






Subbarao Kambhampati, Kaya Stechly & Karthik Valmeekam
计算与增强智能学院
亚利桑那州立大学
电子邮件: {rao, kstechl, kvalmeek}@asu.edu
本文的一个版本发表于《纽约科学院年鉴》:https://nyaspubs.onlinelibrary.wiley.com/doi/10.1111/nyas.15339
摘要
我们将提供对最近出现的大型推理模型(LRMs)如OpenAI ol和DeepSeek R1的广泛统一视角,包括它们的潜力、力量来源、误解和局限性。
大型语言模型(LLMs),这些模型通过自回归训练基于人类的数字足迹生成连贯的文本响应,已展现出应对各种提示的能力。尽管它们表现出令人印象深刻的系统1能力,并擅长模仿适当风格的完成任务,但系统2能力如事实性、推理和规划仍然难以捉摸,甚至可以说是其阿喀琉斯之踵 4 { }^{4} 4。
对此,研究人员开发了一种新型模型——有时被称为大型推理模型(LRMs)——这些模型基于标准LLM架构和训练方法构建。其中最著名的有OpenAI的ol和DeepSeek的R1,它们在推理和规划任务上的表现显著优于旧版LLM的能力范围。
这些模型的构建得益于两大类广泛但相对正交的思想:(i) 测试时推理扩展技术,涉及让LLMs做更多工作,而不仅仅是提供最可能的直接答案;以及(ii) 后训练方法,补充简单的基于网络语料库的自回归训练,使用包含中间标记的数据进行额外训练。(在本文中,我们将使用“推导轨迹”这一中性术语作为中间标记的替代,而不是更
流行的拟人化短语“思维链”和“推理轨迹”。
尽管这些思想正在推动基准测试中的性能飞跃,但对于它们何时以及为何有效尚无共识。利用可靠验证的测试时扩展方法可以理解,因为它们对输出施加了保证;但其他流行的方法仅通过经验得到证明,在某些领域有效而在其他领域无效。对于新后训练技术的成功,甚至存在更多困惑。正如我们将论证的那样,普遍存在的叙述——即通过训练LLMs生成所谓的“推理轨迹”来获得新的泛化能力——是值得怀疑的。
本文的目的是为这些方法提供一个广泛的统一视角,包括它们的潜力、力量来源、误解和局限性。
构建推理模型
测试时推理
并非所有问题都需要相同的精力或时间。两位数乘以两位数的加法问题只需三次一位数加法即可解决,而四位数乘以四位数的问题可能需要七次。有许多方法使用可扩展的在线计算来改进更快的初始猜测,包括有限深度的极小极大算法、实时A*搜索和动态规划,以及蒙特卡洛树搜索
13
{ }^{13}
13。测试时推理方法(见图1)反映了这些思想并受到启发。
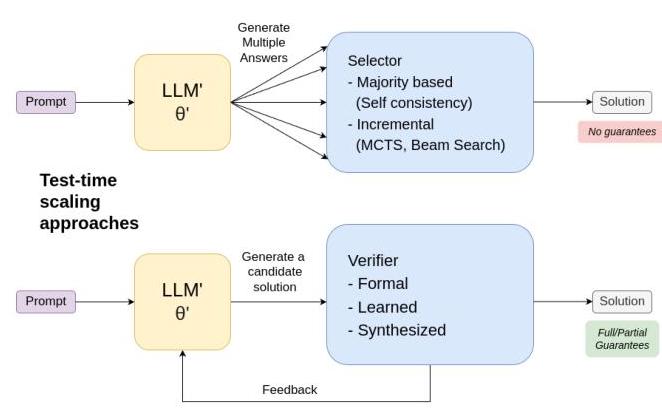
图1. 测试时扩展方法用于提取推理
通过拟人化的观察发现,人们在某些问题上花更多时间思考时似乎表现更好。
或许最流行且持久的一类测试时推理思想是生成许多候选解决方案,并使用某种选择程序来确定最终输出。最简单的实现被称为自我一致性 19 { }^{19} 19:选择最常见的答案。总花费时间与生成的解决方案数量成正比,但这种方法无法提供理论保证,即其答案将更加正确。
更复杂的筛选程序试图验证LLM的输出是否正确。当与LLM配对时,这种组合系统可以被视为一种生成-测试框架,并自然引发关于验证过程的问题:谁来进行验证,以及有何保证?已经尝试了多种方法,包括使用LLM本身作为验证者 20 { }^{20} 20(尽管这已知存在问题 16 { }^{16} 16)、学习验证器 1 , 22 { }^{1,22} 1,22,以及使用带部分或完全保证的外部可靠验证器。在验证器提供解释或反馈的情况下,这些信息可以传递回LLM,使其生成更好的后续猜测。我们的LLM-Modulo框架 5 , 4 { }^{5,4} 5,4提供了对这些基于验证的方法及其保证的全面概述。
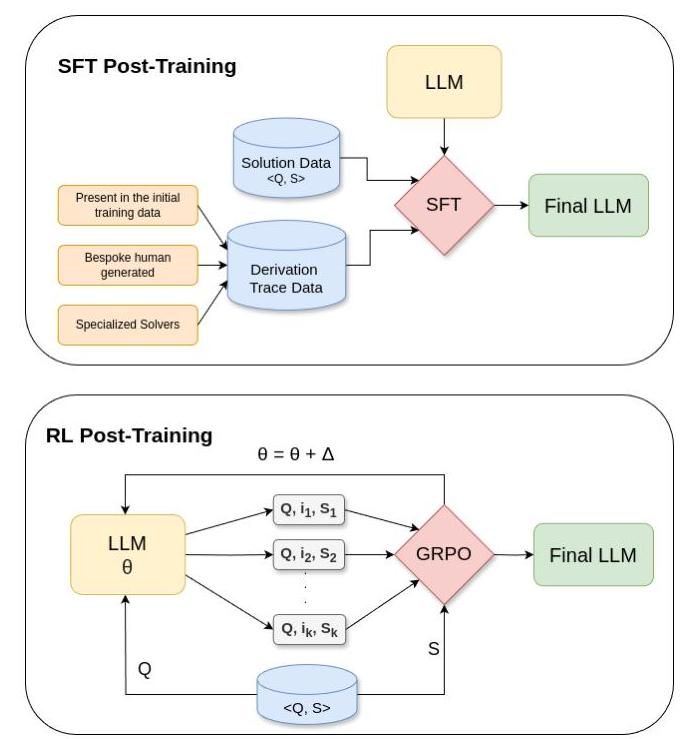
图2. 后训练方法用于提取推理
后训练推导轨迹
LLMs使用非常简单的训练目标:给定一段文本,预测最有可能的下一个标记。当这种方法应用于具有足够高容量的模型和大规模网络语料库时,已成功诱导出捕捉多种文本风格的能力。它们操作的语言媒介和所吸收的大量多样化数据,使得将其应用于几乎任何领域成为可能,包括推理和规划。然而,尽管在规模达到千兆字节的语料库上准确模仿可能足以理论上完成这些任务,标准LLMs尚未实现。它们的补全结果通常看起来合理,但实际上经常错误 4 ^{4} 4,似乎依赖于统计特征和风格特点,而非稳健的过程,即使在这种情况下失败也是如此。
当今研究的一个驱动力在于,这在一定程度上是因为训练数据不完整。LLMs吸收了互联网上的每一篇文章、帖子和书籍,但却没有获取到这些内容背后的生成过程——无论是内部口头表达、草稿大纲还是被丢弃的手写初稿。也许,如果能包含更多的这些推导轨迹,这将有助于LLMs重现相同的过程。
虽然前景光明,但如何以足够的规模获取这类数据远非显而易见。几乎没有大规模的通用推导轨迹集合。不仅让人们产生详细逐步骤表示自己的思维过程负担沉重,而且他们很可能根本无法直接明确地接触到这些过程。即使在能够做到的情况下,他们也可能故意抹去痕迹。正如高斯在被要求给出他证明的逐步直觉时所言:没有哪位自尊的建筑师会在建筑完成后留下支撑结构!
尽管如此,各种方法试图弥补这一不足,从支付标注人员进行逐步骤推导到使用LLMs生成和选择这些推导。我们根据(i) 候选轨迹的生成和过滤方式,以及(ii) 如何利用这些轨迹改进基础LLM对其进行分类;见图2。
在深入细节之前,我们应该指出,这种基于内部思维的人类动机与实际LLM操作之间的差距非常明显。实践中使用的“推导轨迹”往往与稳健的推理过程没有系统关系,尽管它们确实导致了经验性能的提升。我们稍后会回到这一点。
生成候选推导轨迹:一种明显的方式是让人类创建额外的推导数据。OpenAI聘请承包商撰写小学数学问题及逐步解决方案以创建GSM8k 10 { }^{10} 10。尽管公司继续获取此类数据,但这样做成本极高,尤其是在大规模模型训练所需的数据量上。
一种更具可扩展性的方法是使用形式化解算器自动生成解决方案和基于解算器特定中间表示的推理依据。Searchformer
8
{ }^{8}
8 和 Stream of Search
3
{ }^{3}
3 使用标准搜索算法生成不仅包含答案还包含执行轨迹的数据集。例如,使用A*搜索解决问题时,SearchFormer的数据生成流程将提供每次操作开放列表和关闭列表的表示作为推导轨迹。不幸的是,领域专用解算器
无法用于生成任意问题的轨迹,限制了该技术的通用性。
与其从一开始就生成高质量轨迹,一种日益流行的方法是从LLM生成轨迹并随后筛选。这是可行的,因为现代LLMs经过预训练的数据中已经包含了一些推导轨迹(例如教育网页、小学数学解释及其他试图展示其工作过程的来源) 7 { }^{7} 7,并且可以通过简单地在提示中附加“让我们一步一步思考”来可靠地诱导输出符合这些风格的内容 6 { }^{6} 6。
筛选轨迹:这些轨迹通常在筛选前并不实用,一些被舍弃,另一些被保留。研究人员在处理此轨迹选择过程方面各不相同,从仅选择每一步都正确的轨迹(由人工标注者判断),到训练过程奖励模型以尝试自动化人工验证 10 { }^{10} 10,再到通过正式验证是否导致正确最终解决方案来选择轨迹而不考虑轨迹内容 21 , 2 { }^{21,2} 21,2。
使用推导轨迹改进LLMs:一旦选择了推导轨迹,就可以进一步训练LLM。希望是,通过输出有用的中间标记,LLM将在更广泛的问题上更有可能输出正确解决方案。早期方法直接在这些轨迹上微调LLMs 21 , 8 , 3 { }^{21,8,3} 21,8,3,但最近的进展转向使用强化学习(RL)。
最早成功且广为人知的以此方式训练的模型是DeepSeek的R1-Zero和R1模型 2 { }^{2} 2。在完成正常的LLM预训练后,它们开始在一个新数据集上的RL后训练阶段——这个数据集包含可以自动验证答案的问题。在此阶段,LLM为每个问题生成多个可能的补全;这些补全以轨迹的形式呈现,最终答案单独标记,并根据最终答案的正确性进行评分。最佳补全获得奖励,调整模型使其更可能输出这些补全,
${ }^{7}$ 还有一种推测认为,链式思维提示技术的流行导致了在构成大部分预训练数据的大规模网络爬虫中,出现了更多样化的逐步轨迹数据。
而不是那些未导致正确最终答案的补全。本质上,这种RL过程将LLM视为一种标记选择策略,并使用策略梯度算法迭代改进其参数。${ }^{5}$
概念上,这种RL阶段可以看作是一个重复多次的两步过程:首先,从LLM生成潜在轨迹,并使用自动计算的成功标准对其加权;其次,选择性地在LLM自身的输出上进行微调。这种重新定义清楚地表明,纯微调和RL方法并没有最初假设的那么不同。
值得注意的是,无论使用SFT还是RL修改基础LLM的参数,最终模型的架构仍然与其他LLM相同。唯一的区别在于模型捕获的概率分布:倾向于输出模仿其训练轨迹的中间标记,然后是LLM对解决方案的猜测。
实际上,已有实证观察表明,在经过验证输出的第二个LLM上进行微调可以缩小性能差距,甚至在某些情况下可能导致一个超越原始模型的LLM。 5 { }^{5} 5 这些蒸馏方法引发了如此多的关注,以至于现在有了从DeepSeek的R1中提取的过滤轨迹的公共训练数据集,从而跳过了强化学习阶段的需要。
理解推理模型
我们概述了两种广泛但正交的方法——后训练和测试时扩展——这两种方法主要负责激发人们对LRMs规划和推理能力的兴趣。现在,澄清一些普遍存在的误解是有价值的。
LRMs有多好?
LRMs引起兴奋的原因之一是它们相比标准LLMs在推理性能上有明显的提高,
正如通过流行基准测量的那样。供应商,尤其是OpenAI和DeepSeek,通过在公告、解释博客文章和技术报告中突出这些指标的改进来营销他们的模型。
我们在PlanBench上的独立分析 18 , 17 { }^{18,17} 18,17,这是一个早期模型难以解决的简单规划问题测试集,证实了他们的一些结果。尽管新一代模型仍面临泛化失败的问题,但在这些问题上无疑是一大进步。图3提供了一些说明性的结果。o1和R1在我们的静态Blocksworld基准测试中达到饱和,并且——可以说更为令人印象深刻的是——是首批在我们的Mystery Blocksworld领域取得非平凡进展的模型。该领域的问题是Blocksworld问题的确切副本,只是对象和动作的名称被混淆。
尽管与旧版LLMs相比令人印象深刻,能够解决一些(而非全部!)最基本的Mystery问题的能力距离现实世界应用所需的稳健性和通用性仍有很长的路要走。此外,我们的扩展结果显示,即使是来自普通Blocks World的较大实例,仍然会让LRMs犯错,而且在面对不可解问题时,它们会出现严重的幻觉问题。在不可解问题的情况下,模型不仅自信地生成(不可能的)计划,还会试图提供详尽(显然虚假的)理由——冒着说服(甚至是误导?)天真用户信任它们的风险。
由于这些准确性问题,我们认为这些模型最好被视为比标准LLMs有更高密度正确解决方案猜测的更好生成器。事实上,在我们分析o1的工作中 17 { }^{17} 17,我们看到让它在LLM-Modulo框架中扮演标准LLM的角色可以进一步提高准确性,同时提供只有通过正式验证后才输出解决方案的保证。
LRMs是否具有成本效益?
与标准LLMs相比,LRMs在训练和推理阶段都涉及显著的额外成本,供应商将部分这些成本转嫁给最终用户。事实上,当OpenAI推出o1时,它开始对o1在推理过程中产生的中间标记收费,
${ }^{5}$ 这里的“状态”是上下文窗口;下一步行动只是策略发出的标记。参见 https://x.com/rao2z/status/1888699945232089262
${ }^{5}$ 参见 https://x.com/JJitsev/status/1886210147388711192
${ }^{8}$ 参见例如 Open Thoughts: https://github.com/openthoughts/open-thoughts
| 领域 | | 大型语言模型 | | | | | 大型推理模型 | | |
| :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: | :--: |
| | | Claude-3.5 <br> Sonnet | GPT-4b | GPT-4 | LLaMA-3.1 <br> 405B | $\begin{gathered} \text { Gemini } \\ 1.5 \text { Pro } \end{gathered}$ | o1-preview | o1-mini | Deepseek <br> R1 |
| Blocksworld | 零 <br> shot | $\begin{gathered} 329 / 600 \\ (54.8 \%) \end{gathered}$ | $\begin{gathered} 213 / 600 \\ (35.5 \%) \end{gathered}$ | $\begin{gathered} 210 / 600 \\ (34.6 \%) \end{gathered}$ | $\begin{gathered} 376 / 600 \\ (62.6 \%) \end{gathered}$ | $\begin{gathered} 143 / 600 \\ (23.8 \%) \end{gathered}$ | $\begin{gathered} 587 / 600 \\ (97.8 \%) \end{gathered}$ | $\begin{gathered} 340 / 600 \\ (56.6 \%) \end{gathered}$ | $\begin{gathered} 582 / 600 \\ (97 \%) \end{gathered}$ |
| Mystery <br> Blocksworld | 零 <br> shot | $\begin{gathered} 0 / 600 \\ (0 \%) \end{gathered}$ | $\begin{gathered} 0 / 600 \\ (0 \%) \end{gathered}$ | $\begin{gathered} 1 / 600 \\ (0.16 \%) \end{gathered}$ | $\begin{gathered} 5 / 600 \\ (0.8 \%) \end{gathered}$ | - | $\begin{gathered} 317 / 600 \\ (52.8 \%) \end{gathered}$ | $\begin{gathered} 115 / 600 \\ (19.1 \%) \end{gathered}$ | $\begin{gathered} 256 / 600 \\ (42.6 \%) \end{gathered}$ |
| 每100个实例的平均API成本 | - | $\$ 0.44$ | $\$ 0.65$ | $\$ 1.80$ | - | $\$ 0.33$ | $\$ 42.12$ | $\$ 3.69$ | $\$ 2.07$ |
图3. LLMs vs. LRMs on PlanBench
尽管最终用户从未看到这些标记!
虽然使用合成数据进行后训练的成本可能相当可观,但至少这些成本不会直接被最终用户看到。测试时推理成本的情况则完全不同。无论采用何种方法,所有版本的测试时推理都会带来成本膨胀的问题。对于标准LLM而言,生成补全所需的时间和金钱完全取决于该补全的长度,而对于这些系统,每个提示的成本可能无限高,即使在最好的情况下也与底层推理问题的计算复杂度成正比。因此,测试时推理技术打乱了当前LLM公司的商业模式,因为他们不能再预先加载模型成本(在训练期间)然后以低价出售补全。
过去,在比较LLMs和其他替代方案时,我们可以忽略训练成本,认为这些成本在整个模型生命周期内摊销。但现在我们必须考虑到这一新增加的成本来源。目前尚不清楚这在多大程度上会对LRMs相较于其他更专业或特定领域的系统(如经典求解器)有利。
LRMs与LLMs有何不同?
术语“大型语言模型”,最初是指参数数量和训练语料库的规模,但随着时间的推移,在常见用法中逐渐专指一类特定的大型语言模型:基于变压器架构构建的巨大神经网络,经过大规模文本语料库的预训练,然后通过一种称为基于人类反馈的强化学习(RLHF)的技术进行指令微调和用户对齐。鉴于LRMs围绕相同的底层神经架构组织,并使用这些技术的超集进行训练,这就引出了一个问题:为什么我们要将它们区分开来?相关的训练和架构变化是否足以将它们标记为一个新的模型类别?或者它们是否可以合法地被称为LLMs?
很明显,测试时推理技术从根本上改变了最终系统的性质。当标准LLM接收到一段文本时,它将以自回归方式输出对该文本的响应。 1 { }^{1} 1 这是LLMs核心概念和效用的重要组成部分:用户按下回车键后,答案就开始逐标记流式传输给他们。使用测试时推理技术的系统,特别是那些并行探索多种可能性的系统,并不具备这一重要能力,可能只能在处理早期标记的最后阶段才开始输出最终答案——响应中的早期标记可能只在执行的后期阶段才能确定。
那么,仅因后训练于推导轨迹而与基础模型不同的LRMs(例如R1)呢?我们已经注意到,改变训练程序并不会改变模型在推理阶段的基本性质——它仍然会接收提示并输出补全。改变的是哪些
${ }^{1}$ 即,网络将进行一次前向传播并输出单个标记。然后模型将自动递归地重新提示增强后的片段,这一前向传播和重新提示的过程将继续循环,直到遇到字符串结束标记。
补全模型更有可能输出。R1 是一个很好的例子,它被训练为以非常特定的格式响应所有查询:首先是一系列中间“推理”标记,然后是标记过渡的保留文本,最后是一系列“答案”标记。尽管当我们解读这种分段时,它让人联想到人类先思考再说话的过程,但在推理时它并不携带任何特殊的执行级语义——每个标记的生成方式与标准LLM完全相同。
与测试时扩展不同,这里没有问题依赖的自适应计算。虽然这些模型在实践中确实产生长度可变的中间标记序列,但我们认为将其视为一种新颖的测试时扩展范式是奇怪的——这是所有先前LLMs的特性!即使是ChatGPT的最初发布,也会根据不同的查询响应不同数量的标记,而通过适当的提示,许多这些长度差异很容易被解释为先生成草稿再得出最终答案。
我们之前曾论点,LLMs主要由其预训练数据定义,应被视为进行“近似检索”4。特别是在仅在后训练方面有所不同的模型情况下,重要的是问:LRMs是否足够独立于其预训练数据的内容影响,从而超越近似检索?当然有一些证据表明,性能提升可能源于在基准任务上的大量预训练——无论是AIME还是数学奥林匹克竞赛——并且这种性能在面对简单的提示变化时可能很脆弱 11 { }^{11} 11,但结论尚待确定。
LRMs是在推理还是检索?
大多数文献记载的LRMs在推理问题上的进步都是针对那些传统人工智能和计算机科学中存在形式化验证器的任务。当前LRMs的运行模式是在测试时、训练时或蒸馏时利用这些验证器进行生成-测试循环,以部分编译验证信号进入生成。换句话说,后训练LRMs可以被视为逐步将推理编译为检索。这种迭代是必要的,因为对于可以任意扩展复杂性的推理问题(例如多数字多位
数乘法随着位数增加),一个在一定规模实例上训练的LLM很快就会失去在更大规模问题上提供良好猜测的能力
15
{ }^{15}
15。正如我们所见,后训练方法依赖于基础LLM具备足够高的top-k准确率(即,能够在给定k次猜测的情况下生成至少一个正确解决方案),以便验证器有所选择(否则,无论是微调还是RL阶段都没有信号!)
这一总体思路与马文·明斯基提出的格言一致:智能是将生成-测试中的测试部分转移到生成部分。特别地,在测试时使用验证器已经被LLM-Modulo框架提倡 5 { }^{5} 5。正如我们讨论的,LRM后训练方法关键依赖于验证器的信号,将基础LLM提供的轨迹分为那些到达正确解决方案的轨迹与那些没有到达的轨迹(因此,这可以被视为“训练时LLM-Modulo”)。一旦完成,这些轨迹被用来通过微调或RL细化基础LLM(“生成器”)。这部分可以解释为部分将验证器信号编译进生成器。最后,尽管Deepseek R1在推理阶段仅部署细化后的LLM,而不诉诸任何测试时验证,但在利用R1开发额外合成数据以蒸馏其他模型时,他们确实使用了验证器。
将这种训练时、测试时和蒸馏时的验证视为一种阶段性方法,将验证信号编译入基础LLM。特别是,正如我们讨论的,用于R1的基础LLM已经具备生成合理解决方案轨迹的能力(可能是由于预训练数据中已经存在的推导轨迹数据)。后训练可以被视为进一步完善它,以更少的尝试次数生成更准确的解决方案来解决更长/更难的问题。蒸馏可以被视为进一步传播这一过程。在每个阶段,验证信号都被编译入基础LLM,用于越来越长的“推理视界”。这种理解与关于链式思维的有效性研究 15 { }^{15} 15、游戏中的内部与外部规划方法的使用 14 { }^{14} 14、以及变压器的自我改进 7 { }^{7} 7一致。在最后一种情况下,我们会限定任何“自我改进”主张,认为这更多是将验证器信号逐步编译入基础LLM。
中间标记是否确实是LLM推理的痕迹?
正如我们讨论的,后训练可以诱导模型首先生成长串中间标记,然后再输出其最终答案。该领域中有一种趋势,将这些中间标记视为模型类似人类的“思维”或将其视为重述内部过程的推理痕迹。这是关于LRMs最具争议性的问题。
中间标记序列常常看似合理地类似于格式更好、拼写更正确的手稿——从“嗯…”、“啊哈!”、“等一下”到“有趣。”一路喃喃自语——但这并不能告诉我们它们是否被用于与人类使用它们相同的目的,更不用说它们是否可以用作了解LLM“思考”的可解释窗口。**毕竟,LLMs已经模仿了天下万物的风格,所以它们怎么会不模仿预训练数据中任何人类沉思的风格呢?(一个不友善的观察者甚至可能说我们从LLMs变成了LMMs——大型喃喃模型)。
这种拟人化持续不断的一个原因是很难证明或反驳这些生成痕迹的正确性。DeepSeek的R1,即使在非常小和简单的问题上,也会对每个查询产生超过30页的文本,而且远远不清楚如何检查这些独白是否构成合理的推理。 7 † { }^{7 \dagger} 7† 因此,很少有LRM评估甚至尝试检查其预答案痕迹,而是只关注评估其最终答案的正确性。
然而,虽然评估通用LRMs产生的中间标记可能超出直接触及范围,但我们可以通过
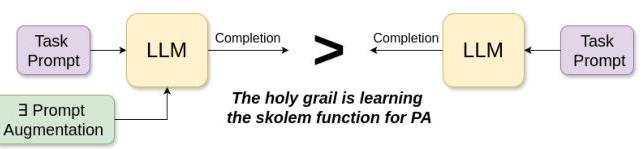
图4. 在任务提示中添加额外标记通常可以提高LLM完成的准确性,即使这些标记没有人类可解析的意义。
正式验证受格式约束模型生成的痕迹状态,这些模型被训练以模仿特定领域求解器的推导痕迹。我们的实验
12
{ }^{12}
12(在SearchFormer
8
{ }^{8}
8和Stream of Search
3
{ }^{3}
3模型上运行)显示,虽然这些痕迹形式正确,但很大一部分被原始生成算法判定为无效
88
{ }^{88}
88——尽管这些错误痕迹仍可能偶然得出正确答案!这一切都让人怀疑训练痕迹的正确性是否真的重要。
9
{ }^{9}
9
然而,许多这方面的研究毫不质疑地假设痕迹的正确性和可读性是必要的优化目标。即使DeepSeek尝试训练了一个仅RL模型(R1-Zero),最终发布的版本(R1)仍是通过额外的数据和过滤步骤专门训练的,以减少模型默认生成不可读中间标记序列的倾向——混杂语言、格式等。
鉴于这些痕迹可能没有任何语义意义,刻意让它们看起来更像人类是危险的,可能会利用用户的认知缺陷来说服他们相信错误答案的有效性。最终,LRMs应该提供用户不知道的解决方案(并且他们可能无法直接验证)。通过生成风格上看似合理的伪推理痕迹来培养虚假的信心和信任似乎是不明智的!
此外,如果目标是提高性能,人类可读性可能是反生产的
1
+
†
{ }^{+\dagger}
+† “推理痕迹”术语带来的另一个混淆是它混淆了LLM生成的未过滤中间标记——推导痕迹——与事后解释或对所述“思考”过程或结果的理性化。例如,o1通常提供一个简化的总结/理性化,而不是中间标记。众所周知,至少对人类而言,这种事后练习很少能揭示任何有意义的思考过程。
+
†
{ }^{+\dagger}
+† 在DeepSeek之前,整个问题毫无意义。OpenAI的o1模型故意向最终用户隐藏其中间标记,尽管收费是基于产生了多少标记!
总结
过去一年见证了“大型推理模型”(LRMs)的兴起,它们似乎在规划和推理问题上带来了显著改进,而这些问题正是LLMs以前苦苦挣扎的领域。我们调查了推动从LLMs的系统1能力转变为LRMs的系统1+2能力的两类广泛技术,并对一些流行的拟人化误解进行了批判性审视。尽管在基准测试中创造了新的准确率记录,但这些系统
仍然对提示的变化敏感,对自己断言过于自信,并且无法稳健泛化。我们认为,它们最适合在类似LLM-Modulo的混合框架中扮演更准确生成器的角色,该框架对外部保证其补全结果。
致谢
我们的研究部分得到了DARPA资助HR00112520016、ONR资助N0001423-12409以及Qualcomm的捐赠支持。我们要感谢整个Yochan团队的热情讨论,以及Vardhan Palod和Atharva Gundawar对推理痕迹的初步研究。
参考文献
[1] Daman Arora 和 Subbarao Kambhampati. 学习和利用验证器以提高预训练语言模型的规划能力。ICML Workshop on Knowledge and Logical Reasoning in the Era of Data-driven Learning, 2023.
[2] DeepSeek-AI. DeepSeek-R1: 通过强化学习激励LLMs的推理能力,2025.
[3] Kanishk Gandhi, Denise Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma 和 Noah D. Goodman. 搜索流(SoS):学习在语言中搜索。Conference on Language Modeling (COLM), 2024.
[4] Subbarao Kambhampati. 大型语言模型能否推理和规划?Annals of the New York Academy of Sciences, 1534(1):15-18, 2024.
[5] Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Paul Saldyt 和 Anil B Murthy. 观点:LLMs不能规划,但可以在LLM-Modulo框架中帮助规划。Forty-first International Conference on Machine Learning, 2024.
[6] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo 和 Yusuke Iwasawa. 大型语言模型是零样本推理者。Advances in neural information processing systems, 35:22199-22213, 2022.
${ }^{\text {® }}$ see https://x.com/rao2z/status/1865985285034553478
${ }^{* * *}$ 即,给定任务提示 $\mathrm{T}, \exists P A s . t . \operatorname{Pr}(\operatorname{Sol}(L L M(T+$ $P A), T))>\operatorname{Pr}(\operatorname{Sol}(L L M(T), T))$,其中 $P A$ 是某种适当的提示增强,$L L M(x)$ 是给定 $x$ 作为提示时LLM输出的补全,$\operatorname{Sol}(y, T)$ 使用验证器检查 $y$ 是否包含 $T$ 的解决方案。那么终极目标就是学习提示增强的斯科伦函数。
${ }^{\dagger \dagger \dagger}$ See https://x.com/rao2z/status/1834354533931385203
[7] Nayoung Lee, Ziyang Cai, Avi Schwarzschild, Kangwook Lee 和 Dimitris Papailiopoulos. 自我改进的Transformer克服了从易到难和长度泛化挑战,2025.
[8] Lucas Lehnert, Sainbayar Sukhbaatar, DiJia Su, Qinqing Zheng, Paul Mcvay, Michael Rabbat 和 Yuandong Tian. 超越A*:通过搜索动态引导Transformer进行更好的规划。Conference on Language Models (COLM), 2024.
[9] Dacheng Li, Shiyi Cao, Tyler Griggs, Shu Liu, Xiangxi Mo, Shishir G. Patil, Matei Zaharia, Joseph E. Gonzalez 和 Ion Stoica. LLMs可以轻松学会从演示结构中推理,不是内容,而是结构才是关键!2025.
[10] Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever 和 Karl Cobbe. 让我们一步步验证,2023.
[11] R. Thomas McCoy, Shunyu Yao, Dan Friedman, Mathew D. Hardy 和 Thomas L. Griffiths. 当语言模型被优化用于推理时,它是否仍然显示出自回归的残余?OpenAI o1分析,2024.
[12] Rimon Melamed, Lucas H. McCabe, Tanay Wakhare, Yejin Kim, H. Howie Huang 和 Enric Boix-Adsera. 提示有邪恶双胞胎。Proc. EMNLP, 2024.
[13] Stuart J Russell 和 Peter Norvig. 人工智能:现代方法。伦敦,2010.
[14] John Schultz, Jakub Adamek, Matej Jusup, Marc Lanctot, Michael Kaisers, Sarah Perrin, Daniel Hennes, Jeremy Shar, Cannada Lewis, Anian Ruoss, Tom Zahavy, Petar Veličković, Laurel Prince, Satinder Singh, Eric Malmi 和 Nenad Tomašev. 通过语言模型的外部和内部规划掌握棋盘游戏,2024.
[15] Kaya Stechly, Karthik Valmeekam 和 Subbarao Kambhampati. 无思维链条:对CoT在规划中的分析。Proc. NeurIPS, 2024.
[16] Kaya Stechly, Karthik Valmeekam 和 Subbarao Kambhampati. 关于大型语言模型在推理和规划任务上的自我验证局限性。Proc. ICLR, 2025.
[17] Karthik Valmeekam, Kaya Stechly, Atharva Gundawar 和 Subbarao Kambhampati. 在草莓田中规划:评估和改进LRM o1的规划和调度能力,2024. 版本将出现在Transcations on Machine Learning Research中。
[18] Karthik Valmeekam, Kaya Stechly 和 Subbarao Kambhampati. LLMs仍然无法规划;LRMs可以吗?对OpenAI的o1在PlanBench上的初步评估,2024.
[19] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery 和 Denny Zhou. 自我一致性提高了语言模型中链式思维推理的能力。The Eleventh International Conference on Learning Representations, 2023.
[20] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao 和 Karthik R Narasimhan. 思维树:用大型语言模型进行深思熟虑的问题解决。Thirty-seventh Conference on Neural Information Processing Systems, 2023.
[21] Eric Zelikman, Yuhuai Wu, Jesse Mu 和 Noah Goodman. STAR:通过推理引导推理。Advances in Neural Information Processing Systems, 35:15476-15488, 2022.
[22] Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar 和 Rishabh Agarwal. 生成验证器:将奖励建模为下一标记预测,2024.
[23] Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter 和 Matt Fredrikson. 对齐语言模型的通用和可转移对抗攻击,2023.
参考论文:https://arxiv.org/pdf/2504.09762
12 { }^{12} 12 https://x.com/rao2z/status/1891260345165263128
88 { }^{88} 88 举例说明:SearchFormer基于A*生成的推导痕迹进行训练。在测试时,模型的语义失败包括尝试从开放列表中删除实际上不在开放列表中的节点、向开放集合添加非邻节点、关闭已经关闭的节点,或者通过算法得出计划但输出无关的最终答案。更糟糕的是,这些问题并非源于泛化失败,因为测试问题与训练集的分布完全相同。
如果目标是提高性能的话。强化学习可以潜在地训练LLMs输出任何老式的中间标记序列——只要底线有所改善就行。实际上,我们相信 ® { }^{\text {® }} R◯ 中间标记的去拟人化始于承认大多数“链式思维”方法中的共同假设:即当提供适当的提示增强而不是仅仅基本任务提示时,LLM将生成更准确的补全(见图4)。那么大问题是如何获得正确的提示增强。***零样本和k样本链式思维提示,以及获取推导轨迹用于后训练的各种方法,都可以被视为回答这个问题的方式。值得研究其他方法,包括由第二个独立LLM提出和改进提示增强的方法。这个LLM可以使用任何标记词汇表,而不受听起来像人类喃喃自语的限制!(事实上,我们可以从这个角度来看待LLM对抗攻击的研究 23 , 12 { }^{23,12} 23,12,这些攻击生成通用标记字符串,迫使LLMs给出不理想的响应!)在这个框架下,可以使用AlphaZero和MuZero中使用的更强大的RL形式来学习专注于提高解决方案准确性的中间标记语言。讽刺的是,这原本是我们对o1工作原理的最初推测! † † † { }^{\dagger \dagger \dagger} ††† ↩︎



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











