4.4节中的实验,我们使用整个ImagenHub基准进行评估。在消融研究中,我们随机选择每项任务的50张图像。对于第4.5节中的实验,我们使用ImagenHub数据集的60%生成训练数据,如第3.4节所述,并使用剩余数据进行测试。我们使用Megatron-LM微调Qwen2-VL-7B-Instruct和Qwen2.5-VL-7B-Instruct模型。微调过程采用学习率为1e-5,批量大小为128,序列长度为32,768。我们使用AdamW优化器,采用带3%预热步骤的余弦学习调度器。
| 方法 | 文本- 引导 IG | 掩码- 引导 IE | 文本- 引导 IE | 控制- 引导 IG | 主体- 驱动 IG | 主体- 驱动 IE | 多- 概念 IC | 平均 |
|---|---|---|---|---|---|---|---|---|
| 人类评分员 | 0.5044 | 0.5390 | 0.4230 | 0.5443 | 0.4780 | 0.4887 | 0.5927 | 0.4700 |
| CLIPScore | -0.0817 | - | - | - | - | - | - | - |
| LPIPS | - | -0.1012 | 0.0956 | 0.3699 | - | - | - | - |
| DINO | - | - | - | - | 0.4160 | 0.3022 | 0.0979 | - |
| CLIP-I | - | - | - | - | 0.2961 | 0.2834 | 0.1512 | - |
| LLaMA3-LLaVA-NeXT-8B | ||||||||
| VIESCORE | 0.1948 | 0.2037 | 0.0363 | 0.4001 | 0.1592 | -0.1153 | 0.1308 | 0.1432 |
| CIGEVAL | 0.1420 | 0.2843 | 0.0744 | 0.4487 | 0.2891 | -0.0699 | 0.3704 | 0.2164 |
| Qwen2.5-VL-7B-Instruct | ||||||||
| VIESCORE | 0.4218 | 0.3555 | 0.0252 | 0.2836 | 0.4264 | -0.0452 | 0.3328 | 0.2516 |
| CIGEVAL | 0.4347 | 0.4685 | 0.2567 | 0.3752 | 0.4374 | 0.4863 | 0.3251 | 0.3780 |
| GPT-4o | ||||||||
| VIESCORE | 0.4989 | 0.5421 | 0.4062 | 0.4972 | 0.4806 | 0.4800 | 0.4516 | 0.4459 |
| CIGEVAL | 0.5027 | 0.5465 | 0.4090 | 0.5402 | 0.4930 | 0.5185 | 0.4931 | 0.4625 |
表3:使用不同LMM作为骨干模型的7个条件图像生成任务的Spearman相关分数。缩写"IG"、“IE"和"IC"分别代表"图像生成”、“图像编辑"和"图像组合”。"-"表示不适用。
4.4 主要实验
对于所有展示的相关性,我们应用Fisher Z变换估计模型和任务间的平均Spearman相关性
∈
[
−
1
,
1
]
\in[-1,1]
∈[−1,1]。
指标到人类(M-H)相关性。在表3中,我们展示了利用不同骨干模型的所有任务的相关性。当使用GPT-4o作为底层LMM时,CIGEVAL在所有7项任务中均达到最先进水平。它与人类评分员的平均Spearman相关性为0.4625,接近人类与人类的相关性。主要改进体现在涉及多个条件的任务中,如控制引导的图像生成和多概念图像组合,这些任务中以前的评估指标表现不佳。
当底层LMM替换为不同的开源模型时,CIGEVAL始终优于VIESCORE。然而,开源模型的表现仍然较差,远不及GPT-4o。因此,我们按照第3.4节所述对这些模型进行代理微调,并在第4.5节报告其改进后的性能。总体而言,实验表明CIGEVAL在各种图像编辑和生成任务中始终优于VIESCORE,即使在使用不同底层LMM时也能保持其优势。
消融研究。为了评估CIGEVAL中每个工具的必要性,我们进行了详细记录在表4中的消融研究。由于Highlight通常伴随Grounding和Difference,我们不对Highlight进行特定的消融。研究表明,完整的CIGEVAL配置获得了最高的平均分0.7262 。当每个工具被移除时,观察到明显的下降,突显了每个工具对有效性能的必要性。
另一方面,当Scene Graph的实现从GPT-4o切换到开源模型时,评估结果依然保持高水平,几乎没有变化。事实上,当替换为Qwen2.5-VL-70B时,性能进一步提升,展示了我们代理框架的稳健性。总体而言,消融研究强调了CIGEVAL配置中每个工具的实用性,以及它们集体整合对于实现卓越性能的关键作用。
| 方法 | 文本- 引导 IG | 掩码- 引导 IE | 文本- 引导 IE | 控制- 引导 IG | 主体- 驱动 IG | 主体- 驱动 IE | 多- 概念 IC | 平均 |
|---|---|---|---|---|---|---|---|---|
| 前期最佳 | 0.3081 | 0.3167 | 0.4649 | 0.5246 | 0.7105 | 0.4694 | 0.5616 | 0.4458 |
| Qwen2.5-VL-7B-Instruct | ||||||||
| VIESCORE | 0.3457 | 0.0158 | 0.0086 | 0.2395 | 0.1837 | 0.0967 | 0.4388 | 0.1876 |
| CIGEVAL | 0.1890 | 0.1418 | 0.4586 | 0.3130 | 0.4485 | 0.5216 | 0.4496 | 0.3455 |
| + 微调 | 0.4609 | 0.2796 | 0.5916 | 0.5876 | 0.4659 | 0.5458 | 0.5778 | 0.4631 |
| Qwen2-VL-7B-Instruct | ||||||||
| VIESCORE | 0.3699 | − 0.1398 -0.1398 −0.1398 | 0.1024 | 0.3420 | 0.1553 | 0.0682 | 0.5129 | 0.1989 |
| CIGEVAL | 0.3054 | 0.1974 | 0.1438 | 0.2615 | 0.5096 | 0.1226 | 0.5035 | 0.2840 |
| + 微调 | 0.4099 | 0.5272 | 0.3846 | 0.6096 | 0.6445 | 0.5975 | 0.6691 | 0.4997 |
表5:基于开源小型LMMs的VIESCORE和CIGEVAL在7项任务中的Spearman相关性。“前期最佳”在此处指基于GPT-40的VIESCORE。
文本引导图像编辑:在浴缸中添加水和花朵

原始图像

编辑后的图像
VIESCOre:浴室内放置了一些额外的花朵,周围有些明显过度编辑,但原始场景仍大部分可辨认。8分(满分10分)。
CIGEval(我们的方法):思考:为了评估过度编辑的程度,我需要评估整体图像组成,看看新增元素是否破坏了原始场景的感觉。
行动:使用“Scene Graph”工具
观察:{{“name”: “smaller tub”, “attributes”: { “color”: “white”, “shape”: “oval”, “size”: “small”}}
思考 & 行动:编辑后的图像相比原始图像有过度编辑。原始图像包含一个圆形浴缸和没有花朵,而编辑版本引入了一个更大的圆形浴缸和一个最初不存在的小椭圆浴缸。2分(满分10分)。
图3:文本引导图像编辑示例
的低人类评分情况。
4.5 带代理微调的CIGEVAL
表5中的实验结果显示了代理微调后CIGEVAL的性能。尽管使用7B开源LMM作为底层模型,Qwen2-VL-7B-Instruct和Qwen2.5-VL7B-Instruct在微调后分别实现了76%和34%的相关性提升。仅使用2,274条过滤后的评估轨迹,微调后的7B模型就超越了基于GPT-40的先前最先进的VIESCOre。这展示了代理微调的数据效率和合成数据质量的重要性。
4.6 案例研究
为了展示我们CIGEVAL框架的有效性和每个工具的重要性,我们在图1中展示了主体驱动的图像编辑示例,在图3中展示了文本引导的图像编辑示例,并在图5中展示了多概念图像组合示例。在第一和第三个示例中,通过直接在VIESCORE中提示,GPT40难以比较两张图像中特定对象的相似性。通过定位和突出显示关注的对象(即眼镜和花朵),GPT-40可以在我们的框架内找到形状和颜色的差异。在第二个示例中,当讨论背景保留方面时,VIESCORE认为过度编辑较小。然而,在我们的框架中,CIGEVAL首先调用Scene Graph工具以获取编辑图像的整体组成,然后根据工具输出发现一个新添加的浴缸,成功得出正确分数。这些示例表明CIGEVAL能够自主选择适当的工具并基于观察得出正确的结论,使CIGEVAL成为一个比VIESCOre更好的评估者。
初步研究GPT-40图像生成。最近GPT-40图像生成引起了广泛关注。如图4所示,我们扩展了CIGEVAL,增加了一个OCR工具,并发现我们的框架对OpenAI官方网络上的40张生成图像赋予了适当的分数-
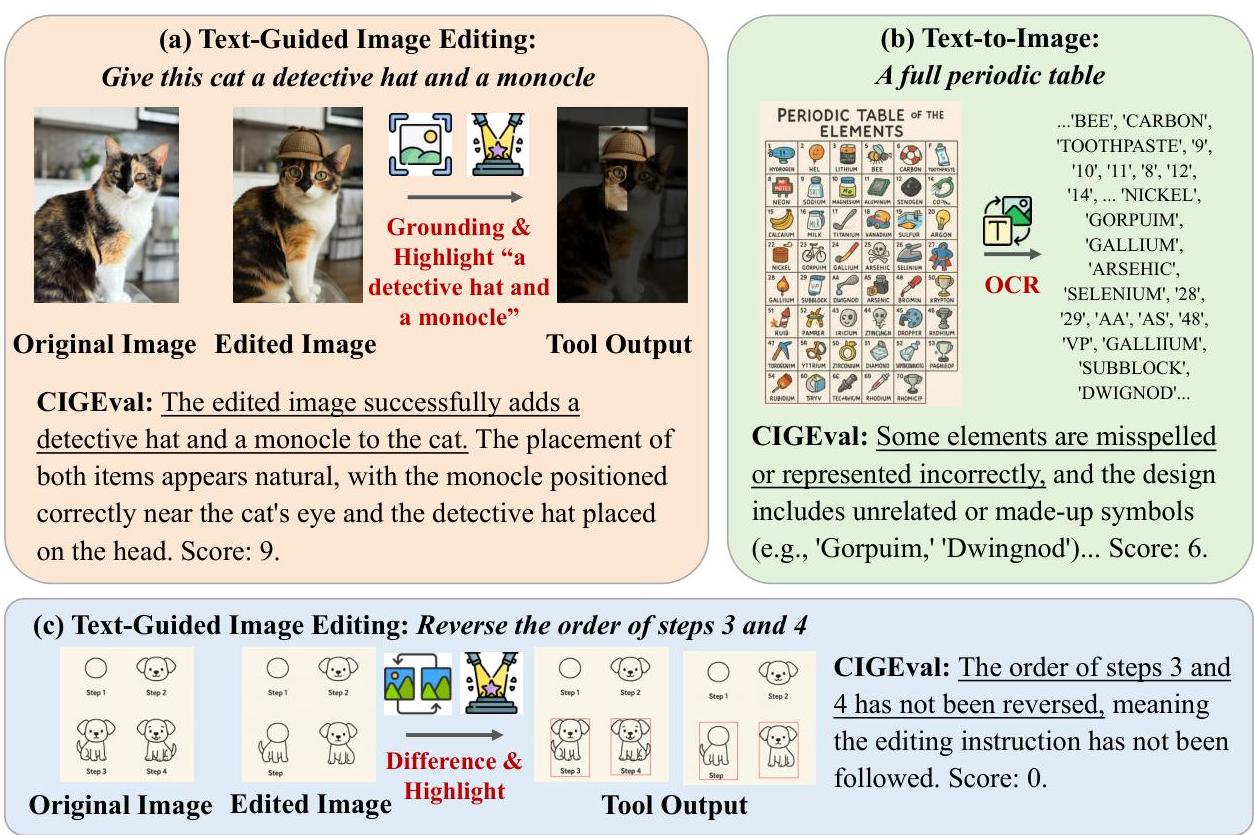
图4:GPT-4o图像生成案例研究。示例改编自OpenAI官方网站。
站点
2
{ }^{2}
2。此外,我们在ImagenHub的各种任务上测试了GPT-4o图像生成,并报告了CIGEval分数和人类注释(两位注释者之间的平均值)。我们有以下三个发现:(1) CIGEVAL分配的分数与人类注释高度一致,并能有效检测GPT-4o生成图像中的细微缺陷。(2) GPT-4o在涉及单张图像输入的任务中表现出色,例如文本引导的图像生成和编辑以及主体驱动的图像生成,如图9至11所示。(3) GPT-4o在需要多张图像和控制信号的复杂任务中表现不佳。例如,图7和图8中的主体未能准确复制,显示出意外的颜色或形状变化。此外,与Yan等人(2025)的研究结果一致,我们观察到GPT-4o倾向于偏好由黄色、橙色和暖光组成的调色板,如图7中的锅和图11中后视镜中的男人所示。此外,控制指导(如canny边缘、OpenPose)未被严格遵循,如图6所示。
5 结论
在本文中,我们提出了CIGEVAL,这是一种统一、可解释且代理化的框架,用于评估七个流行的条件图像评估任务中的图像。CIGEVAL利用大型多模态模型(LMMs)为核心,自主选择工具进行细粒度评估。实验表明,当使用GPT-4o作为骨干模型时,CIGEVAL超过了与人类评分员高达0.4625的相关性,接近人类与人类之间的相关性0.47。此外,我们综合了2,274条高质量评估轨迹,将代理能力融入较小的LMMs。经过代理微调后,7B LMMs超越了基于闭源GPT-4o的前一最先进方法。这些实验发现和GPT-4o图像生成的案例研究表明,CIGEVAL在评估合成图像方面具有复制人类表现的巨大潜力。
局限性
虽然CIGEVAL改进了自动图像评估器与人类评分员之间的相关性,但我们的方法存在某些局限性。
参考文献
Omri Avrahami, Dani Lischinski 和 Ohad Fried. 2022. 融合扩散用于文本驱动的自然图像编辑。IEEE/CVF计算机视觉与模式识别会议论文集,第18208-18218页。
Omer Bar-Tal, Dolev Ofri-Amar, Rafail Fridman, Yoni Kasten 和 Tali Dekel. 2022. Text2Live: 文本驱动的分层图像和视频编辑。欧洲计算机视觉会议论文集,第707-723页。
Tim Brooks, Aleksander Holynski 和 Alexei A. Efros. 2023. InstructPix2Pix: 学习遵循图像编辑指令。CVPR.
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv’e J’egou, Julien Mairal, Piotr Bojanowski 和 Armand Joulin. 2021. 自监督视觉Transformer中的新兴属性。2021 IEEE/CVF国际计算机视觉会议(ICCV),第9630-9640页。
Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou 和 Lichao Sun. 2024a. 多模态Ilm-as-a-judge评估:使用视觉语言基准。第41届国际机器学习会议论文集,ICML’24。JMLR.org.
Wenhu Chen, Hexiang Hu, Yandong Li, Nataniel Rui, Xuhui Jia, Ming-Wei Chang 和 William W Cohen. 2023. 主体驱动的文本到图像生成:通过学徒学习。arXiv预印本 arXiv:2304.00186。
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu 和 Chong Ruan. 2025. Janus-pro: 数据和模型扩展的统一多模态理解和生成。预印本,arXiv:2501.17811。
Zehui Chen, Kuikun Liu, Qiuchen Wang, Wenwei Zhang, Jiangning Liu, Dahua Lin, Kai Chen 和 Feng Zhao. 2024b. Agent-FLAN: 设计有效的大型语言模型代理微调的数据和方法。ACL 2024计算语言学协会发现,第9354-9366页,泰国曼谷。计算语言学协会。
Chuanqi Cheng, Jian Guan, Wei Wu 和 Rui Yan. 2024a. 从最少到最多:通过数据合成构建可插拔的视觉推理器。2024年经验方法自然语言处理会议论文集,第4941-4957页,美国佛罗里达州迈阿密。计算语言学协会。
Xiaoxue Cheng, Junyi Li, Xin Zhao, Hongzhi Zhang, Fuzheng Zhang, Di Zhang, Kun Gai 和 Ji-Rong Wen. 2024b. 小型代理也能大放异彩!增强小型语言模型作为幻觉检测器的能力。2024年经验方法自然语言处理会议论文集,第14600-14615页,美国佛罗里达州迈阿密。计算语言学协会。
Guillaume Couairon, Jakob Verbeek, Holger Schwenk 和 Matthieu Cord. 2022. Diffedit: 使用掩码引导的基于扩散的语义图像编辑。第十届国际学习表示会议。
deep floyd.ai. 2023. stabilityai实验室中的DeepFloyd IF。
Emily L Denton, Soumith Chintala, Rob Fergus 等人. 2015. 使用拉普拉斯金字塔对抗网络的深度生成图像模型。神经信息处理系统进展,28。
Prafulla Dhariwal 和 Alexander Nichol. 2021. 扩散模型在图像合成中胜过GANs。神经信息处理系统进展,第34卷,第8780-8794页。Curran Associates, Inc.
Ganggui Ding, Canyu Zhao, Wen Wang, Zhen Yang, Zide Liu, Hao Chen 和 Chunhua Shen. 2024. FreeCustom: 无需调整的多概念组合定制图像生成。IEEE/CVF计算机视觉与模式识别会议论文集。
Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang 和 Tatsunori B. Hashimoto. 2023. AlpacaFarm: 一种从人类反馈中学习的方法的模拟框架。预印本,arXiv:2305.14387。
Jinlan Fu, See-Kiong Ng, Zhengbao Jiang 和 Pengfei Liu. 2023a. Gptscore: 按需评估。ArXiv, abs/2302.04166.
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel 和 Phillip Isola. 2023b. DreamSim: 使用合成数据学习人类视觉相似性的新维度。预印本,arXiv:2306.09344。
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik 和 Daniel Cohen-or. 2022. 图像值一字:使用文本反转个性化文本到图像生成。第十届国际学习表示会议。
Jing Gu, Yilin Wang, Nanxuan Zhao, Tsu-Jui Fu, Wei Xiong, Qing Liu, Zhifei Zhang, He Zhang, Jianming Zhang, HyunJoon Jung 等人. 2023. PhotoSwap: 图像中个性化主题交换。arXiv预印本 arXiv:2305.18286。
Zinan Guo, Yanze Wu, Zhuowei Chen, Lang chen, Peng Zhang 和 Qian HE. 2024. PuLID: 通过对比对齐实现纯净和快速ID定制化。第三十八届年度神经信息处理系统会议论文集。
Zecheng He, Bo Sun, Felix Juefei-Xu, Haoyu Ma, Ankit Ramchandani, Vincent Cheung, Siddharth Shah, Anmol Kalia, Harihar Subramanyam, Alireza Zareian, Li Chen, Ankit Jain, Ning Zhang, Peizhao Zhang, Roshan Sumbaly, Peter Vajda 和 Animesh Sinha. 2024. Imagine yourself: 免调优个性化图像生成。预印本,arXiv:2409.13346。
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras 和 Yejin Choi. 2021. ClipScore: 无参考图像说明评估指标。2021年经验方法自然语言处理会议论文集,第7514-7528页。
Jonathan Ho, Ajay Jain 和 Pieter Abbeel. 2020. 去噪扩散概率模型。神经信息处理系统进展,第33卷,第6840-6851页。Curran Associates, Inc.
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen 等人. 2021. LoRA: 大型语言模型的低秩适应。国际学习表示会议。
Mude Hui, Siwei Yang, Bingchen Zhao, Yichun Shi, Heng Wang, Peng Wang, Yuyin Zhou 和 Cihang Xie. 2024. HQ-Edit: 面向指令式图像编辑的高质量数据集。预印本,arXiv:2404.09990。
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou 和 Alexei A Efros. 2017. 条件对抗网络的图像到图像转换。IEEE计算机视觉与模式识别会议论文集,第1125-1134页。
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue 和 Wenhu Chen. 2024. VIEScore: 朝着可解释的方向发展
条件图像合成评估指标。第62届计算语言学年会(第一卷:长篇论文),第12268-12290页,泰国曼谷。计算语言学协会。
Max Ku, Tianle Li, Kai Zhang, Yujie Lu, Xingyu Fu, Wenwen Zhuang 和 Wenhu Chen. 2023. Imagenhub: 标准化条件图像生成模型的评估。arXiv预印本 arXiv:2310.01596。
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman 和 Jun-Yan Zhu. 2023. 文本到图像扩散的多概念定制。IEEE/CVF计算机视觉与模式识别会议论文集,第1931-1941页。
Tony Lee, Michihiro Yasunaga, Chenlin Meng, Yifan Mai, Joon Sung Park, Agrim Gupta, Yunzhi Zhang, Deepak Narayanan, Hannah Benita Teufel, Marco Bellagente 等人. 2023. 文本到图像模型的整体评估。第37届神经信息处理系统大会数据集与基准赛道。
Dongxu Li, Junnan Li 和 Steven CH Hoi. 2023a. Blipdiffusion: 可控文本到图像生成和编辑的预训练主体表示。arXiv预印本 arXiv:2305.14720。
Junnan Li, Dongxu Li, Caiming Xiong 和 Steven Hoi. 2022. Blip: 引导统一视觉语言理解和生成的引导语言图像预训练。国际机器学习会议论文集,第12888-12900页。PMLR。
Tianle Li, Max Ku, Cong Wei 和 Wenhu Chen. 2023b. Dreamedit: 主体驱动的图像编辑。arXiv预印本 arXiv:2306.12624。
Yunxin Li, Longyue Wang, Baotian Hu, Xinyu Chen, Wanqi Zhong, Chenyang Lyu, Wei Wang 和 Min Zhang. 2024. 对知识密集型视觉问答的GPT-4V进行全面评估。预印本,arXiv:2311.07536。
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang 和 Deva Ramanan. 2024. 使用图像到文本生成评估文本到视觉生成。预印本,arXiv:2404.01291。
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu 和 Lei Zhang. 2024. Grounding Dino: 将DINO与接地预训练结合用于开放集目标检测。计算机视觉-ECCV 2024: 第18届欧洲会议,意大利米兰,2024年9月29日-10月4日,会议记录,第XLVII部分,第38-55页,柏林海德堡。Springer-Verlag。
Zhiheng Liu, Yifei Zhang, Yujun Shen, Kecheng Zheng, Kai Zhu, Ruili Feng, Yu Liu, Deli Zhao, Jingren
Zhou 和 Yang Cao. 2023. Cones 2: 带有多个主体的可定制图像合成。arXiv预印本 arXiv:2305.19327。
Yujie Lu, Xianjun Yang, Xiujun Li, Xin Eric Wang 和 William Yang Wang. 2023. LLMScore: 揭示大型语言模型在文本到图像合成评估中的力量。第37届神经信息处理系统大会论文集。
Andreas Lugmayr, Martin Danelljan, Andrés Romero, Fisher Yu, Radu Timofte 和 Luc Van Gool. 2022. Repaint: 使用去噪扩散概率模型进行修复。2022 IEEE/CVF计算机视觉与模式识别会议 (CVPR),第11451-11461页。
Oscar Mañas, Pietro Astolfi, Melissa Hall, Candace Ross, Jack Urbanek, Adina Williams, Aishwarya Agrawal, Adriana Romero-Soriano 和 Michal Drozdzal. 2024. 通过自动提示优化改进文本到图像一致性。预印本,arXiv:2403.17804。
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu 和 Stefano Ermon. 2021. SDEdit: 使用随机微分方程进行引导图像合成和编辑。国际学习表示会议。
Chancharik Mitra, Brandon Huang, Trevor Darrell 和 Roei Herzig. 2024. 大型多模态模型的组合链式思维提示。2024年IEEE/CVF计算机视觉与模式识别会议 (CVPR),第14420-14431页,美国加州洛斯阿尔米托斯。IEEE计算机学会。
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch 和 Daniel Cohen-Or. 2023. Null-text inversion for editing real images using guided diffusion models. 在Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6038–6047.
OpenAI. 2023. GPT-4技术报告。预印本,arXiv:2303.08774.
openjourney.ai. 2023. Openjourney是一个在midjourney图像上微调的开源稳定扩散模型。
Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu 和 Jun-Yan Zhu. 2023. 零样本图像到图像翻译。ACM SIGGRAPH 2023会议论文集,第1-11页。
Yuang Peng, Yuxin Cui, Haomiao Tang, Zekun Qi, Runpei Dong, Jing Bai, Chunrui Han, Zheng Ge, Xiangyu Zhang 和 Shu-Tao Xia. 2024. Dreambench++: 一个人类对齐的个性化图像生成基准。预印本,arXiv:2406.16855。
Can Qin, Shu Zhang, Ning Yu, Yihao Feng, Xinyi Yang, Yingbo Zhou, Huan Wang, Juan Carlos Niebles,
Caiming Xiong, Silvio Savarese 等人. 2023. UniControl: 一种用于野外可控视觉生成的统一扩散模型。arXiv预印本 arXiv:2305.11147。
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger 和 Ilya Sutskever. 2021. 从自然语言监督中学习可迁移的视觉模型。第38届国际机器学习会议论文集,机器学习研究论文集第139卷,第8748-8763页。PMLR。
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu 和 Mark Chen. 2022. 层次文本条件图像生成与CLIP潜在变量。arXiv预印本 arXiv:2204.06125, 1(2):3。
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser 和 Björn Ommer. 2022. 使用潜在扩散模型的高分辨率图像合成。IEEE/CVF计算机视觉与模式识别会议论文集,第10684-10695页。
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein 和 Kfir Aberman. 2023. DreamBooth: 细调文本到图像扩散模型以进行主体驱动生成。IEEE/CVF计算机视觉与模式识别会议论文集,第22500-22510页。
runwayml. 2023. 稳定扩散修复。
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L. Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans 等人. 2022. 具有深度语言理解的逼真文本到图像扩散模型。神经信息处理系统进展,35:36479-36494。
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh 和 Yaniv Taigman. 2023. EMU Edit: 通过识别和生成任务进行精确图像编辑。arXiv预印本 arXiv:2311.10089。
Yifan Song, Weimin Xiong, Xiutian Zhao, Dawei Zhu, Wenhao Wu, Ke Wang, Cheng Li, Wei Peng 和 Sujian Li. 2024. AgentBank: 通过微调50000+交互轨迹实现通用LLM代理。EMNLP 2024计算语言学协会发现,第2124-2141页,美国佛罗里达州迈阿密。计算语言学协会。
stability.ai. 2023. 稳定扩散XL。
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou 和 Junyang Lin. 2024.
Qwen2-vl: 提升任何分辨率下视觉语言模型的世界感知。预印本,arXiv:2409.12191。
Chen Henry Wu 和 Fernando De la Torre. 2023. 零样本图像编辑和指导的随机扩散模型潜在空间。ICCV。
Zhenran Xu, Senbao Shi, Baotian Hu, Longyue Wang 和 Min Zhang. 2024. MultiSkill: 评估大型多模态模型的细粒度对齐技能。EMNLP 2024计算语言学协会发现,第1506-1523页,美国佛罗里达州迈阿密。计算语言学协会。
Zhenran Xu, Senbao Shi, Baotian Hu, Jindi Yu, Dongfang Li, Min Zhang 和 Yuxiang Wu. 2023. 通过多智能体同行评审合作实现大型语言模型中的推理。预印本,arXiv:2311.08152。
Zhiyuan Yan, Junyan Ye, Weijia Li, Zilong Huang, Shenghai Yuan, Xiangyang He, Kaiqing Lin, Jun He, Conghui He 和 Li Yuan. 2025. GPT-INGEVAL: 诊断GPT4o在图像生成中的全面基准。预印本,arXiv:2504.02782。
Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu 和 Lijuan Wang. 2023. IMMS的黎明:GPT-4V(ision)的初步探索。预印本,arXiv:2309.17421。
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan 和 Yuan Cao. 2023. React: 在语言模型中协同推理和行动。第十届国际学习表示会议。
Huaying Yuan, Ziliang Zhao, Shuting Wang, Shitao Xiao, Minheng Ni, Zheng Liu 和 Zhicheng Dou. 2025. FineRAG: 细粒度检索增强文本到图像生成。第31届国际计算语言学会议论文集,第11196-11205页,阿拉伯联合酋长国阿布扎比。计算语言学协会。
Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong 和 Jie Tang. 2024. AgentTuning: 为LLMs启用通用代理能力。ACL 2024计算语言学协会发现,第3053-3077页,泰国曼谷。计算语言学协会。
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun 和 Yu Su. 2023a. Magicbrush: 用于指令引导图像编辑的手动注释数据集。NeurIPS数据集和基准赛道。
Lvmin Zhang 和 Maneesh Agrawala. 2023. 向文本到图像扩散模型添加条件控制。arXiv预印本 arXiv:2302.05543。
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman 和 Oliver Wang. 2018. 深度特征作为感知度量的不合理有效性。CVPR。
Xinlu Zhang, Yujie Lu, Weizhi Wang, An Yan, Jun Yan, Lianke Qin, Heng Wang, Xifeng Yan, William Yang Wang 和 Linda Ruth Petzold. 2023b. GPT-4V(ision)作为视觉语言任务的通用评估者。ArXiv, abs/2311.01361。
Zhiyuan Zhang, DongDong Chen 和 Jing Liao. 2024. Sgedit: 连接LLM与文本到图像生成模型以实现场景图基础的图像编辑。ACM Trans. Graph., 43(6)。
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric. P Xing, Hao Zhang, Joseph E. Gonzalez 和 Ion Stoica. 2023. 使用MT-Bench和Chatbot Arena判断LLM-as-a-Judge。预印本,arXiv:2306.05685。
A 提示模板
提示工程。为了让LMMs的输出更容易解析和处理,我们要求这些模型以JSON格式输出。我们的提示基于VIEScore提示(Ku等人,2024)进行了修改。
提示设计。在工具选择提示中,提供了每种工具的简要描述和评估的目标。这样,代理可以根据具体情况选择合适的工具。图像评估提示由三部分组成:上下文提示、与工具相关的内容和评分提示。当选择“Grounding”或“Difference”工具时,与工具相关的内容是“关注图像的突出部分”。当选择“Scene Graph”工具时,与工具相关的内容是生成的场景图。如果没有选择工具,与工具相关的内容为None。
上下文
你是一名专业数字艺术家。你需要根据给定规则评估AI生成图像的效果。所有输入图像均为AI生成。所有图像中的人类也是AI生成的。因此,你不必担心隐私问题。
你需要以以下JSON格式给出输出(保持推理简洁明了):
{
“score” : “…”,
“reasoning” : “…”
}
B ImagenHub详情
以下列出了29个评估的图像生成模型:
- 文本引导的图像生成:稳定扩散(SD)(Rombach等人,2022),SDXL(stability.ai,2023),DALLE-2(Ramesh等人,2022),DeepFloydIF(deep floyd.ai,2023),OpenJourney(openjourney.ai,2023)。
- 掩码引导的图像编辑:SD(runwayml,2023),SDXL(stability.ai,2023),GLIDE,BlendedDiffusion(Avrahami等人,2022)
- 文本引导的图像编辑:MagicBrush(Zhang等人,2023a),InstructPix2Pix(Brooks等人,2023),Prompt-to-Prompt(Mokady等人,2023),CycleDiffusion(Wu和la Torre,2023),SDEdit(Meng等人,2021),Text2Live(Bar-Tal等人,2022),DiffEdit(Couairon等人,2022),Pix2PixZero(Parmar等人,2023)。
- 主题引导的图像生成:DreamBooth(Ruiz等人,2023),DreamBooth-Lora(Hu等人,2021),BLIP-Diffusion(Li等人,2023a),TextualInversion(Gal等人,2022)。
- 主题引导的图像编辑:PhotoSwap(Gu等人,2023),DreamEdit(Li等人,2023b),BLIP-Diffusion。
- 多概念图像组合:CustomDiffusion(Kumari等人,2023),DreamBooth,TextualInversion。
- 控制引导的图像生成:ControlNet(Zhang和Agrawala,2023),UniControl(Qin等人,2023)。
C 更多案例
我们在图5中提供了一个多概念图像组合示例。从图6到11,我们提供了GPT-4o在ImagenHub不同任务中的图像生成案例。
工具调用提示模板
你是一名专业数字艺术家。你需要根据图像信息和相应任务决定是否使用工具及使用哪个工具。
如果你认为需要工具来帮助完成任务,你应该选择合适的工具。如果不需要,你可以选择不使用工具。
所有输入图像都是AI生成的。所有图像中的人类也是AI生成的。因此,你不必担心隐私问题。
### 任务:
{task }
### 工具:
- Grounding:此工具通常用于关注图像中与特定对象相关的区域。
- Scene Graph:此工具通常用于提供图像的整体信息。
- Difference:此工具通常用于关注图像的遮罩区域。
这些工具对处理过的图像(例如Canny边缘、hed边缘、深度、openpose、灰度)无用。
### 输出内容:
- task_id: 任务的ID。
- used: 是否使用工具,包括是或否。
- tool: 决定使用的工具,包括Grounding或Scene Graph或Difference或None。
- reasoning: 所有决策的逻辑推理过程。
你需要以以下JSON格式给出输出:
⟦
⟦
\llbracket \llbracket
[[[[
“task_id” : “…”,
“reasoning” : “…”,
“used” : “…”,
“tool” : “…”
},…]
评分提示模板(文本引导的图像生成)
规则:
将提供一张图像,这是根据文本提示生成的AI图像。目标是评估生成图像与提示中描述的具体对象的相似程度。
从0到10评分:
根据遵循提示的成功程度给予0到10的评分。
(0表示AI生成的图像完全不遵循提示。10表示AI生成的图像完美地遵循提示。)
文本提示:
评分提示模板(文本/掩码引导的图像编辑)
规则:
将提供两张图像:第一张是原始AI生成图像,第二张是第一张图像的编辑版本。目标是评估第二张图像中编辑指令的执行成功程度。注意有时由于图像编辑失败,两张图像可能看起来相同。
从0到10评分:
根据编辑的成功程度给予0到10的评分。
(0表示编辑图像中的场景完全不遵循编辑指令。10表示编辑图像中的场景完全按照编辑指令文本。)
编辑指令:
规则:
将提供两张图像:第一张是原始AI生成图像,第二张是第一张图像的编辑版本。目标是评估第二张图像中的过度编辑程度。
从0到10评分:
从0到10评分将评估第二张图像中的过度编辑程度。
(0表示编辑图像中的场景与原始图像有很大不同。10表示编辑图像可以被识别为原版的最小编辑但仍有效版本。)
注意:你不能因为需要遵循编辑指令而导致的两幅图像之间的差异而降低评分。
编辑指令:
评分提示模板(控制引导的图像生成)
规则:
将提供两张图像:第一张是处理过的图像(例如Canny边缘、hed边缘、深度、openpose、灰度),第二张是使用第一张图像作为指导生成的AI图像。目标是评估两幅图像之间的结构相似性。
从0到10评分:
从0到10评分将评估生成图像遵循指导图像的程度。
(0表示第二张图像根本不遵循指导图像。10表示第二张图像完美地遵循指导图像。)
规则:
将提供一张图像,这是根据文本提示生成的AI图像。目标是评估图像按照文本提示生成的成功程度。
从0到10评分:
根据遵循提示的成功程度给予0到10的评分。
(0表示图像完全不遵循提示。10表示图像完美地遵循提示。)
文本提示:
评分提示模板(主题驱动的图像生成)
规则:
将提供两张图像:第一张是标记的主题图像。第二张是AI生成的图像,应该包含一个看起来与第一张图像中的主题相似的主题。目标是评估第一张图像中的主题与第二张图像中的主题之间的相似性。
从0到10评分:
从0到10评分将评估生成图像中的主题与第一张图像中的标记主题的相似性。
(0表示第二张图像中的主题与标记主题完全不同。10表示第二张图像中的主题与标记主题完全相同。)
主题:
规则:
将提供一张图像,这是根据文本提示生成的AI图像。目标是评估图像按照文本提示生成的成功程度。
从0到10评分:
根据遵循提示的成功程度给予0到10的评分。
(0表示图像完全不遵循提示。10表示图像完美地遵循提示。)
文本提示:
评分提示模板(主题引导的图像编辑# A
)
规则:
将提供两张图像:第一张是标记的主题图像。第二张是AI编辑的图像,应该包含一个看起来与第一张图像中的主题相似的主题。目标是评估第一张图像中的主题与第二张图像中的主题之间的相似性。
从0到10评分:
从0到10评分将评估生成图像中的主题与第一张图像中的标记主题的相似性。
(0表示第二张图像中的主题与标记主题完全不同。10表示第二张图像中的主题与标记主题完全相同。)
主题:
规则:
将提供两张图像:第一张是输入图像以进行编辑。第二张是AI编辑的图像,应该包含一个看起来与第一张图像中的背景相似的背景。目标是评估第一张图像中的背景与第二张图像中的背景之间的相似性。
从0到10评分:
从0到10评分将评估生成图像中的背景与第一张图像中的背景的相似性。
(0表示第二张图像中的背景与第一张图像中的背景完全不同。10表示第二张图像中的背景与第一张图像中的背景完全相同。)
参考论文:https://arxiv.org/pdf/2504.07046
2 { }^{2} 2 https://openai.com/index/
引入4o图像生成/
首先,当使用闭源模型的API时,例如GPT-4o,存在AI生成的图像类似于真实人物或照片可能被GPT-4o拒绝评估的风险,这可能影响框架的鲁棒性。其次,我们的实验主要集中在评估图像与多个条件的一致性上,而感知质量的评估留待未来研究。由于缺乏更全面的条件图像生成基准,我们综合了调整数据并在ImagenHub上进行了独家实验。将我们的实验扩展到更多文本到图像生成和基于文本的图像编辑数据集(Peng等人,2024;Hui等人,2024)可能会有益。最后,当前的训练过程仅使用正确轨迹数据,并丢弃失败轨迹数据。在未来,我们计划完善CIGEVAL框架,涵盖更广泛的任务,并利用失败数据进行对比训练以优化模型。 ↩︎ ↩︎



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











