






山连磊、罗世贤、朱泽舟、袁宇、吴勇*
智能云集团
理想汽车
{shanlianlei,luoshixian, zhuzezhou, yuanyu,wuyong}@lixiang.com
摘要
本文对大型语言模型(LLMs)中的记忆机制进行了深入探讨,分析了不同类型的记忆及其在这些模型中的作用。记忆是智能代理工作流程中的关键元素,与知识和画像密切相关,但具有独特的粒度和功能属性。尽管LLMs具备信息检索和对话总结的能力,但它们缺乏稳定且结构化的长期记忆。将记忆整合到AI系统中对于提供上下文丰富的响应、减少幻觉、提高数据处理效率以及推动AI系统的自我进化至关重要。本文首先介绍了记忆的认知架构,将其分为感觉记忆、短期记忆和长期记忆。人类的感觉记忆通过感官捕捉短暂的信息,而在LLMs中,这对应于输入请求或提示。人类的短期记忆保存信息的时间较短,而LLMs则在即时上下文窗口内处理输入。人类的长期记忆包括显性记忆(情景记忆和语义记忆)和隐性记忆(程序性记忆),而LLMs通过外部数据库、向量存储或图结构实现长期记忆。文本记忆部分讨论了记忆获取、管理和利用。记忆获取涉及选择和压缩历史信息,使用的方法包括记忆选择和总结。记忆管理涵盖更新、访问和存储记忆,以及解决冲突记忆。记忆利用侧重于检索方法,包括全文搜索、SQL查询和语义搜索。基于KV缓存的记忆部分介绍了各种KV选择和压缩策略。KV选择方法包括基于规律的总结、基于分数的方法和特殊标记嵌入。KV压缩技术涉及低秩压缩、KV合并和多模态压缩。记忆管理策略包括卸载记忆、与操作系统集成以及使用共享注意力机制。本文还探讨了基于参数的记忆方法,如LoRA、测试时训练(TTT)和专家混合(MoE)。这些方法将记忆转化为模型参数,提高了记忆效率和利用率。最后,本文讨论了基于隐藏状态的记忆,包括块机制、递归变压器和Mamba模型。这些方法结合了RNNs中的隐藏状态概念与当前方法,以改进长文本的处理和记忆效率。总体而言,本文对LLMs中的记忆机制进行了全面分析,突出了其重要性,并为未来的研究方向提供了指导。
*团队负责人
# 目录
1 引言 … 4
2 认知架构 … 4
2.1 记忆类别 … 5
2.1.1 感觉记忆 … 5
2.1.2 短期记忆 … 5
2.1.3 长期记忆 … 6
2.2 人类记忆与LLMs之间的关键差异与平行关系 … 7
2.2.1 人类记忆 … 7
2.2.2 LLMs信息 … 7
2.2.3 平行与差异 … 8
3 基于文本的记忆 … 8
3.1 记忆获取 … 9
3.1.1 记忆选择 … 9
3.1.2 记忆总结 … 9
3.1.3 双重方法 … 10
3.2 记忆管理 … 10
3.2.1 记忆更新 … 11
3.2.2 记忆访问 … 11
3.2.3 记忆存储的数据结构 … 12
3.2.4 处理矛盾记忆 … 13
3.3 记忆利用 … 13
3.3.1 全文搜索 … 14
3.3.2 结构化查询语言 … 14
3.3.3 语义搜索 … 14
3.3.4 树形搜索 … 14
3.3.5 哈希搜索 … 14
3.3.6 多次搜索 … 15
4 基于KV缓存的记忆 … 15
4.1 记忆获取:KV选择 … 16
4.1.1 规律策略 … 16
4.1.2 值向量范数和熵策略 … 17
4.1.3 分数策略 … 17
4.1.4 特殊标记嵌入策略 … 19
4.1.5 基于学习的标记选择策略 … 19
4.1.6 不同层和不同头采用不同的标记选择策略 … 20
4.1.7 不同层和不同头采用相同的标记选择策略 … 21
4.1.8 局部敏感哈希策略 … 22
4.1.9 回溯策略 … 22
4.2 记忆获取:KV压缩 … 22
4.2.1 低秩压缩 … 22
4.2.2 KV合并 … 23
4.2.3 多级KV压缩 … 23
4.2.4 KV量化 … 24
4.3 记忆管理 … 24
4.3.1 卸载 … 24
4.3.2 与操作系统集成的记忆管理 … 25
4.3.3 共享注意力 … 26
4.3.4 KV缓存压缩与注意力的关系 … 26
5 参数基础的记忆 … 27
5.1 LoRA用于记忆参数化 … 27
5.2 测试时训练用于记忆参数化 … 27
5.3 MoE用于记忆参数化 … 28
6 隐藏状态基础的记忆 … 29
6.1 块机制 … 29
6.2 递归变压器 … 30
6.3 Mamba … 31
7 讨论 … 32
1 引言
记忆,更准确地说是记忆集合,构成了代理工作流程中的一个关键基础元素,与知识和画像紧密交织在一起。然而,由于它与“知识”和“画像”相比具有独特的粒度和功能属性,因此值得单独且集中关注。画像描述了代理如何理解自身身份(包括性格和“化身”)、功能(行为模型)以及操作环境(环境)。知识则提供了支持决策过程的事实信息或学习表示。相比之下,记忆作为动态经验库,整合了这些元素并积极参与决策。尽管经过几十年的研究,大型语言模型(LLMs)的一致记忆保留能力仍然是一个持续探索的领域。当代AI系统能够进行信息检索、对话总结和选择性细节存储。然而,它们缺乏一种可以可靠地持久存在的稳定且结构化的记忆。
在人工智能领域,记忆的整合变得越来越重要。随着AI系统复杂性的增加,记忆功能的引入为这些系统带来了许多显著优势,推动了多个维度的发展。
首先,记忆整合使AI系统能够提供上下文丰富的响应。传统的大型语言模型(LLMs)通常是无状态的,孤立地处理每个提示而不保留先前的上下文信息。然而,通过增强记忆的LLMs突破了这一限制,实现了跨交互的连续性。它们可以同时利用短期上下文和长期数据,从而为用户提供更深入和个性化的响应,显著提升用户体验。其次,记忆整合有助于减轻幻觉现象。当LLMs试图填补检索中的空白但缺乏相关知识时,幻觉现象可能会发生。通过将响应锚定在存储的事实中,即通过检索增强生成(RAG)技术,记忆系统可以有效减少此类错误。尽管RAG的实施面临高级数据处理需求等挑战,其局限性正在不断解决。例如,Graph-RAG方法通过利用图结构来提高检索准确性和可扩展性,提供了新的见解和路径来解决这一问题。第三,记忆整合实现了高效的数据处理。在实际应用中,手动审查大量文档(如PDF文件或财务报表)不仅耗时而且容易出错。相比之下,配备记忆功能的LLM管道可以自动摄取、分类和存储数据,并按需检索。这种架构支持目标检索,减少了不必要的API调用或数据库查询,从而降低计算成本,提高工作效率,并加速各行业的业务流程。最后,记忆整合是AI系统迈向自我进化的关键步骤。将长期记忆整合到AI系统中,使LLMs能够在数据或交互有限的情况下像人类学习一样适应新任务。这不仅提升了它们在现实场景中的性能和适用性,还为AI的未来发展奠定了坚实基础,推动更多领域的突破和创新。
本文将阐明记忆的各种类型及其在代理工作流程中的各自作用。还将探讨这些组件如何在实际应用中融合,澄清模型在记忆模式下“记住”信息的机制,并研究生成式AI对记忆本质的变革影响。我们首先深入认知架构,明确记忆的分类以及人类和LLMs处理记忆方式的区别。随后,我们分析LLM记忆的当前研究状态。最后,我们介绍LLM记忆的未来趋势:认知记忆。
2 认知架构
认知架构是研究人类思维和智能行为的重要工具,其历史可以追溯到几十年前。Kotseruba 和 Tsotsos [2020]回顾了过去40年认知架构的发展,重点研究了它们在模拟核心人类认知能力(如记忆、感知、注意和决策)方面的研究和应用。通过模拟心理学实验(如工作记忆测试和注意力实验),研究人员验证了认知架构模拟人类认知过程的能力。
Soar 认知架构 Laird [2019] 和 ACT-R 认知架构 Ritter 等人 [2019] 是认知架构领域的重要成果。Soar 是一个通用智能系统,可以通过其通用问题求解器(GPS)模块处理从简单逻辑推理到复杂战略游戏的各种问题类型。它还支持多种学习机制,如基于规则的学习和基于案例的学习。ACT-R 专注于模拟人类认知过程,特别是记忆、学习和决策。它通过详细的记忆模型研究工作记忆与长期记忆的交互,并能模拟人类在复杂任务中的决策。这些架构不仅在人工智能研究中发挥了重要作用,还通过心理学实验验证了它们模拟人类认知过程的能力。ICARUS 认知架构 Langley 和 Choi [2006] 代表了认知架构研究的一个新兴方向。ICARUS 致力于通过模拟人类认知过程开发具有自主学习和适应能力的智能系统。它支持自主学习机制,可以通过与环境的互动学习新知识,并处理复杂的任务,如机器人导航和多任务处理。ICARUS 的研究进一步促进了认知架构在人工智能和认知心理学领域的应用和发展。在认知架构中,记忆分为三种类型:感觉记忆、短期记忆和长期记忆。
2.1 记忆类别
2.1.1 感觉记忆
在人类中,感觉记忆是指我们在感知后的最初几秒内通过感官(视觉、听觉或其他感官)获取的信息,之后要么被丢弃,要么转移到短期记忆中。在LLM系统中,SM对应于输入到系统的API请求或提示。感觉记忆捕捉周围环境的快速印象,比如驶过车辆的闪光或脚步声,但这些印象几乎瞬间消失。
2.1.2 短期记忆
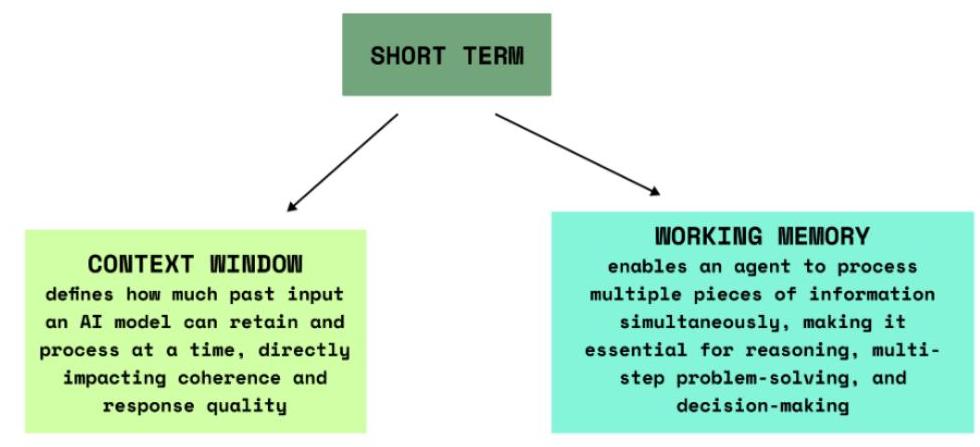
图1:短期记忆
短期记忆(STM)定义如图1所示。人类短期记忆持有并操纵少量处于活跃状态的信息。在LLMs中,STM可以认为是在处理输入——当前可用以供提示处理的文本标记或嵌入——在即时上下文窗口内。一旦该会话结束,模型通常会“丢失”该上下文。
上下文窗口定义了AI模型在一个交换中可以保留多少过去的输入。这一限制在LLMs中至关重要——给AI一个极小的上下文窗口,它会忘记你刚才说的话。扩展这个窗口,它可以维持更长对话的连续性,使响应更加连贯和自然。
工作记忆在多步推理和决策中起着至关重要的作用。正如人类使用工作记忆同时保持多个想法一样——比如在解决问题时——AI代理依赖于它来同时处理多个输入。这对复杂任务如规划尤为重要,因为代理需要在做出决定之前平衡不同的信息片段。
2.1.3 长期记忆
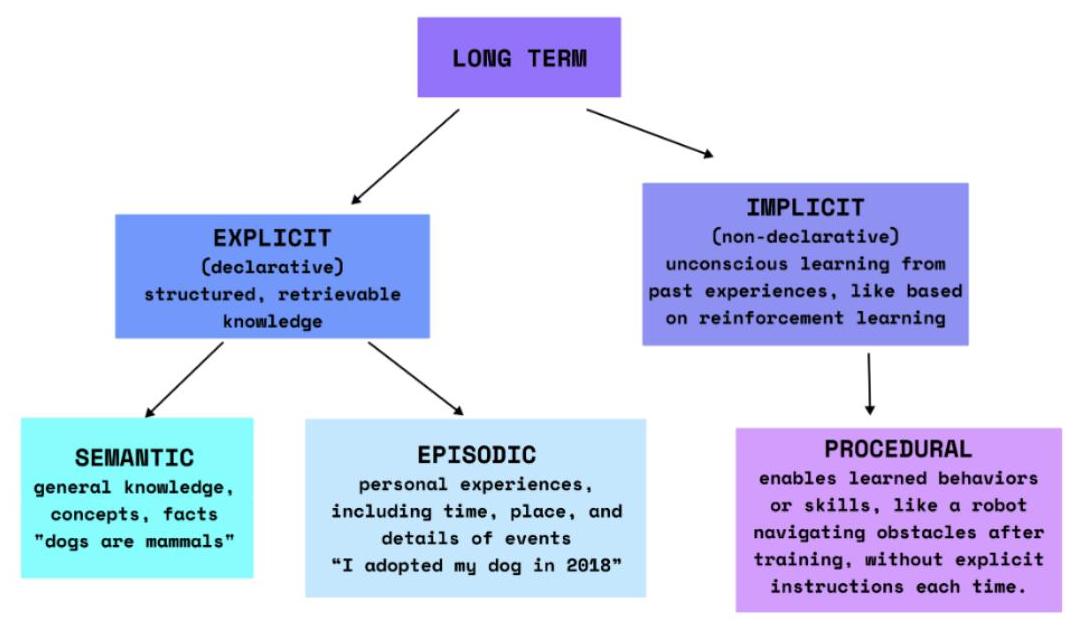
图2:长期记忆
在人类中,长期记忆保留知识、经验和技能。长期记忆分为显性(陈述性)记忆,这是有意识的,包括情景记忆(生活事件)和语义记忆(事实和概念),以及隐性(程序性)记忆,这是无意识的,涵盖技能和习得任务,如图2所示。对于LLMs,LTM可以通过外部数据库、向量存储或图结构实现,这些结构保持相关数据可用,并允许模型在未来的查询中“回忆”信息。
显性记忆使AI能够回忆事实、规则和结构化知识。在这个类别中,语义记忆负责存储一般真理和常识。AI中的语义记忆与其人类对应物相似——它涉及事实信息的存储。AI系统使用语义记忆来保留和回忆训练材料中的事实和一般知识。例如,数字助理使用语义记忆从用户手册中检索产品信息。
情景记忆更具个人特色——它捕捉特定事件和经历,使代理能够记住过去的互动情境。如果客户服务AI记得用户以前要求退款,它可以相应地调整其响应,使互动感觉更直观和人性化。AI的情景记忆与根据过去互动或经历进行情境化的功能有关。这种类型的记忆对客户服务等领域的AI模型至关重要,因为它可以回忆之前的客户对话以优化最佳解决方案。此外,情景记忆可以回忆与个别客户的以往对话,提供个性化服务,就像销售人员记住与客户的过往接触一样。在服务和体验领域,情景记忆使AI能够捕捉交付有效自动化的部落知识。
隐性记忆则是使AI发展直觉的能力,涉及保留和回忆完成任务所需的步骤。它由程序性记忆驱动,帮助代理在不需要明确回忆的情况下学习技能。想想一辆自动驾驶汽车,它在数千英里的训练后提高了车道保持能力。汽车不需要“记住”每一个具体场景——它逐渐形成了一种导航道路的直观理解。当你真正体验到这一点时——这确实令人惊叹。在AI中,程序性记忆允许系统执行通过重复训练学到的自动化功能。一个常见的例子是在工厂环境中操作机器。在客户服务和客户体验的背景下,程序性记忆使AI能够执行多步骤序列,有效地解决甚至复杂的客户需求。
2.2 人类记忆与LLMs的关键差异和平行关系
2.2.1 人类记忆
人类记忆是一种复杂且至关重要的认知功能,与我们的情感、体验和生物学过程紧密相连。它可以基本分为三类主要类型:感觉记忆、短期记忆和长期记忆。
感觉记忆负责捕捉来自环境的短暂感知刺激,例如飞驰而过的车辆的短暂视觉印象或脚步声的瞬时听觉提示。然而,这些感官痕迹通常会在瞬间消散,仅持续几分之一秒。
相比之下,短期记忆充当临时存储系统,用于存储即时使用的所需信息。它使个体能够在短时间内保留少量数据,通常持续几秒到几分钟。一个典型的例子是查找电话号码并拨号而无需写下号码。此过程展示了短期记忆在管理即时任务中的作用。
长期记忆代表承载持久知识、技能和情感体验的储存库,定义了人类认知和行为的丰富性。它包含两个主要子类别:陈述性记忆,涉及事实信息和情节事件的保留;程序性记忆,涉及已学习任务、习惯和运动技能的保留。从短期到长期存储的记忆过渡称为巩固,这一过程高度依赖于大脑的神经生物学机制,尤其是海马体。这个关键的大脑区域在强化和整合记忆方面发挥着核心作用,从而促进它们的长期保留。
人类记忆并非静态;它是本质上动态且可塑的。记忆可以根据新体验、情感意义和背景因素进行修改、更新甚至重建。这种适应性对于学习和认知发展至关重要,因为它使个体能够选择性地保留相关信息,同时丢弃不那么重要的细节。然而,这种灵活性也使人类记忆容易出现不准确和偏差。记忆往往不是以原始形式完全恢复,而是受到诸如背景、情绪状态和个人解释等各种因素的影响而重新构建。虽然这偶尔会导致不可靠性,但它强调了人类记忆的复杂和适应性本质,这从根本上区分了它与人工智能中使用的更僵化和确定性的记忆系统。
2.2.2 LLMs信息
与人类记忆在处理和存储信息时采用的基本原则相比,大型语言模型(LLMs)存在根本区别。这些模型是在包含各种文本来源(如书籍、网站和文章)的广泛数据集上进行训练的。在训练过程中,LLMs识别并学习语言中的统计模式,辨别单词和短语之间的关系。与人类记忆不同,LLMs没有传统意义上的记忆系统;相反,它们将这些语言模式编码为大量的参数——通常是数十亿个数值。这些参数决定了模型如何根据输入提示预测和生成响应。LLMs缺乏类似人类的显性记忆存储。当接收到查询时,LLM不会保留先前交互或训练期间使用的特定数据的记录。相反,它通过基于训练数据中学到的模式计算最可能的词序列来生成响应。这一过程由复杂的算法,特别是变压器架构,所促进,该架构包含注意力机制。这种机制使模型能够选择性地关注输入文本的相关部分,从而产生连贯且上下文适当的响应。本质上,
LLMs的“记忆”并不是真正的记忆系统,而是其训练过程的一种涌现属性。它们依靠编码的模式生成响应,任何适应或学习只能通过重新训练新数据来实现。这是与人类记忆的一个关键区别,人类记忆通过连续的经验输入动态演变,并在实时中本质上具有适应性。
2.2.3 平行与差异
尽管人类和大型语言模型(LLMs)在信息处理方面存在根本差异,但也存在一些值得注意的平行关系。两者都严重依赖于模式识别来处理和解释数据。在人类中,模式识别对于学习至关重要,使得面部识别、语言理解和过去经历的回忆成为可能。同样,LLMs在模式识别方面表现出色,利用其训练数据学习语言的细微之处、预测序列中的后续单词并生成连贯的文本。上下文是影响人类记忆和LLMs的另一个关键因素。对于人类记忆,上下文增强了信息回忆的有效性。例如,在学习发生的相同环境中,更容易触发相关的记忆。LLMs也利用输入文本提供的上下文来引导其响应。变压器架构允许LLMs选择性地关注输入文本中的特定标记(单词或短语),确保响应与周围的上下文一致。
此外,人类和LLMs都表现出类似于初级效应和近期效应的现象。人类倾向于更容易记住列表开头和结尾的项目,这被称为初级效应和近期效应。在LLMs中,这一点反映在模型如何根据输入序列中的位置为特定标记分配更大的权重。变压器中的注意力机制通常优先考虑较新的标记,使LLMs能够生成上下文适当的响应,类似于人类如何依赖最近的信息来引导回忆。
然而,人类记忆和LLMs之间的差异更为深刻。一个重要区别在于记忆形成的本质。人类记忆是动态的,不断演变,受新体验、情感和上下文的影响。学习新信息可以改变现有记忆,并改变它们被感知和回忆的方式。相比之下,LLMs在训练后是静态的。一旦LLM在数据集上训练完成,其知识直到再次训练才会更新。它无法根据新体验实时调整或更新其记忆。
另一个关键区别在于信息的存储和检索方式。人类记忆是有选择性的,具有情感意义的事件更有可能被记住,而琐碎的细节则会随着时间推移而淡忘。LLMs缺乏这种选择性。它们将信息作为参数中编码的模式存储,并根据统计可能性检索信息,而不是根据相关性或情感意义。这导致了一个鲜明对比:LLMs没有重要性或个人体验的概念,而人类记忆是深刻个人化的,并由赋予不同体验的情感权重塑造。最重要的区别之一在于遗忘的功能。人类记忆具有适应性遗忘机制,防止认知超载并帮助优先处理重要信息。遗忘对于保持专注和腾出空间以容纳新体验至关重要,使人类能够丢弃过时或无关的信息并不断更新记忆。
相比之下,LLMs不具备适应性遗忘。一旦训练完成,它们会保留暴露数据集中的所有信息。只有在使用新数据重新训练时,模型的知识才会更新。然而,在实践中,由于令牌长度限制,LLMs在长时间对话中可能出现“遗忘”早期信息的情况。这是一个技术约束,而非认知过程。
最后,人类记忆与意识和意图密切相关。人类主动回忆特定记忆或抑制其他记忆,通常由情感和个人意图引导。相比之下,LLMs缺乏意识、意图或情感。它们基于统计概率生成响应,没有任何潜在的理解或刻意的聚焦。
3 文本记忆
在本章中,我们介绍以文本形式存储的记忆。我们讨论记忆获取、记忆管理和记忆利用。记忆获取指的是选择和压缩历史信息以存储在记忆库中的过程。这一过程可以分为三种方法:记忆选择、记忆总结以及两者的结合。
记忆管理涉及存储在记忆库中的记忆的存储、更新和访问机制,以及解决冲突记忆。记忆利用则与记忆检索有关,即根据当前信息(如查询)获取最相关记忆的过程。这包括全文搜索、基于SQL的搜索、语义搜索、基于树的搜索、基于哈希的搜索、多遍搜索以及结合多种方法的混合搜索方法。获取、管理和利用涵盖了文本记忆的整个过程。本章的结构如上图所示。
3.1 记忆获取
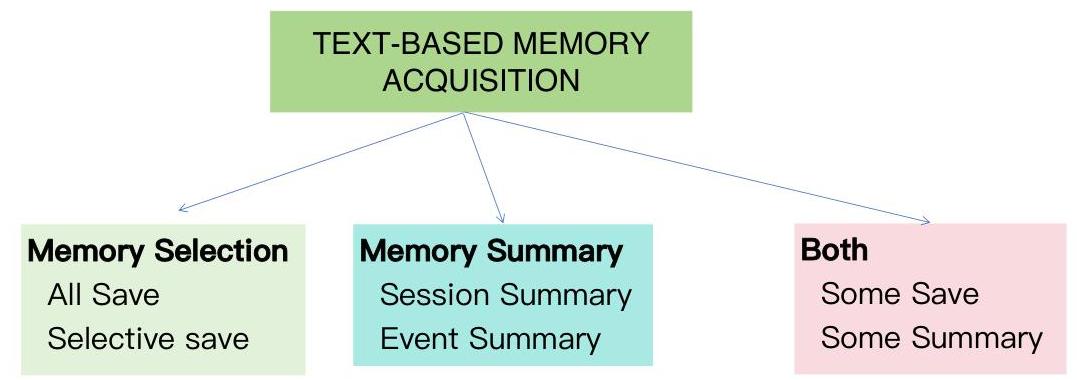
图3:基于文本的记忆获取。
记忆获取包括三种方式:记忆(或称为文本)选择、记忆总结以及两者的结合。
3.1.1 记忆选择
记忆选择指的是保留对话或文本内容的所有或部分的选择过程。最简单的方法是保留所有历史信息作为记忆。在此基础上,研究人员提出了许多基于预设策略的选择方法。例如,丢弃问候语或缺乏信息内容的文本 []。这是一种初步方法,通常用作工作的基线。总之,选择策略可以根据预设标准灵活定义。
3.1.2 记忆总结
记忆总结指的是在压缩对话或文本后保留摘要内容的方法。
COMEDY Chen等人[2024b] 面临着从超过50万数据点的超大数据集中提取和生成对话级记忆的挑战。为了解决这个问题,COMEDY专注于大约40,000个数据点的子集。使用GPT4-Turbo提取对话级记忆(包括事件、用户和机器人描述),然后由注释者编辑以确保信息的完整性和准确性,创建对话级记忆集合
M
M
M。此外,COMEDY 开发了专门用于生成对话级记忆的LLM,并过滤掉无效样本以确保数据质量。在记忆压缩任务中,COMEDY 使用 GPT4-Turbo 总结任务1中的所有对话级记忆
M
M
M 并输出压缩后的记忆
M
ˉ
\bar{M}
Mˉ。此过程包括创建综合用户画像、捕捉用户与机器人之间的动态交互以及记录关键事件。为了平衡创造力和相关性,GPT4-Turbo 在温度设置为0.9时生成三个输出。注释者随后细化和校准这些输出,纠正任何不准确或不一致之处,并在必要时增强清晰度和简洁性,以确保总结准确反映用户画像、交互动态和事件记录。
Memory Bank Zhong 等人[2024] 采用分层事件总结和动态个性理解的方法来模拟人类记忆的复杂性并提升用户体验。它将对话浓缩成每日事件总结和全局总结,创建分层记忆结构,为用户提供过去互动的宏观视角。此外,Memory Bank 通过长期互动不断更新对用户个性的理解,生成每日个性洞察并将这些洞察汇总成全局理解。这种方法使AI伴侣能够根据个人用户的特征定制响应,实现更个性化的互动。
在Lee等人[2024]的研究中,LLMs通过将文档分割成最大为max words的块,确保每步至少处理min words。max words与min words的比例决定了LLM可以处理的最大词数。此外,基于记忆的总结从每个块独立提取摘要。在检索过程中,基于摘要的并行搜索显著减少了相对于顺序搜索原始文本的处理时间。生成答案的过程与并行搜索类似,但由于提示模板会增加额外开销。优化分块和总结策略可以有效提升LLM的处理效率。
在Liu等人[2023]的研究中,归纳推理被定义为包含两个实体之间关系的文本,即关系三元组
(
E
h
,
r
i
,
E
t
)
.
E
h
\left(E_{h}, r_{i}, E_{t}\right) . E_{h}
(Eh,ri,Et).Eh是通过关系
r
i
r_{i}
ri连接到尾实体
E
t
E_{t}
Et的头实体,其中
i
∈
[
0
,
N
]
i \in[0, N]
i∈[0,N]且
N
N
N是关系的数量。概念上,
R
h
=
{
r
1
,
⋯
,
r
N
}
R_{h}=\left\{r_{1}, \cdots, r_{N}\right\}
Rh={r1,⋯,rN}表示实体
E
h
E_{h}
Eh的所有一跳关系。
将归纳推理应用于大型语言模型的主要挑战在于获取与关系三元组匹配的高质量句子。本文提供了两种获取归纳推理的方法:(1) 预训练模型用于开放信息提取,例如OpenIE Manning等人[2014]; (2) 基于大语言模型的少样本提示上下文学习。在本工作中,作者采用了第二种方法,即使用大型语言模型AgentA生成归纳推理。
3.1.3 两者结合
记忆构建是基于记忆模型的关键问题。不同形式或来源的记忆可以显著影响模型的效果。在 Yuan 等人[2023]的研究中,探讨了三种不同类型的记忆,并比较了它们对模型性能的影响。这项研究探讨了三种类型记忆对模型性能的影响。基于历史记录的记忆直接使用未处理的对话历史,简单实用但容易冗余。基于摘要的记忆通过对话摘要提供更丰富的上下文,但可能会丢失细节。条件记忆评估话语的重要性,仅存储关键信息,并将记忆分为两部分:上下文和知识,以提高记忆效率和相关性。此外,该研究尝试多视角记忆,结合各种类型的记忆,为响应生成提供更多样化的信息。
3.2 记忆管理
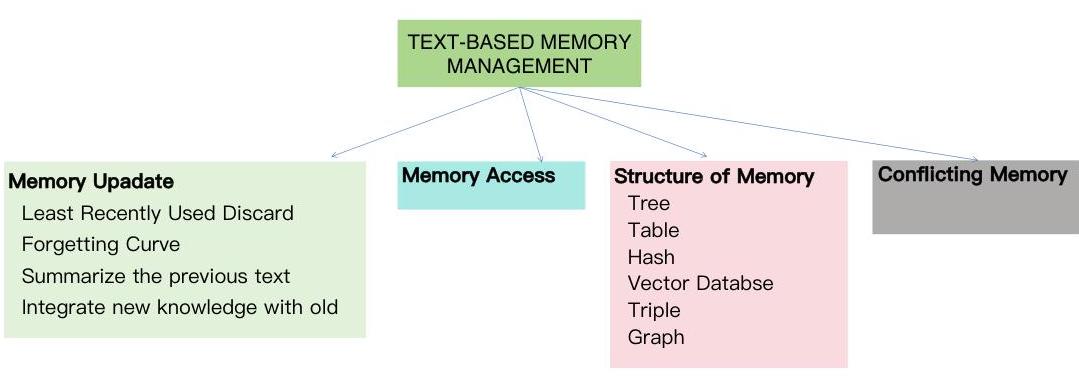
图4:基于文本的记忆管理
记忆管理涵盖四个方面:记忆更新、记忆访问、记忆存储的数据结构以及处理矛盾记忆。
3.2.1 记忆更新
记忆更新策略包括最近最少使用(LRU)丢弃策略、遗忘曲线策略、先前对话摘要更新策略和新旧知识整合策略。
LRU算法是一种基于最近访问模式的缓存淘汰策略。其核心思想是丢弃最长时间未被访问的数据。它通常通过双向链表和哈希表实现:链表的头部是最近访问的数据,尾部是最久未访问的数据。当访问数据时,如果数据在缓存中,则将其移动到链表的头部;如果不在缓存中,则将其添加到头部,如果缓存已满,则删除尾部的数据。
记忆遗忘机制受到艾宾浩斯理论的启发,该理论表明记忆保留随时间推移而减少,初始下降较快,随后减慢。间隔效应表明重新学习信息比首次学习更容易。定期复习可以重置遗忘曲线并提高保留率。遗忘曲线可以通过指数衰减公式建模:
R = e − t S R=e^{-t S} R=e−tS
其中
R
R
R是保留率,
t
t
t是从学习到现在的时间,
e
e
e约为2.71828 ,
S
S
S是记忆强度,受学习深度和重复次数等因素影响。在Zhong等人[2024]中,为了简化,作者将
S
S
S建模为离散值,初始化为1,每次回忆记忆时增加1,并将
t
t
t重置为0 。这减少了遗忘概率,尽管现实生活中的记忆更为复杂。MemoryBank结合这些元素,为LLMs创建了一个全面的记忆管理系统,提高了其提供有意义、个性化互动的能力,并扩展了AI应用的可能性。
先前对话摘要更新策略 Wang 等人[2023] 指导大型语言模型(LLMs)递归生成记忆(摘要)使用对话上下文和先前记忆。具体来说,更新后的记忆通过以下公式计算:
M i = LLM ( H i , M i − 1 , P m ) M_{i}=\operatorname{LLM}\left(H_{i}, M_{i-1}, P_{m}\right) Mi=LLM(Hi,Mi−1,Pm)
其中 M i = { m 1 , m 2 , … , m S } M_{i}=\left\{m_{1}, m_{2}, \ldots, m_{S}\right\} Mi={m1,m2,…,mS} 表示从过去的对话 H i H_{i} Hi中总结出的关键信息的多句集合, P m P_{m} Pm 是用于生成记忆的LLM提示。具体来说,作者将先前记忆和整个对话输入LLM,并使用提示“您的目标是更新记忆。”将新信息整合到给定对话上下文中,先前记忆为 [ M i − 1 ] \left[M_{i-1}\right] [Mi−1],对话为 [ H i ] \left[H_{i}\right] [Hi]。作者将初始记忆 M 0 M_{0} M0 设置为“空”。此操作重复 N N N 次,直到最后一次对话结束,此时可以获得最终记忆 M N M_{N} MN。
整合新旧知识的策略
受人类记忆启发,有必要基于既定的操作原则组织动态更新和思想演化,例如插入新思想、遗忘不重要的思想和合并重复的思想,从而使记忆机制更加自然和适用。从记忆缓存存储架构开始,Liu等人[2023]使用哈希表存储自动生成的思想,其中每个哈希索引对应一组包含相似思想的节点。在同一组内,TiM支持以下操作来组织内存中的思想:插入,即将新思想存储到内存中;遗忘,即从内存中移除不必要的思想,例如矛盾的思想;合并,即将内存中相似的思想合并,例如具有相同头实体的思想。
3.2.2 记忆访问
在Guo等人[2023]的研究中,工作记忆中心作为一个统一的枢纽,协调各个组件之间的数据流。它存储输入、输出和交互历史记录,并提供交互历史窗口和情景缓冲区等功能,以解决记忆孤岛问题。其核心是基于LLMs的中央处理器,负责结合输入和输出进行信息处理和分析并做出决策。外部环境接口动态获取实时输入并传输中央处理器的输出,所有数据都存储在工作记忆中心。交互历史窗口提供短期缓存和上下文锚定,而情景缓冲区通过启用完整场景的检索解决了LLMs的令牌限制问题。
记忆访问策略包括基于角色的访问,根据角色分配权限;基于任务的访问,根据任务需求提供权限;以及自主记忆访问,允许代理独立选择相关记忆。在复杂场景中,记忆管理代理负责高效管理、排序和检索历史数据,以提高多代理系统的效率。
3.2.3 记忆存储的数据结构
记忆的存储结构包括树、表、哈希表、向量数据库、三元组和图。
Aadhithya A等人[2024]提出了一种基于树的搜索方法。层次聚合树(HAT)定义为
H
S
T
=
(
L
,
M
,
A
,
Σ
)
H S T=(L, M, A, \Sigma)
HST=(L,M,A,Σ)。这里,
L
L
L表示树的层次结构,
M
M
M表示树中的节点集合,
A
A
A是用于将子节点文本聚合到父节点的聚合函数,
Σ
\Sigma
Σ也表示树中的节点集合。HAT的一个重要特征是,随着层次的深入,分辨率增加,而从左到右的结果则更为最新。这一特性使HAT能够有效地管理和检索长文本对话中的记忆信息。通过使用GPT将子节点转换为父节点,HAT可以高效地处理和组织信息。
Alonso等人[2024]提出了一种基于表的搜索方法。在基于表的聊天数据库中,每个响应包含文本以及元数据,如发言者姓名、日期、时间和对话ID。这种自然适合表格数据库表示的形式,其中表的每一列包含特定类型的数据(例如时间),每一行包含与特定响应相关的信息。我们通过将表与向量数据库集成,通过创建一个“内容”列,该列存储响应向量数据库中相关语义向量的索引。检索时,可以通过语义检索找到的前k个响应以及基于元数据的查询显著减少处理时间。生成答案的过程与并行搜索类似,但由于提示模板增加了额外开销。优化分块和总结策略可以有效提高LLM的处理效率。
在Liu等人[2023]的研究中,归纳推理被定义为包含两个实体之间关系的文本,即关系三元组
(
E
h
,
r
i
,
E
t
)
.
E
h
\left(E_{h}, r_{i}, E_{t}\right) . E_{h}
(Eh,ri,Et).Eh是通过关系
r
i
r_{i}
ri连接到尾实体
E
t
E_{t}
Et的头实体,其中
i
∈
[
0
,
N
]
i \in[0, N]
i∈[0,N]且
N
N
N是关系的数量。概念上,
R
h
=
{
r
1
,
⋯
,
r
N
}
R_{h}=\left\{r_{1}, \cdots, r_{N}\right\}
Rh={r1,⋯,rN}表示实体
E
h
E_{h}
Eh的所有一跳关系。
将归纳推理应用于大型语言模型的主要挑战在于获取与关系三元组匹配的高质量句子。本文提供了两种获取归纳推理的方法:(1) 预训练模型用于开放信息提取,例如OpenIE Manning等人[2014]; (2) 基于大型语言模型的少样本提示上下文学习。在本工作中,作者采用了第二种方法,即使用大型语言模型AgentA生成归纳推理。
3.2.4 处理矛盾记忆
在长期对话中,记忆的管理和构建是一项复杂且重要的任务,尤其是在面对矛盾记忆时。人们普遍认为避免矛盾记忆是必要的 Kim等人[2024]。然而,这种观点并不完全符合人类认知的真实特征。事实上,人类记忆高度依赖于上下文。同一个人在不同上下文中可能会回忆出不同的信息,甚至对同一事件的记忆也会因上下文变化而有所不同。因此,允许具有矛盾解释的记忆在同一人的记忆系统中共存,不仅符合人类认知的自然规律,还能为对话增添丰富性和真实性。为了有效处理这些矛盾记忆,作者提出了几种大型语言模型在长期对话中可灵活选择的优化策略。首先是“记忆解析”策略。受实体解析方法启发,该策略根据记忆源的上下文将矛盾记忆合并为信息丰富的句子,从而巧妙地解决这些冲突。其次是“记忆消歧”策略。两个陈述之间的矛盾可能是由于缺少上下文引起的,即语用模糊。受实体消歧方法启发,记忆消歧策略通过从记忆上下文中提取相关信息来澄清每个记忆的真实含义,从而消除模糊性。最后是“保留”策略。由于自然语言推理(NLI)模型的限制,有时预测为矛盾的记忆实际上可能并非如此,而是模型理解上的偏差。在这种情况下,保留这些看似矛盾的记忆实际上可以为对话提供更多可能性和深度。通过这些策略,作者旨在将矛盾记忆转化为包含关于说话者更丰富信息的句子,从而提高长期对话的质量和连贯性。
3.3 记忆利用
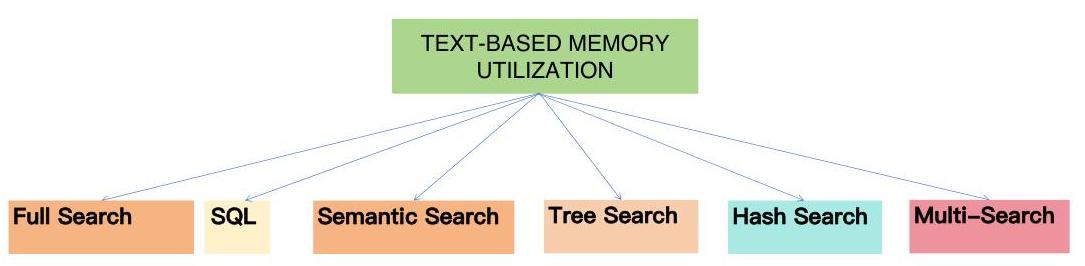
图5:基于文本的记忆利用
3.3.1 全文搜索
全文搜索Chen等人[2024b]涉及扫描整个文本数据集以定位特定字符序列或字符串。这种方法不仅寻找精确匹配,还根据文本结构和措辞考虑近似匹配。在MAS中,当面对广泛查询或不知道信息的确切位置或标签时,代理可以使用全文搜索。例如,当用户询问关于“气候变化影响”的广泛问题时,代理可以利用全文搜索浏览其整个记忆并提取相关段落或互动。
3.3.2 结构化查询语言
结构化查询语言(SQL)也是一种搜索方法Chen等人[2024b]。可以使用标准化的专业编程语言查询表格数据库,如SQL或基于数据框的Python语言(如pandas)。最近,一种高效的表格数据查询方法已经超越了现有的text2SQL方法。该算法创建了一个小型函数库,用于操作和检索表格中的元素。通过使用大型语言模型(LLM),这些函数链可以依次调用来在表格上执行高级多跳查询。作者将链接列表结构应用于元数据查询对话日志。他们使用两个函数从表格中检索子集行:f_value (column_name, [value1, value2, …]) f_between (column_name, [value1, value2]) f_value 函数检索指定列中列出的值至少匹配一个的行。f_between 函数检索值介于 value1 和 value2 之间的所有行。尽管这些函数简单,作者发现它们原则上可以准确完成测试集中的所有问题。作者将原始链接列表方法的提示改编为这个自定义函数库。他们使用LLM编写函数链,并分别提供提示以编写1)函数名,2)第一个参数(列名),和3)第二个参数(值)。
3.3.3 语义搜索
Chen等人[2024b]还提出了语义搜索。给定压缩记忆 M ^ \hat{M} M^和传入对话 D t D_{t} Dt,GPT4-Turbo输出基于记忆的响应。注释者随后审查和优化这些响应,重点关注相关性、连贯性和个性化等方面。他们确保每个注释响应 c t + 1 c_{t+1} ct+1准确反映用户的当前状态和先前的互动,保持高记忆性和参与度。
3.3.4 树形搜索
马尔可夫决策过程(MDP)由元组
(
S
,
A
,
P
,
R
,
γ
)
(S, A, P, R, \gamma)
(S,A,P,R,γ)定义,其中
S
S
S表示树节点集,
A
A
A是生成父节点文本的聚合函数。
A
A
A 的目标是通过从子节点文本生成父节点文本,创建子节点关键信息的简洁摘要,从而形成有意义的层次抽象树(HAT)。每当添加新的子节点时,
A
A
A 都会更新树以保持一致性。在实现中,GPT 被用作聚合函数,通过提示将子节点文本转换为父节点文本,具体提示详见附录。
GPT 被选中是因为其条件文本生成能力,这有助于基于节点文本和用户查询找到最优遍历路径。该框架开放且通用,允许记忆代理是一个神经网络、RL 代理或 GPT 近似值。研究使用了一个多会话聊天数据集,其中两个发言者在一个消息平台上进行对话。会话较短,但在暂停后会继续或开始新话题。每场会话的回合数列于表格中。
当 HAT 中的节点被更新时,
σ
\sigma
σ 更新父节点,传播变化向上。记忆代理的任务是根据用户查询
q
q
q,在 HAT 中找到最佳遍历路径,GPT 生成遍历的最优动作。
3.3.5 基于哈希的搜索
Liu等人[2023]提出了基于哈希的搜索方法。在基于记忆存储的检索任务中,为了获取最相关的思维,作者设计了一种两阶段检索范式。具体来说,当面对新查询
Q
Q
Q时,首先使用大型语言模型代理获取查询的嵌入向量
x
x
x。随后,基于局部敏感
哈希(LSH)的检索过程开始发挥作用。通过应用LSH函数,
hash ( x ) = LSH ( x ) \operatorname{hash}(x)=\operatorname{LSH}(x) hash(x)=LSH(x)
可以生成查询的哈希索引,从而为后续检索操作奠定基础。
3.3.6 多次搜索
在记忆检索过程中,作者采用密集检索方法,利用SimCSE模型将用户输入和每个记忆记录编码为向量。通过计算余弦相似度,选择前K个相关记录用于响应生成。然而,由于检索到的记忆记录可能并非全部有用,甚至可能完全无关,作者引入了记忆的自反思机制。具体来说,在获得检索结果后,语言模型首先需要判断此信息是否足以回应用户的输入。如果足够,语言模型从记忆记录中提取相关信息作为输出。如果不足够,则通过生成代表缺失信息的关键字或短语来改进原始查询,这些关键字或短语随后扩展到原始查询中进行另一轮检索。这个自反思过程可以多次重复,直到语言模型找到足够的信息为止。
4 基于KV缓存的记忆
本章介绍了基于KV缓存的长期记忆。由于基于变压器的LLMs目前是主流,尤其是仅解码器结构的主导地位,基于KV缓存的记忆已成为一个热门研究课题,特别是在长上下文领域。就本章的结构而言,我们遵循第3章的结构,从三个方面介绍记忆:获取、管理和利用。由于与记忆获取相关的研究工作较多,我们将其分为两部分:KV选择和KV压缩。KV选择指的是选择一些KV对保存并丢弃其余部分。我们将选择策略分为八类:基于规律的总结、基于分数的方法、特殊标记嵌入、基于学习的KV选择、不同层和头采用不同的标记选择策略、不同层和头使用相同的KV缓存、局部敏感哈希策略和基于回溯的KV选择。对于KV压缩中的记忆获取,我们将其总结为低秩压缩、KV合并、多模态压缩、KV量化和多级压缩。
对于第二大主要部分,即记忆管理,我们将其分为卸载策略(即将记忆放置在更便宜的内存上)、结合操作系统优化策略、存储数据结构和共享注意力。我们还介绍了一篇探讨KV缓存压缩与注意力之间关系的文章。
对于记忆的利用,即记忆检索,我们介绍了高效注意力、局部敏感哈希、向量检索方法及其他优化方法。
基于KV的内存获取
KV选择
规律策略
值向量范数与熵策略
分数策略
特殊标记嵌入策略
基于学习的标记选择策略
不同层和头采用不同的标记选择策略
不同层和头使用相同的KV缓存
局部敏感哈希策略
回溯策略
KV压缩
低秩压缩
KV合并
多级KV压缩
KV量化
图6:基于KV缓存的记忆管理
4.1 记忆获取:KV选择
4.1.1 规律策略
传统的KV缓存淘汰策略优先淘汰基于注意力得分的不那么关键的KV对。然而,这些策略往往降低生成质量,导致诸如上下文丢失或幻觉等问题。为了解决这个问题,Wan等人[2024]引入了动态判别操作(D2O),这是一种新颖的方法,在无需微调的情况下优化KV缓存大小,同时保留关键上下文。首先,通过观察浅层和深层之间注意力权重的不同密度,作者利用这一见解确定哪些层应避免过度淘汰以最小化信息损失。随后,对于每层的淘汰策略,D2O创新性地引入补偿机制,维持相似性阈值以重新评估先前丢弃标记的重要性,并决定是否召回和合并它们。
Guo等人[2022]引入了一种称为LongT5的文本到文本变压器,它可以高效处理长序列文本。LongT5结合了两种新的注意机制:局部注意和过渡全局注意(TGlobal)。这些机制增强了模型处理长序列的能力,同时保留了T5的原有特性。特别是,TGlobal注意机制通过引入相对位置偏差和层归一化参数,显著提高了模型在长序列任务中的性能。
Liu等人[2024b]推测,并非所有标记都需要存储在大语言模型的记忆中才能理解上下文。正如人类可以快速浏览一篇文章并抓住其主要思想一样,大语言模型也可能能够快速浏览并理解。通常观察到的是,标记的注意力得分遵循强烈的幂律分布,这意味着一个标记只对少数其他标记给予高度关注。更重要的是,作者观察到在训练好的大语言模型中,不同标记之间的注意力模式存在重复现象。某些标记在整个段落中更为重要。具体来说,对于两个不同的标记,它们高度关注的对象存在相似性,而忽略的对象也存在相似性。受这些观察的启发,作者提出了重要性持久性的假设:只有那些在前一步具有显著影响的标记才会在未来步骤中产生显著影响。如果这个假设成立,这意味着有可能预测哪些标记对未来生成至关重要。
Dai等人[2024]提出了一种称为CORM(带最近消息的缓存优化)的KV缓存淘汰策略。CORM可以在无需模型微调的情况下动态保留推理过程中的关键值对。该方法通过利用最近查询的注意力信息来优化LLM的KV缓存和标记生成。CORM方法的核心思想是,如果最近的查询向量足够相似,当前查询可以直接利用最近查询的注意力信息。此外,如果某些关键值对对于最近的查询不那么有用,在生成过程中移除这些对可以显著保留模型的性能。
Xiao等人[2023]首次发现了一个有趣的现象,称为注意力池,即自回归LLMs倾向于分配大量注意力得分给初始标记,即使这些标记在语义上并不重要。基于这一现象,StreamingLLM保留少量的KV对作为初始标记的注意力池,并将它们与滑动窗口KV结合,以锚定注意力计算并稳定模型性能。
Ding等人[2023]引入了LONGNET,一种Transformer变体,可以在不牺牲短序列性能的情况下扩展序列长度至超过十亿个标记。具体来说,作者提出了一种扩张注意力机制,随着距离增加指数级扩展注意力范围。LONGNET有以下几个显著优势:1) 它具有线性计算复杂度,序列中任意两个标记之间的依赖关系呈对数关系;2) 它可以作为极长序列的分布式训练器;3) 其扩张注意力机制可以直接替代标准注意力,并能无缝集成到现有的基于Transformer的优化过程中。
Beltagy等人[2020]在预选输入位置添加了“全局注意力”。重要的是,作者使这种注意力操作对称:即,具有全局注意力的标记将关注序列中的所有标记,而序列中的所有标记也将关注它。
ETC(扩展Transformer架构)Ainslie等人[2020]是一种新型的Transformer架构,旨在解决标准Transformer架构在处理长序列和结构化输入时面临的两个关键挑战。ETC引入了一种全局-局部注意力机制,以扩展注意力到更长的输入。在这种架构中,输入被分为两个序列:全局输入和长输入。全局输入通常包含较少数量的辅助标记,而长输入包括标准输入序列,这是Transformer通常处理的部分。全局-局部注意力机制限制长输入中的标记只能关注全局输入或其局部邻居,从而减少计算复杂度。这种方法将注意力计算从二次扩展改为线性扩展。
Gao等人[2023]主要介绍了一种称为注意力转换的技术,通过调整注意力权重,使模型能够理解更长的上下文。通过实验,作者发现当信息在模型的不同层之间传递时,许多相同的标记出现,它们的位置逐渐靠得更近。这表明重要信息在逐层计算过程中逐步传递到更靠近的位置。此外,作者发现旋转嵌入限制了对长距离信息的理解,但关键信息在逐层计算过程中趋于靠得更近。
4.1.2 值向量范数与熵策略
传统方法通常仅依赖注意力得分来确定关键标记的重要性。然而,Guo等人[2024]发现关键标记的值向量也会影响其重要性。因此,作者提出了一种新的标记剪枝方法,称为Value-Aware Token Pruning (VATP),该方法考虑了注意力得分和值向量的范数,提供了更全面的评估标记重要性的指标。在考虑如何评估和剪枝标记以减少KV缓存的内存占用时,作者不仅关注注意力得分,还特别关注值向量的范数。具体来说,他们引入了一种新方法,称为“Value-Aware Token Pruning (VATP)”,该方法结合了注意力得分和值向量的范数来评估每个标记的重要性。
4.1.3 分数策略
之前的研究提出了KV缓存压缩技术,这些技术通过识别基于累积注意力得分的不重要标记并从KV缓存中删除它们来减少冗余,同时指出只有少量标记在注意力操作中起重要作用。然而,Jo和Shin [2024]观察到现有的累积注意力得分并不适用于Transformer解码器架构。在解码器模型中,由于掩码效应,注意力得分累积次数因标记出现顺序而异,导致不同标记之间的比较不公平。为了解决这个问题,作者提出了一种称为累积
带有遗忘因子的注意力得分(A2SF)的技术,该技术在累积注意力得分的过程中引入了“遗忘因子”。A2SF反复将旧标记生成的过去注意力得分乘以遗忘因子,从而随着时间的推移对过去的注意力得分施加惩罚。因此,较旧的标记受到更大的惩罚,提供不同年龄标记之间的公平性。通过公平比较标记,作者可以更有效地选择重要标记。
Quest算法的一个重要特征Tang等人[2024b]是其动态调整KV缓存内容的能力。具体来说,随着查询向量Q的变化,Quest重新评估标记的关键性并相应地更新KV缓存的内容。这种动态调整确保了KV缓存始终包含当前查询所需的关键信息。作者的见解是,为了避免错过关键标记,应该选择包含具有最高注意力权重的标记的页面。然而,为了高效选择页面,他们应该基于这种见解计算近似的注意力得分。作者发现页面内注意力权重的上限可以用作该页面最高注意力的近似值。页面内注意力权重的上限可以通过键向量的通道最小值(mi)和最大值(Mi)计算。给定查询向量Q,Quest通过取
U
i
=
max
(
Q
i
m
i
,
Q
i
M
i
)
\mathrm{Ui}=\max (\mathrm{Qimi}, \mathrm{QiMi})
Ui=max(Qimi,QiMi)计算通道i的最大可能值。注意,无论Q的符号如何,Ui总是大于Q与页面中任何键值Ki的乘积。因此,当作者求和Ui时,他们获得了该页面所有键向量的注意力权重上限。在得出注意力权重上限后,作者选择顶级K页作为关键页,其中K是一个任意定义的超参数。为了证明Quest的可行性,作者进行了实际的自注意力计算,并收集了每页的Top-K注意力得分。如图3所示,作者的查询感知稀疏性大多与预测的稀疏性一致。Quest仅对选定的页面执行正常的自注意力计算,从而显著减少了内存移动。作者将选定页面中的标记数量定义为“标记预算。”
自适应标记释放 Zhang等人[2024] 是一种评估标记重要性以选择要释放的标记的机制。首先,模型利用Top-K注意力机制计算注意力权重并识别出最重要的K个标记,从而在减少计算负载的同时保持与全注意力模型相当的性能。在更新缓存的关键值状态时,模型将最新的关键值状态添加到缓存中,并选择性地移除较旧且不太重要的关键值状态,以保持稳定的缓存大小。此外,模型采用基于当前上下文和任务需求的动态淘汰策略,灵活选择要释放的标记,确保标记释放策略能够适应不同的任务和上下文。
Keyformer Adnan等人[2024] 利用了这样一个观察:生成推理中大约90%的注意力权重集中在特定子集的标记上,这些标记被称为“关键”标记。Keyformer 使用一种新的评分函数识别这些关键标记,并仅在KV缓存中保留这些关键标记。
Keyformer 的评分函数如下:
f θ ( x i ) = e x i + ζ i / τ ∑ j = 1 k e x j + ζ j / τ f_{\theta}\left(x_{i}\right)=\frac{e^{x_{i}+\zeta_{i} / \tau}}{\sum_{j=1}^{k} e^{x_{j}+\zeta_{j} / \tau}} fθ(xi)=∑j=1kexj+ζj/τexi+ζi/τ
其中
x
i
x_{i}
xi表示未归一化的logits,
ζ
i
\zeta_{i}
ζi是加入的Gumbel噪声分布,
τ
\tau
τ是用于调整概率分布平滑度的温度参数。Keyformer提出的这一评分函数将Gumbel噪声分布整合到未归一化的logits中,以解决标记丢弃引起的问题。
Sparse Window Attention (SWA) Zhao等人[2024] 是一种在大语言模型(LLMs)推理过程中使用的方法,旨在通过生成稀疏注意力模式来减少内存使用,同时保持模型精度。SWA的核心在于结合局部静态和全局动态稀疏模式:它在局部标记上生成静态模式,保留最近的标记以维护语言的顺序语义,同时通过动态模式捕捉之前标记的语义重要性变化。这种混合模式可以更有效地捕获序列中的关键标记。
在Zhang等人[2023]的研究中,作者提出了一种新颖的KV缓存实现方式,该方式显著减少了其内存占用。他们的观察显示:在计算注意力得分时,一小部分标记贡献了大部分值。作者将这些标记称为“重击者”(Heavy Hitters)。通过对这些标记进行全面调查,作者发现
(i) Heavy Hitters的出现是自然的,并且与文本中标记的频繁共现密切相关;(ii) 移除它们会导致性能显著下降。基于这些见解,作者引入了“重击者预言机”(Heavy Hitters Oracle, H2O),这是一种KV缓存淘汰策略,动态平衡最近和Heavy Hitters标记。
Yao等人[2024b]使用大型语言模型计算每个输入标记的熵度量,从而评估其重要性。随后,保留并存储熵值较高的标记(被认为是关键标记)在KV缓存中。这种方法增强了模型在无限长流对话中的记忆能力。
4.1.4 特殊标记嵌入策略
之前的研究所尝试通过选择性丢弃标记来缓解这一问题,但Tang等人[2024a]不可逆地删除了未来查询可能需要的关键信息。本文提出了一种新颖的KV缓存压缩技术,保留所有标记信息。我们的研究表明:i) 大多数注意力头主要关注局部上下文;ii) 只有少量的注意力头,称为检索头,可以显著关注所有输入标记。这些关键观察促使我们为注意力头采用不同的缓存策略。因此,我们引入了RazorAttention,这是一种无需训练的KV缓存压缩算法,为这些关键检索头保留完整的缓存,并丢弃非检索头中的远程标记。此外,我们引入了一种新的机制,涉及“补偿标记”,以进一步从丢弃的标记中恢复信息。
Mohtashami 和 Jaggi [2023] 在本文中提出了一种方法,通过将长文本分成连续块并使用注意力机制检索相关块,从而保持Transformer的随机访问灵活性。
在Luo等人[2024]的研究中,作者提出了一种简单而有效的方法,使大语言模型能够“深呼吸”,鼓励它们从离散文本块中总结信息。具体来说,作者将文本分成多个块,并在每个块的末尾插入一个特殊标记。然后,他们修改注意力掩码,将每个块的信息集成到相应的 < S R > <\mathrm{SR}> <SR>标记中。这使得大语言模型不仅可以解释来自单个历史标记的信息,还可以解释来自标记的信息,从而汇总块的语义信息。
4.1.5 基于学习的标记选择策略
Kim 等人[2022] 主要介绍了一种新的基于学习的标记剪枝方法,称为Learned Token Pruning (LTP),该方法可以自适应地从输入序列中移除不重要的标记,并为Transformer 层内的每一层学习一个阈值。LTP 方法通过基于学习的阈值方法进行剪枝。首先,对于每个标记,它计算所有注意力头的平均注意力概率,并将此平均值定义为该标记的重要性得分。然后,为每一层设置可学习的阈值,如果某标记对该层的重要性得分低于该层的阈值,则该标记将在该层被剪枝。为了使阈值可学习,LTP 采用了软剪枝方案,使用Sigmoid 函数创建可微分的软掩码。尽管这种软掩码近似了硬剪枝的行为,但它允许梯度流向阈值参数,从而实现阈值的学习和优化。
Lee 等人[2022] 引入了一种高效的稀疏注意力机制,称为SPARSEK 注意力,旨在解决长程Transformer 计算中的计算和内存效率问题。该机制通过为每个查询选择固定数量的键值对实现了线性训练复杂度和恒定推理时间的内存成本。SPARSEK 注意力的核心在于结合局部静态和全局动态稀疏模式:它在局部标记上生成静态模式,保留最近的标记以保持语言的顺序语义,同时通过动态模式捕捉之前标记的语义重要性变化。这种混合模式可以更有效地捕获序列中的关键标记。
在Zhang等人[2023]的研究中,作者提出了一种新颖的KV缓存实现方法,显著减少了其内存占用。他们的方法基于一个惊人的观察:在计算注意力得分时,一小部分标记贡献了大部分值。作者将这些标记称为“重击者”(Heavy Hitters)。通过全面调查,作者发现
(i) Heavy Hitters的出现是自然的,并且与文本中标记的频繁共现密切相关;(ii) 移除它们会导致性能显著下降。基于这些见解,作者引入了“重击者预言机”(Heavy Hitters Oracle, H2O),这是一种KV缓存淘汰策略,动态平衡最近和Heavy Hitters标记。
Yao等人[2024b]使用大语言模型计算每个输入标记的熵度量,从而评估其重要性。随后,保留熵值较高的标记(被认为是关键标记),并将它们存储在KV缓存中。这种方法增强了模型在无限长流对话中的记忆能力。
4.1.4 特殊标记嵌入策略
以前的研究试图通过选择性丢弃标记来缓解这一问题,但Tang等人[2024a]不可逆地删除了未来查询可能需要的关键信息。在本文中,我们提出了一种新颖的KV缓存压缩技术,保留所有标记信息。我们的研究表明:i)大多数注意力头主要关注局部上下文;ii)只有少量注意力头,称为检索头,可以显著关注所有输入标记。这些关键观察促使我们为注意力头采用不同的缓存策略。因此,我们引入了RazorAttention,这是一种无需训练的KV缓存压缩算法,为这些关键检索头保留完整缓存,并丢弃非检索头中的远程标记。此外,我们引入了一种新的机制,涉及“补偿标记”,以进一步从丢弃的标记中恢复信息。
Mohtashami 和 Jaggi [2023] 在本文中提出了一种方法,通过将长文本分成连续块并使用注意力机制检索相关块,从而保持Transformer的随机访问灵活性。
在Luo等人[2024]的研究中,作者提出了一种简单而有效的方法,使大语言模型能够“深呼吸”,鼓励它们从离散文本块中总结信息。具体来说,作者将文本分成多个块,并在每个块的末尾插入一个特殊标记。然后,他们修改注意力掩码,将每个块的信息集成到相应的 < S R > <\mathrm{SR}> <SR>标记中。这使得大语言模型不仅可以解释来自单独历史标记的信息,还可以解释来自标记的信息,从而汇总块的语义信息。
4.1.5 基于学习的标记选择策略
Kim等人[2022]主要介绍了一种新的基于学习的标记剪枝方法,称为Learned Token Pruning (LTP),该方法可以自适应地从输入序列中移除不重要的标记,并为Transformer层内的每一层学习一个阈值。LTP方法采用基于学习的阈值剪枝方法。首先,对于每个标记,它计算所有注意力头的平均注意力概率,并将该平均值定义为标记的重要性得分。然后,为每一层设置一个可学习的阈值,如果某个标记的重要性得分低于该层的阈值,则该标记将在该层被剪枝。为了使阈值可学习,LTP采用了一种软剪枝方案,使用Sigmoid函数创建可微分的软掩码。虽然这种软掩码近似了硬剪枝的行为,但它允许梯度流向阈值参数,从而实现阈值的学习和优化。
Lee等人[2022]介绍了一种高效的稀疏注意力机制,称为SPARSEK注意力,旨在解决长程Transformer计算中的计算和内存效率问题。该机制通过为每个查询选择固定数量的键值对,实现了线性训练复杂度和恒定推理时间的内存成本。SPARSEK注意力引入了可学习的稀疏模式,以数据驱动的方式学习稀疏性,而不是使用固定的模式。这使得SPARSEK注意力能够更好地适应不同的任务和数据分布。
SparseK通过可微分的top-k选择操作实现稀疏性,这允许在选择关键KV对的同时保持梯度优化。SparseK的核心思想是将稀疏约束从简单的概率单纯形放宽到k-sum约束,定义如下:
SparseK
(
z
,
k
)
:
=
arg
min
p
∈
C
∥
p
−
z
∥
2
\text { SparseK }(\mathbf{z}, k):=\arg \min _{\mathbf{p} \in \mathbb{C}}\|\mathbf{p}-\mathbf{z}\|^{2}
SparseK (z,k):=argp∈Cmin∥p−z∥2
其中
C
\mathbb{C}
C是k-sum约束集,定义为:
C = { p ∣ 0 ≤ p ≤ 1 , 1 ⊤ p = k } \mathbb{C}=\left\{\mathbf{p} \mid \mathbf{0} \leq \mathbf{p} \leq \mathbf{1}, \mathbf{1}^{\top} \mathbf{p}=k\right\} C={p∣0≤p≤1,1⊤p=k}
此外,SparseK的解决方案可以表示为:
p ∗ = max ( min ( z − τ ( z ) , 1 ) , 0 ) \mathbf{p}^{*}=\max (\min (\mathbf{z}-\tau(\mathbf{z}), \mathbf{1}), \mathbf{0}) p∗=max(min(z−τ(z),1),0)
这里, τ ( z ) \tau(\mathbf{z}) τ(z)是一个满足以下条件的阈值函数:
∑ p ∗ = k \sum \mathbf{p}^{*}=k ∑p∗=k
并且
z
\mathbf{z}
z表示排序后的坐标。通过软阈值操作实现该解决方案,使模型能够在正向传递中执行实际的选择操作,同时在反向传递中保持梯度更新。
Anagnostidis等人[2023]可以动态修剪Transformer模型中的上下文,以提高计算效率和可解释性。作者在每一层引入了参数化修剪机制,使模型能够选择性地丢弃不再需要的上下文信息。具体的修剪过程可以通过以下公式表达:
对于序列中的每对标记 i i i和 j j j,计算修剪门控制信号 I ˉ n , j ℓ \bar{I}_{n, j}^{\ell} Iˉn,jℓ :
I ˉ n , j ℓ = σ ( ( Q int ℓ ) n ⊤ ( K int ℓ ) j r + β ℓ ) \bar{I}_{n, j}^{\ell}=\sigma\left(\frac{\left(\mathbf{Q}_{\text {int }}^{\ell}\right)_{n}^{\top}\left(\mathbf{K}_{\text {int }}^{\ell}\right)_{j}}{\sqrt{r}}+\beta^{\ell}\right) Iˉn,jℓ=σ r(Qint ℓ)n⊤(Kint ℓ)j+βℓ
这里, σ \sigma σ是稀疏sigmoid函数, Q int ℓ \mathbf{Q}_{\text {int }}^{\ell} Qint ℓ和 K int ℓ \mathbf{K}_{\text {int }}^{\ell} Kint ℓ分别表示交互的查询和键向量, β ℓ \beta^{\ell} βℓ是可学习的偏置参数, r r r是缩放因子。使用门控制信号 I ˉ n , j ℓ \bar{I}_{n, j}^{\ell} Iˉn,jℓ来确定是否保留标记 j j j在上下文中对生成标记 n n n的影响:
I k , j ℓ = ∏ n = j + 1 k I ˉ n , j ℓ I_{k, j}^{\ell}=\prod_{n=j+1}^{k} \bar{I}_{n, j}^{\ell} Ik,jℓ=n=j+1∏kIˉn,jℓ
如果 j < k j<k j<k,否则如果 j = k j=k j=k, I k , j ℓ = 1 I_{k, j}^{\ell}=1 Ik,jℓ=1,或者如果 j > k j>k j>k, I k , j ℓ = 0 I_{k, j}^{\ell}=0 Ik,jℓ=0。通过这种方法,模型可以在生成每个新标记时动态调整其上下文,从而减少不必要的计算和内存使用。
4.1.6 不同层和不同头采用不同的标记选择策略。
Wang等人[2024b]主要介绍了一种称为SQUEEZEATTENTION的算法,该算法用于管理LLM(大语言模型)推理中的KV缓存,以进一步减少推理的内存消耗。文章指出,现有的KV缓存优化方法大多集中在序列维度或批量维度上的优化,而忽略了注意力层维度中的潜在机会。通过分析推理过程中不同注意力层的行为,作者提出了一种精确重新分配注意力层缓存预算的方法,从而进一步减少了KV缓存的总量。
Xu等人[2024]专注于长上下文场景,并解决了推理过程中KV缓存内存消耗的低效问题。与现有基于序列长度优化内存的方法不同,作者发现KV缓存的通道维度存在显著冗余,表现为注意力权重不平衡的幅度分布和低秩结构。基于这些观察,作者提出了ThinK,这是一种新颖的查询依赖型KV缓存剪枝方法,旨在最小化注意力权重损失的同时选择性地剪枝最少重要的通道。
Fu等人[2024]提出了Mixture of Attention (MoA),该方法自动为不同的头和层定制不同的稀疏注意力配置。MoA构建并导航各种注意力模式及其相对于输入序列长度的缩放规则的搜索空间。它分析模型,评估潜在配置,并识别最佳的稀疏注意力压缩计划。MoA适应不同的输入大小,揭示了一些注意力头扩展其焦点以适应更长的序列,而其他头则持续集中于固定长度的局部上下文。
Song等人[2023]提出了一种新颖的模型架构,称为Zebra。这种架构有效地解决了Transformer中全注意力引起的二次时间和内存复杂度问题
通过采用分组的局部-全局注意力层。作者的模型类似于斑马的交替条纹,平衡局部和全局注意力层,显著减少了计算需求和内存消耗。
LONGHEADS Lu等人[2024]已被提出以增强预训练语言模型(LLMs)处理长上下文的能力,而无需额外训练。本文的核心思想是充分利用多头注意力的潜力,通过限制每个注意力头选择并专注于预训练长度内的关键上下文块,从而避免处理超出预训练长度(OOD问题)的标记。此外,本文提出了一种块选择策略,利用模型固有的点积注意力选择每个头的重要块。
SnapKV Li等人[2024]是一种针对优化大语言模型(LLMs)处理长上下文时的KV缓存压缩方法。它通过以下步骤实现:首先,位于提示末端的观察窗口用于监控生成过程中的模型对输入标记的注意力模式,这些模式在整个生成过程中保持稳定和一致。接下来,基于观察窗口的投票算法用于识别生成过程中持续被注意力头关注的重要位置,从而选择对应最重要标记的KV对。在投票之前,SnapKV引入了一种基于池化的聚类技术,以捕获完整的局部信息并过滤掉无关标记,从而在压缩上下文的同时保持其完整性。最后,所选的KV对与观察窗口连接,形成一个新的、更小的KV缓存。在随后的生成过程中,模型只需对这个显著减少的缓存进行注意力计算,从而提高效率。
在Cai等人[2024]的研究中,作者探讨了大语言模型中基于注意力的信息流是否通过显著模式聚集长上下文信息。作者的观察表明,大语言模型以金字塔形式聚集信息,注意力在较低层广泛分散,逐渐在特定上下文中整合,并最终在较高层聚焦于关键标记(即具有高激活值或注意力池的标记)。基于这些见解,作者开发了PyramidKV,这是一种新颖且高效的KV缓存压缩方法。这种方法动态调整不同层的KV缓存大小,在较低层分配更多缓存,而在较高层分配较少缓存,与传统方法保持一致的KV缓存大小形成对比。
重新审视当前的剪枝方法后,Feng等人[2024]发现这些方法本质上最小化了修剪前后多头自注意力机制输出之间的L1修剪损失的上限。此外,他们的分析表明,将预算均匀分配到注意力头的做法损害了修剪后的生成质量。基于这些发现,作者提出了一种简单而有效的自适应预算分配算法。该算法不仅优化了理论损失上限,而且通过匹配每个头的不同特征,在实践中减少了L1修剪损失。
4.1.7 不同层和不同头使用相同的标记选择策略。
DeepSeek-V2 Liu等人[2024a]采用了一种创新架构,包括多头隐式注意力(MLA)和DeepSeekMoE。MLA通过显著压缩键值(KV)缓存到隐式向量实现高效推理,而DeepSeekMoE通过稀疏计算以经济的成本训练强大模型。
Yu等人[2024]探索了KV缓存的低秩特性,并提出了一种新的KV头压缩方法。特别是,作者仔细优化了从MHA到GQA的过渡,以最小化压缩误差。此外,为了保持与旋转位置嵌入(RoPE)的兼容性,作者引入了一种专门针对带有RoPE的键缓存的策略。
在Devoto等人[2024]的研究中,作者提出了一种基于L2范数的简单而有效的KV缓存压缩策略。他们首先检查了缓存键的L2范数与注意力得分之间的关系,发现两者之间存在强相关性。具体来说,L2范数较低的键嵌入在解码过程中往往会产生较高的注意力得分。基于这一观察,作者提出了一种KV缓存压缩策略,仅保留L2范数最低的键及其对应的值。该策略的一个显著优势是
它不需要额外的训练或对模型进行重大修改,可以直接应用于任何基于Transformer的解码器模型。
Mu等人[2024]的主要内容介绍了一种名为LISA(可学习共享注意力)的方法,旨在减少大语言模型中各层之间的冗余注意力计算。作者通过实验证明,在大多数情况下,不同层之间的注意力权重表现出相似性,因此通过共享这些权重可以提高模型的效率。为了实现这一目标,作者提出了两个关键组件:注意力头对齐模块和差异补偿模块。
Zuhri等人[2024]主要介绍了一种用于高效推理大语言模型的层压缩KV缓存方法。该方法通过减少缓存层数显著降低了KV缓存的内存消耗并提高了推理速度。
4.1.8 局部敏感哈希策略
Reformer Kitaev等人[2020]是由谷歌研究院和加州大学伯克利分校的研究人员共同撰写的一篇论文,重点在于改进Transformer模型处理长序列数据的效率。该论文提出了两项关键技术:第一,局部敏感哈希(LSH),它取代了传统的点积注意力机制。通过将键随机投影到多个“桶”中,并仅在相同桶内的键之间计算注意力,LSH将自注意力的复杂度从 O ( L 5 ) \mathrm{O}\left(\mathrm{L}^{5}\right) O(L5)降低到 O ( L l o g L ) \mathrm{O}(\mathrm{LlogL}) O(LlogL),显著减少了计算负载,同时保持了相似性。第二,可逆残差层,它改变了网络的前向传播方式,使得激活值在训练期间只需存储一次,而不是像传统Transformer那样在每一层都存储,从而大大减少了内存使用。此外,Reformer引入了分块技术,将前馈网络中的激活值分成多个块进行分别处理,进一步减少了内存消耗。
Pagliardini等人[2023]主要介绍了一种称为稀疏闪存注意力的注意力机制,该机制在处理长序列时提高了计算效率。作者通过引入动态稀疏结构和哈希算法优化注意力矩阵,从而减少了计算量。
4.1.9 回溯策略
以前的标记剪枝方法通常在前向传播阶段去除标记,而不考虑它们对后续层注意力的影响,这可能导致任务中重要标记的丢失。为了解决这个问题,Lee等人[2022]提出了一种注意力回溯方法,该方法从输出到输入跟踪Transformer架构中每个注意力的重要性,以保留对最终预测有显著影响的标记。
4.2 记忆获取:KV压缩
4.2.1 低秩压缩
KV缓存压缩方法通常采样一部分有效的标记或对数据进行低位宽量化。然而,这些方法无法利用KV张量隐藏维度中的冗余。Chang等人[2024]提出了一种隐藏维度压缩方法,称为Palu,这是一种基于低秩投影的新型KV缓存压缩框架。Palu将线性层分解为低秩矩阵,缓存压缩后的中间状态,并动态重建完整的键和值。为了提高准确性、压缩率和效率,Palu进一步包括中粒度低秩分解方案、有效的秩搜索算法、低秩感知量化兼容性增强以及优化的GPU内核与运算符融合。
Dong等人[2024]是一种在大语言模型(LLMs)中优化KV缓存的有效技术。它通过结合稀疏策略和低秩核实现缓存压缩。具体来说,LESS首先采用稀疏策略,根据某些标准(如重要性或频率)选择性地缓存一部分KV对,从而减少缓存大小。随后,它学习原始注意力输出和稀疏策略近似输出之间的残差,并将此残差信息累积到一个固定大小的低秩缓存中。这种低秩缓存不会随序列长度扩展,从而有效减少内存使用。这样,
LESS不仅保留了关键信息,还允许查询访问稀疏策略丢弃的信息。因此,它在保持较小缓存大小的同时最小化了性能退化。此外,LESS在生成过程中可以合成多个标记以生成更长且更连贯的序列。此外,其注意力计算和缓存更新过程均经过精心设计。
4.2.2 KV合并
在Wang等人[2024a]的研究中,作者提出了一种新颖的KV缓存合并方法,称为KVMerger,旨在在有限的内存预算下实现适应性KV缓存压缩,而不显著降低长上下文任务的性能。作者的方法受到一个有趣的观察的启发:在同一序列内,键状态在标记级别上表现出高相似性。为了便于合并,作者开发了一种高效且简单的合并集识别算法,以识别适合合并的KV状态。作者的合并集识别算法引发了一个第二个观察:从相似性的角度来看,KV缓存的稀疏性与数据集无关,并在模型层面持续存在。随后,作者提出了一种基于高斯核加权的合并算法,以选择性地合并每个合并集内的所有状态。KV缓存合并的形式化表达如下:
- 合并集识别:将KV缓存合并问题公式化为一个约束聚类问题,并使用有效的可合并集识别方法识别适合合并的KV状态。
-
- 加权合并算法:对于每个识别出的可合并集,使用高斯核加权合并算法合并状态。合并键状态
(
M
(
K
)
)
(M(\mathcal{K}))
(M(K))和值状态
(
M
(
V
)
)
(M(\mathcal{V}))
(M(V))的表达式如下:
KaTeX parse error: Undefined control sequence: \rig at position 77: …athcal{S}_{k i}\̲r̲i̲g̲
\begin{aligned}
& M(\mathcal{V})=\bigcup_{i=1}^{d} F\left(\mathcal{S}_{v i}\right)
\end{aligned}
$$
- 加权合并算法:对于每个识别出的可合并集,使用高斯核加权合并算法合并状态。合并键状态
(
M
(
K
)
)
(M(\mathcal{K}))
(M(K))和值状态
(
M
(
V
)
)
(M(\mathcal{V}))
(M(V))的表达式如下:
其中
S
k
i
\mathcal{S}_{k i}
Ski和
S
v
i
\mathcal{S}_{v i}
Svi分别表示键状态和值状态的子合并集,
F
F
F是将每个可合并集映射到单一状态的合并函数。
3. 高斯核加权合并:在每个识别出的可合并集中,使用高斯核作为权重来合并状态,确保合并信息得以保留而不显著降低LLM的生成性能。
Hwang等人[2024]专注于将基于注意力机制的工作记忆概念引入深度学习,并探讨在Transformer模型中实现工作记忆的方法。通过引入反馈注意力机制,Transformer模型能够将先前信息传递给当前模块,从而有效处理和压缩长文本上下文的信息。
Roy等人[2021]介绍了一种高效的内容基础稀疏注意力机制,称为路由Transformer。传统的注意力机制在处理长序列时面临较高的计算复杂度。相比之下,路由Transformer通过引入稀疏性和聚类技术解决了这个问题,从而保持了模型的灵活性同时提高了计算效率。
4.2.3 多级KV压缩
He等人[2024]提出了分层记忆Transformer(HMT),这是一种新颖的框架,通过模仿人类记忆行为增强了模型处理长上下文的能力。通过记忆增强的段级别递归,作者构建了一个记忆层次结构,方法是保留早期输入段中的标记,沿序列传递记忆嵌入,并从历史中回忆相关信息。最初,长输入文本序列被划分为多个段 X i X_{i} Xi,每个段包含固定数量的标记。对于第一个段 X 0 X_{0} X0,模型使用Transformer编码器对其进行编码以获得初始记忆:
Mem
0
=
TransformerSegment
(
X
0
)
\operatorname{Mem}_{0}=\operatorname{TransformerSegment}\left(X_{0}\right)
Mem0=TransformerSegment(X0)
这个初始记忆作为处理后续段的基础。对于每个后续段
X
i
X_{i}
Xi,模型以分层方式更新记忆。具体来说,模型首先对当前段
X
i
X_{i}
Xi进行编码以获得局部记忆:
LocalMem i = TransformerSegment ( X i ) \text { LocalMem }_{i}=\text { TransformerSegment }\left(X_{i}\right) LocalMem i= TransformerSegment (Xi)
然后,模型结合局部记忆与前一记忆状态,并通过注意力机制选择重要信息以更新全局记忆:
GlobalMem i = Attention ( LocalMem i , Mem i − 1 ) \text { GlobalMem }_{i}=\text { Attention }\left(\text { LocalMem }_{i}, \text { Mem }_{i-1}\right) GlobalMem i= Attention ( LocalMem i, Mem i−1)
为了控制记忆大小并保留关键信息,模型使用压缩模块压缩全局记忆:
Mem i = Compression ( GlobalMem i ) \text { Mem }_{i}=\text { Compression }\left(\text { GlobalMem }_{i}\right) Mem i= Compression ( GlobalMem i)
这种分层记忆更新机制允许模型在处理每个新段时动态更新和压缩记忆,从而避免信息过载。当处理每个新段时,模型不仅生成当前段的编码,还从记忆中回忆相关信息,并将其与当前段的输出相结合:
Output i = TransformerSegment ( X i ) + Attention ( X i , Mem i ) \text { Output }_{i}=\text { TransformerSegment }\left(X_{i}\right)+\text { Attention }\left(X_{i}, \text { Mem }_{i}\right) Output i= TransformerSegment (Xi)+ Attention (Xi, Mem i)
这种回忆机制使模型能够通过利用历史信息增强当前段的表示,从而更好地理解长文本中的上下文关系。在处理完所有段后,模型将每个段的输出连接起来形成整个长文本的最终表示:
Final Output = Concat ( Output 0 , Output 1 , … , Output n ) \text { Final Output }=\text { Concat }\left(\text { Output }_{0}, \text { Output }_{1}, \ldots, \text { Output }_{n}\right) Final Output = Concat ( Output 0, Output 1,…, Output n)
其中 n n n是输入序列中的段数。
4.2.4 KV量化
4.3 记忆管理
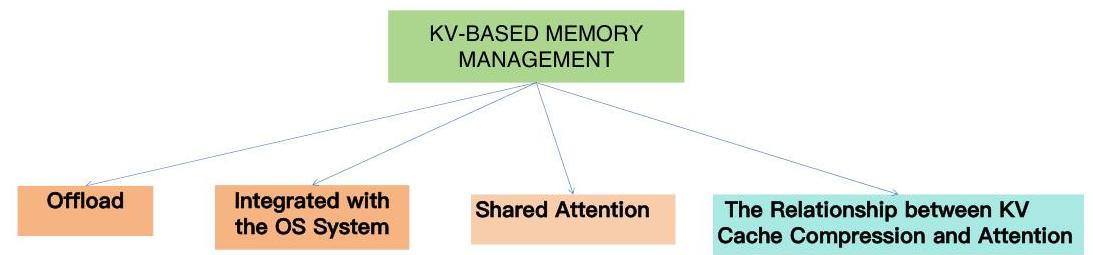
图7:基于KV缓存的记忆管理
4.3.1 卸载
大型语言模型(LLMs)的注意力卸载是一种优化策略,通过将注意力计算转移到专门优化内存的硬件上来提高推理效率并降低成本。LLM推理包括预填充阶段和生成阶段,后者需要高内存带宽,并随着上下文长度增加和KV缓存扩展而遭受加速器利用率下降的问题。研究人员建议利用廉价的内存优化设备来处理注意力操作,同时使用高端加速器来处理其他部分,创建一个异构设置以提升性能和成本效率。实验表明,采用此策略的Lamina系统每美元的吞吐量比传统解决方案高出1.48到12.1倍。此外,诸如GPUDirect RDMA、设备端忙碌轮询以及通信-注意力重叠策略等技术已被用于减少调度和网络延迟,
从而优化用户体验。总体而言,注意力卸载技术在提高资源利用效率和降低成本方面具有巨大潜力。
Pan等人[2024]介绍了InstInfer,这是一种新型的长上下文低功耗机器学习推理系统。该系统通过在解码阶段将关键的注意力计算任务从GPU卸载到CSDs(计算存储设备)来改进推理性能,同时降低能耗和成本,通过在存储内执行注意力计算。
Nawrot等人[2024]专注于通过动态内存压缩(DMC)改进现有大语言模型(LLMs)以加速推理速度。研究人员将决策变量和重要性变量引入模型,使其能够学习定制的压缩策略,从而减少推理过程中的内存使用。
批处理大小受到一些重复使用的中间结果的限制,即KV缓存。这些中间结果占用过多的内存空间,阻止更多的序列同时在图形处理单元(GPU)上处理。虽然可以将它们卸载到主机内存中,但CPU-GPU带宽不可避免地成为瓶颈。He和Zhai[2024]发现了一种方法,将Transformer模型分解为两个具有不同特性的部分,其中一个部分包括内存绑定的KV缓存访问。作者的关键见解是,跨多个节点的CPU聚合内存容量、带宽和计算能力是处理这一部分的有效选择。性能提升来自于减少了数据传输开销和增加了处理模型另一部分的GPU吞吐量。
4.3.2 与操作系统集成的记忆管理
Hu等人[2024]提出MemServe,这是一个统一的系统,整合了请求间和请求内的优化。MemServe引入了MemPool,一种弹性内存池,用于管理服务实例间的分布式内存和KV缓存。通过使用MemPool API,MemServe首次结合了上下文缓存与碎片化推理,得到了全局调度程序的支持,该调度程序通过基于全局提示树的局部性感知策略增强了缓存复用。
Prabhu等人[2024]介绍了一种名为vAttention的动态内存管理系统,适用于LLM(语言模型)服务系统。vAttention利用操作系统对虚拟内存和需求分页的支持,减少了传统PagedAttention方法的编程负担和性能损失。
大型语言模型的高吞吐量服务需要在一个批次中处理足够的请求。然而,现有系统在这方面表现不佳,因为每个请求的键值缓存(KV缓存)内存占用较大且动态增长和缩小。如果管理不当,由于碎片化和冗余复制,这部分内存可能会严重浪费,从而限制了批处理大小。为了解决这个问题,Kwon等人[2023]提出了PagedAttention,这是一种受经典虚拟内存和操作系统中分页技术启发的注意力算法。在此基础上,作者开发了vLLM,这是一种大型语言模型服务系统,实现了(1) 几乎零浪费的KV缓存内存和(2) 在请求内部和跨请求之间的灵活共享KV缓存以进一步减少内存使用。
Chen等人[2024a]介绍了一种称为推测解码的技术,该技术通过在生成长上下文时进行推测解码来平衡延迟和吞吐量。通过理论建模和实证分析,作者发现推测解码可以在处理更长序列和大批量请求时增加吞吐量、减少延迟并保持生成的准确性。
Lin等人[2024]介绍了Infinite-LLM,这是一种新型的大语言模型(LLM)服务系统,旨在解决LLM请求中高度动态的上下文长度管理问题。论文首先分析了LLM模型的计算特性,指出了传统静态模型并行化和KVCache调度方法在处理动态上下文长度时的局限性。为了解决这些问题,论文提出了三种创新:DistAttention机制,它将注意力计算和KVCache分布在整个GPU集群中以提高集群吞吐量;负债机制,它允许从其他实例借用内存以处理大上下文任务并增加生成吞吐量;以及gManager,用于请求和KVCache分配的全局规划和协调。
He和Wu[2024]主要介绍了一种名为KCache的有效推理技术,用于大语言模型(LLMs)的推理过程。KCache在推理过程中将K缓存存储在高带宽内存(HBM)中,将V缓存存储在CPU内存中。它根据注意力计算的softmax结果,动态选择哪些关键信息从CPU内存复制回HBM进行计算。这种方法确保了推理的准确性,同时提高了其性能。
4.3.3 共享注意力
大型语言模型通常预先计算KV缓存,以加快多文本块输入的预填充速度,但Yao等人[2024a]仅在文本块是输入的前缀时有效。当文本块不是前缀时,由于缺乏与前文的交叉注意力,预先计算的KV缓存无法直接使用,这限制了缓存的重用。为了解决这个问题,作者提出了一种称为CacheBlend的方案。CacheBlend无论文本块是否为前缀,都可以重用预先计算的KV缓存。它选择性地重新计算一小部分标记的KV值,以部分更新重用的KV缓存并补充交叉注意力。重新计算这些标记的延迟可以通过与KV缓存检索的流水线处理来掩盖,从而使CacheBlend能够在不增加推理延迟的情况下将缓存存储在较慢但容量更高的设备中。这种方法在保持与完整预填充相同的生成质量的同时提高了效率。
Liao和Vargas[2024]主要介绍了一种称为共享注意力(SA)的方法,该方法通过共享注意力权重来减少大型语言模型中的计算和存储开销。传统方法主要集中在共享键值缓存以减少内存开销,但仍需在每一层独立计算注意力权重。相比之下,SA方法直接共享计算出的注意力权重,这不仅显著减少了键值缓存的大小,还减少了模型推理期间的计算负载。
4.3.4 KV缓存压缩与注意力的关系。
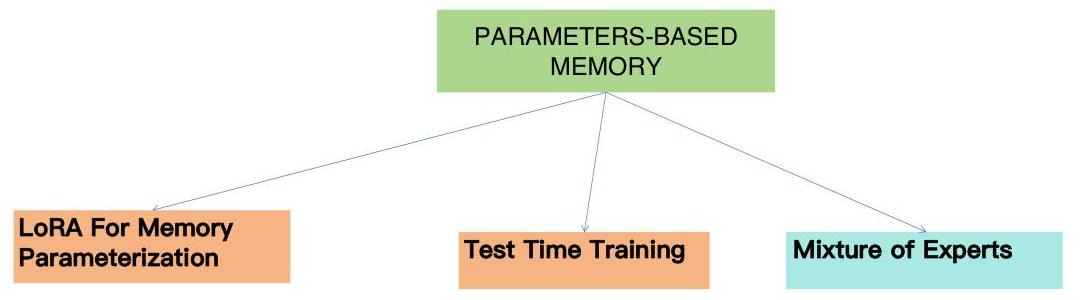
图8:基于参数的记忆
注意力机制是Transformer架构的核心组件,它使大规模语言模型取得了显著的成功。然而,注意力机制的理论基础尚未完全理解,特别是其非凸优化动力学。在Ataee Tarzanagh等人[2023]的研究中,作者研究了开创性的softmax注意力模型 f ( X ) = ⟨ X v f(X)=\langle X v f(X)=⟨Xv,softmax ( X W p ) ⟩ (X W p)\rangle (XWp)⟩,其中 X X X是一个标记序列, ( v , W , p ) (v, W, p) (v,W,p)是可训练参数。他们证明,在 p p p或等效于 W W W上运行梯度下降会方向性收敛到一个最大边缘解,该解可以区分局部最优标记和非最优标记。这明确地将注意力形式化为一种最优标记选择机制。值得注意的是,作者的结果适用于一般数据,并准确地描述了标记在价值嵌入 X v X v Xv和问题几何方面的最优性。作者还提供了正则化路径的广泛分析,建立了即使存在非线性预测头,注意力的最大边缘属性。当 v v v和 p p p同时优化并使用逻辑损失时,作者确定了正则化路径方向性收敛到各自硬边缘支持向量机解的条件,其中 v v v根据标签分离输入特征。
5 参数基础的记忆
无论是基于文本的记忆还是基于KV缓存的记忆,都仅仅是历史信息的存储,它们并未成为模型真正的“记忆。”在本文中,我们介绍了一种记忆参数化的方法,将之前的记忆转化为模型本身的参数。
我们将记忆参数化的策略分为三类:LoRA、测试时训练(TTT)和专家混合(MoE),并分别介绍它们。
5.1 LoRA用于记忆参数化
在线场景中,Transformer语言模型面临着上下文扩展的挑战。随着上下文长度的增加,注意力机制需要越来越多的内存和计算资源,这显著降低了语言模型的吞吐量。为了解决这个问题,Kim等人[2023]提出了一种上下文压缩记忆系统。该系统持续将累积的注意力键/值对压缩到紧凑的记忆空间中,使语言模型能够在计算环境有限的内存中进行高效的推理。作者的压缩过程在推理过程中将轻量级条件LoRA(低秩适应)集成到语言模型的前向传递中,无需微调模型的整体权重集。此外,作者将递归压缩过程建模为单个并行化的前向计算,从而实现高效的训练。通过在对话、个性化和多任务学习等任务上的评估,作者展示了该方法可以在减少上下文记忆大小5倍的情况下达到全上下文模型的性能水平。此外,作者展示了该方法在无限上下文长度的流式场景中的适用性,其性能优于传统的滑动窗口方法。
作者假设一个Transformer语言模型 f θ f_{\theta} fθ有 L L L层,其中隐藏状态的维度为 d d d。为了简化符号,作者将压缩标记的长度设为1。值得注意的是,压缩标记的长度可以扩展到任意长度。在这种假设下,压缩标记(记为 ⟨ \langle ⟨ COMP ⟩ \rangle ⟩)的总大小为 2 × L × d 2 \times L \times d 2×L×d。在每个时间步 t t t,作者将 ⟨ \langle ⟨ COMP ⟩ \rangle ⟩标记附加到上下文 c ( t ) c(t) c(t),并对 c ( t ) c(t) c(t)的键/值和前一记忆状态 Mem ( t − 1 ) \operatorname{Mem}(t-1) Mem(t−1)使用 ⟨ \langle ⟨ COMP ⟩ \rangle ⟩标记进行注意力操作。通过这种操作,使用 ⟨ \langle ⟨ COMP ⟩ \rangle ⟩标记的注意力键/值,作者获得了压缩的隐藏特征 h ( t ) ∈ R 2 × L × d h(t) \in \mathbb{R}^{2 \times L \times d} h(t)∈R2×L×d。
5.2 测试时训练用于记忆参数化
测试时训练(TTT)Sun等人[2020],Gandelsman等人[2022],Hardt和Sun[2023]是一种技术,通过在测试阶段进行额外的训练步骤来优化模型性能。它主要用于解决测试分布偏离训练分布的情况。TTT的核心思想是在测试阶段使用来自测试数据本身的信息对模型进行微调,从而更好地适应测试数据分布。具体来说,TTT引入了一个辅助任务,并通过优化辅助任务的损失函数更新某些模型参数,通常是特征提取器的参数。
在训练阶段,模型不仅学习主任务,还同时学习一个辅助任务。例如,在图像分类任务中,辅助任务可以是预测图像的旋转角度。主任务和辅助任务共享模型的一部分参数,通常是一个特征提取器。在测试阶段,对于每个测试样本,模型通过优化辅助任务的损失函数微调共享的特征提取器,更新模型参数,然后进行主任务的预测。
TTT的公式可以表达如下:假设模型参数表示为
θ
\theta
θ,主任务的损失函数表示为
l
m
l_{m}
lm,辅助任务的损失函数表示为
l
s
l_{s}
ls。设共享特征提取器的参数为
θ
c
\theta_{c}
θc,主任务特定的参数为
θ
m
\theta_{m}
θm,辅助任务特定的参数为
θ
s
\theta_{s}
θs。在训练阶段,模型的优化
目标是最小化主任务和辅助任务损失的加权和:
min θ e , θ m , θ s α l m ( θ e , θ m ) + ( 1 − α ) l s ( θ e , θ s ) \min _{\theta_{e}, \theta_{m}, \theta_{s}} \alpha l_{m}\left(\theta_{e}, \theta_{m}\right)+(1-\alpha) l_{s}\left(\theta_{e}, \theta_{s}\right) θe,θm,θsminαlm(θe,θm)+(1−α)ls(θe,θs)
其中 α \alpha α是平衡两个任务损失的权重。在测试阶段,对于每个测试样本 x x x,模型通过优化辅助任务的损失函数更新特征提取器参数:
θ e ′ = θ e − η ∇ θ e l s ( θ e , θ s ; x ) \theta_{e}^{\prime}=\theta_{e}-\eta \nabla_{\theta_{e}} l_{s}\left(\theta_{e}, \theta_{s} ; x\right) θe′=θe−η∇θels(θe,θs;x)
其中
η
\eta
η是学习率。
TTT有几项优势。它可以通过根据测试数据调整模型参数来动态适应测试数据分布,从而提高模型对当前测试样本的适应性。此外,TTT的计算开销较低,因为它只对少量样本进行少量训练,因此更高效。而且,TTT通常是无监督的,仅依赖于测试样本的无监督信号(如辅助任务的损失),而不需要额外标注。TTT广泛应用于图像分类和图神经网络等领域,特别是在测试和训练数据分布之间存在偏差时,显著提升了模型的性能。通过TTT,模型可以在推理过程中更新其参数以适应推理环境,而无需新的记忆内容。
5.3 MoE用于记忆参数化
Sukhbaatar等人[2024]介绍了一种创新的模型训练方法,称为分支-训练-混合(BTX),旨在有效地将多个专家大语言模型(LLMs)集成到单一的专家混合(MoE)模型中。这种方法结合了分支-训练-合并(BTM)方法和MoE架构的优势,同时缓解了各自的缺点。
BTX方法包括三个主要步骤。首先,在分支和训练阶段,从预训练种子模型创建多个副本(称为专家模型),并在不同的数据子集上独立训练,每个子集对应于特定的知识领域,如数学、编程或维基百科。这种训练过程是并行和异步的,减少了通信成本并提高了训练吞吐量。接下来,在混合阶段,这些专家模型的前馈子层被合并成一个单一的MoE模块,以形成统一的MoE模型。在每个Transformer层中,使用路由器网络选择哪个专家的前馈子层应应用于每个标记。自注意力子层和其他模块的权重通过简单平均结合。最后,在MoE微调阶段,合并后的模型在完整的训练数据集上进一步微调,允许路由器网络学习如何在测试时动态地在不同专家之间路由标记。
BTX方法的优点包括专家训练阶段的并行和异步性质,这减少了通信成本并提高了训练效率。最终的BTX模型是一个统一的神经网络,可以像任何标准LLM一样进行微调。此外,尽管参数数量增加,但由于它是稀疏激活的,模型在推理期间的FLOPs(浮点运算)不会显著增加。该论文还探索了BTX的各种变体,如负载均衡、不同的路由方法和专家拆分与合并策略,以进一步提高模型性能和效率。
6 基于隐藏状态的记忆
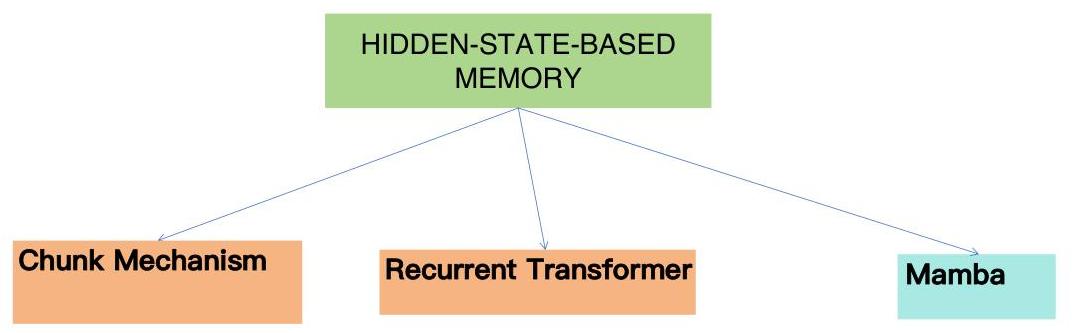
图9:基于隐藏状态的记忆
除了保留文本记忆、KV缓存和参数化记忆外,一些研究人员还将RNNs中的隐藏状态概念与当前方法相结合。这些方法可以分为三类:基于块机制的方法、递归变压器方法和基于Mamba的方法。
6.1 块机制
在处理长文本时,LLMs采用了一种称为块机制的方法,该方法涉及将长文本分成较小的块,以便更高效地进行处理和嵌入。这一过程首先根据固定的字符数、句子、段落或语义将文本分割成多个块。它确保了具有连贯语义的标记聚集在一起,而具有不同语义的标记分开,以保持每个块的语义完整性。随后,每个块单独输入语言模型进行处理,模型为每个块生成一个嵌入向量,该向量捕获块的语义信息。为了避免在块边界处丢失上下文信息,通常使用重叠策略,这意味着每个块的开头部分与前一个块的结尾部分重叠。这些块的嵌入向量可用于诸如信息检索和内容推荐等下游任务。
Transformer中的上下文窗口充当主动记忆,用于少数样本学习和条件生成等任务,这些任务严重依赖于先前的上下文标记。然而,上下文长度的增加会导致计算成本呈二次增长。最近的方法通过结合固定大小的滑动窗口与初始标记实现了线性复杂度,但无条件地在窗口结束时从KV缓存中删除所有标记,导致信息丢失。为了解决这个问题,Willette等人[2024]提出了一种新机制:维护级联子缓冲区,以在保持相同总缓存大小的同时存储更长的上下文,每个缓冲区有条件地接受从前一个缓冲区丢弃的重要标记。
上述过程导致固定的启发式模式丢弃标记,这并不理想,因为模型可能天真地保留价值较低的标记而丢弃重要的标记。为了解决这个问题,作者通过跟踪标记的平均注意力得分,使用指数移动平均(EMA)动态选择要保留的重要标记。他们丢弃EMA得分较低的标记。具体来说,给定超参数
γ
∈
[
0
,
1
]
\gamma \in[0,1]
γ∈[0,1]和时间步
t
t
t的注意力得分向量
s
k
(
t
)
\mathbf{s}_{k}^{(t)}
sk(t),平均注意力得分
μ
(
t
)
\mu^{(t)}
μ(t)更新为:
μ ( t + 1 ) = γ μ ( t ) + ( 1 − γ ) s k ( t ) \mu^{(t+1)}=\gamma \mu^{(t)}+(1-\gamma) \mathbf{s}_{k}^{(t)} μ(t+1)=γμ(t)+(1−γ)sk(t)
Bai等人[2024]的主要内容介绍了一种称为CItruS的方法,旨在解决长序列建模中的信息丢失问题。作者提出了两个子过程:语言建模过程和任务解决过程。在语言建模过程中,采用了基于块的状态淘汰方法以提高建模效率。在任务解决过程中,引入了指令感知状态淘汰,利用最终指令的隐藏状态
作为额外的指令感知查询,提取并保留任务相关的信息。使用此键值缓存生成任务特定的响应。
Corallo 和 Papotti [2024] 提出了一种称为 FINCH 的新方法,该方法通过利用预训练自注意力模型的权重来压缩输入上下文。给定一个提示和一段长文本,FINCH 迭代识别与提示相关的键 (K) 和值 (V) 对,基于文本块。只有这些对被存储在空间受限的上下文窗口中的 KV 缓存中,最终包含长文本的压缩版本。
Bertsch 等人 [2023] 引入了一种称为 Unlimiformer 的方法,该方法在测试时可以接受任意长度的输入文本。Unlimiformer 使用 k - 最近邻索引构建输入文本的隐藏状态。然后在每个解码器层的标准交叉注意力头中查询 k - 最近邻索引,使用 k - 最近邻距离作为注意力得分,并仅关注前 k 个输入标记。这样,Unlimiformer 能够扩展现有的编码器 - 解码器 Transformer 模型以接受任意长度的输入。这种方法不仅具有低计算和内存开销,还能精确近似全局注意力。
Chevalier 等人 [2023] 引入了一种称为 AutoCompressor 的方法,该方法通过生成摘要向量扩展语言模型的上下文窗口,从而增强模型处理长文本的能力。摘要向量从长文档生成,用于改进后续段落的语言建模。作者通过实验表明,摘要向量可以编码有用的信息,帮助下游任务性能,并减少上下文学习的推理成本。此外,作者展示了使用预计算的摘要向量在大型语料库上的文本检索和重新排序任务中的有效性。
Yu 等人 [2023] 引入了一种称为 MEGABYTE 的多尺度解码器架构,该架构可以对超过一百万字节的序列进行端到端可微建模。MEGABYTE 将序列划分为补丁,并在补丁内使用局部子模型和补丁间使用全局模型。这种方法实现了次平方自注意力、更大的前馈层和解码期间更好的并行性,从而在训练和生成期间以更低的成本实现更好的性能。
Xie 等人 [2023] 引入了一种简单的方法,用于处理 Transformer 模型中的长序列。传统的 Transformer 模型在处理长序列时面临计算复杂度的限制。然而,本文提出的方法可以有效地处理长序列,同时在短序列上保持良好的性能。具体来说,本文提出了一种方法,将长输入划分为易于管理长度的块,并选择最具代表性的标记进行解码。此外,本文还引入了一种基于策略学习的选择器来优化长序列信息的压缩过程。
Ye 等人 [2024] 主要介绍了一种称为 ChunkAttention 的注意力模块,该模块通过基于前缀的 KV 缓存和两阶段分区方法来提高自注意力的效率。具体来说,本文提出使用前缀树来实现 KV 缓存,可以动态检测并移除冗余的 KV 缓存以减少内存使用。同时,本文还描述了一种两阶段自注意力计算方法,包括块优先和序列优先阶段。
An 等人 [2024] 引入了一种新颖的无需训练的框架,称为 Dual Chunk Attention (DCA),用于扩展大语言模型 (LLMs) 的上下文窗口。本文首先描述了 DCA 的三个组成部分:块内注意力、块间注意力和连续块注意力。这些注意力机制有助于模型在处理长序列时有效捕捉长距离和短距离依赖。
在 Ivgi 等人 [2023] 中,作者提出了 SLED:滑动编码器和解码器,这是一种简单的方法,用于处理长序列,利用经过实战考验的预训练 LM 来处理短文本。具体来说,作者将输入划分为重叠的块,使用短文本 LM 编码器对每个块进行编码,并使用预训练解码器(融合在解码器中)来融合块间信息。
6.2 递归变压器
递归变压器是一种混合模型,结合了递归神经网络(RNNs)的优点,例如在处理长序列时保留信息的能力,以及变压器模型的并行处理和全局依赖捕捉能力。这种
类型的模型通常包括一个嵌入层,将输入词映射为高维向量;一个递归层,如LSTM或GRU,用于捕捉长期依赖;以及自注意力机制,用于并行处理序列的所有元素。此外,前馈网络对注意力层的输出进行非线性变换,而层规范化有助于稳定训练过程。残差连接在每个子层的输入和输出之间形成,以避免梯度消失问题。递归变压器可能包括编码器和解码器组件,有些模型采用分层结构来处理不同级别的序列。在模型中,信息通过递归层流动以捕捉长期依赖,然后通过注意力机制理解元素之间的全局关系,最后通过前馈网络进行进一步转换。递归变压器的不同变体可以根据特定应用和研究目标调整这些组件或引入新机制以提高性能。
RWKV Peng等人[2023] 是一种专为自然语言处理(NLP)任务设计的新型神经网络架构,结合了循环神经网络(RNNs)和Transformer架构的优势。它独特地结构化,以高效处理长文本序列,同时平衡长期上下文记忆和并行计算能力。
RWKV的核心结构包括输入嵌入、时间门、状态更新和输出层。输入嵌入将文本序列中的每个词或字符映射为向量。时间门通过以下公式控制时间维度上的信息流:
Time Gate ( x t ) = σ ( W t x t + b t ) \text { Time Gate }\left(x_{t}\right)=\sigma\left(W_{t} x_{t}+b_{t}\right) Time Gate (xt)=σ(Wtxt+bt)
其中
x
t
x_{t}
xt是时间步
t
t
t的输入向量,
W
t
W_{t}
Wt是时间门的权重矩阵,
b
t
b_{t}
bt是时间门的偏置向量,
σ
\sigma
σ是激活函数,通常是Sigmoid函数。
状态更新结合时间门的输出与前一时间步的状态,使用以下公式:
h t = Time Gate ( x t ) ⋅ h t − 1 + ( 1 − Time Gate ( x t ) ) ⋅ f ( x t ) h_{t}=\text { Time Gate }\left(x_{t}\right) \cdot h_{t-1}+\left(1-\text { Time Gate }\left(x_{t}\right)\right) \cdot f\left(x_{t}\right) ht= Time Gate (xt)⋅ht−1+(1− Time Gate (xt))⋅f(xt)
其中
h
t
h_{t}
ht是时间步
t
t
t的隐藏状态,
h
t
−
1
h_{t-1}
ht−1是前一时间步的隐藏状态,
f
(
x
t
)
f\left(x_{t}\right)
f(xt)是对当前输入的非线性变换,通常实现为神经网络层。
最后,输出层通过以下公式将隐藏状态转换为输出结果:
y t = W y h t + b y y_{t}=W_{y} h_{t}+b_{y} yt=Wyht+by
其中
y
t
y_{t}
yt是时间步
t
t
t的输出,
W
y
W_{y}
Wy是输出层的权重矩阵,
b
y
b_{y}
by是输出层的偏置向量。
RWKV的主要优点是它能高效处理长文本序列,避免了传统RNNs中常见的梯度消失或爆炸问题。它还具备一定的并行计算能力,提高了训练和推理效率。通过动态控制信息流,RWKV可以更好地捕捉上下文中的长期依赖。
6.3 Mamba
Mamba是一种基于选择性状态空间模型(SSM)的新型序列模型,旨在结合循环神经网络(RNNs)和Transformer的优势,同时提高效率和性能。其核心结构由三部分组成:Transformer MLP、SSM块和选择机制。Transformer MLP负责通道混合,类似于Transformers中的前馈网络部分;SSM块负责序列建模,通过状态空间模型捕捉序列中的长程依赖;选择机制根据输入动态调整模型参数,类似于注意力机制但更高效。
Mamba的工作流程主要包括以下几个关键步骤。首先,输入序列通过线性投影扩展维度,然后离散化。离散化公式为:
A
~
=
exp
(
Δ
A
)
B
~
=
(
Δ
A
)
−
1
(
exp
(
Δ
A
)
−
I
)
⋅
Δ
B
\begin{gathered} \tilde{A}=\exp (\Delta A) \\ \tilde{B}=(\Delta A)^{-1}(\exp (\Delta A)-I) \cdot \Delta B \end{gathered}
A~=exp(ΔA)B~=(ΔA)−1(exp(ΔA)−I)⋅ΔB
其中
Δ
\Delta
Δ是控制状态更新程度的选择因子。接下来,选择机制根据输入动态生成矩阵
B
,
C
B, C
B,C和
Δ
\Delta
Δ,公式为:
s B ( x ) = Linear N ( x ) s C ( x ) = Linear N ( x ) s Δ ( x ) = Linear D ( x ) \begin{aligned} & s_{B}(x)=\operatorname{Linear}_{N}(x) \\ & s_{C}(x)=\operatorname{Linear}_{N}(x) \\ & s_{\Delta}(x)=\operatorname{Linear}_{D}(x) \end{aligned} sB(x)=LinearN(x)sC(x)=LinearN(x)sΔ(x)=LinearD(x)
随后通过 τ Δ = \tau_{\Delta}= τΔ= softplus激活。状态更新和输出计算可以通过递归或卷积形式实现。递归形式公式为:
h t = A ˉ h t − 1 + B ˉ x t y t = C h t \begin{gathered} h_{t}=\bar{A} h_{t-1}+\bar{B} x_{t} \\ y_{t}=C h_{t} \end{gathered} ht=Aˉht−1+Bˉxtyt=Cht
而卷积形式公式为:
y = K × x y=K \times x y=K×x
其中 K K K是由 B ˉ \bar{B} Bˉ和 C C C组成的卷积核。
7 讨论
参考文献
Aadharsh Aadhithya A 等人. 使用分层聚合树增强长期记忆以实现检索增强生成. arXiv e-prints, pages arXiv-2406, 2024.
Muhammad Adnan, Akhil Arunkumar, Gaurav Jain, Prashant Nair, Ilya Soloveychik 和 Purushotham Kamath. Keyformer: 通过关键标记选择实现高效生成推理的KV缓存缩减. Proceedings of Machine Learning and Systems, 6:114-127, 2024.
Joshua Ainslie, Santiago Ontanon, Chris Alberti, Vaclav Cvicek, Zachary Fisher, Philip Pham, Anirudh Ravula, Sumit Sanghai, Qifan Wang 和 Li Yang. Etc: 在Transformer中编码长和结构化输入. arXiv preprint arXiv:2004.08483, 2020.
Nick Alonso, Tomás Figliolia, Anthony Ndirango 和 Beren Millidge. 向对话代理添加上下文和时间敏感的长期记忆. arXiv preprint arXiv:2406.00057, 2024.
Chenxin An, Fei Huang, Jun Zhang, Shansan Gong, Xipeng Qiu, Chang Zhou 和 Lingpeng Kong. 不需训练即可扩展大型语言模型的长上下文. arXiv preprint arXiv:2402.17463, 2024.
Sotiris Anagnostidis, Dario Pavllo, Luca Biggio, Lorenzo Noci, Aurelien Lucchi 和 Thomas Hofmann. 动态上下文修剪以实现高效且可解释的自回归变压器. Advances in Neural Information Processing Systems, 36:65202-65223, 2023.
Davoud Ataee Tarzanagh, Yingcong Li, Xuechen Zhang 和 Samet Oymak. 注意力机制中的最大边距标记选择. Advances in neural information processing systems, 36:4831448362, 2023.
Yu Bai, Xiyuan Zou, Heyan Huang, Sanxing Chen, Marc-Antoine Rondeau, Yang Gao 和 Jackie Chi Kit Cheung. Citrus: 针对长序列建模的块化指令感知状态淘汰. arXiv preprint arXiv:2406.12018, 2024.
Iz Beltagy, Matthew E Peters 和 Arman Cohan. Longformer: 长文档变压器. arXiv preprint arXiv:2004.05150, 2020.
Amanda Bertsch, Uri Alon, Graham Neubig 和 Matthew Gormley. Unlimiformer: 接受无限长度输入的长范围变压器. Advances in Neural Information Processing Systems, 36: 35522 − 35543 , 2023 35522-35543,2023 35522−35543,2023.
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu 等. Pyramidkv: 基于金字塔信息漏斗的动态KV缓存压缩. arXiv preprint arXiv:2406.02069, 2024.
Chi-Chih Chang, Wei-Cheng Lin, Chien-Yu Lin, Chong-Yan Chen, Yu-Fang Hu, Pei-Shuo Wang, Ning-Chi Huang, Luis Ceze, Mohamed S Abdelfattah, 和 Kai-Chiang Wu. Palu: 使用低秩投影压缩KV缓存. arXiv preprint arXiv:2407.21118, 2024.
Jian Chen, Vashisth Tiwari, Ranajoy Sadhukhan, Zhuoming Chen, Jinyuan Shi, Ian En-Hsu Yen, 和 Beidi Chen. Magicdec: 通过投机解码打破长上下文生成中的延迟-吞吐量权衡. arXiv preprint arXiv:2408.11049, 2024a.
Nuo Chen, Hongguang Li, Juhua Huang, Baoyuan Wang, 和 Jia Li. 压缩以印象深刻: 释放真实世界长期内存压缩的潜力. arXiv preprint arXiv:2402.11975, 2024b.
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, 和 Danqi Chen. 适应语言模型以压缩上下文. arXiv preprint arXiv:2305.14788, 2023.
Giulio Corallo 和 Paolo Papotti. Finch: 面向大型语言模型的提示引导的键值缓存压缩. Transactions of the Association for Computational Linguistics, 12:1517-1532, 2024.
Jincheng Dai, Zhuowei Huang, Haiyun Jiang, Chen Chen, Deng Cai, Wei Bi, 和 Shuming Shi. 序列可以秘密告诉你要丢弃什么. arXiv e-prints, pages arXiv-2404, 2024.
Alessio Devoto, Yu Zhao, Simone Scardapane, 和 Pasquale Minervini. 一种基于L2范数的简单有效的KV缓存压缩策略. arXiv preprint arXiv:2406.11430, 2024.
Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, 和 Furu Wei. Longnet: 扩展到十亿标记的变压器. arXiv preprint arXiv:2307.02486, 2023.
Harry Dong, Xinyu Yang, Zhenyu Zhang, Zhangyang Wang, Yuejie Chi, 和 Beidi Chen. 用更少得到更多: 通过KV缓存压缩合成递归来实现高效的LLM推理. arXiv preprint arXiv:2402.09398, 2024.
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, 和 S Kevin Zhou. 优化LLMs中的KV缓存淘汰: 自适应分配以增强预算利用. arXiv e-prints, pages arXiv-2407, 2024.
Tianyu Fu, Haofeng Huang, Xuefei Ning, Genghan Zhang, Boju Chen, Tianqi Wu, Hongyi Wang,Zixiao Huang, Shiyao Li, Shengen Yan 等. MoA: 自动大型语言模型压缩的稀疏注意力混合体. arXiv preprint arXiv:2406.14909, 2024.
Yossi Handelsman, Yu Sun, Xinlei Chen 和 Alexei Efros. 测试时使用掩码自编码器进行训练. Advances in Neural Information Processing Systems, 35:29374-29385, 2022.
Yifei Gao, Lei Wang, Jun Fang, Longhua Hu, 和 Jun Cheng. 赋予你的模型更长更好的上下文理解能力. arXiv preprint arXiv:2307.13365, 2023.
Jing Guo, Nan Li, Jianchuan Qi, Hang Yang, Ruiqiao Li, Yuzhen Feng, Si Zhang, 和 Ming Xu. 强化大型语言模型代理的工作记忆. arXiv preprint arXiv:2312.17259, 2023.
Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, 和 Yinfei Yang. Longt5: 高效处理长序列的文本到文本变压器. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 724-736. Association for Computational Linguistics, 2022.
Zhiyu Guo, Hidetaka Kamigaito, 和 Taro Watanabe. 注意力得分并不是KV缓存缩减中衡量标记重要性的唯一依据: 值同样重要. arXiv preprint arXiv:2406.12335, 2024.
Moritz Hardt 和 Yu Sun. 使用最近邻对大型语言模型进行测试时训练. arXiv preprint arXiv:2305.18466, 2023.
Kostas Hatalis, Despina Christou, Joshua Myers, Steven Jones, Keith Lambert, Adam Amos-Binks, Zohreh Dannenhauer, 和 Dustin Dannenhauer. 记忆很重要: 改善LLM代理长期记忆的需求. In Proceedings of the AAAI Symposium Series, volume 2, pages 277-280, 2023.
Jiaao He 和 Jidong Zhai. Fastdecode: 使用异构管道实现高吞吐量GPU高效的LLM服务. arXiv preprint arXiv:2403.11421, 2024.
Qiaozhi He 和 Zhihua Wu. 高效的LLM推理与KCache. arXiv preprint arXiv:2404.18057, 2024.
Zifan He, Zongyue Qin, Neha Prakriya, Yizhou Sun, 和 Jason Cong. HMT: 层级记忆Transformer用于长上下文语言处理. arXiv e-prints, pages arXiv-2405, 2024.
Cunchen Hu, Heyang Huang, Junhao Hu, Jiang Xu, Xusheng Chen, Tao Xie, Chenxi Wang, Sa Wang, Yungang Bao, Ninghui Sun 等. Memserve: 具有弹性内存池的分布式LLM服务上下文缓存. arXiv preprint arXiv:2406.17565, 2024.
Dongseong Hwang, Weiran Wang, Zhuoyuan Huo, Khe Chai Sim, 和 Pedro Moreno Mengibar. TransformerFAM: 反馈注意力是工作记忆. arXiv preprint arXiv:2404.09173, 2024.
Maor Ivgi, Uri Shaham, 和 Jonathan Berant. 使用短文本模型高效理解长文本. Transactions of the Association for Computational Linguistics, 11:284-299, 2023.
Hyun-rae Jo 和 Dongkun Shin. A2SF: 带遗忘因子的累积注意力评分用于Transformer解码器中的标记剪枝. arXiv preprint arXiv:2407.20485, 2024.
Hana Kim, Kai Tzu-iunn Ong, Seoyeon Kim, Dongha Lee, 和 Jinyoung Yeo. 通过情境感知的人格细化在长期对话中构建和管理常识增强的记忆. arXiv preprint arXiv:2401.14215, 2024.
Jang-Hyun Kim, Junyoung Yeom, Sangdoo Yun, 和 Hyun Oh Song. 在线语言模型交互的压缩上下文记忆. arXiv preprint arXiv:2312.03414, 2023.
Sehoon Kim, Sheng Shen, David Thorsley, Amir Gholami, Woosuk Kwon, Joseph Hassoun, 和 Kurt Keutzer. 学习变压器中的标记剪枝. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 784-794, 2022.
Nikita Kitaev, Łukasz Kaiser, 和 Anselm Levskaya. Reformer: 高效的Transformer. arXiv preprint arXiv:2001.04451, 2020.
Iuliia Kotseruba 和 John K Tsotsos. 40年的认知架构: 核心认知能力和实际应用. Artificial Intelligence Review, 53(1):17-94, 2020.
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, 和 Ion Stoica. 使用PagedAttention高效管理大型语言模型服务的内存. In Proceedings of the 29th Symposium on Operating Systems Principles, pages 611-626, 2023.
John E Laird. Soar认知架构. MIT press, 2019.
Pat Langley 和 Dongkyu Choi. 统一物理代理的认知架构. In Proceedings of the National Conference on Artificial Intelligence, volume 21, page 1469. Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999, 2006.
Heejun Lee, Minki Kang, Youngwan Lee, 和 Sung Ju Hwang. 带有注意力回溯的稀疏标记变压器. In The Eleventh International Conference on Learning Representations, 2022.
Kuang-Huei Lee, Xinyun Chen, Hiroki Furuta, John Canny, 和 Ian Fischer. 具有非常长上下文摘要记忆的人类启发阅读代理. arXiv preprint arXiv:2402.09727, 2024.
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, 和 Deming Chen. SnapKV: LLM在生成前就知道你在寻找什么. Advances in Neural Information Processing Systems, 37:22947-22970, 2024.
Bingli Liao 和 Danilo Vasconcellos Vargas. 超越KV缓存: 高效LLMs的共享注意力. arXiv preprint arXiv:2407.12866, 2024.
Bin Lin, Chen Zhang, Tao Peng, Hanyu Zhao, Wencong Xiao, Minmin Sun, Anmin Liu, Zhipeng Zhang, Lanbo Li, Xiafei Qiu 等. Infinite-LLM: 带DistAttention和分布式KVCache的长上下文高效LLM服务. arXiv preprint arXiv:2401.02669, 2024.
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo 等. Deepseek-v2: 一种强大、经济且高效的专家混合语言模型. arXiv preprint arXiv:2405.04434, 2024a.
Lei Liu, Xiaoyan Yang, Yue Shen, Binbin Hu, Zhiqiang Zhang, Jinjie Gu, 和 Guannan Zhang. Think-in-Memory: 回忆和后思考使LLMs具备长期记忆. arXiv preprint arXiv:2311.08719, 2023.
Qi Liu, Dani Yogatama, 和 Phil Blunsom. 关系记忆增强的语言模型. Transactions of the Association for Computational Linguistics, 10:555-572, 2022.
Zhiyuan Liu 等. Scissorhands: 利用重要性持久性假设在测试时压缩LLM KV缓存. arXiv preprint arXiv:2402.02222, 2024b.
Yi Lu, Xin Zhou, Wei He, Jun Zhao, Tao Ji, Tao Gui, Qi Zhang, 和 Xuanjing Huang. Longheads: 多头注意力实际上是一种长上下文处理器. arXiv preprint arXiv:2402.10685, 2024.
Weiyao Luo, Suncong Zheng, Heming Xia, Weikang Wang, Yan Lei, Tianyu Liu, Shuang Chen, 和 Zhifang Sui. 深呼吸: 增强大语言模型的语言建模能力. arXiv preprint arXiv:2406.10985, 2024.
Christopher D Manning, Mihai Surdeanu, John Bauer, Jenny Rose Finkel, Steven Bethard, 和 David McClosky. 斯坦福CoreNLP自然语言处理工具包. In Proceedings of 52nd annual meeting of the association for computational linguistics: system demonstrations, pages 55 − 60 , 2014 55-60,2014 55−60,2014.
Amirkeivan Mohtashami 和 Martin Jaggi. 地标注意力: Transformer的随机访问无限上下文长度. arXiv preprint arXiv:2305.16300, 2023.
Yongyu Mu, Yuzhang Wu, Yuchun Fan, Chenglong Wang, Hengyu Li, Qiaozhi He, Murun Yang, Tong Xiao, 和 Jingbo Zhu. 跨层注意力共享用于大型语言模型. arXiv preprint arXiv:2408.01890, 2024.
Piotr Nawrot, Adrian Ļancucki, Marcin Chochowski, David Tarjan, 和 Edoardo M Ponti. 动态内存压缩: 为加速推理改造LLMs. arXiv preprint arXiv:2403.09636, 2024.
Matteo Pagliardini, Daniele Paliotta, Martin Jaggi, 和 François Fleuret. 通过稀疏闪存注意力更快地处理大规模序列中的因果注意力. arXiv preprint arXiv:2306.01160, 2023.
Xiurui Pan, Endian Li, Qiao Li, Shengwen Liang, Yizhou Shan, Ke Zhou, Yingwei Luo, Xiaolin Wang, 和 Jie Zhang. Instinfer: 低成本长上下文LLM推理的存储内注意力卸载. arXiv preprint arXiv:2409.04992, 2024.
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella 等. RWKV: 为Transformer时代重新发明RNNs. arXiv preprint arXiv:2305.13048, 2023.
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ramjee, 和 Ashish Panwar. vAttention: 不使用PagedAttention为LLM服务动态内存管理. arXiv preprint arXiv:2405.04437, 2024.
Frank E Ritter, Farnaz Tehranchi, 和 Jacob D Oury. ACT-R: 建模认知的认知架构. Wiley Interdisciplinary Reviews: Cognitive Science, 10(3):e1488, 2019.
Aurko Roy, Mohammad Saffar, Ashish Vaswani, 和 David Grangier. 使用路由变压器的有效基于内容的稀疏注意力. Transactions of the Association for Computational Linguistics, 9:53-68, 2021.
Kaiqiang Song, Xiaoyang Wang, Sangwoo Cho, Xiaoman Pan, 和 Dong Yu. Zebra: 使用分层局部全局注意力扩展上下文窗口. arXiv preprint arXiv:2312.08618, 2023.
Sainbayar Sukhbaatar, Olga Golovneva, Vasu Sharma, Hu Xu, Xi Victoria Lin, Baptiste Rozière, Jacob Kahn, Daniel Li, Wen-tau Yih, Jason Weston 等. Branch-Train-Mix: 将专家LLMs混合到一个专家混合LLM中. arXiv preprint arXiv:2403.07816, 2024.
Yu Sun, Xiaolong Wang, Zhuang Liu, John Miller, Alexei Efros, 和 Moritz Hardt. 测试时带自监督的训练以在分布偏移下实现泛化. In International conference on machine learning, pages 9229-9248. PMLR, 2020.
Hanlin Tang, Yang Lin, Jing Lin, Qingsen Han, Shikuan Hong, Yiwu Yao, 和 Gongyi Wang. RazorAttention: 通过检索头实现高效的KV缓存压缩. arXiv preprint arXiv:2407.15891, 2024a.
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, 和 Song Han. Quest: 查询感知稀疏性以实现高效的长上下文LLM推理. arXiv preprint arXiv:2406.10774, 2024b.
Zhongwei Wan, Xinjian Wu, Yu Zhang, Yi Xin, Chaofan Tao, Zhihong Zhu, Xin Wang, Siqi Luo, Jing Xiong, 和 Mi Zhang. D2O: 大型语言模型生成推理的动态判别操作. arXiv preprint arXiv:2406.13035, 2024.
Qingyue Wang, Liang Ding, Yanan Cao, Zhiliang Tian, Shi Wang, Dacheng Tao, 和 Li Guo. 递归总结使大型语言模型具备长期对话记忆. arXiv preprint arXiv:2308.15022, 2023.
Zheng Wang, Boxiao Jin, Zhongzhi Yu, 和 Minjia Zhang. 模型告诉你在哪里合并: 适应于长上下文任务的LLM KV缓存合并. arXiv preprint arXiv:2407.08454, 2024a.
Zihao Wang, Bin Cui, 和 Shaoduo Gan. SqueezeAttention: 通过逐层最优预算的2D管理LLM推理中的KV缓存. arXiv preprint arXiv:2404.04793, 2024b.
Jeffrey Willette, Heejun Lee, Youngwan Lee, Myeongjae Jeon, 和 Sung Ju Hwang. 训练免费指数扩展滑动窗口上下文的级联KV缓存. arXiv e-prints, pages arXiv-2406, 2024.
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, 和 Mike Lewis. 带有注意力池的高效流式语言模型. arXiv preprint arXiv:2309.17453, 2023.
Jiawen Xie, Pengyu Cheng, Xiao Liang, Yong Dai, 和 Nan Du. 分块、对齐、选择:一种简单的长序列处理方法适用于Transformer. arXiv preprint arXiv:2308.13191, 2023.
Yuhui Xu, Zhanming Jie, Hanze Dong, Lei Wang, Xudong Lu, Aojun Zhou, Amrita Saha, Caiming Xiong, 和 Doyen Sahoo. THINK: 通过查询驱动剪枝实现更薄的键缓存. arXiv preprint arXiv:2407.21018, 2024.
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, 和 Junchen Jiang. CacheBlend: 快速大型语言模型服务知识融合的RAG. arXiv preprint arXiv:2405.16444, 2024a.
Yao Yao, Zuchao Li, 和 Hai Zhao. SirLLM: 流式无限保留LLM. arXiv preprint arXiv:2405.12528, 2024b.
Lu Ye, Ze Tao, Yong Huang, 和 Yang Li. ChunkAttention: 带有前缀感知KV缓存和两阶段分区的高效自注意力. arXiv preprint arXiv:2402.15220, 2024.
Hao Yu, Zelan Yang, Shen Li, Yong Li, 和 Jianxin Wu. 有效压缩LLM的KV头. arXiv preprint arXiv:2406.07056, 2024.
Lili Yu, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer, 和 Mike Lewis. Megabyte: 使用多尺度Transformer预测百万字节序列. Advances in Neural Information Processing Systems, 36:78808-78823, 2023.
Ruifeng Yuan, Shichao Sun, Zili Wang, Ziqiang Cao, 和 Wenjie Li. 进化具有长期条件记忆的大语言模型助手. CoRR, 2023.
Chaoran Zhang, Lixin Zou, Dan Luo, Min Tang, Xiangyang Luo, Zihao Li, 和 Chenliang Li. 高效稀疏注意力需要自适应标记释放. arXiv preprint arXiv:2407.02328, 2024.
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett 等. H2O: 高效生成推理的重击者预言机. Advances in Neural Information Processing Systems, 36:34661-34710, 2023.
Youpeng Zhao, Di Wu, 和 Jun Wang. ALISA: 通过稀疏感知KV缓存加速大语言模型推理. In 2024 ACM/IEEE 第51届国际计算机体系结构研讨会 (ISCA), pages 1005-1017. IEEE, 2024.
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, 和 Yanlin Wang. MemoryBank: 增强大语言模型的长期记忆. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19724-19731, 2024.
Zayd Muhammad Kawakibi Zuhri, Muhammad Farid Adilazuarda, Ayu Purwarianti, 和 Alham Fikri Aji. MLKV: 多层键值头用于内存高效的Transformer解码. arXiv preprint arXiv:2406.09297, 2024.
参考论文:https://arxiv.org/pdf/2504.02441



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











