






Kimina-Prover Preview 技术报告
Numina & Kimi 团队
摘要
我们介绍了 Kimina-Prover Preview,这是一个大型语言模型,开创了形式定理证明中以推理驱动的探索范式,如本预览版本所示。该模型通过 Qwen2.5-72B 的大规模强化学习管道进行训练,在 Lean 4 证明生成方面表现出色,采用了我们称之为形式推理模式的结构化推理模式。这种方法使模型能够模仿人类在 Lean 中的问题解决策略,迭代生成和改进证明步骤。Kimina-Prover 在 miniF2F 基准测试中达到了新的最先进水平,在 pass @ 8192 下达到 80.7 % 80.7 \% 80.7% 。除了基准性能的提升,我们的工作还产生了几个关键见解:(1) Kimina-Prover 展现了高样本效率,即使在最小采样(pass@1)的情况下也能提供强劲结果,并能随着计算预算有效扩展,这源于其独特的推理模式和强化学习训练;(2) 我们展示了模型大小与性能之间的明确扩展趋势,这是以前神经定理证明器在形式数学中未观察到的现象;(3) 所学到的推理风格与传统搜索算法不同,显示出弥合形式验证和非正式数学直觉之间差距的潜力。我们开源了具有 1.5B 和 7B 参数的 Kimina-Prover 1 { }^{1} 1 的精简版本。
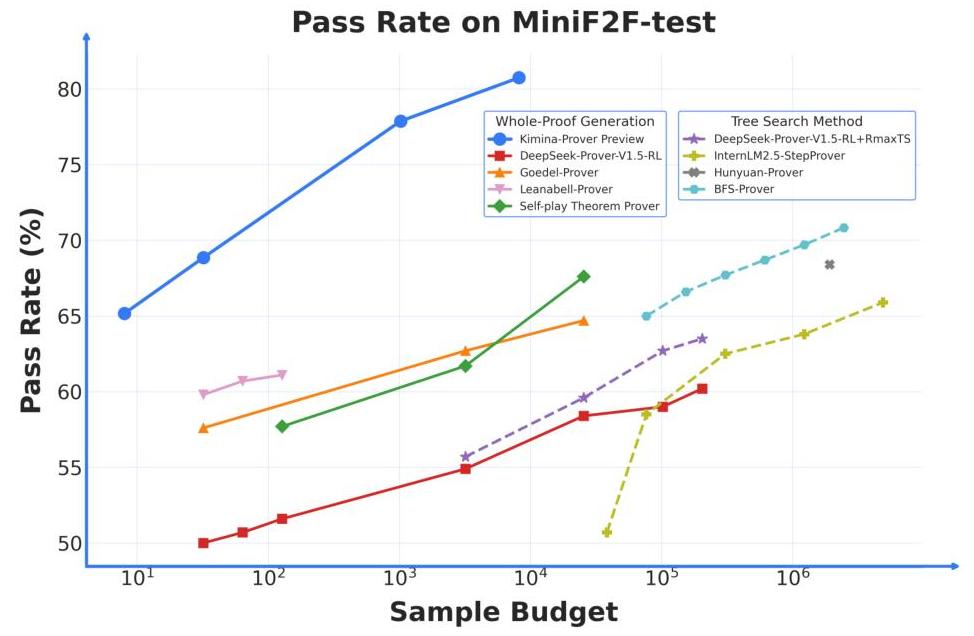
图 1:miniF2F-test 数据集上不同定理证明方法的性能比较。 x x x-轴显示样本预算(语言模型查询次数), y y y-轴显示通过率。方法分为两类:全证明生成和树搜索方法。结果显示 Kimina-Prover Preview 使用更少样本即可实现最高通过率,而树搜索方法通常需要更多样本才能达到类似性能。
1 { }^{1} 1 https://github.com/MoonshotAI/Kimina-Prover-Preview
1 引言
最近在神经定理证明方面的进展集中于利用大型语言模型(LLMs)来应对形式推理在证明助手中的固有挑战,例如 Lean 4(Moura 等人, 2021)或 Isabelle(Nipkow 等人, 2002)。最初的尝试集中在训练 LLMs 来生成交互式证明助手中的单个证明步骤或战术(Polu 等人, 2022; Wu 等人, 2024; H. Wang 等人, 2023; Deepmind, 2024),通常将 LLM 的预测能力与经典搜索算法(如最佳优先搜索(BFS)(Polu 等人, 2022; Wu 等人, 2024; R. Xin 等人, 2025)或蒙特卡罗树搜索(MCTS)(Lample 等人, 2022; H. Wang 等人, 2023; Deepmind, 2024)结合,以探索证明空间。其他策略涉及训练模型从给定状态生成完整的证明结构(H. Xin 等人, 2024; Y. Lin 等人, 2025; First 等人, 2023)。尽管取得了显著进展,这些现有方法仍面临重大挑战。对显式搜索算法(BFS、MCTS)的依赖引入了巨大的计算开销和复杂性,限制了可扩展性。此外,虽然 LLMs 在模式匹配和序列生成方面表现出色,但有效捕捉复杂形式证明所需的深度、结构化且通常是非线性的推理仍然困难。标准的监督微调或基本的链式思考提示可能不足以激发所需的复杂推理。至关重要的是,以前为形式数学定制的神经定理证明器通常未能展示出随着模型规模增加而对应的性能改善,表明它们利用更大模型容量增强推理的能力有限。一些作品(H. Lin 等人, 2025; R. Wang 等人, 2025)试图整合非正式推理提示,但通常依赖于较短的链式思考模式或未针对长篇推理通过强化学习优化的模型。
在这项工作中,我们介绍 Kimina-Prover Preview,代表早期尝试通过开创一种新的推理驱动探索范式来填补这一空白,专为 Lean 4 证明助手中的形式推理进行了具体调整。基于 Kimi k1.5 强化学习(RL)管道的成功经验,该管道已在复杂的非正式数学和编码任务中成功激发长链式思考推理(Kimi-Team 等人, 2025),Kimina-Prover 充分利用 LLM 内部推理能力,通过大规模 RL 和精心设计的奖励信号及结构化推理模式加以增强。这种方法使模型能够模仿人类问题解决策略,通过内部推理令牌引导的过程隐式探索证明空间并迭代生成和改进证明步骤。我们的贡献包括:
- 开创推理驱动探索。我们开创了将大规模强化学习应用于定理证明中以激发长链式思考推理的应用。
-
- 形式数学的有效模型扩展。我们展示了随着 LLM 尺寸增加,神经定理证明性能的明显提升,这种扩展效果在之前的系统中未曾观察到。
-
- 最先进的性能。如图 1 所示,Kimina-Prover 在 miniF2F 基准测试中达到 80.7 % 80.7 \% 80.7%,在 pass @ 8192 上显著超越 BFS Prover(R. Xin 等人, 2025)(72.95%)的先前最佳表现。
2 方法论
2.1 自动形式化构建多样化基础问题集
为了实现形式定理证明的在线强化学习,我们需要一组大量多样的 Lean 4 形式问题。手动构建这样的数据集成本高昂且耗时较长。为了解决这个问题,我们训练模型自动将自然语言问题陈述转换为语法正确的 Lean 4 代码,并以占位符证明结束。然而,这项任务存在一个根本挑战:缺乏具体的自动奖励信号。与证明搜索不同,成功可以很容易地通过是否证明了定理来定义,而生成的形式问题陈述相对于自然语言输入的正确性无法直接验证。我们的解决方案结合了仔细的初始化、监督微调以及带有 LLM 判断的结构化专家迭代过程,逐步提高质量。我们开源了我们的模型 Kimina-Autoformalizer-7B 并在附录 C.2 中详细说明了我们的训练方法。
2.2 形式推理模式
对于推理 LLM 在形式定理证明中取得优异表现的一个关键挑战是非正式数学推理数据与其翻译成形式证明之间的不一致性。为了解决这个问题,我们设计了一种新的形式推理模式,使 Kimina-Prover 能够在一个将非正式和形式数学推理对齐的环境中思考。在训练过程中,我们筛选响应,确保它们在 . . 标记之间格式化思考内容,并在选定的特殊标记之间输出最终证明。
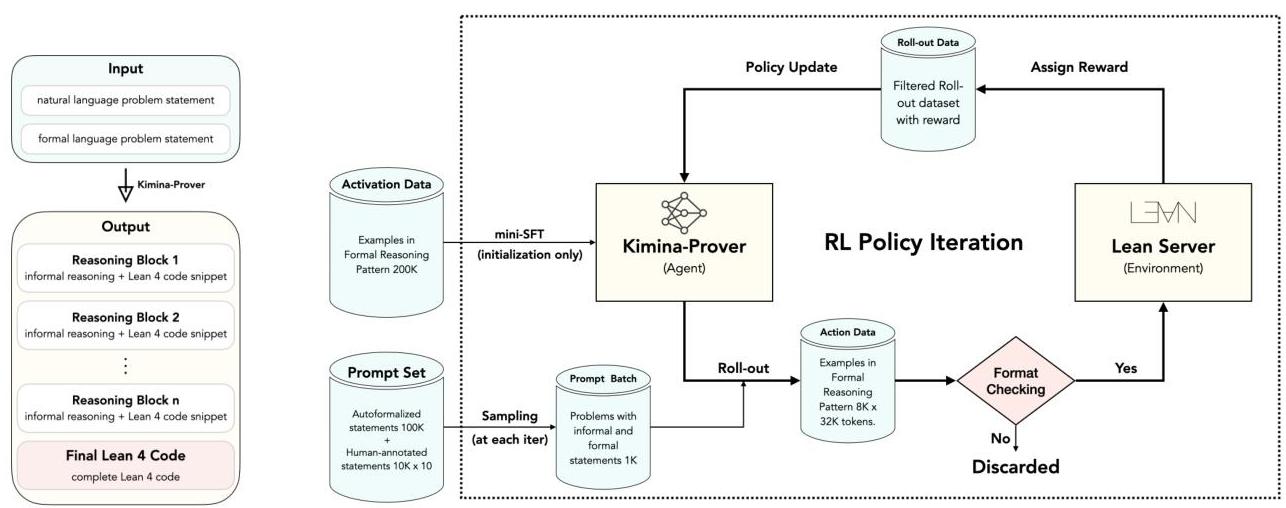
图 2:左。形式推理模式。右。形式 RL 流程。
在思考块内,我们通过插入非正式推理与相关的 Lean 4 代码片段,并用特殊标记标记,以实现非正式-形式对齐。为了强制思考块与最终证明对齐,我们确保大多数 Lean 4 代码片段出现在最终证明中。通过这种推理模式(见图 2 左侧),我们观察到输出令牌长度的扩展,这与我们在评估中得出的证明复杂性相关联。
此外,这种模式在推理解释性方面相较于基于搜索的证明器有了极大的改进。思考块允许用户检查模型在证明生成期间的内部过程。这提供了关于模型失败模式本质的具体见解,并作为最终用户的教育工具。
冷启动。为了启动模型根据我们的形式推理模式输出形式证明的能力,我们在开始强化学习训练循环之前执行了最小的监督微调运行。特别是,我们收集了一组奥林匹克风格的数学问题数据集,其中问题陈述和解答既有自然语言格式也有形式化的 Lean 4 表述。然后我们要求 Claude 3.7 Sonnet(Anthropic 2025)合成一个结合非正式和形式证明的思考块输出,从而生成大约 20K 示例的小型 SFT 数据集(我们尝试了几种 LLM,只有 Claude 的性能令人满意)。这显著提升了模型对非正式和形式推理步骤的对齐能力,并增强了 RL 阶段的下游性能。
非正式数学混合训练。为进一步加强模型初始的非正式数学能力,我们将 Kimi k1.5 的非正式数学思维数据纳入 SFT 训练。Claude 合成的数据展现出有限的反思模式范围。尽管在随后的 RL 训练中观察到了测试时间缩放和反思现象,但这些反思往往质量较低,表现为重复和无意义的短语。整合非正式思维数据旨在为生成更有意义的反思提供更好的起点。实际上,我们的 RL 阶段实验表明,使用这种混合数据训练的检查点显著优于仅基于形式推理数据训练的检查点。
2.3 强化学习
在监督微调(SFT)阶段之后,我们采用强化学习(RL)进一步增强模型的形式定理证明能力,如流程图(图 2)所示。RL 过程迭代优化模型策略。每次迭代从已建立的问题集中抽取一批 N = 1000 N=1000 N=1000 个问题开始。对于每个问题,当前策略生成 k = 8 k=8 k=8 个候选解(rollouts)。然后使用 Lean 编译器严格验证每个候选解的最终 Lean 4 代码以确定其正确性。分配二进制奖励信号:完全正确的证明得 1 分,否则得 0 分。按照 Kimi k1.5(Kimi-Team 等人, 2025)的方法,我们使用以下损失函数优化语言模型:
L
(
θ
)
=
E
(
x
,
y
∗
)
∼
D
[
E
(
y
,
z
)
∼
π
old
[
r
(
x
,
y
,
y
∗
)
−
τ
log
Z
−
τ
log
π
θ
(
y
,
z
∣
x
)
π
old
(
y
,
z
∣
x
)
]
]
L(\theta)=\mathbb{E}_{\left(x, y^{*}\right) \sim D}\left[\mathbb{E}_{(y, z) \sim \pi_{\text {old }}}\left[r\left(x, y, y^{*}\right)-\tau \log Z-\tau \log \frac{\pi_{\theta}(y, z \mid x)}{\pi_{\text {old }}(y, z \mid x)}\right]\right]
L(θ)=E(x,y∗)∼D[E(y,z)∼πold [r(x,y,y∗)−τlogZ−τlogπold (y,z∣x)πθ(y,z∣x)]]
其中
π
old
\pi_{\text {old }}
πold 是前一策略模型,归一化常数
log
Z
\log Z
logZ 实际上通过奖励的经验均值近似。在 RL 训练过程中,我们观察到在测试时形式推理的强大扩展。然而,由于 SFT 数据有限和形式结构问题,RL 格式在负梯度作用下容易崩溃。为了避免这种情况,我们应用格式过滤,设置了两个关键约束:(1) 每个生成样本必须至少包含一个战术块;(2) 战术块必须共同覆盖最终 Lean 4 解决方案中至少
60
%
60 \%
60% 的 Lean 代码。此外,为了对抗负梯度导致的格式崩溃,我们随机丢弃带有负梯度的样本(概率
ω
=
0.5
\omega=0.5
ω=0.5)。结合非正式数学数据的混合训练,这稳定了训练过程并促进了更复杂的形式推理。
实际上,我们的 RL 训练从 Qwen2.5-72B(Qwen-Team 2024)开始。我们保持恒定的学习率
(
2
×
1
0
−
6
)
\left(2 \times 10^{-6}\right)
(2×10−6) 和固定的 KL 散度系数
τ
=
0.4
\tau=0.4
τ=0.4(公式 1)。此 KL 约束确保在整个 RL 过程中,策略不会偏离初始监督策略。
3 结果
3.1 推理设置
基准。我们在 miniF2F 基准测试(K. Zheng 等人, 2022)上评估我们的模型,使用 DeepSeek-ProverV1.5 的 Lean 4 版本。为防止数据污染,我们在 Numina Math 1.5 训练集中明确移除所有 AMC12、AIME 和 IMO 问题,如果它们的来源与 miniF2F 测试集中的问题重叠。我们还识别并纠正了基准测试中的八个不可解问题(mathd_numbertheory_618, aime_1994_p3, amc12a_2021_p9, mathd_algebra_342, mathd_numbertheory_343, mathd_algebra_158, induction_port1p1on2powk1t5on2, induction_prod1p1onk3le3m1onn),并通过 Numina HuggingFace 仓库发布修正版本。评估使用 32K 令牌上下文长度和最多 8192 次尝试的采样预算,每次尝试独立采样。
蒸馏。我们通过展开 Kimina-Prover-Preview 模型的数据并进行 SFT,训练了参数为 1.5B 和 7B 的模型,分别初始化自 Qwen2.5-Math-1.5B-Instruct 和 Qwen2.5-Math-7B-Instruct。我们使用打包和余弦学习率调度
l
r
=
2
×
1
0
−
5
l r=2 \times 10^{-5}
lr=2×10−5 进行 3 个 epoch 的训练。
Lean 服务器。在我们的强化学习和评估管道中,我们集成了 Numina Lean Server(Numina 2025)作为验证后端,为生成的证明尝试提供实时反馈。基于 Lean FRO 的 LeanREPL(Lean FRO 2023),Numina Lean Server 使用基于 LRU 的缓存机制,根据导入头文件重用预加载环境,显著减少初始化开销。此外,它通过同时管理多个 Lean REPL 进程支持跨多个 CPU 的广泛并行化。这些创新使得验证吞吐量提高了
10
×
10 \times
10× ,在配备 64 核 CPU 和 512 GB RAM 的机器上每秒可达 100 次迭代。在 RL 训练中,此验证系统在 rollout 阶段高效运行,实时评估生成的证明。由于相对缓慢的证明生成过程,验证不会成为瓶颈,只需 640 个 CPU 核心即可完成训练。这种效率与以前的语言模型基定理证明方法形成对比,后者通常需要数千个 CPU 核心来维持大规模实时验证(Lample 等人, 2022; H. Xin 等人, 2024)。
3.2 性能分析
3.2.1 与最先进方法的比较
在 miniF2F 基准测试中,Kimina-Prover Preview 在所有评估系统中——包括整体证明生成和树搜索方法——实现了最先进的结果,达到
80.74
%
80.74 \%
80.74% miniF2F-test 准确率(见表 1)。重要的是,Kimina-Prover 即使在低通过率设置下也表现出色,并随着更高的采样预算有效扩展。仅 pass@1,模型就已经达到
52.94
%
52.94 \%
52.94%,而在 pass@32 时达到
68.85
%
68.85 \%
68.85%,已经与许多大样本基线竞争甚至超越,展现了卓越的样本效率。这种效率可以归因于 Kimina-Prover 的新型推理过程。不同于依赖显式步进搜索,Kimina-Prover 隐式地展平了步进搜索,允许模型决定如何和搜索什么。这种架构灵活性使得更针对性和动态的推理成为可能,从而以更少的样本实现更高性能。
另一个关键观察(见图 3)是我们的模型随着模型尺寸增加呈现出清晰的向上趋势——从 1.5B,到 7B,最后到 72B。特别是在更大的采样预算下,72B 变体显示出显著增益(在各自的采样预算下,72B 模型比 7B 版本高出
+
0.44
%
,
+
5.75
%
,
+0.44 \%, +5.75 \%,
+0.44%,+5.75%, 和
+
7.87
%
.
+7.87 \%.
+7.87%.)。据我们所知,这是第一个随着模型尺寸一致扩展性能的形式推理系统,表明 Kimina-Prover 不仅在计算上扩展,而且在其推理能力上也扩展。
| 定理证明系统 | 模型尺寸 | 样本预算 | miniF2F-test |
|---|---|---|---|
| 树搜索系统 | |||
| DeepSeek-Prover-V1.5-RL + RMaxTS (H. Xin 等人, 2024) | 7B | 32 × 16 × 400 32 \times 16 \times 400 32×16×400 | 63.5 % 63.5 \% 63.5% |
| InternLM2.5-StepProver-BF+CG (Wu 等人, 2024) | 7B | 256 × 32 × 600 256 \times 32 \times 600 256×32×600 | 65.9 % 65.9 \% 65.9% |
| HunyuanProver v16+BFS+DC (Y. Li 等人, 2025) | 7B | 600 × 8 × 400 600 \times 8 \times 400 600×8×400 | 68.4 % 68.4 \% 68.4% |
| BFS-Prover (R. Xin 等人, 2025) | 7B | 2048 × 2 × 600 2048 \times 2 \times 600 2048×2×600 | 70.8 % 70.8 \% 70.8% |
| 整体证明系统 | |||
| DeepSeek-Prover-V1.5-RL (H. Xin 等人, 2024) | 7B | 102400 | 60.2 % 60.2 \% 60.2% |
| Goedel-Prover-SFT (Y. Lin 等人, 2025) | 7B | 25600 | 64.7 % 64.7 \% 64.7% |
| Leanabell-Prover (Zhang 等人, 2025) | 7B | 128 | 61.1 % 61.1 \% 61.1% |
| 1 | 42.6 % 42.6 \% 42.6% | ||
| Kimina-Prover-Preview-Distill-1.5B | 1.5B | 32 | 56.2 % 56.2 \% 56.2% |
| 1024 | 61.9 % \mathbf{6 1 . 9 \%} 61.9% | ||
| Kimina-Prover-Preview-Distill-7B | 7B | 1 | 52.5 % 52.5 \% 52.5% |
| 32 | 63.1 % 63.1 \% 63.1% | ||
| 1024 | 70.8 % \mathbf{7 0 . 8 \%} 70.8% | ||
| 1 | 52.94 % 52.94 \% 52.94% | ||
| Kimina-Prover-Preview | 72B | 8 | 65.16 % 65.16 \% 65.16% |
| 32 | 68.85 % 68.85 \% 68.85% | ||
| 1024 | 77.87 % 77.87 \% 77.87% | ||
| 8192 | 80.74 % \mathbf{8 0 . 7 4 \%} 80.74% |
表 1:各种证明系统在模型尺寸、样本预算和 miniF2F-test 结果方面的性能。粗体表示在模型尺寸和计算预算下的最先进性能。
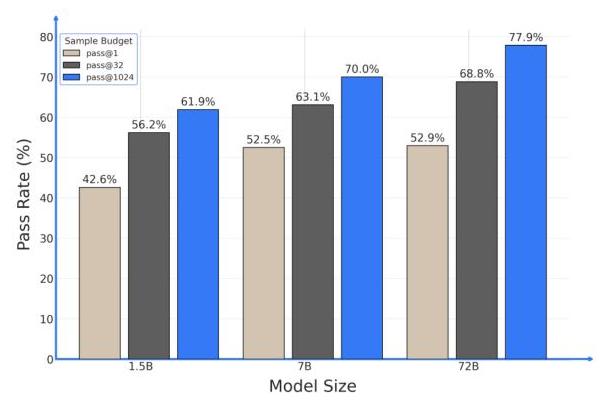
图 3:Kimina-Prover 模型在不同尺寸下的性能扩展。
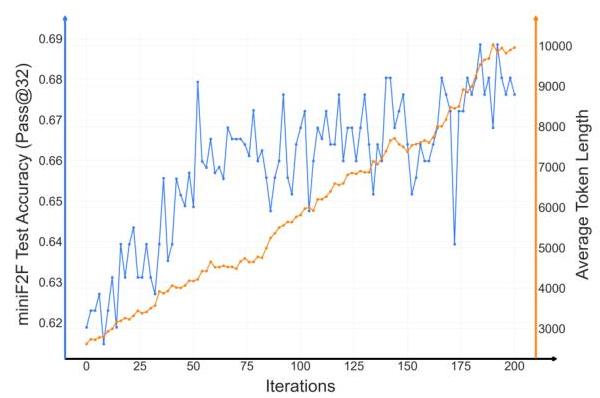
图 4:Kimina-Prover 在训练过程中的 miniF2F 准确率(pass@32)和平均输出令牌长度。
3.2.2 与通用目的 LLM 的比较
在表 2 中,我们将 Kimina-Prover 与领先的通用推理模型 OpenAI’s o3 和 Gemini 2.5 Pro 在 miniF2F 基准及其 IMO 和 AIME 子集上进行比较。尽管这些子集包含相对较简单、较旧的问题,Kimina-Prover 在各个方面都显著优于这两个模型。在 pass@32 下,KiminaProver 在 miniF2F 上达到 68.85 % 68.85 \% 68.85%,而 Gemini 达到 37.70 % 37.70 \% 37.70%,o3 达到 24.59 % 24.59 \% 24.59%。在 IMO 和 AIME 子集上,Kimina-Prover 分别得分 20.00 % 20.00 \% 20.00% 和 46.67 % 46.67 \% 46.67%,远远高于 Gemini( 5 % , 13.33 % 5 \%, 13.33 \% 5%,13.33%)和 o3( 0 % , 6.67 % 0 \%, 6.67 \% 0%,6.67%)。在 pass@8192 下,Kimina-Prover 进一步提升至 80.74 % , 40.00 % 80.74 \%, 40.00 \% 80.74%,40.00%(IMO)和 86.67 % 86.67 \% 86.67%(AIME)。这些结果突显了通用模型的核心局限性。o3 和类似的系统在形式推理中失败,默认采用非正式、不可验证的答案。Gemini 显示出形式推理能力,但经常出现幻觉并生成无效证明。相比之下,Kimina-Prover 始终生成可正式验证、Lean 可检查的证明,展示了准确性和推理能力。
| 基准 | 样本预算 | miniF2F | miniF2F/IMO | miniF2F/AIME |
|---|---|---|---|---|
| OpenAI o3-mini | 32 | 24.59 % 24.59 \% 24.59% | 0 % 0 \% 0% | 6.67 % 6.67 \% 6.67% |
| gemini-2.5-pro-preview-03-25 | 32 | 37.70 % 37.70 \% 37.70% | 5 % 5 \% 5% | 13.33 % 13.33 \% 13.33% |
| Kimina-Prover-Preview | 32 | 68.85 % 68.85 \% 68.85% | 20.00 % 20.00 \% 20.00% | 46.67 % 46.67 \% 46.67% |
| 8192 | 80.74 % 80.74 \% 80.74% | 40.00 % 40.00 \% 40.00% | 86.67 % 86.67 \% 86.67% |
表 2:在 miniF2F 的 IMO 和 AIME 子集上 SOTA 大型推理模型的性能比较。尽管 Gemini 2.5 和 Openai o3-mini 可以通过非正式推理解决 miniF2F 中的所有 15 个 AIME 问题,但这两个模型在形式化这些解决方案时都遇到困难。这突显了当前最先进模型在非正式推理能力和形式推理能力之间的显著差距。
3.2.3 非正式数学与形式数学之间的差距
一个特别有趣的发现是,我们的形式推理模型显示出强大的潜力来弥合非正式数学与形式数学之间的差距。如表 2 所示,尽管通用推理模型如 Gemini-2.5-pro 和 o3-mini 能够在非正式设置下解决 miniF2F 中的所有 AIME 问题,但在形式数学方面表现显著较低。这种差异表明,将一般数学问题解决中的领域知识转移到形式数学推理仍然是一个具有挑战性的任务。相比之下,Kimina-Prover 的形式推理能力表明,形式数学不仅可以用于验证,还可以补充和增强非正式推理,而不是孤立存在。通过在形式系统中学习推理,模型似乎获得了更深的结构理解,这反过来可能有助于非正式数学问题解决。这为未来的研究方向打开了令人兴奋的可能性,即形式数学不仅可用于验证,还可用于提升模型在非正式数学推理任务上的性能。
3.2.4 形式推理的测试时间扩展
推理模型的关键能力之一是其在增加测试时间预算时的改进能力。图 4 显示了 Kimina-Prover 的 miniF2F pass@32 准确率(蓝色)与其输出的平均令牌长度(橙色)在训练过程中的相关性。随着模型学会生成更长的证明——从 2,500 到超过 10,000 个令牌——其准确率从 61.8 % 61.8 \% 61.8% 提升到接近 69 % 69 \% 69%。与非正式数学模型通常平滑扩展不同,形式推理显示出更加波动的模式。准确性频繁跳跃,有时甚至退步,尤其是在 50-150 次迭代之间的中期阶段,可能是由于模型适应复杂、结构化的推理时受到有限形式训练数据的影响。这种动荡但最终成功的趋势表明,即使没有庞大的预训练语料库,形式推理仍然可以有效扩展。这种成功表明,类似的推理方法可能可以转移到其他在预训练期间领域知识有限的领域。
3.2.5 新兴的人类般的证明风格。
鉴于描述的形式推理模式,我们观察到在初始化和 RL 训练后,我们的模型表现出生成复杂推理模式的能力。这些包括探索多条推理路径、反思和改进其思考过程,以及分析小规模案例以揭示普遍模式(见附录 F)。此外,Kimina-Prover 生成的证明比以前基于步骤的证明器生成的证明更加分解和结构化。这体现在证明中丰富的 have 语句中,这是在人类编写的证明中常见的模式,旨在优化清晰度(见附录 E)。这些反思、分解和改进的行为随着问题难度的增加而有效扩展,使我们的方法相对于过度依赖现有 Lean 4 自动化工具的模型具有明显优势。
4 结论
总之,我们提出了 Kimina-Prover,一个通过结合自动化形式化、SFT 和 RL 与特定形式推理模式的训练配方开发的用于 Lean 4 定理证明的大规模推理模型。我们的主要发现表明,性能随着上下文长度和模型尺寸显著扩展——这一趋势在树搜索证明器中并不常见——从而达到了最先进水平(在 miniF2F pass@8192 上达到 80.74 % 80.74 \% 80.74%),计算资源适度。这强调了推理启用的神经证明器的潜力。有希望的未来方向包括通过过滤过度使用高级战术的输出来增强证明质量,利用 Lean 编译器反馈进行迭代改进以高效修复错误,以及集成外部工具如库搜索和计算引擎以缓解生成挑战。
参考文献
Anthropic. Claude 3.7 Sonnet System Card. https://anthropic.com/claude-3-7-sonnet-system-card. 2025. Azerbayev, Zhangir 等人. ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics. 2023. arXiv: 2302.12433 [cs.CL]. URL: https://arxiv.org/abs/2302.12433.
Deepmind. AI achieves silver-medal standard solving International Mathematical Olympiad problems. 2024. URL: https://deepmind.google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/.
DeepSeek-AI. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. 2025. arXiv: 2501.12948 [cs.CL]. URL: https://arxiv.org/abs/2501.12948.
First, Emily 等人. Baldur: Whole-Proof Generation and Repair with Large Language Models. 2023. arXiv: 2303.04910 [cs.LG]. URL: https://arxiv.org/abs/2303.04910.
Huang, Yinya 等人. MUSTARD: Mastering Uniform Synthesis of Theorem and Proof Data. 2024. arXiv: 2402.08957 [cs.AI]. URL: https://arxiv.org/abs/2402.08957.
Jiang, Albert Q. 等人. Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs. 2023. arXiv: 2210.12283 [cs.AI]. URL: https://arxiv.org/abs/2210.12283.
Jiang, Albert Q., Wenda Li, 和 Mateja Jamnik. Multilingual Mathematical Autoformalization. 2023. arXiv: 2311. 03755 [cs.CL]. URL: https://arxiv.org/abs/2311.03755.
Kimi-Team 等人. “Kimi k1.5: Scaling reinforcement learning with llms”. In: arXiv preprint arXiv:2501.12599 (2025).
Lample, Guillaume 等人. “HyperTree Proof Search for Neural Theorem Proving”. In: Advances in Neural Information Processing Systems. Ed. by S. Koyejo 等人. Vol. 35. Curran Associates, Inc., 2022, pp. 26337-26349. URL: //proceedings.neurips.cc/paper_files/paper/2022/file/a8901c5e85fb8e1823bbf0f755053672-Paper-Conference.pdf.
Lean FRO. A read-eval-print-loop for Lean 4. https://github.com/leanprover-community/repl. 2023.
Li, Jia 等人. NuminaMath. https://github.com/project-numina/aimo-progress-prize/blob/main/ report/numina_dataset.pdf. GitHub repository. 2024.
Li, Yang 等人. HunyuanProver: A Scalable Data Synthesis Framework and Guided Tree Search for Automated Theorem Proving. 2025. arXiv: 2412.20735 [cs.AI]. URL: https://arxiv.org/abs/2412.20735.
Lin, Haohan 等人. “Lean-STaR: Learning to Interleave Thinking and Proving”. In: The Thirteenth International Conference on Learning Representations. 2025. URL: https://openreview.net/forum?id=50WZ590y8c.
Lin, Yong 等人. Goedel-Prover: A Frontier Model for Open-Source Automated Theorem Proving. 2025. arXiv: 2502. 07640 [cs.LG]. URL: https://arxiv.org/abs/2502.07640.
Moura, Leonardo de 和 Sebastian Ullrich. “The Lean 4 Theorem Prover and Programming Language”. In: Automated Deduction - CADE 28: 28th International Conference on Automated Deduction, Virtual Event, July 12-15, 2021, Proceedings. Berlin, Heidelberg: Springer-Verlag, 2021, pp. 625-635. ISBN: 978-3-030-79875-8. DOI: 10.1007/978-3-030-79876-5_37. URL: https://doi.org/10.1007/978-3-030-79876-5_37.
Nipkow, Tobias, Lawrence C Paulson, 和 Markus Wenzel. Isabelle/HOL: a proof assistant for higher-order logic. Vol. 2283. Springer Science & Business Media, 2002.
Numina. Numina Lean Server: Technical Report. arXiv preprint forthcoming. 2025.
OpenAI 等人. OpenAI o1 System Card. 2024. arXiv: 2412.16720 [cs.AI]. URL: https://arxiv.org/abs/2412. 16720 .
Polu, Stanislas 等人. Formal Mathematics Statement Curriculum Learning. 2022. arXiv: 2202.01344 [cs.LG]. URL: https://arxiv.org/abs/2202.01344.
Qwen-Team. Qwen2.5: A Party of Foundation Models. Sept. 2024. URL: https://qwenlm.github.io/blog/qwen2.
5
/
5 /
5/.
Renshaw, David. Compfiles: Catalog Of Math Problems Formalized In Lean. https://github.com/dwrensha/ compfiles. GitHub repository. 2024.
Tsonkalas, George 等人. PutnamBench: Evaluating Neural Theorem-Provers on the Putnam Mathematical Competition. 2024. arXiv: 2407.11214 [cs.AI]. URL: https://arxiv.org/abs/2407.11214.
Wang, Haiming 等人. “Dt-solver: Automated theorem proving with dynamic-tree sampling guided by proof-level value function”. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023, pp. 12632-12646.
Wang, Haiming, Huajian Xin, Zhengying Liu, 等人. Proving Theorems Recursively. 2024. arXiv: 2405.14414 [cs.AI]. URL: https://arxiv.org/abs/2405.14414.
Wang, Haiming, Huajian Xin, Chuanyang Zheng, 等人. LEGO-Prover: Neural Theorem Proving with Growing Libraries. 2023. arXiv: 2310.00656 [cs.AI]. URL: https://arxiv.org/abs/2310.00656.
Wang, Ruida 等人. MA-LoT: Multi-Agent Lean-based Long Chain-of-Thought Reasoning enhances Formal Theorem Proving. 2025. arXiv: 2503.03205 [cs.CL]. URL: https://arxiv.org/abs/2503.03205.
Wu, Zijian 等人. InternLM2.5-StepProver: Advancing Automated Theorem Proving via Expert Iteration on Large-Scale LEAN Problems. 2024. arXiv: 2410.15700 [cs.AI]. URL: https://arxiv.org/abs/2410.15700.
Xin, Huajian 等人. DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search. 2024. arXiv: 2408.08152 [cs.CL]. URL: https://arxiv.org/abs/2408.08152.
Xin, Ran 等人. BFS-Prover: Scalable Best-First Tree Search for LLM-based Automatic Theorem Proving. 2025. arXiv: 2502.03438 [cs.AI]. URL: https://arxiv.org/abs/2502.03438.
Zhang, Jingyuan 等人. Leanabell-Prover: Posttraining Scaling in Formal Reasoning. 2025. arXiv: 2504.06122 [cs.AI]. URL: https://arxiv.org/abs/2504.06122.
Zheng, Kunhao, Jesse Michael Han, 和 Stanislas Polu. MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics. 2022. arXiv: 2109.00110 [cs.AI]. URL: https://arxiv.org/abs/2109.00110.
A 贡献
Numina
Jia Li*
Mert Unsal*
Mantas Baksys*
Marco Dos Santos*
Marina Vinyes*
Zhenzhe Ying*
Zekai Zhu*
Jianqiao Lu*
Hugues de Saxcé*
Bolton Bailey
Ebony Zhang
Frederick Pu
Jiawei Liu
Jonas Bayer
Julien Michel
Léo Dr------
eyfus-Schmidt
Lewis Tunstall
Luigi Pagani
Moreira Machado
Pauline Bourigault
Ran Wang
Stanislas Polu
Thibaut Barroyer
Wen-Ding Li
Yazhe Niu
Yann Fleureau
Zhouliang Yu
Kimi 团队
Haiming W
------ang*
Zhengying Liu*
Xiaohan Lin*
Junqi Liu*
Flood Sung*
Chendong Song
Chenjun Xiao
Dehao Zhang
Han Zhu
Longhui Yu
Yangyang Hu
Zhilin Yang
Zihan Wang
名字标记有星号(*)的表示核心贡献者。其他作者按照名字首字母顺序排列。
B 相关工作
最近在自动定理证明方面的研究已经将大型语言模型与形式证明助手(如 Lean 4)相结合。这些系统通常采用训练过的语言模型来生成单独的证明步骤(Lample 等人, 2022; Polu 等人, 2022; Deepmind, 2024; H. Wang 等人, 2023; Wu 等人, 2024; R. Xin 等人, 2025; Y. Lin 等人, 2025; H. Wang, H. Xin, Liu 等人, 2024),或者从给定的证明状态生成完整的证明完成(H. Xin 等人, 2024; Y. Lin 等人, 2025; First 等人, 2023; Huang 等人, 2024; H. Wang, H. Xin, C. Zheng 等人, 2023; Jiang 等人, 2023a)。
为了增强证明搜索中的探索能力,这些基于语言模型的方法经常与经典树搜索算法结合使用,例如最佳优先搜索(Polu 等人, 2022; Wu 等人, 2024; R. Xin 等人, 2025)和蒙特卡罗树搜索(Lample 等人, 2022; H. Wang 等人, 2023; Deepmind, 2024)。搜索组件在这些系统中扮演了核心角色,因为它根据启发式评估指导有希望的证明路径的探索和选择。这种混合方法从启发式驱动的探索中显著受益,但会带来巨大的计算开销。
大规模强化学习最近被应用于改进语言模型的推理能力,以 OpenAI 的 o1(OpenAI 等人, 2024)、DeepSeek 的 R1(DeepSeek-AI 2025)和 Kimi 的 k1.5(Kimi-Team 等人, 2025)为代表的模型,通过在精心设计的奖励信号上进行广泛的强化学习,展现出新兴的长链思考推理行为,使它们能够在复杂的数学和编码任务中取得令人印象深刻的结果,包括像 AIME 和 Codeforces 这样的竞赛。这些成就强调了长期、结构化推理克服困难推理问题的潜力。
一些最近的工作试图将非正式推理与形式定理证明结合起来。例如,H. Lin 等人 2025 提出在预测单个战术之前生成非正式想法,而 R. Wang 等人 2025 则在 Lean 4 中采用了非正式自然语言推理与形式验证之间的结构化交互。然而,这些
以前的尝试要么依赖于传统的短格式链式思考推理,要么依赖于通过从一般推理任务转移学习和监督微调训练的推理模型,而不是强化学习。在我们的工作之前,直接在形式定理证明中应用 RL 驱动的长格式推理的可行性和有效性尚未被探索。
C Kimina-Prover 的训练细节
C. 1 非正式数据集
非正式数据集作为我们管道的基础层,直接输入到大型形式推理模型的监督微调(SFT)和强化学习(RL)中。下面,我们概述了将原始非正式数学数据集转换为用于训练我们模型的精制提示集的数据处理步骤。
我们的非正式数据管道包括以下步骤:
- 初始数据集获取:我们从 Numina 1.5 数据集(J. Li 等人, 2024)开始,这是一个全面的数学问题集合。
-
- 过滤和预处理:我们根据特定标准过滤此数据集,仅保留明确分类为证明或具有显式数值或符号输出的问题。排除涉及几何和组合学的问题,以形成更适合自动化形式化的数据集。这个过滤后的数据集被标记为 auto-statement-candidates。
-
- 自动形式化:auto-statement-candidates 数据集经过自动形式化过程,生成 auto-statements 数据集。这一步将自然语言数学问题转换为与 Lean 4 证明助手兼容的形式陈述。
-
- 人工注释和细化:为确保形式化的质量和精度,我们组建了一个专门的注释团队,负责审查和改进自动形式化过程的输出。注释输出被分类如下:
- 人类陈述:由人类注释者改进的陈述。
-
- 人类证明:由领域专家注释的精选、具有挑战性的陈述附加形式证明。这些证明构成了我们监督微调(SFT)数据集的重要部分。
- 提示集创建:来自 auto-statements 和 human statements 数据集的精制形式化陈述被合并以形成我们的最终提示集。经过验证和证明的形式陈述随后丰富了 SFT 数据集,创造了持续改进的动态循环,以支持后续迭代的强化学习。
这种结构化和迭代的方法确保了稳健的数据质量,促进了后续阶段的有效模型训练和迭代改进。
C. 2 Kimina-Autoformalizer 训练细节
C.2.1 模型初始化
我们首先创建一个用于自动形式化的监督微调数据集,以教导模型竞争级别 Lean 4 问题的结构和风格。该数据集汇总了多个来源的正式问题对:PutnamBench、miniF2F、ProofNet 和 Compfiles(Renshaw 2024)(K. Zheng 等人, 2022)(Tsoukalas 等人, 2024)(Azerbayev 等人, 2023)。我们消融了每个来源的贡献,并发现所有来源都对下游性能有积极贡献。特别是,包括 Mathlib 数据(如 MMA 数据集(Jiang 等人, 2023b)——LLM 生成的 Mathlib 非正式化版本)降低了性能。我们假设两个关键原因:(1) Mathlib 中的数学内容在性质和语气上与竞赛问题有很大不同;(2) Mathlib 陈述通常涉及辅助变量并依赖外部定义,这可能会在生成过程中混淆模型。我们的初始化是 Qwen2.5-Coder-7B-Instruct 在精选数据集上的微调版本,能够从非正式描述生成语法正确的 Lean 4 问题陈述。
C.2.2 带 LLM 评判者的专家迭代
在监督初始化之后,我们采用结构化的专家迭代循环来提高自动形式化模型的质量和覆盖范围。此循环使用 NuminaMath 1.5 数据集中具有挑战性的竞赛风格问题子集。对于每次迭代,我们首先从非正式问题中抽取小批量样本。对于每个问题,模型生成若干候选形式化方案。这些方案经过筛选后只保留那些在
Lean 4 中成功编译的方案。然后我们使用 QwQ-32B 作为评判者来评估每个剩余形式化的语义正确性,使用手工制作的提示来引导其评估。我们观察到使用多个样本和一致投票结构显著减少了误报的数量,对真正阳性的影响很小。通过编译和评判阶段的形式化方案被添加到训练数据集中,并执行一次训练步骤。
由于此任务中的奖励信号本质上是模糊的,且基于 LLM 的反馈容易产生误报,我们在整个训练过程中监控模型输出,并在迭代中逐步改进评判者提示。这使我们能够保持对数据质量的细粒度控制。随着我们的证明基础设施不断改进,我们还引入了自动过滤器以丢弃有问题的形式化方案。这些包括检测逻辑矛盾、证明形式化陈述的否定、或通过短 LLM 生成的证明识别问题是平凡的。这些保障措施有助于确保训练集既具有挑战性又正确,引导模型在未来迭代中实现有意义的改进。
C.2.3 Kimina-Autoformalizer 性能
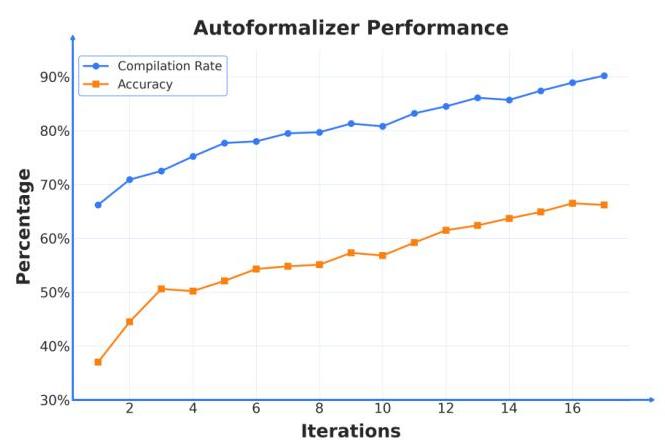
图 5:各次迭代中自动形式化器的性能。
为了评估我们的自动形式化器,我们使用一个人工策划的测试集,大小约为 1,000,并在此集上优化 LLM 评判者提示以获得可靠结果。在每次迭代后,我们使用贪婪解码为每个问题生成一种自动形式化方案。我们跟踪两个指标:(1) Lean 4 编译率和 (2) 自动形式化准确率,定义为既编译又被 LLM 判定正确的样本百分比。我们可以从图表中看到,随着迭代的进行,性能稳步且可靠地提高,达到了
90
%
90 \%
90% 的一次性编译率和
66
%
66 \%
66% 的准确率。
我们评估了几种现有的自动形式化模型,但发现大多数难以始终生成有效的 Lean 4 代码。相反,这些模型主要生成 Lean 3 语法,我们将这一限制归因于它们预训练数据的组成。在这些 LLMs 的知识截止日期之前,Lean 3 占据了在线存储库和文档的主要地位,而语法差异较大的 Lean 4 则相对较新且代表性不足。这种训练数据的不平衡导致没有针对特定 Lean 4 进行微调的模型默认采用更熟悉的 Lean 3 模式。比较模型无法以有意义的比率生成可编译的 Lean 4 代码,最终阻止我们建立与现有方法公平的基准,突显了在新兴形式语言中工作的挑战。
我们注意到这种方法需要仔细的专家监控,因为我们观察到只要模型通过编译,模型就会反复犯 LLM 评判模型无法捕捉的错误。我们认为这在非可验证领域中应用强化学习提出了重大挑战。
C. 3 问题集
在本节中,我们详细说明了我们问题集的创建过程,这是我们强化学习管道的一个基础组成部分。提示集由两个不同的子集组成:一个来自自动形式化模型,另一个由人工注释的陈述组成。为了确保问题集难度平衡,我们利用 QwQ-32B 预览模型为每个问题分配难度评分,并据此构建难度分布均匀的数据集。
鉴于我们的人工注释陈述数量有限——大约 10k——相比自动生成的 100k,我们在训练中优先考虑高质量数据。因此,我们重新采样我们的注释集,以实现与自动形式化子集 1:1 的比例,从而生成总问题数为 200k 的平衡且高质量的问题集。
为了进一步提高强化学习管道的效率和效果,我们采用以下策略迭代改进提示集:
通过否定证明进行错误过滤。我们使用 DeepSeek-Prover 的否定证明来识别并从问题集中移除潜在的错误形式化方案。
自适应问题修剪。在特定的强化学习迭代后,我们修剪模型一贯表现出高熟练度的问题。这种自适应修剪允许模型将计算资源集中在越来越具有挑战性和信息量丰富的問題上,促进形式推理能力的持续改进。
困难问题的注释管道。对于形式化错误的陈述或非常困难的问题,我们将其发送到注释管道,由人工注释者进行额外的陈述和证明注释。这确保了具有挑战性的问题不会被丢弃,而是得到适当的人工监督。
后 RL 验证。在强化学习训练后,我们使用评判模型评估模型生成的证明是否正确,或者模型是否仅仅利用了形式化中的错误。这一步确保生成证明的完整性和可靠性。
D Kimina-Prover 发现的证明示例
D. 1 新证明的 IMO 问题来自 miniF2F 基准
Kimina-Prover 成功证明了一个 IMO 问题(imo_1968_p5_1),这是以前从未解决过的公开发布的模型。我们展示了 Kimina-Prover 生成的证明。此证明显示了模型计划其证明草图的出色能力。此类输出中的新兴行为表明,与之前的模型相比,推理能力有了明显的改进。例如,在此证明中,模型首先陈述了一个关键的辅助引理 h2,并继续在多行中证明它。接着通过 (use 2 ∗ 2 * 2∗ a) 策略猜测正确答案。证明通过一个复杂的推理链完成,其中先前证明的引理 h2 是完成证明的关键和必要条件。
theorem imo_1968_p5_1 (a : \(\mathbb{R})\left(\mathrm{f}: \mathbb{R} \rightarrow \mathbb{R}\right)\left(\mathrm{h}_{0}: 0<\mathrm{a}\right)\)
\(\left(h_{1}: \forall x, f(x+a)=1 / 2+\right.\) Real.sqrt \(\left(f x-f x^{\wedge} 2\right)): \exists b>0, \forall x, f(x+b)=f x:=\) by
have \(\mathrm{h} 2: \forall \mathrm{x}, 0 \leq \mathrm{f} \mathrm{x} \wedge \mathrm{f} \mathrm{x} \leq 1:=\mathrm{by}\)
intro \(x\)
have \(\mathrm{h} 1:=\mathrm{h}_{1}(\mathrm{x}-\mathrm{a})\)
rw [show \(\mathrm{x}-\mathrm{a}+\mathrm{a}=\mathrm{x}\) by ring] at \(\mathrm{h} 1\)
have h3 : \(0 \leq\) Real.sqrt \(\left(f(x-a)-f(x-a)^{\wedge} 2\right):=\) Real.sqrt_nonneg \(\left(f(x-a)-f(x-\right.\)
a) ^ 2 )
have h4 : f x = 1 / 2 + Real.sqrt (f (x - a) - f (x - a) ^ 2) := by linarith
have h5 : f x \(\leq 1:=\) by
have h6 : Real.sqrt (f (x - a) - f (x - a) ^ 2) \(\leq 1 / 2:=\) by
have h7 : f (x - a) - f (x - a) ^ \(2 \leq 1 / 4:=\) by
nlinarith [sq_nonneg (f (x - a) - 1 / 2)]
have h8 : \(0 \leq\) Real.sqrt (f (x - a) - f (x - a) ^ 2) := Real.sqrt_nonneg (f (x - a) - f (x
- a) ^ 2)
- have h9 : Real.sqrt (f (x - a) - f (x - a) ^ 2) \(\leq\) Real.sqrt (1 / 4 : \(\mathbb{R}):=\)
- Real.sqrt_le_sqrt (by linarith)
- have h10 : Real.sqrt \((1 / 4: \mathbb{R})=1 / 2:=\) by
- rw [Real.sqrt_eq_iff_sq_eq] <;> norm_num
- linarith
- linarith [h4, h6]
- have h11 : \(0 \leq \mathrm{f} \mathrm{x}:=\mathrm{by}\)
- nlinarith [Real.sqrt_nonneg (f (x - a) - f (x - a) ^ 2), h4]
- exact \(\langle\mathrm{h} 11, \mathrm{~h} 5)\)
- use \(2 * \mathrm{a}\)
- constructor
- linarith \(\left[\mathrm{h}_{0}\right]\)
- intro x
- ```
- ```
- have h3 := h; (x + a)
- have h4 := h; x
- rw [show x + a + a = x + 2 * a by ring] at h3
- have h5 : f (x + 2 * a) = 1 / 2 + Real.sqrt (f (x + a) - f (x + a) ^ 2) := by linarith
- have h6 : f (x + a) - f (x + a) ^ 2 = (f x - 1 / 2) ^ 2 := by
- have h7 : f (x + a) = 1 / 2 + Real.sqrt (f x - f x ^ 2) := by linarith
- rw [h7]
- ring_nf
- rw [Real.sq_sqrt (by nlinarith [h2 x])]
- ring
- rw [h6] at h5
- have h7 : Real.sqrt ((f x - 1 / 2) ^ 2) = abs (f x - 1 / 2) := by
- rw [Real.sqrt_sq_eq_abs]
- have h8 : abs (f x - 1 / 2) = f x - 1 / 2 := by
- have h9 : f x \geq 1 / 2 := by
- have h10 := h; (x - a)
- rw [show x - a + a = x by ring] at h10
- have h11 : Real.sqrt (f (x - a) - f (x - a) ^ 2) \geq 0 := Real.sqrt_nonneg (f (x - a) - f
- (x - a) ^ 2)
- linarith [h10, h11]
- apply abs_of_nonneg
- linarith
- rw [h7, h8] at h5
- linarith [h5]
- ```
列表 1:Kimina-Prover 找到的 IMO 1968 P5(第一部分)的 Lean 4 证明。
# D. 2 AIME 问题的证明示例
Kimina-Prover 在形式定理证明领域中擅长解决复杂的三角方程。这一点在它对 aime_1991_p9 的证明中得到了体现。给定初始假设 h0 表述为:h0 : 1 / Real.cos x + Real. tan $\mathrm{x}=22 / 7$,模型能够使用三角恒等式
have h3 : Real.sin x ^ 2 + Real.cos x ^ 2 = 1 := Real.sin_sq_add_cos_sq x
推导出正弦和余弦函数的值。
have h_cos : Real.cos x = 308 / 533 := by nlinarith [h_cos_sq]
have h_sin’ : Real.sin x = 435 / 533 := by
have h9 : Real.sin x = (22 * Real.cos x - 7) / 7 := h_sin
rw [h9, h_cos]
norm_num
从这里,模型将这些推导出的值代入 h1: h1 : 1 / Real.sin x + 1 / Real. $\tan \mathrm{x}=\mathrm{m}$。在此步骤之后,它成功地结束了证明,显示出对代数技巧的强大掌握。
theorem aime_1991_p9 (x : R) (m : Q) (h0 : 1 / Real.cos x + Real.tan x = 22 / 7)
(h1 : 1 / Real.sin x + 1 / Real.tan x = m) : \m.den + m.num = 44 := by
have h2 : Real.cos x \neq 0 := by
by_contra h
have h3 : 1 / Real.cos x = 0 := by
field_simp [h]
have h4 : Real.tan x = 0 := by
rw [Real.tan_eq_sin_div_cos]
simp [h]
have h5 : (22 : R) / 7 = 0 := by linarith [h;, h3, h4]
norm_num at h5
have h_tan : Real.tan x = Real.sin x / Real.cos x := by
rw [Real.tan_eq_sin_div_cos]
have h3 : Real.sin x ^ 2 + Real.cos x ^ 2 = 1 := Real.sin_sq_add_cos_sq x
have h4 : 1 / Real.cos x + Real.tan x = 22 / 7 := h
rw [h_tan] at h4
have h5 : 1 / Real.cos x + Real.sin x / Real.cos x = 22 / 7 := h4
have h6 : (1 + Real.sin x) / Real.cos x = 22 / 7 := by
have h7 : Real.cos x \neq 0 := h2
field_simp [h7] at h5
nlinarith
have h7 : 7 * (1 + Real.sin x) = 22 * Real.cos x := by
have h8 : Real.cos x \neq 0 := h2
field_simp at h6
nlinarith
have h_sin : Real.sin x = (22 * Real.cos x - 7) / 7 := by linarith
have h8 : Real.sin x ^ 2 + Real.cos x ^ 2 = 1 := Real.sin_sq_add_cos_sq x
have h9 : Real.sin x = (22 * Real.cos x - 7) / 7 := h_sin
have h_cos_sq : Real.cos x ^ 2 = (308 / 533) ^ 2 := by
have h10 : Real.cos x \neq 0 := h2
have h11 : Real.sin x = (22 * Real.cos x - 7) / 7 := h_sin
rw [h11] at h3
have h12 : ((22 * Real.cos x - 7) / 7) ^ 2 + Real.cos x ^ 2 = 1 := by linarith
have h13 : (22 * Real.cos x - 7) ^ 2 + (7 * Real.cos x) ^ 2 = 49 := by
nlinarith
have h14 : (Real.cos x) * (533 * Real.cos x - 308) = 0 := by
ring_nf at h13
linarith
cases' (mul_eq_zero.mp h14) with h_cos h15
- Real.cos x = 0
- exfalso
- exact h10 (by linarith)
- - 533 * Real.cos x - 308 = 0
- have h_cos : Real.cos x = 308 / 533 := by linarith
- nlinarith [h_cos]
- have h_cos : Real.cos x = 308 / 533 := by nlinarith [h_cos_sq]
- have h_sin' : Real.sin x = 435 / 533 := by
- have h9 : Real.sin x = (22 * Real.cos x - 7) / 7 := h_sin
- rw [h9, h_cos]
- norm_num
- have h_csc_cot : (1 / Real.sin x : R) + (1 / Real.tan x : R) = (29 / 15 : R) := by
- have h10 : Real.sin x \neq 0 := by
- by_contra h
- have h11 : Real.sin x = 0 := by linarith
- rw [h11] at h3
- have h12 : Real.cos x ^ 2 = 1 := by nlinarith
- have h13 : Real.cos x = 1 V Real.cos x = -1 := by
- have h14 : Real.cos x ^ 2 - 1 = 0 := by linarith
- have h15 : (Real.cos x - 1) * (Real.cos x + 1) = 0 := by
- ring_nf at h14
- linarith
- cases (mul_eq_zero.mp h15) with
- | inl h16 => left; linarith
- | inr h17 => right; linarith
- cases h13 with
- | inl h14 =>
- have h15 : Real.cos x = 308 / 533 := h_cos
- linarith
- ```
- ```
- inr h14 =>
- have h15 : Real.cos x = 308 / 533 := h_cos
- linarith
- have h11 : Real.tan x \(\neq 0:=\) by
- by_contra h
- have h12 : Real.sin \(\mathrm{x}=0:=\) by
- rw [Real.tan_eq_sin_div_cos] at h
- have h13 : Real.cos \(\mathrm{x} \neq 0:=\) h2
- field_simp [h13] at h
- linarith
- contradiction
- have h12 : (1 / Real.sin x : R) + (1 / Real.tan x : R) \(=(29 / 15: R):=\) by
- have h13 : Real.tan x = Real.sin x / Real.cos x := Real.tan_eq_sin_div_cos x
- rw [h13]
- have h14 : Real.sin \(\mathrm{x} \neq 0:=\) h10
- have h15 : Real.cos \(\mathrm{x} \neq 0:=\) h2
- field_simp [h14, h15, h_sin', h_cos]
- norm_num
- exact h12
- have h_m : (m : R) \(=(29 / 15: R):=\) by
- have h12 : (1 / Real.sin x : R) + (1 / Real.tan x : R) \(=(29 / 15: R):=\) h_csc_cot
- have h13 : (1 / Real.sin x : R) + (1 / Real.tan x : R) \(=(m: R):=\) by
- exact_mod_cast h;
- rw [h13] at h12
- linarith
- have h14 : m = (29 / 15 : Q) := by
- have h15 : (m : R) \(=(29 / 15: R):=\) h_m
- have h16 : (m : R) \(=(29 / 15: Q):=\) by
- norm_num at h15 \%
- exact_mod_cast h15
- exact_mod_cast h16
- rw [h14]
- norm_num
- ```
列表 2:Kimina-Prover 找到的 AIME 1991 Problem 9 的 Lean 4 证明。
Kimina-Prover 还擅长在 Lean 4 战术 calc 下进行长时间计算。这在 aime_1997_p9 的证明中有所体现。我们特别想指出的是,此证明中所需的 calc 块用于证明陈述 h32、h33、…、h34。这些计算步骤需要仔细和精确地考虑当前证明上下文,不能仅依赖于 Lean 4 的自动化战术,这显示了对形式定理证明领域的深刻理解。
D. 3 形式推理模式示例
以下列表展示了 Kimina-Prover 的形式推理模式。在接受问题后,模型首先使用自然语言推理来获取一般证明思路。然后,它逐步将思想形式化为 Lean 4 代码。在此过程中,模型进一步确保推理的严谨性,并审慎考虑如何有效利用适当的战术来形式化证明。在完成证明后,模型将所有 Lean 代码片段组装成连贯且完整的 Lean 证明。
输入:
– 在等差数列中,第 7 项为 30,第 11 项为 60。确定第 21 项。
theorem mathd_algebra_354 (a d :
R
\mathbb{R}
R )
(
h
0
:
a
+
6
∗
d
=
30
)
(
h
1
:
a
+
10
∗
d
=
60
)
:
\left(h_{0}: a+6 * d=30\right)\left(h_{1}: a+10 * d=60\right):
(h0:a+6∗d=30)(h1:a+10∗d=60):
a
+
20
∗
d
=
135
:
=
a+20 * d=135:=
a+20∗d=135:= by
输出:
<
<
< think>
解决等差数列的第 21 项
已知在等差数列中,第 7 项为 30,第 11 项为 60。我需要找到第 21 项。
首先,让我们考虑等差数列的结构。等差数列的一般项由
a
n
=
a
+
(
n
−
1
)
d
a_{n}=a+(n-1) d
an=a+(n−1)d 给出,其中
a
a
a 是首项,
d
d
d 是公差。
给定:
- 第 7 项 a 7 = a + 6 d = 30 a_{7}=a+6 d=30 a7=a+6d=30
-
- 第 11 项 a 11 = a + 10 d = 60 a_{11}=a+10 d=60 a11=a+10d=60
-
- 我们需要找到第 21 项
a
21
=
a
+
20
d
a_{21}=a+20 d
a21=a+20d
让我们解出 a a a 和 d d d 来找到 a 21 a_{21} a21。
从第二个方程减去第一个方程:
( a + 10 d ) − ( a + 6 d ) = 60 − 30 (a+10 d)-(a+6 d)=60-30 (a+10d)−(a+6d)=60−30
4 d = 30 4 d=30 4d=30
d = 30 / 4 = 7.5 d=30 / 4=7.5 d=30/4=7.5 或 15 2 \frac{15}{2} 215
现在,将 d = 7.5 d=7.5 d=7.5 代入第一个方程:
a + 6 ( 7.5 ) = 30 a+6(7.5)=30 a+6(7.5)=30
a + 45 = 30 a+45=30 a+45=30
a = 30 − 45 = − 15 a=30-45=-15 a=30−45=−15
所以,第 21 项是 a 21 = a + 20 d = − 15 + 20 ( 7.5 ) = − 15 + 150 = 135 a_{21}=a+20 d=-15+20(7.5)=-15+150=135 a21=a+20d=−15+20(7.5)=−15+150=135
让我们用 Lean 4 将其形式化:
- 我们需要找到第 21 项
a
21
=
a
+
20
d
a_{21}=a+20 d
a21=a+20d
import Mathlib
import Aesop
set_option maxHeartbeats 0
open BigOperators Real Nat Topology Rat
theorem mathd_algebra_354 (a d : R) (h
我们有两个方程:
- a + 6 d = 30 ( h 0 ) a+6 d=30\left(h_{0}\right) a+6d=30(h0)
-
-
a
+
10
d
=
60
(
h
1
)
a+10 d=60\left(h_{1}\right)
a+10d=60(h1)
我们需要找到 a + 20 d a+20 d a+20d。
从这两个方程中,我们可以消除 a a a 来求解 d d d。从 h 1 h_{1} h1 减去 h 0 h_{0} h0:
( a + 10 d ) − ( a + 6 d ) = 60 − 30 (a+10 d)-(a+6 d)=60-30 (a+10d)−(a+6d)=60−30
4 d = 30 4 d=30 4d=30
d = 30 / 4 = 7.5 d=30 / 4=7.5 d=30/4=7.5 或 15 2 \frac{15}{2} 215
让我们在 Lean 中计算这个:
-
a
+
10
d
=
60
(
h
1
)
a+10 d=60\left(h_{1}\right)
a+10d=60(h1)
have hd : d = 15 / 2 := by
linarith
```
现在我们有 $d=\frac{15}{2}$。让我们验证这个计算:
从 $a+10 d=60$ 和 $a+6 d=30$,相减得到 $4 d=30$,所以 $d=\frac{30}{4}=\frac{15}{2}$。这是正确的。
接下来,我们将 $d=\frac{15}{2}$ 代入其中一个方程来求解 $a$。让我们使用 $h_{0}: a+6 d=30$
$a+6\left(\frac{15}{2}\right)=30$
$a+45=30$
$a=30-45=-15$
在 Lean 中,一旦我们有了 $d$,我们就可以确定 $a$:
have ha : a = -15 := by
linarith [h
```
现在我们需要计算
a
+
20
d
:
a
+
20
d
=
−
15
+
20
(
15
2
)
=
−
15
+
150
=
135
a+20 d: a+20 d=-15+20\left(\frac{15}{2}\right)=-15+150=135
a+20d:a+20d=−15+20(215)=−15+150=135
在 Lean 中,我们可以直接使用
a
a
a 和
d
d
d 的值来计算
a
+
20
d
a+20 d
a+20d:
linarith [ha, hd]
Lean 证明之所以简洁,是因为一旦我们有了
d
=
15
2
d=\frac{15}{2}
d=215 和
a
=
−
15
a=-15
a=−15,它可以直接计算
a
+
20
d
=
a+20 d=
a+20d=
−
15
+
20
⋅
15
2
=
−
15
+
30
⋅
15
1
=
−
15
+
150
=
135
-15+20 \cdot \frac{15}{2}=-15+30 \cdot \frac{15}{1}=-15+150=135
−15+20⋅215=−15+30⋅115=−15+150=135 使用线性算术。
所以,序列的第 21 项是 135 。
import Mathlib
import Aesop
set_option maxHeartbeats 0
open BigOperators Real Nat Topology Rat
theorem mathd_algebra_354 (a d : R) (h}\mp@subsup{h}{0}{0}:a+6*d=30) (h}\mp@subsup{h}{1}{1}:a+10*d=60):
a + 20* d = 135 := by
have hd : d = 15 / 2 := by
linarith
have ha : a = -15 := by
linarith [h0, hd]
linarith [ha, hd]
```
# E 与 BFS-Prover 的证明对比
所有以前证明器在 miniF2F 基准测试中的表现表明,BFS-Prover 解决了最多的 IMO 问题——总共五个:imo_1969_p1、imo_1960_p2、imo_1962_p2、imo_1964_p2 和 imo1983_p6。Kimina-Prover 能够正确证明这五个问题中的每一个。下面,我们选择一个例子 imo_1962_p2 来比较 BFS-Prover 和 Kimina-Prover 生成的证明。
我们观察到 Kimina-Prover 通过分解论证为多个 'have' 语句来生成证明,从而形成了清晰且高度可读的逻辑结构。相比之下,BFS-Prover 生成的证明——依赖于逐步战术搜索——使得直接从代码中辨别每一步的目的变得困难。这种对比突显了 Kimina-Prover 强大的证明草图规划能力。
theorem imo_1962_p2 (x : R) (h 0 : 0 \leq 3 - x) (h 1 : 0 \leq x + 1)
(h 2 : 1 / 2 < Real.sqrt (3 - x) - Real.sqrt (x + 1)) : -1 \leq x \wedge x < 1 - Real.sqrt 31 / 8 := by
have h3 : -1 \leq x := by
nlinarith
have h4 : Real.sqrt (3 - x) - Real.sqrt (x + 1) > 1 / 2 := by linarith
have h5 : Real.sqrt (x + 1) \geq 0 := Real.sqrt_nonneg (x + 1)
have h6 : (7 / 4 - 2 * x) > Real.sqrt (x + 1) := by
nlinarith [Real.sq_sqrt (show (0 : R) \leq 3 - x by linarith), Real.sq_sqrt (show (0 : R) \leq x +
1 by linarith),
Real.sqrt_nonneg (3 - x), Real.sqrt_nonneg (x + 1)]
have h7 : (7 / 4 - 2 * x) ^ 2 > (Real.sqrt (x + 1)) ^ 2 := by
nlinarith [h6, Real.sqrt_nonneg (x + 1)]
have h8 : (7 / 4 - 2 * x) ^ 2 > x + 1 := by
have h10 : (Real.sqrt (x + 1)) ^ 2 = x + 1 := by
rw [Real.sq_sqrt]
linarith
nlinarith [h7, h10]
have h9 : 64 * x ^ 2 - 128 * x + 33 > 0 := by
nlinarith [h8]
have h10 : x < 1 - Real.sqrt 31 / 8 := by
by_contrs hx
push_neg at hx
have h12 : Real.sqrt 31 > 0 := by
apply Real.sqrt_pos.mpr
norm_num
nlinarith [neg (x - (1 - Real.sqrt 31 / 8)), sq_nonneg (Real.sqrt 31), Real.sq_sqrt
(show (0 : R) \leq31 by norm_num),
h12]
exact 〈h3, h10〉
```
列表 3:Kimina-Prover 找到的 IMO-1962-P2 的 Lean 4 证明。
theorem imo_1962_p2 (x : R)
(h0:0<=3-x)
(h1:0<=x+1)
(h2:1/2<sqrt(3-x)-sqrt(x+1)):
-1<= x and x < 1 - sqrt(31)/8 := by {
constructor
linarith
rw [+- sub_pos]
field_simp [Real.sqrt_lt] at h2 |-
apply lt_of_le_of_lt
rw [mul_comm]
rw [sub_sq_add_neg]
apply lt_of_le_of_lt
rw [+- lt_sub_iff_add_lt]
ring_nf
rw [+- lt_sub_iff_add_lt]
linarith [Real.sq_sqrt (by linarith : 0<= 1 + x)]
rw [Real.sqrt_lt (by norm_num)]
rw [Real.sqrt_lt] <;> nlinarith
norm_num at this
}
列表 4:BFS-Prover 找到的 IMO-1962-P2 的 Lean 4 证明。
参考论文:https://arxiv.org/pdf/2504.11354



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











