






李小鹏∗,香港城市大学,香港 贾鹏月∗,香港城市大学,香港 徐德荣,香港城市大学,香港和中国科学技术大学,中国 吴一闻,香港城市大学,香港 张颖仪,香港城市大学,香港和大连理工大学,中国 张文琳,香港城市大学,香港 王万宇,香港城市大学,香港 王一超,华为诺亚方舟实验室,中国 杜昭成,华为诺亚方舟实验室,中国 李相阳,华为诺亚方舟实验室,中国 刘勇,华为诺亚方舟实验室,新加坡 郭慧峰,华为诺亚方舟实验室,中国 唐瑞明†,华为诺亚方舟实验室,中国
赵翔宇†,香港城市大学,香港
个性化已成为现代AI系统中的一个基本能力,能够实现与用户偏好、上下文和目标一致的定制化交互。最近的研究越来越集中于检索增强生成(RAG)框架及其在个性化设置中向更高级的基于代理架构的演变,以提高用户满意度。在此基础上,本调查系统地考察了RAG三个核心阶段中的个性化:预检索、检索和生成。除了RAG之外,我们还进一步扩展其能力到个性化的LLM-based Agents领域,这些代理增强了传统的RAG系统,包括用户理解、个性化规划和执行以及动态生成等功能。对于RAG中的个性化和基于代理的个性化,我们提供了正式定义,进行了全面的文献综述,并总结了关键数据集和评估指标。此外,我们讨论了这一发展领域中的基本挑战、局限性和有前景的研究方向。相关论文和资源持续更新在Github Repo1。
CCS概念:•信息系统→个性化。
附加关键词和短语:大型语言模型,检索增强生成,代理,个性化
1https://github.com/Applied-Machine-Learning-Lab/Awesome-Personalized-RAG-Agent
*等量贡献。
†通讯作者。
未经许可,不得以任何方式复制或分发本文的部分或全部内容用于盈利或商业用途,除非事先获得特定许可和/或支付费用。复制时需注明此声明及首页完整引用信息。版权所有由他人拥有的本作品组件必须得到尊重。允许摘录并注明来源。其他形式的复制、重新发布、服务器上载或再分发至列表需要事先获得具体许可和/或支付费用。请向permissions@acm.org请求权限。©2018 版权由作者/所有者持有。出版权利已授予ACM。稿件提交给ACM
ACM参考格式:
李小鹏∗,贾鹏月∗,徐德荣,吴一闻,张颖仪,张文琳,王万宇,王一超,杜昭成,李相阳,刘勇,郭慧峰,唐瑞明†,赵翔宇†。2018。个性化调查:从RAG到Agent。在Make sure to enter the correct conference title from your rights confirmation email (Conference acronym 'XX). ACM, New York, NY, USA, 25页。 https://doi.org/XXXXXXX.XXXXXXX
1 引言
大型语言模型(LLMs)通过实现前所未有的自然语言理解和生成规模,彻底改变了AI驱动的应用程序。然而,这些模型通常存在过时响应和幻觉等问题,严重影响了信息生成的准确性。检索增强生成(RAG)作为一种有希望的框架出现,它通过从外部语料库中集成检索到的信息,例如外部API [13, [36]
其多功能性已在多个领域得到显著应用,包括问答 [115],企业搜索 [[16]
尽管RAG和代理工作流之间的结构对齐突显了它们的深度融合,但提升这些智能系统的下一个关键步骤在于个性化。个性化是实现更适应和情境感知AI的关键驱动力,对于通向人工通用智能(AGI)的进步至关重要。它在个性化推理 [39, [149]
受上述问题的启发,本调查旨在提供一份关于将个性化整合到RAG和代理RAG框架中的综合回顾,以提升用户体验和优化满意度。这项工作的关键贡献可以概括如下:
- 我们广泛探讨了现有文献中如何在RAG的不同阶段(预检索、检索和生成)以及代理RAG(理解、规划、执行和生成)中整合个性化。
-
- 我们总结了现有研究中用于每个子任务的关键数据集、基准和评估指标,以促进未来在各自领域的研究。
- 我们总结了现有研究中用于每个子任务的关键数据集、基准和评估指标,以促进未来在各自领域的研究。
图1. 个性化与RAG和代理流的相关性。
- 我们还指出了当前研究的局限性,并建议了个性化RAG的未来发展方向,强调潜在进展以解决现有挑战。
- 本调查的大纲如下:我们介绍什么是个性化(第2节),并解释如何将其应用于RAG管道(第3节)。然后,我们在不同阶段的RAG和代理RAG工作流中探讨了个性化整合的文献综述(第4节),并讨论了现有研究中使用的关鍵数据集和评估指标(第5节)。最后,我们提出了当前研究的局限性和未来方向的讨论(第6节)。
2 什么是个性化
当前研究中的个性化指的是调整模型预测或生成内容以符合个人偏好的过程。在RAG和代理的背景下,个性化涉及在RAG管道的各个阶段或代理内纳入用户特定信息。用户个性化可以分为以下类型:
-
显式用户配置文件:显式呈现的用户信息,包括传记细节、属性(例如年龄、位置、性别、教育)和社会联系(例如社交网络)。
-
- 用户历史交互:行为数据,包括浏览历史、点击和购买记录,帮助推断用户兴趣和偏好以改进个性化。
-
| 领域 | 子领域 | 子子领域 | 文章 | |
-
|-------------------|-----------------------------------------|---------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|–|
-
| 预检索 | 查询
重写 | 学习到
个性化查询重写 | CLE-QR [60], CGF [38], PEARL [80] | | -
| | | LLM到
个性化查询重写 | 最少到最多提示 [173], ERAGent [112], CoPS [174], Agent4Ranking [61], FIG [22], BASES [99] | | -
| | 查询 | 标签查询
扩展 | Gossple [10], Biancalana和Micarelli [12], SoQuES [15], Zhou等人 [172] | | -
| | 扩展 | 其他 | Lin和Huang [66], Bender等人 [9], 轴线PQEC [79], WE-LM [144], PSQE [14], PQEWC [7] | |
-
| | 其他 | | Bobo [33], Kannadasan和Aslanyan [52], PSQE [8] | |
-
| 检索 | 索引 | | PEARL [80], KG-Retriever [21], EMG-RAG [137], PGraphRAG [5] | |
-
| | 检索 | 密集
检索 | MeMemo [138], RECAP [71], LAPDOG [43], Gu等人 [37], PersonaLM [77], UIA [155], XPERT [125], DPSR [157],
RTM [11], Pearl [80], MemPrompt [74], ERRA [23], MALP [160], USER-LLM [84], PER-PCS [120] | | -
| | | 稀疏
检索 | OPPU [121], PAG [101], Au等人 [5], UniMS-RAG [128], Deng等人 [29], | | -
| | | 提示为基础
检索 | LAPS [50], UniMP [140], Shen等人 [111] | | -
| | | 其他 | Salemi等人 [103], PersonalTM [65], Zhang等人 [165] | |
-
| | 后检索 | | PersonaRAG [156], Pavliukevich等人 [89], UniMS-RAG [128], Salemi和Zamani [106], Zhang等人 [164], AutoCompressors [24], FIT-RAG [76] | |
-
| 生成 | 从明确偏好生成 | 直接
提示 | [49], 角色画像 [154] 意见QA [107], Kang等人 [51], Liu等人 [67], Cue-CoT [129], TICL [26]
2
P | | -
| | | 带配置文件增强
提示 | GPG [158], Richardson等人 [101], ONCE [70], LLMTreeRec [163], KAR [145], Matryoshka [58] | | -
| | | 个性化提示
提示 | Li等人 [57], RecGPT [166], PEPLER-D [59], GRAPA [94], SGPT [28], PFCL [152] | | -
| | 从隐含偏好生成 | 基于微调的方法 | PLoRA [165], LM-P [142], MiLP [165], OPPU [122], PER-PCS [120], Review-LLM [91],
UserIdentifier [78], UserAdapter [171], HYDRA [175], PocketLLM [90], CoGenesis [161] | | -
| | | 基于强化学习的方法 | P-RLHF [62], P-SOUPS [47], PAD [20], REST-PG [104], Salemi等人 [103], RewriterSlRl [57],Kulkarni等人 [54] | |
-
| 从RAG到Agent | 个性化
理解 | 在用户配置文件
理解 | Xu等人 [148], Abbasian等人 [2], | | -
| | | 在代理角色
理解 | RoleLLM [139], Character-LLM [110], Wang等人 [134], | | -
| | | 在代理用户角色
联合理解 | SocialBench [18], Dai等人 [27], Ran等人 [96], Wang等人 [126], Tu等人 [123], Neeko [153] | | -
| | 个性化规划
和执行 | 内存
管理 | EMG-RAG [137], Park等人 [87], Abbasian等人 [2], RecAgent [133], TravelPlanner+ [114], PersonalWAB [17], VOYAGER [127], MemoeryLLM [136] | | -
| | | 工具和API调用 | VOYAGER [127], Zhang等人 [159], PUMA [17], Wang等人 [126], PenetrativeAI [148], Huang等人 [44], [87], MetaGPT [40], OKR-Agent [169] | |
-
| | 个性化
生成 | 与用户事实
对齐 | Character-LLM [110], Wang等人 [135], Dai等人 [27] | | -
| | | 与用户
偏好对齐 | Wang等人 [139], Ran等人 [96], Wang等人 [134], Chen等人 [18] | |
| | | | | 表1. 个性化RAG和代理概述。 |
|–|–|–|–|--------------------------------------------------|
|–|–|–|–|--------------------------------------------------| -
用户历史内容:从用户生成的内容中派生的隐式个性化,例如聊天历史、电子邮件、评论和社交媒体互动。
-
- 基于人设的用户模拟:使用LLM-based代理进行个性化交互模拟。
在RAG和代理工作流的各个阶段整合这种个性化信息,使得响应能够动态地与人类偏好保持一致,从而使响应更加以用户为中心和适应性强。
- 基于人设的用户模拟:使用LLM-based代理进行个性化交互模拟。
3 如何采用个性化
我们将个性化引入RAG管道的过程定义如下:
G = G ( R ( Q ( q , p ) , C , p ) , prompt , p , θ ) (1) \mathcal{G} = \mathcal{G}\left(\mathcal{R}\left(\mathcal{Q}\left(q, p\right), \mathcal{C}, p\right), \text{prompt}, p, \theta\right) \tag{1} G=G(R(Q(q,p),C,p),prompt,p,θ)(1)
其中表示个性化信息,该过程分为三个步骤展开。在预检索阶段,查询处理(Q)利用个性化信息(如通过查询重写或扩展)细化查询。在检索阶段,检索器(R)利用从语料库(C)中获取相关文档。最后,在生成阶段,检索到的信息结合和通过给定提示结构化后输入到生成器(G)中,生成最终响应。显然,个性化信息直接影响RAG管道的多个阶段。在本调查中,我们将代理系统视为RAG框架的专门应用,其中个性化以类似于RAG框架的方式被纳入。
预检索
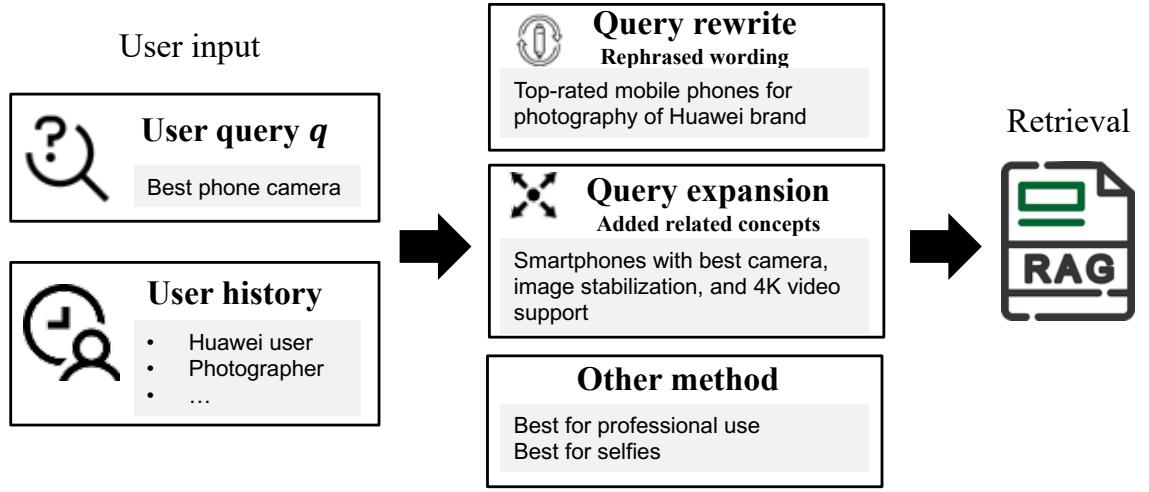
图2. 个性化预检索阶段概述。
4 在哪里采用个性化
4.1 预检索
4.1.1 定义。预检索是信息检索系统中的关键步骤,在检索过程之前增强或修改原始用户查询,以提高搜索结果的相关性和质量,如图 2. 所示。此过程通常结合额外的情境或个性化信息,以更好地使查询与用户的意图对齐。该过程可形式化为:
q ∗ = Q ( q , p ) (2) q^* = \mathcal{Q}\left(q, p\right) \tag{2} q∗=Q(q,p)(2)
其中和分别表示个性化信息和原始查询,而 ∗ 是经过查询重构后的优化查询。
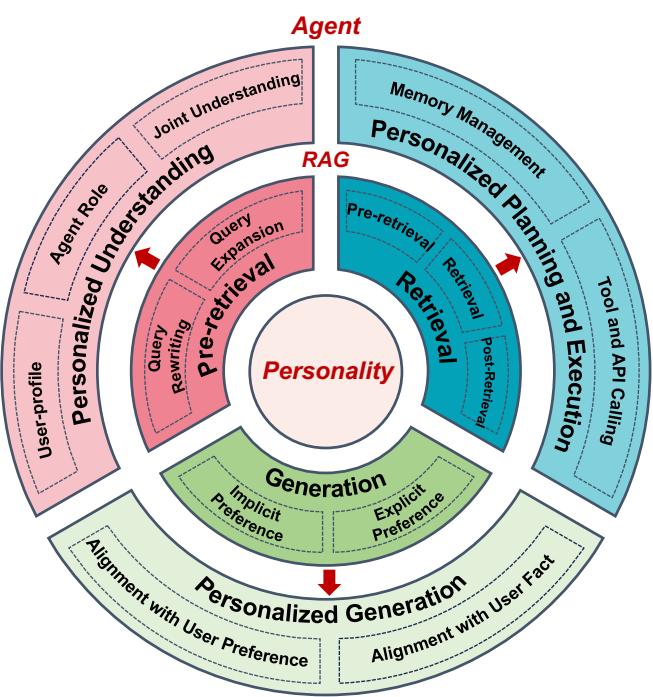
4.1.2 查询重写。RAG在预检索阶段的查询重写是指通过改进相关性、消除歧义或将上下文信息纳入检索前的文档中,以增强检索效果的用户查询重写过程。个性化查询重写的文献可以大致分为两类:(1) 直接个性化查询重写和(2) 辅助个性化查询重写。
(1). 直接个性化查询重写。第一类重点是通过直接模型进行个性化查询重写。例如,Cho等人[25]提出了一种面向对话式AI的个性化搜索查询重写系统,解决了用户特定的语义和语音错误。Nguyen等人[[82]
(2). 辅助个性化查询重写。第二类强调通过辅助机制(如检索、推理策略和外部记忆)进行个性化查询重写。Zhou等人[173] 提出了一种最少到最多的提示策略,有助于LLM中的复杂推理,可以适应个性化文本生成。ERAGent [[112]
4.1.3 查询扩展。查询扩展通过扩展用户的原始查询来增强检索系统,添加额外的术语、同义词或细化结构以更好地捕捉意图。这提高了检索文档的相关性和范围。最近LLM的发展重新激发了这个领域[46, [48,
(1). 标签查询扩展。到2009年,研究开始结合标签信息以增强个性化查询扩展。例如,Gossple [10] 引入了TagMap和TagRank算法,动态选择来自基于用户-项目标签距离余弦相似性的个性化网络的标签,提高了召回性能。同样,Biancalana和Micarelli [[12]
(2). 其他。除了基于标签的技术,早期个性化查询扩展研究主要集中在基于搜索历史[66]、社会网络或从友谊网络派生的偏好的用户个性化建模。Axiomatic PQEC框架[[79]
个性化调查:从RAG到Agent 会议缩写 'XX, June 03–05, 2018, Woodstock, NY
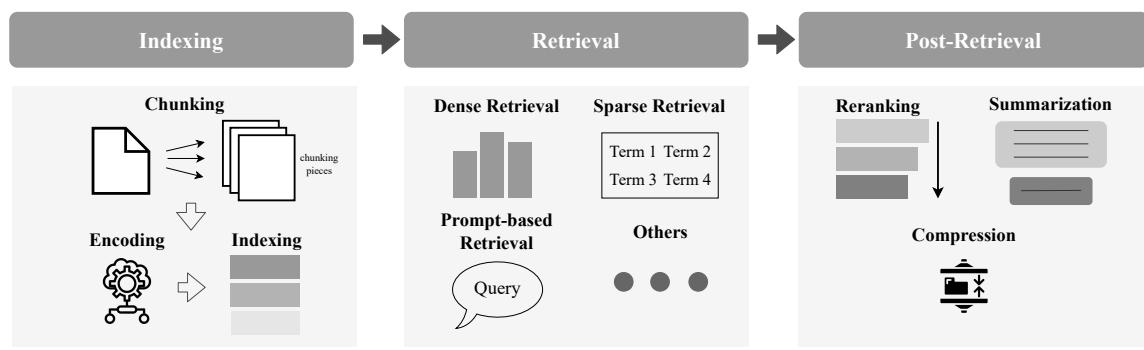
图3. 个性化检索阶段概述。
4.1.4 其他。除了查询重写和查询扩展,其他与个性化查询相关的研究聚焦于查询消歧和自动补全[116]。Bobo[[33]
4.1.5 讨论。虽然查询重写和查询扩展都旨在通过将用户输入与系统理解对齐来增强检索质量,但它们在个性化中的作用在根本上有不同的特点。了解每种技术的操作特性和应用场景对于设计有效的个性化检索系统至关重要。关键要点如下:
- 查询重写在原始查询模糊、未指定或与检索意图不一致时最为有益,特别是在对话或多轮设置中。
-
- 查询扩展在原始查询相关但不完整时最为有效,即当它需要语义扩展以涵盖额外的相关概念时。
4.2 检索
4.2.1 定义。检索过程涉及从语料库C中基于查询 * 检索最相关的文档 * ,如图 3. 所示。为了融入个性化,将额外的用户特定信息集成到检索函数 R 中。这允许检索过程根据个别用户的偏好或情境调整所选文档,从而增强生成输出的相关性和个性化。
D ∗ = R ( q ∗ , C , p ) (3) D^* = \mathcal{R}\left(q^*, \mathcal{C}, p\right) \tag{3} D∗=R(q∗,C,p)(3)
在检索过程中,个性化主要可以通过关注三个步骤引入:索引、检索和后检索。这些步骤确保高效准确地检索相关文档或知识,同时根据个别用户的偏好定制过程。以下是每个步骤的详细说明。
4.2.2 索引。索引将知识库数据组织成结构化格式,以便于高效检索。在RAG管道中,文档要么被切块,要么完全编码为代表形式,然后集成到可搜索系统中[30, [117]
为了在索引阶段引入个性化,PEARL[80]通过使用DeBERTa模型对个人历史数据进行编码生成用户嵌入。这些嵌入随后被聚类以创建个性化的共享索引。其他方法将知识图谱集成到索引中以增强检索性能。例如,KG-Retriever[[21]
4.2.3 检索。检索步骤将用户查询与索引知识库匹配以获取相关候选。它可以大致分为四种类型:(1) 密集检索,(2) 稀疏检索,(3) 提示为基础的检索,和(4) 其他。
(1). 密集检索。密集检索方法通常使用向量嵌入和相似度度量(如余弦相似度),并通过将用户偏好、上下文或交互编码到查询或文档嵌入中实现个性化,通过相似度匹配提供定制结果。例如,MeMemo[138]通过将用户特定嵌入与文档向量匹配检索个性化信息,专注于私有、设备上的文本生成。类似地,RECAP[[71]
密集检索还增强了特定应用,如电子商务、医疗协助和语言模型。DPSR[157]和RTM[[11]
(2). 稀疏检索。稀疏检索方法通常依赖于基于术语的匹配(如BM25),并通过为更相关的术语或关键词分配更高的权重实现个性化。OPPU[121]使用BM25算法从用户的历 史数据中选择与当前查询最相关的k条记录。类似地,PAG[[101]
(3). 提示为基础的检索。提示为基础的检索利用提示指导从模型或外部来源检索,并通过制作用户特定提示引导检索过程引入个性化。这些提示可能包括明确的用户偏好、历史交互或反映用户独特需求的详细指令。通过将这种个性化上下文直接嵌入提示中,检索过程可以动态调整以捕获和返回与用户最相关的结果。LAPS[50]专注于多会话对话搜索,通过存储用户偏好和对话上下文,然后使用提示检索与用户偏见和感兴趣类别相关的相关信息。UniMP[[140]
(4). 其他。基于强化学习的检索通过根据用户反馈优化检索策略实现个性化,随着时间学习用户偏好以调整策略。Salemi等人[103]结合BM25、RbR和密集检索模型,通过强化学习(RL)和知识蒸馏(KD)对其进行精炼,以适应用户配置文件进行个性化输出。参数为基础的检索利用预训练模型参数隐式存储和检索用户特定信息,允许直接从模型检索而不使用传统索引。PersonalTM[[65]
4.2.4 后检索。当前的后检索方法主要集中在细化检索到的文档或响应以提高相关性和连贯性,当前方法可分为三部分(1)重新排序,(2)摘要生成,和(3)压缩。
(1). 重新排序。重新排序通过优先考虑更相关的文档增强个性化内容生成。PersonaRAG[156]通过整合以用户为中心的代理(如现场会话代理和文档排名代理)扩展RAG,以细化文档排名并提高整体性能。Pavliukevich等人[[89]
(2). 摘要生成。摘要生成指的是总结检索到的信息以提高性能。例如,Zhang等人[164]引入了一个角色扮演代理系统,以总结检索到的历史,从而改进最终的个性化意见摘要过程。
(3). 压缩。压缩涉及压缩嵌入或检索到的内容以提高效率和有效性。例如,AutoCompressor[24]将上下文嵌入压缩为较短的语义表示,FIT-RAG[[76]
4.2.5 讨论。索引、检索和后检索方法各自在确保高效和个性化信息处理方面发挥着关键作用,具有特定应用和权衡。索引的重点是组织知识库以实现高效检索,使用诸如TF-IDF和BM25之类的稀疏编码方法,这些方法虽然高效但在理解语义方面有限,以及像BERT和DeBERTa这样的密集编码方法,这些方法提供了更好的语义理解但需要大量计算资源。这些方法广泛应用于诸如问答和个性化推荐系统等任务中。检索涉及将用户查询与相关文档匹配,可以分为密集检索,提供高语义理解和个性化但计算成本高;稀疏检索,高效且可解释但处理语义的能力较低;提示为基础的检索,高度灵活且适应用户需求但需要仔细设计提示;以及先进的方法如基于强化学习的方法,动态适应用户反馈但实现复杂。这一步骤在个性化对话系统、搜索引擎和电子商务等应用中至关重要。后检索方法通过重新排序,提高个性化和优先相关内容但增加计算开销;摘要生成,简化复杂信息以提高用户理解但可能丢失关键细节;和压缩,通过压缩信息减少计算成本但在个性化上下文中仍待深入探索。一起,这些方法提供了一个全面的管道,以提供高效、相关和个性化的输出,平衡它们在语义理解、相关性和灵活性方面的优势与计算成本和实施复杂性相关的挑战。
4.3 生成
4.3.1 定义。个性化生成通过生成器G结合用户特定检索的文档 * 、任务特定提示 和用户偏好信息 参数化生成与个人偏好对齐的定制内容 * ,如图 4. 所示。生成过程可以形式化为
G ∗ − − − − − − = G ( D ∗ , prompt , p , θ ) . (4) \mathcal{G}^* ------= \mathcal{G}\left(\mathcal{D}^*, \text{prompt}, \mathfrak{p}, \theta\right). \tag{4} G∗−−−−−−=G(D∗,prompt,p,θ).(4)
个性化生成可以通过结合显式和隐式偏好来实现。显式偏好驱动的方法利用直接输入信号(例如 * ,提示,和 ),以根据特定用户偏好定制输出。相反,隐式偏好编码方法在训练过程中将个性化信息嵌入到生成器模型的参数中,从而在无需明确运行时输入的情况下促进偏好对齐。
4.3.2 从显式偏好生成。将显式偏好整合到LLM中有助于个性化内容生成。显式偏好信息包括用户人口统计信息(例如年龄、职业、性别、位置)、用户行为序列(反映历史行为模式)和用户历史输出文本(捕捉写作风格和语气偏好)。为了个性化生成,显式偏好的注入可以分为三类:(1) 直接集成提示,(2) 摘要增强提示,和 (3) 自适应提示。
(1). 直接集成提示。通过提示将用户显式偏好整合到语言模型中,能够预测用户的意图和行为模式,从而促进个性化内容生成。例如,P 2[49],Character Profiling[[154]
调查个性化:从RAG到Agent 会议缩写 'XX, June 03–05, 2018, Woodstock, NY
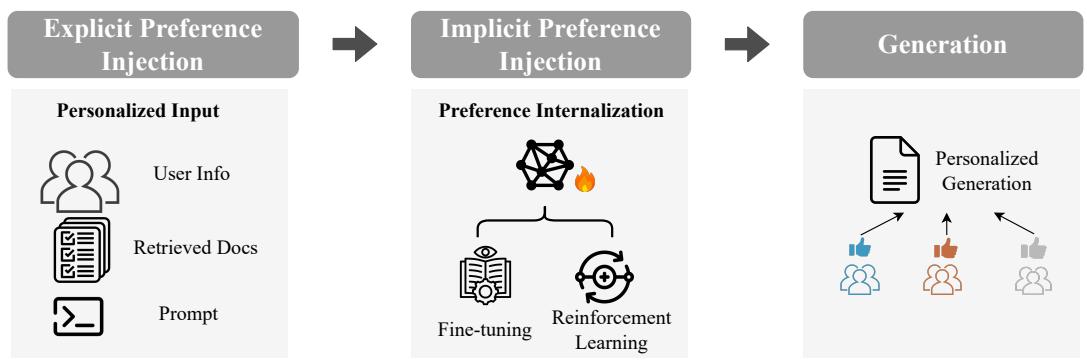
图4. 个性化生成阶段概述。
通过提示将交互历史整合到LLM中,以预测候选项目的用户评分。Cue-CoT[129] 使用链式推理从上下文线索推断用户需求,使深入对话问题获得个性化响应。此外,TICL[[26]
(2). 摘要增强提示。直接通过提示整合个性化信息在处理模糊意图信号时面临挑战:冗长的交互历史会引入掩盖关键行为模式的噪声[69],而稀疏的行为数据缺乏足够的上下文,使得LLM难以推导出有意义的用户偏好。为了解决这些问题,最近的方法侧重于总结用户的个性化意图并将其整合到提示中。例如,GPG[[158]
(3). 自适应提示。手动设计个性化提示需要专业知识和大量劳动,这促使了自动化个性化提示生成方法的发展。例如,Li等人[57] 通过监督学习和强化学习训练个性化提示重写器。RecGPT[[166]
4.3.3 从隐式偏好生成。与通过文本输入捕获用户偏好的显式偏好建模不同,基于隐式偏好的方法通过内部参数实现个性化。这种个性化要么通过参数高效微调(PEFT)技术,如LoRA[42] 实现,
或基于强化学习的方法进行偏好对齐[20, [57]
(1). 基于微调的方法。对于微调方法,LoRA由于资源高效且能快速适应而不影响模型性能,是最广泛采用的方法。PLoRA[165] 引入了一个个性化知识整合框架,结合任务特定的LoRA和用户特定知识。类似地,LM-P[[142]
除了基于LoRA的方法外,还提出了其他个性化生成管道。UserIdentifier[78] 引入了一个用户特定标识符,显著减少了训练成本同时增强了个性化演示。UserAdapter[[171]
(2). 基于强化学习的方法。除了基于微调的方法外,近期研究还探索了基于强化学习的技术,通过使输出与用户偏好对齐来个性化文本生成。P-RLHF[62] 被提出联合学习用户特定和奖励模型,以使文本生成与用户的风格或标准对齐。P-SOUPS[[47]
4.3.4 讨论。个性化生成可以通过显式和隐式偏好注入来实现,但它们表现出不同的特性,适用于不同的场景。在基于显式偏好的生成中,个性化是通过用户简档描述、上下文信息和其他类似输入明确定义的,并通过提示纳入生成器。这种方法的一个关键优势是可解释性,因为个性化信息是明确提供的并且易于追踪。尽管利用提供的偏好和内部知识,显式偏好注入的个性化受限于模型能力和无关信息干扰。相比之下,基于隐式偏好的生成将个性化信息内化到
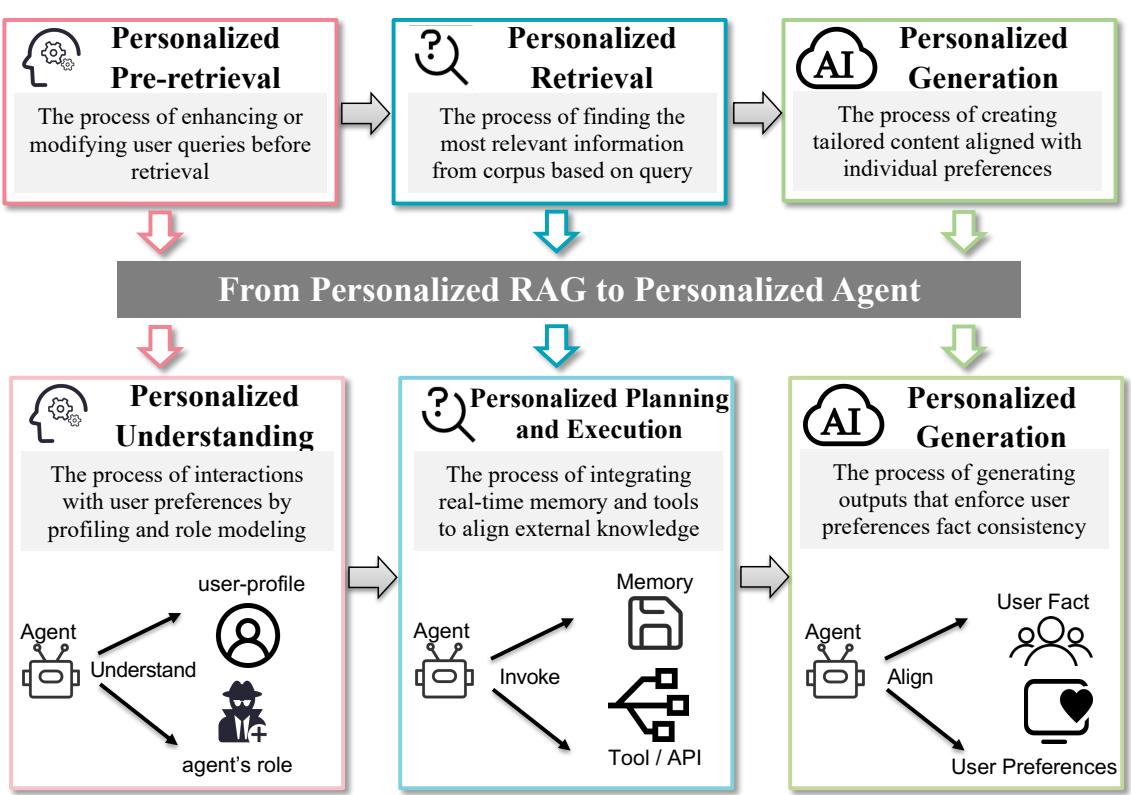
图5. 从个性化RAG到个性化代理的过渡概述。
应用机器学习实验室 1 城大
生成器的参数中,通过场景特定的个性化数据适应模型,以实现更精细的个性化。然而,这些方法通常需要大量的训练和计算成本,因为它们需要微调生成器的内部参数。因此,在选择这些方法时应考虑具体应用场景和资源限制。
4.4 从RAG到代理
4.4.1 定义。个性化LLM-based代理是一种系统,旨在动态整合用户上下文、记忆和外部工具或API,支持高度个性化和目标导向的互动[19, [45,
- 个性化理解:代理中的这一阶段与RAG中概述的查询理解和重写过程平行(见第4.1节)。然而,它超越了静态语义解析,通过整合动态用户画像[139]和角色建模[[110]- 个性化规划和执行:代理中的这一阶段镜像了RAG中第4.2节所述的检索过程,但它超越了静态文档检索,通过整合实时内存管理[87]和复杂的工具及API调用[[127]- 个性化生成:代理中的这一阶段镜像了RAG在第4.3节中的生成过程,但超越了静态模板生成,通过整合用户偏好和事实对齐。代理通过角色特定机制(例如,对话代理中的社会适应性[2])动态强制执行用户偏好并确保事实一致性,使输出能够随着个性化和情境约束和谐演化,而不仅仅依赖于预先定义的生成框架。
总体而言,我们将代理架构视为“个性化RAG++”,其中持久记忆[137] 替代了静态索引,工具API[[17]
4.4.2 个性化理解。个性化理解指的是代理通过整合用户意图识别和上下文分析准确解释用户输入的能力。此过程确保互动既富有意义又符合上下文。这种分类背后的理由在于其具备解决理解三大核心方面的能力:识别用户意图、分析上下文和利用用户简档。每个方面在改善代理性能方面都发挥着独特作用。
(1). 用户简档理解。在用户简档理解中,代理的个性化能力主要取决于其准确建模和理解用户偏好、上下文和意图的能力。Xu等人[148] 提出了一种框架,其中LLM被设计为理解物理世界,从而促进代理与其环境之间的更深层次连接,这对于精确的任务执行至关重要。Abbasian等人[[2]
(2). 角色理解。在代理的角色理解中,代理在此环境中的角色也至关重要。近期研究集中于增强LLM中的角色扮演能力。Wang等人[139] 引入了RoleLLM基准测试,旨在激发和细化LLM的角色扮演能力,展示了角色理解如何影响代理在对话任务中的表现。同样,Shao等人[[110]
(3). 用户角色联合理解。在代理的用户角色联合理解中,通过框架评估和增强LLM的社会性和性格方面,探索用户和角色理解的交集。SocialBench Chen等人[18] 提供了一个角色扮演代理的社会性评估框架。Dai等人[[27]
[96] 通过分别结合多模态数据和性格指示信息,使代理更好地适应动态环境中用户和角色的理解。此外,Wang等人[[126]
4.4.3 个性化规划和执行。个性化规划和执行是指设计和实施专门针对个人独特情境和目标的战略或行动[44, [87,
(1). 内存管理。有效的内存系统允许代理整合用户的历 史偏好、行为模式和上下文习惯,增强其制定计划和根据用户特定需求定制互动的能力[17, [127,
(2). 工具和API调用。外部工具的集成扩展了代理的能力,超出了纯粹的语言推理范围,使代理能够与用户互动并执行个性化任务[17, [126,
这种综合表明现代代理系统通过两种主要策略实现增强的个性化:1) 内存增强架构,利用可编辑内存图[137]、反思机制[[87]
4.4.4 个性化生成。基于个性化规划和执行机制奠定的基础,这些机制使代理能够根据用户特定的情境调整策略[44, [159]
适应性推理与人类对齐结果之间的差距,使代理能够产生上下文相关且情感适当的响应。
(1). 与用户事实对齐。与用户事实对齐强调个性化响应的准确性、一致性和事实依据,确保它们在各种用户互动中保持可信度。这在个性化代理中尤其具有挑战性,因为在避免幻觉的同时保持角色真实性需要在创造力与事实依从之间取得平衡。最近的进展通过改进的训练框架和评估指标解决了这些挑战。例如,Character-LLM[110] 集成内存增强架构以减少幻觉同时保留角色特定特征。Wang等人[[135]
(2). 与用户偏好对齐。与用户偏好对齐确保生成的输出反映个体化的人格特质、价值观和互动风格。这需要代理动态解释隐式用户线索并相应调整响应。Wang等人[139] 对特定角色对齐进行了基准测试。Ran等人[[96]
4.4.5 讨论。从RAG到个性化代理的架构演进在人机交互中引入了重大进步,但也暴露出需要进一步研究的关键挑战。
虽然个性化理解能够解释用户意图和上下文,但在实时适应性和泛化方面存在局限性。当前方法如RoleLLM[139] 和Character-LLM[[110]
个性化规划和执行通过内存管理和工具集成实现了显著的任务专业化,但在复杂环境中仍面临可扩展性问题。尽管像EMG-RAG[137] 和VOYAGER[[127]
个性化生成在平衡事实准确性与偏好对齐的同时,面临过拟合风险,过度微调到用户简档可能会强化认知偏差。技术解决表面级对齐但缺乏伦理边界检测机制。例如,代理在没有关键监督的情况下模仿用户偏好时,可能会无意传播有害刻板印象。未来系统可以集成价值对齐的强化学习与有人参与的循环验证,以保持真实性同时防止有害定制。
| 领域 | 指标 类别 | 指标 | 数据集 | |
|---|---|---|---|---|
| 预检索 | 文本 质量 | BLEU, ROUGE, EM | Avocado Research Email Collection [[57, 85]], Amazon review[[57, 83]], Reddit comments[[57, 118]], Amazon ESCI dataset[[82, 97]], PIP | |
| 信息 检索 | MAP, MRR, NDCG, 精度, 召回率, RBP | AOL[[88, 174]], WARRIORS[[99]], Personalized Results Re-Ranking benchmark [[6]], del.icio.us [[9, 15, 144, 172]], Flickr [[9, 108]], CiteULike [[10, 14]], LRDP [[12]], Delicious [[141]], Bibsonomy [[79]], Wikipedia [[8, 33]] | ||
| 分类 | 准确率, Macro-F1 | SCAN [[56, 173]], AITA WORKSM[[53, 80]], Robust04 [[61]] | ||
| 其他 | XEntropy, PMS, Image-Align, PQEC, Profoverlap | Amazon ESCI dataset[[82, 97]], PIP, Bibsonomy [[79]] | ||
| 检索 | 文本 质量 | BLEU, ROUGE, Dis, PPL | TOPDIAL [[130]], Pchatbot [[93]], DuLemon [[150]] | |
| 信息 检索 | 召回率, MRR, 精度, F1 | LiveChat [[34]], Pchatbot [[93]], DuLemon [[150]] | ||
| 分类 | 准确率, 成功率 | TOPDIAL [[130]], PersonalityEvd [[119]], DuLemon [[150]], PersonalityEdit [[75]] | ||
| 其他 | 流畅度, 一致性, 合理性, ES, DD, TPEI, PAE | PersonalityEvd [[119]], PersonalityEdit [[75]] | ||
| 生成 | 文本 质量 | BLEU, ROUGE, Dis, PPL, METEOR | LaMP [[105]], Long LaMP [[55]], Dulemon [[150]], PGraphRAG [[5]], AmazonQA/Products [[29]], Reddit [[170]], MedicalDialogue [[162]] | |
| 分类 | 准确率, F1, 人格F1 | LaMP [[105]], Long LaMP [[55]], Dulemon [[150]], AmazonQA/Products [[29]], Reddit [[170]], MedicalDialogue [[162]] | ||
| 回归 | MAE, RMSE | LaMP [[105]], Long LaMP [[55]], PGraphRAG [[5]] | ||
| 其他 | 流畅度, 平均成功率, 相对改进中位数 | Personalized-Gen [[3]] | ||
| 代理 | 文本 质量 | BLEU, ROUGE, METEOR, CIDEr, EM, 流畅度, 一致性相关的指标 | RICO [[126]], RoleBench [[139]], Shao等人 [[110]], Socialbench [[18]], MMRole-Data [[27]], ROLEPERSONALITY [[96]], ChatHaruhi [[134]], Character-LLM-Data [[153]], Knowledge Behind Persona [[41]], Wang等人 [[137]], Wang等人 [[135]], Zheng等人 [[169]] | |
| 信息 检索 | 召回率, F1, 精度 | Knowledge Behind Persona [[41]] | ||
| 分类 | 准确率, 失败率, 分类准确率, 偏好率, 正确性 | MIT-BIH 心律失常数据库 [[148]], VirtualHome [[44]], Socialbench [[18]], ARC [[100]], AGIEval [[100]], HellaSwag [[100]], MedMCQA [[100]], AQUA-RAT [[100]], LogiQA [[100]], LSAT-AR [[100]], LSAT-LR [[100]], LSAT-RC [[100]], SAT-English [[100]], SAT-Math [[100]], PersonalWAB [[17]], TravelPlanner+ [[114]] | ||
| 其他 | Pass@k, 可执行性, 生产力, 故事的合理性 | Hong等人[[40]], Zheng等人[[169]] |
表2. 个性化RAG和代理的数据集和指标。
5 评估和数据集
在个性化发展的各个阶段,从RAG到高级基于代理的系统,模型的评估严重依赖于为特定任务量身定制的多样化数据集和指标。本调查将指标分类为几个关键类型:文本质量指标(如BLEU、ROUGE、METEOR)评估生成输出的流畅性和一致性;信息检索指标(如MAP、MRR、召回率)评估检索信息的准确性和相关性;分类指标(如准确率、F1)衡量任务特定的正确性;回归指标(如MAE、RMSE)量化预测误差;以及其他指标(如流畅度、Pass@k)解决特定领域或任务的独特方面,如合理性和可执行性。这些指标涵盖了预检索、检索、生成和基于代理的个性化方法,反映了它们多样化的目标。为了提供全面的概述,我们编制了这些领域的广泛数据集列表,详见表 2. 这些数据集及其相应的指标使研究人员能够基准测试和改进个性化系统,从增强查询重写到在物理和虚拟环境中启用自主代理。
6 挑战和未来方向
个性化RAG和基于代理的系统仍然面临几个关键挑战,值得进一步探索。我们列出如下:
- 平衡个性化和可扩展性:将个性化数据(如偏好、历史和上下文信号)整合到RAG流程中通常会增加计算复杂度,使得在大规模系统中保持
- 效率和可扩展性变得困难。未来的工作可以探索轻量级、自适应嵌入和混合框架,无缝融合用户简档与实时上下文。
- 有效评估个性化:当前指标如BLEU、ROUGE和人工评估未能充分捕捉输出与动态用户偏好的细微对齐,缺乏个性化的有效性评估指标。开发专门的基准和指标以评估长期用户满意度和适应性对于实际应用至关重要。
-
- 通过设备-云端协作保护隐私:个性化检索通常涉及处理敏感的用户数据,引发了隐私担忧,尤其是在全球对数据保护法规(如欧盟《通用数据保护条例》GDPR)日益关注的情况下。因此,一种有前景的方法是协同整合本地处理敏感个人数据的小型语言模型与提供更广泛上下文知识的云基LLM。
- 个性化代理规划:目前关于代理规划的研究仍处于早期阶段,大部分工作集中在构建基础框架如GUI代理[81]和代理在不同领域的应用[[131]- 确保道德和一致的系统:数据处理中的偏差、用户画像中的隐私问题以及检索和生成阶段的一致性仍然是未解决的问题。未来的研究方向应优先考虑道德保障、隐私保护技术和跨阶段优化,以构建可信、统一的个性化系统。
7 结论
本文探讨了从检索增强生成(RAG)到高级基于LLM的代理的个性化景观,详细介绍了预检索、检索和生成阶段的适应,并扩展到代理能力。通过回顾最近的文献、数据集和指标,我们突显了通过定制化AI系统提升用户满意度的进展和多样性。然而,诸如可扩展性、有效评估和伦理问题等挑战凸显了对创新解决方案的需求。未来的研究应专注于轻量级框架、专门基准和隐私保护技术,以推动个性化AI的发展。相关论文和资源也在线汇编,以便于未来研究。
参考文献
-
[1] 2021. BERT: 自然语言处理和理解中的应用综述。arXiv预印本 arXiv:2103.11943 (2021).
-
- [2] Mahyar Abbasian, Iman Azimi, Amir M Rahmani, 和 Ramesh Jain. 2023. 对话健康代理:一种由个性化LLM驱动的代理框架。arXiv预印本 arXiv:2310.02374 (2023).
-
- [3] Bashar Alhafni, Vivek Kulkarni, Dhruv Kumar, 和 Vipul Raheja. 2024. 具有细粒度语言控制的个性化文本生成。在个性化生成AI系统研讨会论文集(PERSONALIZE 2024)中。88–101.
-
- [4] Amazon. [n. d.]. Amazon客户评论数据集。在线数据集。https://nijianmo.github.io/amazon/
-
- [5] Steven Au, Cameron J Dimacali, Ojasmitha Pedirappagari, Namyong Park, Franck Dernoncourt, Yu Wang, Nikos Kanakaris, Hanieh Deilamsalehy, Ryan A Rossi, 和 Nesreen K Ahmed. 2025. 面向大型语言模型的个性化图检索。arXiv预印本 arXiv:2501.02157 (2025).
-
- [6] Elias Bassani, Pranav Kasela, Alessandro Raganato, 和 Gabriella Pasi. 2022.多域个性化搜索评估基准。在第31届ACM国际信息与知识管理会议论文集。3822–3827。
-
- [7] Elias Bassani, Nicola Tonellotto, 和 Gabriella Pasi. 2023. 基于上下文词嵌入的个性化查询扩展。ACM信息系统交易 42, 2 (2023), 1–35。
-
- [8] Oliver Baumann 和 Mirco Schoenfeld. 2024. PSQE: 面向用户中心查询消歧的个性化语义查询扩展。(2024)。
-
[9] Matthias Bender, Tom Crecelius, Mouna Kacimi, Sebastian Michel, Thomas Neumann, Josiane Xavier Parreira, Ralf Schenkel, 和 Gerhard Weikum. 2008. 利用社交关系进行查询扩展和结果排名。在2008年IEEE第24届数据工程国际会议研讨会。IEEE, 501–506。
-
- [10] Marin Bertier, Rachid Guerraoui, Vincent Leroy, 和 Anne-Marie Kermarrec. 2009. 朝向个性化查询扩展。在第二届ACM EuroSys社交网络系统研讨会论文集。7–12。
-
- [11] Keping Bi, Qingyao Ai, 和 W Bruce Croft. 2021. 学习细粒度基于评论的转换模型以实现个性化产品搜索。在第44届国际ACM SIGIR信息检索研究与发展会议论文集。123–132。
-
- [12] Claudio Biancalana 和 Alessandro Micarelli. 2009. 社交标签在查询扩展中的应用:一种新的个性化网络搜索方式。在2009年计算科学与工程国际会议,第4卷。IEEE, 1060–1065。
-
- [13] Microsoft Bing. [n. d.]. Bing搜索引擎。https://www.bing.com
-
- [14] Mohamed Reda Bouadjenek, Hakim Hacid, 和 Mokrane Bouzeghoub. 2019. 使用社交注释的个性化社交查询扩展。大规模数据与知识为中心系统XL事务(2019),1–25。
-
- [15] Mohamed Reda Bouadjenek, Hakim Hacid, Mokrane Bouzeghoub, 和 Johann Daigremont. 2011. 使用社交书签系统的个性化社交查询扩展。在第34届国际ACM SIGIR信息检索研究与发展会议论文集。1113–1114。
-
- [16] Domenico Bulfamante. 2023. 使用可扩展知识库的生成式企业搜索。博士学位论文。都灵理工大学。
-
- [17] Hongru Cai, Yongqi Li, Wenjie Wang, ZHU Fengbin, Xiaoyu Shen, Wenjie Li, 和 Tat-Seng Chua. [n. d.]. 大型语言模型赋能的个性化Web代理。在THE WEB CONFERENCE 2025。
-
- [18] Hongzhan Chen, Hehong Chen, Ming Yan, Wenshen Xu, Xing Gao, Weizhou Shen, Xiaojun Quan, Chenliang Li, Ji Zhang, Fei Huang, 等人. 2024. Socialbench: 角色扮演对话代理的社会性评估。arXiv预印本 arXiv:2403.13679 (2024)。
-
- [19] Jiangjie Chen, Xintao Wang, Rui Xu, Siyu Yuan, Yikai Zhang, Wei Shi, Jian Xie, Shuang Li, Ruihan Yang, Tinghui Zhu, 等人. 2024. 从角色到个性化:角色扮演语言代理综述。arXiv预印本 arXiv:2404.18231 (2024)。
-
- [20] Ruizhe Chen, Xiaotian Zhang, Meng Luo, Wenhao Chai, 和 Zuozhu Liu. 2024. Pad: 在解码时个性化对齐LLMs。arXiv预印本 arXiv:2410.04070 (2024)。
-
- [21] Weijie Chen, Ting Bai, Jinbo Su, Jian Luan, Wei Liu, 和 Chuan Shi. 2024. Kg-retriever: 面向检索增强大型语言模型的有效知识索引。arXiv预印本 arXiv:2412.05547 (2024)。
-
- [22] Zheng Chen, Ziyan Jiang, Fan Yang, Eunah Cho, Xing Fan, Xiaojiang Huang, Yanbin Lu, 和 Aram Galstyan. 2023. 图遇LLM: 一种用于鲁棒对话理解的新型协同过滤方法。arXiv预印本 arXiv:2305.14449 (2023)。
-
- [23] Hao Cheng, Shuo Wang, Wensheng Lu, Wei Zhang, Mingyang Zhou, Kezhong Lu, 和 Hao Liao. 2023. 带有个性化评论检索和方面学习的可解释推荐。arXiv预印本 arXiv:2306.12657 (2023)。
-
- [24] Alexis Chevalier, Alexander Wettig, Anirudh Ajith, 和 Danqi Chen. 2023. 适应语言模型以压缩上下文。arXiv预印本 arXiv:2305.14788 (2023)。
-
- [25] Eunah Cho, Ziyan Jiang, Jie Hao, Zheng Chen, Saurabh Gupta, Xing Fan, 和 Chenlei Guo. 2021. 面向对话AI的个性化搜索查询重写系统。在第三届自然语言处理对话AI研讨会论文集。179–188。
-
- [26] Hyundong Cho, Karishma Sharma, Nicolaas Jedema, Leonardo FR Ribeiro, Alessandro Moschitti, Ravi Krishnan, 和 Jonathan May. 2025. 无需调优的个性化对齐:通过试错解释学习。arXiv预印本 arXiv:2502.08972 (2025)。
-
- [27] Yanqi Dai, Huanran Hu, Lei Wang, Shengjie Jin, Xu Chen, 和 Zhiwu Lu. 2024. MMrole: 开发和评估多模态角色扮演代理的综合框架。arXiv预印本 arXiv:2408.04203 (2024)。
-
- [28] Wenlong Deng, Christos Thrampoulidis, 和 Xiaoxiao Li. 2024. 解锁提示调优在连接通用和个性化联邦学习中的潜力。在IEEE/CVF计算机视觉和模式识别会议论文集。6087–6097。
-
- [29] Yang Deng, Yaliang Li, Wenxuan Zhang, Bolin Ding, 和 Wai Lam. 2022. 通过多视角偏好建模实现电子商务中的个性化答案生成。ACM信息系统事务(TOIS)40, 4 (2022), 1–28。
-
- [30] Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, 和 Hervé Jégou. 2024. Faiss库。(2024). arXiv:2401.08281 [cs.LG]
-
- [31] ESPN. [n. d.]. ESPN体育统计数据集。在线数据集。
-
- [32] Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, 和 Qing Li. 2024. 关于RAG遇见LLMs的综述:迈向检索增强型大型语言模型。在第30届ACM SIGKDD知识发现与数据挖掘会议论文集。6491–6501。
-
- [33] Byron J Gao, David C Anastasiu, 和 Xing Jiang. 2010. 利用用户输入上下文术语进行查询消歧。在Coling 2010: 海报。329–337。
-
- [34] Jingsheng Gao, Yixin Lian, Ziyi Zhou, Yuzhuo Fu, 和 Baoyuan Wang. 2023. LiveChat: 自动构建的大规模个性化对话数据集。arXiv预印本 arXiv:2306.08401 (2023)。
-
- [35] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Haofen Wang, 和 Haofen Wang. 2023. 面向大型语言模型的检索增强生成:综述。arXiv预印本 arXiv:2312.10997 2 (2023)。
-
- [36] Google. [n. d.]. Google搜索。https://www.google.com
-
- [37] Jia-Chen Gu, Hui Liu, Zhen-Hua Ling, Quan Liu, Zhigang Chen, 和 Xiaodan Zhu. 2021. 合作很重要!融合人物资料进行个性化响应选择的经验研究。在第44届国际ACM SIGIR信息检索研究与发展会议论文集。565–574。
-
- [38] Jie Hao, Yang Liu, Xing Fan, Saurabh Gupta, Saleh Soltan, Rakesh Chada, Pradeep Natarajan, Chenlei Guo, 和 Gökhan Tür. 2022. CGF: 对话AI中查询重写的约束生成框架。在2022年经验方法在自然语言处理会议行业轨道论文集。475–483。
-
- [39] Nicola Henze, Peter Dolog, 和 Wolfgang Nejdl. 2004. 语义网中的推理和本体论用于个性化电子学习。教育技术与社会杂志 7, 4 (2004), 82–97。
-
- [40] Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, 等人. 2023. MetaGPT: 面向多代理协作框架的元编程。arXiv预印本 arXiv:2308.00352 3, 4 (2023), 6。
-
- [41] WANG Hongru, Minda Hu, Yang Deng, Rui Wang, Fei Mi, Weichao Wang, Yasheng Wang, Wai-Chung Kwan, Irwin King, 和 Kam-Fai Wong. [n. d.]. 大型语言模型作为个性化知识基础对话的源规划器。在2023年经验方法在自然语言处理会议论文集。
-
- [42] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, 等人. 2022. LoRA: 大型语言模型的低秩适配。ICLR 1, 2 (2022), 3。
-
- [43] Qiushi Huang, Shuai Fu, Xubo Liu, Wenwu Wang, Tom Ko, Yu Zhang, 和 Lilian Tang. 2024. 学习检索增强以实现个性化对话生成。arXiv预印本 arXiv:2406.18847 (2024)。
-
- [44] Wenlong Huang, Pieter Abbeel, Deepak Pathak, 和 Igor Mordatch. 2022. 语言模型作为零次规划器:提取具身代理的可操作知识。在国际机器学习会议。PMLR, 9118–9147。
-
- [45] Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, 和 Enhong Chen. 2024. 理解LLM代理的规划:综述。arXiv预印本 arXiv:2402.02716 (2024)。
-
- [46] Rolf Jagerman, Honglei Zhuang, Zhen Qin, Xuanhui Wang, 和 Michael Bendersky. 2023. 通过提示大型语言模型进行查询扩展。arXiv预印本 arXiv:2305.03653 (2023)。
-
- [47] Joel Jang, Seungone Kim, Bill Yuchen Lin, Yizhong Wang, Jack Hessel, Luke Zettlemoyer, Hannaneh Hajishirzi, Yejin Choi, 和 Prithviraj Ammanabrolu. 2023. Personalized SOUPS: 通过后参数合并实现个性化大型语言模型对齐。arXiv预印本 arXiv:2310.11564 (2023)。
-
- [48] Pengyue Jia, Yiding Liu, Xiangyu Zhao, Xiaopeng Li, Changying Hao, Shuaiqiang Wang, 和 Dawei Yin. 2024. MILL: 使用大型语言模型进行零样本查询扩展的相互验证。在2024年北美计算语言学协会会议人类语言技术(第一卷:长篇论文)。2498–2518。
-
- [49] Guangyuan Jiang, Manjie Xu, Song-Chun Zhu, Wenjuan Han, Chi Zhang, 和 Yixin Zhu. 2023. 评估和诱导预训练语言模型的性格。神经信息处理系统进展 36 (2023), 10622–10643。
-
- [50] Hideaki Joko, Shubham Chatterjee, Andrew Ramsay, Arjen P De Vries, Jeff Dalton, 和 Faegheh Hasibi. 2024. 个人Laps:用于个性化多会话对话搜索的LLM增强对话构建。在第47届国际ACM SIGIR信息检索研究与发展会议论文集。796–806。
-
- [51] Wang-Cheng Kang, Jianmo Ni, Nikhil Mehta, Maheswaran Sathiamoorthy, Lichan Hong, Ed Chi, 和 Derek Zhiyuan Cheng. 2023. LLMs是否理解用户偏好?评估LLMs在用户评分预测上的表现。arXiv预印本 arXiv:2305.06474 (2023)。
-
- [52] Manojkumar Rangasamy Kannadasan 和 Grigor Aslanyan. 2019. 通过轻量级用户上下文表示实现个性化查询自动补全。arXiv预印本 arXiv:1905.01386 (2019)。
-
- [53] Anjuli Kannan, Karol Kurach, Sujith Ravi, Tobias Kaufmann, Andrew Tomkins, Balint Miklos, Greg Corrado, Laszlo Lukacs, Marina Ganea, Peter Young, 和 Vivek Ramavajjala. 2016. Smart Reply: 邮件的自动化响应建议。在第22届ACM SIGKDD知识发现与数据挖掘国际会议论文集(旧金山,加利福尼亚,美国)(KDD '16)。Association for Computing Machinery, New York, NY, USA, 955–964。 https://doi.org/10.1145/2939672.2939801
-
- [54] Mandar Kulkarni, Praveen Tangarajan, Kyung Kim, 和 Anusua Trivedi. 2024. 面向领域聊天机器人优化RAG的强化学习。arXiv预印本 arXiv:2401.06800 (2024)。
-
- [55] Ishita Kumar, Snigdha Viswanathan, Sushrita Yerra, Alireza Salemi, Ryan A Rossi, Franck Dernoncourt, Hanieh Deilamsalehy, Xiang Chen, Ruiyi Zhang, Shubham Agarwal, 等人. 2024. LongLAMP: 面向个性化长文本生成的基准。arXiv预印本 arXiv:2407.11016 (2024)。
-
- [56] Brenden Lake 和 Marco Baroni. 2018. 没有系统性的泛化:序列到序列循环网络的组合技能。在机器学习国际会议。PMLR, 2873–2882。
-
- [57] Cheng Li, Mingyang Zhang, Qiaozhu Mei, Weize Kong, 和 Michael Bendersky. 2024. 学习重写提示以实现个性化文本生成。在2024年ACM Web会议论文集。3367–3378。
-
- [58] Changhao Li, Yuchen Zhuang, Rushi Qiang, Haotian Sun, Hanjun Dai, Chao Zhang, 和 Bo Dai. 2024. Matryoshka: 使用LLM驱动黑盒LLM的学习。arXiv预印本 arXiv:2410.20749 (2024)。
-
- [59] Lei Li, Yongfeng Zhang, 和 Li Chen. 2023. 可解释推荐的个性化提示学习。ACM信息系统事务 41, 4 (2023), 1–26。
-
- [60] Sen Li, Fuyu Lv, Taiwei Jin, Guiyang Li, Yukun Zheng, Tao Zhuang, Qingwen Liu, Xiaoyi Zeng, James Kwok, 和 Qianli Ma. 2022. 淘宝搜索中的查询重写。在第31届ACM国际信息与知识管理会议论文集。3262–3271。
-
[61] Xiaopeng Li, Lixin Su, Pengyue Jia, Xiangyu Zhao, Suqi Cheng, Junfeng Wang, 和 Dawei Yin. 2023. Agent4ranking: 使用多代理LLM进行个性化查询重写的语义稳健排名。arXiv预印本 arXiv:2312.15450 (2023)。
-
- [62] Xinyu Li, Ruiyang Zhou, Zachary C Lipton, 和 Liu Leqi. 2024. 来自个性化人类反馈的个性化语言建模。arXiv预印本 arXiv:2402.05133 (2024)。
-
- [63] Yuanchun Li, Hao Wen, Weijun Wang, Xiangyu Li, Yizhen Yuan, Guohong Liu, Jiacheng Liu, Wenxing Xu, Xiang Wang, Yi Sun, 等人. 2024. 个人LLM代理:关于能力、效率和安全性的见解与调查。arXiv预印本 arXiv:2401.05459 (2024)。
-
- [64] Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, 和 Meishan Zhang. 2023. 通过多阶段对比学习实现通用文本嵌入。arXiv预印本 arXiv:2308.03281 (2023)。
-
- [65] Ruixue Lian, Sixing Lu, Clint Solomon, Gustavo Aguilar, Pragaash Ponnusamy, Jialong Han, Chengyuan Ma, 和 Chenlei Guo. 2023. PersonalTM: 用于个性化检索的Transformer记忆。在第46届国际ACM SIGIR信息检索研究与发展会议论文集。2256–2260。
-
- [66] Shan-Mu Lin 和 Chuen-Min Huang. 2006. 局部查询扩展中的个性化最优搜索。在第18届计算语言学和语音处理会议论文集。221–236。
-
- [67] Junling Liu, Chao Liu, Peilin Zhou, Renjie Lv, Kang Zhou, 和 Yan Zhang. 2023. ChatGPT是一个好的推荐者吗?初步研究。arXiv预印本 arXiv:2304.10149 (2023)。
-
- [68] Jiahong Liu, Zexuan Qiu, Zhongyang Li, Quanyu Dai, Jieming Zhu, Minda Hu, Menglin Yang, 和 Irwin King. 2025. 个性化大型语言模型综述:进展与未来方向。arXiv预印本 arXiv:2502.11528 (2025)。
-
- [69] Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, 和 Percy Liang. 2024. 迷失在中间:语言模型如何使用长上下文。计算语言学协会交易 12 (2024), 157–173。
-
- [70] Qijiong Liu, Nuo Chen, Tetsuya Sakai, 和 Xiao-Ming Wu. 2024. ONCE: 使用开源和闭源大型语言模型提升内容推荐。在第17届ACM国际Web搜索和数据挖掘会议论文集。452–461。
-
- [71] Shuai Liu, Hyundong J Cho, Marjorie Freedman, Xuezhe Ma, 和 Jonathan May. 2023. RECAP: 面向个性化对话响应生成的检索增强情境感知前缀编码器。arXiv预印本 arXiv:2306.07206 (2023)。
-
- [72] Tyler Lu 和 Craig Boutilier. 2011. 预算化的社会选择:从共识到个性化决策。在IJCAI, 第11卷。280–286。
-
- [73] Zhengyi Ma, Zhicheng Dou, Yutao Zhu, Hanxun Zhong, 和 Ji-Rong Wen. 2021. 每人一个聊天机器人:基于隐式用户画像创建个性化聊天机器人。在第44届国际ACM SIGIR信息检索研究与发展会议论文集。555–564。
-
- [74] Aman Madaan, Niket Tandon, Peter Clark, 和 Yiming Yang. 2022. 部署后的GPT-3改进的记忆辅助提示编辑。arXiv预印本 arXiv:2201.06009 (2022)。
-
- [75] Shengyu Mao, Xiaohan Wang, Mengru Wang, Yong Jiang, Pengjun Xie, Fei Huang, 和 Ningyu Zhang. 2024. 编辑大型语言模型的人格特征。在CCF国际自然语言处理与中文计算会议。Springer, 241–254。
-
- [76] Yuren Mao, Xuemei Dong, Wenyi Xu, Yunjun Gao, Bin Wei, 和 Ying Zhang. 2024. Fit-RAG: 带有事实信息和标记减少的黑盒RAG。arXiv预印本 arXiv:2403.14374 (2024)。
-
- [77] Puneet Mathur, Zhe Liu, Ke Li, Yingyi Ma, Gil Keren, Zeeshan Ahmed, Dinesh Manocha, 和 Xuedong Zhang. 2023. PersonaLM: 通过领域分布聚合最近邻n-gram检索增强的语言模型个性化。在计算语言学协会会议:EMNLP 2023的发现。11314–11328。
-
- [78] Fatemehsadat Mireshghallah, Vaishnavi Shrivastava, Milad Shokouhi, Taylor Berg-Kirkpatrick, Robert Sim, 和 Dimitrios Dimitriadis. 2021. UserIdentifier: 简单有效的个性化情感分析隐式用户表示。arXiv预印本 arXiv:2110.00135 (2021)。
-
- [79] Philippe Mulhem, Nawal Ould Amer, 和 Mathias Géry. 2016. 使用书签系统的公理术语个性化查询扩展。在数据库与专家系统应用国际会议。Springer, 235–243。
-
- [80] Sheshera Mysore, Zhuoran Lu, Mengting Wan, Longqi Yang, Steve Menezes, Tina Baghaee, Emmanuel Barajas Gonzalez, Jennifer Neville, 和 Tara Safavi. 2023. Pearl: 使用生成校准检索器个性化大型语言模型写作助手。arXiv预印本 arXiv:2311.09180 (2023)。
-
- [81] Dang Nguyen, Jian Chen, Yu Wang, Gang Wu, Namyong Park, Zhengmian Hu, Hanjia Lyu, Junda Wu, Ryan Aponte, Yu Xia, 等人. 2024. GUI代理:综述。arXiv预印本 arXiv:2412.13501 (2024)。
-
- [82] Duy A Nguyen, Rishi Kesav Mohan, Van Yang, Pritom Saha Akash, 和 Kevin Chen-Chuan Chang. 2025. 基于RL的查询重写:在线电子商务系统中的蒸馏LLM。arXiv预印本 arXiv:2501.18056 (2025)。
-
- [83] Jianmo Ni, Jiacheng Li, 和 Julian McAuley. 2019. 使用远程标注评论和细粒度方面的理由进行推荐。在2019年经验方法在自然语言处理和第九届国际联合自然语言处理会议(EMNLP-IJCNLP)论文集。188–197。
-
- [84] Lin Ning, Luyang Liu, Jiaxing Wu, Neo Wu, Devora Berlowitz, Sushant Prakash, Bradley Green, Shawn O’Banion, 和 Jun Xie. 2024. User-LLM: 使用用户嵌入高效地使LLM上下文化。arXiv预印本 arXiv:2402.13598 (2024)。
-
- [85] Douglas Oard, William Webber, David Kirsch, 和 Sergey Golitsynskiy. 2015. Avocado研究邮件集合。费城:语言数据联盟(2015)。
-
- [86] 美国国家医学图书馆。[n. d.]. PubMed:免费的生物医学文献资源。https://pubmed.ncbi.nlm.nih.gov/
-
- [87] Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, 和 Michael S Bernstein. 2023. 生成代理:人类行为的交互式模拟。在第36届年度ACM用户界面软件和技术研讨会论文集。1–22。
-
- [88] Greg Pass, Abdur Chowdhury, 和 Cayley Torgeson. 2006. 搜索图景。在第一届可扩展信息系统国际会议(香港)(InfoScale '06)。Association for Computing Machinery, New York, NY, USA, 1–es。 https://doi.org/10.1145/1146847.1146848
-
- [89] Vadim Igorevich Pavliukevich, Alina Khasanovna Zherdeva, Olesya Vladimirovna Makhnytkina, 和 Dmitriy Viktorovich Dyrmovskiy. [n. d.]. 使用LoRA微调改进RAG进行人格文本生成。([n. d.]).
-
- [90] Dan Peng, Zhihui Fu, 和 Jun Wang. 2024. PocketLLM: 实现设备端个性化LLM的微调。arXiv预印本 arXiv:2407.01031 (2024)。
-
- [91] Qiyao Peng, Hongtao Liu, Hongyan Xu, Qing Yang, Minglai Shao, 和 Wenjun Wang. 2024. Review-LLM: 利用大型语言模型进行个性化评论生成。arXiv:2407.07487 [cs.CL] https://arxiv.org/abs/2407.07487
-
- [92] Hongjin Qian, Zhicheng Dou, Yutao Zhu, Yueyuan Ma, 和 Ji-Rong Wen. 2021. 隐式用户画像学习以实现个性化检索型聊天机器人。在第三十届ACM国际信息与知识管理会议论文集。1467–1477。
-
- [93] Hongjin Qian, Xiaohe Li, Hanxun Zhong, Yu Guo, Yueyuan Ma, Yutao Zhu, Zhanliang Liu, Zhicheng Dou, 和 Ji-Rong Wen. 2021. Pchatbot: 用于个性化聊天机器人的大规模数据集。在第四十四届国际ACM SIGIR信息检索研究与发展会议论文集。2470–2477。
-
- [94] Xiaoru Qu, Yifan Wang, Zhao Li, 和 Jun Gao. 2024. 图增强提示学习用于个性化评论生成。数据科学与工程 9, 3 (2024), 309–324。
-
- [95] A. Rajaraman 和 J.D. Ullman. 2011. 大数据集挖------
-
- [96] 任轶腾,王鑫涛,许锐,袁新丰,梁家庆,杨德清,和肖洋华。2024
-
------. 捕捉心智,而不仅仅是词语:通过人格指示数据增强角色扮演语言模型。arXiv预印本 arXiv:2406.18921 (2024)。
-
- [97] Chandan K. Reddy, Lluís Màrquez, Fran Valero, Nikhil Rao, Hugo Zaragoza, Sambaran Bandyopadhyay, Arnab Biswas, Xing Anlu, 和 Karthik Subbian。2022. 购物查询数据集:一个大规模的ESCI基准,用于改进产品搜索。(2022). arXiv:2206.06588
-
- [98] Nils Reimers 和 Iryna Gurevych。2019. Sentence-BERT:使用Siamese BERT网络的句子嵌入。arXiv预印本 arXiv:1908.10084 (2019)。[99] Ren Ruiyang, Qiu Peng, Qu Yingqi, Liu Jing, Zhao Wayne Xin, Wu Hua, Wen Ji-Rong, 和 Wang Haifeng。2024. BASES:基于大型语言模型代理的大规模网络搜索用户模拟。arXiv预印本 arXiv:2402.17505 (2024)。
-
- [100] Matthew Renze 和 Erhan Guven。2024. 自我反思在LLM代理中的效果:对问题解决性能的影响。arXiv预印本 arXiv:2405.06682 (2024)。
-
- [101] Chris Richardson, Yao Zhang, Kellen Gillespie, Sudipta Kar, Arshdeep Singh, Zeynab Raeesy, Omar Zia Khan, 和 Abhinav Sethy。2023. 整合摘要和检索以通过大型语言模型增强个性化。arXiv预印本 arXiv:2310.20081 (2023)。
-
- [102] Stephen Robertson, Hugo Zaragoza, 等人。2009. 概率相关性框架:BM25及其超越。信息检索基础与趋势 3, 4 (2009), 333–389。
-
- [103] Alireza Salemi, Surya Kallumadi, 和 Hamed Zamani。2024. 个性化大型语言模型的优化方法通过检索增强。在第47届国际ACM SIGIR信息检索研究与发展会议论文集。752–762。
-
- [104] Alireza Salemi, Cheng Li, Mingyang Zhang, Qiaozhu Mei, Weize Kong, Tao Chen, Zhuowan Li, Michael Bendersky, 和 Hamed Zamani。2025. 增强推理的自训练用于长篇个性化文本生成。arXiv预印本 arXiv:2501.04167 (2025)。
-
- [105] Alireza Salemi, Sheshera Mysore, Michael Bendersky, 和 Hamed Zamani。2024. LaMP:当大型语言模型遇到个性化。在第62届年度计算语言学协会会议论文集(第一卷:长篇论文)。7370–7392。
-
- [106] Alireza Salemi 和 Hamed Zamani。2024. 学习为多个检索增强模型进行迭代效用最大化的排名。arXiv预印本 arXiv:2410.09942 (2024)。
-
- [107] Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, 和 Tatsunori Hashimoto。2023. 语言模型反映了谁的意见?在国际机器学习会议。PMLR, 29971–30004。
-
- [108] Rossano Schifanella, Alain Barrat, Ciro Cattuto, Benjamin Markines, 和 Filippo Menczer。2010. 民俗标签系统中的“人们”:通过共享元数据预测社会链接。在第三届ACM国际Web搜索和数据挖掘会议论文集。271–280。
-
- [109] Noor Shaker, Georgios Yannakakis, 和 Julian Togelius。2010. 面向平台游戏的自动个性化内容生成。在AAAI人工智能与交互式数字娱乐会议论文集,第6卷。63–68。
-
- [110] 邵云凡,李琳阳,戴俊琦,和邱锡鹏。2023. Character-LLM:一个可训练的角色扮演代理。arXiv预印本 arXiv:2310.10158 (2023)。
-
- [111] Jocelyn Shen, Joel Mire, Hae Won Park, Cynthia Breazeal, 和 Maarten Sap。2024. HEART-felt叙事:使用LLM追踪个人故事中的同理心和叙事风格。arXiv预印本 arXiv:2405.17633 (2024)。
-
- [112] Shi Yunxiao, Zi Xing, Shi Zijing, Zhang Haimin, Wu Qiang, 和 Xu Min。2024. ERAGent:通过提高准确性、效率和个性化增强检索增强型语言模型。arXiv预印本 arXiv:2405.06683 (2024)。
-
- [113] Aditi Singh, Ehtesham Abul, Kumar Saket, 和 Khoei Tala Talaei。2025. 代理检索增强生成:关于代理RAG的综述。arXiv预印本 arXiv:2501.09136 (2025)。
-
- [114] Harmanpreet Singh, Verma Nikhil, Wang Yixiao, Bharadwaj Manasa, Fashandi Homa, Ferreira Kevin, 和 Lee Chul。2024. 个性化大语言模型代理:定制化旅行规划案例研究。在2024年经验方法在自然语言处理会议行业轨道论文集。486–514。
-
- [115] Siriwardhana Shamane, Weerasekera Rivindu, Wen Elliott, Kaluarachchi Tharindu, Rana Rajib, 和 Nanayakkara Suranga。2023. 改善开放领域问答中检索增强生成(RAG)模型的领域适应性。计算语言学协会交易 11 (2023), 1–17。
-
- [116] Song Mingyang 和 Zheng Mao。2024. 大型语言模型查询优化综述。arXiv预印本 arXiv:2412.17558 (2024)。
-
[117] Spotify。2023. Annoy:C++/Python中的近似最近邻。https://github.com/spotify/annoy
-
- [118] Stuck_In_the_Matrix。2015. Reddit公共评论(2007-10至2015-05)。(2015)。https://www.reddit.com/r/datasets/comments/3bxlg7/i_ [have_every_publicly_available_reddit_comment/- [119] Sun Lei, Zhao Jinming, 和 Jin Qin。2024. 揭示人格特质:一个新的对话中可解释人格识别基准数据集。arXiv预印本 arXiv:2409.19723 (2024)。
-
- [120] Tan Zhaoxuan, Liu Zheyuan, 和 Jiang Meng。2024. 个性化碎片:通过协作努力实现高效的个性化大语言模型。arXiv预印本 arXiv:2406.10471 (2024)。
-
- [121] Tan Zhaoxuan, Zeng Qingkai, Tian Yijun, Liu Zheyuan, Yin Bing, 和 Jiang Meng。2024. 通过个性化的参数高效微调实现大众化大语言模型。arXiv预印本 arXiv:2402.04401 (2024)。
-
- [122] Tan Zhaoxuan, Zeng Qingkai, Tian Yijun, Liu Zheyuan, Yin Bing, 和 Jiang Meng。2025. 通过个性化的参数高效微调实现大众化大语言模型。arXiv:2402.04401 [cs.CL] https://arxiv.org/abs/2402.04401
-
- [123] Tu Quan, Fan Shilong, Tian Zihang, 和 Yan Rui。2024. Charactereval:一个中文角色扮演对话代理评估基准。arXiv预印本 arXiv:2401.01275 (2024)。
-
- [124] Cornell University。[n. d.]。arXiv:开放获取存储库。https://arxiv.org/
-
- [125] Vemuri Hemanth, Agrawal Sheshansh, Mittal Shivam, Saini Deepak, Soni Akshay, Sambasivan Abhinav V, Lu Wenhao, Wang Yajun, Parsana Mehul, Kar Purushottam, 等人。2023. 百万级项目的个性化检索。在第46届国际ACM SIGIR信息检索研究与发展会议论文集。1014–1022。
-
- [126] Bryan Wang, Gang Li, 和 Yang Li。2023. 使用大语言模型实现移动UI的对话交互。在2023年人机交互系统CHI会议论文集。1–17。
-
- [127] Wang Guanzhi, Xie Yuqi, Jiang Yunfan, Mandlekar Ajay, Xiao Chaowei, Zhu Yuke, Fan Linxi, 和 Anandkumar Anima。2023. Voyager:一个带有大语言模型的开放式具身代理。arXiv预印本 arXiv:2305.16291 (2023)。
-
- [128] Wang Hongru, Huang Wenyu, Deng Yang, Wang Rui, Wang Zezhong, Wang Yufei, Mi Fei, Pan Jeff Z, 和 Wong Kam-Fai。2024. UniMS-RAG:统一多源检索增强生成用于个性化对话系统。arXiv预印本 arXiv:2401.13256 (2024)。
-
- [129] Wang Hongru, Wang Rui, Mi Fei, Deng Yang, Wang Zezhong, Liang Bin, Xu Ruifeng, 和 Wong Kam-Fai。2023. Cue-CoT:使用链式思维提示应对深度对话问题的LLM响应。arXiv预印本 arXiv:2305.11792 (2023)。
-
- [130] Wang Jian, Cheng Yi, Lin Dongding, Leong Chak Tou, 和 Li Wenjie。2023. 目标导向的个性化主动对话系统:问题公式化和数据集整理。arXiv预印本 arXiv:2310.07397 (2023)。
-
- [131] Lei Wang, Ma Chen, Feng Xueyang, Zhang Zeyu, Yang Hao, Zhang Jingsen, Chen Zhiyuan, Tang Jiakai, Chen Xu, Lin Yankai, 等人。2024. 大型语言模型基础自主代理综述。计算机科学前沿 18, 6 (2024), 186345。
-
- [132] Liang Wang, Yang Nan, 和 Wei Furu。2023. Query2doc:使用大型语言模型进行查询扩展。arXiv预印本 arXiv:2303.07678 (2023)。
-
- [133] Lei Wang, Zhang Jingsen, Yang Hao, Chen Zhiyuan, Tang Jiakai, Zhang Zeyu, Chen Xu, Lin Yankai, Song Ruihua, Zhao Wayne Xin, 等人。2023. 使用基于大语言模型的代理进行用户行为模拟。arXiv预印本 arXiv:2306.02552 (2023)。
-
- [134] Wang Xintao, Xiao Yunze, Huang Jen-tse, Yuan Siyu, Xu Rui, Zhou Wangchunshu, Fei Yaying, Leng Ziang, Wang Wei, 等人。2023. Incharacter:通过心理访谈评估角色扮演代理的性格保真度。arXiv预印本 arXiv:2310.17976 (2023)。
-
- [135] Wang Yixiao, Fashandi Homa, 和 Ferreira Kevin。2024. 研究量化角色扮演对话代理的性格一致性。在2024年经验方法在自然语言处理会议行业轨道论文集。239–255。
-
- [136] Wang Yu, Gao Yifan, Chen Xiusi, Jiang Haoming, Yang Jingfeng, Yin Qingyu, Li Zheng, Li Xian, Yin Bing, 等人。[n. d.] MEMORYLLM:迈向自我更新的大语言模型。在第四十一届国际机器学习会议上。
-
- [137] Wang Zheng, Li Zhongyang, Jiang Zeren, Tu Dandan, 和 Shi Wei。2024. 通过可编辑记忆图上的检索增强生成构建个性化代理。在2024年经验方法在自然语言处理会议论文集。4891–4906。
-
- [138] Wang Zijie J 和 Chau Duen Horng。2024. MeMemo:设备端检索增强用于私密和个性化的文本生成。在第47届国际ACM SIGIR信息检索研究与发展会议论文集。2765–2770。
-
- [139] Wang Zekun Moore, Peng Zhongyuan, Que Haoran, Liu Jiaheng, Zhou Wangchunshu, Wu Yuhan, Guo Hongcheng, Gan Ruitong, Ni Zehao, Yang Jian, 等人。2023. RoleLLM:基准测试、激发和增强大型语言模型的角色扮演能力。arXiv预印本 arXiv:2310.00746 (2023)。
-
- [140] Wei Tianxin, Jin Bowen, Li Ruirui, Zeng Hansi, Wang Zhengyang, Sun Jianhui, Yin Qingyu, Lu Hanqing, Wang Suhang, He Jingrui, 等人。2024. 向统一多模态个性化迈进:用于生成推荐及其他任务的大视觉-语言模型。arXiv预印本 arXiv:2403.10667 (2024)。
-
- [141] Robert Wetzker, Zimmermann Carsten, 和 Bauckhage Christian。2008. 分析社交书签系统:del.icio.us烹饪书。在ECAI 2008 Mining Social Data研讨会论文集。26–30。
-
- [142] Stanisław Woźniak, Bartłomiej Koptyra, Arkadiusz Janz, Kazienko Przemysław, 和 Kocoń Jan。2024. 个性化大语言模型。arXiv预印本 arXiv:2402.09269 (2024)。
-
- [143] Wu Junde, Zhu Jiayuan, Qi Yunli, Chen Jingkun, Xu Min, Menolascina Filippo, 和 Grau Vicente。2024. 医疗图RAG:通过图检索增强生成实现安全医疗大语言模型。arXiv预印本 arXiv:2408.04187 (2024)。
-
- [144] Wu Xuan, Zhou Dong, Xu Yu, 和 Lawless Séamus。2017. 利用多关系社交数据的个性化查询扩展。在2017年第12届语义和社会媒体适配及个性化国际研讨会(SMAP)论文集。IEEE, 65–70。
会议缩写 'XX, June 03–05, 2018, Woodstock, NY X. Li 和 P. Jia 等人。
- [144] Wu Xuan, Zhou Dong, Xu Yu, 和 Lawless Séamus。2017. 利用多关系社交数据的个性化查询扩展。在2017年第12届语义和社会媒体适配及个性化国际研讨会(SMAP)论文集。IEEE, 65–70。
-
[145] Xi Yunjia, Liu Weiwen, Lin Jianghao, Cai Xiaoling, Zhu Hong, Zhu Jieming, Chen Bo, Tang Ruiming, Zhang Weinan, 和 Yu Yong。2024. 来自大语言模型的知识增强以实现开放世界推荐。在第18届ACM推荐系统会议论文集。12–22。
-
- [146] Xi Zhiheng, Chen Wenxiang, Guo Xin, He Wei, Ding Yiwen, Hong Boyang, Zhang Ming, Wang Junzhe, Jin Senjie, Zhou Enyu, 等人。2025. 大语言模型基础代理的兴起和潜力:综述。中国科学信息科学 68, 2 (2025), 121101。
-
- [147] Xiao Shitao, Liu Zheng, Zhang Peitian, Muennighoff Niklas, Lian Defu, 和 Nie Jian-Yun。2024. C-PACK:通用中文嵌入的打包资源。在第47届国际ACM SIGIR信息检索研究与发展会议论文集。641–649。
-
- [148] Xu Huatao, Han Liying, Yang Qirui, Li Mo, 和 Srivastava Mani。2024. Penetrative AI:使LLMs理解物理世界。在第25届国际移动计算系统和应用研讨会论文集。1–7。
-
- [149] Xu Hongyan, Liu Hongtao, Jiao Pengfei, 和 Wang Wenjun。2021. 变换推理网络用于个性化评论摘要。在第44届国际ACM SIGIR信息检索研究与发展会议论文集。1452–1461。
-
- [150] Xu Xinchao, Gou Zhibin, Wu Wenquan, Niu Zheng-Yu, Wu Hua, Wang Haifeng, 和 Wang Shihang。2022. 很久不见!具有长期人物记忆的开放域对话。arXiv预印本 arXiv:2203.05797 (2022)。
-
- [151] Xu Yiyan, Zhang Jinghao, Salemi Alireza, Hu Xinting, Wang Wenjie, Feng Fuli, Zamani Hamed, He Xiangnan, 和 Chua Tat-Seng。2025. 大模型时代的个性化生成:综述。arXiv预印本 arXiv:2503.02614 (2025)。
-
- [152] Yu Hao, Yang Xin, Chen Xiusi, Kang Yan, Wang Yu, Zhang Junbo, 和 Li Tianrui。2024. 通过多粒度提示实现个性化联邦持续学习。在第30届ACM SIGKDD知识发现与数据挖掘会议论文集。4023–4034。
-
- [153] Yu Xiaoyan, Luo Tongxu, Wei Yifan, Lei Fangyu, Huang Yiming, Peng Hao, 和 Zhu Liehuang。2024. Neeko:利用动态LoRA实现高效多角色扮演代理。arXiv预印本 arXiv:2402.13717 (2024)。
-
- [154] Yuan Xinfeng, Yuan Siyu, Cui Yuhan, Lin Tianhe, Wang Xintao, Xu Rui, Chen Jiangjie, 和 Yang Deqing。2024. 通过虚构作品中的人物画像评估大语言模型对人物的理解能力。arXiv预印本 arXiv:2404.12726 (2024)。
-
- [155] Zeng Hansi, Kallumadi Surya, Alibadi Zaid, Nogueira Rodrigo, 和 Zamani Hamed。2023. 统一信息访问的个性化密集检索框架。在第46届国际ACM SIGIR信息检索研究与发展会议论文集。121–130。
-
- [156] Zerhoudi Saber 和 Granitzer Michael。2024. PersonaRAG:通过用户中心代理增强检索增强生成系统。arXiv预印本 arXiv:2407.09394 (2024)。
-
- [157] Zhang Han, Wang Songlin, Zhang Kang, Tang Zhiling, Jiang Yunjiang, Xiao Yun, Yan Weipeng, 和 Yang Wen-Yun。2020. 面向个性化和语义检索的电子商务搜索端到端解决方案:通过嵌入学习实现。在第43届国际ACM SIGIR信息检索研究与发展会议论文集。2407–2416。
-
- [158] Zhang Jiarui。2024. 指导配置文件生成改善LLMs的个性化。arXiv预印本 arXiv:2409.13093 (2024)。
-
- [159] Jesse Zhang, Zhang Jiahui, Pertsch Karl, Liu Ziyi, Ren Xiang, Chang Minsuk, Sun Shao-Hua, 和 Lim Joseph J。[n. d.] Bootstrap Your Own Skills:通过大语言模型指导学习新任务。在第七届年度机器人学习会议。
-
- [160] Zhang Kai, Kang Yangyang, Zhao Fubang, 和 Liu Xiaozhong。2023. 基于大语言模型的医疗助手个性化:协调短期和长期记忆。arXiv预印本 arXiv:2309.11696 (2023)。
-
- [161] Zhang Kaiyan, Wang Jianyu, Hua Ermo, Qi Biqing, Ding Ning, 和 Zhou Bowen。2024. CoGenesis:大小语言模型协作框架以实现安全情境感知指令跟随。arXiv预印本 arXiv:2403.03129 (2024)。
-
- [162] Zhang Kai, Zhao Fubang, Kang Yangyang, 和 Liu Xiaozhong。2023. 带有短期和长期记忆协调的记忆增强LLM个性化。arXiv预印本 arXiv:2309.11696 (2023)。
-
- [163] Zhang Wenlin, Wu Chuhan, Li Xiangyang, Wang Yuhao, Dong Kuicai, Wang Yichao, Dai Xinyi, Zhao Xiangyu, Guo Huifeng, 和 Tang Ruiming。2025. LLMTreeRec:释放大语言模型在冷启动推荐中的潜力。在第31届国际计算语言学会议论文集。886–896。
-
- [164] Zhang Yanyue, Xu Zhibin, Wu Wenquan, Zhang Jinghao, 和 Zhou Wen-Yun。2025. 与用户排练:基于大语言模型的角色扮演个性化意见摘要。arXiv预印本 arXiv:2503.00449 (2025)。
-
- [165] Zhang You, Wang Jin, Yu Liang-Chih, Xu Dan, 和 Zhang Xuejie。2024. 面向人类中心文本理解的个性化LoRA。在AAAI人工智能会议论文集,第38卷。19588–19596。
-
- [166] Zhang Yabin, Yu Wenhui, Zhang Erhan, Chen Xu, Hu Lantao, Jiang Peng, 和 Gai Kun。2024. RecGPT:通过ChatGPT训练范式生成个性化提示以实现顺序推荐。arXiv预印本 arXiv:2404.08675 (2024)。
-
- [167] Zhang Zeyu, Bo Xiaohe, Ma Chen, Li Rui, Chen Xu, Dai Quanyu, Zhu Jieming, Dong Zhenhua, 和 Wen Ji-Rong。2024. 基于大语言模型代理的记忆机制综述。arXiv预印本 arXiv:2404.13501 (2024)。
-
- [168] Zhang Zhehao, Rossi Ryan A, Kveton Branislav, Shao Yijia, Yang Diyi, Zamani Hamed, Dernoncourt Franck, Barrow Joe, Yu Tong, Kim Sungchul, 等人。2024. 大语言模型的个性化:综述。arXiv预印本 arXiv:2411.00027 (2024)。
-
- [169] Zheng Yi, Ma Chongyang, Shi Kanle, 和 Huang Haibin。2023. 代理人遇到OKR:具有分层自我协作和自我评估的对象和关键结果驱动代理系统。arXiv预印本 arXiv:2311.16542 (2023)。
-
- [170] Zhong Hanxun, Dou Zhicheng, Zhu Yutao, Xu Hongjin, 和 Wen Ji-Rong。2022. 少即是多:学习精炼对话历史以实现个性化对话生成。arXiv预印本 arXiv:2204.08128 (2022)。
-
- [171] Zhong Wanjun, Tang Duyu, Wang Jiahai, Yin Jian, 和 Duan Nan。2021. UserAdapter:情感分析中的少量样本用户学习。在计算语言学协会会议:ACL-IJCNLP 2021的发现。1484–1488。
- [171] Zhong Wanjun, Tang Duyu, Wang Jiahai, Yin Jian, 和 Duan Nan。2021. UserAdapter:情感分析中的少量样本用户学习。在计算语言学协会会议:ACL-IJCNLP 2021的发现。1484–1488。
-
[172] Zhou Dong, Lawless Séamus, 和 Wade Vincent。2012. 通过社交媒体的个性化查询扩展改进搜索。信息检索 15 (2012), 218–242。
-
- [173] Zhou Denny, Schärli Nathanael, Hou Le, Wei Jason, Scales Nathan, Wang Xuezhi, Schuurmans Dale, Cui Claire, Bousquet Olivier, 和 Le Quoc等人。2022. 最少到最多提示使大型语言模型能够进行复杂推理。arXiv预印本 arXiv:2205.10625 (2022)。
-
- [174] Zhou Yujia, Zhu Qiannan, Jin Jiajie, 和 Dou Zhicheng。2024. 认知个性化搜索整合大型语言模型与高效内存机制。在2024年ACM Web会议论文集。1464–1473。
-
- [175] Zhuang Yuchen, Sun Haotian, Yu Yue, Qiang Rushi, Wang Qifan, Zhang Chao, 和 Dai Bo。[n. d.] Hydra:黑盒LLM个性化模型分解框架,2024。URL https://arxiv. org/abs/2406.02888 ([n. d.])。
2007年2月20日收到;2009年3月12日修订;2009年6月5日接受
- [175] Zhuang Yuchen, Sun Haotian, Yu Yue, Qiang Rushi, Wang Qifan, Zhang Chao, 和 Dai Bo。[n. d.] Hydra:黑盒LLM个性化模型分解框架,2024。URL https://arxiv. org/abs/2406.02888 ([n. d.])。
参考 Paper:https://arxiv.org/pdf/2504.10147.tar.gz



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











