






王成宇
1
{}^{1}
1, 张涛林
2
{}^{2}
2, 洪日昌
2
{}^{2}
2, 黄军
1
{}^{1}
1
1
{}^{1}
1 阿里云计算
2
{}^{2}
2 合肥工业大学计算机科学与信息工程学院 chengyu.wcy@alibaba-inc.com
摘要
最近,大型推理模型(LRMs)如DeepSeek-R1通过慢思考过程在推理能力方面取得了显著进展。尽管这些成就显著,但LRMs的巨大计算需求带来了相当大的挑战。相比之下,小型推理模型(SRMs),通常从较大的模型蒸馏而来,提供了更高的效率,并且可以展现出与LRMs不同的能力和认知轨迹。本文对近170篇关于SRMs解决各种复杂推理任务的最新论文进行了综述。我们回顾了当前SRMs的现状,并分析了与SRMs相关的多样化的训练和推理技术。此外,我们还提供了SRMs在特定领域应用的全面综述,并讨论了可能的未来研究方向。本综述为研究人员利用或开发高效高级推理功能的SRMs提供了重要参考。
1 引言
“在小事上忠诚,因为你的力量就在其中。” ——特蕾莎修女
最近,自然语言处理(NLP)已被大型语言模型(LLMs)(Zhao等人,2023年)广泛改变,这些模型在广泛的下游任务中表现出显著的能力。值得注意的是,大型推理模型(LRMs)(Xu等人,2025年),例如DeepSeekR1(DeepSeek-AI,2025年)和QwQ-32B 1 {}^{1} 1,专门用于通过使用慢思考过程解决推理问题(如数学问题、代码生成、逻辑推理等)。然而,这些模型的强大性能需要巨大的成本,无论是训练还是推理都需要大量的
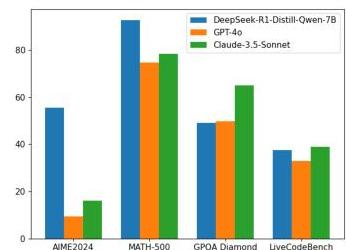
图1:代表性LLMs和SRMs在各种推理基准上的简单比较。
计算资源。例如,DeepSeek-R1模型包含671亿参数,并至少需要配备八块A100(80GB)GPU的服务器,或者更好的硬件配置来进行在线服务。
因此,研究界对利用更小的模型(Fu等人,2023b;Magister等人,2023;Shridhar等人,2023;Zhang等人,2025a)来解决复杂的推理任务越来越感兴趣,寻求更高效但仍有效的替代方案。随着DeepSeek-R1的发布,开源社区观察到许多成就,表明具备慢思考能力的小型推理模型(SRMs),即长链式思维过程(Wei等人,2022),可以在某些推理任务中超越更大的LLMs,如图1所示。 2 {}^{2} 2 然而,由于SRMs通常展现出与LRMs不同的能力和认知轨迹(Yan等人,2023;Zhang等人,2024a;Hu等人,2024b),这些模型的训练和推理方法可能存在根本性差异。因此,大量努力被投入到开发与LRMs相当甚至超越的强SRMs。我们观察到文献中有几项调查专注于LLMs的推理任务(Plaat等人,2024;Xu等人,2025;Huang
1
1
{ }^{1}
1 王成宇和张涛林对该工作贡献相同。联系人:C. Wang.
1
{ }^{1}
1 https://qwenlm.github.io/blog/ qwq-32b/
图2:本综述的路线图。
和Chang,2023;Giadikiaroglou等人,2024;Ahn等人,2024)。然而,专门针对SRMs的调查和评论仍然不足。
在本文中,我们提供了一个简短而全面的SRMs综述。通过回顾过去三年内发布的约170篇研究论文,我们的综述旨在整合关于SRMs的技术、应用和可能未来研究方向的知识。本综述的路线图如图2所示。
本综述涵盖哪些内容?我们首先快速浏览开源社区中的流行SRMs。接下来,我们探讨各种旨在增强预训练模型推理能力的训练和推理技术。此外,我们还调查基于这些模型的特定领域应用,讨论可能的未来研究方向并提出我们的建议。
本综述未涵盖哪些内容?本综述不涵盖LLMs整体的一般模型架构设计和算法,也不深入探讨与复杂推理任务无关的任务。此外,我们不探索压缩技术(如剪枝和量化)和大规模预训练技术以获得较小的模型,而是专注于特定的推理技术。
简而言之,SRMs的研究对于NLP社区来说是一个重要且及时的研究主题。通过接受SRMs的效率和能力,研究人员可以推动高绩效且适合实际应用的模型的发展。
2 快速浏览SRMs
继OpenAI发布o1 3 {}^{3} 3之后,AI社区见证了一场向开发具有强大推理能力模型的范式转变。
我们回顾了开源社区中流行的SRMs,这些SRMs作为非常有用的骨干网络,有助于研究人员进一步探索。
2.1 典型领域的SRMs
在OpenAI的o1之前,已经引入了特定任务的SRMs,特别是在代码完成和自然语言到代码转换等代码相关任务中,由于其广泛应用。最近,Qwen2.5-Coder系列(Hui等人,2024)包括从1.5B到32B不同规模的LRMs和SRMs。DeepSeek-Coder(Guo等人,2024)、StarCoder2(Lozhkov等人,2024)和OlympicCoder 4 {}^{4} 4 是其他显著系列,具有强大的代码相关任务推理能力。有关代码相关SRMs的更多信息,请参见Jiang等人(2024)。数学是另一个引人入胜的SRM领域,涉及复杂的推理步骤以解决数学问题。突出的开源系列包括Qwen2.5-Math(Yang等人,2024a)、DeepSeek-Math(Shao等人,2024)和InternLM-Math(Ying等人,2024)。对于其他领域(如医疗保健、科学、法律和金融)的SRMs,我们请读者参阅第5节以获取详细信息。
2.2 通用SRMs
随着像DeepSeek-R1和QwQ-32B这样强大的LRMs变得公开可用,并且其输出明确包含长CoT轨迹,通用SRMs也已发布,其中大多数是通过从LRMs进行知识蒸馏训练的。这些模型的一些例子包括由DeepSeek AI团队(DeepSeek-AI,2025)基于LLaMA和Qwen系列发布的蒸馏模型(如DeepSeek-R1-Distill-LLaMA-8B和DeepSeek-R1-Distill-Qwen-7B)、s1(Muennighoff等人,2025)、OpenThinker 5 {}^{5} 5、Bespoke-Stratos 6 {}^{6} 6、LLaMA-O1 7 {}^{7} 7、Marcoo1(Zhao等人,2024)以及许多其他模型。总之,SRMs的出现标志着该领域的一个重大进步。这些SRMs使研究人员能够在各种骨干网络上进行高效且经济的研究。
1
3
{ }^{3}
3 https://openai.com/o1/
3.1 获取知识来源
创建包含推理过程的高质量数据集对于训练SRMs至关重要。虽然人工注释保证了优越的质量,但它极其昂贵且不切实际,特别是对于标注整个长链式思维(CoT)过程(Wei等人,2022),因为注释者必须引导甚至编写每个推理步骤(Lightman等人,2024)。接下来,我们将简要讨论人机协作方法,并更多关注自动注释。
8
{}^{8}
8
人机协作。在人机协作中,LLMs/LRMs使用少量精心选择的高质量示例作为上下文演示来进行注释。然后人类注释者只需纠正低质量的注释,这仅占整个数据集的一小部分(Mikulová等人,2022;Kim等人,2024;Li,2024;Wang等人,2024e;Movva等人,2024)。这种方法确保了数据质量,同时最小化了对人类参与的需求。
自动注释。早期使用自动注释技术的工作主要集中在不生成长推理轨迹的复杂任务上,如工具使用(Schick等人,2023;Wang等人,2024b;Qiao等人,2024a)。随着注释者的推理能力提高,先进的LRMs现在可以以零样本方式生成长推理轨迹(Kwon等人,2024)。例如,利用DeepSeek-R1进行自动注释是一种有效解决方案,因为它可以轻松生成带有大上下文窗口的长CoT轨迹(DeepSeek-AI,2025)。这种方法也被称为“知识蒸馏”,用于训练各种类型的SLMs(Hsieh等人,2023;Ho等人,2023;Li等人,2023;Yue等人,2024b,a;Yang等人,2024c;Tang等人,2024)。研究表明,SRMs可以通过仅使用合成数据集进行有效训练。另一种研究趋势是结合专门代理根据计划、
工具使用、反思和改进等操作对训练数据进行注释。在这种情况下,LRMs不仅注释数据集,还记录这些代理如何通过互动做出正确决策(Qiao等人,2024b;Li等人,2024;Song等人,2024;Motwani等人,2024;Kumar等人,2024)。这些互动步骤可被视为推理过程。
此外,由于长推理轨迹本质上包含多个步骤,确定每一步的正确性为SRMs学习提供了细粒度的见解。虽然这些注释任务更具挑战性,但它们对训练过程奖励模型(PRMs)有益。在文献中,早期工作(Luo等人,2023)注释了数学问题解决中每一步的正确性。后续工作(Wang等人,2024c,g)采用蒙特卡罗采样评估中间推理步骤,基于这些步骤的推理结果平均值。进一步扩展依赖于蒙特卡罗树搜索(MCTS)及其变体,利用树搜索提高推理质量(Zhang等人,2024c;Chen等人,2024f)。因此,我们建议可以利用推理时扩展方法进行数据集整理。
3.2 监督学习
监督微调(SFT)是一种标准的监督学习技术,它将模型与特定任务指令对齐。有了高质量的推理数据集,很自然地可以将SFT扩展到基于CoT的SFT。在这种范式下,SRMs被要求显式生成中间推理步骤,并最终为输入指令提供输出,从而增强其解决复杂任务的推理能力。报告显示,结合知识蒸馏的基于CoT的SFT方法可以产生强大的SRMs。然而,SFT受限于对高质量标注数据集的依赖,这些数据集的成本高昂且耗时。例如,报告显示,训练蒸馏DeepSeek-R1模型的数据集大小为800K。此外,微调SRMs比普通语言模型更耗费计算资源,尤其是当训练序列(带CoT轨迹)较长时。这就需要参数高效的学习(Wang等人,2023a;Han等人,2024),如LoRA(Hu等人,2022)、QLoRA(Dettmers等人,2023)、AdaLoRA(Zhang等人,2023a)等。SFT的另一缺点是它迫使SRMs“利用”训练数据集
${ }^{8}$ 为了支持未来研究,我们提供了一个不断增长但不完整的流行开源数据集列表,这些数据集包含由LRMs生成的长CoT和输出注释,如表1(附录)所示。这些数据集可以从HuggingFace Datasets下载,为没有高昂复制成本的研究人员提供一个起点来训练SRMs。
通过结合数据注释和先进的训练算法,可以简化SRMs的训练。利用自动注释和知识蒸馏技术在强模型发布后变得越来越重要。基于收集和注释的数据集,CoT-based SFT是训练SRMs的一个良好起点。先进的强化学习方法通过评估中间推理步骤和减少计算需求提供了有效的训练。对于SRMs,尚无广泛接受的共识表明哪种RL算法表现最佳,而DeepSeek-R1的成功故事倾向于结果奖励监督(DeepSeek-AI,2025),将PRMs和MCTS视为“不成功的尝试”。我们建议现在得出结论可能为时过早,特别是对于SRMs。研究人员可以通过利用促进SRM开发的数据集和RL存储库来加速研究。
但不是“探索”更多的可能性,这促使更多研究强化学习。
3.3 强化学习
强化学习(RL)为训练SRMs提供了一个强有力的替代方案。它允许模型通过试错学习最优策略,并改善泛化能力,而不仅仅是在SFT期间遵循黄金响应。
从经典方法开始。Ouyang等人(2022)采用人类反馈强化学习(RLHF)与近端策略优化(PPO)(Schulman等人,2017)相结合的方法,使LLMs与人类意图对齐。为了减少手动标注的努力,AI反馈强化学习范式(RLAIF)(Bai等人,2022)被引入,以利用模型生成的标签训练奖励模型。这些工作建立了适用于语言模型的强化训练基础,可以直接应用于SRMs。为了绕过优化奖励模型的复杂过程,直接偏好优化(DPO)(Rafailov等人,2023)使用简单的边缘损失对模型进行对齐。DPO的扩展,如KTO(Ethayarajh等人,2024)、ODPO(Amini等人,2024)和SimPO(Meng等人,2024),由于其自回归性质也适用于SRMs。然而,它们并未特别针对SRMs生成的长CoT过程进行优化。
通过结果奖励监督增强多步推理。一种直接方法是利用最终结果作为监督信号来计算RL的奖励,而不考虑中间推理步骤。在文献中,强化微调(ReFT)(Trung等人,2024)是一种针对推理任务的有效训练算法。它首先通过标准SFT预热底层模型,然后使用PPO算法的在线RL过程进一步微调。丰富的推理路径会根据问题自动采样,奖励来自真实答案。VinePPO(Kazemnejad等人,2024)识别出PPO价值网络中用于确定中间推理步骤价值的偏差,并改为利用蒙特卡洛采样进行无偏价值函数估计。关键规划步骤学习(CPL)(Wang等人,2024d)使用MCTS在多步推理任务中探索各种规划步骤,基于中间步骤的价值评估迭代训练策略和价值模型以提高推理性能。此外,组相对策略优化(GRPO)(Shao等人,2024)是PPO算法的一种变体,消除了批评模型。它从同一输入提示的多个推理结果的组分数估计奖励,显著减少了训练资源。GRPO成功应用于训练强SRMs如DeepSeekMath7B,还用于训练超大型LRMs如DeepSeek-R1(DeepSeek-AI,2025)。
9
{}^{9}
9
具有过程奖励监督的细粒度RL。上述方法的一个潜在缺点是奖励仅提供给最终结果。PRMs(Zhang等人,2025b),如前所述,侧重于评估中间推理步骤,提供贯穿SRMs生成的CoT轨迹的细粒度反馈。这种类型的方法也称为过程奖励监督。该领域的典型工作是Math-Shepherd(Wang等人,2024c),它基于PRMs进行逐步步验证和强化。此外,Self-Explore(Hwang等人,2024)使用PRMs通过纠正“初坑”(解决问题时的初始错误)来改进数学推理。它奖励纠正这些错误的步骤,实现无需广泛人工注释的自我监督微调。过程优势验证器(PAVs)(Setlur等人,2024)被提出以评估步骤级进度,改进RL中的解搜索正确性。除了在线RL,离线方法衍生自DPO(Rafailov等人,2023)也已使用过程奖励监督。例如,
${ }^{9}$ 注意,GRPO可以应用于结果监督和过程监督场景。
SVPO(Chen等人,2024a)利用MCTS导航推理路径并标注步骤级偏好。类似基于搜索的方法可在(Xie等人,2024;Wang等人,2024a;Guan等人,2025)中找到。我们在表2(附录)中进一步列出了一些影响深远的公共存储库,支持SRMs的RL训练。
4 使用规模提升SRM推理
解决复杂推理任务通常需要多步计算。本节探讨了扩展SRMs推理的关键方法。
4.1 链式思维(CoT)提示
CoT提示是少数示例提示(Brown等人,2020)的扩展,相比算法和结构化推理显示出更广泛的应用性,后者最初专注于生成中间步骤(Chiang和Chen,2019;Nye等人,2021)。虽然简单采样在计算上很简单,但通常效率低下且次优,因为它随机分配测试时计算预算给不太有希望的分支(Snell等人,2024;Wu等人,2024)。为了解决这个问题,研究人员探索了优先考虑更有希望的推理路径或中间步骤的方法,有效地缩小了搜索空间(Wang等人,2023b;Yao等人,2023;Sel等人,2024)。CoT-SC(Wang等人,2023b)在CoT基础上扩展了树结构。在此框架中,几个CoT分支从相同的初始(根)提示延伸,产生的最有利结果被选为最终答案。SoT(Ning等人,2024)指导SRMs生成答案骨架,然后使用并行API调用或批处理解码填充每个骨架点。最近,大量研究调查了树形思维(ToT)(Long,2023;Yao等人,2023),通过树搜索实现推理,利用树结构将问题分解为子问题,并使用不同的提示解决它们。
4.2 基于代理的推理
基于代理的推理主要分为两类:代理协作以管理不同角色和训练特定的代理图。
代理协作。多个代理之间的合作已成为提高单个SRMs性能的有效方法(Du等人,2024;Liang等人,2024;Wang等人,2024f)。现有方法分为两大类:
流程内和流程间通信。流程内通信检查代理在一个对话回合内的消息交换。通用通信结构包括:(1)即时输出:代理不相互交流,根据自身回答问题的能力输出响应(Zhang等人,2024f;Du等人,2024)。 (2)链式连接:通过将每个代理链接在一起实现代理之间的通信(Qian等人,2024a;Hong等人,2024;Holt等人,2024)。 (3)树式连接:监督代理(称为根或经理)指导下属代理(Wu等人,2023a;Yan等人,2024;Zhou等人,2024c)。 (4)图式连接:每个代理被视为图中的节点,信息通过边传输(Jiang等人,2023;Zhuge等人,2024;Wang等人,2025)。 流程间通信检查连续话语轮次间的信息传输。通用拓扑结构包括:(1)全连接:每个代理接收前一轮所有代理的话语(Du等人,2024)。 (2)部分连接:某些响应根据评分或评级系统进行过滤(Zheng等人,2023;Liu等人,2023)。 (3)摘要:交互轮次间的先前对话被压缩成摘要形式(Shinn等人,2023;Fu等人,2023a;Chen等人,2024c)。
代理图。通过学习图连通性来改进代理协作,以促进通信是一种长期且有效的方法。在LLMs出现之前,大量努力致力于探索多代理系统的最佳通信图结构,利用诸如图扩散(Pesce和Montana,2023)、加权图神经网络(Liu等人,2022)和变压器(Hu等人,2024c)等技术。在LLM驱动的代理兴起浪潮中,ChatEval(Chan等人,2024)和AutoGen(Wu等人,2023a)隐含地使用图结构表示同时通信,而STOP(Zelikman等人,2023)和DSPy(Khattab等人,2023)联合优化提示和推理结构。此外,MacNet(Qian等人,2024b)和GPTSwarm(Zhuge等人,2024)使用有向无环图建模代理通信。不像CDC(Pesce和Montana,2023)从扩散过程视角动态修改通信图,和TWG-Q(Liu等人,2022)集中于时间权重学习和加权GCN实现,CommFormer(Hu等人,2024c)采取独特路径。它专-
为了在推理过程中提升SRMs的推理能力,采用了多种策略。CoT提示被广泛用于引导SRMs生成中间推理步骤,显著提高了其在复杂推理任务上的表现。基于代理的推理方法也展示了通过利用多个代理之间的交互来增强SRMs推理的巨大潜力。此外,提出了如自增强树搜索和分步验证器等推理时间扩展技术,以优化推理期间的计算资源并实现更高的效率。
门在于在推理阶段之前学习静态图以增强通信效率,从而区别于这些先前方法使用的传统技术。
4.3 推理时间扩展
Snell等人(2024)优化了推理期间的计算资源分配,实现了显著的效率提升。自增强树搜索(Lample等人,2022;Bi等人,2024)整合了各种推理路径并应用稀疏激活技术。此外,分步验证器被用来动态修剪搜索树(Pope等人,2023;Lightman等人,2024)。此外,Chen等人(2024e)引入了一种两阶段消除方法,使用配对比较来迭代精炼候选对象。通过迭代精炼,这些方法(Welleck等人,2023;Madaan等人,2023;Chen等人,2024d,2025)在复杂任务上提高了性能。S1(Muennighoff等人,2025)被提出作为一种简单的测试时间应用扩展方法,使用推理长度约束以最大化资源利用率。
与重复采样相比,基于扩展的方法使模型能够迭代生成解决方案尝试,每次尝试都基于前一次结果进行改进(Hou等人,2025;Lee等人,2025)。像MCTS(Choi等人,2023;Zhang等人,2023b;Zhou等人,2024a)和引导波束搜索(Xie等人,2023)这样的方法通过基于树的搜索(Gandhi等人,2024;Wu等人,2024)桥接顺序和并行扩展(Muennighoff等人,2025)。通过其创新的过程奖励模型,REBASE(Wu等人,2024)有效管理了树搜索中的利用-修剪权衡,在经验结果上优于基于采样的技术和MCTS(Wu等人,2024)。奖励模型(Lightman等人,2024;Wang等人,2024c)在这些方法中起着关键作用,主要存在两种形式:基于结果和基于过程。基于结果的奖励模型(Xin等人,2024;Ankner等人,2024),通过评分评估最终解决方案,对Best-of-N选择策略特别有价值。相反,基于过程的奖励模型(Xin等人,2024;Wang等人,2024c;Wu等人,2024)分析推理步骤,使其特别有效于指导基于树的搜索。
5 领域特定应用
虽然LRMs需要广泛的知识,领域特定的SRMs更注重专业知识。在这里,我们强调各个领域的热门应用。
5.1 医疗健康
希波克拉底(Acikgoz等人,2024)提供了对数据集、代码库、模型和协议的无限制访问权限 10 {}^{10} 10。它在包含医学指南、PMCPatients(Zhao等人,2022)和PubMedQA-contexts(Jin等人,2019)的医学语料库上进行训练,总计3亿个标记。Hippo系列经历了持续预训练、SFT和RLHF。Mistral和Llama-2的微调版本在评估中与几个70B模型竞争。例如,Hippo-Mistral-7B在MedQA上达到59.9%,超过了Meditron-70B(Chen等人,2023)(58.5%)。BioMedLM(Bolton等人,2024)是一个2.7B模型,预先训练在PubMed(Gao等人,2021)上。AdaLM(Yao等人,2021)通过在医学重点SLM上继续训练改进领域SRMs。实验表明,适应-然后-蒸馏方法最为有效。MentalLLaMA(Yang等人,2024b)开创了两个关键贡献:(1)第一个IMHI数据集用于心理健康分析,以及(2)第一个开源模型能够解释性分析社交媒体内容。华佗GPT-o1(Chen等人,2024b)引入了可验证的医学问题以及医学验证器以评估模型输出的准确性。这种可验证性允许通过两步方法推进医学推理:(1)利用验证器指导复杂推理路径的搜索,以及(2)通过基于验证器的奖励进行RL,以进一步改进复杂推理。
${ }^{10}$ https://cyberiada.github.io/ Hippocrates/
开发领域特定SRMs的标准方法涉及将通用模型适应到专业数据集。因此,许多研究人员构建定制数据集(Nguyen等人,2023;Yang等人,2024b;Zhang等人,2024b,d),通常使用高级LLMs(如GPT-4)进行标注,并随后用于模型的持续预训练或微调,如LLaMA-2-7B(Acikgoz等人,2024)。为了确保高质量输出,开发了专用的标注框架,如SciGLM(Zhang等人,2024b)所使用的框架。对于拥有大量文本语料库的领域,一种有效策略是从头开始训练基础模型,然后进行SFT(Yang等人,2023)。开发领域特定SRMs的另一种方法涉及双过程:从LLMs蒸馏通用能力,并系统地集成领域语料库中的专业知识(Yao等人,2021)。
5.2 科学
SciGLM(Zhang等人,2024b)是一个大学水平的科学模型,通过采用自我反思指令标注框架解决了数据限制问题。使用GPT-4(OpenAI,2023),它通过结构化提示的三阶段过程为未标注的科学问题生成逐步推理:(1)CoT提示(引导模型提供逐步推理),(2)反思提示(帮助识别和纠正推理过程中的错误),(3)答案整合(结合纠正后的解决方案以清晰准确的输出)。此外,Llemma(Azerbayev等人,2024),一个从CodeLlama(Rozière等人,2023)改编的科学模型,专注于高级数学推理。通过扩展预训练,其7B模型使用新构建的Proof-Pile-2数据集的55B标记进一步开发。该数据集包含了科学出版物、数学网页内容和计算数学资源。增强后的模型在关键数学基准测试中表现出色,包括MATH(Hendrycks等人,2021)、GSM8k(Cobbe等人,2021)、OCWCourses(Lewkowycz等人,2022)、MMLU-STEM(Hendrycks等人,2021)和SAT,超越了所有同样大小的模型。ChemLLM(Zhang等人,2024d)是一个化学SRM,采用其ChemData框架,将化学知识重新格式化为对话数据。该模型基于InternLM2-Base-7B(Cai等人,2024),首先通过预训练170万对问答对来自HuggingFace的多领域语料库来加强其基础能力。随后的SFT结合了ChemData和多语料库,以保持广泛的技能同时专业化于化学。ChemLLM在跨学科化学应用中表现出色,在几个领域与GPT-4(OpenAI,2023)持平,同时持续超越GPT-3.5(Ouyang等人,2022)。值得注意的是,它在Mol2caption上达到了92.6,几乎达到了GPT-4的性能水平。AstroLLaMA(Nguyen等人,2023)是一个专门用于天文学应用的模型。基于Llama-2-7B(Touvron等人,2023),该模型使用从arXiv 11 {}^{11} 11 收集的超过30万篇天文学摘要进行扩展预训练。它支持各种天文学相关应用,包括自动化研究论文摘要和创建用于天文学研究的对话式AI系统。
5.3 其他领域
MindLLM(Yang等人,2023)是一个双语(中文-英文)模型,具有双语预训练:英语能力通过The Pile数据集(Gao等人,2021)发展,而中文能力通过武道(Yuan等人,2021)、CBook和各种中文网络资源培养。这种双语方法同时增强了模型的能力,同时减轻了专业化过程中的灾难性遗忘。通过监督微调,该模型在特定领域表现出显著实力:(1)法律应用:利用开放法律数据集、LaW-GPT(Zhou等人,2024b)的情景问答和DISC-LawLLM(Yue等人,2023)的NLP法律任务。LaWGPT(Zhou等人,2024b)是一系列旨在扩展法律词汇覆盖范围的模型。这些模型通过广泛的中国法律文本语料库进行预训练,以提高法律领域的基础语义理解能力。作为中国法律SRM开发的Lawyer LLaMA(Huang等人,2023)通过综合法律数据集进行训练,能够提供法律指导、进行案例评估和生成法律写作。ChatLaw(Cui等人,2023)是一个开源法律SRM系列。该系列包括像ChatLaw-13B和ChatLaw33B这样的模型,这些模型在广泛的法律数据集上进行训练,其中包括新闻、论坛讨论和司法解释。此外,ChatLaw-Text2Vec变体使用93万份法院案件数据集开发
${ }^{11}$ https://www.kaggle.com/ Cornell-University/arxiv
相似匹配模型。(2)金融应用:以东方财富网为主要训练数据。Fin-R1(Liu等人,2025)生成了一个高质量的CoT数据集,仔细蒸馏和过滤来自多个权威金融来源的数据,专门针对专业的金融推理任务。同时,一个金融SRM专门训练以满足金融行业的关键需求:决策支持、数值准确性等。正如BloombergGPT(Wu等人,2023b)所示,训练语料库结合了一般和金融内容,各占一半比例。一个关键特征是包含了一个目标50亿标记的彭博数据集,仅占整体训练材料的0.7%。这一特定数据段在金融基准测试中显著提升了结果。
6 未来研究方向
在本节中,我们强调了一些可能的未来SRMs研究方向。
增强蒸馏技术。尽管当前的蒸馏过程已成功将LRMs蒸馏为更易于管理的SRMs,但仍有很大的改进空间。首先,由于其参数规模和容量较小,SRMs在应对挑战性任务时的学习能力往往受到限制。研究逐步从LRMs向SRMs转移复杂推理知识的方法是一个有趣的想法。从基本推理任务开始,逐步传授复杂的CoT知识,可以使SRMs更加稳健。其次,虽然基于SFT的蒸馏过程取得了显著成功,但利用RL-in-the-loop机制可以帮助识别SRMs可能不足的地方,从而有针对性地调整以解决这些缺陷。最后,通过在蒸馏过程中整合外部知识源(如知识图谱),研究人员可以丰富SRMs的额外上下文和背景知识。
自适应RL策略。为了进一步增强SRMs的能力,自适应RL策略提供了一个有前景的研究方向。对于SRMs来说,值得研究自适应机制以在RL中平衡探索和利用,因为SRMs在SFT后探索远离参考模型的替代方案的能力有限。通过根据任务复杂性和模型性能动态调整探索率,SRMs可以更好地导航学习空间以实现更有效的推理。此外,通过优化特定推理任务的奖励,SRMs可以学习更细致的决策规则,从而提高准确性和效率。最后,开发持续学习框架也很有趣,这使得SRMs可以根据持续的交互和反馈增量更新其知识和策略。
低资源环境下的学习。低资源环境下的学习是SRMs的关键前沿。许多领域和应用面临着高质量数据匮乏、计算资源有限和受约束环境的问题。有必要研究利用相关领域的CoT推理数据集来丰富低资源数据集的策略。关于计算资源,虽然有许多关于SFT的参数高效学习的研究(Hu等人,2022;Dettmers等人,2023),但参数高效学习是否以及何时对SRMs的RL有用仍是一个问题。
7 结论
总之,本综述对SRMs进行了全面概述。SRMs的进步为在资源受限环境中部署高性能模型开辟了新的途径,这对学术研究和商业应用都至关重要。随着SRMs的不断发展,未来的研究所面临的任务不仅是增强其推理能力,还要探索创新的方式将SRMs集成到更广泛的NLP任务中。
${ }^{12}$ https://www.eastmoney.com/default. html
## 局限性
尽管我们的综述提供了对SRMs及其应用的概述,但承认本工作中固有的几个局限性是很重要的。首先,大模型和小模型推理领域正在迅速发展,不断有新模型和技术出现。因此,不可避免地存在捕捉最新进展的延迟,某些尖端发展可能未能充分代表。其次,我们的分析主要集中在已发表的文献上,可能有一些未发表或专有的SRMs进展未被涵盖。这种对已有出版物的依赖可能会引入一定程度的出版偏差,可能限制发现的范围。最后,尽管我们涵盖了SRMs已应用的广泛领域,一些小众或新兴领域可能未得到深入讨论,反映了当前研究重点的状态。
伦理考量和边界影响
本工作主要回顾了SRMs的最新进展,并未呈现直接的伦理问题。然而,需要注意的是,许多SRMs是从较大模型蒸馏而来的,引发了对潜在偏差和隐私问题延续的担忧。解决这些问题超出了本文的范围。我们建议读者参考相关调查(Kibriya等人,2024;Gao等人,2024;Fan等人,2023)以获取更详细的讨论。
SRMs的探索和发展对NLP领域及其他领域有着重要意义。本综述强调了SRMs通过减少所需计算资源,使先进推理能力民主化接入的潜力。这一方面尤其与硬件资源有限的机构相关,促进了AI研究和应用的包容性。此外,SRMs为可持续AI研究和部署提供了机会,因其减少的计算需求与努力最小化大型AI模型相关碳足迹的目标一致。
参考文献
Acikgoz, Emre Can, Osman Batur Ince, Rayene Bench, Arda Anil Boz, Ilker Kesen, Aykut Erdem, 和 Erkut Erdem. 2024. “Hippocrates: 开源框架推进医疗领域的大型语言模型.” CoRR, abs/2404.16621.
Ahn, Janice, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, 和 Wenpeng Yin. 2024. “用于数学推理的大规模语言模型:进展与挑战.” 第18届欧洲计算语言学协会会议论文集,第225-237页。计算语言学协会。
Amini, Afra, Tim Vieira, 和 Ryan Cotterell. 2024. “带有偏移的直接偏好优化.” 计算语言学协会发现论文集,ACL 2024,第9954-9972页。计算语言学协会。
Ankner, Zachary, Mansheej Paul, Brandon Cui, Jonathan D. Chang, 和 Prithviraj Ammanabrolu. 2024. “大声批评奖励模型.” CoRR, abs/2408.11791.
Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen Marcus McAleer, Albert Q. Jiang, Jia Deng, Stella Biderman, 和 Sean Welleck. 2024. “Llemma: 数学领域的开源语言模型.” 第十二届国际学习表征会议论文集。
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, Kamile Lukosiute, Liane Lovitt, Michael Sellitto, Nelson Elhage, Nicholas Schiefer, Noemí Mercado, Nova DasSarma, Robert Lasenby, Robin Larson, Sam Ringer, Scott Johnston, Shauna Kravec, Sheer El Showk, Stanislav Fort, Tamera Lanham, Timothy Telleen-Lawton, Tom Conerly, Tom Henighan, Tristan Hume, Samuel R. Bowman, Zac Hatfield-Dodds, Ben Mann, Dario Amodei, Nicholas Joseph, Sam McCandlish, Tom Brown, 和 Jared Kaplan. 2022. “宪法AI:通过AI反馈实现无害性.” CoRR, abs/2212.08073.
Zhenni Bi, Kai Han, Chuanjian Liu, Yehui Tang, 和 Yunhe Wang. 2024. “Forest-of-thought: 扩展测试时间计算以增强LLM推理.” CoRR, abs/2412.09078.
Elliot Bolton, Abhinav Venigalla, Michihiro Yasunaga, David Hall, Betty Xiong, Tony Lee, Roxana Daneshjou, Jonathan Frankle, Percy Liang, Michael Carbin, 和 Christopher D. Manning. 2024. “Biomedlm: 在生物医学文本上训练的27亿参数语言模型.” CoRR, abs/2403.18421.
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child,
Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, 和 Dario Amodei. 2020. “语言模型是少样本学习者.” 第33届神经信息处理系统大会论文集。
Cai, Zheng, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, Xiaoyi Dong, Huodong Duan, Qi Fan, Zhaoye Fei, Yang Gao, Jiaye Ge, Chenya Gu, Yuzhe Gu, Tao Gui, Aijia Guo, Qipeng Guo, Conghui He, Yingfan Hu, Ting Huang, Tao Jiang, Penglong Jiao, Zhenjiang Jin, Zhikai Lei, Jiaxing Li, Jingwen Li, Linyang Li, Shuaibin Li, Wei Li, Yining Li, Hongwei Liu, Jiangning Liu, Jiawei Hong, Kaiwen Liu, Kuikun Liu, Xiaoran Liu, Chengqi Lv, Haijun Lv, Kai Lv, Li Ma, Runyuan Ma, Zerun Ma, Wenchang Ning, Linke Ouyang, Jiantao Qiu, Yuan Qu, Fukai Shang, Yunfan Shao, Demin Song, Zifan Song, Zhihao Sui, Peng Sun, Yu Sun, Huanze Tang, Bin Wang, Guoteng Wang, Jiaqi Wang, Jiayu Wang, Rui Wang, Yudong Wang, Ziyi Wang, Xingjian Wei, Qizhen Weng, Fan Wu, Yingtong Xiong, Xiaomeng Zhao, 等人. 2024. “InternLM2技术报告.” CoRR, abs/2403.17297.
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, 和 Zhiyuan Liu. 2024. “Chateval: 通过多代理辩论实现更好的基于LLM的评估器.” 第十二届国际学习表征会议论文集。
Guoxin Chen, Minpeng Liao, Chengxi Li, 和 Kai Fan. 2024a. “步骤级价值偏好优化用于数学推理.” 计算语言学协会发现论文集:EMNLP 2024,第7889-7903页。计算语言学协会。
Jiefeng Chen, Jie Ren, Xinyun Chen, Chengrun Yang, Ruoxi Sun, 和 Sercan O. Arik. 2025. “SETS: 利用自验证和自纠正提高测试时扩展性能.” CoRR, abs/2501.19306.
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, 和 Benyou Wang. 2024b. “Huatuogpt-o1,利用LLMs进行医学复杂推理.” CoRR, abs/2412.18925.
Pei Chen, Shuai Zhang, 和 Boran Han. 2024c. “Comm: 复杂问题求解中的协作多代理、多推理路径提示.” 计算语言学协会发现论文集:NAACL 2024,第1720-1738页。
Xinyun Chen, Maxwell Lin, Nathanael Schärli, 和 Denny Zhou. 2024d. “教会大规模语言模型自我调试.” 第12届国际学习表征会议论文集。
Yanxi Chen, Xuchen Pan, Yaliang Li, Bolin Ding, 和 Jingren Zhou. 2024e. “大语言模型测试时计算的简单且可证明的扩展定律.” CoRR, abs/2411.19477.
Zeming Chen, Alejandro Hernández-Cano, Angelika Romanou, Antoine Bonnet, Kyle Matoba, Francesco Salvi, Matteo Pagliardini, Simin Fan, Andreas Köpf, Amirkeivan Mohtashami, Alexandre Sallinen, Alireza Sakhaeirad, Vinitra Swamy, Igor Krawczuk, Deniz Bayazit, Axel Marmet, Syrielle Montariol, Mary-Anne Hartley, Martin Jaggi, 和 Antoine Bosselut. 2023. “MEDITRON-70B: 扩展大型语言模型的医学预训练.” CoRR, abs/2311.16079.
Ziru Chen, Michael White, Raymond J. Mooney, Ali Payani, Yu Su, 和 Huan Sun. 2024f. “当树搜索对LLM规划有用时?这取决于判别器.” 第62届年度计算语言学协会会议论文集,第13659-13678页。计算语言学协会。
Ting-Rui Chiang 和 Yun-Nung Chen. 2019. “语义对齐方程生成用于解决和推理数学文字问题.” 第2019年北美计算语言学协会会议论文集:人类语言技术,第2656-2668页。
Sehyun Choi, Tianqing Fang, Zhaowei Wang, 和 Yangqiu Song. 2023. “KCTS: 带有标记级幻觉检测的知识约束树搜索解码.” 第2023年经验方法在自然语言处理会议论文集,第14035-14053页。
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, 和 John Schulman. 2021. “训练验证器解决数学文字问题.” CoRR, abs/2110.14168.
Jiaxi Cui, Zongjian Li, Yang Yan, Bohua Chen, 和 Li Yuan. 2023. “Chatlaw: 开源法律大型语言模型集成外部知识库.” CoRR, abs/2306.16092.
DeepSeek-AI. 2025. “Deepseek-r1: 通过强化学习激励LLMs的推理能力.” CoRR, abs/2501.12948.
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, 和 Luke Zettlemoyer. 2023. “QLoRA: 高效微调量化LLMs.” 第36届神经信息处理系统大会论文集:2023年年度神经信息处理系统大会。
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, 和 Igor Mordatch. 2024. “通过多代理辩论改进语言模型的事实性和推理能力.” 第四十一届国际机器学习会议论文集。
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, 和 Douwe Kiela. 2024. “KTO: 模型对齐作为前景理论优化.” CoRR, abs/2402.01306.
Mingyuan Fan, Cen Chen, Chengyu Wang, 和 Jun Huang. 2023. “最新生成模型可信度景观的全面调查.” CoRR, abs/2307.16680.
Yao Fu, Hao Peng, Tushar Khot, 和 Mirella Lapata. 2023a. “通过自我博弈和AI反馈上下文学习改进语言模型谈判.” CoRR, abs/2305.10142.
Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, 和 Tushar Khot. 2023b. “专门化更小的语言模型向多步推理发展.” 国际机器学习会议论文集,ICML 2023,第202卷,第10421-10430页。PMLR.
Kanishk Gandhi, Denise Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, 和 Noah D. Goodman. 2024. “搜索流(SOS):学习在语言中进行搜索.” CoRR, abs/2404.03683.
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, 和 Connor Leahy. 2021. “The pile: 一个800GB的多样化文本数据集用于语言建模.” CoRR, abs/2101.00027.
Zhengjie Gao, Xuanzi Liu, Yuanshuai Lan, 和 Zheng Yang. 2024. “大语言模型安全性的简要调查.” 计算机与信息技术杂志,32(1):47-64.
Panagiotis Giadikiaroglou, Maria Lymperaiou, Giorgos Filandrianos, 和 Giorgos Stamou. 2024. “使用大语言模型推理解决谜题的调查.” 第2024年经验方法在自然语言处理会议论文集,第11574-11591页。计算语言学协会。
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, 和 Mao Yang. 2025. “rstar-math: 小型LLMs可以通过自我进化深度思考掌握数学推理.” CoRR, abs/2501.04519.
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, 和 Wenfeng Liang. 2024. “Deepseek-coder: 当大型语言模型遇到编程——代码智能的兴起.” CoRR, abs/2401.14196.
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, 和 Sai Qian Zhang. 2024. “大型模型高效微调的全面调查.” CoRR, abs/2403.14608.
Alexander Havrilla, Sharath Chandra Raparthy, Christoforos Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravinskyi, Eric Hambro, 和 Roberta Raileanu. 2024. “Glore: 何时、何地以及如何通过全局和局部改进提升LLM推理.” 第四十一届国际机器学习会议论文集。OpenReview.net.
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, 和 Jacob Steinhardt. 2021. “测量大规模多任务语言理解.” 第9届国际学习表征会议论文集。
Namgyu Ho, Laura Schmid, 和 Se-Young Yun. 2023. “大型语言模型是推理教师.” 第61届年度计算语言学协会会议论文集,第14852-14882页。计算语言学协会。
Samuel Holt, Max Ruiz Luyten, 和 Mihaela van der Schaar. 2024. “L2MAC: 大型语言模型自动计算机用于广泛的代码生成.” 第十二届国际学习表征会议论文集。
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, 和 Jürgen Schmidhuber. 2024. “Metagpt: 元编程用于多代理协作框架.” 第十二届国际学习表征会议论文集。
Zhenyu Hou, Xin Lv, Rui Lu, Jiajie Zhang, Yujiang Li, Zijun Yao, Juanzi Li, Jie Tang, 和 Yuxiao Dong. 2025. “通过强化学习和推理扩展提升语言模型推理.” CoRR, abs/2501.11651.
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, 和 Tomas Pfister. 2023. “蒸馏逐步!使用更少的训练数据和更小的模型尺寸超越更大的语言模型.” 计算语言学协会发现论文集:ACL 2023,第8003-8017页。计算语言学协会。
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, 和 Weizhu Chen. 2022. “LoRA: 大型语言模型的低秩适应.” 第十届国际学习表征会议论文集。OpenReview.net.
Jian Hu, Xibin Wu, Weixun Wang, Xianyu, Dehao Zhang, 和 Yu Cao. 2024a. “OpenRLHF: 易于使用、可扩展且高性能的RLHF框架.” CoRR, abs/2405.11143.
Linmei Hu, Hongyu He, Duokang Wang, Ziwang Zhao, Yingxia Shao, 和 Liqiang Nie. 2024b. “LLM vs 小型模型?基于大型语言模型的文本增强增强个性检测模型.”
第三十八届AAAI人工智能会议论文集,第18234-18242页。AAAI出版社。
Shengchao Hu, Li Shen, Ya Zhang, 和 Dacheng Tao. 2024c. “从图建模视角学习多代理通信.” 第十二届国际学习表征会议论文集。
Jie Huang 和 Kevin Chen-Chuan Chang. 2023. “走向大语言模型中的推理:调查.” 计算语言学协会发现论文集:ACL 2023,第1049-1065页。计算语言学协会。
Quzhe Huang, Mingxu Tao, Zhenwei An, Chen Zhang, Cong Jiang, Zhibin Chen, Zirui Wu, 和 Yansong Feng. 2023. “Lawyer llama 技术报告.” CoRR, abs/2305.15062.
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, An Yang, Rui Men, Fei Huang, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, 和 Junyang Lin. 2024. “Qwen2.5-coder 技术报告.” CoRR, abs/2409.12186.
Hyeonbin Hwang, Doyoung Kim, Seungone Kim, Seonghyeon Ye, 和 Minjoon Seo. 2024. “Selfexplore to avoid the pit: 使用精细奖励改进语言模型的推理能力.” CoRR, abs/2404.10346.
Dongfu Jiang, Xiang Ren, 和 Bill Yuchen Lin. 2023. “LLM-blender: 使用成对排名和生成融合集成大型语言模型.” 第61届年度计算语言学协会会议论文集,第14165-14178页。
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, 和 Sunghun Kim. 2024. “关于代码生成的大语言模型调查.” CoRR, abs/2406.00515.
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W. Cohen, 和 Xinghua Lu. 2019. “PubMedQA: 生物医学研究问答数据集.” 第2019年经验方法在自然语言处理会议论文集及第九届国际自然语言处理联合会议论文集,第2567-2577页。
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron C. Courville, 和 Nicolas Le Roux. 2024. “Vineppo: 通过精炼信用分配解锁LLM推理的RL潜力.” CoRR, abs/2410.01679.
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, 和 Christopher Potts. 2023. “DSPy: 将声明性语言模型调用编译为自改进管道.” CoRR, abs/2310.03714.
Hareem Kibriya, Wazir Zada Khan, Ayesha Siddiqa, 和 Muhammad Khurrum Khan. 2024. “大语言模型中的隐私问题:调查.” 计算机与电气工程,120:109698.
Hannah Kim, Kushan Mitra, Rafael Li Chen, Sajjadur Rahman, 和 Dan Zhang. 2024. “Meganno+: 一种人类-LLM协作注释系统.” 第18届欧洲计算语言学协会会议论文集,第168-176页。计算语言学协会。
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D. Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M. Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal M. P. Behbahani, 和 Aleksandra Faust. 2024. “通过强化学习使语言模型自校正.” CoRR, abs/2409.12917.
Teyun Kwon, Norman Di Palo, 和 Edward Johns. 2024. “作为零样本轨迹生成器的语言模型.” IEEE Robotics Autom. Lett., 9(7):6728-6735.
Guillaume Lample, Timothée Lacroix, Marie-Anne Lachaux, Aurélien Rodriguez, Amaury Hayat, Thibaut Lavril, Gabriel Ebner, 和 Xavier Martinet. 2022. “超树证明搜索用于神经定理证明.” 第35届神经信息处理系统大会论文集:2022年年度神经信息处理系统大会。
Kuang-Huei Lee, Ian Fischer, Yueh-Hua Wu, Dave Marwood, Shumeet Baluja, Dale Schuurmans, 和 Xinyun Chen. 2025. “演化更深的LLM思维.” CoRR, abs/2501.09891.
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay V. Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, 和 Vedant Misra. 2022. “使用语言模型解决定量推理问题.” 第35届神经信息处理系统大会论文集:2022年年度神经信息处理系统大会。
Chengpeng Li, Guanting Dong, Mingfeng Xue, Ru Peng, Xiang Wang, 和 Dayiheng Liu. 2024. “Dotamath: 带有助手代码和自我修正的数学推理分解.” CoRR, abs/2407.04078.
Jiyi Li. 2024. “人类-LLM混合文本答案聚合用于群体注释.” 第2024年经验方法在自然语言处理会议论文集,第15609-15622页。计算语言学协会。
Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, 和 Yejin Choi. 2023. “符号链式思维蒸馏:小型模型也可以‘分步思考’.” 第61届年度计算语言学协会会议论文集,第2665-2679页。计算语言学协会。
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, 和 Zhaopeng Tu. 2024. “通过多代理辩论鼓励大型语言模型的发散思维.” 第2024年经验方法在自然语言处理会议论文集,第17889-17904页。
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, 和 Karl Cobbe. 2024. “让我们逐步验证.” 第十二届国际学习表征会议论文集。OpenReview.net.
Yuntao Liu, Yong Dou, Yuan Li, Xinhai Xu, 和 Donghong Liu. 2022. “多代理强化学习的时间动态加权图卷积.” 第44届认知科学学会年度会议论文集,CogSci 2022, 多伦多,安大略省,加拿大,2022年7月27-30日。认知科学学会。
Zhaowei Liu, Xin Guo, Fangqi Lou, Lingfeng Zeng, Jinyi Niu, Zixuan Wang, Jiajie Xu, Weige Cai, Ziwei Yang, Xueqian Zhao, Chao Li, Sheng Xu, Dezhi Chen, Yun Chen, Zuo Bai, 和 Liwen Zhang. 2025. “Fin-r1: 通过强化学习进行金融推理的大型语言模型.” CoRR, abs/2503.16252.
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, 和 Diyi Yang. 2023. “动态LLM-agent网络:具有代理团队优化的LLM-agent协作框架.” CoRR, abs/2310.02170.
Jieyi Long. 2023. “大型语言模型引导的思维树.” CoRR, abs/2305.08291.
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, WenDing Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Zheltonozhskii, Nii Osae Osae Dade, Wenhao Yu, Lucas Krauß, Naman Jain, Yixuan Su, Xuanli He, Manan Dey, Edoardo Abati, Yekun Chai, Niklas Muennighoff, Xiangru Tang, Muhtasham Oblokulov, Christopher Akiki, Marc Marone, Chenghao Mou, Mayank Mishra, Alex Gu, Binyuan Hui, Tri Dao, Armel Zebaze, Olivier Dehaene, Nicolas Patry, Canwen Xu, Julian J. McAuley, Han Hu, Torsten Scholak, Sébastien Paquet, Jennifer Robinson, Carolyn Jane Anderson, Nicolas Chapados, 等人. 2024. “StarCoder 2 和 Stack v2: 下一代.” CoRR, abs/2402.19173.
Dakuan Lu, Xiaoyu Tan, Rui Xu, Tianchu Yao, Chao Qu, Wei Chu, Yinghui Xu, 和 Yuan Qi. 2025. “SCP-116K: 高等教育科学领域高质量的问题-解决方案数据集
和自动化提取的通用管道.” CoRR, abs/2501.15587.
Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, 和 Dongmei Zhang. 2023. “Wizardmath: 通过强化进化指令增强大型语言模型的数学推理能力.” CoRR, abs/2308.09583.
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, 和 Peter Clark. 2023. “Self-refine: 自我反馈的迭代细化.” 第36届神经信息处理系统大会论文集:2023年年度神经信息处理系统大会。
Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adámek, Eric Malmi, 和 Aliaksei Severyn. 2023. “教授小型语言模型推理.” 第61届年度计算语言学协会会议论文集,第1773-1781页。计算语言学协会。
Zhiyu Mei, Wei Fu, Kaiwei Li, Guangju Wang, Huanchen Zhang, 和 Yi Wu. 2024. “Realhf: 通过参数重分配优化大型语言模型的RLHF训练.” CoRR, abs/2406.14088.
Zhiyu Mei, Wei Fu, Kaiwei Li, Guangju Wang, Huanchen Zhang, 和 Yi Wu. 2025. “REAL: 通过参数重分配高效训练大型语言模型的RLHF.” 第八届机器学习与系统会议论文集. mlsys.org.
Yu Meng, Mengzhou Xia, 和 Danqi Chen. 2024. “SimPO: 不依赖参考的简单偏好优化奖励.” 第38届神经信息处理系统大会论文集:2024年年度神经信息处理系统大会.
Marie Mikulová, Milan Straka, Jan Stepánek, Barbora Stepánková, 和 Jan Hajic. 2022. “手动注释的质量与效率:预注释偏差.” 第十三届语言资源与评估会议论文集,第2909-2918页. 欧洲语言资源协会.
Sumeet Ramesh Motwani, Chandler Smith, Rocktim Jyoti Das, Markian Rybchuk, Philip H. S. Torr, Ivan Laptev, Fabio Pizzati, Ronald Clark, 和 Christian Schröder de Witt. 2024. “MALT: 改进推理的多代理LLM训练.” CoRR, abs/2412.01928.
Rajiv Movva, Pang Wei Koh, 和 Emma Pierson. 2024. “注释对齐:比较LLM和人类对话安全性的注释.” 第2024年经验方法在自然语言处理会议论文集,第9048-9062页. 计算语言学协会.
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel J. Candès, 和 Tatsunori Hashimoto. 2025. “s1: 简单的测试时间扩展.” CoRR, abs/2501.19393.
Tuan Dung Nguyen, Yuan-Sen Ting, Ioana Ciuca, Charlie O’Neill, Zechang Sun, Maja Jablonska, Sandor Kruk, Ernest Perkowski, Jack W. Miller, Jason Li, Josh Peek, Kartheik Iyer, Tomasz Rózanski, UniverseTBD. 2023. “Astrollama: 向专业基础模型迈进.” CoRR, abs/2309.06126.
Xuefei Ning, Zinan Lin, Zixuan Zhou, Zifu Wang, Huazhong Yang, 和 Yu Wang. 2024. “Skeleton-of-Thought: 提示LLMs进行高效的并行生成.” 第12届国际学习表征会议论文集.
Maxwell I. Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, 和 Augustus Odena. 2021. “展示你的工作:语言模型的中间计算刮痕垫.” CoRR, abs/2112.00114.
OpenAI. 2023. “GPT-4 技术报告.” CoRR, abs/2303.08774.
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, 和 Ryan Lowe. 2022. “通过人类反馈训练语言模型遵循指令.” 第35届神经信息处理系统大会论文集:2022年年度神经信息处理系统大会。
Emanuele Pesce 和 Giovanni Montana. 2023. “通过连通性驱动的通信学习多代理协调.” 机器学习杂志,112(2):483-514.
Aske Plaat, Annie Wong, Suzan Verberne, Joost Broekens, Niki van Stein, 和 Thomas Bäck. 2024. “使用大语言模型推理的调查.” CoRR, abs/2407.11511.
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, 和 Jeff Dean. 2023. “高效扩展变压器推理.” 第六届机器学习与系统会议论文集. mlsys.org.
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu,
和 Maosong Sun. 2024a. “Chatdev: 软件开发的通信代理.” 第62届年度计算语言学协会会议论文集,第15174-15186页。
Chen Qian, Zihao Xie, Yifei Wang, Wei Liu, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, 和 Maosong Sun. 2024b. “扩展基于大型语言模型的多代理协作.” CoRR, abs/2406.07155.
Shuofei Qiao, Honghao Gui, Chengfei Lv, Qianghuai Jia, Huajun Chen, 和 Ningyu Zhang. 2024a. “通过执行反馈让语言模型成为更好的工具学习者.” 在第2024年北美计算语言学协会会议论文集:人类语言技术,第3550-3568页. 计算语言学协会。ng, Yujie Luo, Wangchunshu Zhou, Yuchen Eleanor Jiang, Chengfei Lv, 和 Huajun Chen. 2024b. “AutoAct: 自动从头开始的QA代理学习.” 在第62届年度计算语言学协会会议论文集,第3003-3021页. 计算语言学协会。
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, 和 Chelsea Finn. 2023. “直接偏好优化:你的语言模型实际上是一个奖励模型.” 在第36届神经信息处理系统大会论文集:2023年年度神经信息处理系统大会。
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton-Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, 和 Gabriel Synnaeve. 2023. “Code Llama: 开放的基础代码模型.” CoRR, abs/2308.12950.
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, 和 Thomas Scialom. 2023. “Toolformer: 语言模型可以自己学习使用工具.” 在第36届神经信息处理系统大会论文集:2023年年度神经信息处理系统大会。
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, 和 Oleg Klimov. 2017. “近端策略优化算法.” CoRR, abs/1707.06347.
Bilgehan Sel, Ahmad Al-Tawaha, Vanshaj Khattar, Ruoxi Jia, 和 Ming Jin. 2024. “算法思维:增强大型语言模型中的想法探索.” 在第四十一届国际机器学习会议中。
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, 和 Aviral Kumar. 2024. “奖励进步:为LLM推理扩展自动化过程验证器.” CoRR, abs/2410.08146.
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, 和 Daya Guo. 2024. “DeepSeekMath: 推动开放语言模型中数学推理的极限.” CoRR, abs/2402.03300.
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, 和 Chuan Wu. 2024. “HybridFlow: 灵活且高效的RLHF框架.” CoRR, abs/2409.19256.
Noah Shinn, Beck Labash, 和 Ashwin Gopinath. 2023. “Reflexion: 具有动态记忆和自我反思的自主代理.” CoRR, abs/2303.11366.
Kumar Shridhar, Alessandro Stolfo, 和 Mrinmaya Sachan. 2023. “将推理能力蒸馏到更小的语言模型中.” 在计算语言学协会发现论文集:ACL 2023,第7059-7073页. 计算语言学协会。
Charlie Snell, Jaehoon Lee, Kelvin Xu, 和 Aviral Kumar. 2024. “最优扩展LLM测试时计算比扩展模型参数更有效.” CoRR, abs/2408.03314.
Yifan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, 和 Bill Yuchen Lin. 2024. “试错:基于探索的轨迹优化用于LLM代理.” CoRR, abs/2403.02502.
Zhengyang Tang, Xingxing Zhang, Benyou Wang, 和 Furu Wei. 2024. “MathScale: 数学推理的指令微调扩展.” 第四十一届国际机器学习会议论文集. OpenReview.net.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian CantonFerrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurélien Rodriguez, Robert Stojnic, Sergey Edunov, 和 Thomas
Scialom. 2023. “Llama 2: 开放的基础和微调聊天模型.” CoRR, abs/2307.09288.
Luong Quoc Trung, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, 和 Hang Li. 2024. “ReFT: 使用强化微调进行推理.” 在第62届年度计算语言学协会会议论文集,第7601-7614页. 计算语言学协会。
Chaojie Wang, Yanchen Deng, Zhiyi Lv, Zeng Liang, Jujie He, Shuicheng Yan, 和 Bo An. 2024a. “Q*: 使用深思熟虑规划改进LLMs的多步推理.” CoRR, abs/2406.14283.
Chengyu Wang, Junbing Yan, Wei Zhang, 和 Jun Huang. 2023a. “迈向更好的大型语言模型高效微调:立场文件.” CoRR, abs/2311.13126.
Hongru Wang, Yujia Qin, Yankai Lin, Jeff Z. Pan, 和 Kam-Fai Wong. 2024b. “赋能大型语言模型:现实世界交互的工具学习.” 在第47届国际ACM SIGIR信息检索研究与发展会议论文集,第2983-2986页. ACM.
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, 和 Zhifang Sui. 2024c. “Math-Shepherd: 无需人工注释逐步验证和强化LLMs.” 在第62届年度计算语言学协会会议论文集,第9426-9439页. 计算语言学协会。
Tianlong Wang, Junzhe Chen, Xueting Han, 和 Jing Bai. 2024d. “CPL: 关键规划步骤学习提升LLM在推理任务中的泛化能力.” CoRR, abs/2409.08642.
Xinru Wang, Hannah Kim, Sajjadur Rahman, Kushan Mitra, 和 Zhengjie Miao. 2024e. “通过有效验证LLM标签实现人类-LLM协作注释.” 在CHI计算系统中的人为因素会议论文集,第303:1-303:21页. ACM.
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, 和 Denny Zhou. 2023b. “自一致性改进了语言模型中的链式思维推理.” 在第十一届国际学习表征会议论文集中。
Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, 和 Heng Ji. 2024f. “释放大型语言模型中的新兴认知协同作用:通过多角色自我协作的任务解决代理.” 在第2024年北美计算语言学协会会议论文集:人类语言技术,第257-279页。
Zihan Wang, Yunxuan Li, Yuexin Wu, Liangchen Luo, Le Hou, Hongkun Yu, 和 Jingbo Shang. 2024g. “通过验证器进行多步问题求解:对模型诱导过程监督的经验分析.” 在计算语言学协会发现论文集:EMNLP 2024,第7309-7319页. 计算语言学协会。
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, 和 Denny Zhou. 2022. “链式思维提示激发了大语言模型中的推理.” 在第35届神经信息处理系统大会论文集中:2022年年度神经信息处理系统大会。
Sean Welleck, Ximing Lu, Peter West, Faeze Brahman, Tianxiao Shen, Daniel Khashabi, 和 Yejin Choi. 2023. “通过自我纠正生成序列.” 在第十一届国际学习表征会议论文集中。OpenReview.net.
Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, Haosheng Zou, Yongchao Deng, Shousheng Jia, 和 Xiangzheng Zhang. 2025. “Light-R1: 从零开始的长CoT课程监督的课程SFT、DPO和RL.” arXiv预印本 arXiv:2503.10460.
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, 和 Chi Wang. 2023a. “Autogen: 通过多代理对话框架启用下一代LLM应用.” CoRR, abs/2308.08155.
Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David S. Rosenberg, 和 Gideon Mann. 2023b. “BloombergGPT: 面向金融领域的大型语言模型.” CoRR, abs/2303.17564.
Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, 和 Yiming Yang. 2024. “语言模型解决问题的计算最优推理经验分析.” CoRR, abs/2408.00724.
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, 和 Michael Shieh. 2024. “蒙特卡洛树搜索通过迭代偏好学习提升推理.” CoRR, abs/2405.00451.
Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, James Xu Zhao, Min-Yen Kan, Junxian He, 和 Michael Qizhe Xie. 2023. “自评估引导波束搜索用于推理.” 在第36届神经信息处理系统大会论文集中:2023年年度神经信息处理系统大会。
Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, 和
Xiaodan Liang. 2024. “DeepSeek-Prover: 通过大规模合成数据推进定理证明在LLMs中的发展.” CoRR, abs/2405.14333.
Fengli Xu, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, Jiahui Gong, Tianjian Ouyang, Fanjin Meng, Chenyang Shao, Yuwei Yan, Qinglong Yang, Yiwen Song, Sijian Ren, Xinyuan Hu, Yu Li, Jie Feng, Chen Gao, 和 Yong Li. 2025. “走向大型推理模型:关于使用大型语言模型加强推理的调查.” CoRR, abs/2501.09686.
Junbing Yan, Chengyu Wang, Taolin Zhang, Xiaofeng He, Jun Huang, 和 Wei Zhang. 2023. “从复杂到简单:解开小型语言模型推理的认知树.” 在计算语言学协会发现论文集:EMNLP 2023,第12413-12425页. 计算语言学协会。
Yikuan Yan, Yaolun Zhang, 和 Keman Huang. 2024. “当你应该依赖自己时:通过RL代理指导LLM成为网络安全游戏的大师.” CoRR, abs/2403.17674.
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, 和 Zhenru Zhang. 2024a. “Qwen2.5-Math 技术报告:通过自我改进迈向数学专家模型.” CoRR, abs/2409.12122.
Kailai Yang, Tianlin Zhang, Ziyan Kuang, Qianqian Xie, Jimin Huang, 和 Sophia Ananiadou. 2024b. “Mentallama: 使用大型语言模型进行可解释的心理健康分析.” 在2024年ACM网络会议上发表的论文,第 4489 − 4500 4489-4500 4489−4500页。
Yizhe Yang, Huashan Sun, Jiawei Li, Runheng Liu, Yinghao Li, Yuhang Liu, Heyan Huang, 和 Yang Gao. 2023. “MindLLM: 从头开始预训练轻量级大型语言模型,评估和领域应用.” CoRR, abs/2310.15777.
Zhaorui Yang, Tianyu Pang, Haozhe Feng, Han Wang, Wei Chen, Minfeng Zhu, 和 Qian Liu. 2024c. “自蒸馏弥合语言模型微调中的分布差距.” 在第62届年度计算语言学协会会议论文集,第1028-1043页. 计算语言学协会。
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, 和 Karthik Narasimhan. 2023. “思维树:大型语言模型的深思熟虑问题解决.” 在第36届神经信息处理系统大会论文集:2023年年度神经信息处理系统大会。
Yunzhi Yao, Shaohan Huang, Wenhui Wang, Li Dong, 和 Furu Wei. 2021. “适应与蒸馏:开发小、快、有效的领域预训练语言模型.” 在计算语言学协会发现论文集:ACL/IJCNLP 2021,第 460 − 470 460-470 460−470页。
Huaiyuan Ying, Shuo Zhang, Linyang Li, Zhejian Zhou, Yunfan Shao, Zhaoye Fei, Yichuan Ma, Jiawei Hong, Kuikun Liu, Ziyi Wang, Yudong Wang, Zijian Wu, Shuaibin Li, Fengzhe Zhou, Hongwei Liu, Songyang Zhang, Wenwei Zhang, Hang Yan, Xipeng Qiu, Jiayu Wang, Kai Chen, 和 Dahua Lin. 2024. “InternLMMath: 开放性数学大型语言模型迈向可验证推理.” CoRR, abs/2402.06332.
Sha Yuan, Hanyu Zhao, Zhengxiao Du, Ming Ding, Xiao Liu, Yukuo Cen, Xu Zou, Zhilin Yang, 和 Jie Tang. 2021. “武道语料库:用于预训练语言模型的超大规模中文语料库.” AI Open, 2:65-68.
Weizhe Yuan, Jane Yu, Song Jiang, Karthik Padthe, Yang Li, Dong Wang, Ilia Kulikov, Kyunghyun Cho, Yuandong Tian, Jason E Weston, 和 Xian Li. 2025. “自然推理:在野外进行推理的280万挑战性问题.” CoRR, abs/2502.13124.
Shengbin Yue, Wei Chen, Siyuan Wang, Bingxuan Li, Chenchen Shen, Shujun Liu, Yuxuan Zhou, Yao Xiao, Song Yun, Xuanjing Huang, 和 Zhongyu Wei. 2023. “Disc-LawLLM: 微调大型语言模型以提供智能法律服务.” CoRR, abs/2309.11325.
Yuanhao Yue, Chengyu Wang, Jun Huang, 和 Peng Wang. 2024a. “构建低成本云上微调LLM的数据增强模型家族.” CoRR, abs/2412.04871.
Yuanhao Yue, Chengyu Wang, Jun Huang, 和 Peng Wang. 2024b. “通过任务感知课程规划蒸馏大型语言模型的指令跟随能力.” 在计算语言学协会发现论文集:EMNLP 2024,第6030-6054页. 计算语言学协会。
Eric Zelikman, Eliana Lorch, Lester Mackey, 和 Adam Tauman Kalai. 2023. “自我教学优化器(STOP):递归自我改进代码生成.” CoRR, abs/2310.02304.
Biao Zhang, Zhongtao Liu, Colin Cherry, 和 Orhan Firat. 2024a. “当扩展遇到LLM微调:数据、模型和微调方法的影响.” 在第十二届国际学习表征会议中。OpenReview.net.
Dan Zhang, Ziniu Hu, Sining Zhoubian, Zhengxiao Du, Kaiyu Yang, Zihan Wang, Yisong Yue, Yuxiao Dong, 和 Jie Tang. 2024b. “SciGLM: 使用自我反思指令标注和调整训练科学语言模型.” CoRR, abs/2401.07950.
Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, 和 Jie Tang. 2024c. “REST-MCTS*: 基于过程奖励引导的树搜索的LLM自训练.” 在第38届神经信息处理系统大会论文集:2024年年度神经信息处理系统大会。
Di Zhang, Wei Liu, Qian Tan, Jingdan Chen, Hang Yan, Yuliang Yan, Jiatong Li, Weiran Huang, Xiangyu Yue, Dongzhan Zhou, Shufei Zhang, Mao Su, Hansen Zhong, Yuqiang Li, 和 Wanli Ouyang. 2024d. “ChemLLM: 化学大型语言模型.” CoRR, abs/2402.06852.
Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jeffrey Xu Yu, 和 Tianlong Chen. 2024e. “Cut the Crap: 一种经济的LLM多代理系统通信管道.” CoRR, abs/2410.02506.
Jintian Zhang, Xin Xu, Ningyu Zhang, Ruibo Liu, Bryan Hooi, 和 Shumin Deng. 2024f. “探索LLM代理的合作机制:社会心理学视角.” 在第62届年度计算语言学协会会议论文集,第14544-14607页。
Qin Zhang, Ziqi Liu, 和 Shirui Pan. 2025a. “小型语言模型的崛起.” IEEE智能系统杂志,40(1):3037.
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, 和 Tuo Zhao. 2023a. “自适应预算分配用于参数高效微调.” 在第十一届国际学习表征会议中。OpenReview.net.
Shun Zhang, Zhenfang Chen, Yikang Shen, Mingyu Ding, Joshua B. Tenenbaum, 和 Chuang Gan. 2023b. “使用大型语言模型进行代码生成规划.” 在第十一届国际学习表征会议中。
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, 和 Junyang Lin. 2025b. “数学推理中开发过程奖励模型的经验教训.” CoRR, abs:2501.07301.
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, 和 Ji-Rong Wen. 2023. “大语言模型综述.” CoRR, abs:2303.18223.
Yu Zhao, Huifeng Yin, Bo Zeng, Hao Wang, Tianqi Shi, Chenyang Lyu, Longyue Wang, Weihua Luo, 和 Kaifu Zhang. 2024. “Marco-o1: 向开放式推理模型迈进以实现开放式解决方案.” CoRR, abs:2411.14405.
Zhengyun Zhao, Qiao Jin, 和 Sheng Yu. 2022. “PMCPatients: 从PubMed Central案例报告中提取的大规模患者笔记和关系数据集.” CoRR, abs:2202.13876.
Chuanyang Zheng, Zhengying Liu, Enze Xie, Zhenguo Li, 和 Yu Li. 2023. “渐进提示改进大型语言模型中的推理.” CoRR, abs:2304.09797.
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, 和 Yongqiang Ma. 2024. “LLM代理协作机制的探索:社会心理学视角.” CoRR, abs:2403.13372.
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, 和 Yu-Xiong Wang. 2024a. “语言代理树搜索统一了语言模型中的推理、行动和规划.” 在第四十一届国际机器学习会议中。
Zhi Zhou, Jiang-Xin Shi, Peng-Xiao Song, Xiaowen Yang, Yi-Xuan Jin, Lan-Zhe Guo, 和 Yufeng Li. 2024b. “LawGPT: 一个增强中国法律知识的大型语言模型.” CoRR, abs:2406.04614.
Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, 和 Bin Liu. 2024c. “大型语言模型作为强化学习代理的策略教师.” 在第三十三届国际人工智能联合会议论文集中,第5671-5679页。
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, 和 Jürgen Schmidhuber. 2024. “GPTSwarm: 作为可优化图的语言代理.” 在第四十一届国际机器学习会议中。
| 数据集关键 | 规模 | 注释者 | 相关论文 |
|---|---|---|---|
| FreedomIntelligence/medical-o1-reasoning-SFT | 25.4 K | GPT-40 | (Chen等人,2024b) |
| FreedomIntelligence/Medical-R1-Distill-Data | 22 K | DeepSeek-R1 | (Chen等人,2024b) |
| FreedomIntelligence/Medical-R1-Distill-Data-Chinese | 17 K | DeepSeek-R1 | (Chen等人,2024b) |
| facebook/natural reasoning | 2.8 M | Llama3.3-70B-Instruct | (Yuan等人,2025) |
| Congliu/Chinese-DeepSeek-R1-Distill-data-110k | 110 K | DeepSeek-R1 | |
| open-r1/codeforces-cots | 47.8 K | DeepSeek-R1 | |
| open-r1/OpenR1-Math-220k | 220 K | DeepSeek-R1 | |
| SmallDoge/SmallThoughts | 50 K | DeepSeek-R1 | |
| GeneralReasoning/GeneralThought-323K | 323 K | 多个 | |
| GeneralReasoning/GeneralThought-195K | 195 K | 多个 | |
| open-thoughts/OpenThoughts-114k | 114 K | DeepSeek-R1 | |
| bespokelabs/Bespoke-Stratos-17k | 17 K | DeepSeek-R1 | |
| simplescaling/s1K-1.1 | 1 K | DeepSeek-R1 | (Muennighoff等人,2025) |
| EricLu/SCP-116K | 116 K | o1-mini, QwQ-32B-Preview | (Lu等人,2025) |
表1:由LRMs注释的开源长CoT和输出数据集列表。
| 存储库 | URL |
|---|---|
| open-r1 | https://github.com/huggingface/open-r1 |
| trl | https://github.com/huggingface/trl |
| verl (Sheng等人,2024) | https://github.com/volcengine/verl |
| ReaLHF (Mei等人,2024) | https://github.com/openpsi-project/ReaLHF |
| AReaL (Mei等人,2025) | https://github.com/inclusionAI/AReaL |
| deepscaler | https://github.com/agentica-project/deepscaler |
| Light-R1 (Wen等人,2025) | https://github.com/Qihoo360/Light-R1 |
| Open-Reasoner-Zero (Wen等人,2025) | https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero |
| OpenRLHF (Hu等人,2024a) | https://github.com/OpenRLHF/OpenRLHF |
| LLaMA-Factory (Zheng等人,2024) | https://github.com/hiyouga/LLaMA-Factory |
表2:支持SRMs的RL训练的开源存储库列表。
参考论文:https://arxiv.org/pdf/2504.09100



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











